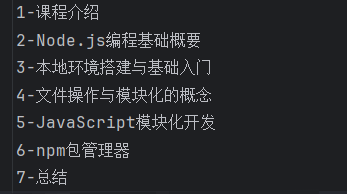
有时候在B站学习,编写学习笔记时,视频的分P数比较多,如下所示:

批量获取B站标题作为笔记的标题,可以大大提升编写笔记的效率,此时可以使用如下脚本获取标题:
python
import urllib
import urllib.request
import re
# 发送请求并返回获取到的HTML数据(字符串)
def get_html(url):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75'}
# 使用传入的url创建一个请求
request = urllib.request.Request(url, headers=header)
# 发送请求并得到响应
response = urllib.request.urlopen(request)
# 获取通过utf-8格式解码后的HTML数据
HTML = response.read().decode('utf-8')
# 返回HTML数据
return HTML
# 将数据保存到文件
def save_titles(data):
file = open('标题.txt', 'w')
for i, title in enumerate(data):
file.write(title)
file.write('\n')
print(f'第{i}个标题写入成功!')
file.close()
# 从HTML数据中匹配出所有标题
def get_titles(html):
# 通过正则表达式创建一个正则匹配模式
pattern = re.compile('<div class="title-txt">(.*?)</div>')
# 得到所有匹配结果,findall的返回值类型为列表
titles = re.findall(pattern, html)
# 返回所有标题内容
return titles
# 发送请求并获取数据
html = get_html('https://www.bilibili.com/video/xxx')# 此处替换为希望获取标题的视频链接
# 匹配出我们需要的数据
titles = get_titles(html)
# 将数据保存到本地
save_titles(titles)
# 暂停一下
pause = input('任意键退出')将脚本中get_html函数的参数替换为希望获取标题的视频链接,运行脚本,即可生成标题.txt: