AI轻量级推理架构
- 前言:让大模型走出GPU的"牢笼"
- 第一章:LLaMA.cpp:CPU运行大模型的"革命者"
-
- [1.1 核心痛点:LLM的"体重"与GPU的"稀缺"](#1.1 核心痛点:LLM的“体重”与GPU的“稀缺”)
- [1.2 LLaMA.cpp的诞生与使命:打破硬件壁垒](#1.2 LLaMA.cpp的诞生与使命:打破硬件壁垒)
- [1.3 优劣势分析:便携、高效与局限性](#1.3 优劣势分析:便携、高效与局限性)
- 第二章:核心黑科技一:GGML格式------模型的"极简主义"打包法
-
- [2.1 GGML是什么?------ 为CPU优化而生的高效张量表示](#2.1 GGML是什么?—— 为CPU优化而生的高效张量表示)
- [2.2 GGML的核心优化点:静态图编译与多种量化支持](#2.2 GGML的核心优化点:静态图编译与多种量化支持)
- [2.3 【一张图看懂】:GGML文件结构与传统模型的对比](#2.3 【一张图看懂】:GGML文件结构与传统模型的对比)
- [第三章:核心黑科技二:KV Cache管理------推理速度的"涡轮增压"](#第三章:核心黑科技二:KV Cache管理——推理速度的“涡轮增压”)
-
- [3.1 KV Cache原理回顾:LLM推理的"记忆单元"](#3.1 KV Cache原理回顾:LLM推理的“记忆单元”)
- [3.2 LLaMA.cpp中的KV Cache优化:高效内存管理与量化](#3.2 LLaMA.cpp中的KV Cache优化:高效内存管理与量化)
- [3.3 【一张图看懂】:KV Cache如何加速LLM推理](#3.3 【一张图看懂】:KV Cache如何加速LLM推理)
- 第四章:LLaMA.cpp推理流程:从Prompt到CPU执行
-
- [4.1 模型加载:GGML文件的解析与内存映射](#4.1 模型加载:GGML文件的解析与内存映射)
- [4.2 预处理:Tokenization与Tensor准备](#4.2 预处理:Tokenization与Tensor准备)
- [4.3 核心推理:量化计算与KV Cache协同](#4.3 核心推理:量化计算与KV Cache协同)
- [4.4 后处理:Token解码与流式输出](#4.4 后处理:Token解码与流式输出)
- 第五章:【代码实战】驱动LLaMA.cpp:本地CPU运行大模型
-
- [5.1 环境准备:安装LLaMA.cpp与下载GGUF模型](#5.1 环境准备:安装LLaMA.cpp与下载GGUF模型)
- 5.2:命令行运行LLaMA.cpp推理
- [5.3 Python绑定(llama-cpp-python)实现对话](#5.3 Python绑定(llama-cpp-python)实现对话)
- "量化参数"的魔力:Q4_K_M、Q5_K_S是什么意思?
- 总结与展望:CPU上的LLM,无限可能的边缘AI
前言:让大模型走出GPU的"牢笼"
你已经见识了LLaMA大模型 和Stable Diffusion 的强大,它们通常需要在GPU上才能运行。然而,GPU价格昂贵、功耗巨大,并不是每个人都能拥有。
这就像一个拥有"绝世武功"的武林高手,虽然武艺高强,但却被"硬件"这个"牢笼"所限制,只能在特定的"演武场"(高端GPU)上施展拳脚。
LLaMA.cpp的出现,彻底改变了这一局面。

它就像为大模型量身定制了一双**"轻量化跑鞋",让它们能够在普通CPU、甚至手机、树莓派等边缘设备上**"健步如飞",以令人惊讶的速度进行推理。
今天,我们将深入LLaMA.cpp的内部,揭秘其背后的"黑科技",理解它如何让大模型打破硬件壁垒,走向大众
第一章:LLaMA.cpp:CPU运行大模型的"革命者"
分析LLM部署的痛点,LLaMA.cpp的诞生背景、使命,并初步评估其优劣势。
1.1 核心痛点:LLM的"体重"与GPU的"稀缺"
模型大:LLaMA-7B模型通常有14GB左右的权重(fp16精度),加载就需要14GB显存。
推理慢:即使是GPU,如果没有优化,推理也可能很慢。
GPU稀缺且昂贵:高端GPU并非人人可得,云端GPU租用成本高昂。
边缘部署困难:手机、物联网设备等根本没有GPU,或算力不足。
1.2 LLaMA.cpp的诞生与使命:打破硬件壁垒
LLaMA.cpp最初由Georgi Gerganov开发,旨在利用LLaMA模型的开源权重,实现CPU上的高效推理。
"点cpp"的含义:.cpp表示其核心代码由C/C++实现,能够直接操作底层硬件,实现极致性能优化,而无需依赖Python的额外开销。
使命:让大语言模型在更广泛的设备上运行,实现本地化、隐私保护、低成本、实时性的AI应用。
1.3 优劣势分析:便携、高效与局限性
特性 优势 劣势
部署环境 CPU、边缘设备 (Mac M系列芯片表现尤佳) GPU上的性能通常仍优于CPU
成本 极低(无需额外GPU)
性能 CPU上推理速度惊人,甚至可实时 针对GPU的推理优化(如TensorRT)更极致
隐私 数据在本地处理,隐私性高
易用性 单一二进制文件,易于分发和使用 编译相对复杂,需根据CPU架构优化
适用范围 专注于LLM,尤其是LLaMA家族 仅限语言模型,不适用于图像/视频生成
第二章:核心黑科技一:GGML格式------模型的"极简主义"打包法
深入GGML文件格式,理解它如何为CPU推理带来极致的优化。
2.1 GGML是什么?------ 为CPU优化而生的高效张量表示
GGML(Georgi Gerganov's Machine Learning)是一种自定义的张量表示格式,也是LLaMA.cpp的核心创新之一。它专门为CPU上的高效、低内存推理而设计。
设计理念:避免通用深度学习框架(如PyTorch、TensorFlow)带来的额外抽象和运行时开销,直接面向CPU的内存布局和指令集进行优化。
核心:它不仅仅是保存模型权重,更是一种运行时张量库和动态计算图的编译器。
2.2 GGML的核心优化点:静态图编译与多种量化支持
自定义张量类型:GGML定义了自己的张量类型,可以更灵活地控制内存布局。
静态图编译:在推理时,LLaMA.cpp会根据模型结构编译成一个优化的静态计算图,而不是像PyTorch那样动态执行。这减少了运行时解释的开销。
多种量化支持:这是GGML最核心的优势之一。它原生支持多种低精度量化类型(如int4, int5, int8),并且这些量化算法都是专门为CPU的SIMD(单指令多数据)指令集优化的。
这意味着:
-
模型文件更小。
-
内存占用更低。
-
CPU计算速度更快。
2.3 【一张图看懂】:GGML文件结构与传统模型的对比

第三章:核心黑科技二:KV Cache管理------推理速度的"涡轮增压"
回顾KV Cache原理,并深入LLaMA.cpp中如何高效管理和利用KV Cache,以实现惊人的推理速度。
3.1 KV Cache原理回顾:LLM推理的"记忆单元"
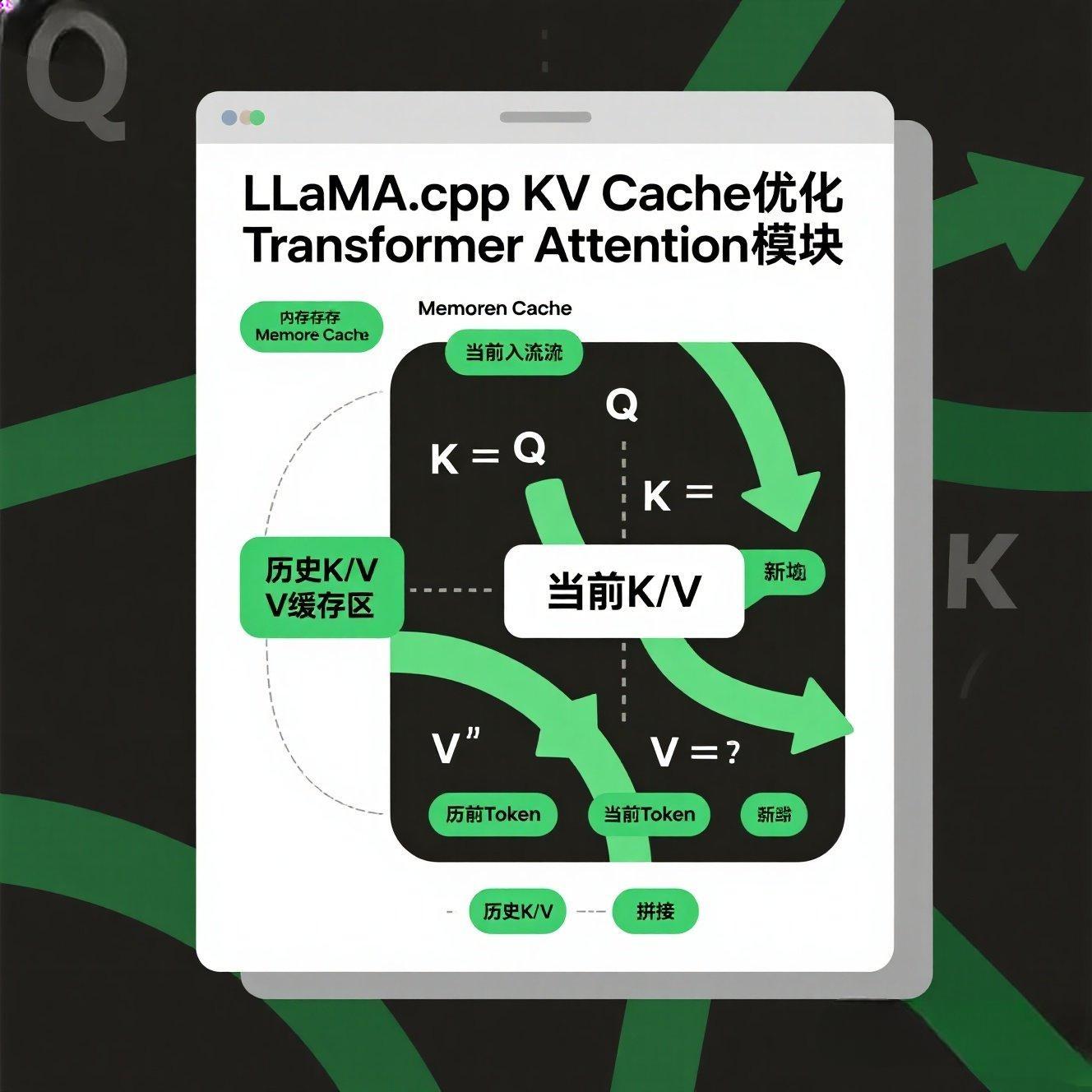
我们在之前章节中已经提到,KV Cache是LLM自回归生成的核心优化。
问题:生成下一个Token时,需要重新计算当前Token与所有历史Token的注意力。随着序列变长,计算量呈平方增长。
解决方案:缓存历史Token的Key (K) 和 Value (V) 向量。每次只计算当前新Token的Q, K, V,然后把新K, V与历史缓存的K, V拼接起来进行注意力计算。
效果:将每次推理的计算复杂度从 O(L^2) 降到 O(L),大幅提升生成速度。
3.2 LLaMA.cpp中的KV Cache优化:高效内存管理与量化
LLaMA.cpp对KV Cache进行了多层优化,使其在CPU上也能发挥极致效率:
内存布局优化:针对CPU缓存(Cache)友好的内存布局,减少缓存未命中(Cache Miss)。
量化KV Cache:LLaMA.cpp甚至可以对KV Cache中的K和V向量进行量化存储(例如INT8),这进
一步节省了内存空间,使得在有限的RAM下也能处理更长的上下文。
分块管理:长序列的KV Cache会被分成小块进行管理,避免一次性分配过大内存。
3.3 【一张图看懂】:KV Cache如何加速LLM推理
第四章:LLaMA.cpp推理流程:从Prompt到CPU执行
分解LLaMA.cpp在CPU上执行推理的完整流程,从文件加载到最终输出。
4.1 模型加载:GGML文件的解析与内存映射
LLaMA.cpp会解析GGUF文件(新一代的GGML格式)。
它将权重和元数据直接加载到CPU内存中。由于GGUF格式的优化,这个过程非常快,甚至可以内存映射(mmap),无需完全加载到RAM,直接从磁盘读取。
4.2 预处理:Tokenization与Tensor准备
用户输入的Prompt被内置的Tokenizer(通常是SentencePiece)处理,转换为Token ID序列。
这些ID被转换为GGML自定义的张量格式,准备输入模型。
4.3 核心推理:量化计算与KV Cache协同
分层推理:数据逐层通过Transformer Block。
量化计算:GGML库会利用CPU的SIMD指令集(如AVX2, AVX512),对量化后的权重(例如INT4)进行高效的矩阵乘法运算。
KV Cache更新:每生成一个Token,其K和V向量都会被计算并存入KV Cache。
4.4 后处理:Token解码与流式输出
模型预测的下一个Token ID被解码回人类可读的字符。
为了实现实时性,LLaMA.cpp通常采用流式输出,即预测一个字就显示一个字,而不是等整个回复生成完毕。
第五章:【代码实战】驱动LLaMA.cpp:本地CPU运行大模型
重要提示:LLaMA.cpp本身是C/C++项目,需要编译。但社区提供了方便的Python绑定llama-cpp-python,我们可以直接用pip安装它,它会自动帮你编译并安装好LLaMA.cpp的运行时库。
提供如何在命令行和Python中,运行LLaMA.cpp进行推理的完整步骤和代码。
5.1 环境准备:安装LLaMA.cpp与下载GGUF模型
步骤1:安装 llama-cpp-python
dart
# 确保你的环境中有CMake (Windows用户可能需要安装Visual Studio或MinGW)
# Linux/macOS用户通常自带
# 安装带有GPU支持的llama-cpp-python (如果你的GPU支持,例如NVIDIA CUDA,请自行安装CUDA Toolkit)
# 对于大多数消费级显卡,CPU版本已足够强大,且更易安装
pip install llama-cpp-python
# 如果想尝试GPU加速 (例如CUDA/cuBLAS),需要指定安装
# pip install llama-cpp-python[server,cuda] # 对于NVIDIA GPU
# pip install llama-cpp-python[server,clblast] # 对于AMD/Intel GPU
# pip install llama-cpp-python[server] # 纯CPU版本 (推荐,最简单)步骤2:下载GGUF模型
访问Hugging Face Hub,搜索LLaMA 2或Qwen的模型,并筛选.gguf格式。例如:
Qwen/Qwen1.5-0.5B-Chat-GGUF (非常小,适合快速测试)
TheBloke/Llama-2-7B-Chat-GGUF (7B模型,CPU可流畅运行)
下载.gguf文件(例如 qwen1_5-0_5b-chat-q4_k_m.gguf)到你的项目目录或一个合适的位置。
5.2:命令行运行LLaMA.cpp推理
在不编写Python代码的情况下,直接通过命令行体验LLaMA.cpp的推理速度
安装llama-cpp-python后,其内部会下载并编译LLaMA.cpp的二进制文件。你可以在Python环境的安装目录中找到它。
例如:.\venv\Lib\site-packages\llama_cpp\llama_cpp_cpp_shared_library.pyd 的同级目录,或者通过 pip show llama-cpp-python 查看其安装位置。
或者,你可以直接从llama.cpp的GitHub仓库下载或编译其main可执行文件。
步骤2:运行命令
dart
# 进入你放置GGUF模型的目录
cd /path/to/your/gguf_model/
# 假设你的GGUF模型名为 model.gguf
# 运行推理命令 (这是 llama.cpp 原生命令行的简化版)
# -m: 指定模型路径
# -p: 你的Prompt
# -n: 生成的Token数量
# --temp: 温度 (控制随机性)
# --repeat_penalty: 重复惩罚
# --color: 彩色输出
./main -m model.gguf -p "Hello, please tell me a story about a brave knight." -n 128 --temp 0.7 --repeat_penalty 1.1 --color代码解读】
这个命令行演示了LLaMA.cpp的极致便携性。你无需任何Python代码,只需一个二进制文件和一个模型文件,就能直接在命令行与大模型交互。观察它的推理速度,你会惊讶于CPU的潜力!
5.3 Python绑定(llama-cpp-python)实现对话
在Python脚本中加载GGUF模型,并实现一个交互式对话。
dart
# llama_cpp_python_demo.py
from llama_cpp import Llama # 导入Llama类
import os
# --- 1. 定义模型路径 ---
# 请替换为你的GGUF模型实际路径
# 例如:model_path = "D:/path/to/your/qwen1_5-0_5b-chat-q4_k_m.gguf"
model_path = "path/to/your/qwen1_5-0_5b-chat-q4_k_m.gguf" # <--- 替换为你的GGUF模型路径
# --- 2. 实例化Llama模型 ---
print(f"正在加载GGUF模型: {model_path}...")
# n_ctx: 上下文窗口大小,控制模型能记住多长的对话历史
# n_gpu_layers: 如果有GPU加速,指定多少层放在GPU上 (这里即使CPU运行,参数也要有)
llm = Llama(model_path=model_path, n_ctx=2048, n_gpu_layers=0, verbose=False) # verbose=False 关闭内部日志
print("模型加载完成!")
# --- 3. 定义对话Prompt模板 ---
# LLaMA系列模型通常需要特定的对话格式
# 这是一个简化的Qwen的对话模板
def format_qwen_chat_prompt(messages):
prompt = ""
for message in messages:
if message["role"] == "user":
prompt += f"<|im_start|>user\n{message['content']}<|im_end|>\n"
elif message["role"] == "assistant":
prompt += f"<|im_start|>assistant\n{message['content']}<|im_end|>\n"
elif message["role"] == "system":
prompt += f"<|im_start|>system\n{message['content']}<|im_end|>\n"
prompt += "<|im_start|>assistant\n"
return prompt
# --- 4. 交互式对话 ---
messages = [{"role": "system", "content": "You are a helpful assistant."}]
print("\n--- 开始对话 (输入'退出'结束) ---")
while True:
user_input = input("你: ")
if user_input.lower() == '退出':
print("AI: 再见!")
break
messages.append({"role": "user", "content": user_input})
# 格式化Prompt
chat_prompt = format_qwen_chat_prompt(messages)
# 进行推理
# max_tokens: 最大生成数量
# temperature: 随机性
# stream: 开启流式输出,实时显示结果
print("AI: ", end="")
response_stream = llm.create_chat_completion(
messages=messages, # 使用llama_cpp自带的messages格式,它会帮你处理内部Prompt
max_tokens=256,
temperature=0.7,
stream=True
)
ai_response_content = ""
for chunk in response_stream:
delta_content = chunk["choices"][0]["delta"].get("content", "")
print(delta_content, end="", flush=True) # 实时打印流式输出
ai_response_content += delta_content
print() # 换行
messages.append({"role": "assistant", "content": ai_response_content})【代码解读与见证奇迹】
运行这段Python脚本,你会看到一个交互式的命令行聊天界面。
Llama(model_path=..., n_ctx=...):实例化LLaMA.cpp模型,n_ctx是上下文窗口大小。n_gpu_layers=0表示强制在CPU上运行。
llm.create_chat_completion(messages=..., stream=True):这是LLaMA.cpp的Python绑定提供的高级API,它支持Hugging Facemessages格式,并能流式输出结果,让你体验到和ChatGPT类似的实时对话感觉。
你会发现,即使在CPU上,小参数量模型(如0.5B)也能实现几乎实时的对话,而7B模型也能在几秒内给出回复,这在几年前是难以想象的。
"量化参数"的魔力:Q4_K_M、Q5_K_S是什么意思?

本节概括:提前预热LLaMA.cpp中各种GGUF量化类型的含义,为后续"模型压缩与量化技术"章节做铺垫。
你在下载GGUF模型时,可能会看到类似q4_k_m.gguf、q5_k_s.gguf这样的文件名。这里的q4_k_m就是指量化类型。
q4 / q5:表示模型权重被量化到了4比特或5比特精度。比特数越低,模型越小,速度越快,但精度损失可能越大。
_k:表示使用了K-Quant量化技术。这是LLaMA.cpp独有的、为Transformer层优化的一种量化方式,它对权重和激活值进行分组量化,旨在最小化精度损失。
_m / _s / _l:进一步表示K-Quant的子类型。
_m (medium):中等大小,平衡了速度和质量。
_s (small):更小,但可能牺牲更多精度。
_l (large):更大,保留更多精度。
这些量化类型,是LLaMA.cpp能够在CPU上高效运行的核心魔法。我们将在后续的**《模型压缩与量化技术》**章节中深入探讨。
总结与展望:CPU上的LLM,无限可能的边缘AI
总结与展望:CPU上的LLM,无限可能的边缘AI
恭喜你!今天你已经深入解剖了LLaMA.cpp这一革命性的CPU推理框架,并亲手在本地驱动了它。
✨ 本章惊喜概括 ✨
| 你掌握了什么? | 对应的核心概念/技术 |
|---|---|
| LLaMA.cpp的革命性 | ✅ 在CPU上高效运行LLM,打破硬件壁垒 |
| GGML格式 | ✅ 为CPU优化的高效张量表示与量化支持 |
| KV Cache管理 | ✅ 高速推理的"涡轮增压"与量化KV Cache |
| LLaMA.cpp推理流程 | ✅ 从模型加载到流式输出的完整链路 |
| 驱动LLaMA.cpp实战 | ✅ 亲手代码实现命令行与Python绑定推理 |
| 量化类型初探 | ✅ q4_k_m等GGUF量化参数的含义 |
| 你现在不仅能理解大模型的原理,更能将它们部署到普通设备上,开启本地化、低成本、高隐私的AI应用新范式。 | |
| 🔮 敬请期待! 在下一章中,我们将继续深入**《推理链路与部署机制》,探索LLaMA.cpp所依赖的《GGUF模型格式结构与参数解析》**,彻底搞懂这种模型文件的"档案"! |