引言
这周在公司里学习了一些关于mysql的知识,听完之后感觉之前学习的数据库都太基础了。
知识点有很多,在这里做个总结也让自己消化吸收一下一、数据库引擎
- 什么叫数据库引擎呢?他就是用来把自己写的代码和数据库可以连接起来的一种组件。
- 下表是mysql可以使用的一些数据库引擎,这次重点介绍的是InnoDB
| Engine | Support | Comment | Transactions | XA | Savepoints |
|---|---|---|---|---|---|
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
二、为什么用InnoDB
InnoDB和MyISAM对比
| Feature | MylSAM | InnoDB |
|---|---|---|
| Clustered indexes(聚合索引) | No | Yes |
| B-tree indexes | Yes | Yes |
| Hash indexes | No | No |
| T-tree indexes | No | No |
| Full-text search indexes(全文索引) | Yes | Yes |
| Data caches | No | Yes |
| Foreign key support | No | Yes |
| Locking granularity(锁粒度) | Table | Row |
| Transactions | No | Yes |
| Storage limits(存储空间限制) | 256TB | 64TB |
| Compressed data(数据压缩) | Yes | Yes |
注:
1.MylSAM的压缩表必须使用压缩行格式,这种表在MylSAM里是只读的
2.T-tree: 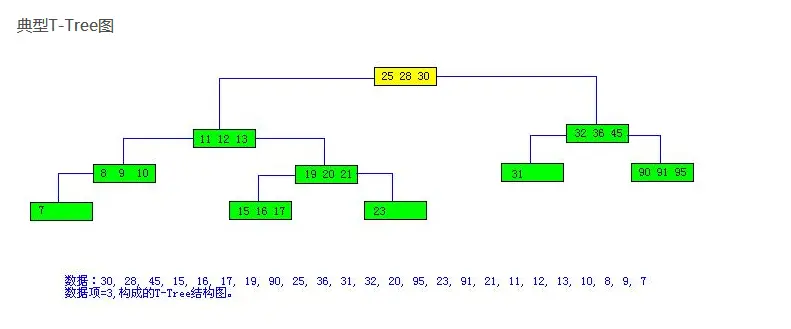
这可以理解为一个二叉树,我们可以看到每个节点都有只要有子节点都会有三个数据,如果要寻找某个数据,比如要找23,那么先看23比25小,
那就是在根节点的左几点,左节点的数据为11、11、13,23比13大,那么就是在改节点的右节点,右节点的数据为19、20、21,23比21大,
那么在就是在该节点的右节点,最后成功找到23。3.MySql-InnoDB-缓存管理(将命中率高的数据存入内存中)(www.2cto.com/database/20...
- 可能之前MyISAM使用的会比较多,作为一个前端对这块不是很了解,不过这次分享对比这两种数据库引擎的对面,InnoDB的优势还是很明显的。InnoDVB除了在可存贮空间上会比MyISAM少一些,在其他性能上还是具有很大优势的
- InnoDB的优势
- 遵循ACID原则(atomicity原子性,consistency一致性,isolation隔离性,durability持久性),具有事务特性的能力:
- 原子性(Atomicity):一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性
- 一致性(Consistency): 数据库总是从一个一致性的状态转换到另一个一致性的状态。
- 隔离性(Isolation):一个事务所做的修改在最终提交以前,对其他事务是不可见的。
- 持久性(Durability):一旦事务提交,则其所做的修改不会永久保存到数据库。
- 行级锁和Oracle风格的读一致性,提高多用户下的并发度和性能
- 只有通过索引条件检索数据,InnoDB才使用行级锁,否则仍然使用表锁
- 支持外键约束
3.使用InnoDB的好处
-
崩溃后能很好地恢复
- 未完成的事务将根据redo log的数据重做
- 已提交但未写入的修改,将从doublewrite buffer重做
- 系统闲时会purge buffer
-
维护一个内存中的buffer pool缓冲池,数据被访问时,表和索引数据会被缓存
-
对增删改的change buffering 策略,如果被修改数据的页不在缓冲池中,则这个修改可以存在change buffer 中,等相应页被放进缓冲池(发生对该页的访问)时,再写入修改,称为merge
-
adaptive hash index ,经常被访问的页会自动在内存建立一个哈希索引,适于=和IN的查询。buffer pool中会预留这种索引需要的内存空间。建立在已有的B树索引基础上,哈希索引可以是部分的,B树索引不需要全部缓存在缓冲池中
-
使用checksum校验和机制检测内存或硬盘的损坏
-
InnoDB是为处理巨大数据量的最大性能设计
-
可以在一个查询中join混用InnoDB引擎的表和其他引擎的表
ok,这一段是纯复制粘贴过来的,这样看不太好理解,这一块可以先带过,往下看会更好理解这些好处和优势
三、MYSQL 执行计划(explain详解)
- 初学sql语法的时候应该知道几个最基本的增删改查语法,但是这这些曾删改查的操作到底对数据库进行了说明操作呢,其实这是操作也是可以查看的,操作叫做'执行计划'。要查看这个执行计划很简单,只要
explain + sql 语句即可 - 为什么要看这个执行计划呢?其实只要sql语句执行对了,就可以达到预期的效果,但是通过对执行计划的查询会返回一些参数,我们就可以根据这些参数来优化sql语句,下面就来介绍这些返回的参数
1. id
- select查询的序列号
2. select_type
- simple:这是一种最简单的查询,不包含子查询也不包含多表联合查询,也没有union(自动压缩多个结果集合中的重复结果);无论查询语句是多么复杂,执行计划中select_type为simple的单位查询一定只有一个
- primary: 一个需要Union操作或含子查询的select查询执行计划中。与simple一样,select_type为primary的单位select查询也只存在1个,位于查询最外侧的select单位查询的select_type为primary
- union : 由union操作联合而成的单位select查询中,除第一个外,第二个以后的所有单位select查询的select_type都为union。union的第一个单位select的select_type不是union,而是DERIVED。它是一个临时表,用于存储联合(Union)后的查询结果。
- DERIVED:子查询中FROM后面的语句
- UNION RESULT:使用union的结果
3. table
- 输出的行所引用的表
4. type
sql
这一块返回的值相当重要,这是判断sql语句性能最重要的标准,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index >ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。-
All : 全数据表扫描。花费时间最长。如果你搜索的条件里没有加上索引的话,哪怕得到的结果只有一条数据,他也要把全表查询一遍,也属于ALL
-
index: 扫描全部索引树。
-
range: 扫描部分索引。扫描部分索引,索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行,常见于between、<、>等的查询
-
ref :非唯一性索引扫描,就是这个查询的字段添加了索引,但是并不是主键,他和RANGE 的区别是RANGE 的查询条件是一个范围,而ref只是固定的一个或多个值
-
eq_ref: 唯一性索引扫描,也就是说搜索的字段是一个组件,比如用户表的用户id,因为主键的唯一性,返回的数据只可能有一条
-
const: 表最多有一个匹配行,因为仅有一行,在这行的列值可被优化器剩余部分认为是常数,const表很快,因为它们只读取一次。
-
system: 表仅有一行。这是const联接类型的一个特例。
最后两种情况过去特殊,毕竟一个表只有一条数据的情况不常有
5. possible_keys
- 代表这次查询可能会用到的索引,其实就是搜索的时候查询条件里有索引的字段
6.key
- 真实用到的索引。查询的字段中可能出现了好几个存在索引的字段,但并不是所有都会用到,他最终用到的只有最优的索引
7.key_len
- 显示MySQL决定使用的键长度。表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。如果键是NULL,长度就是NULL。
8.ref
- 显示索引的那一列被使用了,如果可能,是一个常量const。
9.rows
- mysql 预估为了找到所需的行而要读取的行数
10.Extra
- Using filesort: mysql对数据使用一个外部的索引排序,而不是按照表内的索引进行排序读取。也就是说mysql无法利用索引完成的排序操作成为"文件排序"
- Using temporary: mysql 对查询结果排序时会使用临时表。
- Using index : 此值表示mysql将使用覆盖索引,以避免访问表。
- 覆盖索引(Covering Index):也叫索引覆盖。就是select列表中的字段,只用从索引中就能获取,不必根据索引再次读取数据文件,换句话说查询列要被所建的索引覆盖。 注意: a、如需使用覆盖索引,select列表中的字段只取出需要的列,不要使用
select *b、如果将所有字段都建索引会导致索引文件过大,反而降低crud性能
- 覆盖索引(Covering Index):也叫索引覆盖。就是select列表中的字段,只用从索引中就能获取,不必根据索引再次读取数据文件,换句话说查询列要被所建的索引覆盖。 注意: a、如需使用覆盖索引,select列表中的字段只取出需要的列,不要使用
- Using where: mysql 将在存储引擎检索行后再进行过滤,许多where条件里涉及索引中的列,当(并且如果)它读取索引时,就能被存储引擎检验,因此不是所有带where子句的查询都会显示"Using where"。有时"Using where"的出现就是一个暗示:查询可受益于不同的索引。
- Using join buffer: 使用了链接缓存
- Impossible WHERE:where子句的值总是false,不能用来获取任何元祖
- select tables optimized away: 在没有group by子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段在进行计算,查询执行计划生成的阶段即可完成优化
- distinct: 优化distinct操作,在找到第一个匹配的元祖后即停止找同样值得动作
四、数据库事务和隔离级别
1.事务
-
什么是事务呢,比如a给b转账100,那么a的余额要扣除100,b的余额要加100,这对数据库来说是两个操作,但是事情却是一个事情,两件事情要么一起成功,要么一起失败,决不允许出现一方成功一方失败的情况,所以这时候就把这两件事情放到了一个事务里面。
-
BEGIN 或 START TRANSACTION 显式地开启一个事务;
-
COMMIT 也可以使用 COMMIT WORK,不过二者是等价的。COMMIT 会提交事务,并使已对数据库进行的所有修改成为永久性的;
2.数据访问冲突
- 脏读(Dirty Read) : 一个事务看到另一个事务还未提交确已经发生的事件。比如说在A事务里,有个把某商品价格从100修改未200的操作,但是并没有提交。与此同时B事务要查询该商品的价格,此时数据库该商品的价格仍是100,但是因为隔离等级不够,事务B里面查出来的数据变成了200,如果事务A成功提交了当然没问题,但是如果事务A提交失败了,那么信息不久错误了吗?这种一个事务查询到另一个事务还未确认发生的事件,叫他脏读
- 脏写(Dirty Write) :假设一个场景,账号A有1000块钱,小明有权限从账号A给自己发100块钱,这时候账号A要在事务A中执行账号A-100元的操作,与此同时小王也要用账号A给自己的账号转100块钱,此时在事务B中也要执行账号A-100元。按正常情况下,账号A应当只剩800元,但是,如果事务A还未提交,对于事务A来说说,余额应该变为900,事务B来说,余额也是变为900,最后一提交,余额真就变成了900。好像是钱变多了是一件值得开心的事情,但是在代码中,这是绝对绝对不允许出现的错误。这种一个事务中把另一个事务的时间覆盖了,叫他脏写
- 幻读 :假设小王刚刚入职一家公司,公司的管理员要给小王添加一个个人账号,他发现用户列表中没有小王的信息,就准备给他添加一个账号,结果在点击添加按钮的时候发现账号已存在,然后刷新了一下小王的账号确实存在了,原来是另一个管理员在他提交事务之前先一步添加了小王的账号。类似这种存在的错误叫他幻读
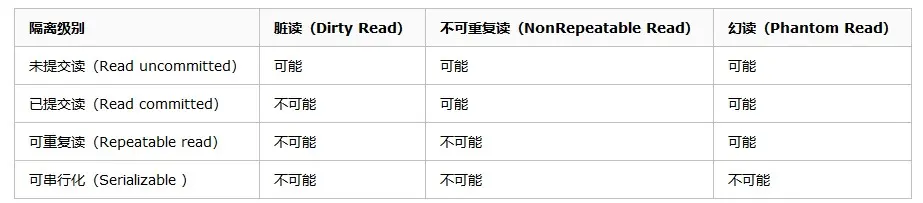
3.SQL标准中的事务四种隔离级别
-
未提交读(Read Uncommitted):这种隔离可以看到事务还未提交之前的数据,他是会出现脏读的情况的。个人感觉一般不会把隔离等级设置的这么低
-
提交读(Read Committed):只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)
-
不可重复读指的在一个事务中前后两次读取的结果并不致,例如:
在事务A中,读取到张三的工资为5000,操作没有完成,事务还没提交。
与此同时,
事务B把张三的工资改为8000,并提交了事务。
随后,在事务A中,再次读取张三的工资,此时工资变为8000。在一个事务中前后两次读取的结果并不致,导致了不可重复读。
-
-
可重复读(Repeated Read) :可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。在SQL标准中,该隔离级别消除了不可重复读,但是还存在幻象读。个人感觉出现幻读现象影响不会太大,虽然显示可能会有误,但他不会影响最后的结果
-
串行读(Serializable):完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞。虽然这样做可以完全杜绝读写错误,但是并不推荐这么做,这样做的坏处是非常明显的,他大大降低了查询的效率,相当于完全没有并发性,一个时间只能做一件事情
-
查询mysql隔离级别:select @@transaction_isolation;
五、Mysql共享锁、排他锁、悲观锁、乐观锁及其使用场景
1. Mysql锁的名称:
- 表级锁:锁定整个表
- 行级锁:仅锁定一行数据
- 页级锁:锁定一行以上数据
- 共享锁(S锁):也可叫读锁,如果设置了该锁,前三个出现的锁定数据的范围使得这部分数据不可读
- 排他锁(X锁):也可叫写锁,如果设置了该锁,前三个出现的锁定数据的范围使得这部分数据不可写
- 悲观锁、乐观锁:这两种所仅仅代表为了防止出现死锁给锁的限制大不大,不真实存在,仅仅是一个概念
2.InnoDB与MyISAM
- MyISAM 操作数据都是使用的表锁,你更新一条记录就要锁整个表,导致性能较低,并发不高。当然同时它也不会存在死锁问题
- MyISAM 操作数据都是使用的表锁,你更新一条记录就要锁整个表,导致性能较低,并发不高。当然同时它也不会存在死锁问题。而 InnoDB 与 MyISAM 的最大不同有两点:一是 InnoDB 支持事务;二是InnoDB采用了行级锁。也就是你需要修改哪行,就可以只锁定哪行。
- 在 Mysql 中,行级锁并不是直接锁记录,而是锁索引。索引分为主键索引和非主键索引两种,如果一条sql 语句操作了主键索引,Mysql 就会锁定这条主键索引;如果一条语句操作了非主键索引,MySQL会先锁定该非主键索引,再锁定相关的主键索引。
- InnoDB 行锁是通过给索引项加锁实现的,如果没有索引,InnoDB 会通过隐藏的聚簇索引来对记录加锁。也就是说:如果不通过索引条件检索数据,那么InnoDB将对表中所有数据加锁,实际效果跟表锁一样。因为没有了索引,找到某一条记录就得扫描全表,要扫描全表,就得锁定表。
六、共享锁与排他锁
- 数据库的增删改操作默认都会加排他锁,而查询不会加任何锁。
- 共享锁:对某一资源加共享锁,自身可以读该资源,其他人也可以读该资源(也可以再继续加共享锁,即 共享锁可多个共存),但无法修改。要想修改就必须等所有共享锁都释放完之后。语法为:
select * from table lock in share mode - 排他锁:对某一资源加排他锁,自身可以进行增删改查,其他人无法进行任何操作。语法为:
select * from table for update - 注意:在事务中自动加入
for update会自动把这个事务当成一个写操作,这样即使事务中只有一个查询语句,也要等其他事务提交之后才能继续进行
七、乐观锁与悲观锁
- 注意:之前已经说过,乐观锁和悲观锁知识一个概念,他不像共享锁和排他锁一样真实存在,他仅仅知识对会不会发生死锁的一个态度
- 死锁:什么叫死锁,很简单的例子,加入有两扇门A和B,他们都有各自的钥匙A和B,通过共享锁或是排他锁的方式把他们都锁上了,现在想打开A门的钥匙在事务B里面,而打开B门的钥匙在事务A里面,他们只有提交了事务才能把锁放出来,但是现在两个事务的门都关上了,那就两个事务都只能大眼瞪小眼,谁也提交不了了。
- 悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。
- 乐观锁:总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据