一、序
MMKV是腾讯开发的高性能移动端键值存储框架,目前被广泛应用在各类产品中。
最近心血来潮提了一个PR,虽然最终没有合入,但在此过程中也有所收获,于是和大家做一下分享。
在进入正题之前,先来一段历史回顾:
- 在2017年时腾讯发表了 微信终端跨平台组件 mars 系列(一):高性能日志模块xlog 这篇文章,那时候我就意识到 mmap api 在小文件存储上有挖掘潜力;
- 2018年3月,文章 基于 mmap 的 iOS 高性能通用 key-value 组件 发布,但彼时尚未开源,并且文章说的是iOS key-value 组件 。
- 于是我就不等其开源了,利用周末时间开发了一个Android平台的key-value组件(2018年6月):LightKV-高性能key-value存储组件。
- 同年11月,MMKV开源了,是一个跨平台的库,有腾讯和微信背书,MMKV很快就火了。
- 后来我看到社区有人说MMKV可能会有"数据丢失(整个文件)"的情况,于是去研究其代码,发现确实存在可能导致文件损坏的地方;
翻阅其issue列表,确实已经有人反馈过了:MMKV Discussions #1001, 但作者并不是很认可此问题,也就没有去解决,并且将issue转成discussion; - 三人行,必有我师。回过头来看LightKV, 虽然说没有MMKV的那个问题,但是也有不少设计不周的地方。于是,在2021年,我在综合了此前的经验和思考之后,另起炉灶实现了FastKV ,该库实现了效率和完整性的兼顾。
- MMKV的那个问题,解决的方向是有的,但是此前没有足够的动力去动手实现,直到最近,从动机到条件我感觉都差不多了,于是抽了点时间去实现,并提了PR:PR #1564。
该PR最终没有合入:并非没有解决问题,而是作者的其他一些考虑(留后面细说)。
好了,故事讲完了,我们来开始正题,先简单地从MMKV的原理说起。
二、MMKV实现原理
2.1 双文件架构设计
MMKV采用双文件架构,实现数据与元信息的分离:
arduino
MMKV存储架构
├── 主数据文件 (.mmkv)
│ ├── [0-4字节] actualSize (数据实际大小)
│ └── [4字节-actualSize] 键值对数据
│ └── [actualSize-末尾] 空闲空间
└── 元数据文件 (.crc)
└── MMKVMetaInfo结构 (完整定义)
├── uint32_t m_crcDigest // CRC校验和
├── uint32_t m_version // 版本信息
├── uint32_t m_sequence // 序列号(全量写回计数)
├── uint8_t m_vector[16] // AES加密向量
├── uint32_t m_actualSize // 数据实际大小
├── m_lastConfirmedMetaInfo结构 // 已确认的元信息
│ ├── uint32_t lastActualSize // 上次确认的数据大小
│ ├── uint32_t lastCRCDigest // 上次确认的CRC
│ └── uint32_t _reserved[16] // 预留字段
├── uint64_t m_flags // 扩展标志位
└── ... // 空闲空间元数据文件目前为固定一个page size(通常为4K,也有可能为16K,由平台决定)。
- 主数据文件格式 (.mmkv)
scss
┌─────────────────┬─────────────────────────────────────────┐
│ actualSize │ protobuf数据 │
│ (4字节) │ 键值对序列化数据 │
│ Fixed32Size │ [key1|value1|key2|value2|...] │
└─────────────────┴─────────────────────────────────────────┘- 元数据文件格式 (.crc)
scss
┌─────────────────────────────────────────────────────────────┐
│ MMKVMetaInfo (~400字节) │
├─────────────┬─────────────┬─────────────┬─────────────┬─────┤
│ m_crcDigest│ m_version │ m_sequence │ m_vector │ ... │
│ (4字节) │ (4字节) │ (4字节) │ (16字节) │ │
│ CRC校验 │ 版本号 │ 序列号 │ AES IV │ │
└─────────────┴─────────────┴─────────────┴─────────────┴─────┘
│ m_lastConfirmedMetaInfo │
│ 确认的元信息备份 │
├─────────────────────────────────────────────────────────────┤
│ m_flag │
│ 扩展标志位 │
└─────────────────────────────────────────────────────────────┘2.2 mmap技术要点
MMKV的高性能基础之一,来自于其使用 mmap(内存映射)来写入数据:
cpp
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);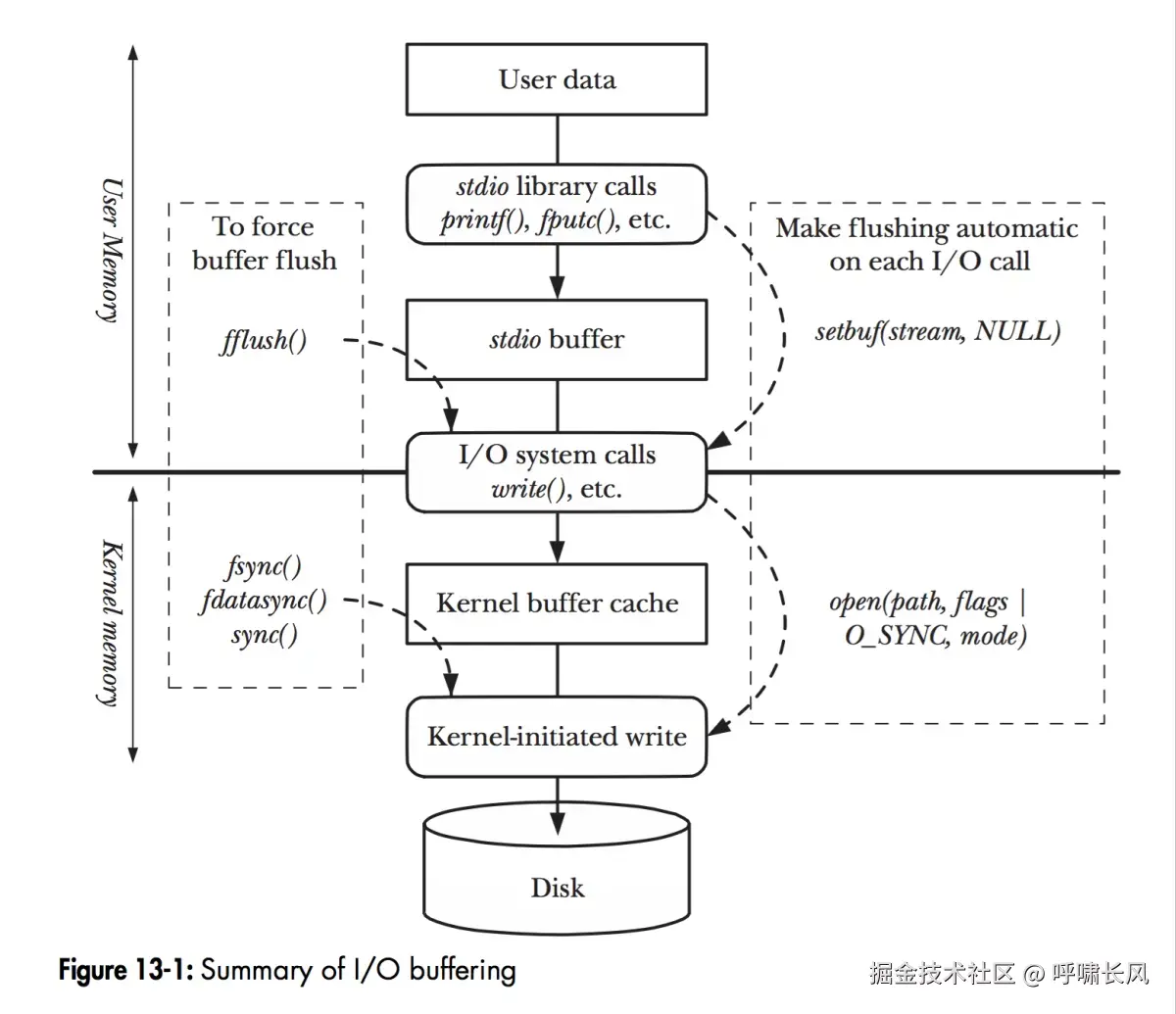
常规的 fwrite() 调用,仅会将数据写入到用户缓存 ,需要再调用 fflush 才能将数据写到内核缓存。
而 mmap 则是直接将内核缓存的地址返回给调用者。
对于离散的写入(客户端常见场景),每次写入调用都 fwrite()+ fflush的话,这些都是系统调用;而mmap 则是一次系统调用之后,获取到内核缓存的地址,然后可以在该段内存内随机读写。
如果仅仅是节约系统调用而已的话,mmkv并不足以在写入效率上和常规的 SharePreferences(Android)、NSUserDefaults(iOS)的拉开大的差距。
- 拉开差距的原因,是MMKV的"key-value"更新,在"空闲空间"足够的情况下,仅涉及写内存,而不涉及
fsync; MMKV仅当"空闲空间"不足,需要扩容或重整内存时,才会涉及元数据文件的fsync; - 而SharePreferences等则是每次提交数据都会经历
fwrite()+fflush+fsync(虽然apply模式会将这些操作放在后台线程,但是由于其他一些实现设计,也会影响其写入的调用效率------这部分不是本文的主题,这里就不多做展开了)。 fsync不是一个简单的系统调用,其调用会阻塞当前线程,直到数据写入磁盘(慢操作)。
这里涉及到一个"数据安全 "和"性能 "的折衷,而MMKV选择了"性能"。
其选择也是有所考虑的:当数据写入到内核缓存,后续操作系统会定时处理脏页回写,即使用户进程崩溃,也不影响。
那写入到内核缓存就是万事大吉了吗?不完全是。
操作系统会定时将脏页写盘没错,但是在定时周期内系统崩溃了或者设备断电了,那就写不成了。
但这并不是最致命的问题 :如今操作系统已经比较成熟了,系统崩溃的情况比较少见,电池用到没电也是偶发事件,而"系统崩溃等事件的同时有脏页待写"的概率会更低。
真正的问题,是前面提到的 MMKV Discussions #1001 所描述的情况,这个我们留到后面分析。
2.3 数据操作流程
2.3.1 数据写入流程
2.3.2 数据读取流程
2.4 内存缓存机制
MMKV核心数据结构:
cpp
// key-value节点信息
struct KeyValueHolder {
uint16_t computedKVSize; // internal use only
uint16_t keySize;
uint32_t valueSize;
uint32_t offset;
KeyValueHolder() = default;
KeyValueHolder(uint32_t keyLength, uint32_t valueLength, uint32_t offset);
MMBuffer toMMBuffer(const void *basePtr) const;
};
// KeyValueHolderCrypt 要更加复杂一些,这里省略
// 定义类型别名
using MMKVMap = std::unordered_map<std::string, mmkv::KeyValueHolder, KeyHasher, KeyEqualer>;
using MMKVMapCrypt = std::unordered_map<std::string, mmkv::KeyValueHolderCrypt, KeyHasher, KeyEqualer>;
// MMKV核心数据
class MMKV {
MMKVMap *m_dic; // 普通模式的内存缓存
MMKVMapCrypt *m_dicCrypt; // 加密模式的内存缓存
CodedOutputData *m_output; // 输出编码器
MMKVMetaInfo *m_metaInfo; // 元信息
uint32_t m_crcDigest; // 增量CRC
size_t m_actualSize; // 实际数据大小
bool m_needLoadFromFile; // 延迟加载标记
};- 用字典(
std::unordered_map) 保存key-value索引:key为std::string, value为KeyValueHolder。 - 加载时仅读取数据位置和大小信息(保存到KeyValueHolder), 访问时(
decode)实时解析成对应类型后返回。 - MMKV的value编码(
encode)并不保存数据的"类型"信息,将数据解析成何种类型取决于decode时的类型信息:如果encode/decode的类型不匹配,可能会读到错误的数据。
2.5 写入机制详解
MMKV采用两种主要的写入策略来处理不同场景的数据更新:
2.5.1 普通写入 (appendDataWithKey/overrideDataWithKey)
用于单个键值对的增量更新:
cpp
// 追加写入新数据到文件末尾
bool MMKV::appendDataWithKey(const MMBuffer &data, MMKVKey_t key) {
// 1. 编码键值对数据
auto encodedData = MiniPBCoder::encodeDataWithObject(data);
// 2. 检查空间是否足够
if (encodedData.length() + m_actualSize > m_file->getFileSize()) {
return expandAndWriteBack(newSize, preparedData);
}
// 3. 写入到mmap内存
m_output->writeData(encodedData);
// 4. 更新元信息和CRC
updateCRCDigest(encodedData.getPtr(), encodedData.length());
writeActualSize(m_actualSize, m_crcDigest, nullptr, false);
return true;
}2.5.2 全量写回 (doFullWriteBack)
当需要整理文件空间或处理大量数据变更时触发:
触发条件:
- 空间不足需要扩展文件时
- 删除大量数据后的空间整理
- 键过期清理后的数据重组
- 加密密钥变更时的数据重写
核心流程:
cpp
bool MMKV::doFullWriteBack(pair<MMBuffer, size_t> prepared, AESCrypt *newCrypter) {
auto ptr = (uint8_t *) m_file->getMemory();
auto totalSize = prepared.second;
// 1. 准备输出编码器 (跳过4字节的actualSize头部)
delete m_output;
m_output = new CodedOutputData(ptr + Fixed32Size, m_file->getFileSize() - Fixed32Size);
// 2. 处理加密场景
if (newCrypter) {
uint8_t newIV[AES_KEY_LEN];
AESCrypt::fillRandomIV(newIV);
newCrypter->resetIV(newIV, sizeof(newIV));
}
// 3. 数据移动和重组 (关键的WriteBack操作)
if (m_crypter) {
memmoveDictionary(*m_dicCrypt, m_output, ptr, decrypter, encrypter, prepared);
} else {
if (prepared.first.length() != 0) {
fullWriteBackWholeData(std::move(preparedData), totalSize, m_output);
} else {
memmoveDictionary(*m_dic, m_output, ptr, encrypter, totalSize);
}
}
// 4. 更新文件状态
m_actualSize = totalSize;
recalculateCRCDigestWithIV(newIV);
m_hasFullWriteback = true;
return true;
}三、 WriteBack数据损坏问题
前面我们提到,系统崩溃/设备断电等情况比较少见;
但是进程意外退出(进程崩溃、系统进程回收、用户清理进程 )的情况还是比较常见的:MMKV在 MMKV Discussions #1001 所描述的过程中发生进程意外退出,会导致文件损坏。
问题根因分析
- 内存整理阶段:需要移动大量数据块(memmove操作)
- 就地更新风险:在同一文件内进行数据移动
- 原子性缺失:操作过程中进程崩溃会导致部分写入
在数据整理过程中,memmoveDictionary需要在同一文件内移动数据:
cpp
void MMKV::memmoveDictionary(MMKVMap &dic, CodedOutputData *output, uint8_t *ptr,
AESCrypt *encrypter, size_t totalSize) {
// 遍历所有键值对,重新编码并移动到文件前部
for (auto §ion : dataSections) {
// 关键问题:这里原地操作内核缓存(writePtr指向的内存)
memmove(writePtr, basePtr + section.first, section.second);
writePtr += section.second;
}
}典型的损坏场景:
css
原始文件:[Header][Data1][Garbage][Data2][...]
整理中: [Header][Data1][Da...] ← 进程崩溃
结果: 文件损坏,数据丢失四、 WriteBack保护解决方案
4.1 设计思路
基于"先备份,后操作,再清理"的原子操作思想:
- 备份阶段 :将要移动的数据备份到
metaFile,并记录备份的元数据 - 操作阶段 :将有效数据的
memcpy到主文件 - 清理阶段:操作成功后清理备份数据
- 恢复机制:启动时检测备份,如果存在有效的备份数据,先执行恢复,再继续剩余流程
4.2 元数据文件扩展
为了支持WriteBack保护,我们对原有的元数据文件进行了扩展:
scss
扩展后的元数据文件 (.crc)
├── MMKVMetaInfo结构 (~400字节)
│ ├── 原有字段
│ │ ├── CRC校验和
│ │ ├── 版本信息
│ │ ├── 序列号 (多进程同步)
│ │ ├── 加密向量 (AES IV)
│ │ └── 扩展标志位
│ └── 新增WriteBack保护字段
│ └── MMKVBackupInfo m_backupInfo
│ ├── m_magic (备份魔数)
│ ├── m_restorePoint (恢复位置)
│ ├── m_backupDataSize (备份大小)
│ └── m_restoredFileCRC (目标CRC)
└── WriteBack保护备份数据区域 (动态大小)
└── 实际的备份数据内容
cpp
struct MMKVBackupInfo {
uint32_t m_magic = 0; // 备份有效性标识
uint32_t m_restorePoint = 0; // 恢复点位置
uint32_t m_backupDataSize = 0; // 备份数据大小
uint32_t m_restoredFileCRC = 0; // 恢复后文件CRC
bool hasData() const {
return m_magic == MMKV_BACKUP_MAGIC && m_backupDataSize > 0;
}
void update(uint32_t restorePoint, uint32_t backupDataSize, uint32_t restoredFileCRC) {
m_magic = MMKV_BACKUP_MAGIC;
m_restorePoint = restorePoint;
m_backupDataSize = backupDataSize;
m_restoredFileCRC = restoredFileCRC;
}
};这种设计的考虑:
- 复用现有架构:无需额外文件,复用元数据文件
- 原子性保证:备份信息与备份数据在同一文件中
- 向后兼容:老版本忽略扩展字段,不影响基本功能
- 动态扩展:根据需要动态分配备份空间
4.3 保护流程实现
cpp
uint8_t* MMKV::memmoveSectionsWithBackup(
const std::vector<std::pair<uint32_t, uint32_t>>& dataSections,
uint8_t* writePtr, uint8_t* basePtr) {
// 1. 计算需要移动的数据大小
uint32_t dataToMove = 0;
for (const auto& section : dataSections) {
dataToMove += section.second;
}
// 2. 备份数据到metaFile
bool backupSuccess = backupDataToMetaFile(dataSections, dataToMove, restorePoint);
// 3. 执行数据移动
if (backupSuccess) {
memcpy(writePtr, backupBuffer, dataToMove);
writePtr += dataToMove;
// 4. 清理备份
clearMetaFileBackup();
}
return writePtr;
}4.4 恢复机制
cpp
void MMKV::loadFromFile() {
loadMetaInfoAndCheck();
// check for writeback protection backup and attempt recovery if needed
if (m_metaInfo->m_backupInfo.hasData()) {
if (restoreDataFromMetaFile()) {
MMKVInfo("successfully recovered writeback protection backup for [%s]", m_mmapID.c_str());
} else {
clearMetaFileBackup();
}
}
// ... 其余加载流程
}
bool MMKV::restoreDataFromMetaFile() {
auto& backupInfo = m_metaInfo->m_backupInfo;
// 1. CRC验证
uint32_t expectedCRC = calculateExpectedCRC(backupInfo);
if (expectedCRC != backupInfo.m_restoredFileCRC) {
return false;
}
// 2. 恢复数据
memcpy(mainPtr + backupInfo.m_restorePoint, backupPtr, backupInfo.m_backupDataSize);
// 3. 更新文件状态
m_actualSize = backupInfo.m_restorePoint + backupInfo.m_backupDataSize;
writeActualSize(m_actualSize, backupInfo.m_restoredFileCRC, iv, KeepSequence);
// 4. 清理备份
clearMetaFileBackup();
return true;
}4.5 带WriteBack保护的完整数据流程
- 写入流程(带保护)
- 读取流程(带恢复)
五、 PR #1564讨论过程记录
5.1 初始提交
今年7月,我提交了PR #1564,包含:
- 核心实现:WriteBack保护机制,支持CRC验证和恢复
- 跨平台支持:Android、iOS、HarmonyOS、Flutter、Python、Golang全平台API
- 测试覆盖:包含正常操作和故障模拟的完整测试
5.2 初步讨论
作者的主要关切:
"这个新的保护机制引入了显著的复杂性和潜在的性能开销,可能与项目的目标不符。'双写'策略可能导致MetaFile增长到接近整个键值存储的大小,使msync()调用变得昂贵。这种权衡似乎与MMKV优先考虑极致效率和性能的核心理念相冲突。"
对于作者的关切,我提出了两个备选方案:
选项1:限制备份策略
- 限制备份数据大小不超过pageSize(~4KB)
- 利用MetaFile的空闲空间避免额外存储成本
- 大数据时降级为收集+统一memcpy策略
选项2:最小开销策略
- 不再写到备份文件,仅将有效数据收集到临时缓存,然后统一写到磁盘
我的考虑是:
- 元数据大小目前仅占用不到200字节,而元数据文件至少有4K,剩余空间可用于做备份;
- 客户端的KV数据通常是轻量级数据,大部分存储实例小于4K(尤其是按用户、业务区分实例的实现);
- 通常情况下,"冷数据"位于主文件前部,"热数据"位于文件尾部,所以做内存整理时,通常只需要移动尾部的数据,有较大概率小于pageSize;
- 即使不做备份/恢复,仅仅是将"有效数据收集到临时缓存,然后统一写到磁盘"也能降低进程退出导致文件损坏的概率。
5.3 进一步讨论
作者对于备份方案的回复:
最初,MMKV 会计算待 WriteBack 的数据,然后执行
memcpy()。这本质上与选项 1 或整个选项 2 中的回退解决方案相同。
当前
memmove()的实现是为了加快 WriteBack过程并减少内存占用 。我认为没有理由回滚到旧方法。
我提出:
- 相对于"旧方法",关键区别在于,选项 1 提供选择性原子保护,并举例说明了SQLite实现原子性写入的方式。
- "先收集,然后统一写入",在非加密的模式下可能和直接memmove差不多快,但是加密模式下由于涉及加解密,会增加漏洞窗口。
作者进一步回复:
- 缩小该窗口的解决方案,它只会使需要加密的子集用户受益,为此而增加一个开关,不划算;
- 至于解决方案 1,只能保护数据少或更新少的实例,写入数据超过此小阈值的用例,还是会遇到问题;
- SQLite 是一个成熟的事务型数据库,其设计核心原则是遵循 ACID。相比之下,MMKV 则旨在设计为轻量级、高性能的键值存储,优先考虑速度和最小的内存占用。
于是我提出可以提供一个分级保护选项:
创建一个 setWriteBackStrategy(strategy) 接口, 提供三个选项,而不是二元的启用/禁用选项:
STRATEGY_MEMMOVE_INPLACE(默认)- 当前主实现STRATEGY_CONDITIONAL_BACKUP- 仅当数据 < (pageSize - sizeof(MMKVMetaInfo)) 时备份STRATEGY_FULL_BACKUP- 无论大小始终备份
并引述了 Discussion#1001 中某个用户提出的观点:
"I can still see cases where data integrity is more important than performance(...), and you can leave the decision to the developer"
作者提出:
- STRATEGY_CONDITIONAL_BACKUP:正如我们所讨论的,这会增加解决最不关键问题的复杂性。它保护风险窗口本来就很小的小型写入操作,而较大、高风险的操作则不受保护。
- STRATEGY_FULL_BACKUP:由于"双重写入"开销,此选项从根本上与 MMKV 的性能优先理念相冲突,这会使 msync() 的成本过高。
- 我们应该寻找一个本质上安全高效的解决方案,而不是让用户在两者之间做出选择。
提供太多的"妥协性选项",确实不好,于是我提出还是回到"启用/禁用选项",当启用保护时,元数据仅sync 前面的 sizeof(MMKVMetaInfo) 字节:
scss
if (m_enableWriteBackProtection) {
// Only sync the essential MMKVMetaInfo, not the entire meta file
msync(m_metaFile->getMemory(), sizeof(MMKVMetaInfo), MMKV_SYNC);
} else {
// Keep original logic
m_metaFile->msync(MMKV_SYNC);
}此方案:
- 对所有 WriteBack 操作保持完全保护,无论其大小
- 保持简单的接口:只需启用/禁用,无需策略复杂性
- 仅同步元数据而不同步备份数据,既消除昂贵的全文件
msync(),同时依旧能有效防止进程意外退出而损坏数据。
作者回复:
这种更新的方法确实减少了同步整个 MetaFile 所需的时间。然而,它并没有降低复杂度或内存占用。
事实上,任何备份/恢复机制都会带来一些"复杂性",这是无法避免的。 而对于"内存占用",我继续提出了优化方案:
- 先将有效数据备份到元数据文件,然后再写回主文件;
- 如此,既消除了"临时缓存"的创建/销毁,也保持了原子写入能力。
作者回复:
这种新方法确实消除了临时缓冲区的内存占用。然而,MetaFile 本身与整个键值对一样大,这实际上使内存占用增加了一倍。
正当我要提出可以考虑"截断、重新映射"等方式消除 MetaFile 的内存占用时,作者先回复了:
- 我们应该量化有多少比例的损坏事件是由这个特定阶段的中断直接引起的;
- 假设数据确认
WriteBack是主要问题,我建议我们完全摒弃备份-恢复模式。讨论表明,这种模式会迫使我们在性能、复杂性和安全性之间做出不利的权衡。
由于客观因素,我没有条件去做这种"量化"(事实上这种量化MMKV团队自己去统计会比较合适)。
我认为要想确保原子性,必然需要某种形式的暂存机制,或许存在某种简化的"备份-恢复"模式,然后我又尝试了"分段"执行memmove并每次执行前做"分段"的备份,但这样实现"复杂度"会飙升,是很不划算的。 最终,我坦言当前讨论到的方案已是我想要的最优方案了。
5.4 结果
最终的结果是:PR没有合入。
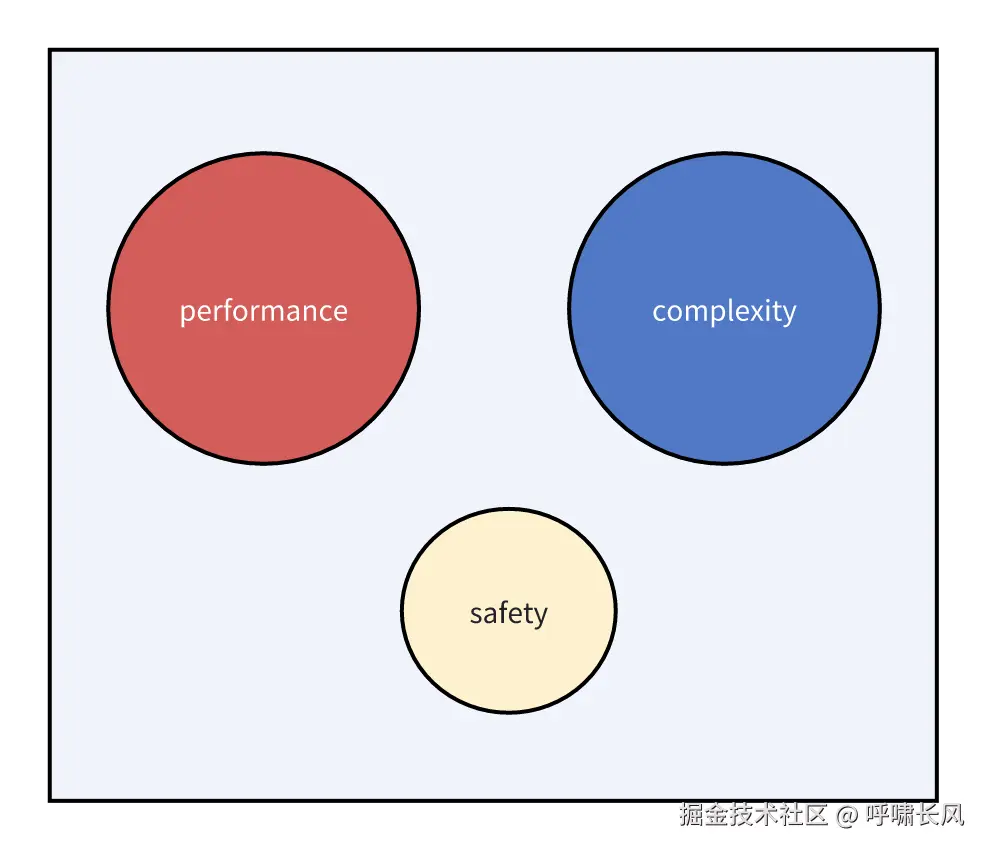
作者强调:我们的主要目标是是坚持MMKV的
core philosophy,当前提出的方案,引入了性能和复杂性的权衡,我们认为目前最好避免这种情况。
在MMKV的核心理念中,性能和复杂性优先级于安全性。
六、实现优化
PR未能合入的原因,不是因为没有解决问题,而是解决问题引入的复杂性,与MMKV的设计哲学相悖。
我个人的理念,引入可控的复杂性来实现数据的安全性是值得的。
因此,我继续在folk的仓库中,基于PR讨论的反馈,实现了两个关键优化:
- 直接使用metaFile缓冲区:避免临时内存分配
- 部分metaFile同步:只同步必要的元信息部分
同时,基于数据完整性优先的观点,将WriteBack保护设为默认启用:
cpp
// MMKV.h
class MMKV {
bool m_enableWriteBackProtection = true; // 默认启用
};这样用户默认就能保护数据完整性,无需对每个实例额外调用 enable 接口来启用保护机制。
6.1 直接使用metaFile缓冲区
原实现问题:
cpp
// 创建临时缓冲区 + 扩展metaFile = 双重内存占用
auto tempBufferHolder = std::make_unique<uint8_t[]>(dataToMove);
auto tempBuffer = tempBufferHolder.get();
// 收集数据到临时缓冲区...
backupDataToMetaFile(tempBuffer, dataToMove, restorePoint);优化后实现:
cpp
uint8_t* MMKV::memmoveSectionsWithBackup(...) {
// 1. 确保metaFile有足够空间
auto requiredSize = sizeof(MMKVMetaInfo) + dataToMove;
if (!ensureMetaFileSize(requiredSize)) {
// fallback处理...
return writePtr;
}
// 2. 直接使用metaFile内存作为缓冲区
auto metaBuffer = (uint8_t*)m_metaFile->getMemory() + sizeof(MMKVMetaInfo);
// 3. 直接在metaFile中收集数据
auto bufferPtr = metaBuffer;
for (const auto& section : dataSections) {
memcpy(bufferPtr, basePtr + section.first, section.second);
bufferPtr += section.second;
}
// 4. 记录备份信息
m_metaInfo->m_backupInfo.update(restorePoint, dataToMove, restoredFileCRC);
m_metaInfo->writeBackupInfoOnly(m_metaFile->getMemory());
// 5. 从metaFile拷贝到目标位置
memcpy(writePtr, metaBuffer, dataToMove);
writePtr += dataToMove;
// 6. 清理备份
clearMetaFileBackup();
return writePtr;
}内存占用优化效果:
- 避免双重内存占用(临时buffer + metaFile扩展)
- 最大可节省50%内存占用
- 减少一次内存分配/释放操作
6.2 同步部分metaFile
原问题: PR讨论中指出,metaFile可能因为备份数据变得很大,同步整个文件会有性能开销。
解决方案:
- 新增msyncRange方法:
cpp
// MemoryFile.h
class MemoryFile {
bool msyncRange(size_t offset, size_t length, SyncFlag syncFlag);
};
// MemoryFile.cpp
bool MemoryFile::msyncRange(size_t offset, size_t length, SyncFlag syncFlag) {
// 边界检查
if (offset >= m_size) return false;
size_t actualLength = std::min(length, m_size - offset);
// 只同步指定范围
auto ret = ::msync(static_cast<uint8_t*>(m_ptr) + offset, actualLength,
syncFlag ? MS_SYNC : MS_ASYNC);
return ret == 0;
}性能优化效果:
- 同步数据降至固定200字节
- 大幅减少潜在的
msync()系统调用开销 - 避免不必要的磁盘I/O
七、总结
虽然PR最终没有合入,但是也算有所收获 ------ 在这个探索的过程中,学习到一些新的知识和经验。
写这篇文章的目标:
- 给需要数据完整性保障的系统提供一些参考;
- 抛砖引玉,希望有喜欢挑战的读者,能进一步提出更好的解决方案。
这里附上我folk的仓库的地址:github.com/BillyWei01/... ,以供参考。