**参考:**AdaCoT: Rethinking Cross-Lingual Factual Reasoning throughAdaptive Chain-of-Thought
AdaCoT(Adaptive Chain-of-Thought,自适应思维链)是一项提升大型语言模型(LLMs)跨语言事实推理能力的新框架。这篇论文深入探讨了LLMs在多语言环境下表现不一的问题,尤其是在资源匮乏语言上的表现不佳,并提出了解决方案。 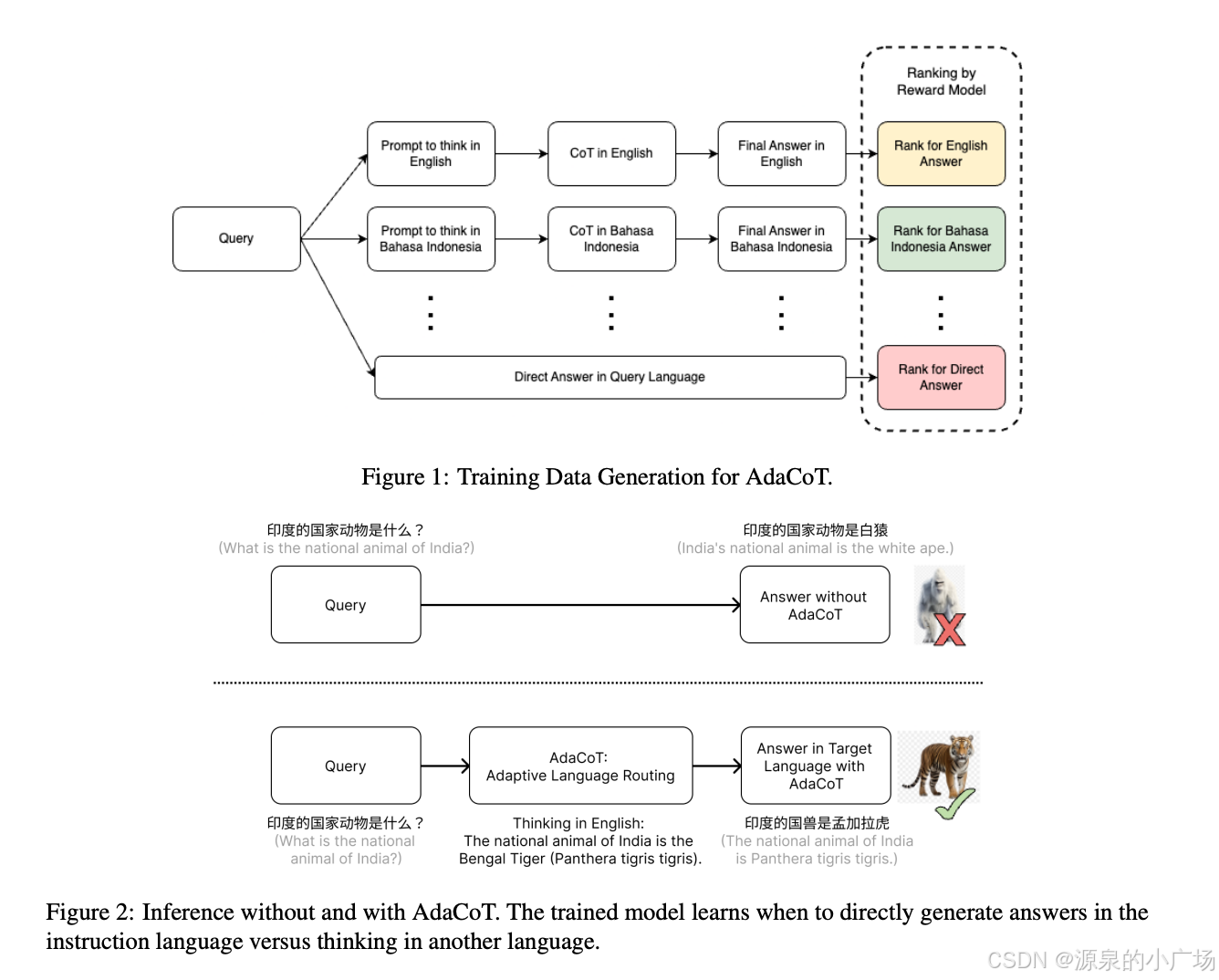
1. 论文背景与AdaCoT旨在解决的问题
大型语言模型在多语言预训练方面展现出强大的能力,但由于训练数据分布不均,其性能在不同语言间存在显著差异,尤其偏向英语等主流语言。这导致LLMs在处理跨语言事实知识时面临挑战,特别是在资源匮乏语言中。传统的翻译方法或简单的跨语言微调往往无法捕捉细微的推理过程或导致信息失真。AdaCoT正是为了解决这些问题而提出的。
2. AdaCoT核心思想
AdaCoT的核心思想是通过在生成目标语言响应之前,动态地将思维过程路由到中间的"思维语言"中,从而增强多语言事实推理能力。它认识到不同语言在特定推理任务上可能具有优势,例如,某些语言可能擅长逻辑连接,而另一些则可能在数学词汇方面表现出色。
3. 算法原理
AdaCoT框架基于两个关键原则:
-
动态路由优化(Dynamic Routing Optimization): 根据任务特性和历史表现,学习选择最有效的中间"思维语言"。这意味着模型会根据具体查询内容和知识分布,自适应地决定是直接在目标语言中生成答案,还是先在某种辅助语言中进行思考。
-
跨语言知识整合(Cross-Lingual Knowledge Integration): 综合来自多种语言视角的见解,以生成更稳健的最终输出。通过这种方式,AdaCoT能够利用不同语言的优势,同时保持文化和语言的细微差别。
4. 方法论
AdaCoT通过一种双路径机制来实现其自适应路由:
- 跨语言思维链(Cross-Lingual Chain-of-Thought, CoT): 利用辅助语言中的思维链推理步骤来提升最终输出质量。
- 直接生成(Direct Generation): 对于模型在目标语言中表现良好或使用中间语言可能降低性能(例如,诗歌创作)的情况,直接在目标语言中生成响应,绕过中间语言以提高效率。
训练阶段的算法流程:
候选响应生成(Candidate Response Generation):
给定一个目标语言(l)的输入查询(P_l),AdaCoT首先利用LLM将其翻译成多种主要语言,包括原始语言以及英语、中文和印尼语等辅助语言。
然后,采用两种策略生成多样化的候选响应:
跨语言思维链(Cross-Lingual CoT):
将原始查询P_l翻译成辅助语言P_t。
基础LLM根据P_t在辅助语言(t)中生成中间推理过程(I_t)。
教师模型(例如GPT-4o)利用原始查询P_l和中间推理I_t,在目标语言(l)中生成最终响应(R_l)。这里的目标是R_l既要保持I_t的语义含义,又要遵循P_l的原始指令。
直接生成(Direct Generation): 基础LLM直接在目标语言(l)中从P_l生成响应,不使用任何辅助语言。
候选响应排序(Candidate Response Ranking):
1.使用一个强大的LLM(例如GPT-4o)作为评估器,对不同语言路径(或直接生成)产生的多样化响应进行评分。
评分基于四个指标:事实不准确性、响应幻觉、重复性以及对指令的遵循程度,采用0-10的李克特量表。
选择得分最高的路径作为最优路径。
AdaCoT微调(AdaCoT Fine-Tuning):
利用评估得分(S_t)来指导最优推理动作的选择,最大化选择得分最高路径的可能性。
仅对得分大于等于9(高质量输出)的实例进行微调,这使得模型能够从高质量的推理策略中学习。
通过这种方式,模型学会根据输入查询动态预测正确的推理路径和最终响应。
5. 实验结果
AdaCoT在多个基准数据集(如Multilingual TruthfulQA、CrossAlpaca-Eval 2.0、Cross-MMLU和Cross-LogiQA)上进行了全面评估。实验结果表明,AdaCoT在事实推理质量和跨语言一致性方面取得了显著提升,尤其是在资源匮乏语言设置中表现出强大的性能增益。自适应路由机制也被证明对高资源语言同样有效。
优势与局限性优势:
弥合性能差距: 有效弥合了高资源语言和低资源语言之间的性能差距。
保留文化和语言细微差别: 在提升性能的同时,保持了文化和语言的细微差别。
无需额外预训练: 不需要对大型多语言语料库进行额外的预训练,提高了计算效率。
利用语言优势: 能够利用不同语言在特定推理任务上的优势。
局限性:
思维语言数量有限: 目前框架依赖于有限的思维语言集合,这限制了其在更广泛语言环境中的泛化能力。
计算效率: 动态路由机制虽然创新,但可能导致推理延迟增加,带来计算效率问题。
高质量训练数据需求: AdaCoT需要多样化、高质量的训练指令,这在某些领域或资源匮乏语言中可能难以获取。