缓存在分布式系统中应用广泛,如何在架构设计中使用缓存来优化业务一直都是一个重要的话题。本文主要对引入缓存需要解决的问题以及一些优秀的实践,让读者对缓存有一个比较宏观的了解。
01
一、无处不在的缓存
缓存对性能的提升十分明显,特别是在分布式系统中,80%的业务访问集中在20%的数据上,如何用好缓存是架构设计的必修课。
目前,很多系统框架可能会涉及到方方面面,如下图所示:
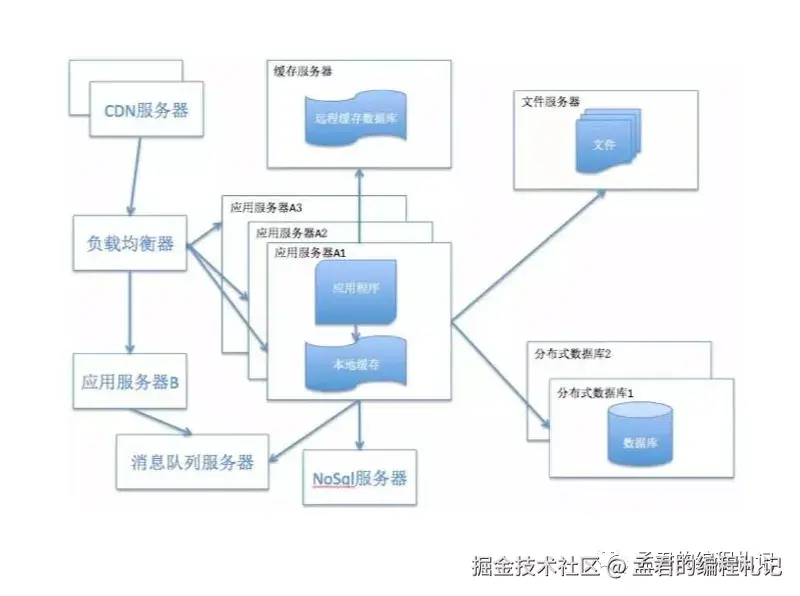
从客户端访问,到最终的数据存储,整个流程中有各式各样的缓存,主要有如下几个部分:
-
客户端缓存
-
- 对于互联网通常来说的是BS架构应用,可以分为页面缓存和浏览器缓存;
- 对于移动互联网来说,指的是APP自身所使用的缓存。
-
代理服务器缓存(如Nginx)
-
- 向用户提供静态内容,内容缓存等
-
分布式缓存
-
- 如Redis,可以供分布式下的应用使用,提高查询效率
-
数据库缓存
-
- Mysql使用了查询缓冲机制,将select语句和查询结果放在缓冲区中,以后对同样的SQL语句,将直接从缓冲区中读取结果,节省查询时间,提高SQL查询的效率。
-
本地缓存
-
- 如Ehcache、Guava,应用自身使用
-
... ...
本质
空间换时间 - 利用分布式下不同介质的快速存储设备,来替换数据库,加快系统的数据处理和响应速度。
就近原则 - 将数据缓存到离用户最近的位置;将数据缓存到离应用最近的位置。
02
二、缓存要解决的问题
引入缓存我们获取的数据的过程就变成如图所示:
优先从缓存中获取数据,若命中则直接返回。
若未命中,则查询数据库:
若数据库中无数据,则返回"未找到 XXX"的提示信息;
若查询到数据,则将其写入缓存,并返回结果。
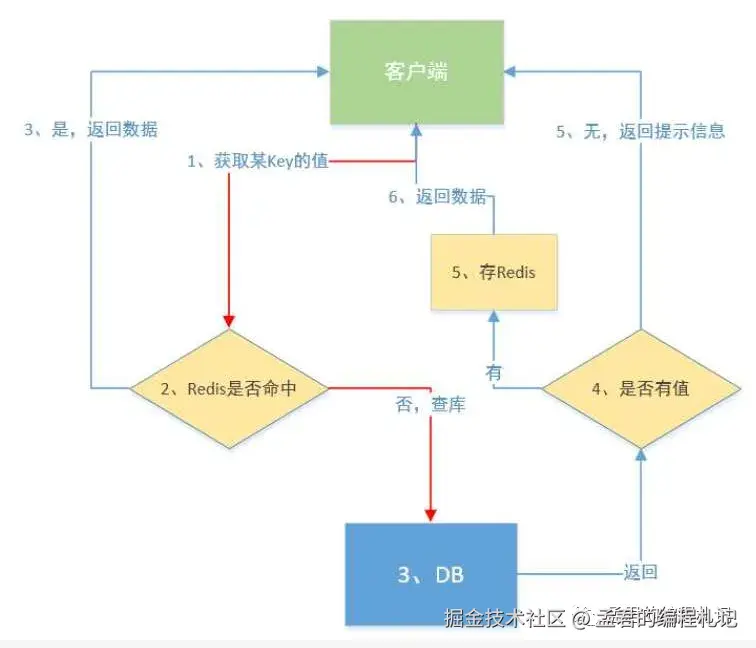
引入缓存一方面可以有效减轻数据库压力,提升查询性能与系统吞吐量;
但另一方面,也带来了诸多需要重点关注的问题,例如:
-
缓存穿透
-
缓存雪崩
-
缓存并发
-
一致性问题
-
缓存升级
-
数据迁移
接下来,我们一个个来看看。
1、缓存穿透
缓存穿透指的是使用不存在的key进行大量的高并发查询,这导致缓存无法命中。每次请求都要穿透到后端数据库系统进行查询,使数据库压力过大,甚至使数据库被压死。
从缓存视角看无法在缓存中找到记录;从数据库视角看无法在数据库中找到记录。缓存穿透的解决方法 ,可以通过空对象(NullObject) 或者 布隆过滤器来解决。
- 空对象(NullObject)
我们通常将空值缓存起来,再次接收到同样的查询请求时。若命中缓存并且值为空对象,就会转换成业务需要的结果返回(包含错误码和结果不存在的错误信息),这样就不会透传到数据库,避免缓存穿透。
- 布隆过滤器
将所有可能存在的数据哈希到一个足够大的bitmap中去,不存在的数据会被bitmap拦截,从而避免了对底层存储系统的压力。
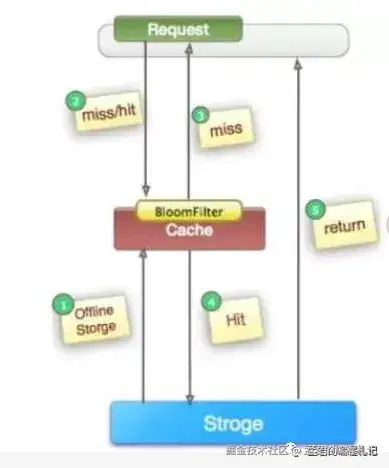
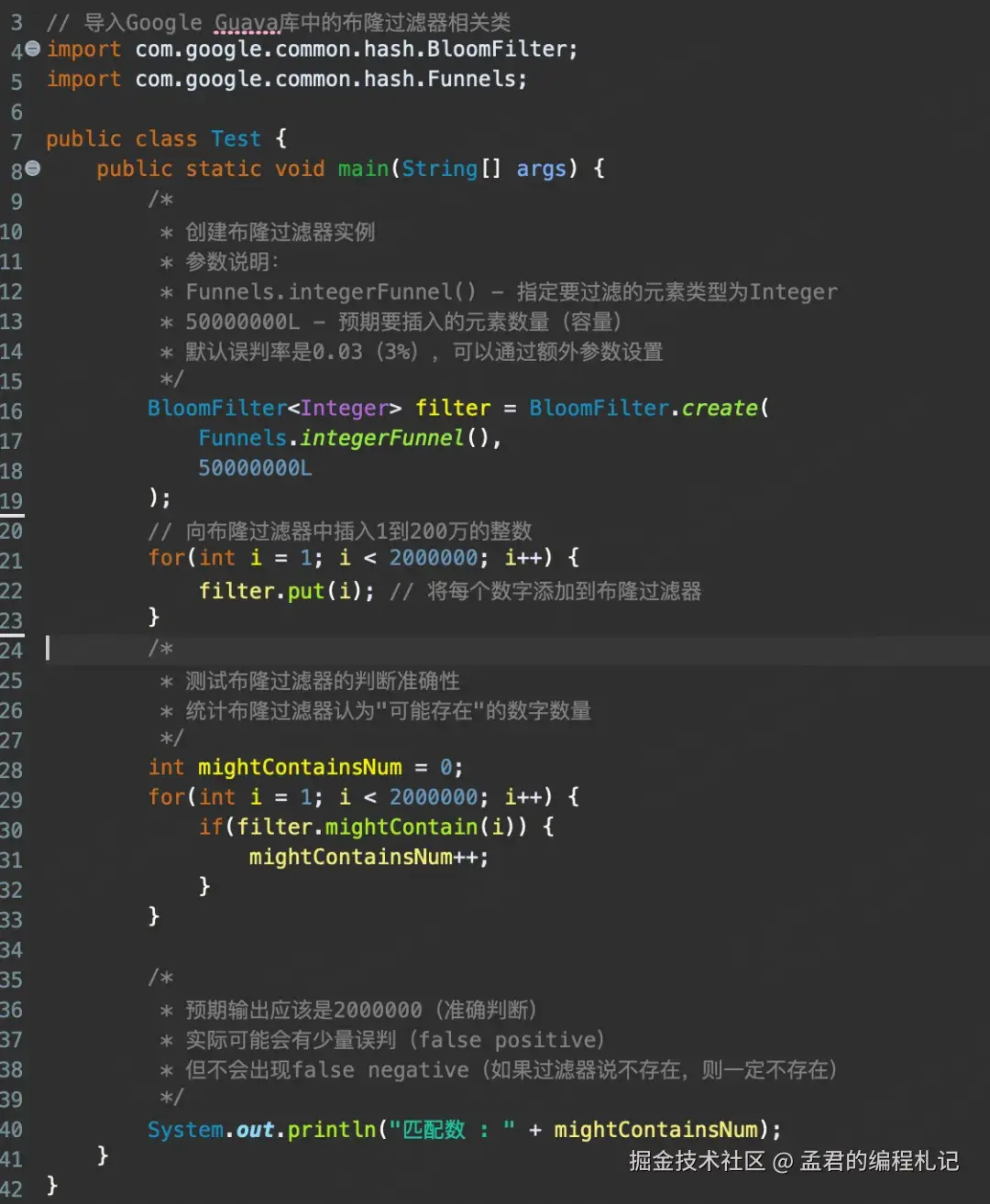
布隆过滤器可以使用Guava来做,一个简单的示例如下:
2、缓存雪崩
缓存雪崩指在服务器重启或者大量缓存集中在某一个时间段内失效,给后端数据库造成瞬时的负载升高的压力,甚至压垮数据库的情况。
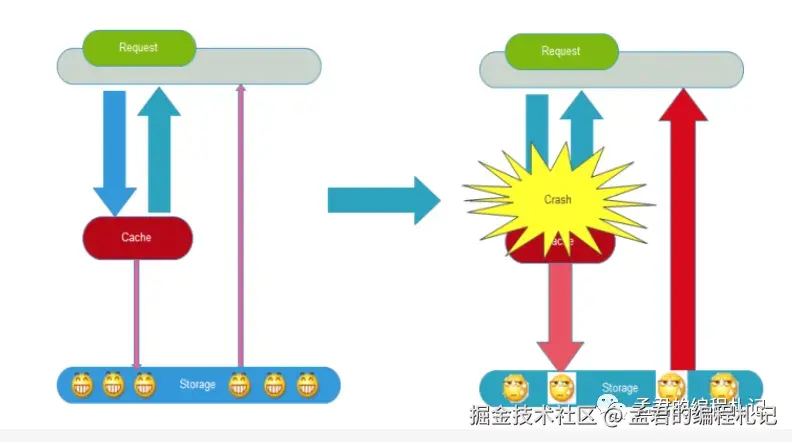
缓存雪崩的一个简单且有效的应对策略是设置不同的缓存失效时间。通常的做法是为不同的数据对象设定不一致的过期时间,以避免在同一时间大量缓存同时失效,从而引发对数据库的冲击。
例如,在缓存产品(Product)数据时,可以为每个产品设置略有差异的过期时间:以30分钟为基础时间,再随机增加0~5分钟,使实际失效时间分布在30至35分钟之间,从而实现失效时间的打散,降低雪崩风险。
除此之外,其他常见的防护手段还包括:
-
引入二级缓存,通过多级缓存机制缓冲热点;
-
缓存永不过期,结合定时任务或基于策略的主动失效机制来更新缓存;
-
热点数据预加载与自动刷新机制,保证缓存持续可用;
-
限流与降级策略,在缓存失效后限制对后端的访问量,避免瞬时流量冲垮系统。
3、缓存并发
**
**
缓存并发的问题通常发生在高并发的场景下,当一个缓存key过期时候,因为访问这个缓存key的请求量较大,多个请求同时发现缓存过期。因此多个请求会同时访问数据库来查询最新的数据,并且写回缓存,这样造成应用和数据库的负载增加,性能降低。
缓存并发可以通过分布式锁、 软过期等方法解决。
- 分布式锁
使用分布式锁,保证对每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
- 软过期
对缓存的数据设置失效时间,就是不使用缓存服务提供的过期时间,而是业务在数据存储过期时间信息,由业务程序判断是否过期并更新,在发现了数据即将过期时,将缓存的失效延长,程序可以派遣一个线程去数据库获取最新的数据,其他线程这时看到了延长了的过期时间,就会继续使用旧数据,等派遣的线程获取最新数据后再更新缓存。
其它解决方法入手多级缓存 、永不过期等。
4、一致性问题
**
**
当数据变化时候,为了去保持数据库和缓存数据的一致性,数据库和缓存处理的方式主要有2种:
方法1: 先删除缓存,再更新数据库
方法2: 先更新数据库,再删除缓存(个人使用这个,推荐)
- 先删除缓存,再更新数据库
理由
1、原子性考量
2、因为如果删除缓存成功,更新数据库失败,最多只是会造成缓存穿透,引起一次Cache miss,后面还会更新缓存。而如果更新数据库成功,删除缓存失败,会引起比较严重的数据不一致情况。
有很多同学选择该方式来处理,原因主要是如上所述吧。
但是,这个在并发的场景中,两个并发操作,一个是更新操作,另一个是查询操作,更新操作删除缓存后,查询操作没有命中缓存,先把老数据读出来后放到缓存中,然后更新操作更新了数据库。于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。
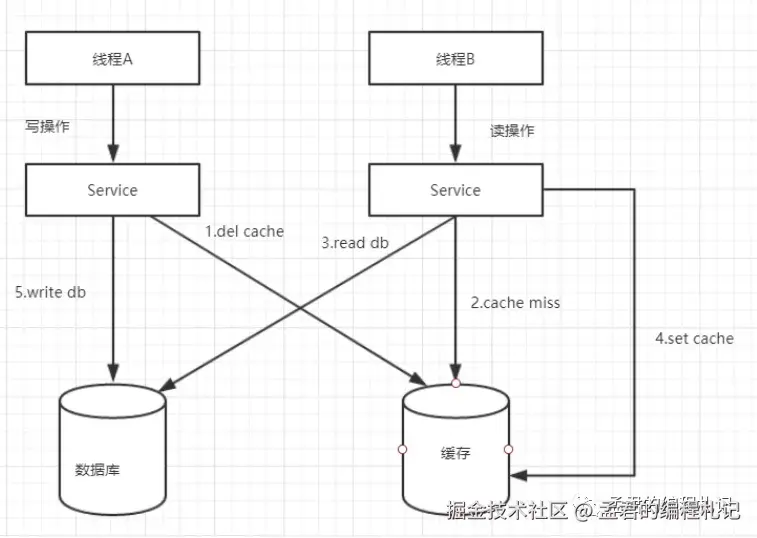
这种方式也是有数据不一致的场景存在,当然可以通过双删除的方式解决,即更新数据库后再删除一次缓存。
我为什么没有选择这种方式,主要还是因为,我觉得数据还是要以数据库的数据为准,缓存应该是个辅助,其操作成功不意味着最终真正的成功。写缓存失败就不再写数据库,虽然保证了原子性,但这种做法对比较影响业务。所以,个人还是比较倾向于方法二:先更新数据库,再删除缓存。
- 先更新数据库,再删除缓存
注
这里使用的是删除del而不是set,之所以这样是怕两个并发的写操作导致脏数据。
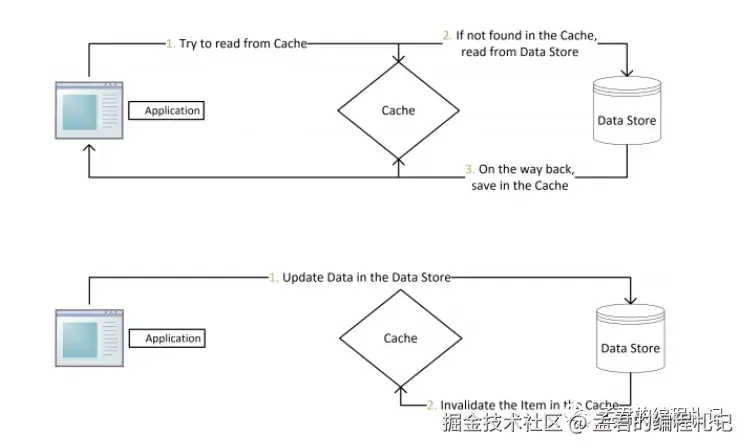
这种主要采用了Cache Aside Patter, 其主要的思想是:
-
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
-
命中:应用程序从cache中取数据,取到后返回。
-
更新:先把数据存到数据库中,成功后,再让缓存失
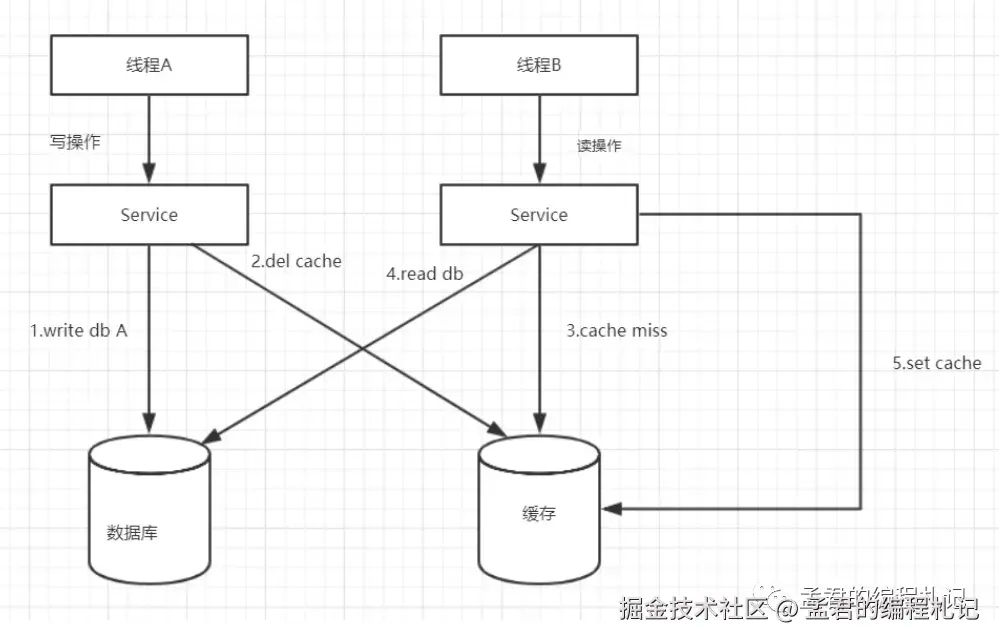
该种处理方式基本没有很大的并发问题,其造成脏数据的情况相对概率相对较低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。
脏数据场景
一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
不过,在这种场景下仍可能面临一些潜在问题,例如:
-
数据库更新成功,但在读写分离架构下,是否会有问题?读请求可能落在从库,从而读取到旧数据;
-
数据库更新成功但缓存删除失败(如因网络抖动等原因),导致缓存脏读, 如何做?
针对这些问题,可以采取以下应对策略:
-
针对读写分离:对存在强一致性需求的表或关键业务操作,可强制走主库读取,确保读取到最新数据;
-
针对缓存删除失败:可引入消息队列机制,在数据库更新后异步发送消息,由专门的消费者进行缓存删除操作,并支持失败重试,提升删除的可靠性。
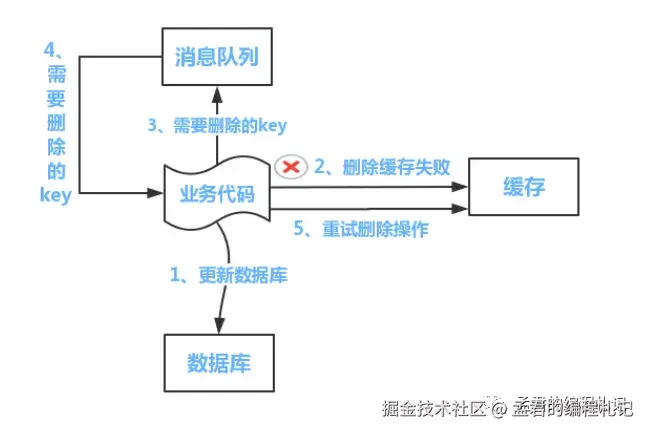
采用这种方式时,业务逻辑需要显式处理缓存失效或更新的相关操作,对代码有一定的侵入性。
那么,是否有办法让业务层只关注核心业务逻辑,而无需关心缓存的一致性处理?
答案是肯定的。可以借助 Canal 等中间件,通过订阅数据库的 binlog(变更日志) 来实现缓存的异步更新。例如:
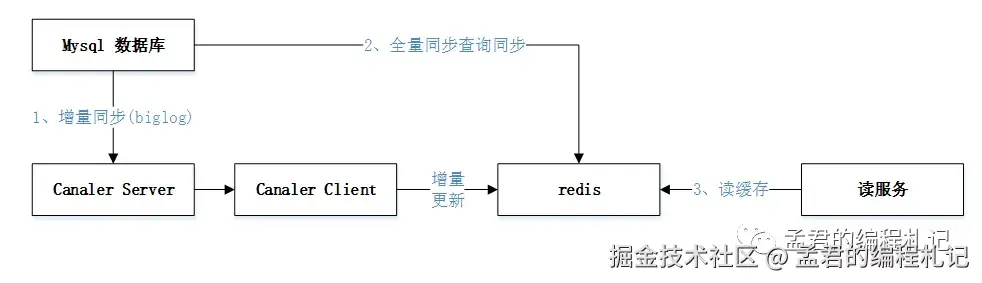
通过这种方式,缓存失效的处理被抽离到业务逻辑之外,业务层可以专注于自身的核心功能,而无需关心缓存一致性问题。
缓存维护由独立的非业务组件负责,实现了职责分离,如下图所示:
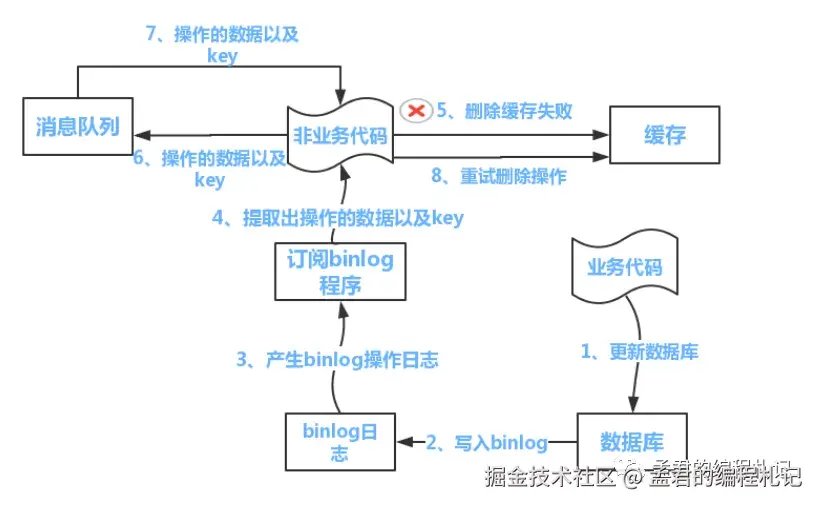 补充
补充
关于先更新数据库还是先删除缓存,这些还是要根据自己的业务场景、特点来选择。个人而言,我更加倾向于【先更新数据库,后删除缓存】的方式。
5、本地缓存
**
**
在很多场景中,我们还会引入本地缓存(比如采用Guava来做),以增加查询效率。
场景
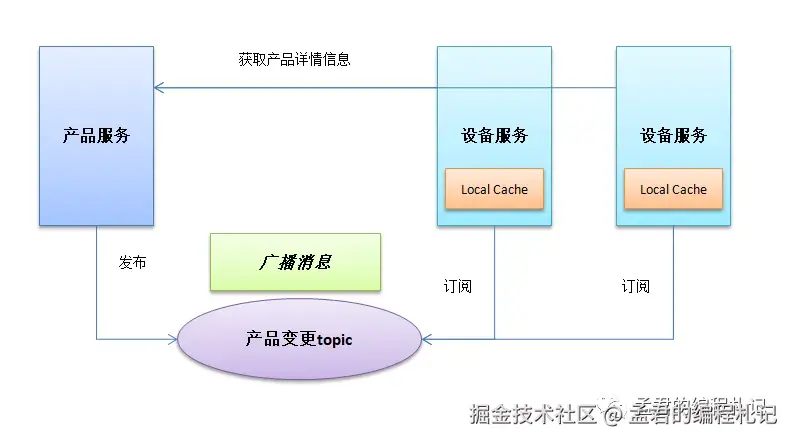
有两个(dubbo)应用product和device,其中:
product服务接口提供中获取产品详情的方法,包含产品基本信息定义,以及包含的数据点等定义。
device服务需要使用到获取product的获取产品详情方法。
在上述场景中,详情的获取是这样的device -->product --> 缓存,
因为产品的定义修改是低频的,所以如果在device中增加product详情的本地缓存,将减少调用product服务的次数,减少网络带来的开销,提升device相关接口的效率。

引入本地缓存后,变成如下模样。
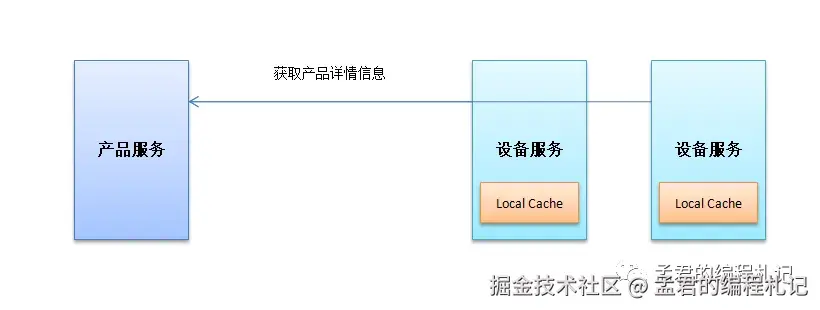
这样一来,本地查询是加快了,但是同时也带来了如下的问题:
如果产品信息更新,分布式环境下device的应用服务可能有几十个,每个device应用中的本地缓存如何同步更新?
一个较靠谱的解决方法便是引入消息队列进行通知,采用广播的方式。
6、缓存的对象扩展
思考
前期对某个对象(如产品Product)进行了缓存,缓存对象包含产品的名称、productKey。现在需要在该缓存对象中增加一个所述品类的的信息,需要在原来的基础上进行扩容。
上线发布需要注意些什么呢?
解决方法:
-
对需要改变的key的名字增加版本加以区分,如原来prod:{productKey},改成prod:{productKey}:v2
-
配置中心增加应急开关,用于是否启用新的key
-
不能够在灰度的时候打开应急开关,因为,如果原来产品信息如名称有更新,则:
-
-
灰度机器处理的话,其不会更新原来的key
-
非灰度机器处理的话,其不会更新新的key
这两者都会造成产品信息查询的时候,有部分流量返回的数据是不正确的。
-
-
如线上发现问题,直接关闭开关
7、版本升级,数据迁移
思考
Redis版本需要升级,比如4.0升级到5.0,需要进行数据迁移。
如何做呢?
这个时候需要考虑业务场景了,是否是静态迁移还是动态迁移。
静态迁移(需要做好评估,一般在晚上交易量小或者非核心业务场景中用)
-
停机应用,先将应用停止
-
迁移历史数据,按照新的规则把历史数据迁移到新的缓存集群中
-
更改应用的数据源配置,指向新的缓存集群
-
重新启动应用
如果不能停机,进行数据迁移如何做呢?
平滑迁移(适合对可用性要求较高的场景,如停机会带来较大损失,无交易低峰)
-
双写。按照新旧规则同时往新缓存和旧缓存中写数据
-
迁移历史数据,如果在一定的时间内新缓存就有足够的数据,那么可以不需要进行此操作
-
切读。把应用层所有的读操作路由到新的缓存集群上
-
下线双写。把写入旧的逻辑下线(可以采用线上配置开关处理)
03
三、缓存使用优秀实践
在高并发系统中,缓存是一种关键的性能优化手段,但也带来内存占用、数据一致性和系统稳定性等挑战。以下是一些推荐的缓存使用实践:
- 预估缓存需求
-
- 缓存主要消耗服务器内存,因此在设计缓存策略前,应评估需缓存的数据结构、数据大小、数据量及其生命周期(失效时间),避免内存溢出或资源浪费。
- 核心业务与非核心业务分离缓存实例
-
- 将关键业务与非关键业务分别使用不同的缓存实例,防止非核心业务缓存异常影响核心业务的稳定性。
- 合理设置缓存过期时间
-
- 缓存应设置合适的超时时间。过长可能导致缓存污染,过短可能频繁回源数据库。极端情况下会拖垮线程池,造成"缓存雪崩"。
- 使用业务前缀区分缓存 Key
-
- 当多个业务共享同一个缓存实例时,应统一为缓存 Key 添加业务前缀,避免命名冲突导致缓存互相覆盖。
- 打散 Key 的过期时间
-
- 避免大量缓存同时过期造成瞬时访问数据库压力。可以采用基础时间 + 随机时间的方式设置缓存过期时间,实现失效时间分布的打散。
- 避免缓存大对象
-
- 缓存对象不宜过大,否则可能导致网络阻塞、GC压力增大,甚至拖慢整体缓存响应,影响系统性能。
- 引入缓存降级机制
-
- 对于核心业务,建议引入缓存降级策略:在缓存不可用或数据异常时自动降级为数据库查询,确保服务可用性。
- 加强缓存监控
-
- 对所有缓存实例进行实时监控,包括慢查询统计、大对象识别、命中率分析、内存使用情况等,及时发现潜在问题,确保系统稳定运行。
温馨提示
缓存是一个大的课题,可以做的事情很多,比如优化、稳定性等。
所谓技无止境,没有最好只有更好。在不同的场景,使用缓存可能会遇到这样那样的问题,还需要选择合适的方式去解决。
/ END /
更多推荐