一、引言
最近一段时间笔者作为研发人员参与了公司大大小小的Agent功能实现,在开发的过程中了解到了一个名叫 Browser-Use的项目(Browser Use),这个项目提供了一种方案可以通过自然语言与大模型进行交互然后由大模型来操作浏览器。
其实浏览器自动化并不稀奇,只要是做过自动化测试的朋友都知道playwright和Selenium 两个鼎鼎大名的浏览器自动化测试工具,其实Browser-Use项目也是基于playwright技术加上视觉大模型来实现的。也就是因为基于视觉模型,所以使用下来感觉整体速度不是很快,但是基本的功能是可以实现的。
由于官方网站的模型是基于OpenAI的,在国内大多数公司可能还是倾向使用国内的开源大模型,所以本文介绍的方案是基于qwen2.5-vl-72b 模型为主体来实现大模型操作浏览器的功能。
二、案例效果演示
任务1: 打开www.baidu.com 搜索周杰伦的百度百科,并计算周杰伦今年应该是多大年纪
任务分析:这个案例首先大模型首先需要驱动浏览器打开百度百科,然后还需要在百度百科上检索周杰伦的出生年月,最后获取当前年份并做计算得出周杰伦的年龄。整体来说算是一个有点复杂的任务。
任务执行效果:
程序运行之后,自动唤起一个浏览器,界面大致是这样的:
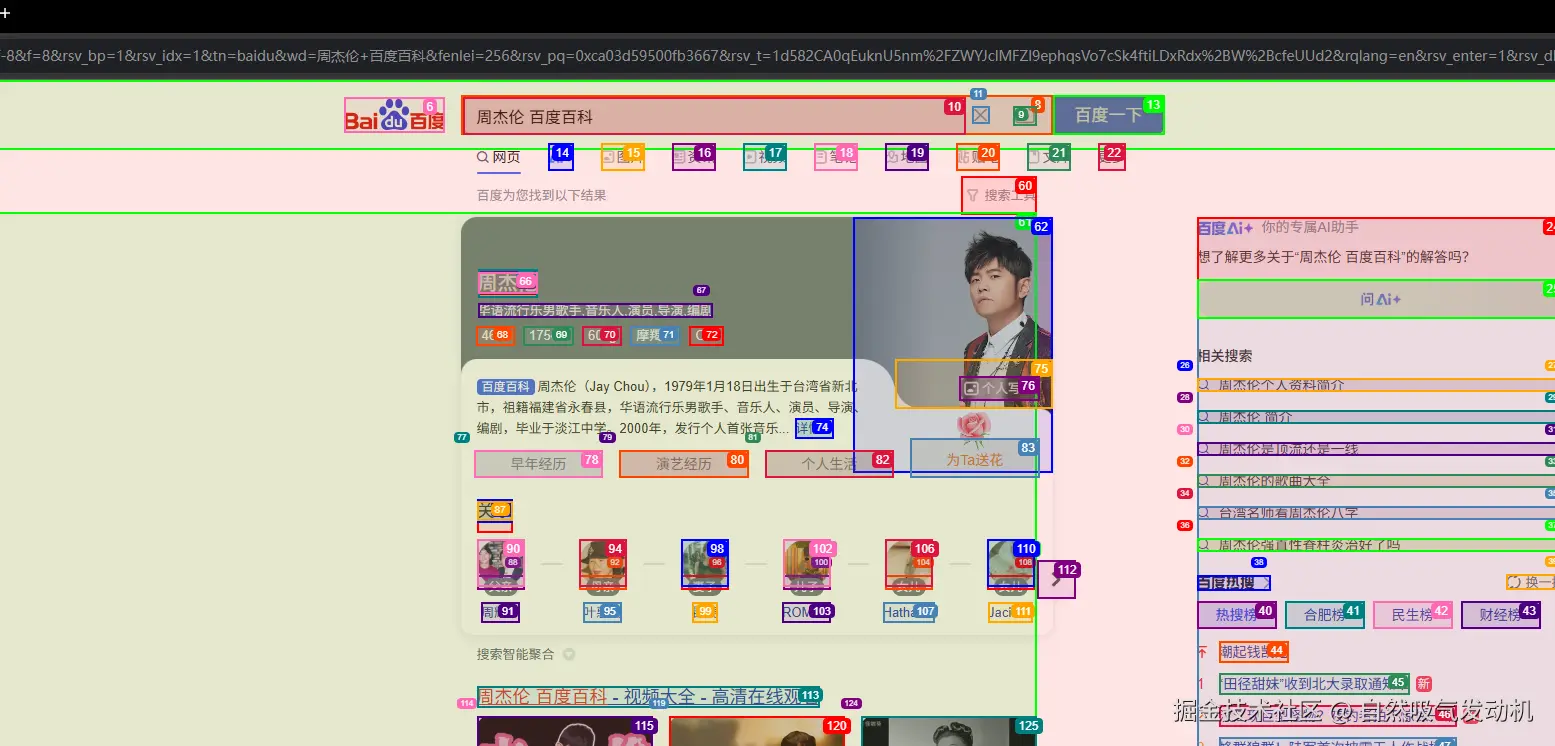
上面各种框选的部分是用于找出当前页面可以点击的部分以及关键元素。此外从运行过程中看打开的浏览器并非我本地自带的浏览器而是使用了PlayWright自带的浏览器驱动。
从代码的控制台的日志输出可以看出,整体运行步骤中是存在大模型的思考动作的整体过程是分步骤进行的,并在最终给出的Result:"周杰伦出生于1979年,截至2025年8月4日,他的年龄是46岁"
(PS:可以看下这里的截图中的Token消耗,真的可以说是非常巨大了这么简单的任务就消耗了111K的token ,钱包简直在滴血)

任务2: 浏览器地址栏输入 juejin.cn/ 打开稀土掘金网站 点击签到按钮进行签到
任务分析:这个任务因为需要进行登录,我希望不同于任务1,我需要程序调用我本地安装的浏览器,此外还需要精准识别页面按钮并进行点击。
任务执行效果:
首先页面唤起一个浏览器,这里我代码里面做了调整直接唤起的是我本地电脑安装的的chrome浏览器(截图中可以看出因为我之前在本地的浏览器登陆过掘金,所以无需登录),随后正确点击了签到按钮进行了签到:
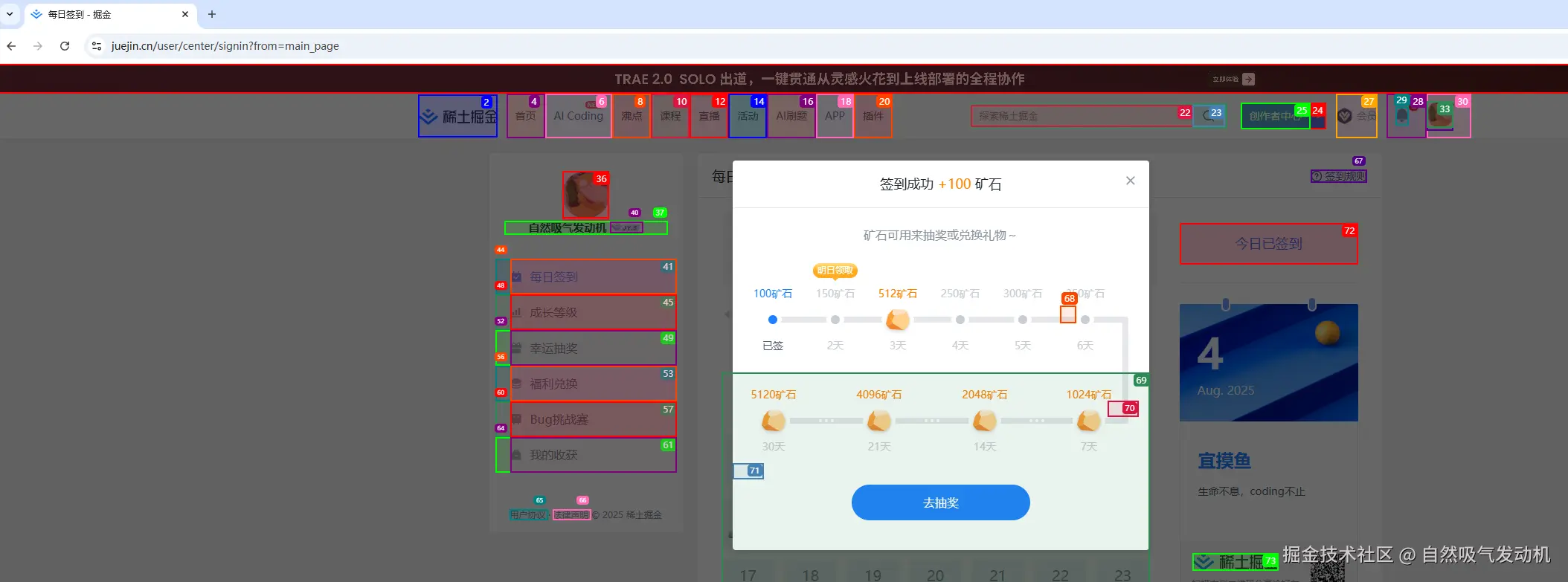
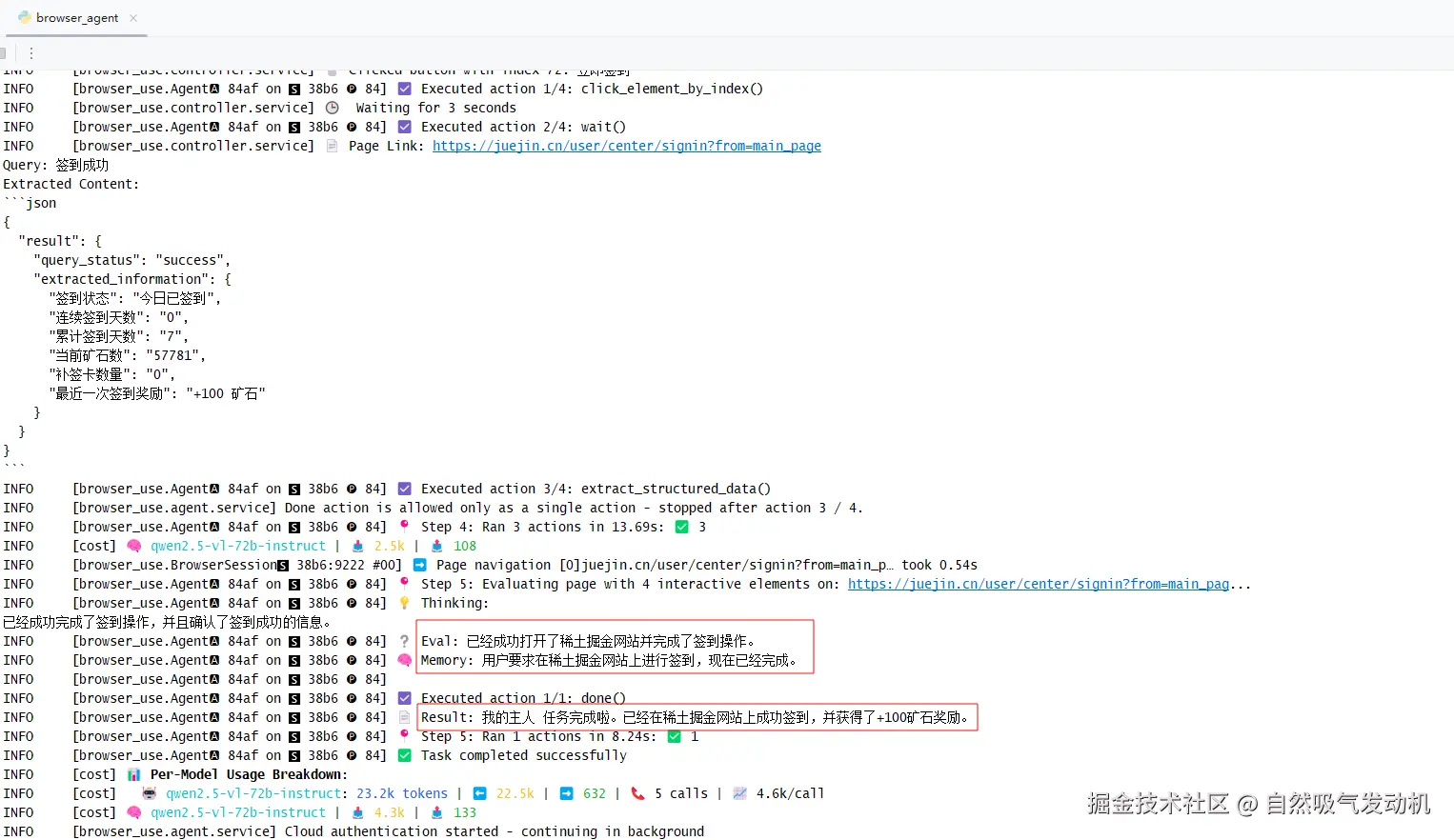
在程序控制台层面也进行了有效输出,这里我还修改了大模型的提示词,所以任务的输出结果会更人性(好玩)一点,这里我还是使用打字的方式告诉大模型去掘金签到,如果外接一个TTS语音转文字工具,动动嘴让大模型替你完成掘金签到不是梦
三、技术细节解密
在上面一节的案例效果展示中,展示了如何切换使用 Playwright浏览器驱动 和 本地自带浏览器 来完成任务,也演示了如何去修改提示词来实现不同的执行行为,下面针对这些细节问题,进行实现细节的说明。
3.1 关键代码说明
我们先来看看关键部分的代码,其实非常简单:
python
import asyncio
from browser_use import Agent
async def main():
agent =Agent(
task="打开http://www.baidu.com 搜索周杰伦的百度百科,并计算周杰伦今年应该是多大年纪",
llm=llm
)
result = await agent.run()
print(result)
asyncio.run(main())上面的代码就是第一个案例的实际运行的核心代码,这里引入的 Agent 类来自于 browser_use的官方依赖包中,我们只需要指定Task,运行这个main方法就可以自动打开一个浏览器,并执行task中描述的任务,可以说是相当简单了。
但是假如我们需要修改下Agent的提示词,此外我希望Agent不要使用PlayWright自带的浏览器驱动而是使用本地安装的浏览器应用程序,又该怎么进行实现呢?其实代码也非常简单, 只需将上述代码做下面这样的简单修改:
python
browser_session = BrowserSession(
executable_path='C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe',
user_data_dir='~/.config/browseruse/profiles/default',
)
browser_session = BrowserSession(browser_pid=60256)
override_system_message = "任务执行完成后请回复:我的主人 任务完成啦"
async def main():
agent = Agent(
task="浏览器地址栏输入 https://juejin.cn/ 打开稀土掘金网站 点击签到按钮进行签到",
llm=llm,
browser_session=browser_session,
override_system_message=override_system_message,
)
result = await agent.run()
print(result)
asyncio.run(main())在上面的这段代码中我们为Agent额外添加了 browser_session 和 override_system_message 两个新的参数
- override_system_message
修改Agent的提示词其实官方更为推荐使用"extend_system_message" 参数,他会继承Agent之前的默认提示词,并将你设定的提示词放在系统默认提示词的后面,这里使用的override_system_message 则是完全的复写了系统提示词。
- browser_session
这个参数让我们能够实现使用本地浏览器的功能,注意如果使用本地的浏览器,需要本地的浏览器开启debug端口,这个可以自行百度,这里我直接写了一个windows的powerShell脚本来方便测试,通过这个脚本可以开启本地9222浏览器调试端口
powershell
# 关闭所有 Chrome 进程
taskkill /f /im chrome.exe
# 启动带调试端口的 Chrome
$chromePath = "C:\Program Files\Google\Chrome\Application\chrome.exe"
$debugPort = 9222
$userDataDir = "C:\ChromeDebugProfile"
Start-Process -FilePath $chromePath -ArgumentList "--remote-debugging-port=$debugPort", "--user-data-dir=$userDataDir"使用本地浏览器的好处在于我们本地的浏览器有很多cookie和登录记录,免去了需要输入密码的麻烦,尤其现在许多网站还开启了MFA 验证,每次都要登录就变得非常麻烦。
3.2 如何切换到Qwen-VL视觉模型
从官网介绍中我们可以看出,对于模型的支持最为推荐的还是Google的Gemini 模型,为什么呢?官网也说了 因为便宜!

但是我们在国内大多数公司还是倾向使用DeepSeek或者Qwen这样的开源模型。这里官网也说了使用Qwen模型需要使用OpenAI的compatibale API 进行包装,具体如何包装官网没说,通过仔细研究OpenAI的API的定义,笔者也是成功完成了模型适配,大致代码如下:
python
# from langchain_openai import ChatOpenAI
from typing import Optional, Literal
from browser_use.llm import ChatOpenAI
def create_openai_llm(
model: str,
base_url: Optional[str] = None,
api_key: Optional[str] = None,
temperature: float = 0.0,
**kwargs,
) -> ChatOpenAI:
llm_kwargs = {"model": model, "temperature": temperature, **kwargs}
if base_url:
llm_kwargs["base_url"] = base_url
if api_key:
llm_kwargs["api_key"] = api_key
return ChatOpenAI(**llm_kwargs)这里一定要注意,ChatOpenAI 不要导错包了,这里需要导入成browser_use.llm 包中的 ChatOpenAI, 不要导入成 langchain_openai 的ChatOpenAI 依赖了,通过这个适配方法,我们只需要在.env 文件写入下述信息,并传到这个create_openai_llm中作为入参,即可达到使用Qwen-VL的模型效果:
properties
VL_API_KEY=sk-你自己的sk信息
VL_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
VL_MODEL=qwen2.5-vl-72b-instruct四、总结
通过初步体验browser_use项目,相信读者们对这门技术也有了一定了解,官方网站中还有更多的相关用法,读者可以自行探索。
总体来看,虽然browser_use项目表现出来的效果挺惊艳,并在GitHub上狂揽67K star, 但是还是token消耗大、执行效率低的问题还是存在,大部分情况下如果大模型需要进行数据搜索,使用tavily 更为适合而不是直接唤起浏览器。
事实上目前Agent操作APP界面或者端侧浏览器,往往需要端侧配合做功能定制,使用的长连接+AIDL的技术方案,以达到节省Token和提升响应速度的效果,而不是单纯的依赖视觉模型。
但是这个项目为我们提供了一种愿景,在未来也许我们不需要键盘鼠标来和浏览器进行交互了,借助大模型的自然语言理解能力,也许未来我们可以直接和浏览器进行对话沟通让浏览器按照我们的需求进行工作。
例如我们需要做浏览器的自动化测试,只需要和大模型进行自然语言沟通 ,向Agent下达一个定时任务 "每天22点登录一次主站检查一次商品列表的搜索功能" agent就可以自动完成一切。此外如果让应用外接语音之后操作浏览器的行为直接变成了语音对话交互,就有可能实现多个浏览器并行操作,也可能带来巨大的效率提升。