一、背景
在云基础设施管理中,经常需要将已手动创建的存量资源纳入Terraform的管理体系。Terraform提供的导入块(Import Block) 功能,可实现配置驱动的资源导入,相比传统的terraform import命令,具有以下优势:
- 可预测性:通过配置文件明确记录导入规则,避免命令行操作的随机性;
- 适配CI/CD:支持集成到自动化流水线,便于团队协作和版本控制;
- 预览能力:在执行导入前可通过
plan命令预览操作,降低误操作风险。
资源导入后,Terraform会将其记录在状态文件(state)中,后续可像管理原生Terraform资源一样,进行属性更新、销毁等全生命周期操作。导入块本身可作为资源来源的记录保留在配置中,也可在导入完成后删除。
二、基础语法
导入块可添加到任意Terraform配置文件中(常见做法是创建imports.tf单独管理,或与对应资源块放在一起)。基础语法如下:
ini
import {
to = aws_instance.example # 资源在状态文件中的地址(格式:资源类型.资源名称)
id = "i-abcd1234" # 云平台上的资源实际ID(如AWS实例ID)
# provider = aws.secondary # 可选,指定非默认的 provider 实例
}
# 对应的资源定义块(必须存在,否则导入会失败)
resource "aws_instance" "example" {
name = "hashi"
# 其他资源属性...
}核心参数说明
to:必填,指定资源导入后在Terraform状态中的唯一标识(格式为资源类型.资源名称,若资源有索引需包含索引,如aws_s3_bucket.this["prod"])。id:必填,云平台上的资源实际ID(需与资源类型匹配,如AWS S3桶的ID为桶名称,EC2实例的ID为i-xxxx)。provider:可选,指定用于导入的provider实例(默认使用默认provider)。
三、使用 for_each 导入多个实例
当需要导入批量资源时,可通过for_each参数在单个导入块中实现多实例导入。for_each接收一个集合(映射或列表),通过each.key和each.value迭代生成导入规则,适用于资源名称/ID有规律的场景。
3.1 导入同模块内的多个资源
例如,导入多个S3桶,按环境(staging/uat/prod)区分:
ini
# 定义待导入资源的映射关系(键:资源索引,值:云平台资源ID)
locals {
buckets = {
"staging" = "bucket-staging" # 键将作为资源索引,值为实际桶ID
"uat" = "bucket-uat"
"prod" = "bucket-prod"
}
}
# 批量导入块
import {
for_each = local.buckets # 迭代本地变量中的映射
to = aws_s3_bucket.this[each.key] # 资源地址包含索引(与for_each键对应)
id = each.value # 云平台资源ID(与for_each值对应)
}
# 对应的资源定义(需与导入块的for_each匹配)
resource "aws_s3_bucket" "this" {
for_each = local.buckets # 索引与导入块一致
}3.2 导入跨模块的多个资源
若资源分布在不同子模块中,可通过module.模块名.资源地址指定导入目标:
vbnet
locals {
# 定义跨模块资源的元数据(分组、索引、实际ID)
buckets = [
{ group = "one", key = "bucket1", id = "one-bucket-1" },
{ group = "one", key = "bucket2", id = "one-bucket-2" },
{ group = "two", key = "bucket1", id = "two-bucket-1" },
{ group = "two", key = "bucket2", id = "two-bucket-2" },
]
}
# 跨模块批量导入
import {
for_each = { for b in local.buckets : "${b.group}-${b.key}" => b } # 生成唯一键
id = each.value.id # 云平台资源ID
to = module.group[each.value.group].aws_s3_bucket.this[each.value.key] # 跨模块资源地址
}四、执行导入操作(plan 与 apply)
导入块通过terraform plan和terraform apply完成资源导入,整体流程如下:
-
定义导入块 :明确待导入资源的
to(目标地址)和id(实际ID)。 -
编写资源块 :创建与导入块匹配的
resource块(至少包含资源类型和名称,属性可后续补充)。 -
预览导入计划 :执行
terraform plan,Terraform会检查导入配置的合法性,并提示需补充的资源属性。- 可选参数
-generate-config-out=generated.tf:自动生成资源属性模板,简化配置编写。
- 可选参数
-
执行导入 :确认计划无误后,执行
terraform apply,Terraform会将资源写入状态文件,完成导入。
注意:导入操作是幂等的 ------同一资源若已导入状态文件,再次执行
apply不会重复操作,因此导入块可保留作为记录。
五、实战:导入腾讯云CVM实例
以下以导入腾讯云CVM实例为例,演示完整流程。
5.1 准备工作
- 从腾讯云控制台获取目标CVM实例的
实例ID(如ins-a7zrb4i2)。 - 配置腾讯云Provider(确保已安装对应版本,建议v1.79.3及以上):
ini
# 配置Provider
provider "tencentcloud" {
region = "ap-hongkong" # 实例所在Region
}
terraform {
required_providers {
tencentcloud = {
source = "tencentcloudstack/tencentcloud"
version = "1.79.3"
}
}
}5.2 定义导入块
ini
# 导入块:指定目标资源地址和实例ID
import {
to = tencentcloud_instance.this # 导入后在Terraform中的名称
id = "ins-a7zrb4i2" # 腾讯云CVM实例ID
}5.3 编写资源块(初始版本)
创建与导入块匹配的资源定义(初始可为空,后续根据plan结果补充):
bash
resource "tencentcloud_instance" "this" {
# 暂不填写属性,后续根据plan提示补充
}5.4 预览并完善配置
-
执行
terraform plan,查看缺失的必填属性: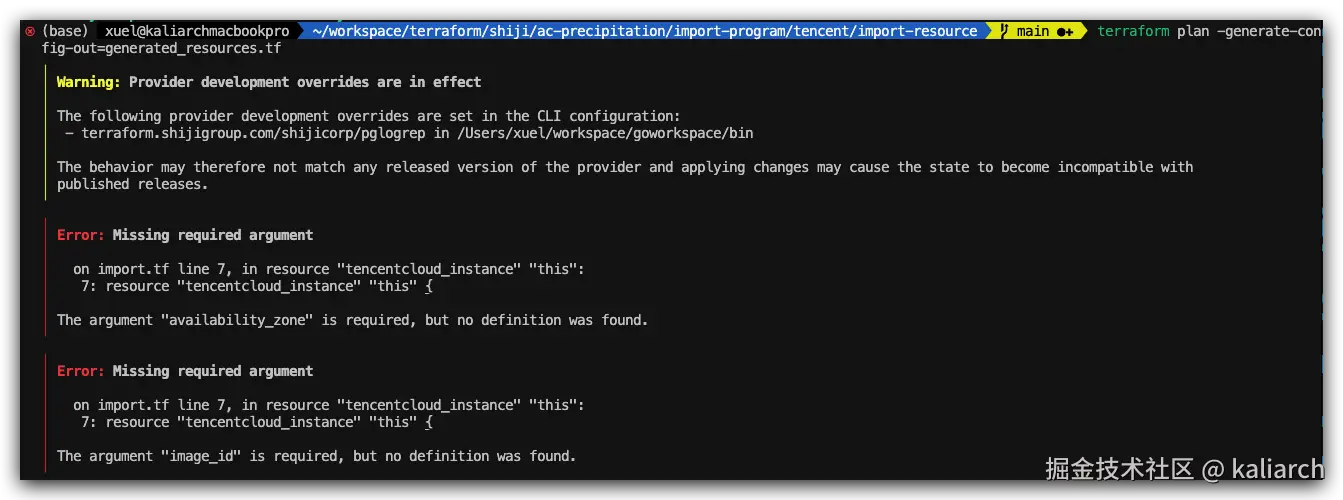 从输出可知,需补充
从输出可知,需补充image_id(镜像ID)和availability_zone(可用区)。 -
补充必填属性后再次执行
plan:iniresource "tencentcloud_instance" "this" { image_id = "img-l8og963d" # 从控制台获取的镜像ID availability_zone = "ap-hongkong-2" # 实例所在可用区 }此时可能提示部分可选属性不匹配(如公网IP、实例名称等),需继续补充:

-
完善所有属性(确保与控制台一致):
iniresource "tencentcloud_instance" "this" { image_id = "img-l8og963d" availability_zone = "ap-hongkong-2" allocate_public_ip = true # 开启公网IP(与实例实际配置一致) instance_name = "tf-vault-server-dev" # 实例名称 system_disk_type = "CLOUD_BSSD" # 系统盘类型 tags = { "tagkey" = "xuel_tf_20240110" # 标签(与实例实际标签一致) } }
5.5 执行导入
- 再次执行
terraform plan,确认无资源重建风险(输出"Import will read existing resource"):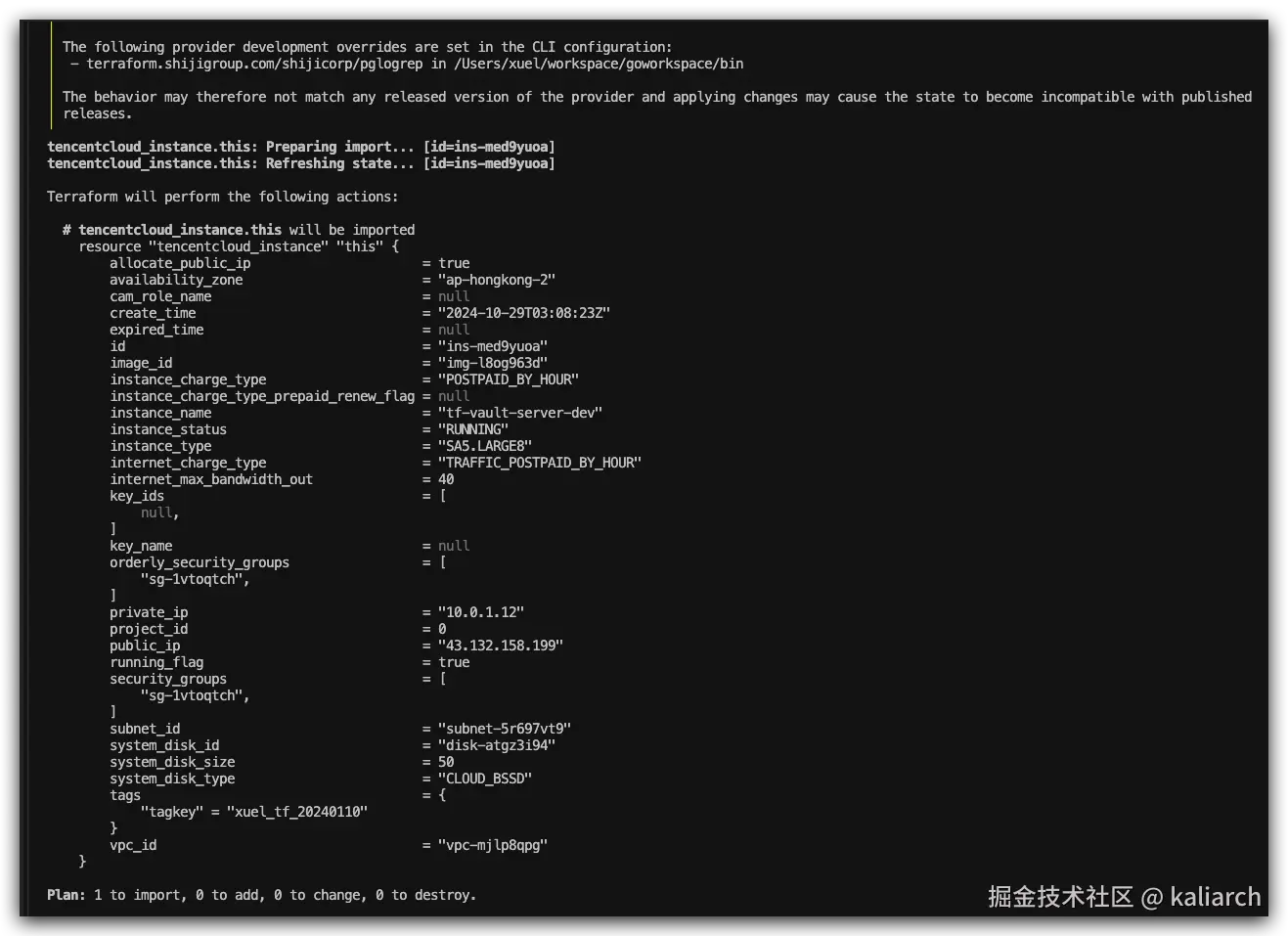
- 执行
terraform apply -auto-approve完成导入: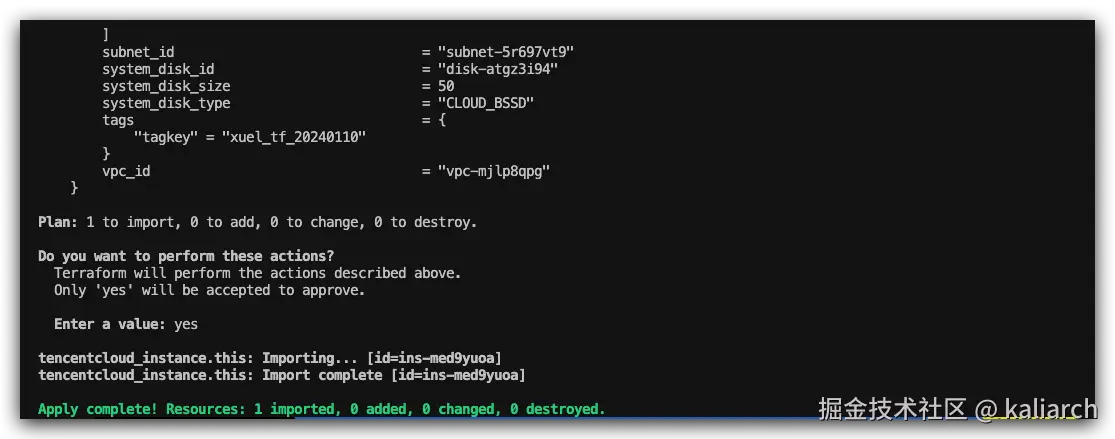
- 验证结果:查看状态文件(
terraform.tfstate),确认实例已被记录: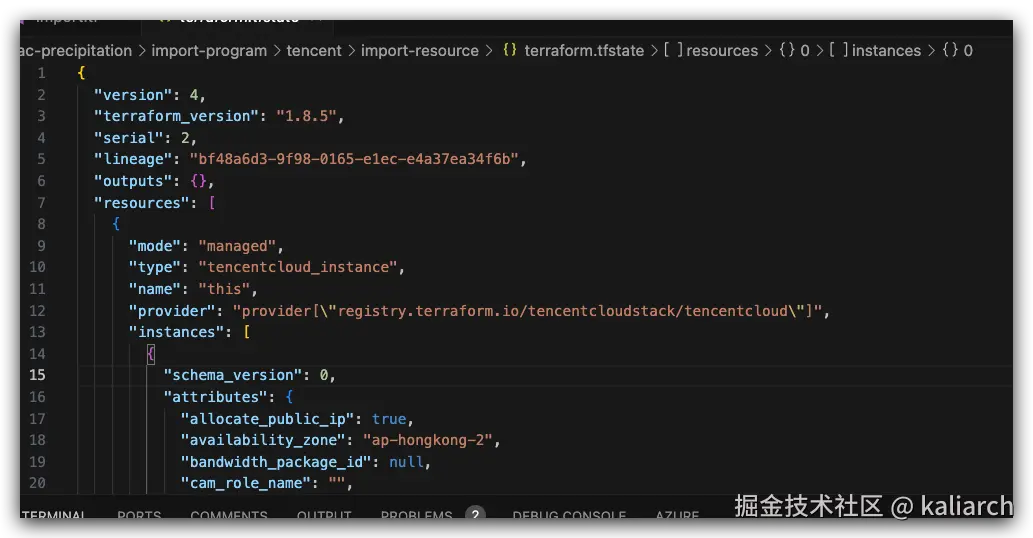
- (可选)删除导入块:由于导入是幂等的,后续可删除导入块,直接通过资源块管理实例。
六、注意事项
- 版本要求:导入块仅在Terraform v1.5.0及以上版本支持,使用前需确认版本兼容性。
- 资源块必须存在 :导入块依赖对应的
resource块,若未定义会导致plan失败。 - 属性一致性 :导入后需确保资源块属性与云平台实际配置一致,否则
plan会提示"变更"(可能触发资源重建)。 - 幂等性保障:同一资源多次导入不会重复操作,可安全保留导入块作为配置记录。