作者:杨泽华(玄飚)
简介
聚焦 LoongSuite 生态核心组件 LoongCollector,深度解析 LoongCollector 在智算服务中的技术突破,涵盖多租户观测隔离、GPU 集群性能追踪及事件驱动型数据管道设计,通过零侵入采集、智能预处理与自适应扩缩容机制,构建面向云原生 AI 场景的全栈可观测性基础设施,重新定义高并发、强异构环境下的可观测性能力边界。
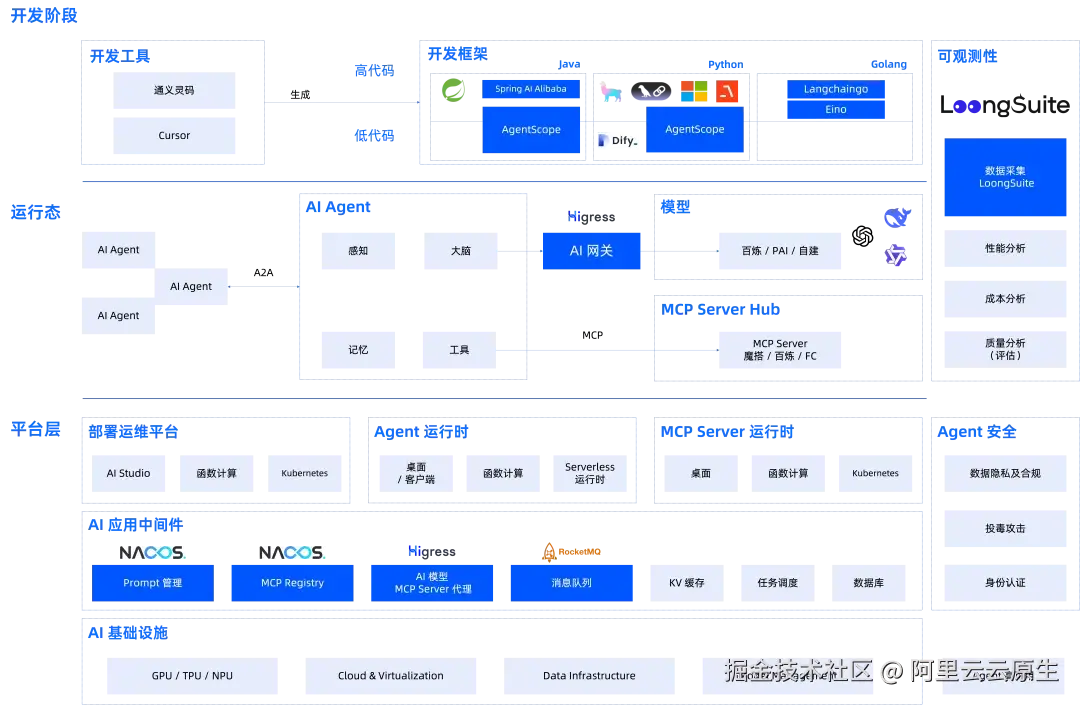
一、LoongSuite 生态中的 LoongCollector
在 AI Agent 技术体系中,可观测性作为核心基石,通过实时采集模型调用链路、资源消耗、系统性能指标等关键数据,为智能体的性能优化、安全风控及故障定位提供决策依据。它不仅支撑着动态 Prompt 管理、任务队列调度等核心流程的可视化监控,更通过追踪敏感数据流动与异常行为,成为保障 AI 系统可信运行与持续进化的关键基础设施。
LoongSuite (/lʊŋ swiːt/)(音译 龙-sweet),是阿里云开源的 AI 时代高性能低成本的可观测采集套件,旨在帮助更多企业,通过高性能低成本的方式,更高效地获取、利用标准化数据规范模型建立可观测体系。
LoongSuite 套件具备以下独特的优势:
- 零侵入采集:通过进程级插桩与主机级探针结合,无需修改代码即可捕获全链路数据。
- 全栈支持:覆盖 Java、Go、Python 等主流语言,适配云原生 AI 场景。
- 生态兼容:与 OpenTelemetry 等国际标准深度兼容,支持开源或云上托管分析平台。
而 LoongCollector 则是 LoongSuite 组件的"心脏",是 LoongSuite 组件的核心数据采集引擎,它具备三大核心能力:
- 多维度数据的统一采集能力。LoongCollector 的本质是一个 All-in-One 架构的采集器,支持包括 Logs、Metrics、Traces、Events、Profiles 的全类型数据采集,还支持通过 eBPF 等无侵入技术实现进程外数据采集,减少对业务的干扰。
- 极致的性能与稳定性。LoongCollctor 采用时间片调度和无锁化设计,实现高并发场景下的低资源消耗与高吞吐,还有高低水位反馈队列与持久化缓存,确保数据不丢失、服务不抖动。
- 灵活部署与智能路由。LoongCollector 作为其他可观测组件与下游存储的数据传输桥梁,支持灵活部署编排,将集群内不同数据源或其他 agent 产生的多维度原始可观测数据进行统一处理、结构化转换,最后智能路由、统一分发。
LoongCollector 在 LoongSuite 组件中的位置可以用下图来概括:
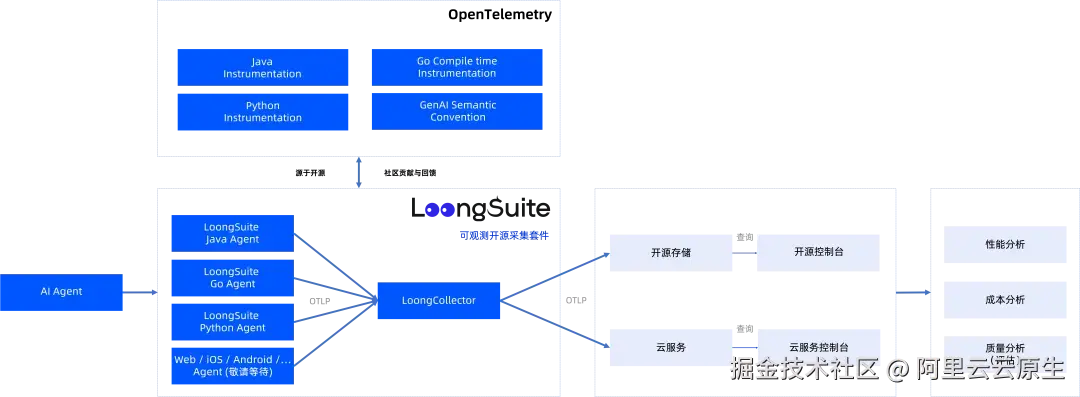
二、LoongCollector 核心优势
LoongCollector 之所以可以在 LoongSuite 组件中承担重任,是因为其拥有诸多核心优势。
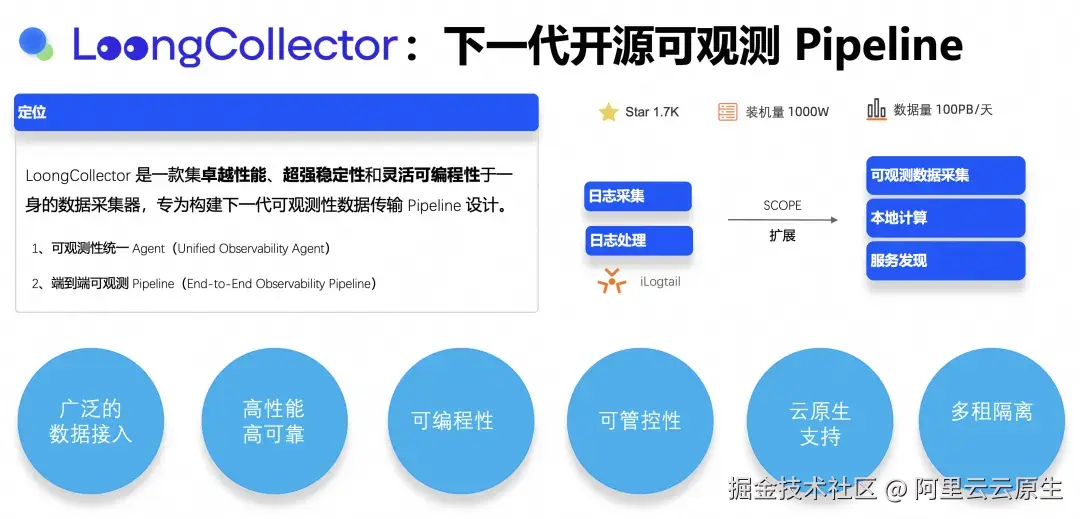
LoongCollector 是一款集卓越性能、超强稳定性和灵活可编程性于一身的数据采集器,专为构建下一代可观测 Pipeline 设计。愿景是:打造业界领先的"统一可观测 Agent(Unified Observability Agent)"与"端到端可观测 Pipeline(End-to-End Observability Pipeline)"。
LoongCollector 源自阿里云可观测性团队所开源的 iLogtail 项目,在继承了 iLogtail 强大的日志采集与处理能力的基础上,进行了全面的功能升级与扩展。从原来单一日志场景,逐步扩展为可观测数据采集、本地计算、服务发现的统一体。凭借着广泛的数据接入、高性能、高可靠、可编程性、可管控性、云原生支持、多租隔离等特点,LoongCollector 可以很好的适应智算服务可观测采集与预处理的需求场景。
遥测数据,无限边界
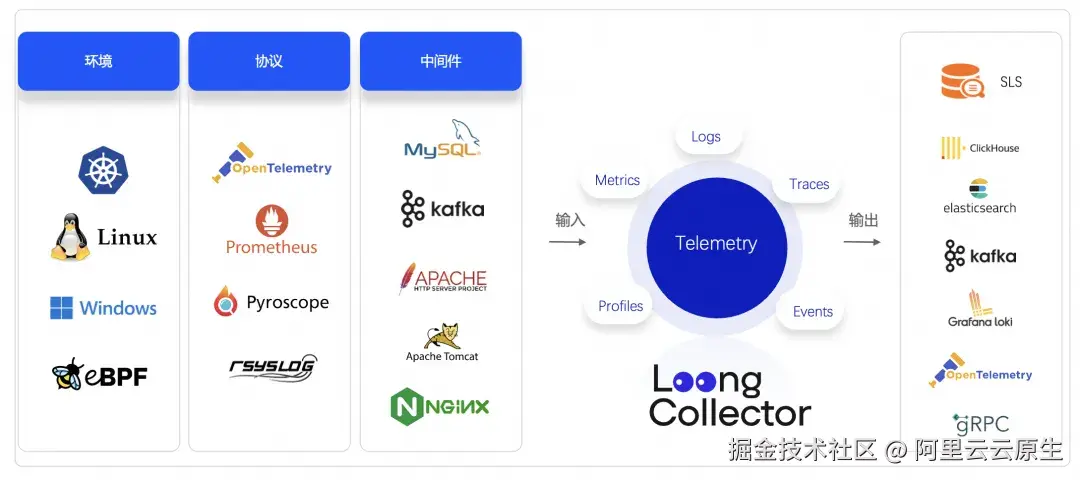
LoongCollector 秉承 All-in-One 的设计理念,致力于所有的采集工作用一个 Agent 实现 Logs、Metric、Traces、Events、Profiles 的采集、处理、路由、发送等功能。LoongCollector 着重强化了 Prometheus 指标抓取能力,深度融入 eBPF(Extended Berkeley Packet Filter)技术以实现无侵入式采集,提供原生的指标采集功能,做到真正的 OneAgent。
秉承开源、开放的原则,积极拥抱 OpenTelemetry、Prometheus 在内的开源标准;同时,支持 OpenTelemetry Flusher、ClickHouse Flusher、Kafka Flusher 等众多开源生态对接能力。作为可观测基础设施,LoongCollector 不断完善在异构环境下的兼容能力,并积极致力于实现对主流操作系统环境的全面且深度的支持。
K8s 采集场景的能力一直都是 LoongCollector 的核心能力所在。众所周知在可观测领域,K8s 元数据(例如 Namespace、Pod、Container、Labels 等)对于可观测数据分析往往起着至关重要的作用。LoongCollector 基于标准 CRI API 与 Pod 的底层定义进行交互,实现 K8s 下各类元数据信息获取,从而无侵入地实现采集时的 K8s 元信息 AutoTagging 能力。
性能可靠,无懈可击
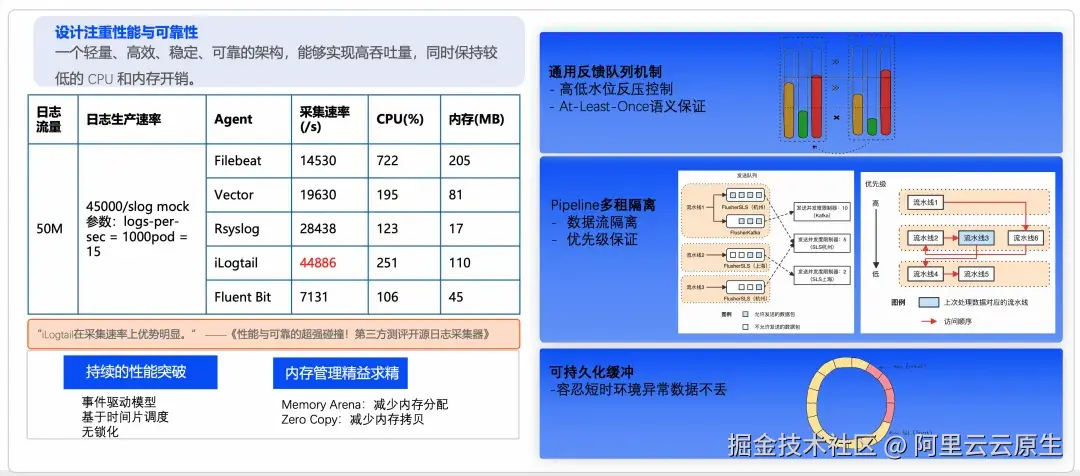
LoongCollector 始终将追求极致的采集性能和超强可靠性放在首位,坚信这是实践长期主义理念的根基。主要表现为性能、资源开销、稳定性上的精益求精。
- 持续的性能突破:采用了单线程事件驱动,并且结合时间片调度、无锁化、数据流处理免拷贝等技术,使其在具备高性能的同时资源占用也极低。
- 内存管理精益求精:使用 Memory Arena 技术减少内存的分配次数,核心数据流使用 Zero Copy 技术减少内存无效拷贝。
- 高低水位反馈队列:流量反压控制机制,At-Least-Once 语义保证。
- Pipeline 多租户隔离:不同数据流之间相互隔离,提供优先级调度机制;多目标发送,网络异常流控机制。
- 可持久化缓存:容忍短时间环境异常,保证数据不丢。
编程管道,无与伦比
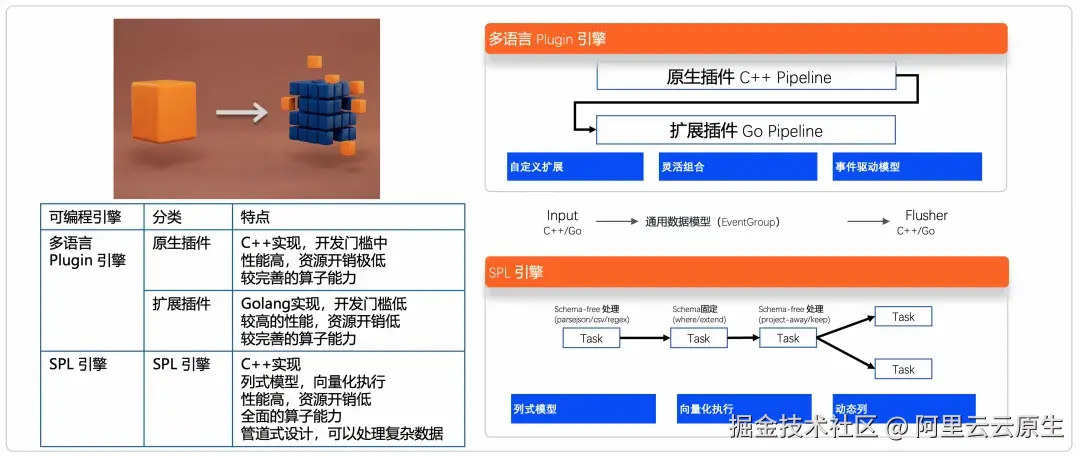
LoongCollector 通过 SPL 与多语言 Plugin 双引擎加持,构建完善的可编程体系,提供了强大的数据预处理能力。不同引擎都可以相互打通,通过灵活的组合实现预期的计算能力。
开发者可以根据自身需求灵活选择可编程引擎。如果看重执行效率,可以选择原生插件;如果看重算子全面性,需要处理复杂数据,可以选择 SPL 引擎;如果强调低门槛的自身定制化,可以选择扩展插件,采用 Golang 进行编程。
配置管理,无忧无虑
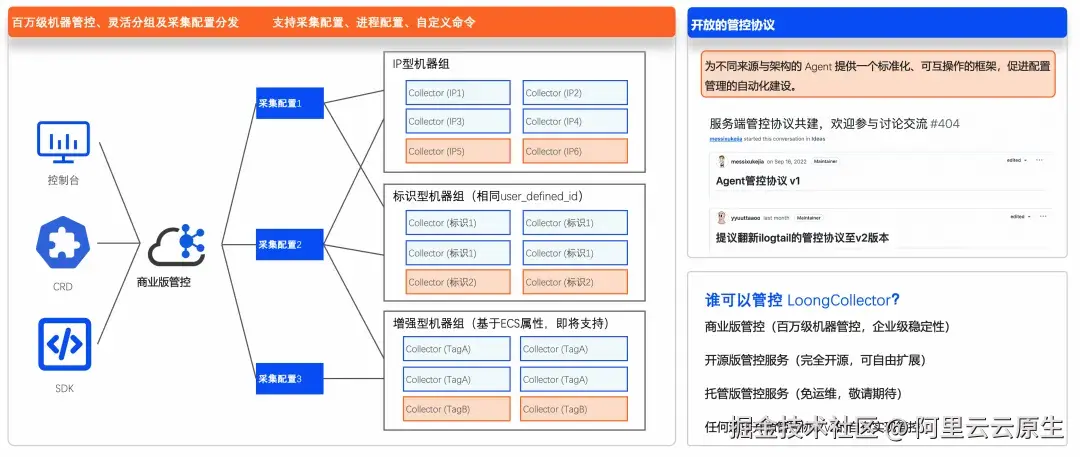
在分布式智算服务复杂的生产环境中,管理成千上万节点的配置接入是一项严峻挑战,这尤其凸显了在行业内缺乏一套统一且高效的管控规范的问题。针对这一痛点,LoongCollector 社区设计并推行了一套详尽的 Agent 管控协议。此协议旨在为不同来源与架构的 Agent 提供一个标准化、可互操作的框架,从而促进配置管理的自动化。
基于该管控协议实现的 ConfigServer 服务,可以管控任意符合该协议的 Agent,显著提升了大规模分布式系统中配置策略的统一性、实时性和可追溯性。ConfigServer 作为一款可观测 Agent 的管控服务,支持以下功能:
- 以 Agent 组的形式对采集 Agent 进行统一管理。
- 远程批量配置采集 Agent 的采集配置。
- 监控采集 Agent 运行状态,汇总告警信息。
行业对比
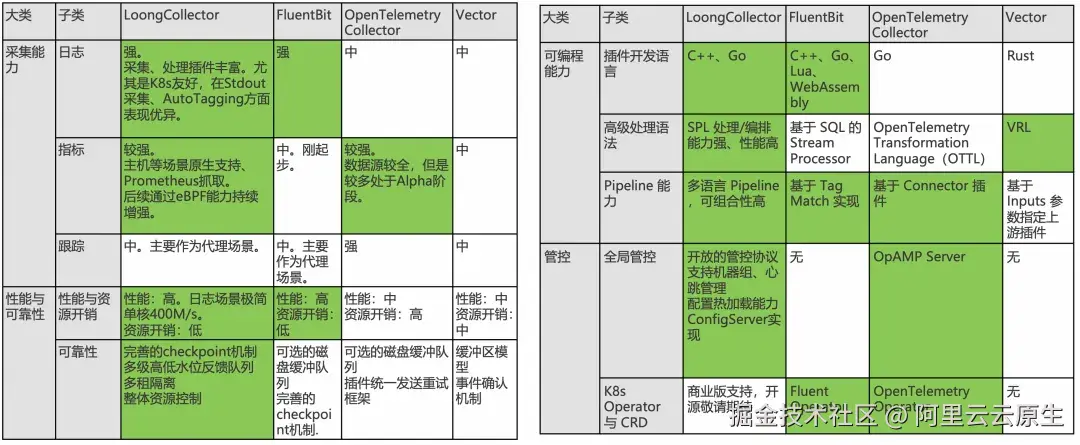
在可观测领域,Fluent Bit、OpenTelemetry Collector 及 Vector 都是备受推崇的可观测数据采集器。其中,FluentBit 小巧精悍,以性能著称;OpenTelemetry Collector 背靠 CNCF,借助 Opentelemetry 概念构建了丰富的生态体系;而 Vector 在 Datadog 加持下,则通过 Observability Pipelines 与 VRL 的组合,为数据处理提供了新的选择。而 LoongCollector 则立足日志场景,通过持续完善指标、跟踪等场景实现更全面的 OneAgent 采集能力;依托性能、稳定性、Pipeline灵活性、可编程性优势,打造核心能力的差异化;同时,借助强大的管控能力,提供了大规模采集配置管理能力。更多详见下表,绿色部分为优势项。
三、智算场景可观测需求、调整与实践
智算服务可观测需求与挑战

前面我们知道云原生架构的容器服务逐渐成为了支撑 AI 智算的基础底座。随着 AI 任务规模快速发展,特别是大模型的参数量从十亿量级跃升至万亿级别,训练规模的急剧扩张不仅引发了集群成本的显著上涨,还对系统稳定性构成了挑战。典型的挑战有:
- GPU 价格昂贵,且坏卡率高,如何自动进行坏卡检测,从而任务、环境自愈,是保证 AI 生产任务不间断的基本保障需求。
- 模型如何调参,任务为什么跑得慢,都需要暴露更多透明化的观测能力帮助进行模型性能优化,帮助调参。
- 在生产环境如进行推理任务时,如何保障集群、AI 业务任务的环境稳定性。
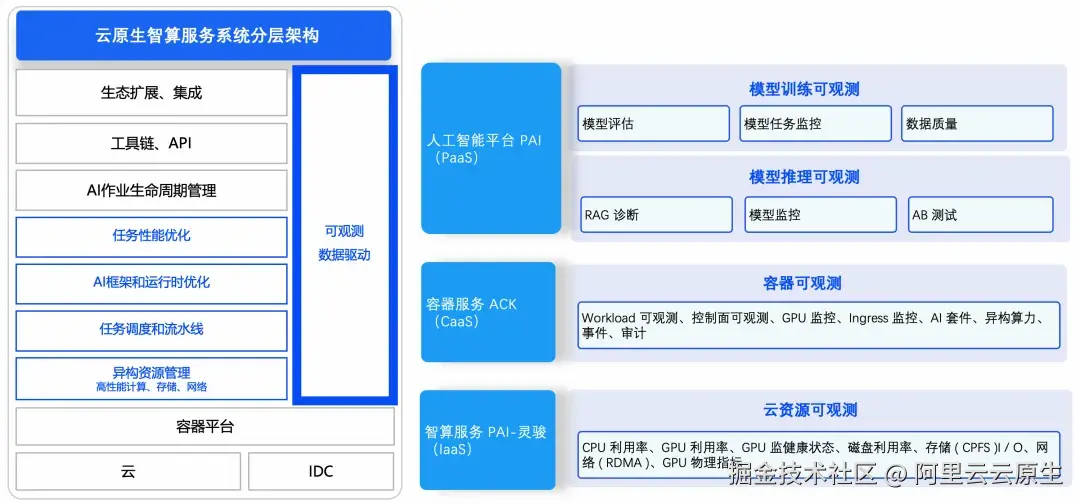
为了有效应对上述挑战,迫切需要构建可观测数据驱动的云原生智算服务架构。对应于智算服务系统分层架构,可观测体系也针对性地分为 IaaS 层云资源可观测、CaaS 层容器可观测 、PaaS 模型训练/推理可观测等三个层次。
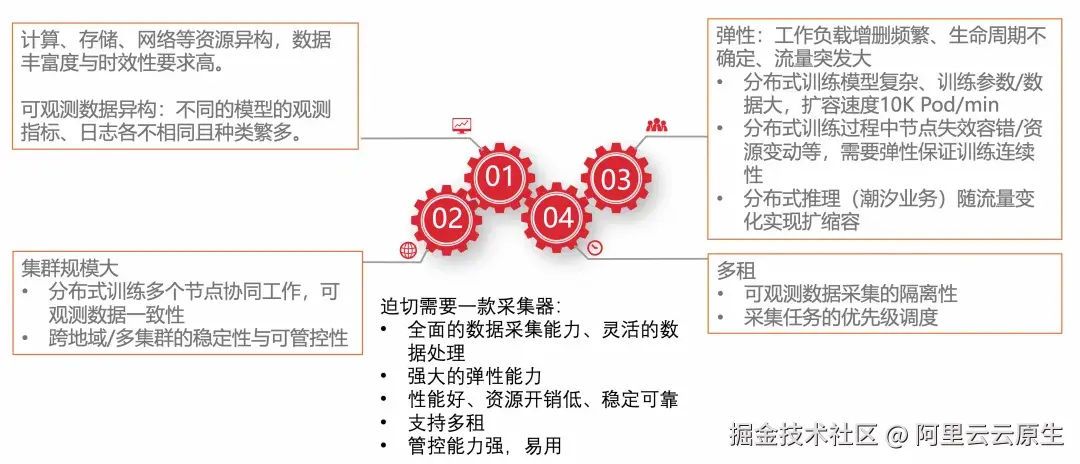
在构建面向智能计算服务的可观测性体系时,一个关键需求是如何能够适应云原生 AI 基础设施的特点,进行有效的可观测数据采集及预处理。这一过程中面临的主要挑战包括但不限于:
-
异构属性
- 资源异构:计算、存储、网络等资源异构,数据丰富度与时效性要求高。例如,GPU、CPU、RDMA、CPFS 等。
- 数据异构:从集群组件到模型所应用产生的观测指标、日志各不相同且种类繁多。
-
集群规模大
- 分布式训练多个节点协同工作,可观测数据一致性。
- 多集群/跨地域训练时稳定性,能够应对网络不稳定的风险。
- 大规模多集群下采集任务的可管控性。
-
弹性:工作负载增删频繁、生命周期不确定、流量突发大。
- 分布式训练模型复杂、训练参数/数据大,扩容速度 10K Pod/min。
- 分布式训练过程中节点失效容错/资源变动等,需要弹性保证训练连续性。
- 分布式推理(潮汐业务)随流量变化进行扩缩容。
-
多租
- 可观测数据采集的隔离性。
- 采集任务的优先级调度。
因此,迫切需要一款强大的适应于云原生智算服务的可观测 Pipeline,它需要集可观测采集与预处理于一身,具备全面的数据采集能力、灵活的数据处理;强大的弹性能力;性能好、资源开销低、稳定可靠;支持多租;管控能力强,易用等特点。
恰好的是,LoongCollector 就是这样的一款 集可观测采集与预处理于一身、具备强大的弹性伸缩能力、高性能、低开销、多租管控友好的、稳定可靠的可观测数据采集器。下面,我们来讲讲 LoongCollector 如何处理与应对这些挑战。
智算服务 LoongCollector 实践
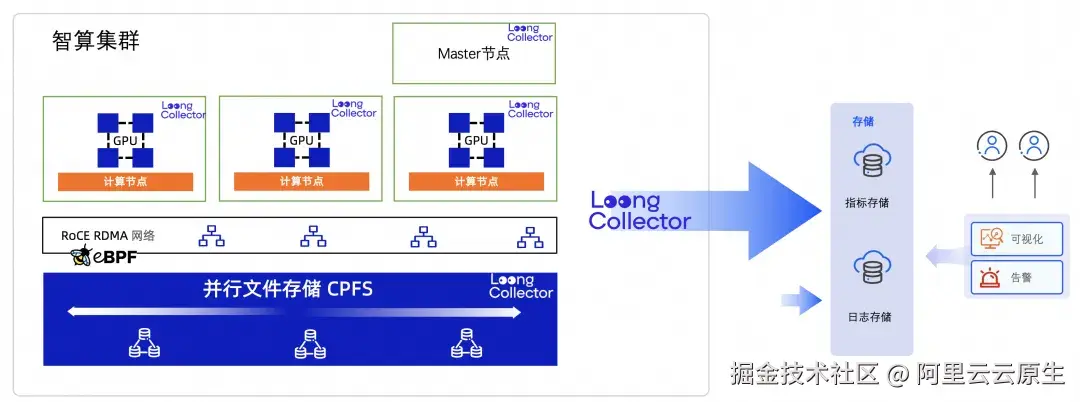
作为一款高性能的可观测数据采集与预处理 Pipeline,LoongCollector 在智算集群中具备如下几种工作模式:
-
Agent 模式:As An Agent
- LoongCollector 作为 Agent 运行在智算集群的节点上,每个 LoongCollector 实例专注于采集所在节点的多维度可观测性数据。
- 充分利用本地计算资源,实现在数据源头的即时处理,降低了数据传输带来的延迟和网络流量,提升了数据处理的时效性。
- 具备随节点动态扩展的自适应能力,确保在集群规模演变时,可观测数据的采集与处理能力无缝弹性伸缩。
-
集群模式:As A Service
- LoongCollector 部署于一个或多个核心数据处理节点,以多副本部署及支持扩缩容,用于接收来自系统内 Agent 或开源协议的数据,并进行转换、汇集等操作。
- 作为中心化服务,便于掌握整个系统的上下文,强化了集群元数据的关联分析能力,为深入理解系统状态与数据流向奠定了基础。
- 作为集中式服务枢纽,提供 Prometheus 指标抓取等集群数据抓取和处理能力。
分布式指标采集
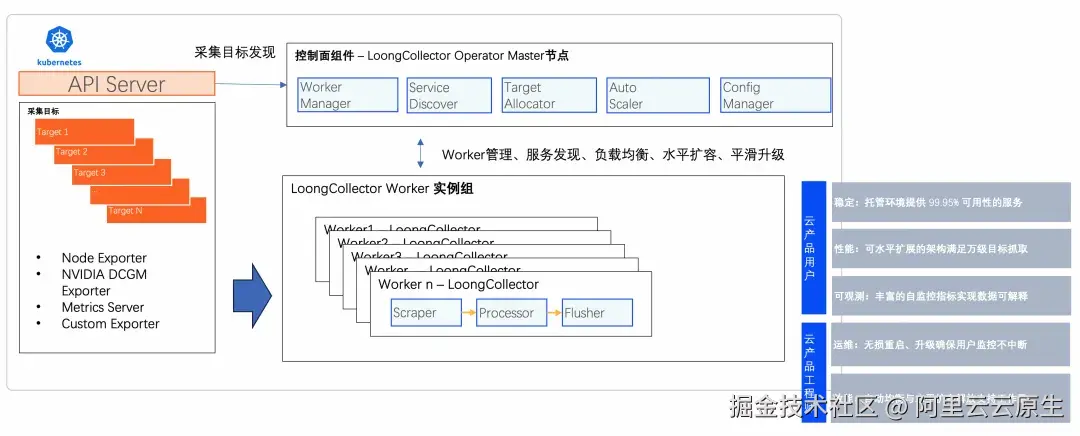
鉴于智算服务系统架构的复杂性和多样性,需要对多种关键性能指标进行监控。这些指标涵盖了从基础设施层面到应用层面的范围,并且以 Prometheus Exporter 的形式对外提供数据接口。例如针对计算节点资源的 Node Exporter,针对 GPU 设备的 NVIDIA DCGM Exporter,针对集群的 kube-state-metrics,针对训练框架的 TensorFlow Exporter、PyTorch Exporter 等。
LoongCollector 具备原生支持直接抓取 Prometheus Exporter 所暴露的各项指标的能力,采用 Master-Slave 多副本采集模式。
- Master 功能由 LoongCollector Operator 承载,根据服务发现结果提供 Target Allocator 能力,实现 Woker 负载均衡、水平扩缩容能力、平滑升级等能力。
- Worker 节点则由 LoongCollector 承载,采用 Pipleline 架构,根据 Target Allocator 结果进行指标抓取与处理。
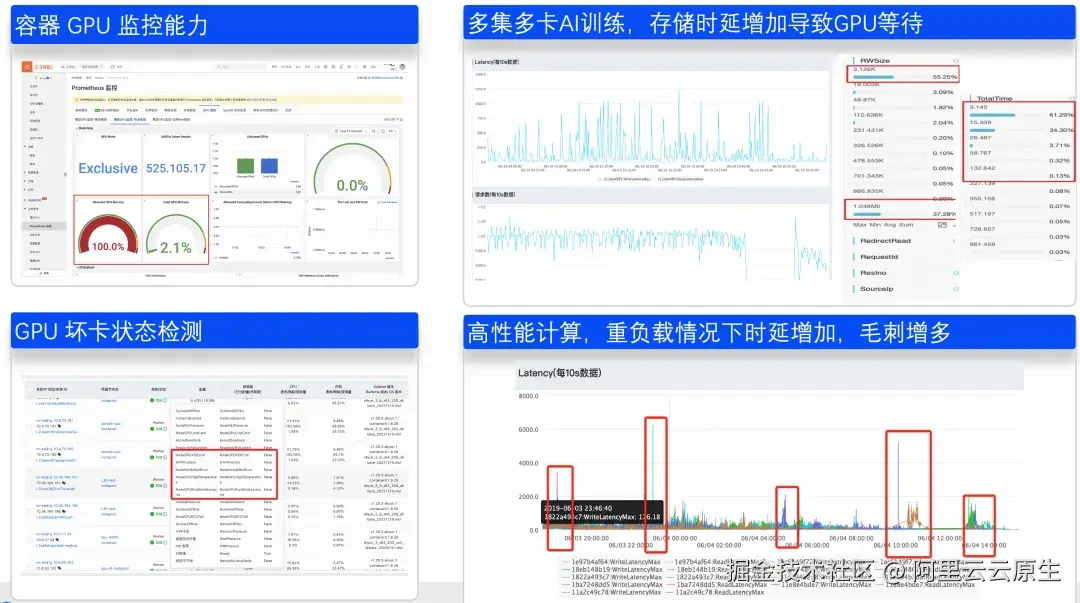
基于智算服务采集的指标结果,可以通过可视化仪表盘进行 GPU 使用量监控及坏卡状态检测。同时对于高吞吐量的场景,可以快速发现多集群多卡 AI 训练的瓶颈点,以便更好的提升 GPU 等资源利用率。
分布式日志采集
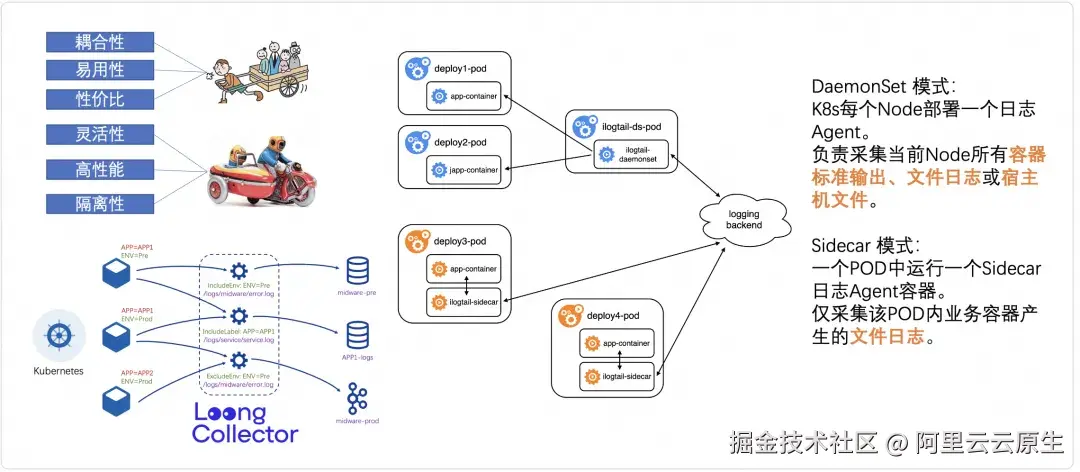
在智算集群日志采集场景下,LoongCollector 根据业务要求提供了灵活的部署方式。
- DaemonSet 方式:在集群的每个节点上部署一个 LoongCollector,负责采集该节点上所有容器的日志;特点:运维简单、资源占用少、配置方式灵活;但是隔离性较弱。
- Sidecar 方式:每个 Pod 中伴随业务容器运行一个 LoongCollector 容器,用于采集该 Pod 中业务容器产生的日志;特点:多租户隔离性好、性能好;但资源占用较多。
不管是分布式训练还是推理服务部署,都有较强的弹性特点。LoongCollector 很好的适应了弹性与多租的要求:
-
容器自动发现:通过访问位于宿主机上容器运行时(Docker Engine/ContainerD)的 sock 获取容器的上下文信息。
- 容器层级信息:容器名、ID、挂载点、环境变量、Label
- K8s层级信息:Pod、命名空间、Labels。
-
容器过滤及隔离性:基于容器上下文信息,提供采集容器过滤能力,既可以保证采集的隔离性,也可以减少不必要的资源浪费。
-
元信息关联:基于容器上下文信息和容器环境变量,提供在日志中富化 K8s 元信息的能力。
-
采集路径发现
- 标准输出:可以根据容器元信息自动识别不同运行时的标准输出格式和日志路径,不需要额外手动配置。
- 容器内文件:对于 overlay、overlay2 的存储驱动,根据日志类型及容器运行时自动拼接出采集路径。
数据处理方案:容器上下文关联与数据处理
智算服务场景下,为了最大化地挖掘数据价值,通常需要将集群日志、分布式训练日志以及推理服务日志高效采集并传输至后端日志分析平台,并在此基础上实施一系列的数据增强策略。对于分布式训练日志而言,需要关联容器上下文需包含容器 ID、Pod 名称、命名空间和节点信息,确保追踪和优化跨容器的 AI 训练任务;推理服务为了针对访问流量等进行更高效的分析,需要对日志进行字段标准化处理,同时也需要关联容器上下文。
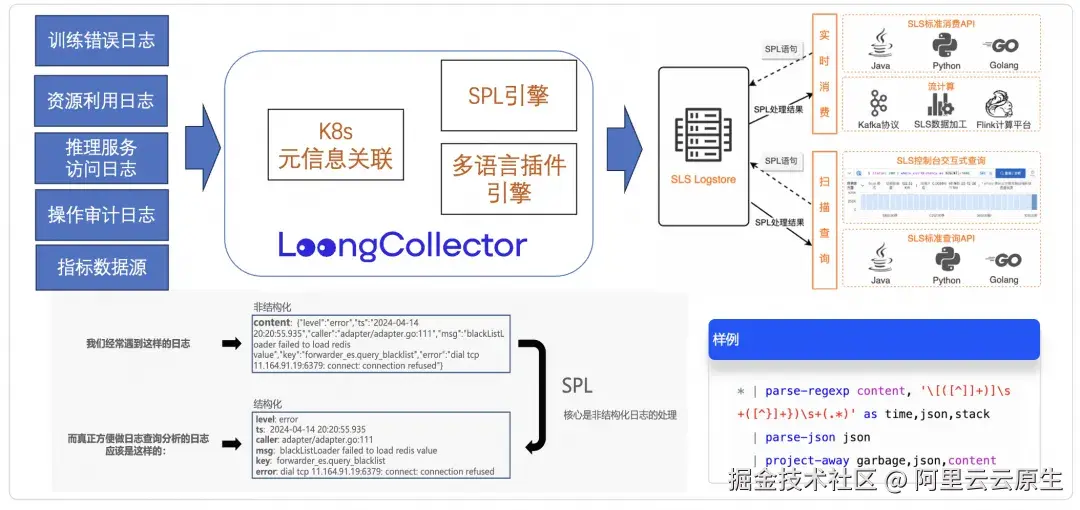
LoongCollector 凭借强大的计算能力,可以针对接入的数据,关联 K8s 元信息;同时,利用 SPL、多语言插件计算引擎,提供灵活的数据处理编排能力,便于处理各类负责格式。
如下是一些典型的日志处理场景:
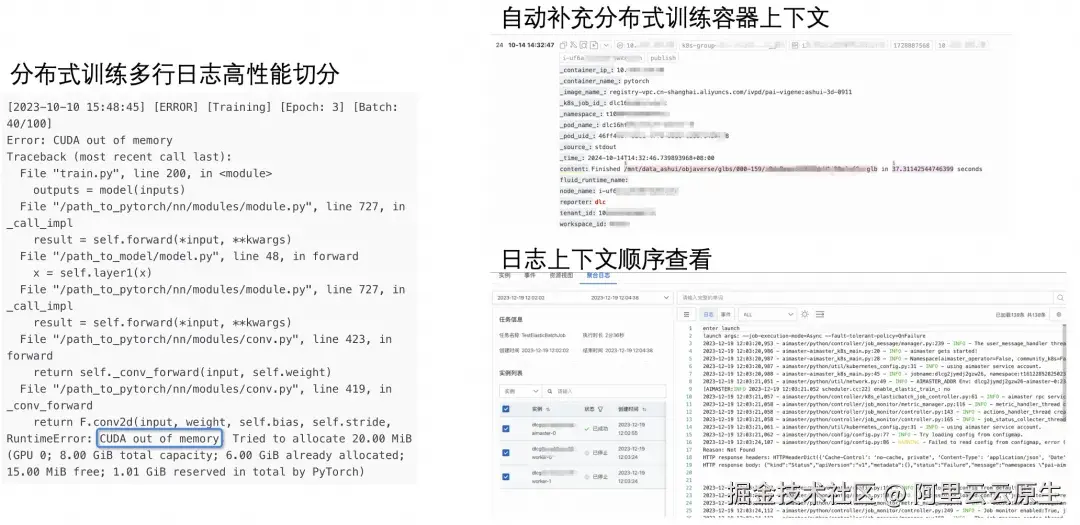
- 分布式训练多行日志切分:训练异常往往涉及调用栈信息,通常以多行形式呈现。
- 分布式训练、推理服务容器上下文关联:便于追踪异常训练任务与线上服务。
- 日志上下文顺序查看:采集到日志分析系统不会导致日志乱序。
eBPF 采集
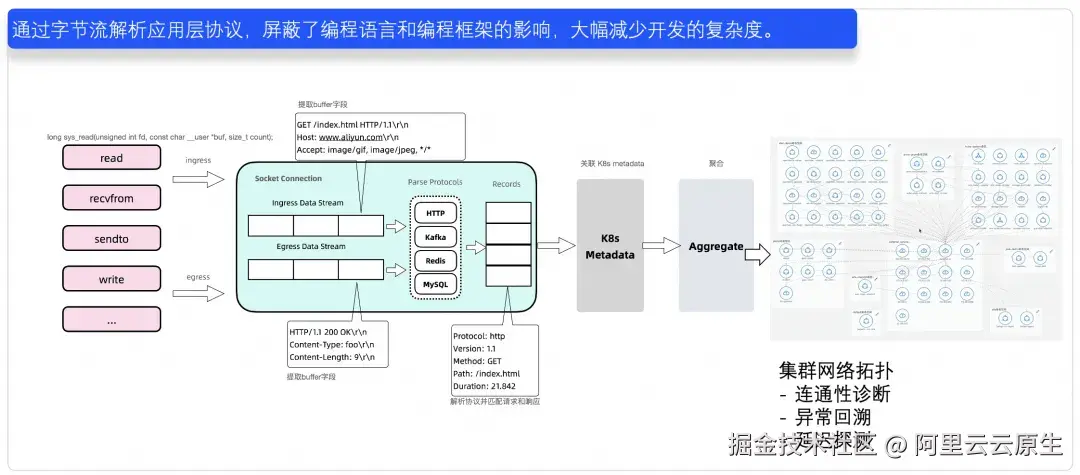
在分布式训练框架下,多个计算节点协同工作以加速模型训练过程。然而,在实际操作中,整体系统性能可能受到多种因素的影响而变得不稳定,如网络延迟、带宽限制及计算资源瓶颈等,这些都可能导致训练效率的波动甚至下降。LoongCollector 通过 eBPF 技术,在智算服务中实现无侵入网络监控,通过实时捕获和分析流量,识别集群网络拓扑,达到快速捕获异常点的作用,进而提升整个模型训练的效率。
Pipeline 自身可观测
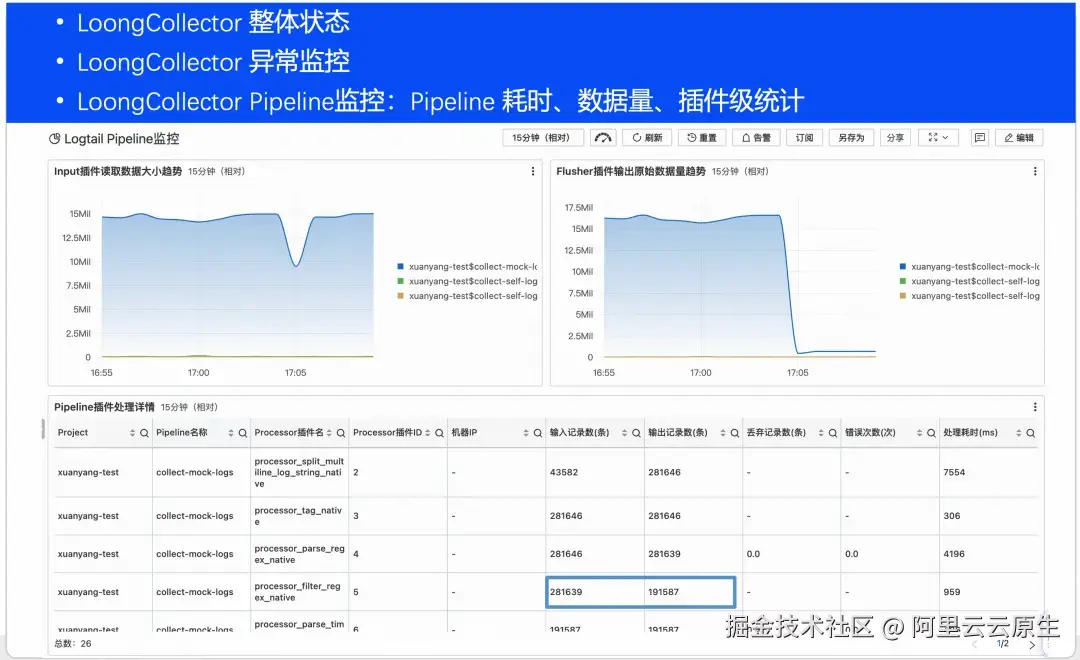
LoongCollector 作为可观测采集的基础设置,其自身稳定性的重要性不言而喻。然而运行环境是复杂多变的,因此,针对自身运行状态的可观测进行了重点建设,方便在大规模集群中及时发现采集异常或瓶颈。
- 整体运行状态的监控,包括 CPU、内存、启动时间等。
- 所有采集 Pipeline 都有完整指标,可以在 Project/Logstore 等维度上进行不同采集配置的统计与比较。
- 所有插件都有自己的指标,可以构建完整流水线的拓扑图,每个插件的状态可以进行清楚的观测。
四、探索数据采集的未来
未来,LoongCollector 将持续围绕长期主义进行建设,打造核心竞争力,以适应 AI 时代快速发展的需求。
我们会通过 C++ 化、框架优化、内存控制、缓存等方式,将 LoongCollector 的性能进一步优化、稳定性进一步提升。
通过进一步支持 Promethues 抓取能力、eBPF 的深度集成、增加主机指标采集等能力,实现更好的 All in One Agent。
我们还会通过一系列的优化,让 LoongCollector 更自动、更智能,更好的服务 AI 时代。
LoongCollector 将不仅是工具,更是构建智能计算基础设施的基石,大家可以在 Github 上试用、参与 LoongCollector 和 LoongSuite 的其他项目,一起携手,用可观测性点亮 AI 的未来。
