Node.js 凭借其非阻塞 I/O 和事件驱动模型,在后端开发中占据重要地位。但提及 "单线程" 这一特性时,很多开发者会困惑:Node.js 如何应对 CPU 密集型任务?如何利用多核 CPU?答案就藏在多进程 与多线程的设计中。本文将从原理到实践,详细解析 Node.js 的多进程与多线程机制。
一、Node.js 的 "单线程" 本质:并非绝对单线程
首先需要明确:Node.js 的 "单线程" 指的是 "JavaScript 执行线程" 的单线程,而非整个 Node.js 进程只有一个线程。
Node.js 进程包含多个线程:
-
JavaScript 主线程:执行用户编写的 JS 代码,受 V8 引擎限制,单线程执行。
-
I/O 线程:由 libuv 库管理(Node.js 的底层事件循环库),负责处理文件、网络等 I/O 操作(如 fs 模块的异步 API、HTTP 请求等),这些操作在独立线程中执行,完成后通过事件循环通知主线程。
-
其他线程:如定时器线程(处理 setTimeout/setInterval)、DNS 解析线程等。
单线程的优势与局限
-
优势:避免多线程切换的开销,适合 I/O 密集型任务(如 API 服务、数据库交互),代码逻辑简单(无需处理线程同步问题)。
-
局限:
-
无法利用多核 CPU(单个 JS 线程只能占用一个核)。
-
CPU 密集型任务(如大量计算、数据处理)会阻塞主线程,导致事件循环停滞,影响整个应用响应速度。
-
为解决这些问题,Node.js 提供了多进程 和多线程两种方案。
二、多进程:通过独立进程利用多核
多进程方案的核心是:通过创建多个独立的 Node.js 进程,让每个进程运行在不同的 CPU 核心上,从而利用多核资源。每个进程拥有独立的 V8 引擎、内存空间和事件循环,进程间通过IPC(进程间通信) 机制交互。
1. child_process:创建独立子进程
child_process 模块是 Node.js 内置的多进程工具,用于创建子进程(可以是 Node 脚本、其他语言程序等)。常见 API 包括 spawn、exec、execFile、fork(专为 Node 脚本设计)。
示例:用 fork 创建 Node 子进程
fork 是 spawn 的特殊形式,专门用于创建 Node 子进程,会自动建立 IPC 通道,方便父子进程通信。
父进程(parent.js) :
javascript
const { fork } = require('child_process');
const child = fork('./child.js'); // 创建子进程
// 父进程向子进程发送消息
child.send({ type: 'task', data: [1, 2, 3, 4] });
// 接收子进程的消息
child.on('message', (result) => {
console.log('子进程返回结果:', result); // 输出:子进程返回结果:10
});
// 监听子进程退出
child.on('exit', (code) => {
console.log(`子进程退出,退出码:${code}`);
});子进程(child.js) :
arduino
// 接收父进程的消息
process.on('message', (msg) => {
if (msg.type === 'task') {
const sum = msg.data.reduce((a, b) => a + b, 0);
// 向父进程发送结果
process.send(sum);
// 完成后退出
process.exit(0);
}
});2. cluster:专为服务端设计的多进程集群
cluster 模块基于 child_process.fork 实现,专为网络服务(如 HTTP 服务器)设计,解决了两个核心问题:
- 多个进程共享同一个端口(避免端口占用冲突)。
- 自动实现负载均衡(分发客户端请求到不同进程)。
cluster 的工作原理
- 主进程(master) :负责管理工作进程(worker),不处理业务逻辑。
- 工作进程(worker) :由主进程通过
fork创建,处理实际的客户端请求(如 HTTP 请求)。 - 端口共享 :主进程监听端口后,将连接转发给工作进程(底层通过
SO_REUSEADDR实现)。 - 负载均衡:默认使用 "轮询(round-robin)" 策略分发请求(Windows 系统因底层限制,使用 "随机" 策略)。
示例:用 cluster 创建 HTTP 服务集群
javascript
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length; // 获取 CPU 核心数
if (cluster.isPrimary) { // 主进程逻辑
console.log(`主进程 ${process.pid} 启动`);
// 根据 CPU 核心数创建工作进程
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
// 监听工作进程退出,自动重启
cluster.on('exit', (worker, code, signal) => {
console.log(`工作进程 ${worker.process.pid} 退出,重启中...`);
cluster.fork();
});
} else { // 工作进程逻辑:创建 HTTP 服务器
http.createServer((req, res) => {
res.writeHead(200);
res.end(`由工作进程 ${process.pid} 处理\n`);
}).listen(8000);
console.log(`工作进程 ${process.pid} 启动`);
}运行后,访问 http://localhost:8000 会发现请求被不同的工作进程处理(每次返回的 pid 不同),实现了多核利用。
多进程的优缺点
-
优点:
- 充分利用多核 CPU,解决单线程的性能瓶颈。
- 进程隔离:单个进程崩溃不会影响其他进程,提高应用稳定性。
-
缺点:
- 内存占用高:每个进程有独立的 V8 引擎和内存空间(一个 Node 进程约占用 30-50MB 内存),不适合创建大量进程。
- 通信成本高:进程间通过 IPC 通信(消息传递),无法直接共享内存,数据传递需要序列化 / 反序列化(如 JSON)。
三、多线程:通过共享内存提升计算效率
Node.js 在 v10.5.0 中正式引入 worker_threads 模块,支持创建多线程(工作线程),用于处理 CPU 密集型任务。与多进程不同,线程共享同一进程的内存空间,因此通信成本更低。
线程与进程的核心区别
- 进程:操作系统资源分配的基本单位,拥有独立的内存、CPU 资源。
- 线程:进程内的执行单元,共享进程的内存空间(如堆内存),但有独立的栈内存(存储局部变量)。
worker_threads 模块的使用
worker_threads 允许创建多个工作线程,主线程与工作线程通过消息队列 通信,也可通过 SharedArrayBuffer 共享内存(需注意同步问题)。
示例:用工作线程处理计算任务
主线程(main.js) :
javascript
const { Worker } = require('worker_threads');
// 创建工作线程
const worker = new Worker('./worker.js', {
workerData: { numbers: [1, 2, 3, 4, 5] } // 初始化数据(复制到工作线程)
});
// 接收工作线程的结果
worker.on('message', (sum) => {
console.log('计算结果:', sum); // 输出:计算结果:15
});
// 监听错误
worker.on('error', (err) => console.error('线程错误:', err));
// 监听退出
worker.on('exit', (code) => {
if (code !== 0) console.log(`线程退出,退出码:${code}`);
});工作线程(worker.js) :
javascript
const { parentPort, workerData } = require('worker_threads');
// 从 workerData 获取初始数据
const numbers = workerData.numbers;
// 执行 CPU 密集型计算(求和)
const sum = numbers.reduce((a, b) => a + b, 0);
// 向主线程发送结果
parentPort.postMessage(sum);共享内存与同步
工作线程可以通过 SharedArrayBuffer 共享内存(避免数据复制),但需通过 Atomics 模块保证同步(防止多个线程同时修改数据导致的 "竞态条件")。
示例:共享内存与原子操作
javascript
// 主线程
const { Worker, isMainThread } = require('worker_threads');
const buffer = new SharedArrayBuffer(4); // 4字节共享内存(存储一个32位整数)
const arr = new Int32Array(buffer);
arr[0] = 0; // 初始值
if (isMainThread) {
// 创建两个工作线程,同时修改共享内存
new Worker(__filename);
new Worker(__filename);
// 等待线程执行完成
setTimeout(() => {
console.log('最终结果:', arr[0]); // 输出:最终结果:2(两个线程各加1)
}, 100);
} else {
// 工作线程:通过 Atomics 原子操作修改共享内存
Atomics.add(arr, 0, 1); // 原子性地给 arr[0] 加1
}多线程的优缺点
-
优点:
- 内存占用低:线程共享进程内存,适合创建多个线程处理计算任务。
- 通信高效:共享内存避免数据复制(需配合同步机制)。
-
缺点:
- 线程安全问题:共享内存可能导致竞态条件,需通过
Atomics等工具保证同步,增加代码复杂度。 - 无法完全隔离:单个线程崩溃可能影响整个进程(需通过
try/catch捕获错误)。
- 线程安全问题:共享内存可能导致竞态条件,需通过
四、多进程 vs 多线程:如何选择?
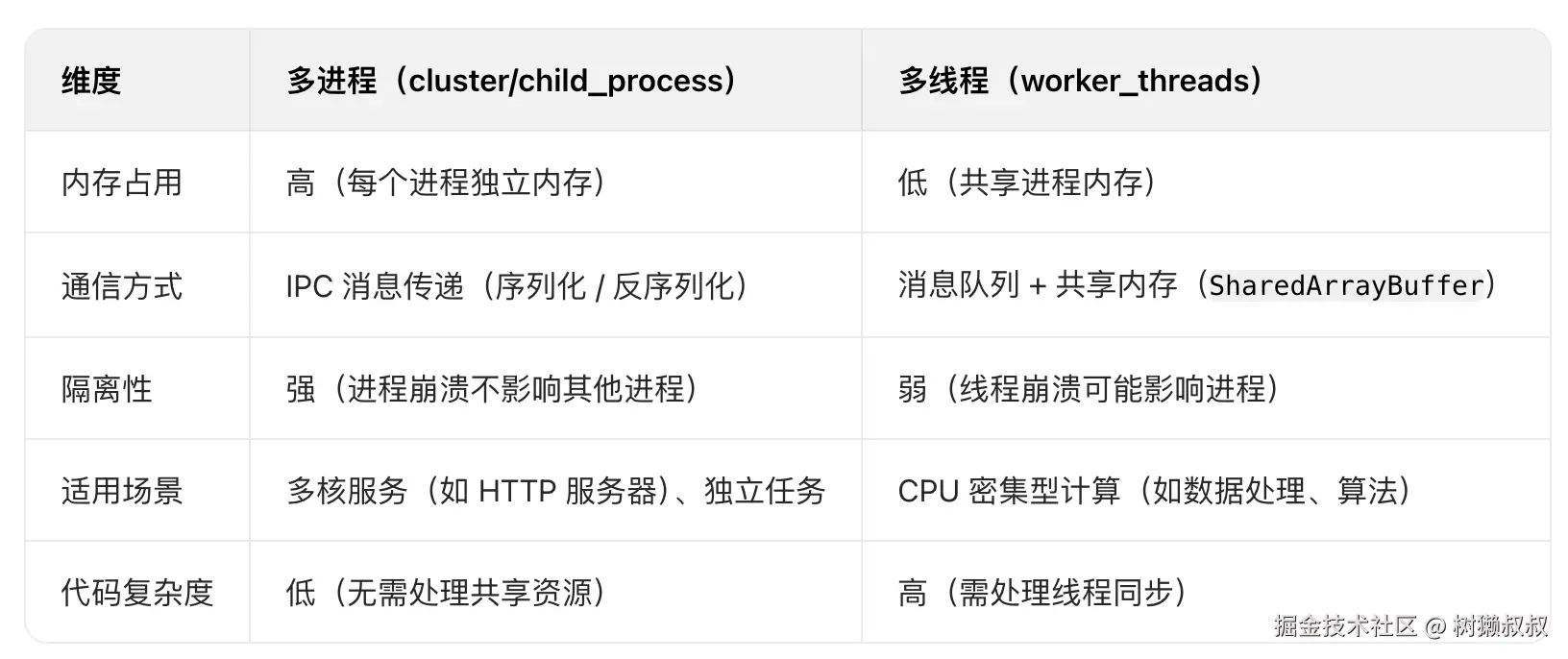
实践建议
- I/O 密集型服务 :优先用
cluster模块创建多进程,利用多核处理并发请求(如 API 服务器、数据库中间件)。 - CPU 密集型任务 :优先用
worker_threads(如数据统计、图片处理),避免阻塞主线程。 - 混合场景:多进程 + 多线程结合(如主进程管理多个工作进程,每个工作进程内用多线程处理计算任务)。
- 资源限制:进程数量不宜过多(建议与 CPU 核心数一致),线程数量根据任务复杂度调整(避免过多线程切换开销)。
五、总结
Node.js 的 "单线程" 并非绝对,其通过多进程和多线程机制突破了性能瓶颈:
-
多进程 (
cluster/child_process)通过独立进程利用多核,适合构建高可用的网络服务,优势是隔离性强,缺点是内存占用高。 -
多线程 (
worker_threads)通过共享内存提升计算效率,适合处理 CPU 密集型任务,优势是内存高效,缺点是需处理线程安全问题。
在实际开发中,需根据任务类型(I/O 密集 / CPU 密集)、资源限制(内存、CPU 核心数)选择合适的方案,甚至结合两者实现最优性能。理解 Node.js 的多进程与多线程机制,是编写高性能 Node 应用的关键。