摘要: X2Doris 是 SelectDB 推出的可视化数据迁移工具,支持从 Hive、Kudu、Doris/StarRocks 迁移至 Apache Doris 或 SelectDB Cloud。部署需准备 Spark、MySQL 元数据库,配置 Hadoop/YARN、Kerberos 等环境。通过平台可自动建表、字段映射、分区转换、设置任务参数并启动作业,支持多数据源、失败重试和进度跟踪,简化大数据迁移流程。SelectDB官网:面向实时分析的现代化分析型数据仓库-OLAP实时数仓-SelectDB
1.安装与部署
1.1项目介绍
X2Doris 是 SelectDB 开发的,专门用于将各种离线数据迁移到 Apache Doris 中的核心工具,该工具集 自动建 Doris 表 和 数据迁移 为一体,目前支持了 Apache Doris/Hive/Kudu、StarRocks 数据库往 Doris 或 SelectDB Cloud 迁移的工作,整个过程可视化的平台操作,非常简单易用,减轻数据同步到 Doris 或 SelectDB Cloud 中的门槛。
1.2 安装部署
1.2.1. 安装要求
准备部署 X2Doris 的机器必须确保有效的网络策略: 要迁移的源 和 目标写出的 Doris/SelectDB Cloud,保证网络可以连接。
1.2.2.选择安装包
X2Doris 底层采用 Spark 实现,推荐部署到有 Hadoop,Yarn 的大数据环境中,这样可以充分利用大数据的集群能力,能大大提高数据迁移的效率和速度。如果没有大数据环境也可以的,单机部署即可 (选择自带 Spark 的版本就可以了。如果没有 Hadoop 环境就不要安装伪分布式的 Hadoop 集群环境了)。
2.1 如果有 Spark 环境
下载地址: SelectDB Tools下载-SelectDB
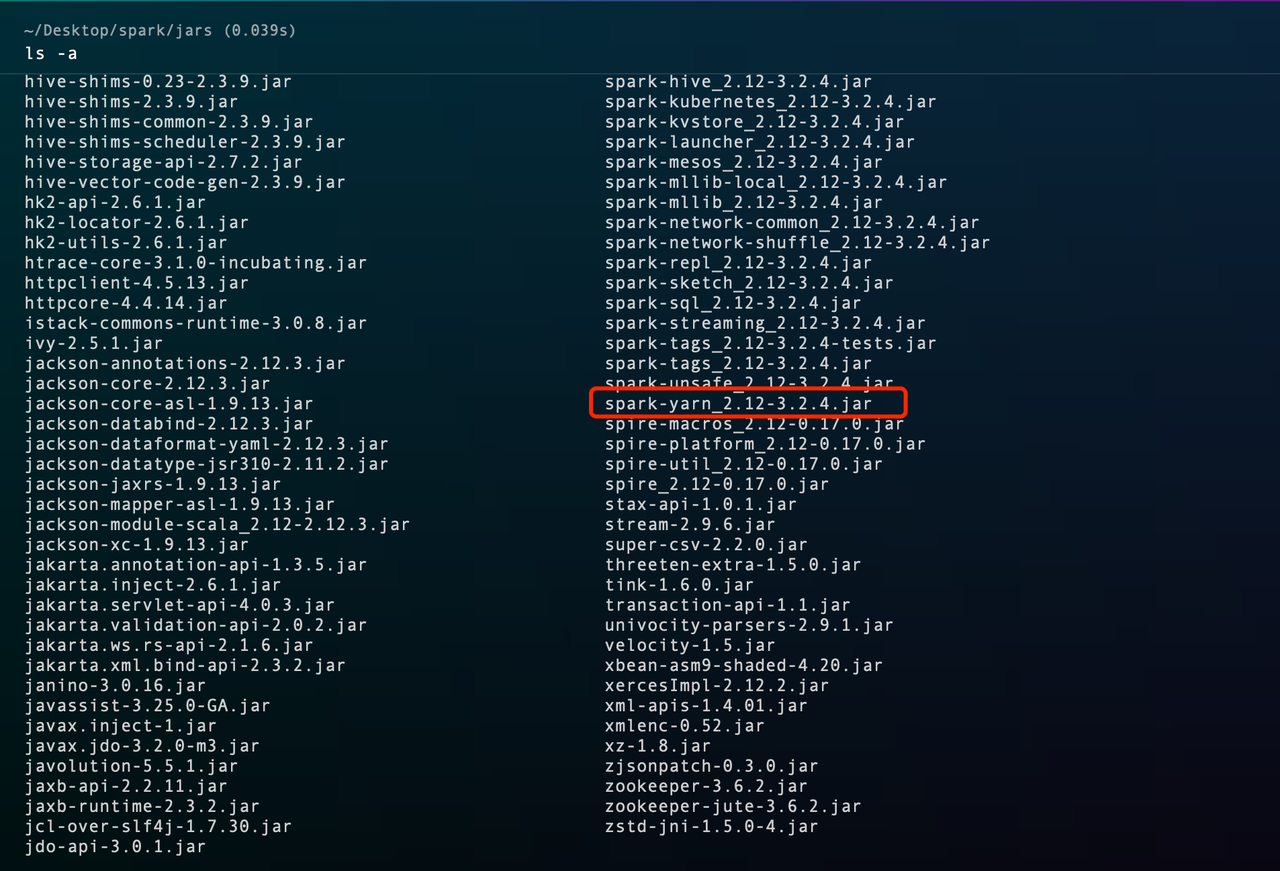
进入 Spark 安装目录的 jars 目录下,查看 Spark 依赖包对应的 Scala 版本,如下:可以看到 spark-yarn_2.12 -3.2.4.jar, 这里的2.12 即为 Scala 的 版本。
然后下载与 Scala 版本对应的 X2Doris 安装包即可,X2Doris 安装包的文件名有 Scala 的版本,如:selectdb-x2Doris_2.12-1.0.0-bin.tar.gz 就是 Scala 2.12 对应的版本
2.2 如果没有 Spark 环境
直接选择 Scala 2.12 对应的 X2Doris 安装包即可。
1.2.3. 解包安装包
bash
tar -xzvf selectdb-x2doris_2.12-1.0.0-bin.tar.gz1.2.4. 初始化元数据
4.1 将系统的数据库类型改成 mysql
进入到 conf 下,修改 application.yml 将 spring.profiles.active 改成 mysql,注意 默认的 h2, 是内存数据库,已经做了持久化,重启数据仍然存在,但是推荐使用mysql
4.2 修改 conf/application-mysql.yml 文件,指定 MySQL 的连接信息
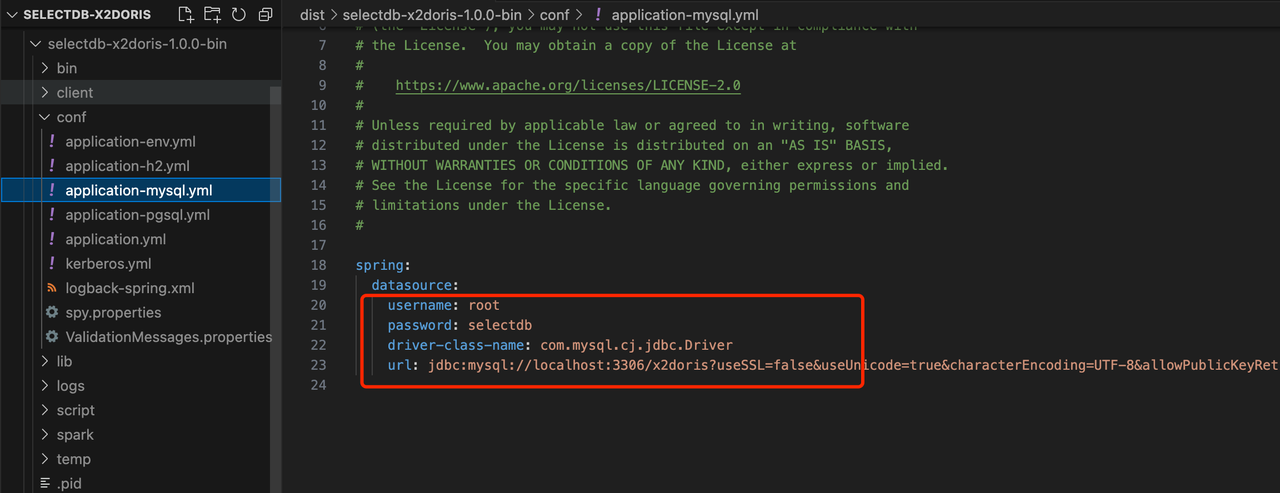
4.3 执行脚本
进入到 script 下:有两个目录,分别是 schema 和 data
- 先执行
schema下的mysql-schema.sql完成表结构的初始化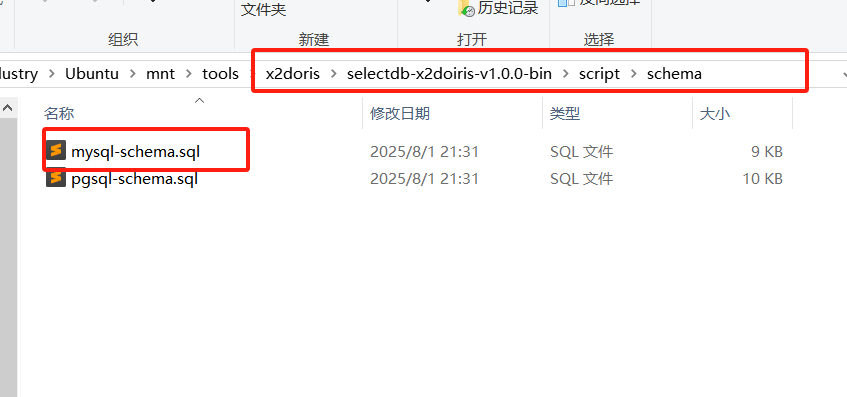
- 再执行
data下的mysql-data.sql完成元数据初始化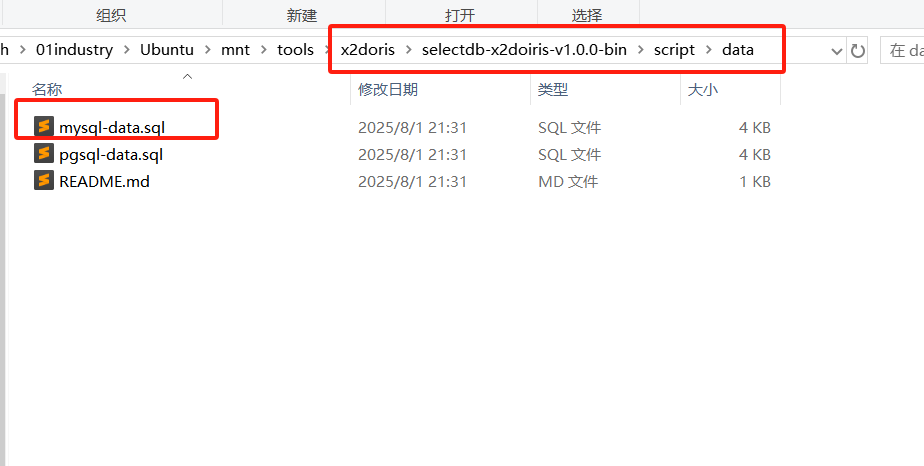
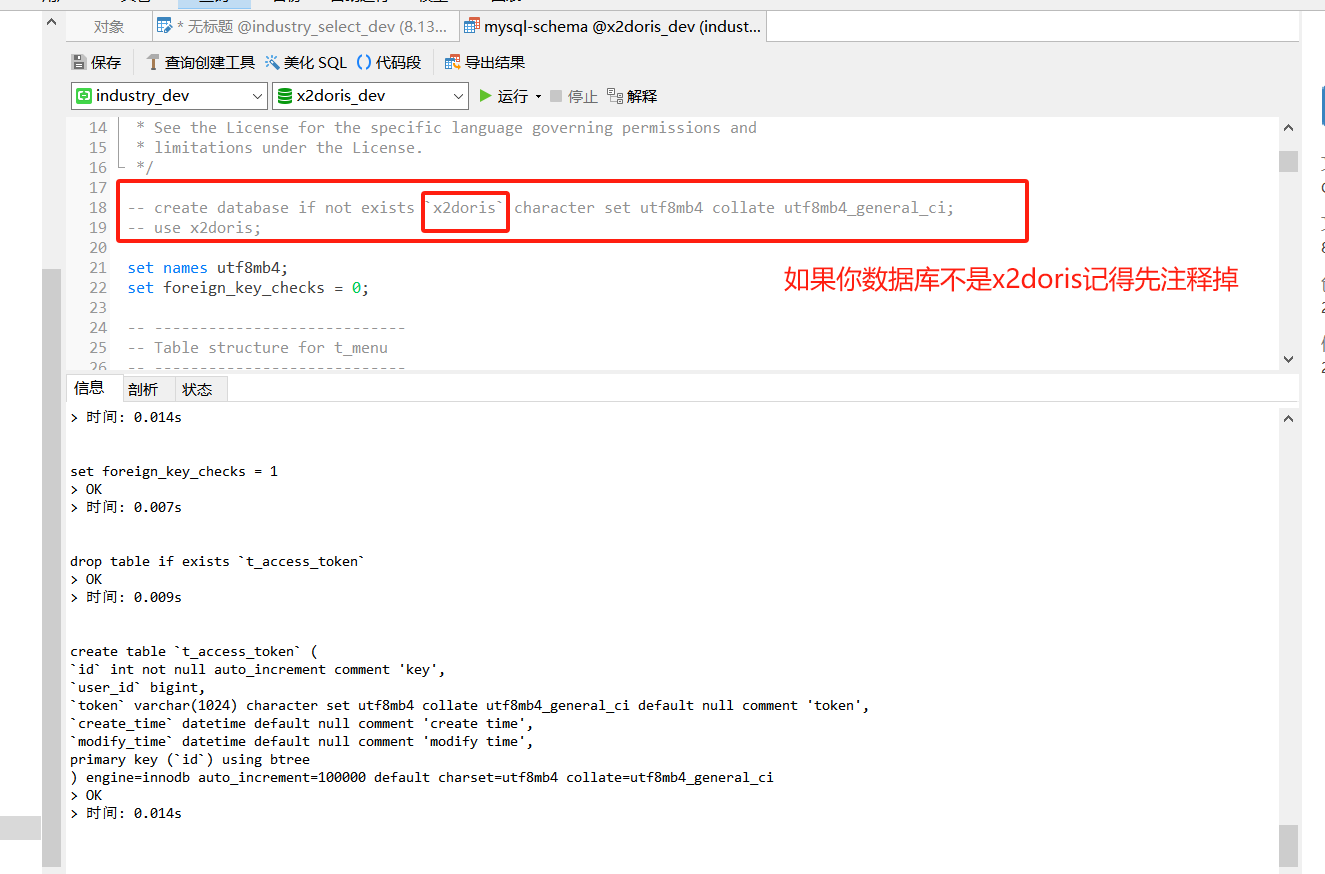
PostgreSQL 操作与 MySQL 类似,此处不再赘述。
⚠️注意:默认使用 h2 数据库,重启后,数据会被清空!
1.2.5. 认证相关配置
5.1. Kerberos
如果你的 Hadoop 集群开启了 Kerberos 认证(未开启 Kerberos 认证则可以跳过此步骤),则需要配置下 Kerberos 的信息,编辑 conf/kerberos.yml :
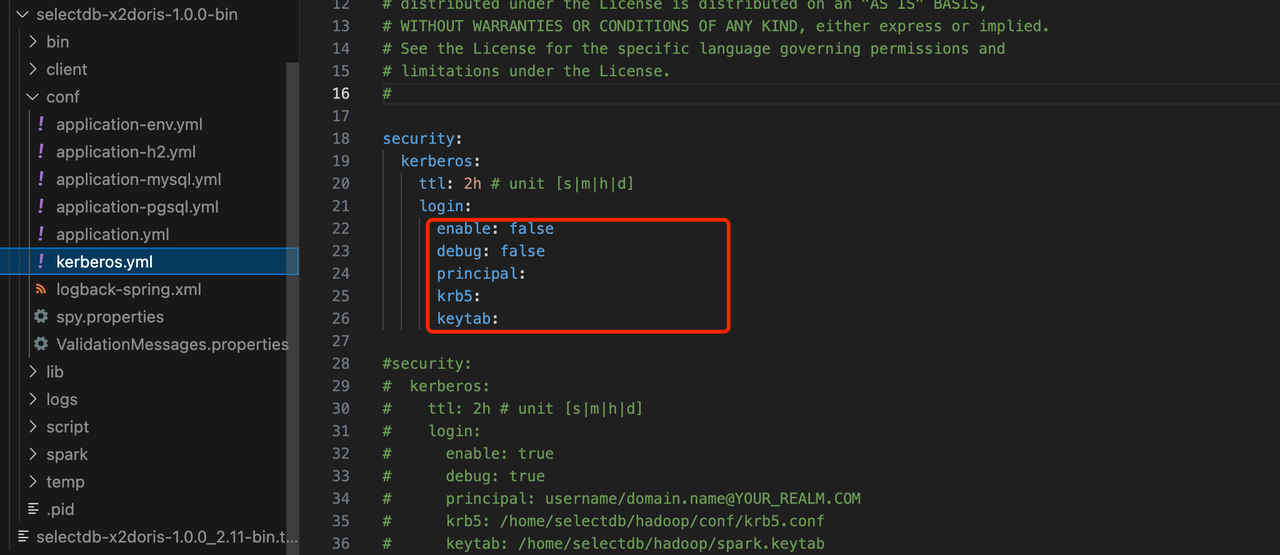
enable: true #开启 Kerberos 开关
principal 和 krb5, keytab 填写实际的路径即可
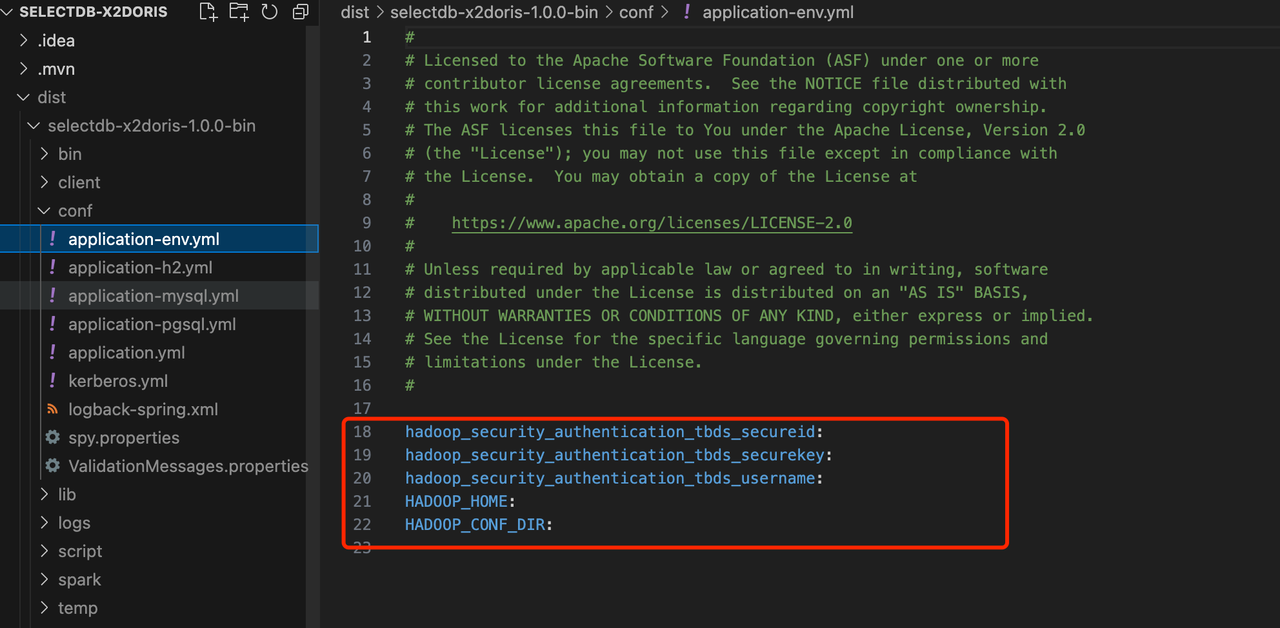
5.2. tbds
tbds 是腾讯云大数据集群, 非 tbds 则跳过即可,编辑 conf/application-env.yml 填写如下信息即可:
1.3启动使用
1.3.1启动
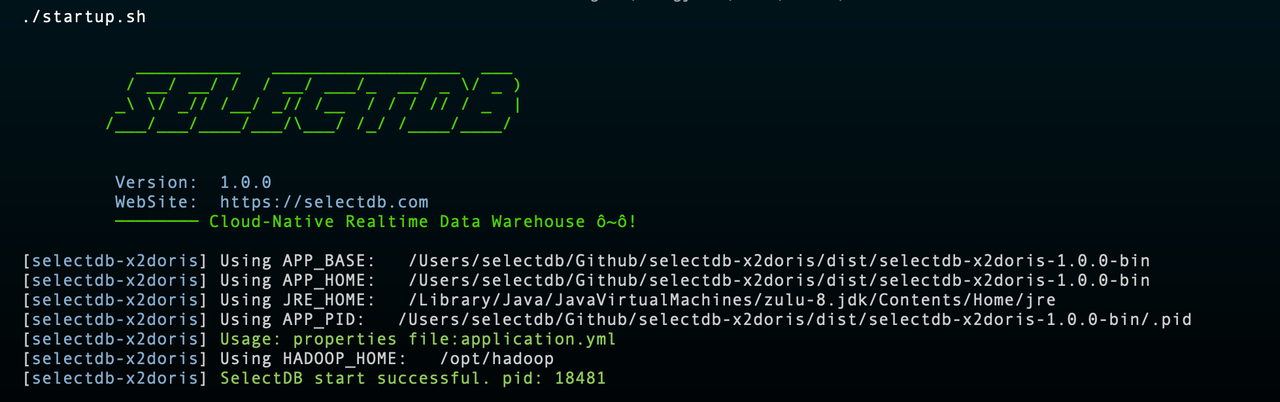
前置工作都准备就绪了,进入到 bin 目录下,执行 startup.sh
1.3.2 登录平台
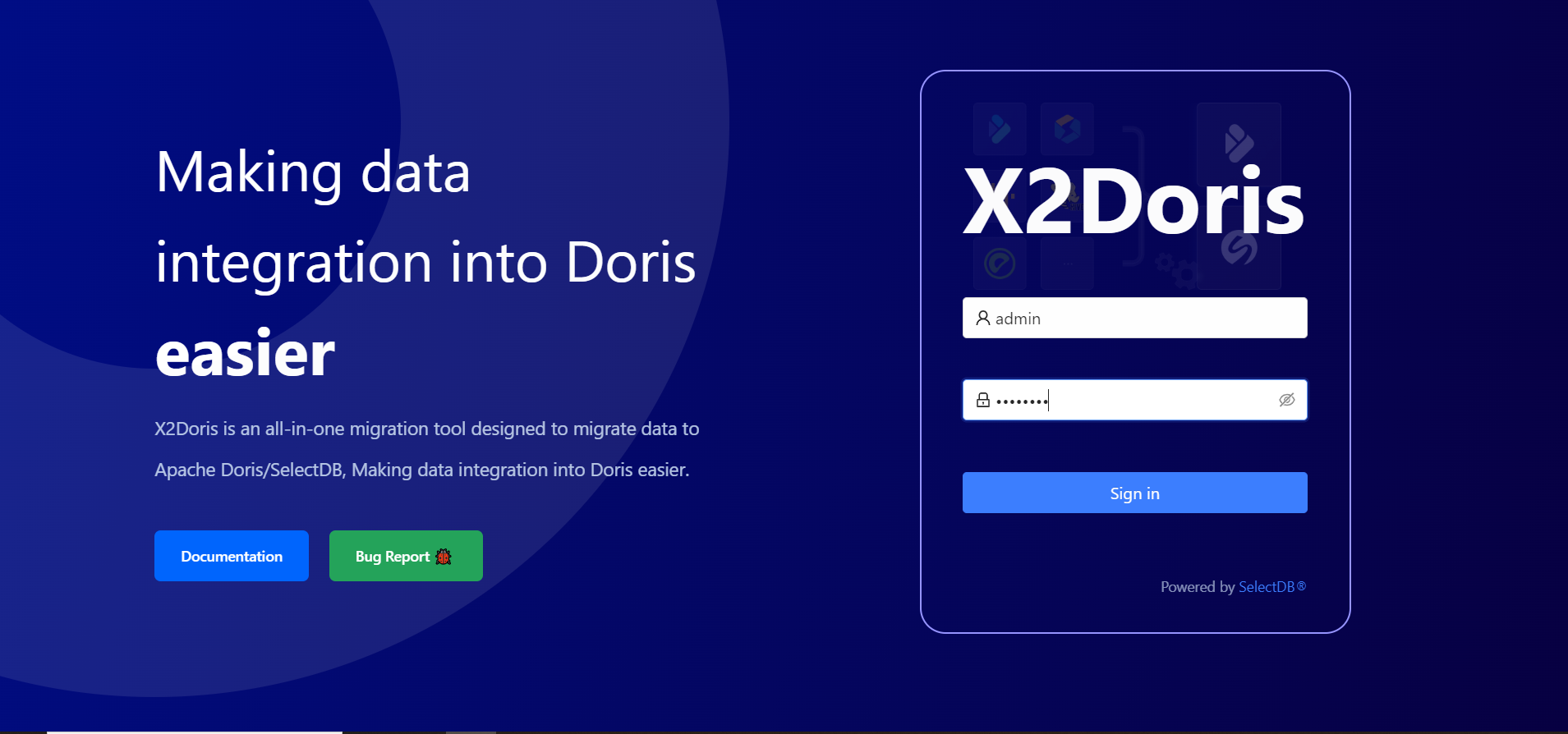
默认访问地址: http://$host:9091 ,可以在 application.yml 里面进行修改。 默认用户名密码: admin/admin,登陆后可在主界面操作修改。
2.使用手册
2.1修改默认用户密码
用户登陆成功后,可以点击主界面右上角的"用户名"修改密码。
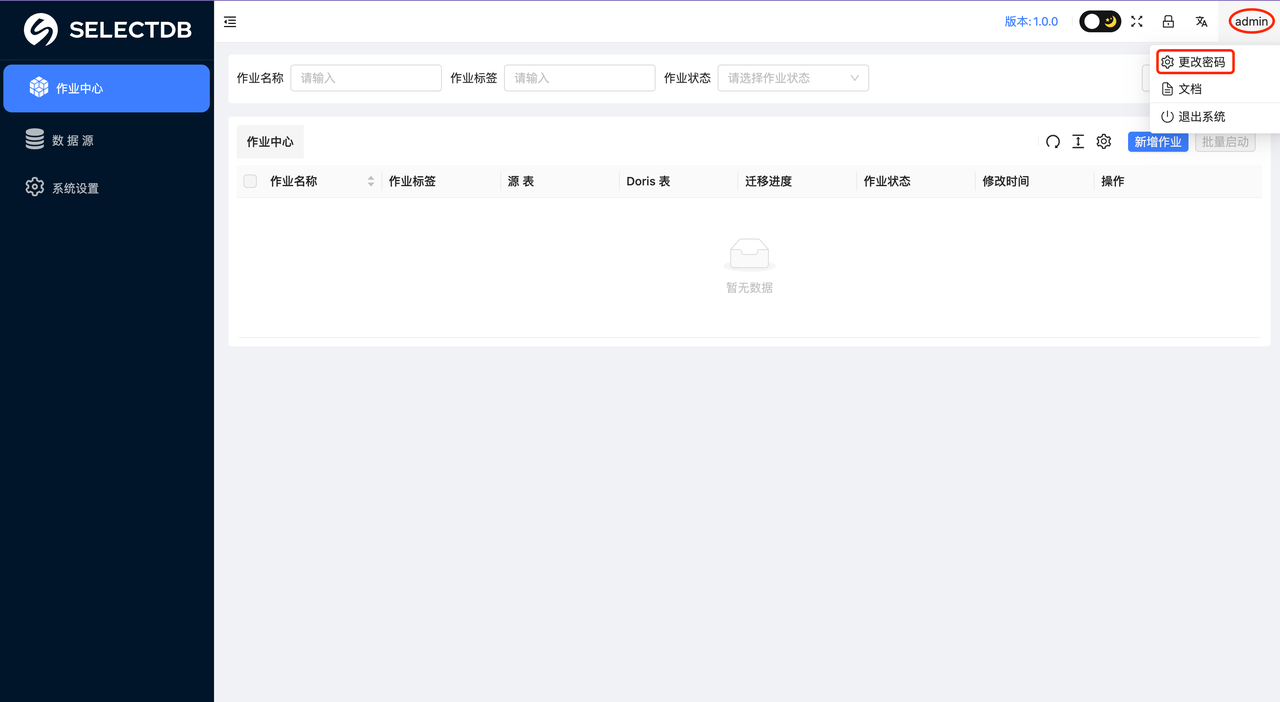
点击修改密码按钮,弹出如下界面,按照界面提示填写相关信息即可修改密码
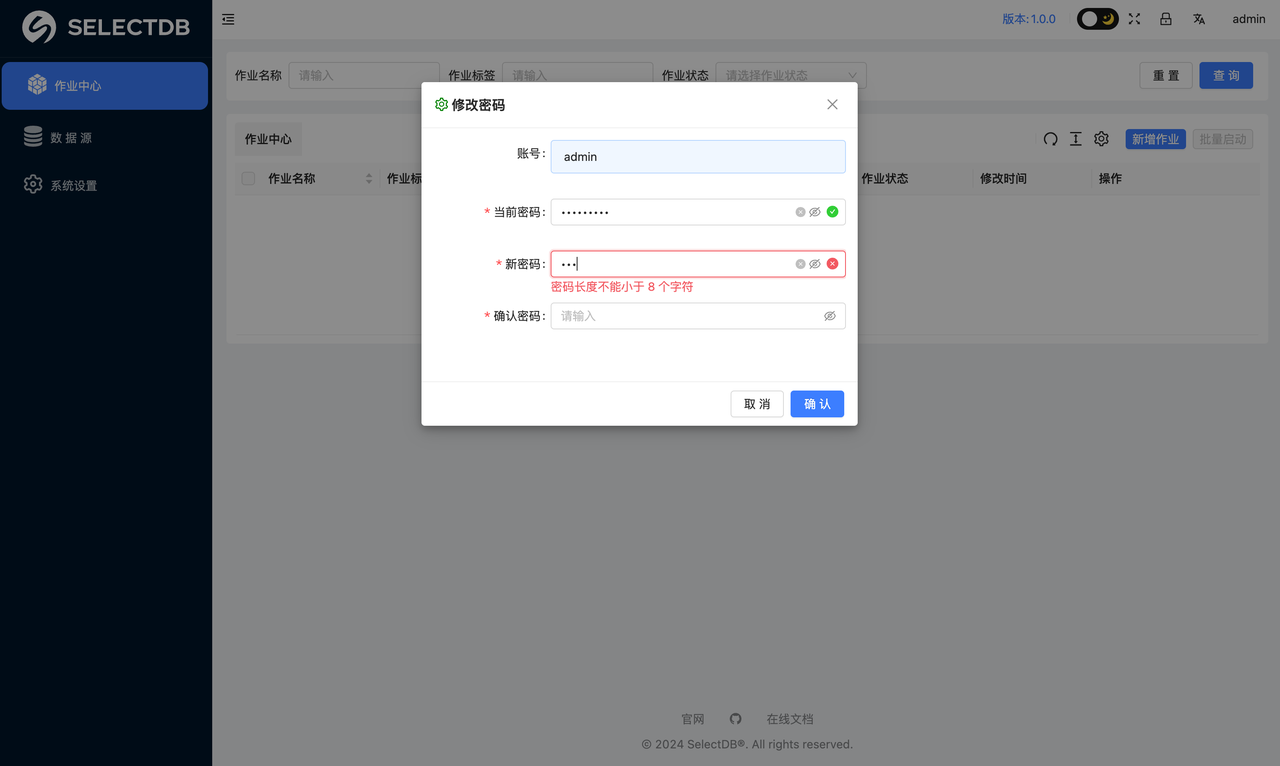
修改密码后,会提示修改密码成功弹窗,可以选择立即退出或者取消。
2.2 系统设置
在正式使用平台之前,要做的第一件事就是进入 设置中心 设置系统参数,该部分参数都为必须要设置的参数,具体如下:
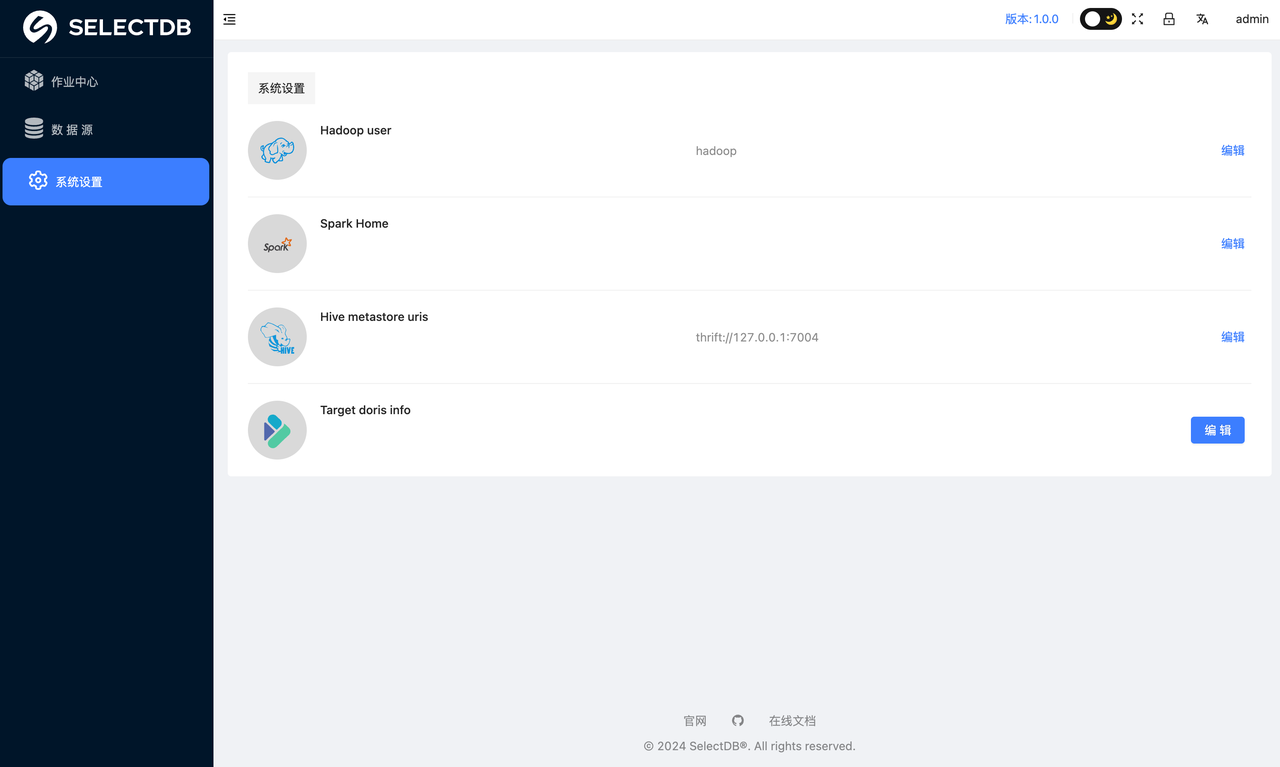
- Hadoop user: 指定提交作业到 yarn 上的用户 (无 Hadoop 环境跳过)
- Spark Home: 如果你有大数据集群,且安装了 Spark,则指定下你集群的 Spark Home
- Hive metastore uris: 如果 Hive 数据迁移至 Doris,需要知道 hvie 的 metastore uri (非 hive 数据源跳过)
- Target doris info: 迁移数据的目标 Doris 或者 SelectDB Cloud 连接信息设置。
其中 Target doris info 点击编辑 按钮,会有弹窗,直接输入相关信息即可,如下:
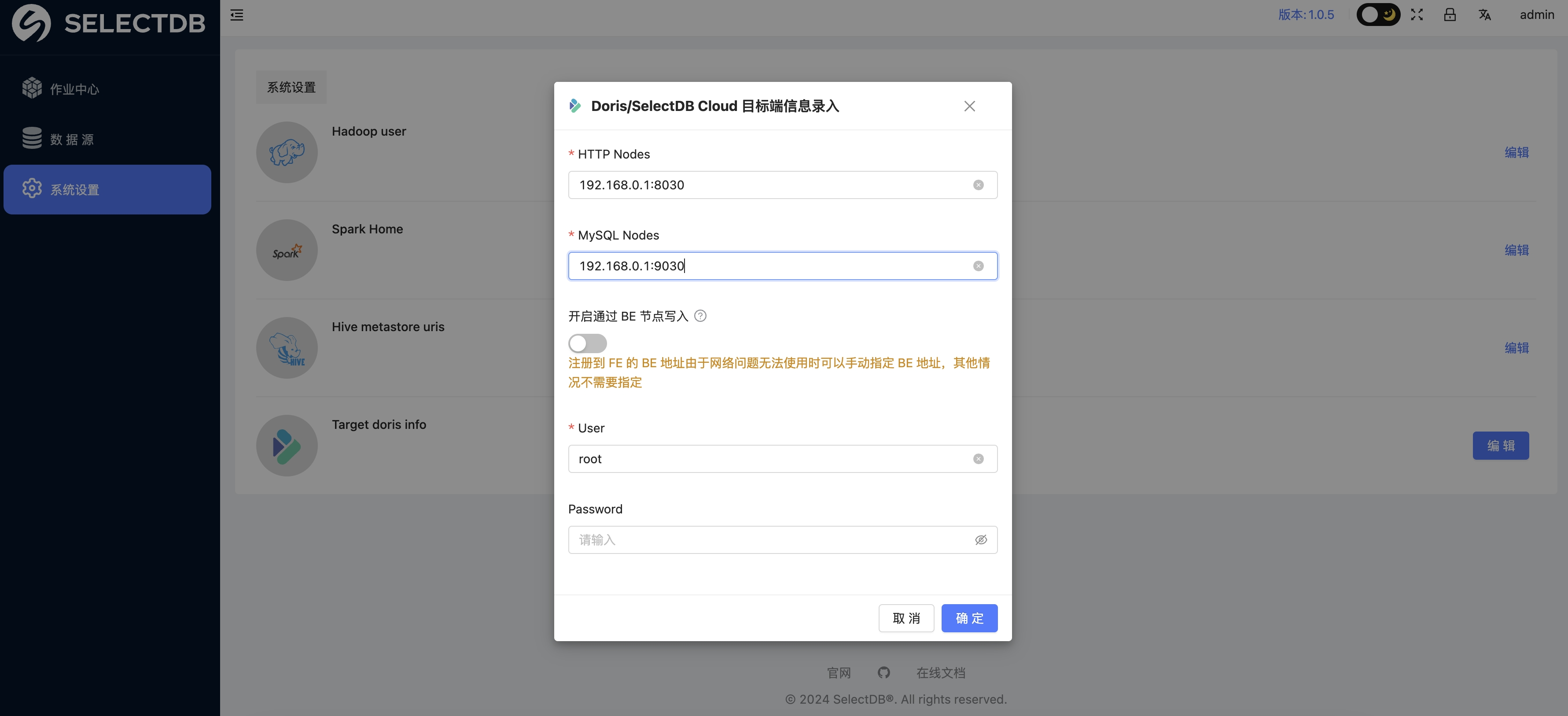
HTTP Nodes:
HTTP 连接的 host 和 port,多个用","连接,如:192.168.0.1:8030,192.168.0.1:8030
MySQL Nodes:
MySQL JDBC 连接的 host 和 port , 多个用"," 连接,如:192.168.0.1:9030,192.168.0.1:9030
开启通过 BE 节点写入:
可以不用设置,只有当注册到 FE 的 BE 地址由于网络问题无法使用时可以手动指定 BE 地址,才需要指定
⚠️
注意:如果是目标是 SelectDB Cloud 则去 SelectDB Cloud 连接信息里检查连接的 host 和 port
2.3 Hive to Doris
1. 前置条件
- 部署 X2Doris 的机器必须可以连接 Hadoop 集群,是 Hadoop 的一个节点,或至少有 Hadoop gateway 环境(可以在该机器上执行 Hadoop,Hive 命令,能正常连接访问 Hadoop,Hive 集群
- 部署 X2Doris 的机器必须配置了 Hadoop 环境变量,必须配置
HADOOP_HOME,HADOOP_CONF_DIR,HIVE_CONF_DIR,例如:
bash
export HADOOP_HOME=/opt/hadoop #hadoop 安装目录export HADOOP_CONF_DIR=/etc/hadoop/confexport HIVE_HOME=$HADOOP_HOME/../hiveexport HIVE_CONF_DIR=$HADOOP_HOME/confexport HBASE_HOME=$HADOOP_HOME/../hbaseexport HADOOP_HDFS_HOME=$HADOOP_HOME/../hadoop-hdfsexport HADOOP_MAPRED_HOME=$HADOOP_HOME/../hadoop-mapreduceexport HADOOP_YARN_HOME=$HADOOP_HOME/../hadoop-yarn⚠️
注意:在 HADOOP_CONF_DIR 或 HIVE_CONF_DIR 下 必须要有hive-site.xml
2. 配置元数据读取
修改配置文件 conf/application-hive.yaml来设置获取 Hive 元数据方式,目前支持三种:JDBC,阿里云 DLF,Metastore
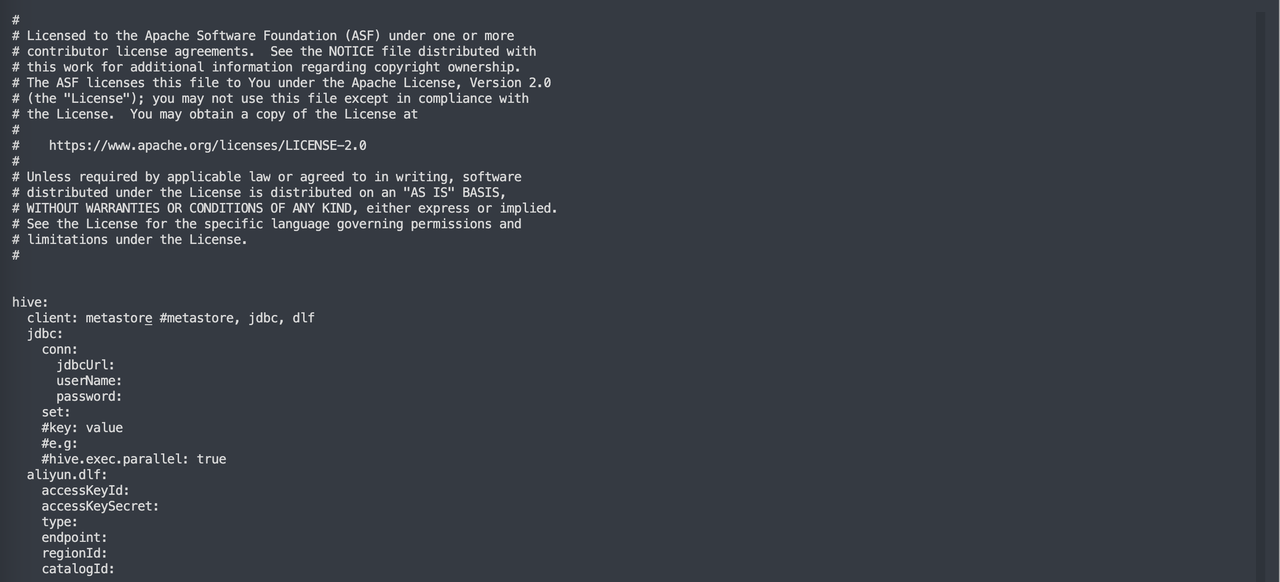
1. Metastore
这是默认推荐的读取 Hive 元数据的方式,如果 Hive 是标准的 Apache Hive,则推荐这种方式,直接将 client 设置为 metastore 即可
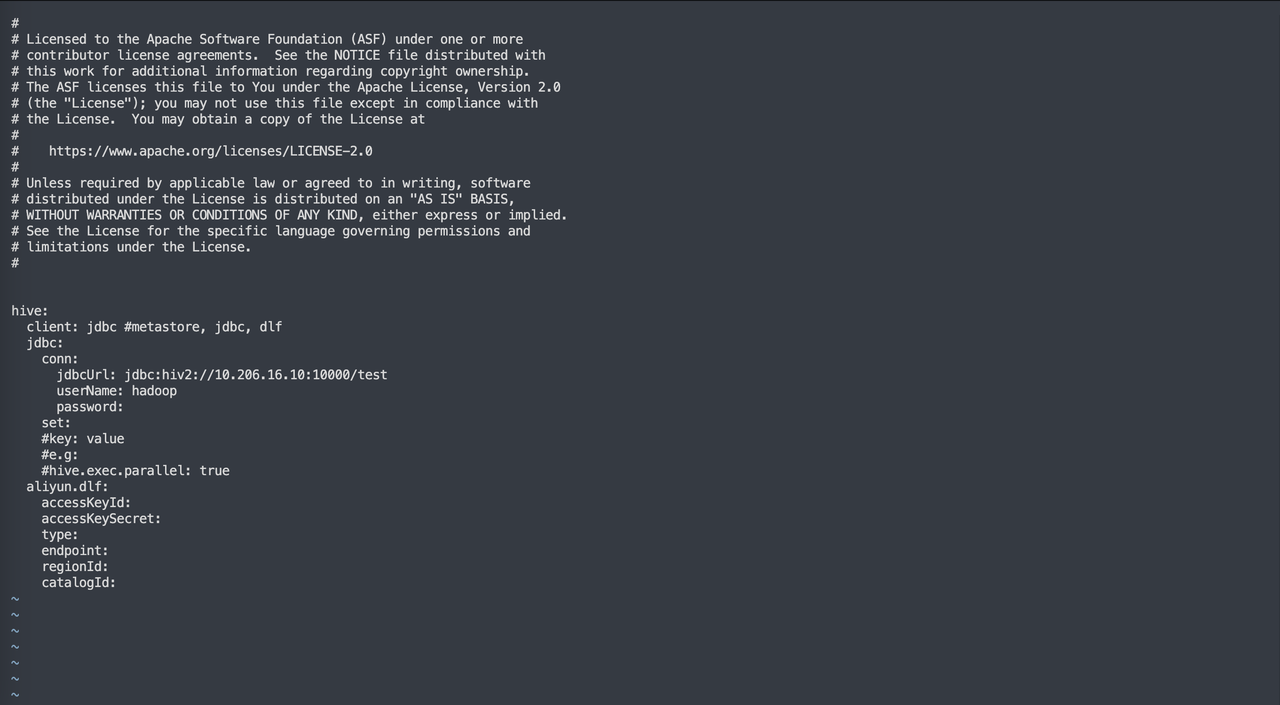
2. JDBC 方式
如果因为诸如权限等问题,不能使用metastore 的方式,则可以尝试使用 JDBC 的方式,将 client 设置为 JDBC,设置对应的 jdbcUrl 和用户名、密码,同时可以通过在 set 后面添加配置来设置链接参数
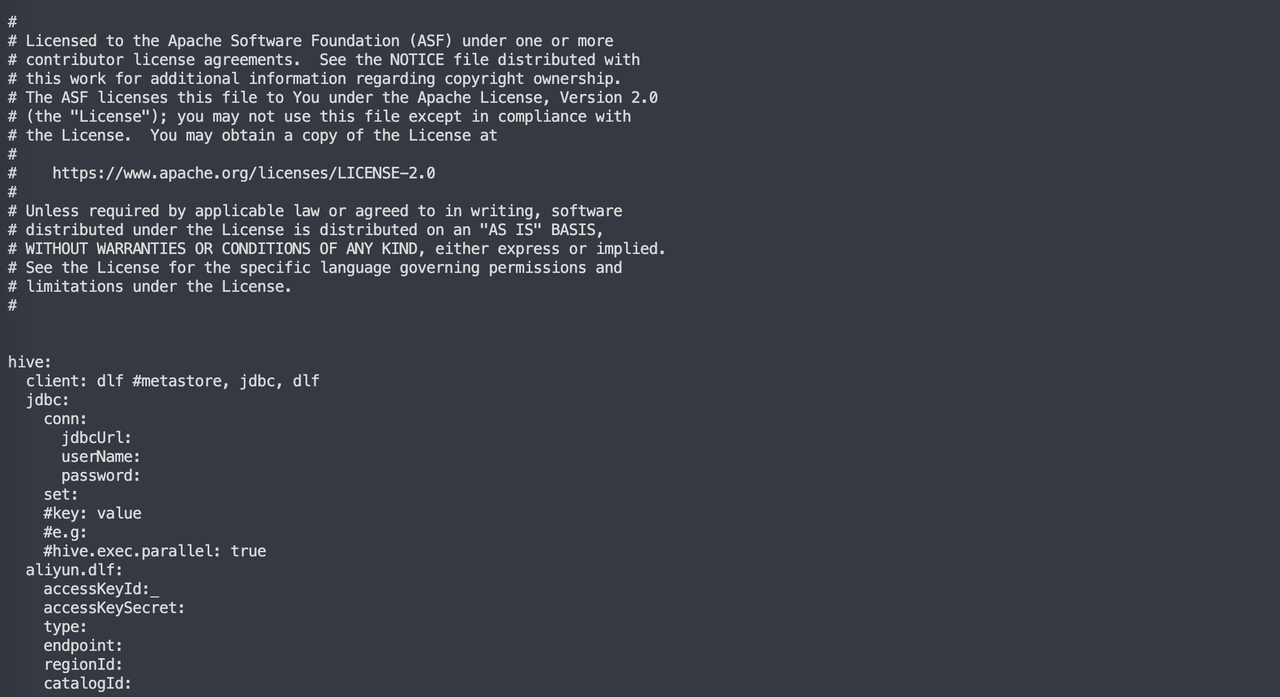
3. 阿里云 DLF
如果 Hive 是阿里云的 Hive,则需要设置 client 为 dlf,填写阿里云 DLF 服务有效的 ak、sk、认证类型、endpoint、regionId 以及 catalogId
在 System Settings 中配置 Metastore 的 thrift 链接地址
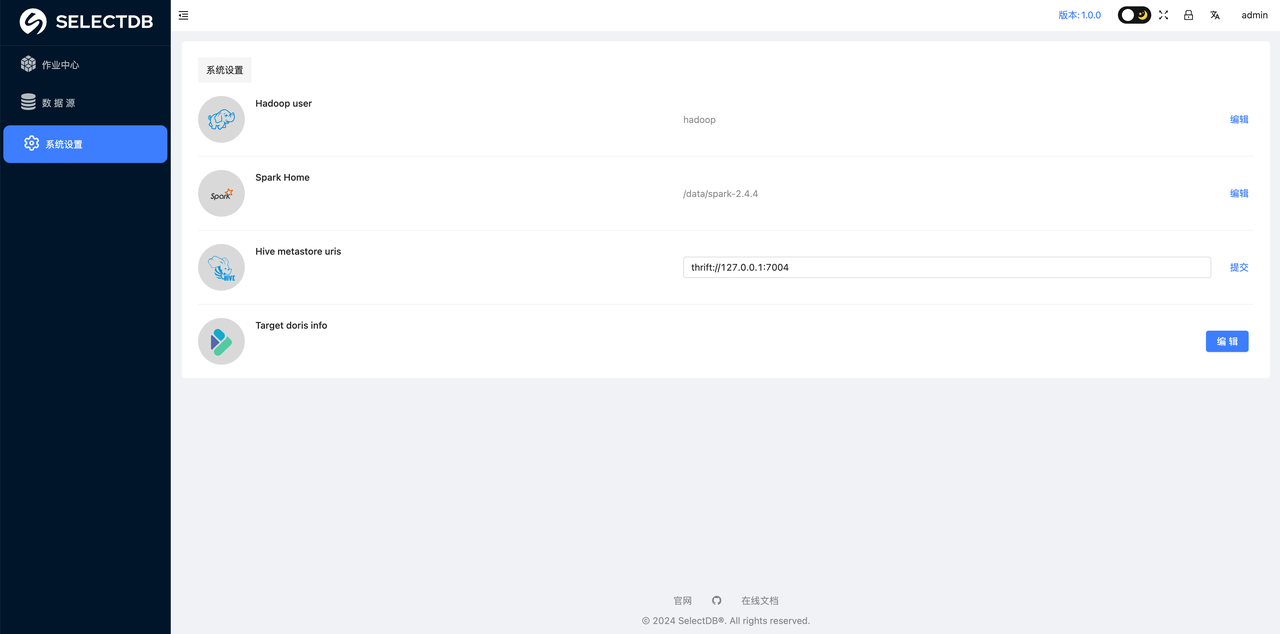
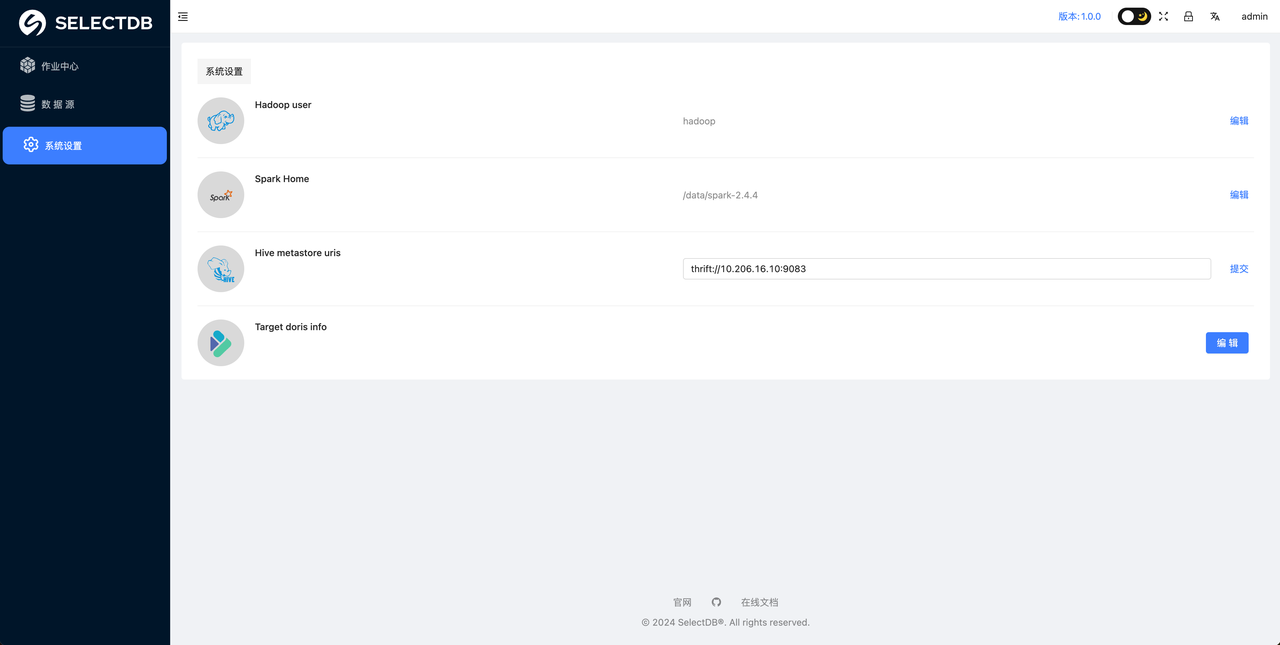
配置好后点击 提交 提交配置
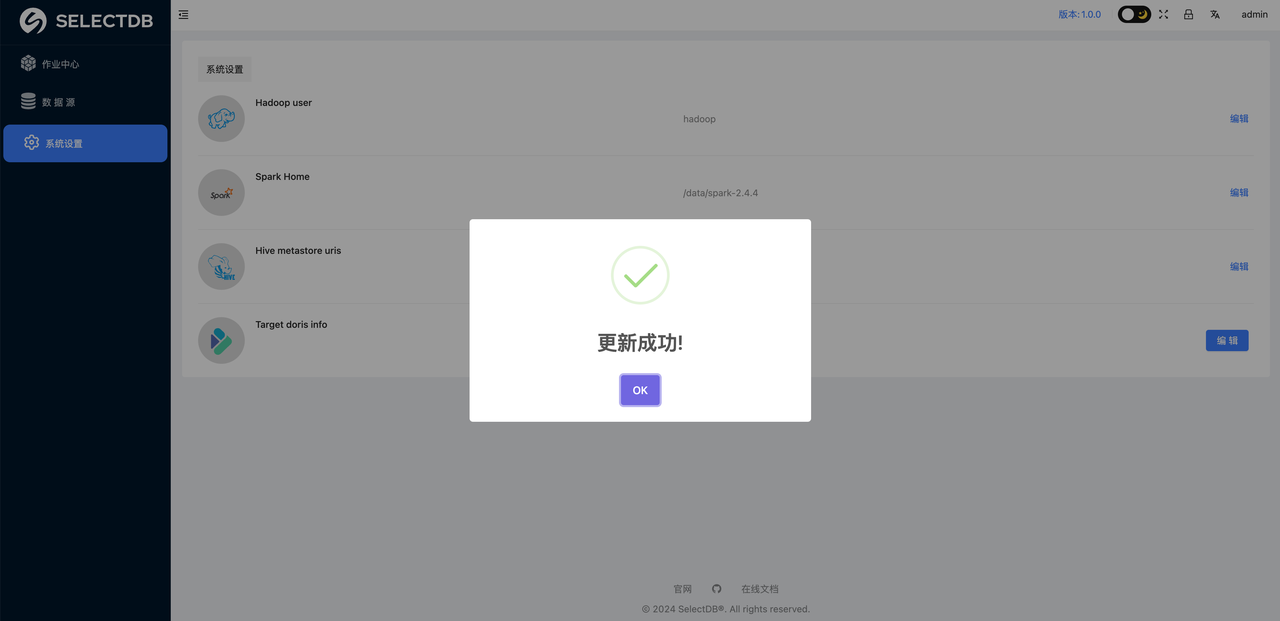
提示更新成功表示可以正常连接
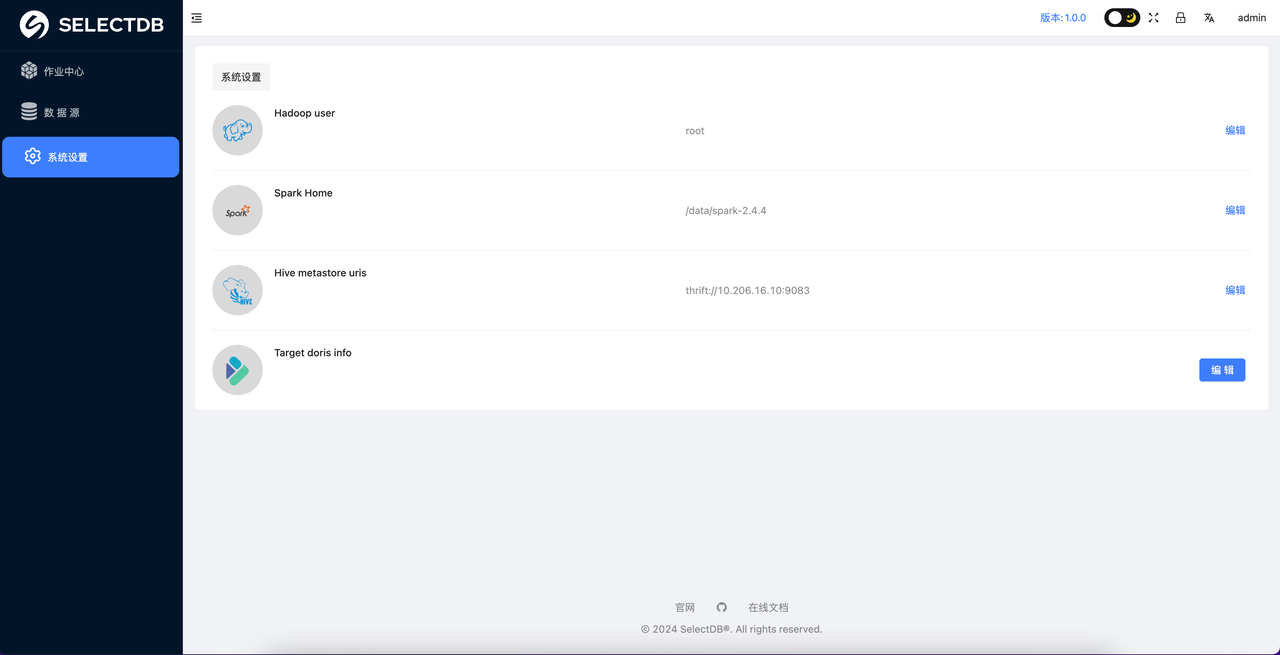
3. 设置系统信息
Hive 需要设置以下信息,该部分参数都为必须要设置的参数,具体如下:
Hadoop user: 该作业会访问 Hive 数据,该 Hadoop user 即为操作 Hive 表的 Hadoop 用户 (日常 Hive 作业的操作用户即可)Spark Home: 指定部署机安装的 Spark 的路径Hive metastore Uri: Hive 的 metastore uri,可以去 $HADOOP_CONF_DIR 下查找 hive-site.xml 的配置获取目标 Doris(SelectDB Cloud): 目标要写出数据的 Doris (SelectDB Cloud) 的信息
4. 创建同步作业
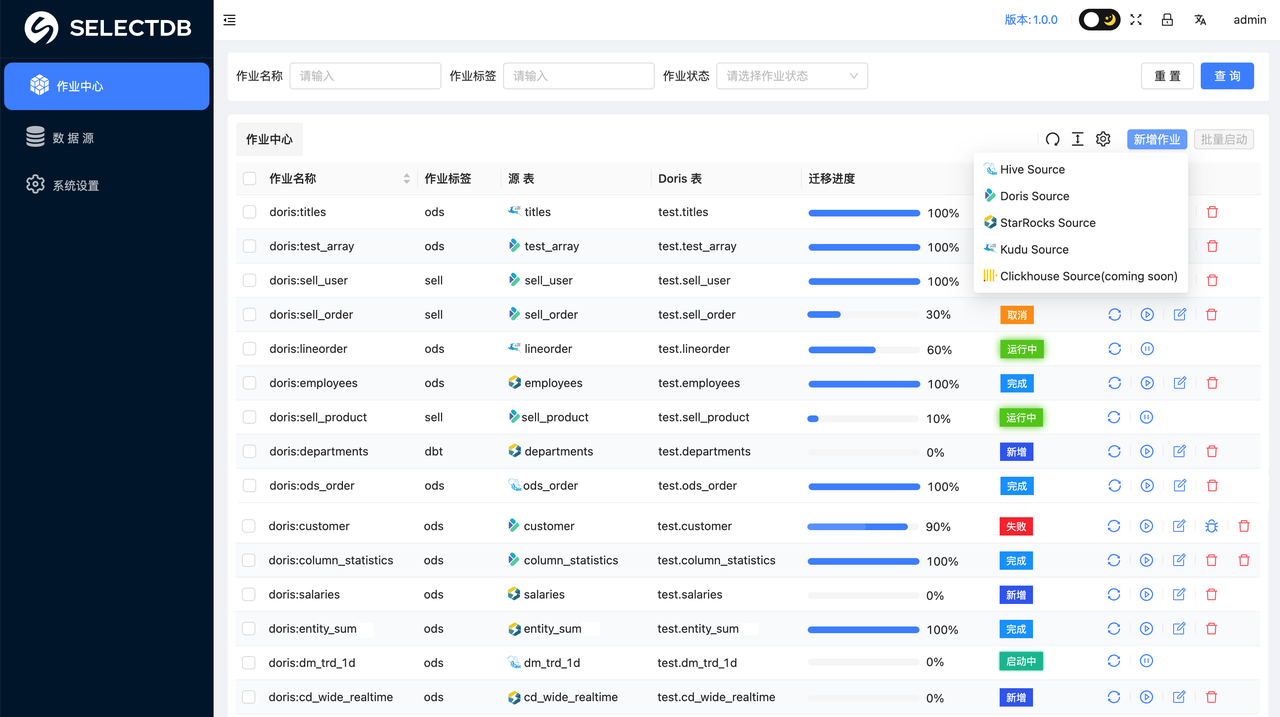
系统设置 完成之后,就可以进入到 作业中心 了,这里可以点击 添加 来创建一个作业:
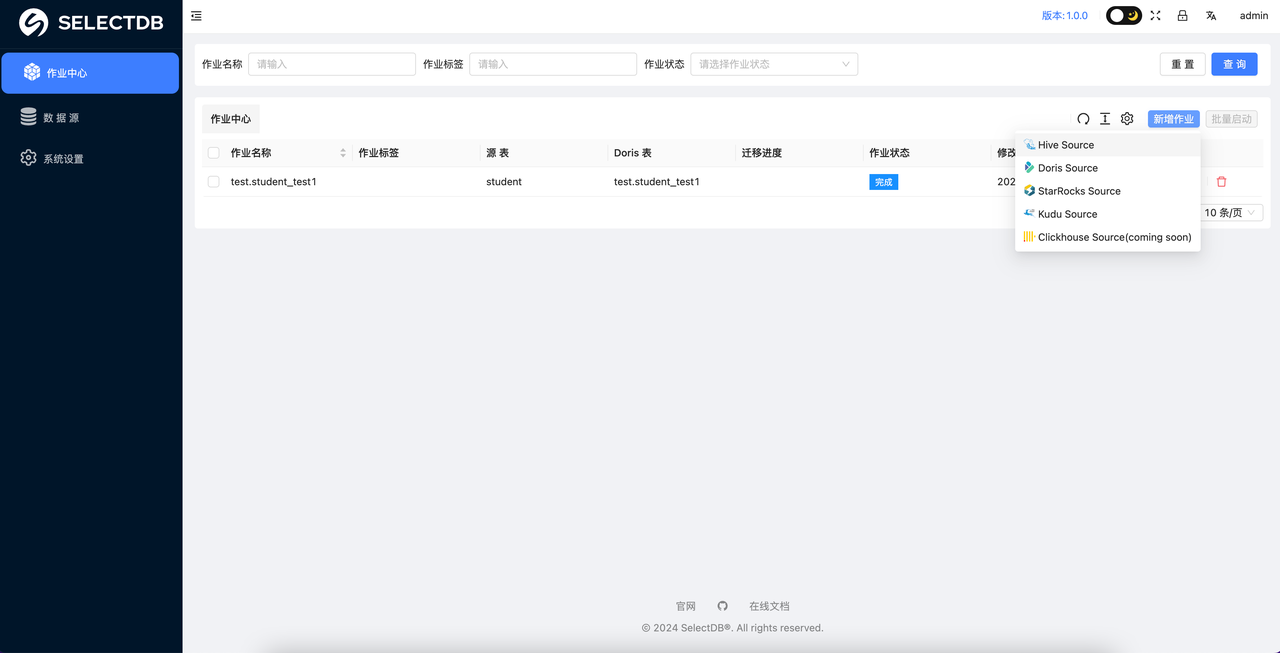
在添加的时候会自动检测 Hive 环境的连接情况,如果 Hive 连接失败,会告警:
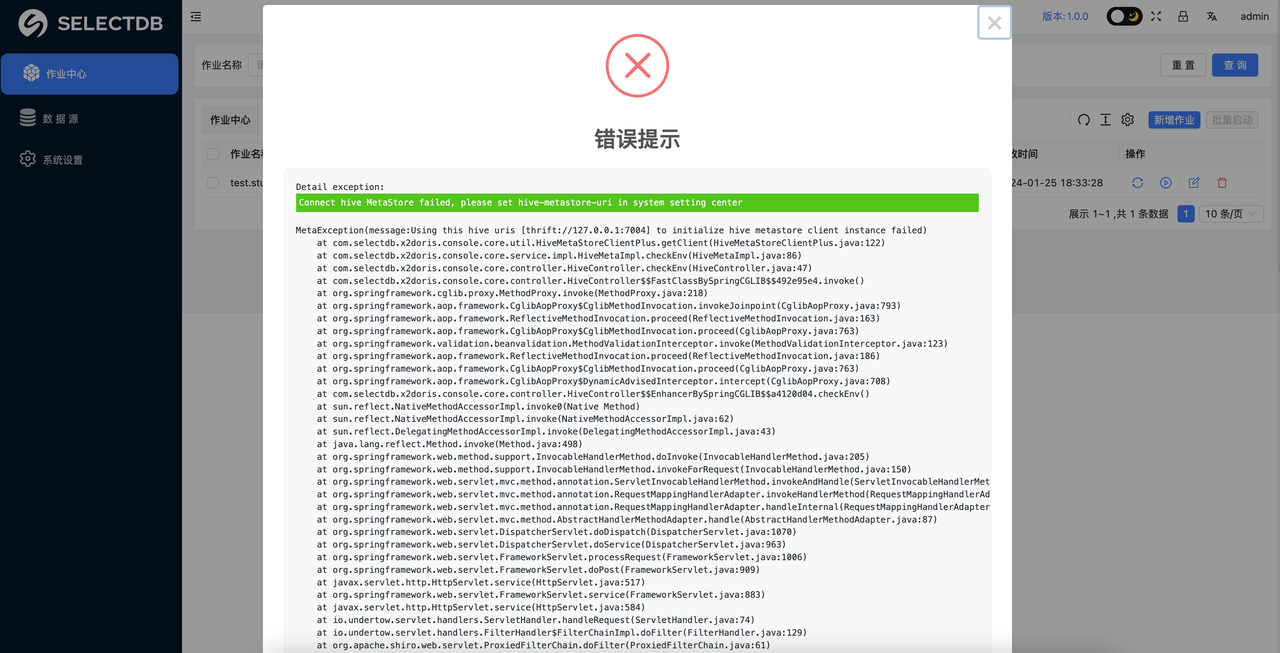
那么此时就需要检查: "系统设置" 里的 Hive metastore uris 和当前部署机的通讯是否正常了。这一步必须要确保通过才可以进行后续的迁移工作,如果连接正常就可以直接进行新增作业。
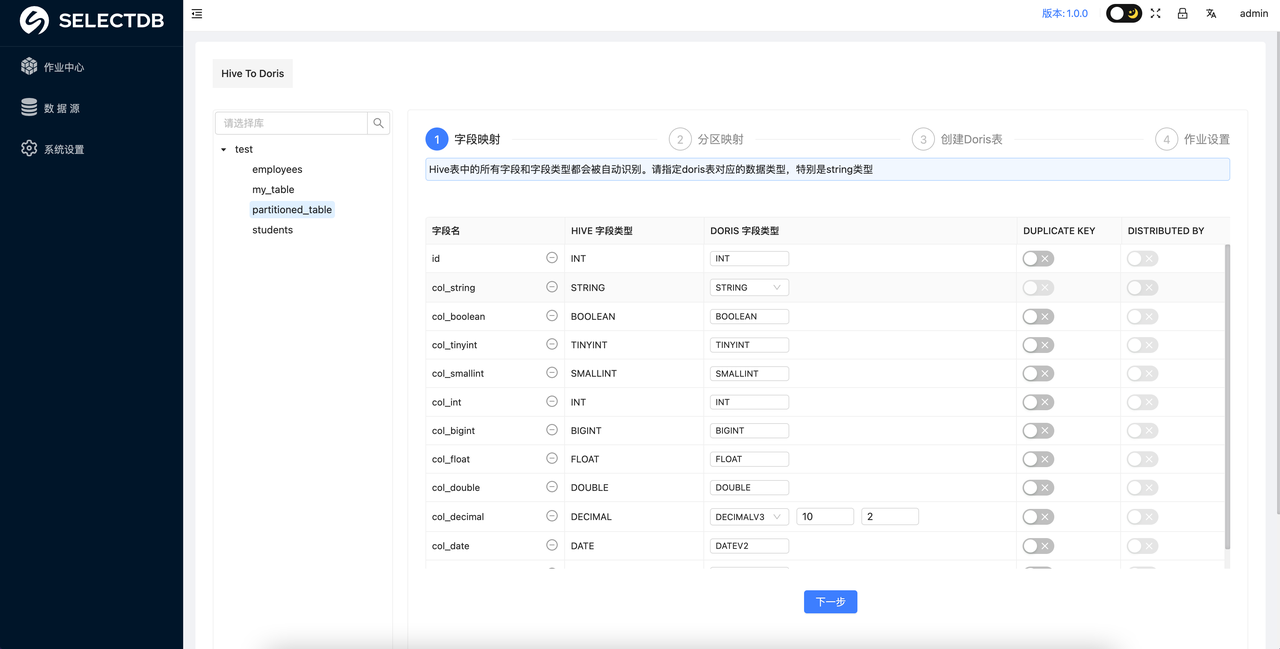
5. 字段类型映射
如果和 Hive 连接正常,就会自动把 Hive 数仓中所有的库和表都罗列出来。此时就可以点击左侧的树形目录,选择目标表进行操作,选中一个表之后,右侧会自动罗列出该表与 Doris 的字段映射关系,可以很轻松的映射目标 Doris 表的字段类型。根据提示进行操作即可完成字段的映射。DUPLICATE KEY 和 DISTRIBUTED KEY 是 Doris Duplicate 模型中必须要指定的参数,按需进行指定即可。
⚠️
注意:已经自动识别了 Hive 表中的分区字段,并且自动强制将分区自动设置为DUPLICATE KEY 字段
⚠️
注意:
- 自动生成的 Doris DDL 建表语句为 Duplicate 模型,可以根据实际情况手动修改
STRING类型不能设置为DUPLICATE KEY,需要将STRING类型改成VARCHAR类型即可
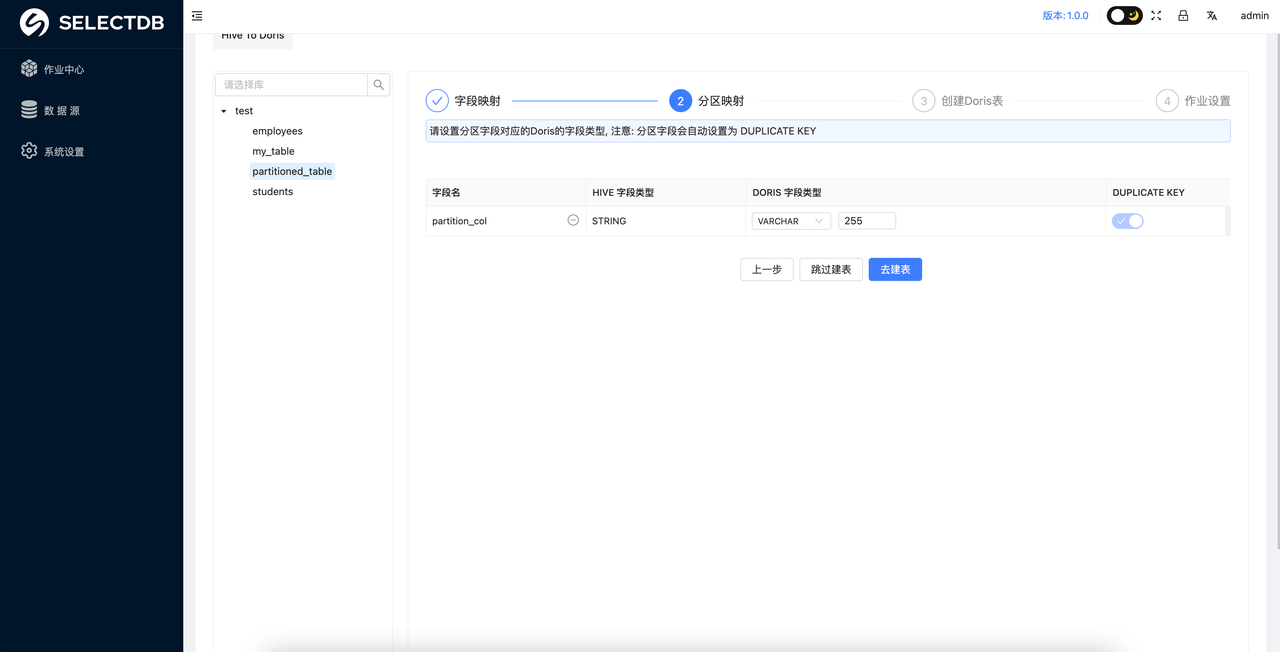
6. 分区映射
如果 Hive 原表中的分区字段类型是 STRING ,则可以根据数据实际类型判断是否需要将对应的 Doris 表的字段类型转成时间类型。如果转成时间类型的话,则需要设置分区的区间。
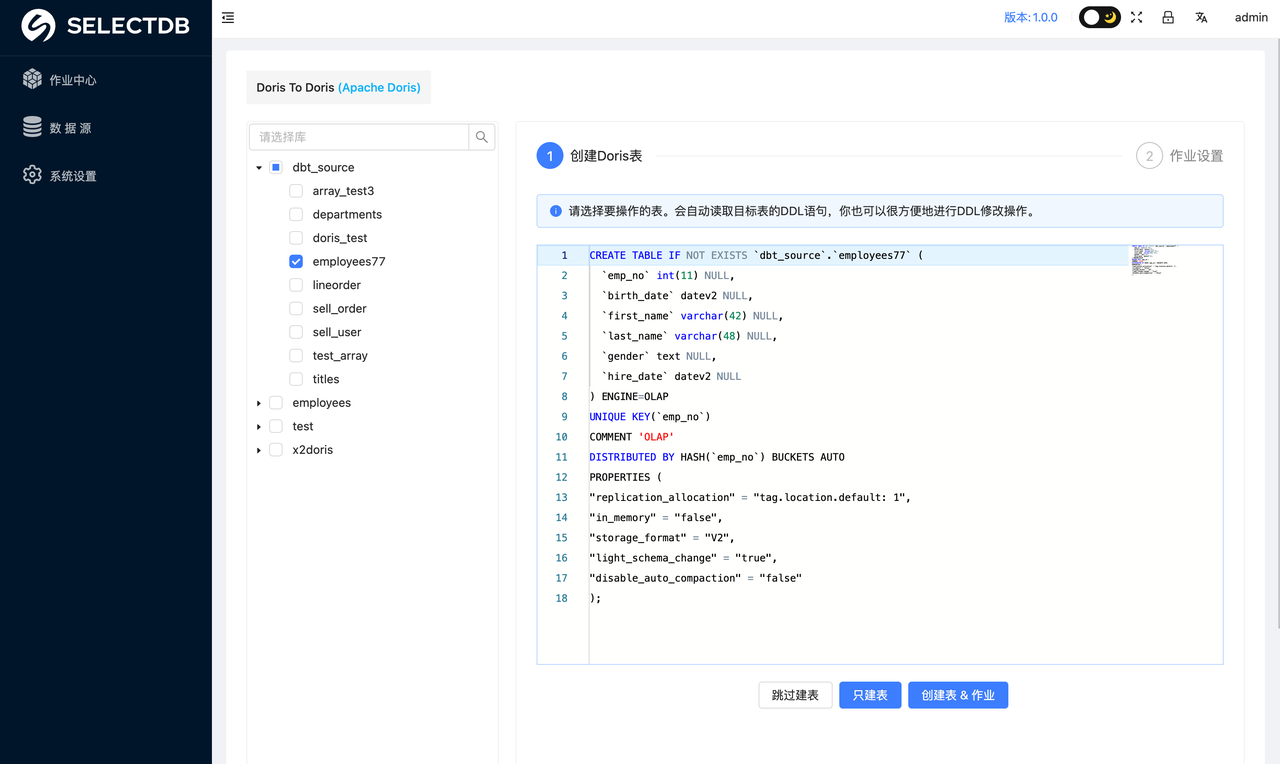
7. 创建 Doris 表
完成前两步即可进入到 Doris 表 DDL 的确认阶段,在该阶段已经自动生成了对应的 Doris 表的建表 DDL 语句,你可以 进行 Review 确认,手动修改 DDL。
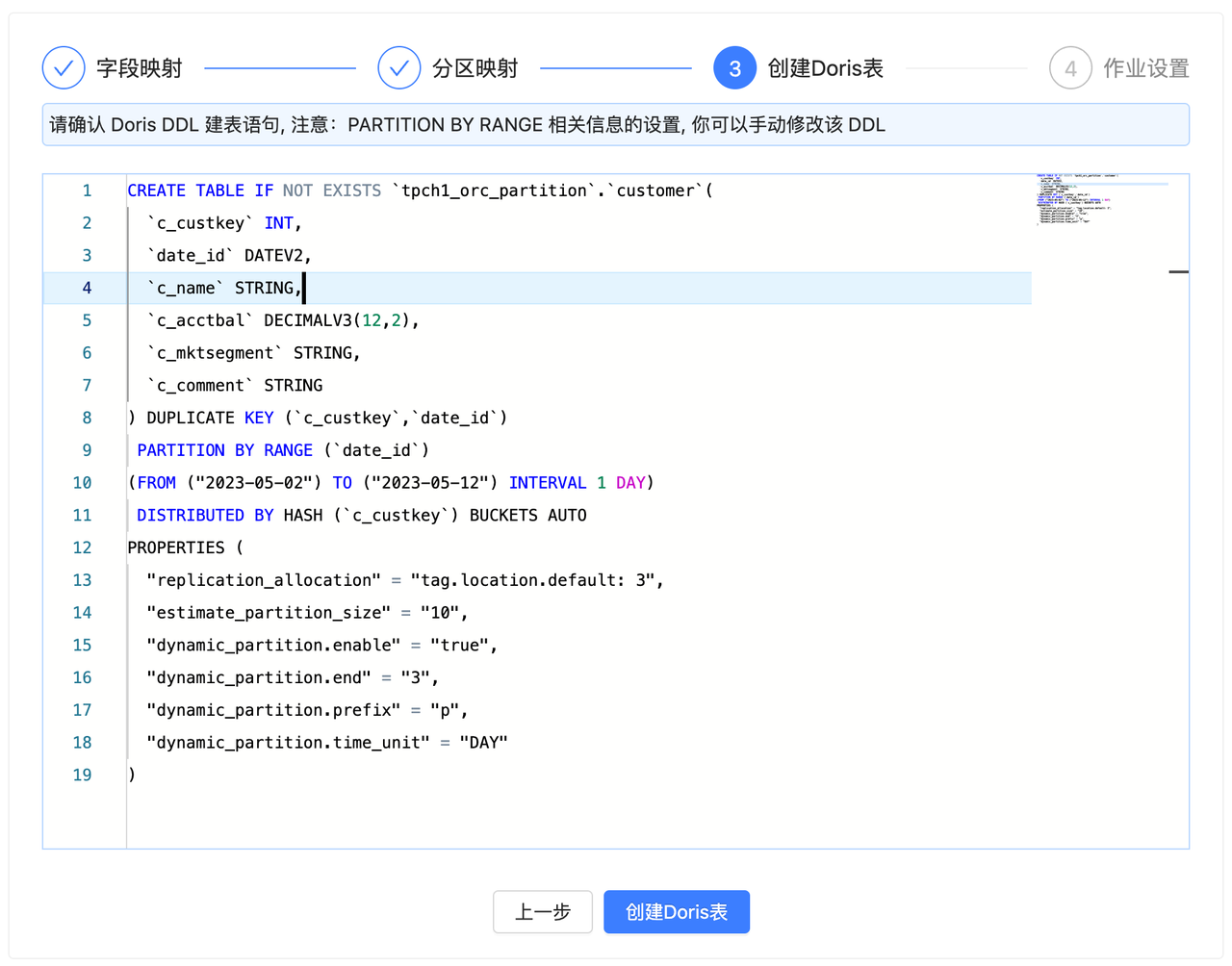
确认无误后,可以点击 创建 Doris 表
⚠️
注意:要确保对应 Doris 的库存在,库需要用户手动创建
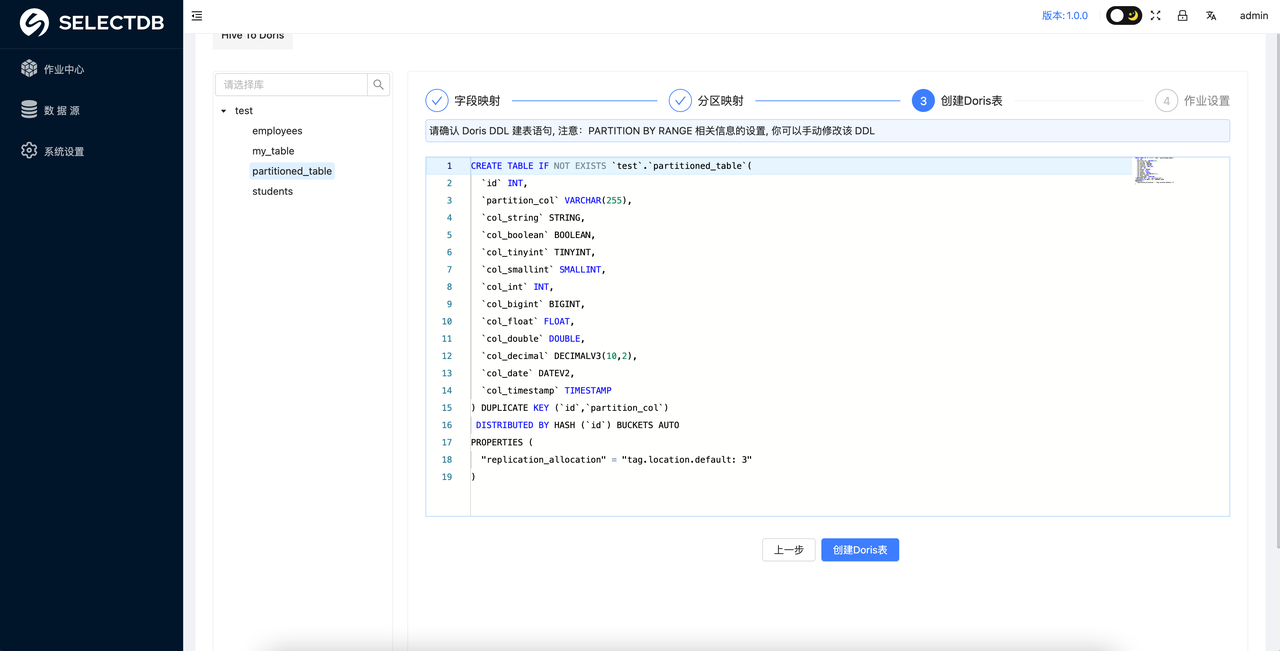
8. 作业设置
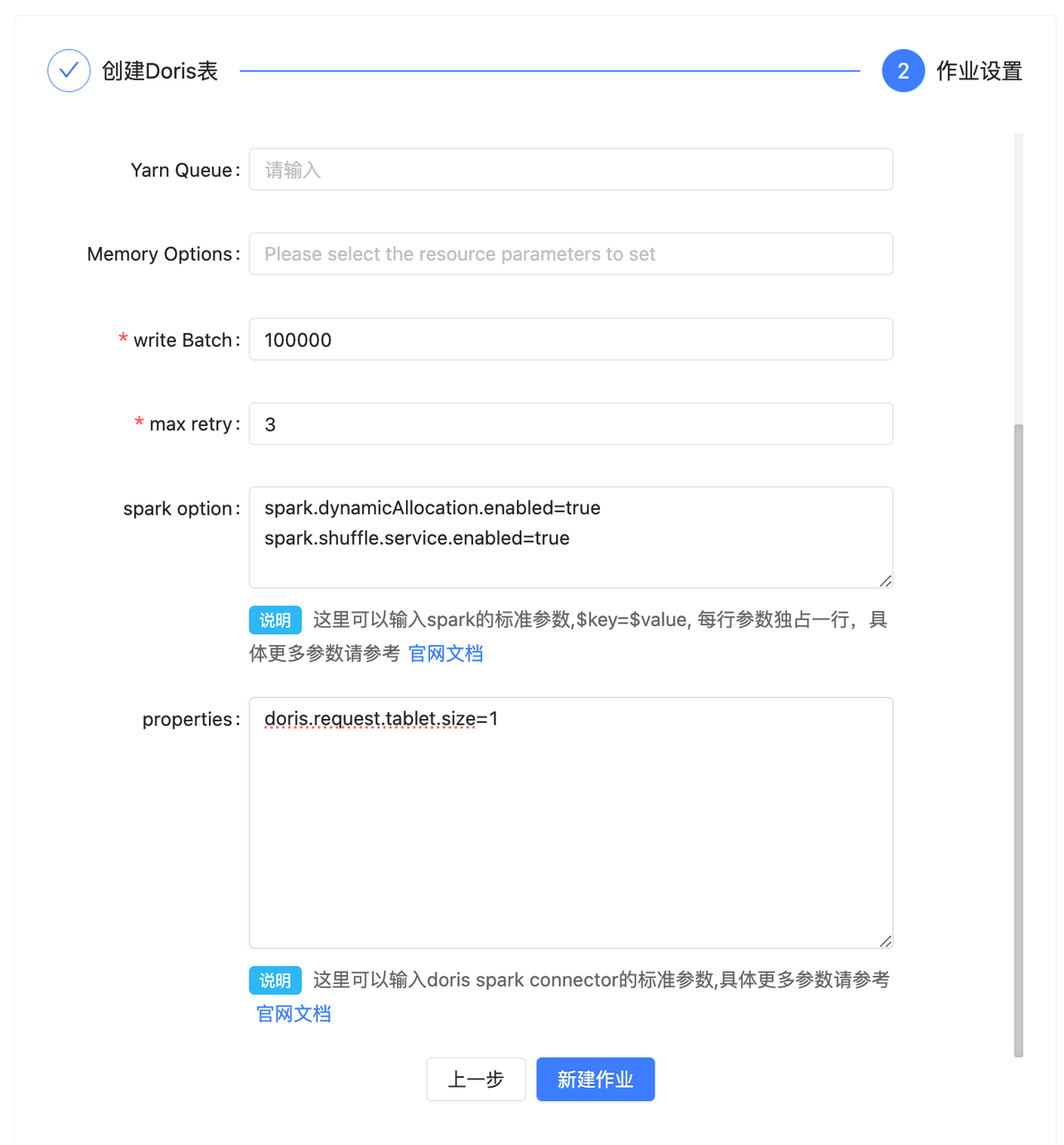
在点击创建作业之后会弹出一个任务配置的界面,用户需要在这个界面配置任务迁移所需要的参数,具体示例如下:
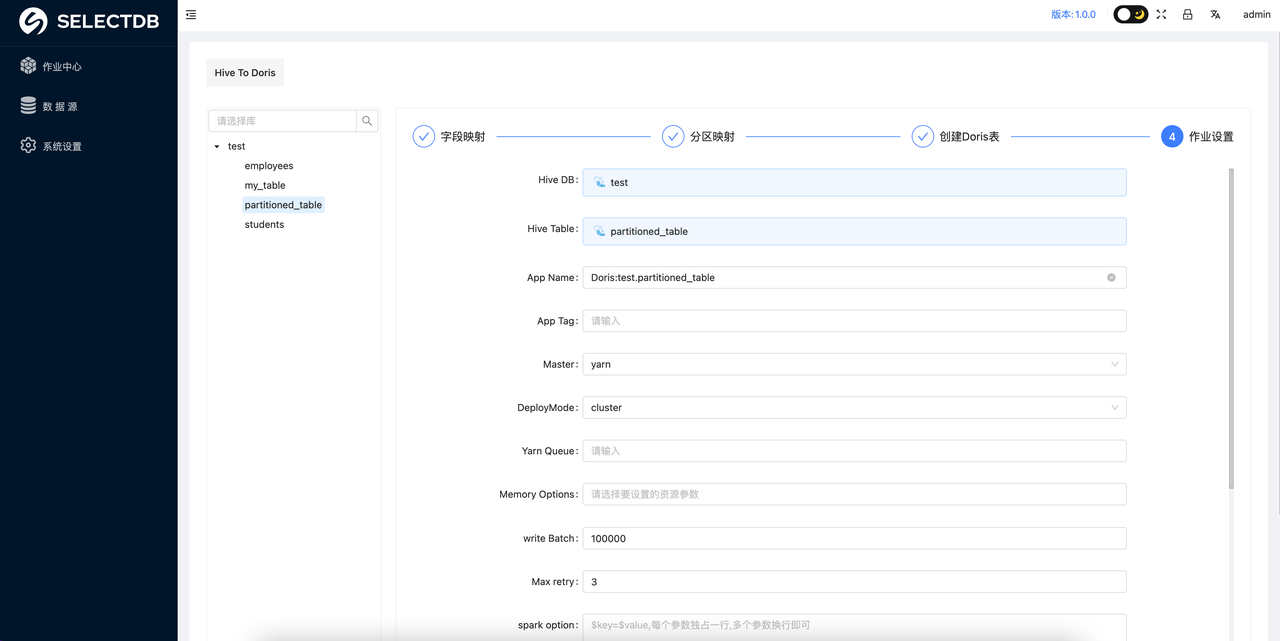
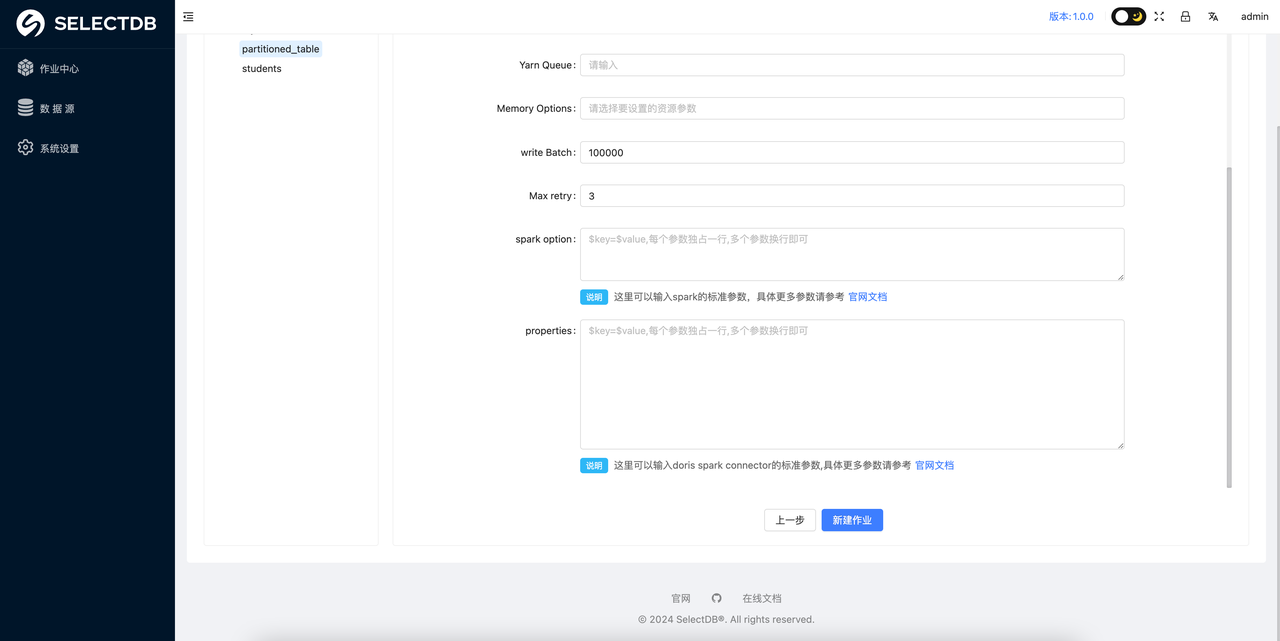
具体参数解释如下(重要参数已经加粗):
- Hive DB:自动生成,数据源的数据库名称
- Hive Table:自动生成,数据源的要迁移的表的名称
- App Name:自动生成,数据迁移任务的名称
- App Tag:自动生成,数据迁移任务的 Tag
- Master: 需要选择是 local 模式、yarn 模式还是 Standalone 模式,这里是指的 X2Doris 的任务运行的方式,这个根据实际情况调整。
- Yarn Queue: Spark 任务运行所使用的队列资源
- Memory Options: 这里需要选择 Spark 任务的一些内存参数,如 executor 和 driver 的 core 的数量和内存大小,这个根据实际情况进行调整。
- Write Batch: 数据刷写时的批次大小,这个可以根据实际数据量调整大小,如果迁移的数据量比较大,建议该值调整为 500000 以上
- Max retry:任务失败的重试次数,如果网络情况不理想,可以适当增大此参数
- Spark option:Spark 的自定义参数,如果需要增加 Spark 任务的其他参数,可以在这里添加,以
key=value的形式增加即可。 - Properties: 数据迁移时,如果有针对数据源读取或者 Doris 数据写入的一些优化参数,可以在这里编写,具体的参数描述可以看对应的 Spark connector 的官方文档
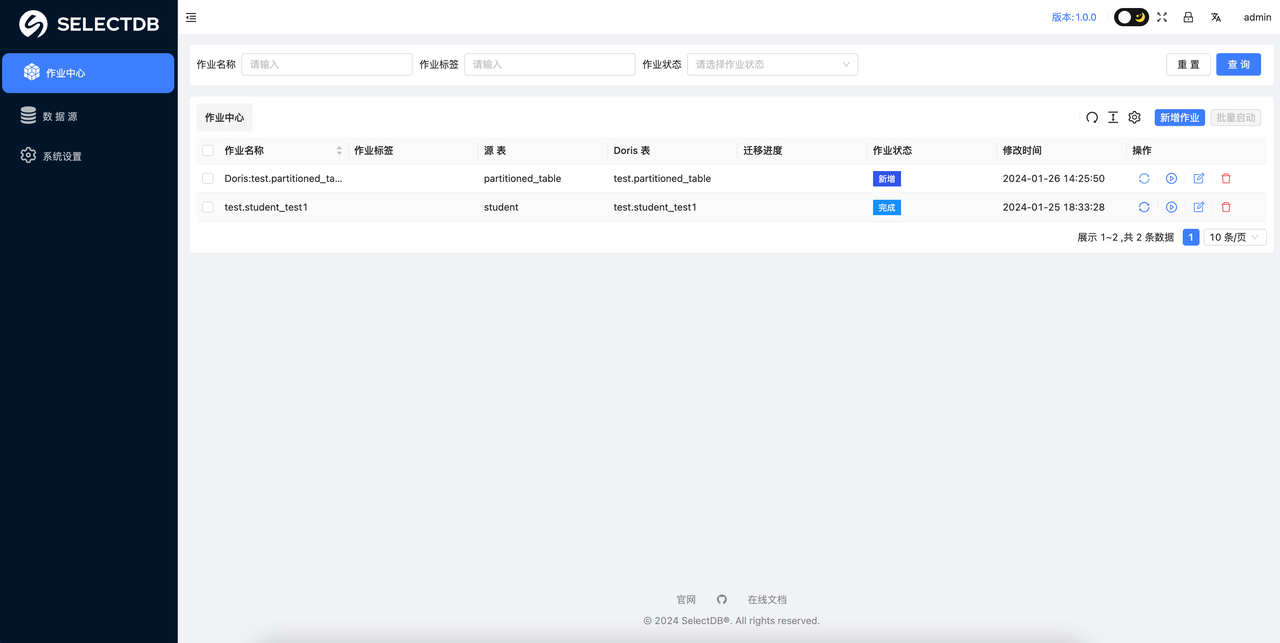
在上一步创建完数据迁移任务后,用户就可以在任务详情界面看到刚创建的数据迁移任务,如下图所示:
2.4 Doris to Doris
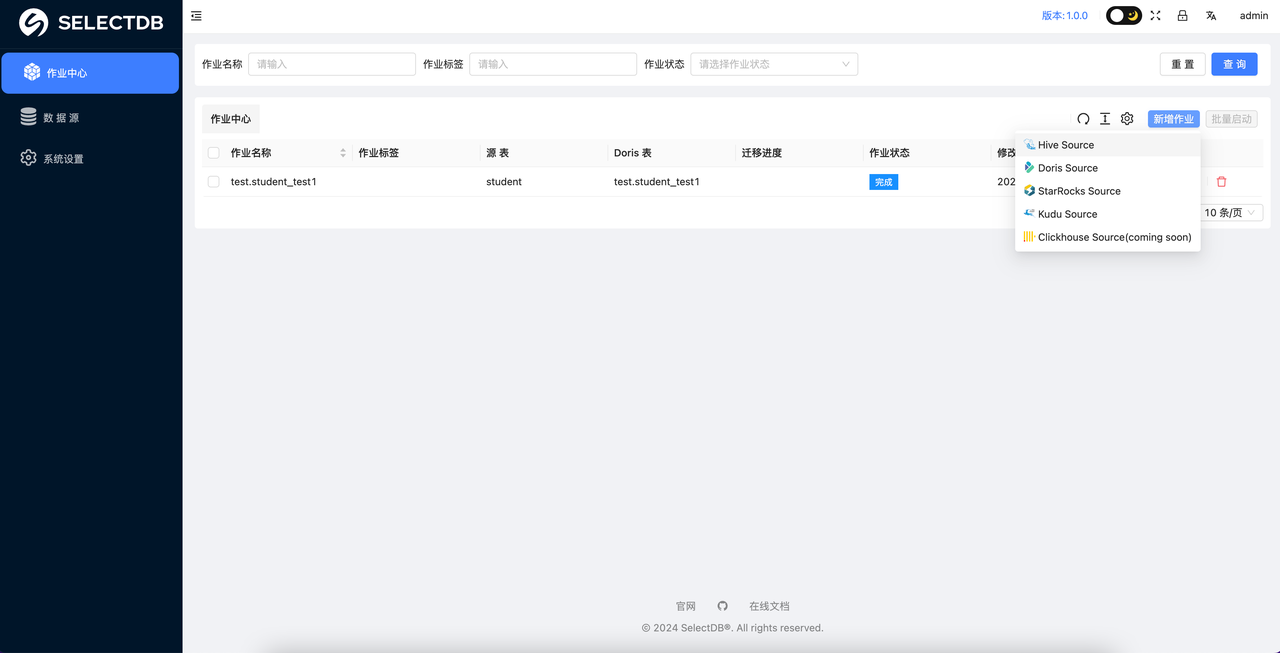
在作业中心点击"新增作业"选择 Doris/StarRocks,此时会弹窗,让选择数据源。
如果之前没有添加数据源,则需要先添加数据源。
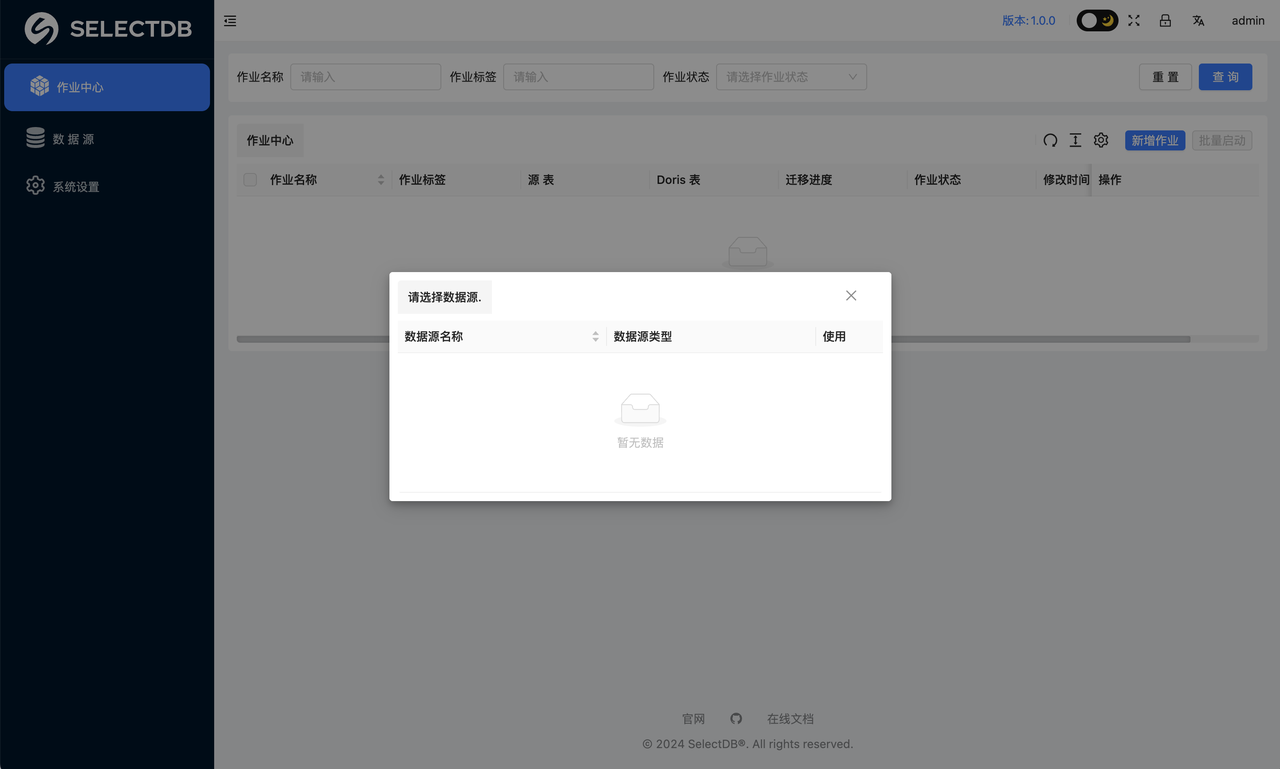
1. 添加数据源
点击左侧的"数据源"菜单。此时可以看到所有的数据源列表,可以选择新增一个数据源,这里我们选择新增一个 Doris 数据源。
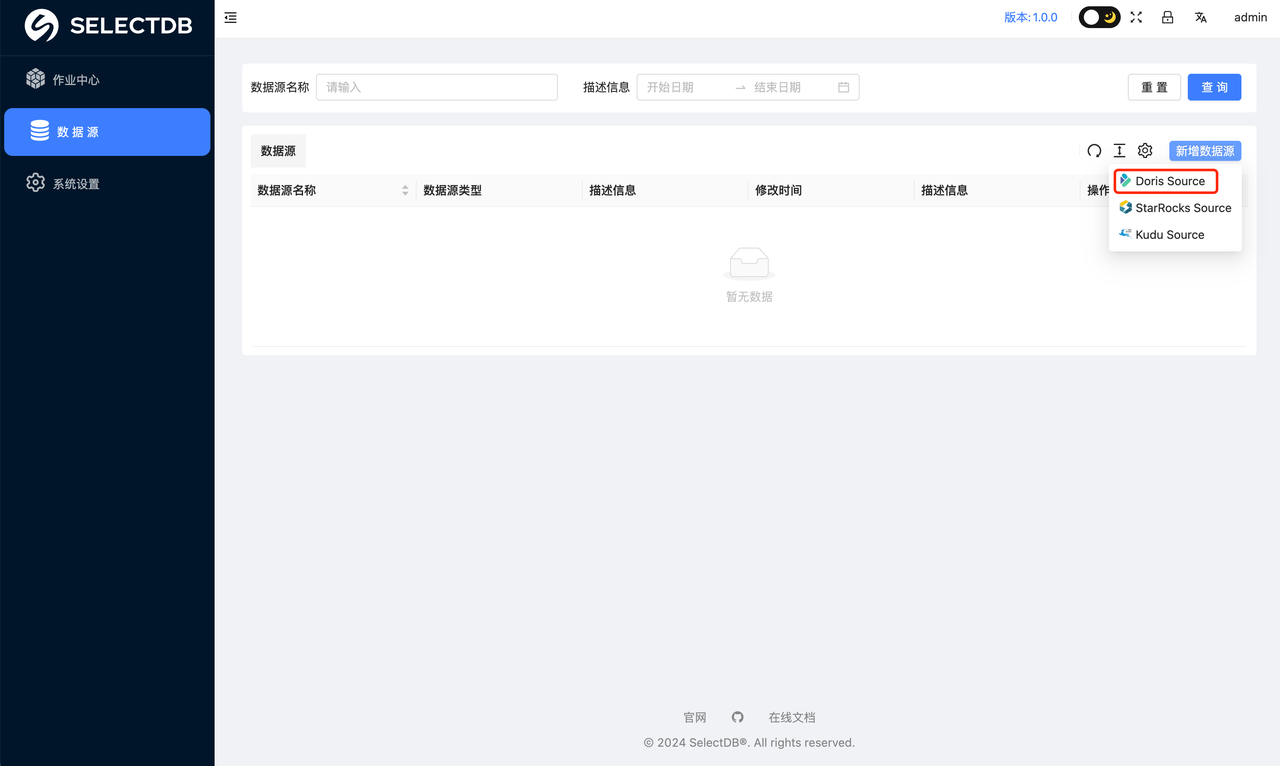
此时会弹窗。让输入 Doris 的连接信息。如:
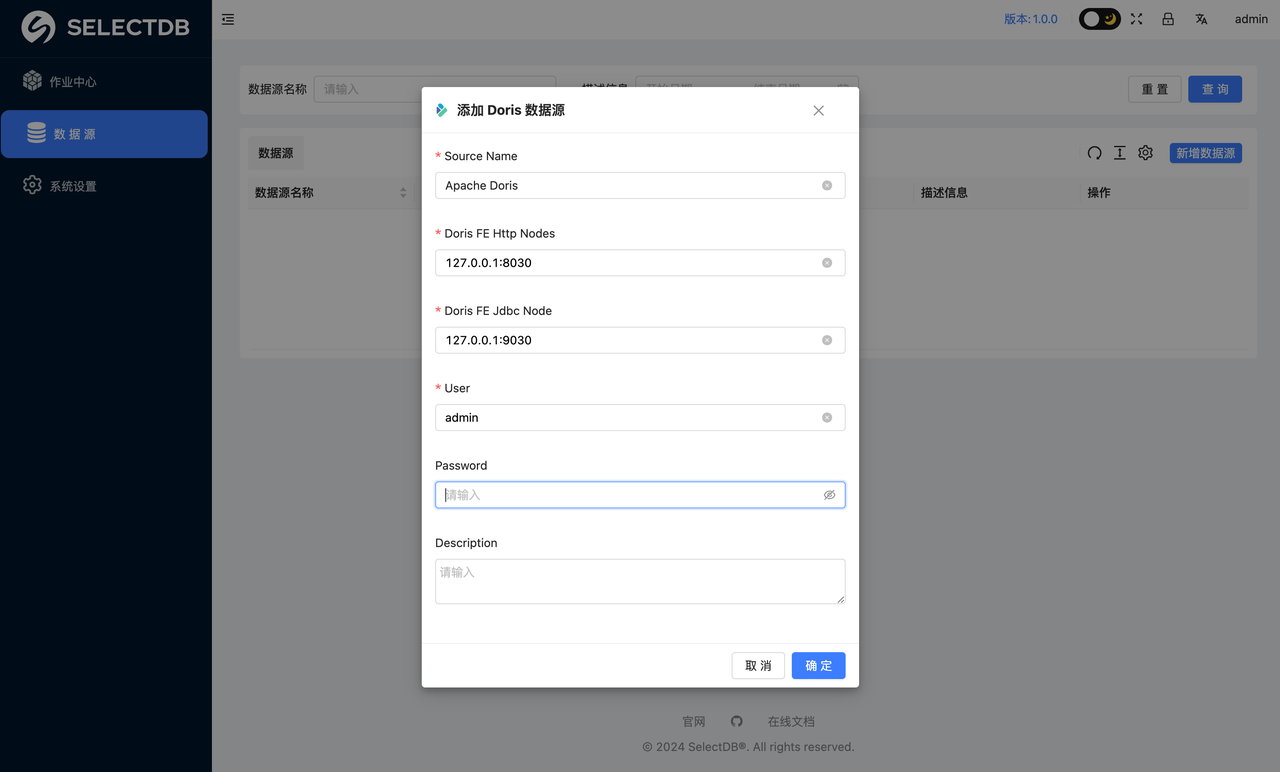
设置 Doris 的 HTTP 节点、Jdbc 节点信息、用户名、密码,然后点击 确定 提交 也可以设置多个节点,格式为 ip1:port1,ip2:port2,ip3:port3,多个节点间以逗号分隔
在此过程中,会自动验证输入的连接信息,如果 host,用户名密码都正确,则会条件成功,页面会自动跳转到"数据源"页面,可以看到刚刚添加的数据源,如:
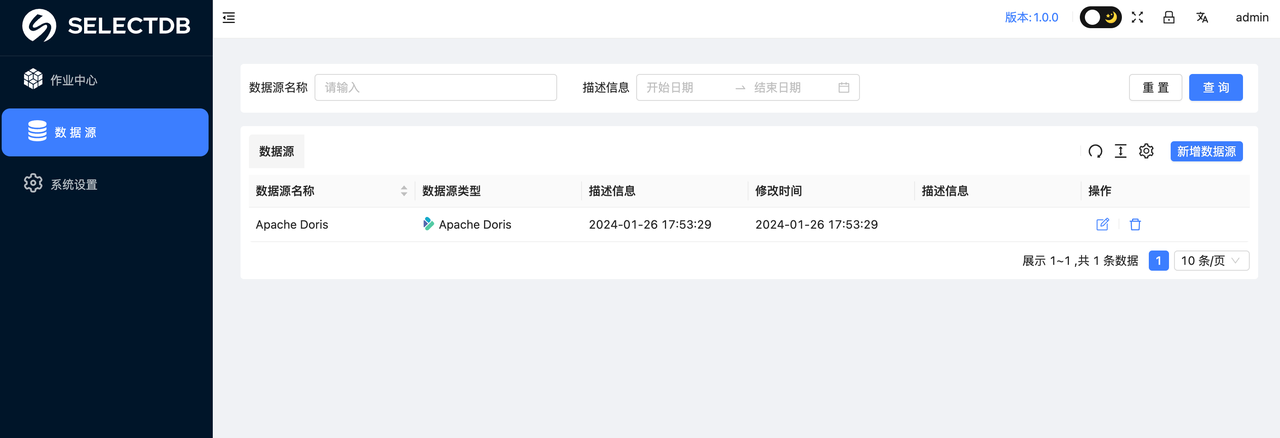
2. 创建同步作业
添加"数据源"之后,返回到"作业中心"页面,可以重新点击"新增作业",选择 Doris Source,此时会弹窗让选择数据源,点击使用即可:
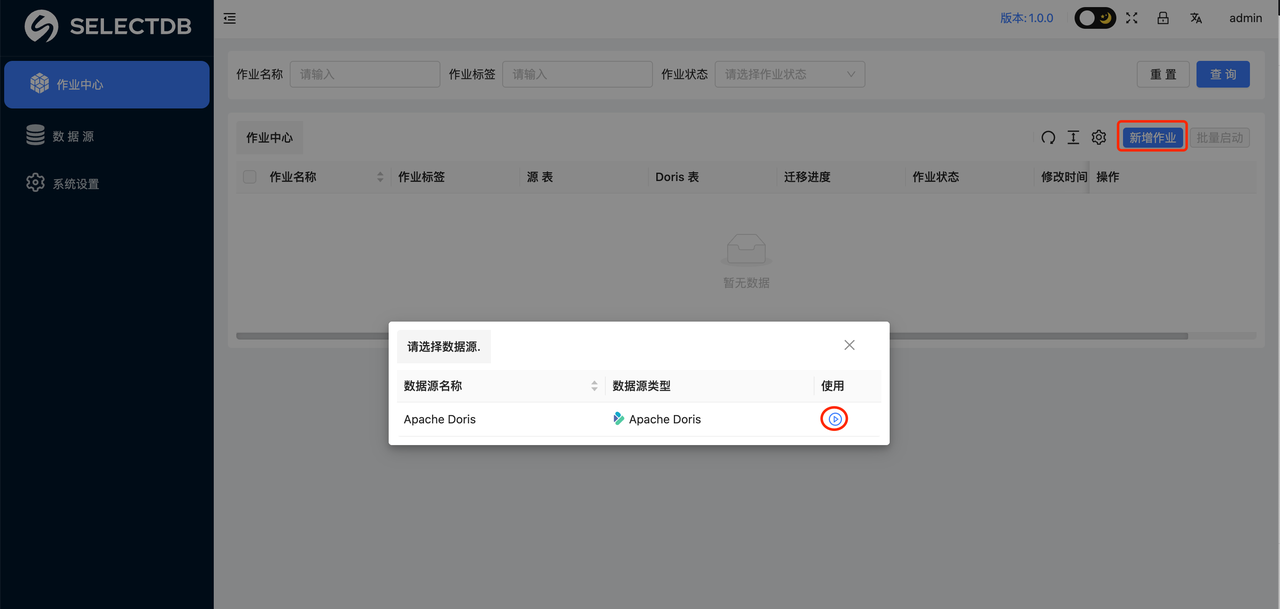
此时会跳转到作业如下页面:会将 Doris 中的数据库和表都以树形结构呈现出来,选择要迁移的表,你可以选择一张表,也可以选择多张,或者整库,如果选择单张表:此时会看到 ddl 语句已经自动生成,你可以 Review 确认这些 DDL
⚠️
注意:只有选择单表才会看到 DDL 语句,如果选择多表则使用默认生成策略生成的 DDL
确认无误后,你可以根据实际需求,进行建表,或者创建作业,这里的操作有:
- 跳过建表:用于要迁移的表在 Doris (SelectDB Cloud) 目标端已经存在,则可以跳过建表
- 只建表:用于只创建表,不创建迁移作业。
- 创建表 & 作业:用于同时创建表和迁移作业
在此过程中,会自动识别字段。如果判断目标 Doris 为 SelectDB Cloud 则会自动处理 Properties 里的参数。
3. 作业设置
最后一步作业设置具体参数和 Hive to Doris 操作一致。
StarRocks、Kudu 和 Doris 的迁移使用方式一致,这里不再赘述。
2.5 启动同步作业
在作业中心可以看到所有创建的作业,如下:
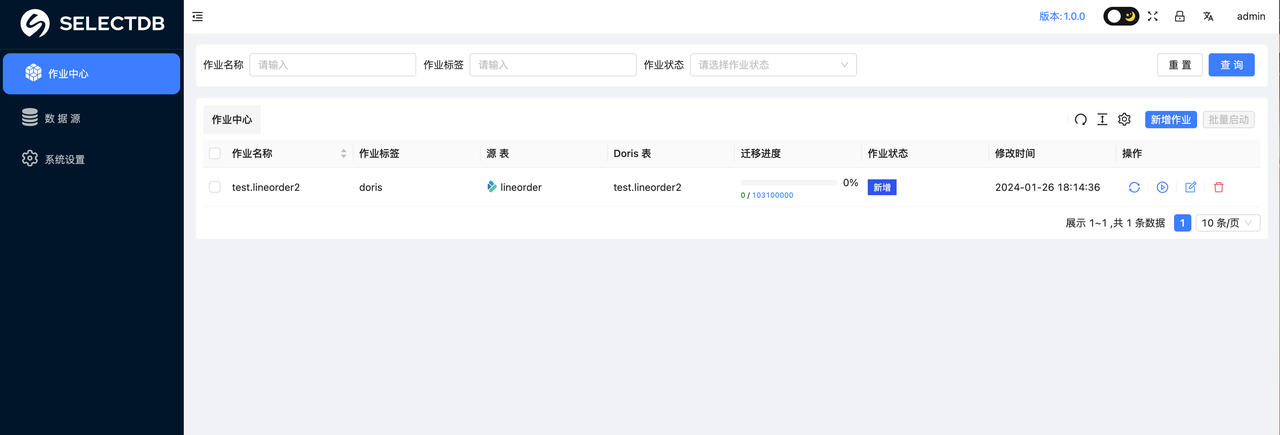
点击操作里的"启动按钮",会弹窗对应的窗口。如下:
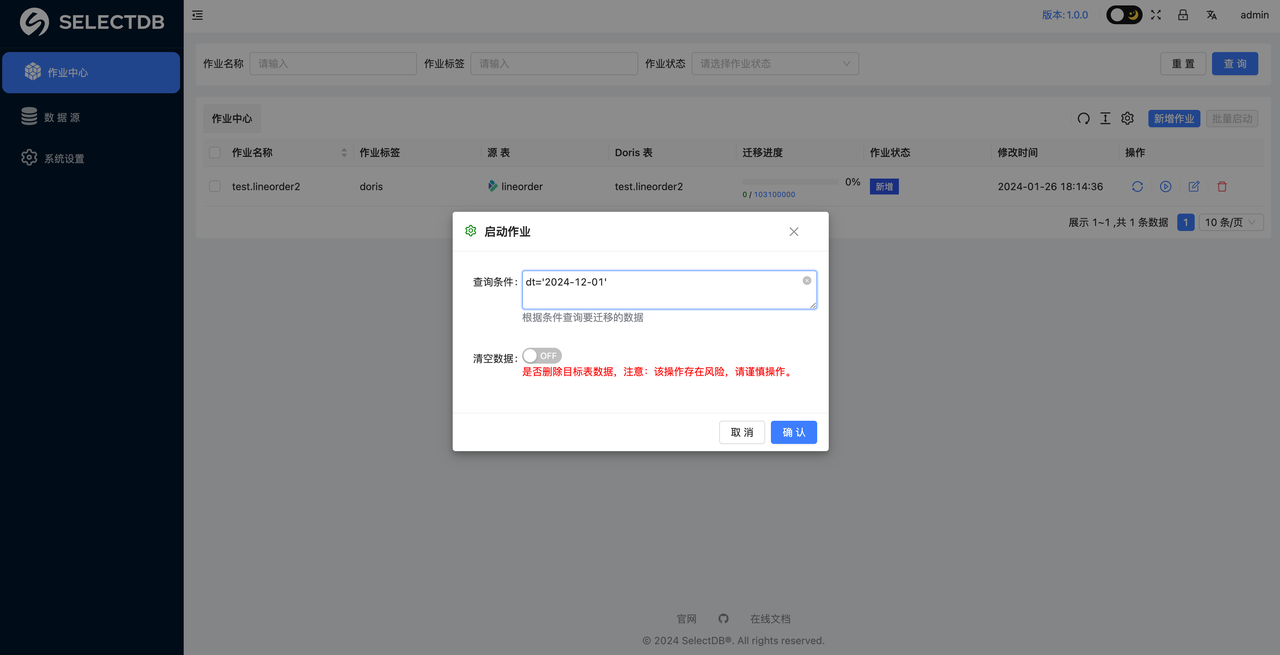
查询条件:该参数是我们允许在数据迁移的过程中,传入过滤条件,对数据源的数据进行 ETL 操作。这里在写对应条件的时候,不需要写 where 关键字,只需要写后边的过滤逻辑即可。
清空数据:这个按钮默认是 OFF 状态,点击切换到 ON 状态后,会在每次迁移任务运行前,对我们目标库的数据进行清除操作,是一个极度危险的操作,生产数据迁移时,慎重操作。
如果没有额外的 ETL 和清除数据的需求,我们只需要点击 OK 即可运行我们的数据迁移任务。
⚠️注意:在运行任务之前,一定要在系统设置里配置 SPARK_HOME,否则没有 Spark 客户端环境,是无法提交 Spark 任务的。
2.6 更新作业迁移进度
在启动作业之后。作业的状态会自动刷新,前端会自动更新,迁移进度需要手动点击刷新按钮来查看数据的迁移状态,切记不要频繁的刷新进度更新按钮,此时迁移进度会显示出来。如下图:
2.7 参数优化指南
在 Doris/SR to Doris(SelectDB Cloud) 的场景中,如果你的 Doris 和 yarn 资源比较空闲,则可以进一步优化速度,可以在 properties 设置如下参数:
doris.request.tablet.size=1 #如果数据源是 dorisstarrocks.request.tablet.size=1 #如果数据源是 starrocks该参数作用是:一个 RDD Partition 对应的 Doris Tablet 个数。此数值设置越小,则会生成越多的 Partition。从而提升 Spark 侧的并行度,但同时会对 Doris 造成更大的压力。
如果使用的是 local 模式,可以通过 spark.local.parallelism 来调整 local 模式下的任务并发线程数,从而提升 local 模式下任务同步速度。
2.8 任务失败如何定位
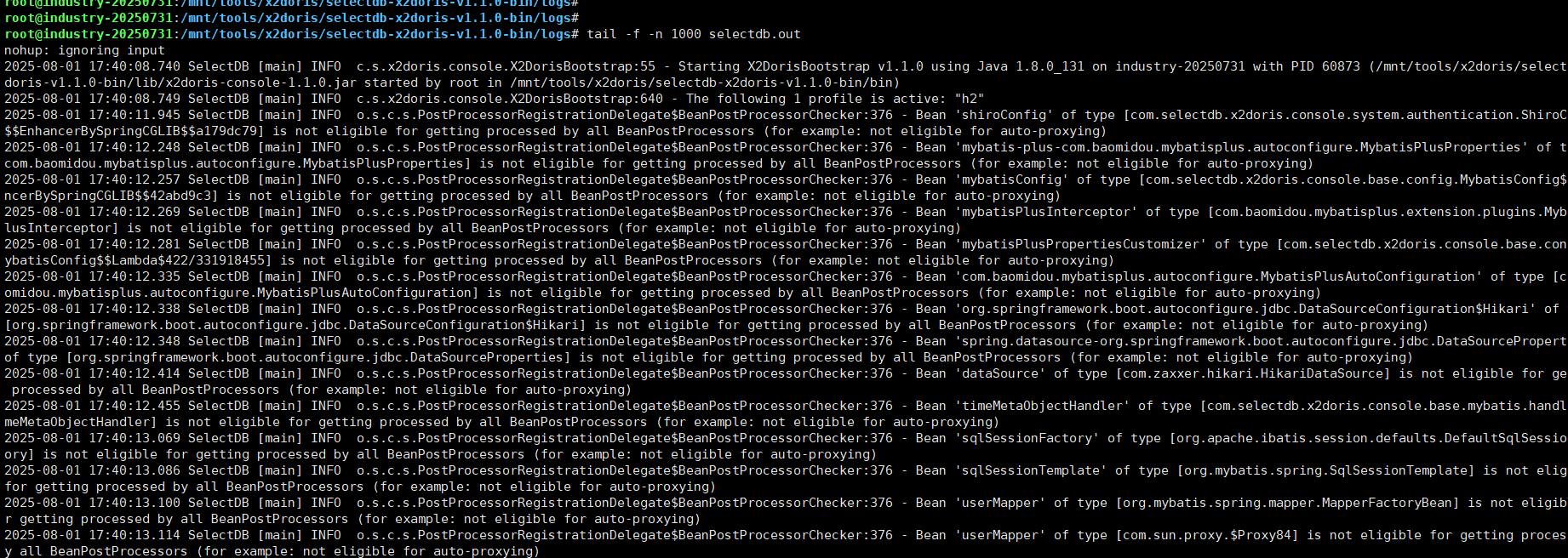
当我们的数据迁移任务失败后,优先排查我们安装 X2Doris 程序的运行日志,对应目录在 X2Doris 安装目录下的 log 目录,可以查看 selectdb.out 来观察和定位程序运行情况。
如果在查看上述日志没有解决问题的话,请携带日志以及该迁移任务运行的上下文背景,寻求 SelectDB 的官方人员的帮助。
2.9 常见问题
问题描述:安装后能打开后台,但是登录不进入系统里面。
问题分析:一般是没初始化配置,像nacos一样,先默认一个数据库(本文是mysql),然后导入数据库,关掉应用再启动,问题解决。总结一句话:看日志是解决问题的关键。
10个关键词解释:
-
X2Doris:SelectDB 开发的数据迁移工具,支持离线数据同步至 Doris。
-
Doris:开源 MPP 分析型数据库,支持高并发、低延迟查询。
-
SelectDB Cloud:Doris 的云服务版本,由 SelectDB 提供托管。
-
Spark:底层计算引擎,X2Doris 依赖其分布式处理能力。
-
YARN:Hadoop 资源调度框架,用于分配 Spark 任务资源。
-
Metastore:Hive 元数据服务,存储表结构、分区等信息。
-
Kerberos:Hadoop 安全认证协议,需配置 keytab 和 principal。
-
DDL:数据定义语言,X2Doris 自动生成 Doris 建表语句。
-
ETL:数据清洗转换,迁移时可添加过滤条件。
-
Duplicate Key:Doris 表模型之一,需指定排序键,X2Doris 自动映射分区字段为 Key。
参考文章: