**摘要:**SelectDB是一款基于Apache Doris的新一代实时数据仓库解决方案,具备实时极速、融合统一、弹性架构和开放生态四大核心特性。它采用云原生存算分离架构,支持秒级数据更新、毫秒级查询响应,在TPC-H等基准测试中性能超越传统系统3-5倍。SelectDB提供两款产品:SelectDB Cloud(全托管SaaS)和SelectDB Enterprise(私有化部署),支持多数据源接入、联邦查询和冷热数据分层存储,存储成本可降低90%。在日志分析、用户画像等场景中,SelectDB相比Elasticsearch实现查询性能提升2-4倍、存储成本降低70%。其兼容MySQL协议的特性降低了使用门槛,帮助企业快速构建实时数据分析平台。
一、引言
在大数据时代,数据量呈爆炸式增长,企业和组织对于实时数据分析的需求也日益迫切。无论是金融行业的实时风控、互联网行业的用户行为分析,还是零售行业的销售趋势预测,都依赖于高效、准确的实时数据分析。传统的数据仓库技术在面对海量数据和复杂查询时,往往显得力不从心,难以满足实时性和性能的要求。因此,新一代实时数据仓库应运而生,SelectDB 就是其中的佼佼者。
SelectDB 作为一款创新的实时数据仓库解决方案,融合了先进的技术架构和强大的功能特性,为用户提供了卓越的实时数据分析体验。它能够快速处理大规模数据,实现秒级甚至毫秒级的查询响应,帮助企业及时获取有价值的信息,做出明智的决策。接下来,让我们深入了解 SelectDB 的技术内幕、应用场景以及实际案例,揭开它在实时数据分析领域的神秘面纱。
二、SelectDB 是什么
selectDB官网:https://www.selectdb.com/
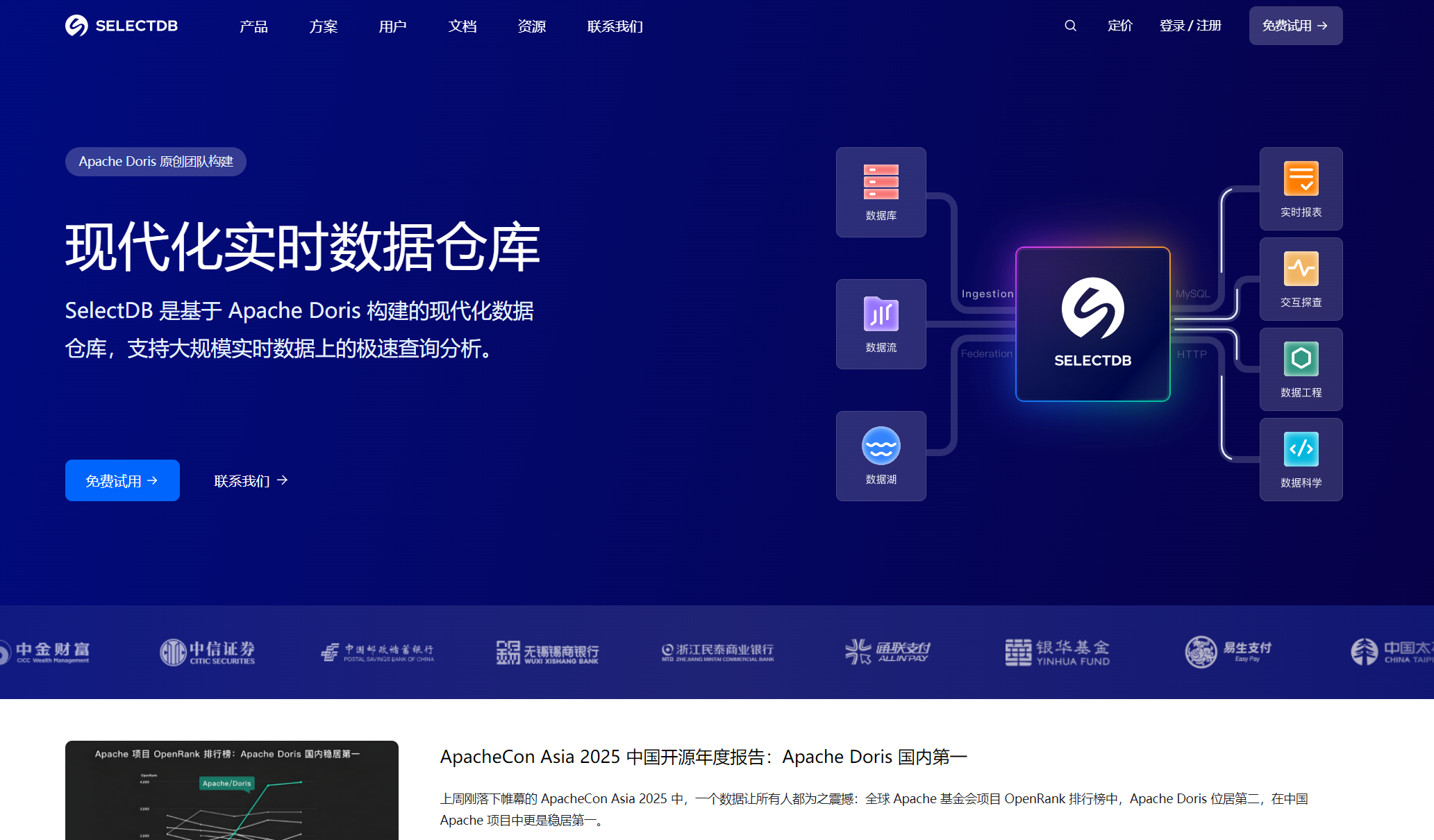
SelectDB 是北京飞轮科技有限公司基于 Apache Doris 项目开发的新一代实时数据仓库 ,具备实时性、云原生、开源等特点。它采用了先进的云原生存算分离架构,这种架构模式将计算资源和存储资源分开管理,充分发挥了云计算平台的强大功能,比如计算集群可以根据工作负载的高低峰运行时段、作业执行规律,灵活配置不同规模的计算资源,实现弹性伸缩。同时,在存储方面支持冷热存储分层,将全量数据存储到成本更低且极其可靠的共享存储中,热数据仅在本地 Cache,相比存算一体三副本,存储成本最高下降至原先的 1/10。
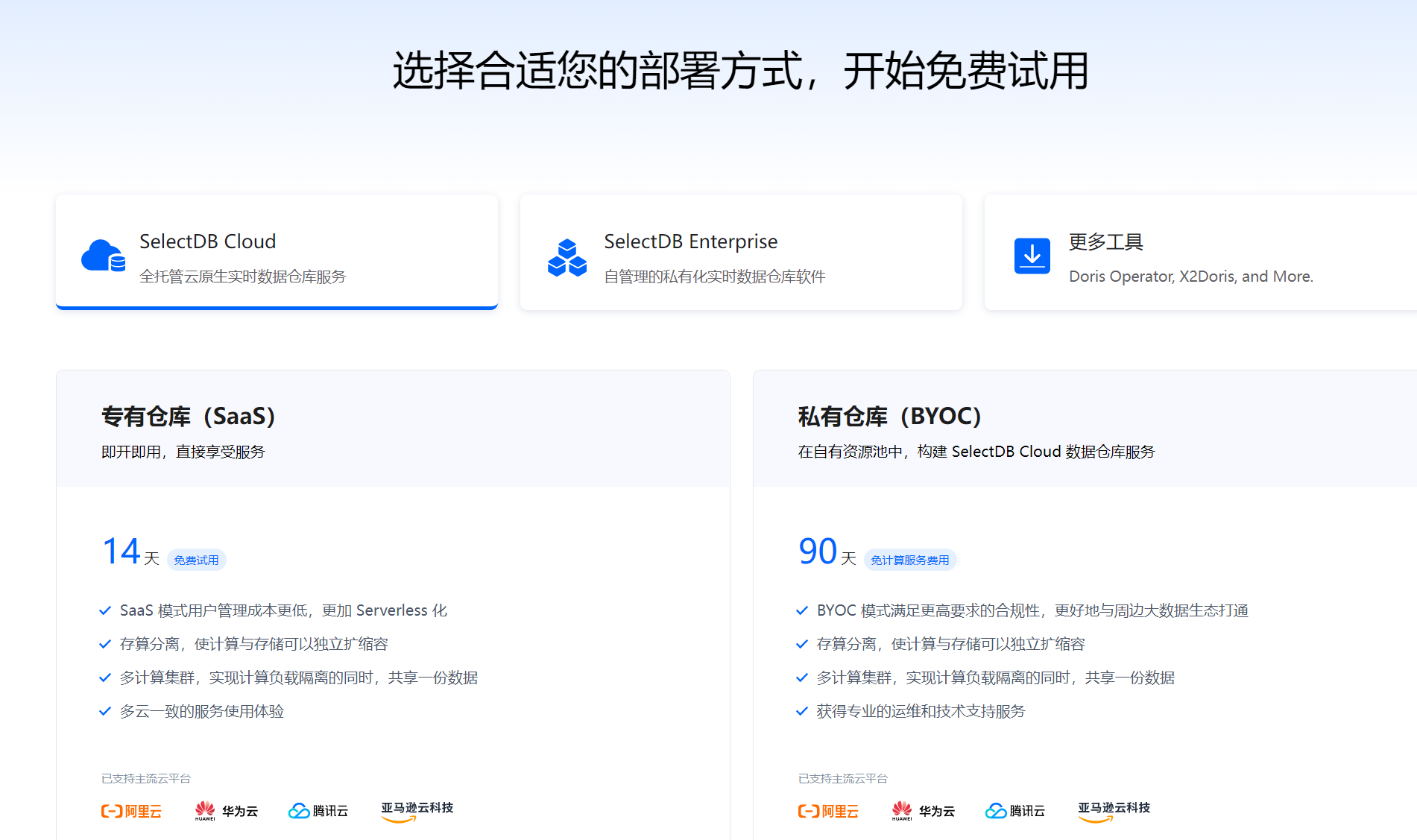
SelectDB 主要有两款企业级产品,分别为 SelectDB Cloud 和 SelectDB Enterprise,能够差异化地满足来自云上和私有化部署用户的不同需求。其中,SelectDB Cloud 采用云原生存算分离架构、全托管 SaaS 化产品形态,公有云交付,一键部署,作为首款多云中立的云原生数仓,目前已在阿里云、腾讯云、华为云、AWS 上开通;SelectDB Enterprise 则是自管理(Self-managed),本地软件交付,部署在客户的 IDC、私有云 / 专有云 VPC,可以运行在裸金属服务器、虚拟机、K8S 。
在实时数据仓库领域,SelectDB 凭借其卓越的性能和创新的架构,已经占据了重要的地位。它能够在大规模数据上实现极速查询分析,帮助企业快速从海量数据中获取有价值的信息,为企业决策提供有力支持。无论是在数据处理的实时性、查询的高效性,还是在成本控制和易用性方面,SelectDB 都展现出了明显的优势,成为众多企业进行实时数据分析的首选方案之一。
三、SelectDB 的核心特性
(一)实时极速
在大数据时代,数据的实时性和查询速度是衡量数据仓库性能的关键指标。SelectDB 在这两方面表现出色,实现了实时极速的数据分析体验。
数据延迟和查询延迟是衡量实时分析的两个核心指标。SelectDB 以实时的数据导入和数据存储确保分析数据的新鲜性,以极速高并发的数据查询满足响应的及时性。在数据导入存储方面,SelectDB 实现了秒级的数据实时更新(主键表)与追加,实现了实时数据的秒级可见,在主键表和非主键表上实现了高效的实时更新和追加;内置了数据库的 CDC(变更数据捕获)功能以及 Kafka 的流式数据同步功能,能够实现秒级的数据同步;能够毫秒级提供 Schema 修改的功能,同时 Schema 修改期间完全不影响在线业务的运行;通过引入 Array、Map、JSON 等数据结构,能够高效支持半结构化数据类型的存储和处理需求。
在查询性能上,SelectDB 也表现卓越。在 TPC-H 等基准测试中,SelectDB 展现出远超传统数据湖查询系统 3 - 5 倍的性能提升 。它实现了单节点 30000QPS 的超高并发点查询,真正具备了在一套架构下同时满足高吞吐的 OLAP 分析和高并发的 Data Serving 在线服务的能力;在 ClickHouse 所发起的数据库性能排行榜 Clickbench 中,2022 年 10 月 SelectDB 首登榜单即斩获榜单第一名的成绩,这进一步证明了 SelectDB 在处理大宽表查询方面具备出色的性能;在 SSB 和 TPC-H 等多表 Join 的测试中,SelectDB 性能最多可以达到 ClickHouse 的 100 倍、Greenplum 的 5 - 10 倍。
(二)融合统一
SelectDB 作为现代化统一的数据仓库,单一系统支持多种数据源、多种数据类型和多种数据分析场景,是 All - In - One 的分析平台,更加易于使用和管理,让企业精力从管理复杂的数据基础设施转为关注上层的数据应用。
在数据源方面,SelectDB 支持从各种常见的数据源接入数据,如 Kafka、JDBC、HDFS 等,无论是结构化数据,还是如日志、JSON 等半结构化数据,亦或是图像、音频等非结构化数据,SelectDB 都能很好地进行处理和分析。在湖仓融合分析场景中,它作为查询引擎可以直接查询 Iceberg、Hudi、Paimon、DeltaLake、Hive 等湖仓中的数据,在不移动数据的情况下,实现查询分析的数倍加速;还能作为统一的查询网关,支持跨多个数据源查询位于数据湖、数据仓库、数据库中的数据,实现联邦查询,简化架构并消除数据孤岛。
在数据类型上,SelectDB 不仅支持常规的数值、字符串等数据类型,还通过引入 Array、Map、JSON 等数据结构,能够高效支持半结构化数据类型的存储和处理需求。在用户行为分析场景中,用户的行为数据常常以 JSON 格式存储,包含了丰富的信息,如用户的操作时间、操作类型、所在地区等。SelectDB 可以直接对这些 JSON 数据进行解析和分析,无需复杂的数据转换过程,大大提高了分析效率。
(三)弹性架构
SelectDB 极致的弹性架构依托三种分离:计算与计算分离,实现了更细粒度的计算资源的管理;不同热度的数据分层存储,在不损失存储性能的情况下实现存储成本的大幅下降;存储计算分离,让存储和计算实现真正的独立扩缩容。
计算与计算分离方面,SelectDB 支持创建多个计算集群,每个集群可以独立配置计算资源,不同的计算集群可以分别处理不同类型的任务,如在线业务与离线数据分析需求,高效实现负载隔离,避免不同业务之间相互影响,提升查询性能和系统稳定性。
数据分层存储上,SelectDB 采用冷热存储分层技术,热数据存储在高性能的 SSD 上,以确保查询速度,而冷数据则存储在成本更低的对象存储中,从而有效控制总体存储成本。这种方式使得存储资源得到更合理的利用,既保证了热数据的快速访问,又降低了整体存储成本。
存算分离架构中,计算资源和存储资源分开管理,用户可以根据业务需求独立地扩展或缩减计算资源和存储资源。当业务量突然增加时,可以快速增加计算节点来提高处理能力,而无需担心存储资源的限制;反之,当业务量减少时,可以减少计算节点,降低成本。存储资源也可以根据数据量的增长或减少进行灵活调整,实现了资源的最优配置。
(四)开放生态
SelectDB 基于 Apache Doris 构建,与 Apache Doris 100% 兼容,这使得基于 Apache Doris 开发的应用可以轻松迁移到 SelectDB 上,保护了用户的前期投资。采用开放的 SQL 和广泛使用的 MySQL 协议,确保系统学习和对接下游应用成本极低,用户可以使用熟悉的 MySQL 客户端、驱动和 BI 工具来连接和操作 SelectDB,降低了学习成本和使用门槛。
同时,SelectDB 提供开放的数据读写 API,让大数据生态产品可以自由访问,防止数据被锁定在单一系统中、形成数据孤岛。在数据处理流程中,可能会使用到 Spark、Flink 等大数据处理框架,SelectDB 的开放 API 可以方便地与这些框架进行集成,实现数据的高效传输和处理。
四、SelectDB 的应用场景
(一)实时报表与多维分析
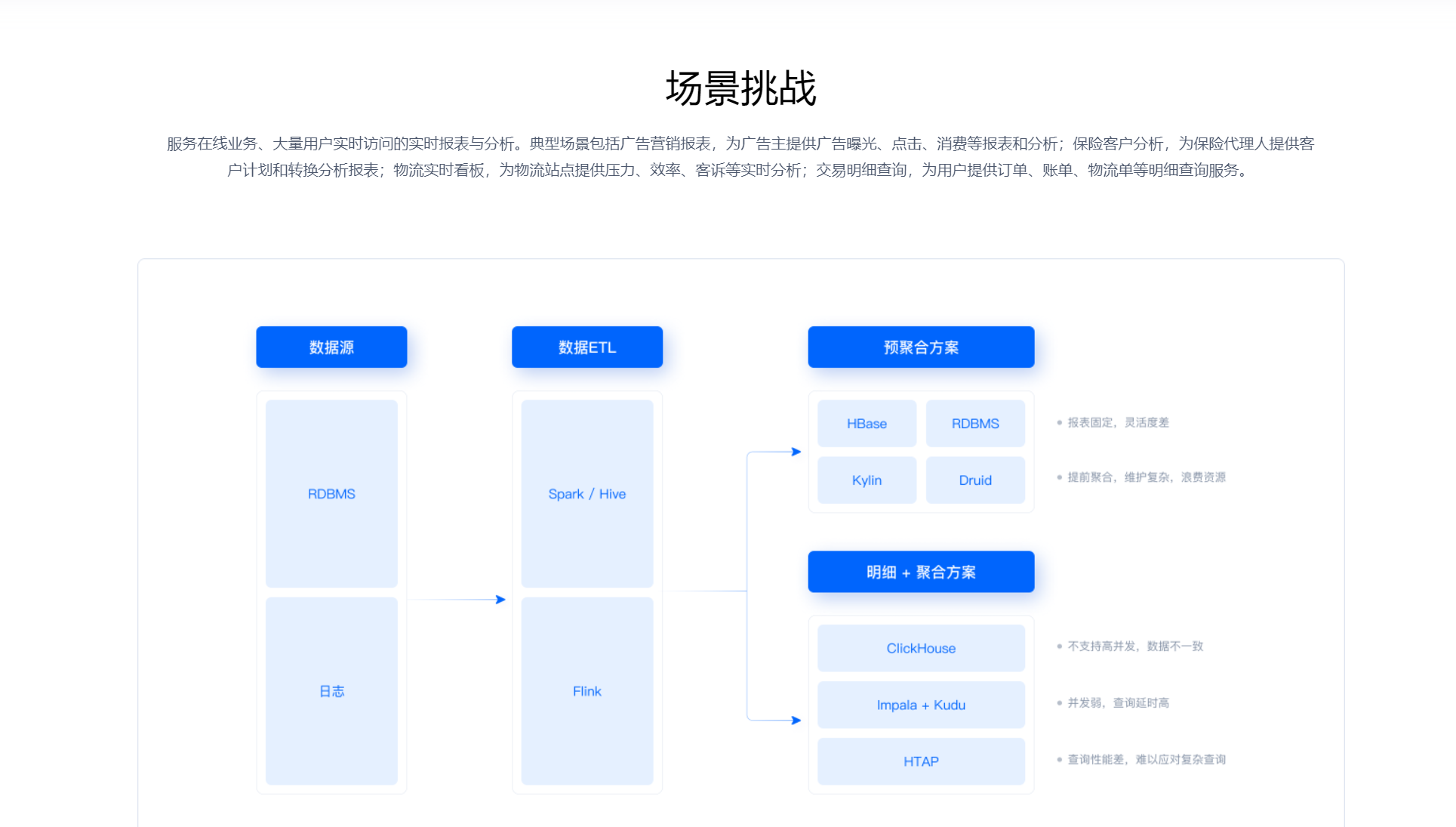
在大规模业务场景下,企业需要处理海量的业务数据,并生成各种报表以支持决策分析。SelectDB 凭借其强大的实时数据导入和查询能力,能够实现毫秒级延时、上万并发和秒级数据可见的报表分析。通过对业务数据库或应用日志的变更数据进行快速实时导入,SelectDB 可以实时更新报表数据,让企业管理者能够及时了解业务的最新动态。在电商领域,企业需要实时了解商品的销售情况、用户的购买行为等,SelectDB 可以实时导入交易数据和用户行为数据,快速生成销售报表、用户分析报表等,帮助企业及时调整营销策略。
(二)数据联邦与查询加速
企业的数据往往存储在不同的数据源中,如数据湖、关系型数据库、NoSQL 数据库等,这就导致了数据孤岛的问题。SelectDB 基于 Multi - Catalog 机制,能够实现对数据湖和多种异构数据源的高效数据集成,降低数据流转成本,提供统一的分析体验。它可以直接查询存储在数据湖中的数据,如 Hive、Iceberg、Hudi 等格式的数据,无需将数据进行迁移或转换。同时,SelectDB 还可以作为统一的查询网关,支持跨多个数据源查询位于数据湖、数据仓库、数据库中的数据,实现联邦查询。在一个大型企业中,销售数据存储在关系型数据库中,用户数据存储在 NoSQL 数据库中,而日志数据存储在数据湖中,SelectDB 可以通过 Multi - Catalog 机制,将这些不同数据源的数据进行整合,实现统一的查询分析,大大提升了查询性能和分析效率 。
(三)用户画像与行为分析
对于企业来说,了解用户的属性和行为是实现精准营销和个性化服务的关键。SelectDB 能够为企业提供实时更新、秒级查询的用户属性与行为洞察能力,帮助企业高效完成用户参与、留存、转化等相关行为分析,以及人群洞察和人群圈选等画像分析。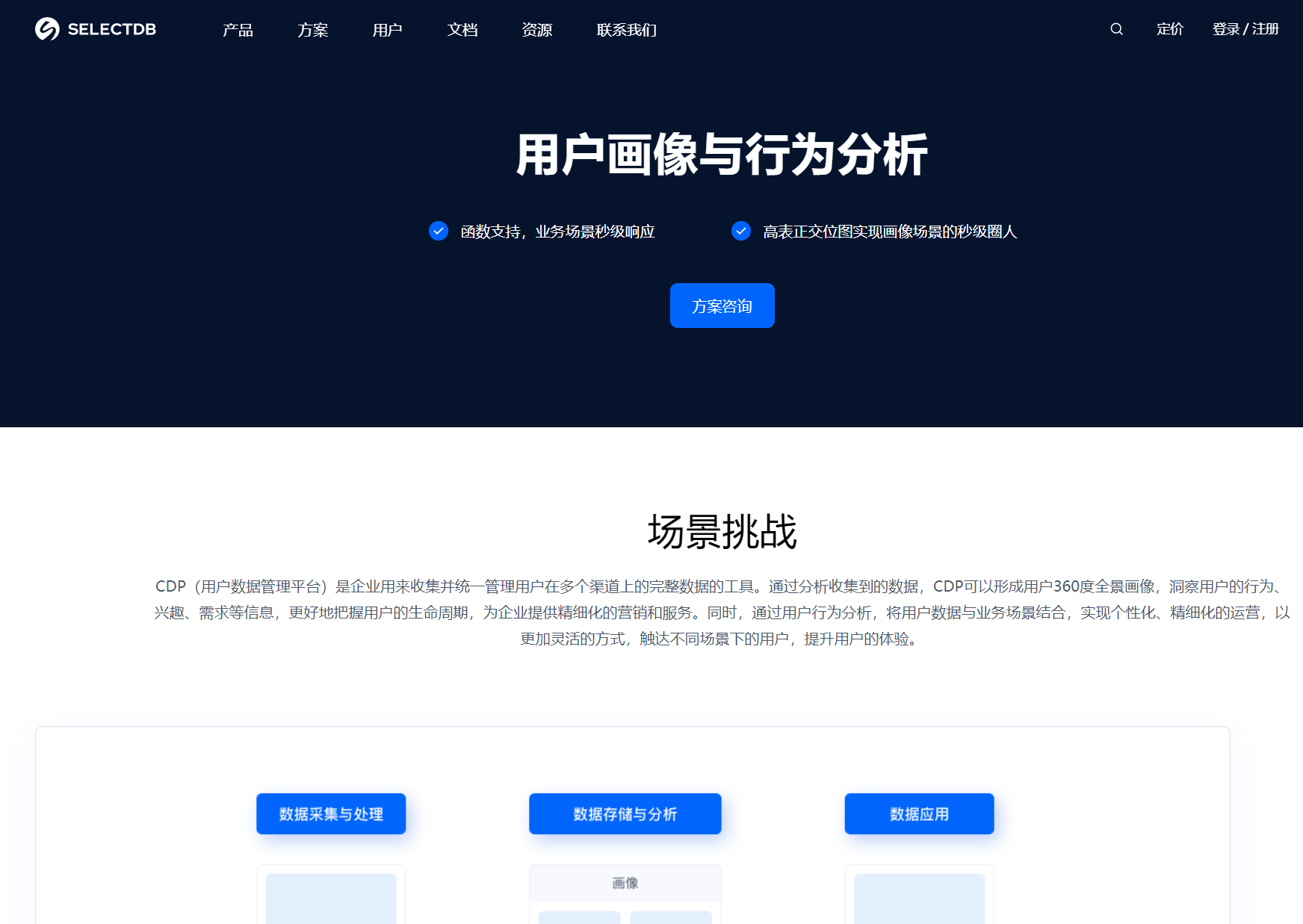 通过实时采集和分析用户在网站、APP 等平台上的行为数据,如浏览记录、点击行为、购买记录等,SelectDB 可以实时构建用户画像,并对用户的行为进行分析预测。电商企业可以利用 SelectDB 分析用户的购买偏好和购买频率,为用户推荐个性化的商品,提高用户的购买转化率。
通过实时采集和分析用户在网站、APP 等平台上的行为数据,如浏览记录、点击行为、购买记录等,SelectDB 可以实时构建用户画像,并对用户的行为进行分析预测。电商企业可以利用 SelectDB 分析用户的购买偏好和购买频率,为用户推荐个性化的商品,提高用户的购买转化率。
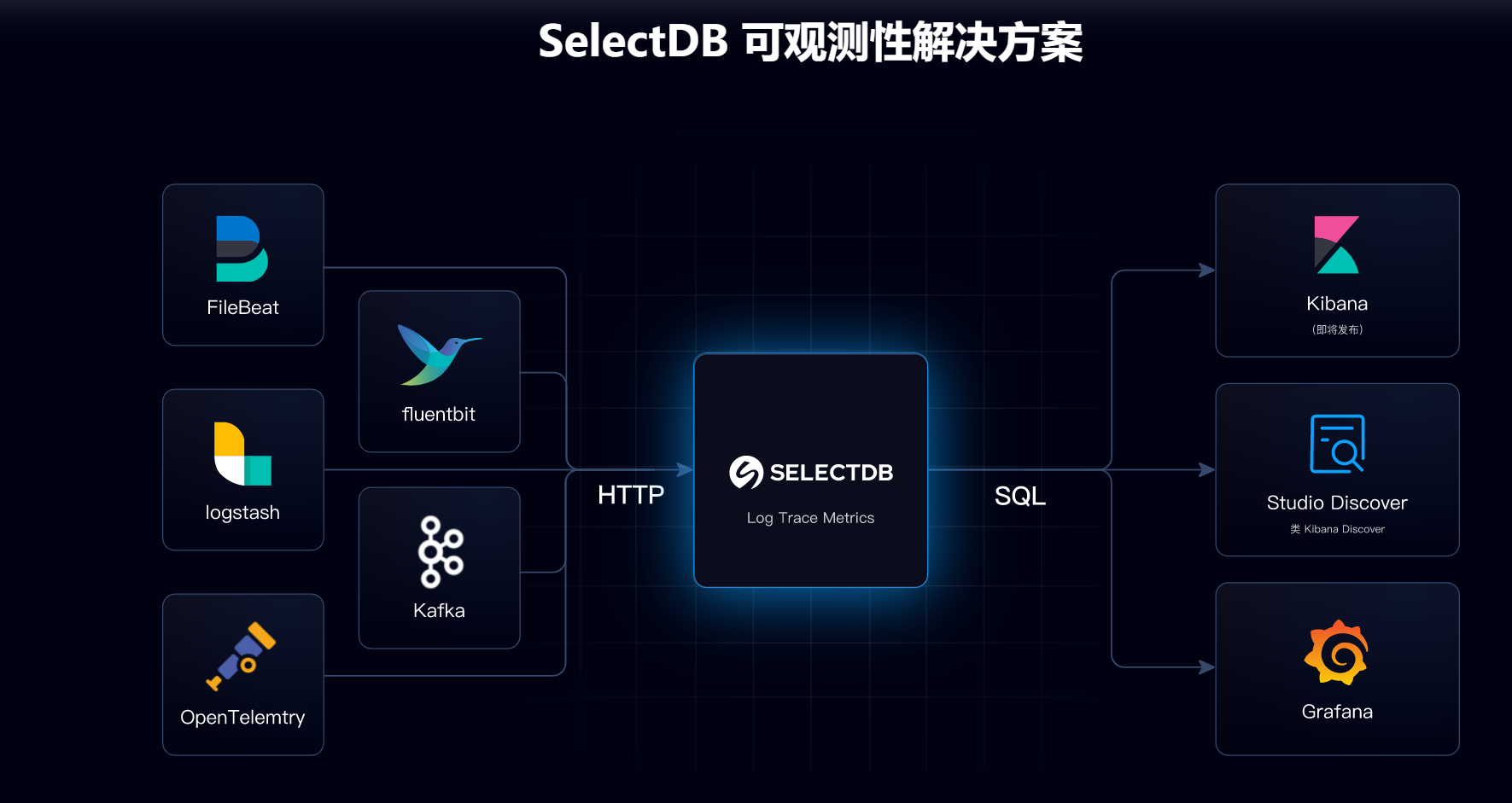
(四)日志存储与分析
在业务、系统或物联网日志场景中,企业需要对大量的日志数据进行实时入库和分析,以监控系统的运行状态、发现潜在的问题。SelectDB 实现了业务、系统或者物联网等相关的日志数据的实时入库,并支持将其存储为结构化、半结构化或原始文本,从而帮助企业高性能、低成本构建起统一的日志存储与分析平台。 SelectDB 具备高并发写入和高效查询的能力,能够快速处理大量的日志数据。通过对日志数据的分析,企业可以及时发现系统中的异常情况,如服务器故障、网络攻击等,并采取相应的措施进行处理。
SelectDB 具备高并发写入和高效查询的能力,能够快速处理大量的日志数据。通过对日志数据的分析,企业可以及时发现系统中的异常情况,如服务器故障、网络攻击等,并采取相应的措施进行处理。
五、SelectDB 的性能优势

(一)与其他数据库对比测试
为了更直观地展现 SelectDB 的性能优势,我们将其与常见的数据库如 Elasticsearch、ClickHouse 等进行对比测试。在测试环境上,我们选择了配置相同的服务器集群,以确保测试结果的公正性和可比性。服务器均采用高性能的 CPU、大容量内存和高速存储设备,网络环境也保持一致,避免因硬件和网络差异对测试结果产生影响。
在写入性能方面,SelectDB 展现出了卓越的表现。以处理大规模日志数据为例,当每秒需要写入百万条日志记录时,Elasticsearch 由于其写入机制和架构特点,在高并发写入时会出现资源紧张的情况,导致写入延迟增加,高峰期甚至容易出现写入拒绝的问题,平均写入延迟达到了 500 毫秒左右。而 SelectDB 采用了优化的写入算法和高效的数据存储结构,能够轻松应对高并发写入场景,平均写入延迟仅为 100 毫秒,写入性能是 Elasticsearch 的 5 倍 。这使得 SelectDB 在面对海量数据快速写入的需求时,能够更加稳定、高效地完成任务。
查询性能测试中,对于复杂的多表关联查询和全文检索查询,SelectDB 同样表现出色。在多表关联查询场景下,涉及 5 个以上表的关联查询时,ClickHouse 的查询性能会随着表的数量增加而明显下降,查询耗时较长,平均查询时间达到了 2 秒以上。而 SelectDB 凭借其强大的查询优化器和高效的执行引擎,能够快速处理复杂的多表关联逻辑,平均查询时间仅为 0.2 秒,性能最多可以达到 ClickHouse 的 10 倍。在全文检索查询方面,SelectDB 针对日志分析场景对倒排索引进行了优化,在处理包含大量文本的日志数据时,查询性能是 Elasticsearch 的 2 倍,能够快速准确地返回检索结果,满足用户对实时分析的需求。
在聚合统计分析性能上,SelectDB 的优势也十分明显。当对亿级数据进行聚合计算,如计算分位数、错误率等指标时,Elasticsearch 极易出现超时问题,很难满足大规模数据下的业务分析需求。而 SelectDB 能够快速完成聚合计算,聚合统计分析性能是 Elasticsearch 的 6 - 21 倍,能够为企业提供及时、准确的数据分析结果,助力企业决策。
(二)实际案例中的性能表现
在实际应用中,SelectDB 的性能优势得到了充分验证。以观测云为例,观测云是一家专注于云、云原生、应用及业务统一监测的企业,在日志存储与分析场景中,原本使用 Elasticsearch 作为存储和分析引擎,但随着业务的快速发展,数据量呈爆发式增长,Elasticsearch 逐渐暴露出诸多问题,如写入占用资源多、对无模式表支持差、聚合查询性能差等。

引入 SelectDB 后,观测云实现了性能与成本的双重飞跃。在存储成本方面,SelectDB 的高效数据压缩和智能分层存储策略,使观测云在存储成本上实现了大幅降低,相比使用 Elasticsearch,存储成本降低约 70%。在查询性能上,SelectDB 的高性能查询引擎和优化的执行计划,使观测云在数据查询和分析方面实现了质的飞跃,查询性能提升 2 - 4 倍 。此外,SelectDB 的倒排索引技术支持,使观测云能够更快地执行复杂的全文检索查询,满足日志分析等场景的需求;其灵活的 Variant 数据类型,为观测云提供了更灵活的 Schema 管理能力,适应了快速变化的业务需求。最终,SelectDB 的引入帮助观测云实现了整体性价比 10 倍提升,为其日志存储和分析场景服务提供了强大动力。
六、如何使用 SelectDB

(一)快速上手指南
SelectDB 提供了多种便捷的安装部署方式,以满足不同用户的需求。对于希望快速体验 SelectDB 强大功能的用户,在公有云平台使用 SelectDB Cloud 是一个理想的选择 。
以在阿里云上使用 SelectDB Cloud 为例,首先需要登录阿里云官网,在云市场中搜索 SelectDB Cloud。找到对应的产品后,点击进入产品详情页面,然后按照页面提示进行操作。在创建 SelectDB Cloud 实例时,需要选择合适的配置,如计算资源、存储容量等。配置完成后,确认订单并完成支付,即可快速创建一个 SelectDB Cloud 实例。创建成功后,用户可以通过提供的连接信息,使用 MySQL 客户端或其他支持 MySQL 协议的工具连接到 SelectDB Cloud,开始进行数据操作。
对于有私有化部署需求的用户,可以下载 SelectDB Enterprise 的安装包,根据官方文档的指导,在本地服务器或私有云环境中进行安装部署。在安装过程中,需要注意服务器的硬件配置、操作系统版本等要求,以确保 SelectDB 能够稳定运行。
(二)基本操作与 SQL 语法
在 SelectDB 中,常用的数据库操作命令包括创建数据库、删除数据库、切换数据库等。创建数据库可以使用以下命令:
sql
CREATE DATABASE my_database;这将创建一个名为 my_database 的数据库。如果要删除数据库,可以使用:
sql
DROP DATABASE my_database;切换到指定数据库则使用:
sql
USE my_database;表操作方面,创建表的命令如下:
sql
CREATE TABLE my_table (
id INT,
name VARCHAR(50),
age INT
) ENGINE=OLAP
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 16;上述语句创建了一个名为 my_table 的表,包含 id、name 和 age 三个字段,采用 DUPLICATE KEY 的方式存储数据,数据按照 id 进行哈希分布,分成 16 个桶。删除表的命令为:
sql
DROP TABLE my_table;基本的 SQL 查询语法与标准 SQL 类似。例如,查询 my_table 表中的所有数据:
sql
SELECT * FROM my_table;查询指定字段的数据:
sql
SELECT id, name FROM my_table;添加条件查询,如查询 age 大于 20 的记录:
sql
SELECT * FROM my_table WHERE age > 20;还可以进行数据排序,按照 age 字段升序排列:
sql
SELECT * FROM my_table ORDER BY age ASC;(三)高级功能与配置优化
SelectDB 的多计算集群功能可以极大地提升系统的性能和灵活性。在实际应用中,企业可能有在线业务和离线数据分析等不同的业务需求,这些业务对资源的需求和性能要求各不相同。通过创建多个计算集群,用户可以将不同的业务负载分配到不同的集群中,实现负载隔离,避免业务之间相互影响。
在数据导入优化方面,SelectDB 提供了多种数据导入方式,如 Stream Load、Broker Load、Routine Load 等,每种方式都有其适用的场景。在导入大量数据时,可以根据数据的特点和业务需求选择合适的导入方式。如果数据是实时产生的小批量数据,使用 Stream Load 可以实现快速的数据导入;对于存储在 HDFS 等分布式文件系统中的大规模数据,Broker Load 则更为合适。同时,合理设置导入参数,如并行度、缓冲区大小等,也能有效提高数据导入的速度。
查询性能调优也是使用 SelectDB 时需要关注的重点。用户可以通过创建合适的索引来加速查询。在查询经常涉及的字段上创建索引,能够显著提高查询效率。优化查询语句也是关键。避免使用复杂的子查询和全表扫描,合理使用 JOIN 操作,能够减少查询的执行时间。分析查询执行计划,找出性能瓶颈,也是优化查询性能的重要手段。通过 EXPLAIN 命令可以查看查询的执行计划,了解查询的执行过程,从而针对性地进行优化 。
七、3 个经典代码案例 + 逐行解读
案例 1:日志实时入库 + 倒排检索
场景:Nginx 日志 → Kafka → Doris,按 IP 和关键词检索
sql
-- 1. 建表:日志原始字段 + 倒排索引
CREATE TABLE nginx_log (
log_time DATETIME,
client_ip VARCHAR(32),
request_url STRING,
status INT,
INDEX idx_url (`request_url`) USING INVERTED -- 倒排索引
) ENGINE=OLAP
DUPLICATE KEY(log_time, client_ip)
DISTRIBUTED BY HASH(client_ip) BUCKETS 32;
-- 2. Routine Load 持续消费 Kafka
CREATE ROUTINE LOAD load_nginx ON nginx_log
PROPERTIES (
"desired_concurrent_number"="3"
)
FROM KAFKA (
"kafka_broker_list"="kafka:9092",
"kafka_topic"="nginx_access"
);
-- 3. 关键词检索,毫秒级返回
SELECT *
FROM nginx_log
WHERE request_url MATCH 'api/v1/order/*'
AND log_time >= now() - interval 5 minute;解读:
-
第 4 行
USING INVERTED建倒排,全文检索性能≈ES。 -
ROUTINE LOAD把 Kafka 消费逻辑下沉到 Doris,省掉 Flink/Logstash。 -
最后一条 SQL 即席查询,5 分钟内的订单接口访问日志秒出。
案例 2:亿级用户 UV 实时去重(Bitmap)
sql
-- 用户访问明细表
CREATE TABLE user_visit (
dt DATE,
user_id BIGINT,
page_id INT
) DUPLICATE KEY(dt, user_id);
-- 预聚合物化视图:每日 UV
CREATE MATERIALIZED VIEW uv_daily
AS
SELECT dt,
bitmap_union(to_bitmap(user_id)) AS uv_bitmap
FROM user_visit
GROUP BY dt;
-- 查询:任意日期 UV
SELECT dt, bitmap_count(uv_bitmap) AS uv
FROM uv_daily
WHERE dt BETWEEN '2025-07-01' AND '2025-07-31';解读:
-
to_bitmap把 user_id 压缩成 RoaringBitmap,亿级去重内存占用极低。 -
物化视图自动增量刷新,查询时直接读聚合结果,TP99 从 3 s 降到 80 ms。
案例 3:跨源联邦查询(MySQL + Iceberg)
sql
-- 1. 创建外部 Catalog:指向 MySQL
CREATE CATALOG mysql_catalog PROPERTIES (
"type"="jdbc",
"user"="root",
"password"="123456",
"jdbc_url"="jdbc:mysql://mysql:3306/erp"
);
-- 2. 创建外部 Catalog:指向 Iceberg
CREATE CATALOG iceberg_catalog PROPERTIES (
"type"="iceberg",
"warehouse"="hdfs://ns/iceberg"
);
-- 3. 一条 SQL 跨源 Join:订单表(MySQL) + 行为日志(Iceberg)
SELECT o.order_id,
o.amount,
b.event_type,
b.event_time
FROM mysql_catalog.erp.orders o
JOIN iceberg_catalog.events.user_behavior b
ON o.user_id = b.user_id
WHERE o.order_date = '2025-07-30';解读:
-
无需把 MySQL 订单表或 Iceberg 日志导入 Doris,即可实时 Join。
-
Doris 作为统一查询网关,节省数据搬迁和链路维护成本。
八、总结与展望

SelectDB 作为新一代实时数据仓库,以其实时极速、融合统一、弹性架构和开放生态的核心特性,在大数据分析领域展现出了强大的竞争力。它能够满足企业在实时报表与多维分析、数据联邦与查询加速、用户画像与行为分析、日志存储与分析等多个关键场景的需求,为企业提供了高效、准确的数据分析支持。
在性能方面,SelectDB 通过与其他数据库的对比测试以及实际案例中的出色表现,证明了其在数据处理和查询分析上的卓越能力,能够帮助企业在海量数据中快速获取有价值的信息,为决策提供有力依据。同时,SelectDB 提供了便捷的使用方式和丰富的功能配置选项,无论是快速上手的新手还是需要进行高级功能配置优化的专业用户,都能轻松驾驭。
随着大数据技术的不断发展和企业对数据分析需求的持续增长,SelectDB 有望在未来取得更广阔的发展空间。它将不断优化自身性能,拓展应用场景,与更多的大数据生态产品进行深度融合,为企业提供更加全面、高效的数据分析解决方案。
如果你正在寻找一款强大的实时数据仓库解决方案,不妨尝试一下 SelectDB。相信它会给你带来意想不到的惊喜,助力你的企业在大数据时代实现数据价值的最大化 。

15 个技术关键字(一句话说明)
-
云原生存算分离
计算节点与对象存储解耦,白天高峰 100 节点,夜间缩到 5 节点,成本随流量呼吸。
-
实时主键表
支持 UPSERT / DELETE,数据秒级可见,完美替代离线 T+1 全量同步。
-
倒排索引
对日志文本字段自动构建倒排,关键词检索比 LIKE 快 50~100 倍。
-
冷热分层
SSD 只放 7 天热数据,其余自动下沉 OSS,整体存储成本降到 1/10。
-
Multi-Catalog
一条 SQL 同时 Join Hive、MySQL、Iceberg,联邦查询零数据搬运。
-
Variant 半结构化
JSON、Array、Map 直接入库,Schema 变化无需 DDL,业务敏捷度 +100%。
-
物化视图
预聚合结果自动刷新,查询 10 亿行变 1 万行,TP99 从 2 s 降到 200 ms。
-
高并发点查
单节点 3 万 QPS;把 Doris 当 KV 用,BI 看板再也不卡。
-
Flink-Doris-Connector
Exactly-Once 语义实时写入,Flink 作业宕机重启零数据重复。
-
Doris Operator
K8s 上一条 kubectl apply 拉起整个集群,升级、扩缩容全自动。
-
X2Doris 迁移工具
图形界面拖拽 ClickHouse / MySQL 表到 Doris,十分钟完成 PB 级迁移。
-
MySQL 协议兼容
任何 MySQL 客户端、BI 工具零改造接入,学习成本 ≈ 0。
-
Bitmap 精确去重
亿级用户 UV 计算内存占用 < 1 GB,实时广告报表秒出。
-
Light Schema Change
加列、改列类型毫秒完成,线上业务无感知。
-
弹性计算组
在线与离线跑在不同计算组,互不干扰,白天跑报表,夜里跑 ETL。
分享官方文章: