书籍表 Books:
±---------------±--------+
| Column Name | Type |
±---------------±--------+
| book_id | int |
| name | varchar |
| available_from | date |
±---------------±--------+
book_id 是这个表的主键(具有唯一值的列)。
订单表 Orders:
±---------------±--------+
| Column Name | Type |
±---------------±--------+
| order_id | int |
| book_id | int |
| quantity | int |
| dispatch_date | date |
±---------------±--------+
order_id 是这个表的主键(具有唯一值的列)。
book_id 是 Books 表的外键(reference 列)。
编写解决方案,筛选出过去一年中订单总量 少于 10 本 的 书籍,并且 不考虑 上架距今销售 不满一个月 的书籍 。假设今天是 2019-06-23 。
返回结果表 无顺序要求 。
结果格式如下所示。
示例 1:
输入:
Books 表:
±--------±-------------------±---------------+
| book_id | name | available_from |
±--------±-------------------±---------------+
| 1 | "Kalila And Demna" | 2010-01-01 |
| 2 | "28 Letters" | 2012-05-12 |
| 3 | "The Hobbit" | 2019-06-10 |
| 4 | "13 Reasons Why" | 2019-06-01 |
| 5 | "The Hunger Games" | 2008-09-21 |
±--------±-------------------±---------------+
Orders 表:
±---------±--------±---------±--------------+
| order_id | book_id | quantity | dispatch_date |
±---------±--------±---------±--------------+
| 1 | 1 | 2 | 2018-07-26 |
| 2 | 1 | 1 | 2018-11-05 |
| 3 | 3 | 8 | 2019-06-11 |
| 4 | 4 | 6 | 2019-06-05 |
| 5 | 4 | 5 | 2019-06-20 |
| 6 | 5 | 9 | 2009-02-02 |
| 7 | 5 | 8 | 2010-04-13 |
±---------±--------±---------±--------------+
输出:
±----------±-------------------+
| book_id | name |
±----------±-------------------+
| 1 | "Kalila And Demna" |
| 2 | "28 Letters" |
| 5 | "The Hunger Games" |
±----------±-------------------+
错误题解析
首先需要明确是查询 book 书籍,books是主表这个是容易忽视的点
错误的题解
select books.book_id,books.name ,Orders.quantity ,Orders.dispatch_date between date_sub('2019-06-23', interval 1 year) and '2019-06-23'
from Books left join Orders on Orders.book_id =Books.book_id
where
#Orders.dispatch_date between date_sub('2019-06-23', interval 1 year) and '2019-06-23' and
books.available_from <=
date_sub('2019-06-23', interval 1 month)
group by books.book_id,books.name
#having coalesce(sum(Orders.quantity),0 ) #sum(case when Orders.quantity is null then 0 else Orders.quantity end ) <10
依据 select 语句执行的顺序,先执行 join 语句然后再进行关联的操作,由于条件中返回为null 或者为0会被过滤掉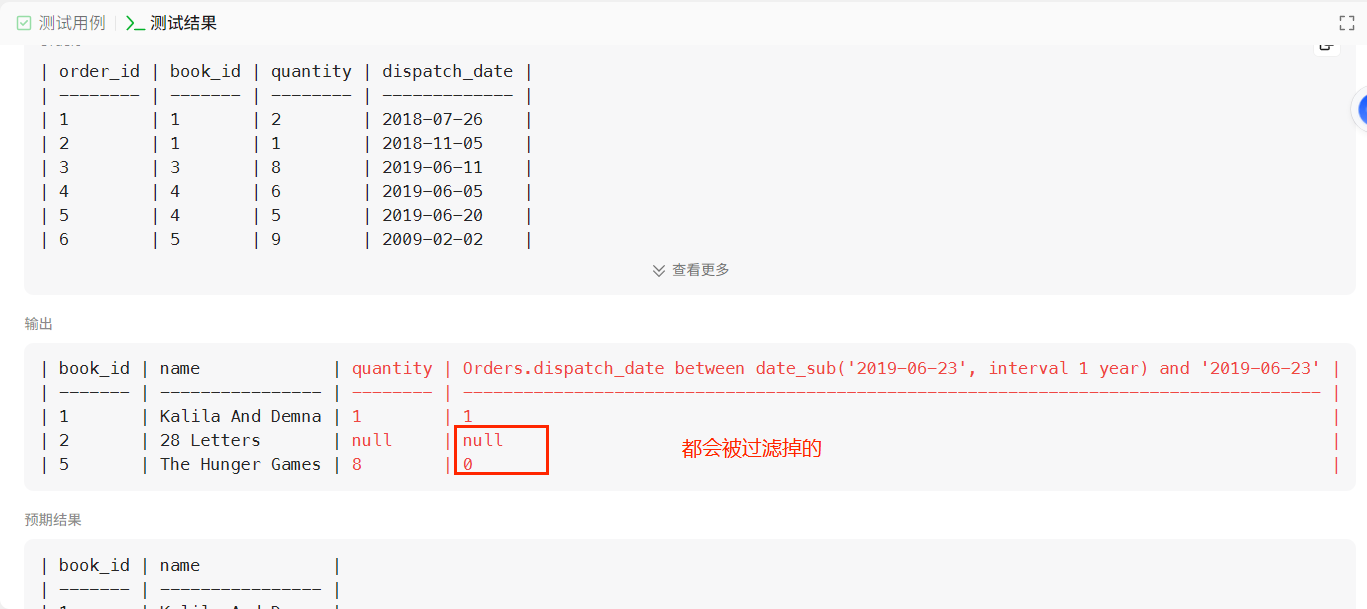
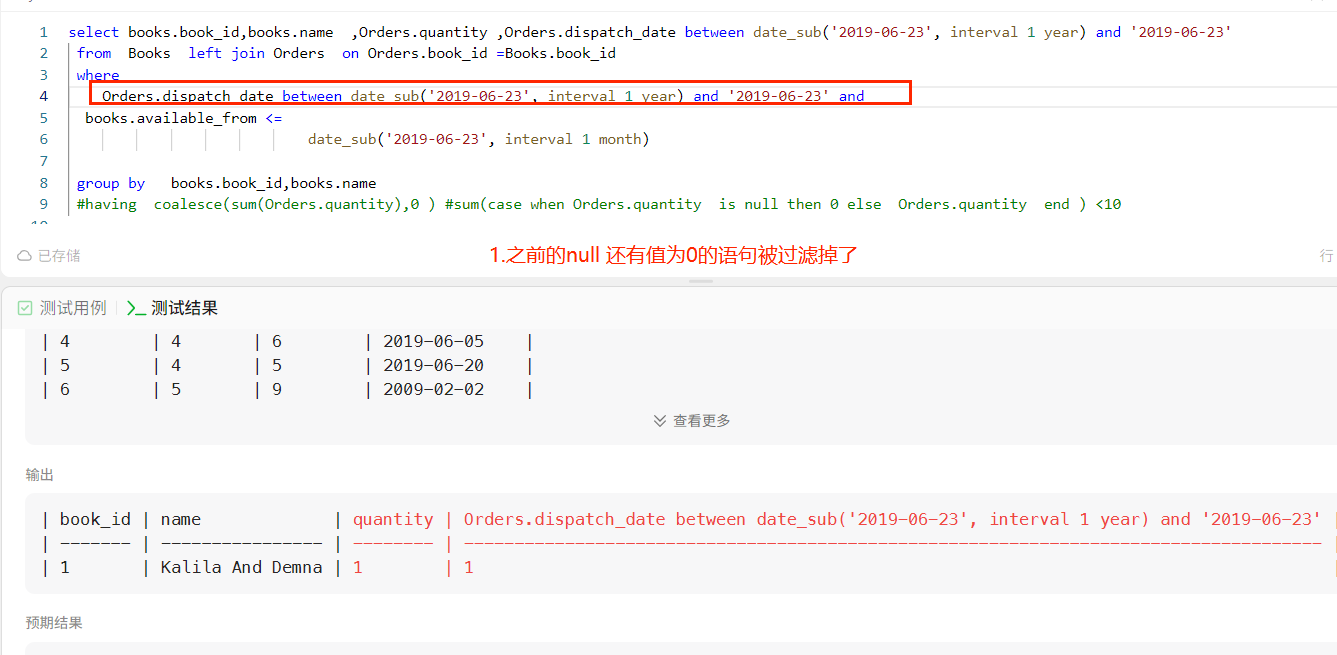
select books.book_id,books.name # ,Orders.quantity
from Books left join (select book_id,order_id,quantity from Orders where Orders.dispatch_date between date_sub('2019-06-23', interval 1 year) and '2019-06-23')Orders on Orders.book_id =Books.book_id
where
books.available_from <=
date_sub('2019-06-23', interval 1 month)
group by books.book_id,books.name
having coalesce(sum(Orders.quantity),0 )<10 #sum(case when Orders.quantity is null then 0 else Orders.quantity end ) <10