目录
[① 导入标准库中的 time 模块的语句](#① 导入标准库中的 time 模块的语句)
[② 打开指定网址](#② 打开指定网址)
[③ 关闭标签页](#③ 关闭标签页)
[④ 退出浏览器并释放驱动](#④ 退出浏览器并释放驱动)
[3.1 浏览器最大化 maximize_window ()](#3.1 浏览器最大化 maximize_window ())
[3.2 浏览器最小化 minimize_window ()](#3.2 浏览器最小化 minimize_window ())
[4.1 浏览器的打开位置 set_window_position (0,0)](#4.1 浏览器的打开位置 set_window_position (0,0))
[4.2 浏览器的打开尺寸 set_window_size (0,0)](#4.2 浏览器的打开尺寸 set_window_size (0,0))
[5.1 浏览器截图 get_screenshot_as_file ()](#5.1 浏览器截图 get_screenshot_as_file ())
[5.2 刷新当前网页 refresh ()](#5.2 刷新当前网页 refresh ())
[1. document.getElementById('id值')](#1. document.getElementById('id值'))
[2. document.getElementsByClassName('类名')](#2. document.getElementsByClassName('类名'))
[3. document.getElementsByTagName('标签名')](#3. document.getElementsByTagName('标签名'))
[4. document.getElementsByName('name值')](#4. document.getElementsByName('name值'))
[6.1 ID定位](#6.1 ID定位)
[6.3 CLASS_NAME定位](#6.3 CLASS_NAME定位)
[6.4 TAG_NAME定位](#6.4 TAG_NAME定位)
[6.5 LINK_TEXT定位](#6.5 LINK_TEXT定位)
[6.6 PARTIAL_LINK_TEXT定位](#6.6 PARTIAL_LINK_TEXT定位)
[6.7 CSS_SELECTOR定位](#6.7 CSS_SELECTOR定位)
[6.8 XPATH定位](#6.8 XPATH定位)
[6.9 隐性等待](#6.9 隐性等待)
[7.1 元素点击:click()](#7.1 元素点击:click())
[7.2 输入框元素输入:send_keys(value)](#7.2 输入框元素输入:send_keys(value))
[7.3 输入框元素清空:clear()](#7.3 输入框元素清空:clear())
[7.4 单选、多选、下拉元素交互](#7.4 单选、多选、下拉元素交互)
[7.5 上传元素交互](#7.5 上传元素交互)
[7.6 警告框元素交互](#7.6 警告框元素交互)
[7.7 确认框元素交互](#7.7 确认框元素交互)
[7.8 提示框元素交互](#7.8 提示框元素交互)
[7.9 iframe 嵌套页面的进入、退出](#7.9 iframe 嵌套页面的进入、退出)
[7.10 获取元素文本内容、是否可见](#7.10 获取元素文本内容、是否可见)
[8.1 获取全部标签页句柄](#8.1 获取全部标签页句柄)
[8.2 获取当前标签页的句柄](#8.2 获取当前标签页的句柄)
[8.3 切换标签页](#8.3 切换标签页)
[9.1 多线程的核心概念](#9.1 多线程的核心概念)
[9.2 多线程的基础依赖](#9.2 多线程的基础依赖)
[9.3 多线程执行自动化的基本结构](#9.3 多线程执行自动化的基本结构)
[9.4 应用格式与示例](#9.4 应用格式与示例)
[9.5 注意事项](#9.5 注意事项)
[9.6 多线程与单线程对比](#9.6 多线程与单线程对比)
[10.1 网页前进](#10.1 网页前进)
[10.2 网页后退](#10.2 网页后退)
[11.1 核心原理与应用场景](#11.1 核心原理与应用场景)
[11.2 实现步骤](#11.2 实现步骤)
[步骤 1:启动调试模式的 Chrome 浏览器](#步骤 1:启动调试模式的 Chrome 浏览器)
[步骤 2:获取目标元素的定位信息](#步骤 2:获取目标元素的定位信息)
[步骤 3:编写 Selenium 脚本连接现有浏览器](#步骤 3:编写 Selenium 脚本连接现有浏览器)
[11.3 完整代码示例(连点器案例)](#11.3 完整代码示例(连点器案例))
[11.4 关键配置说明](#11.4 关键配置说明)
[11.5 注意事项](#11.5 注意事项)
[方案一:使用 Python 定时库(轻量级)](#方案一:使用 Python 定时库(轻量级))
[1. 依赖安装](#1. 依赖安装)
[2. 应用格式与示例](#2. 应用格式与示例)
[3. 使用说明](#3. 使用说明)
[1. Windows 系统设置步骤](#1. Windows 系统设置步骤)
[步骤 1:准备可独立运行的脚本](#步骤 1:准备可独立运行的脚本)
[步骤 2:通过 "任务计划程序" 设置定时任务](#步骤 2:通过 “任务计划程序” 设置定时任务)
[2. Linux 系统设置步骤](#2. Linux 系统设置步骤)
[步骤 1:准备脚本并赋予执行权限](#步骤 1:准备脚本并赋予执行权限)
[步骤 2:通过 crontab 设置定时任务](#步骤 2:通过 crontab 设置定时任务)
[3. 关键注意事项](#3. 关键注意事项)
[三、Selenium 自动化综合案例:](#三、Selenium 自动化综合案例:)
[2、本地 HTML 按钮循环点击计数器脚本](#2、本地 HTML 按钮循环点击计数器脚本)
PythonWeb自动化 三方库:Selenium
什么是自动化
自动化是指使用技术手段模拟人工,执行重复性任务,准确率100%,高于人工
自动应用场景
自动化测试
自动化运维
自动化办公
自动化游戏
自动化落地项目
工厂机器人、扫地机器人、AI机器人、办公脚本、游戏脚本等等。基本上所有重复模拟人工的活,在理论上都能完成。
Selenium
web自动化中的老牌知名开源库,支持多种浏览器,如谷歌Chrome,火狐Firefox、微软Edge、苹果Safari等,跨平台兼容性高。
通过浏览器驱动控制浏览器,通过元素定位模拟人工交互,以实现web自动化(无焦点状态依然执行)
无焦点状态可以检点理解为能后台运行
官方技术文档:Selenium
〇、Selenium环境安装
1、安装浏览器(如谷歌Chrome)
打开浏览器点击右上角三个点-帮助-关于Google Chrome
2、查看版本号 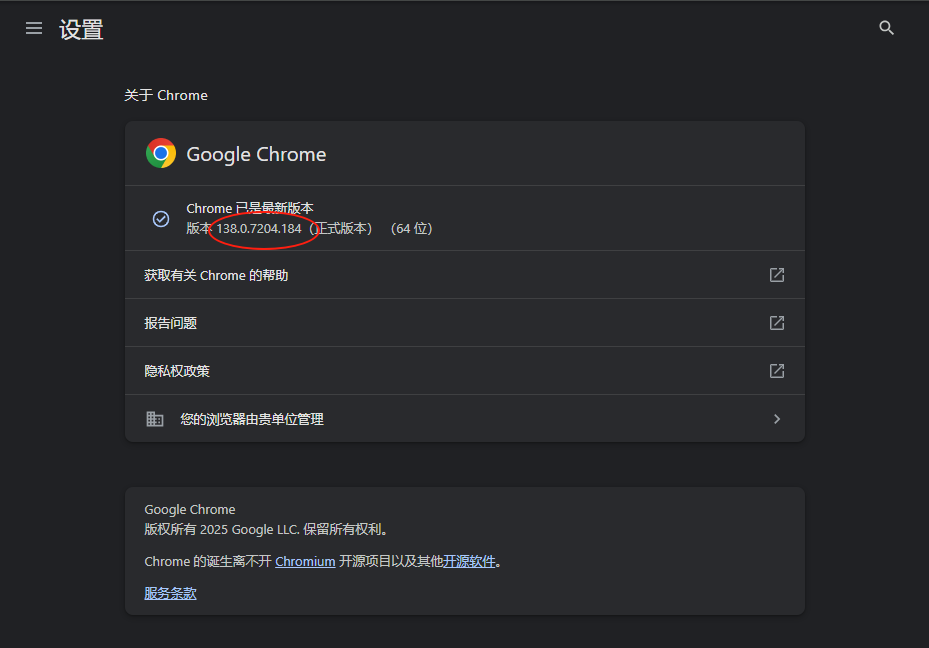
3、浏览器驱动安装
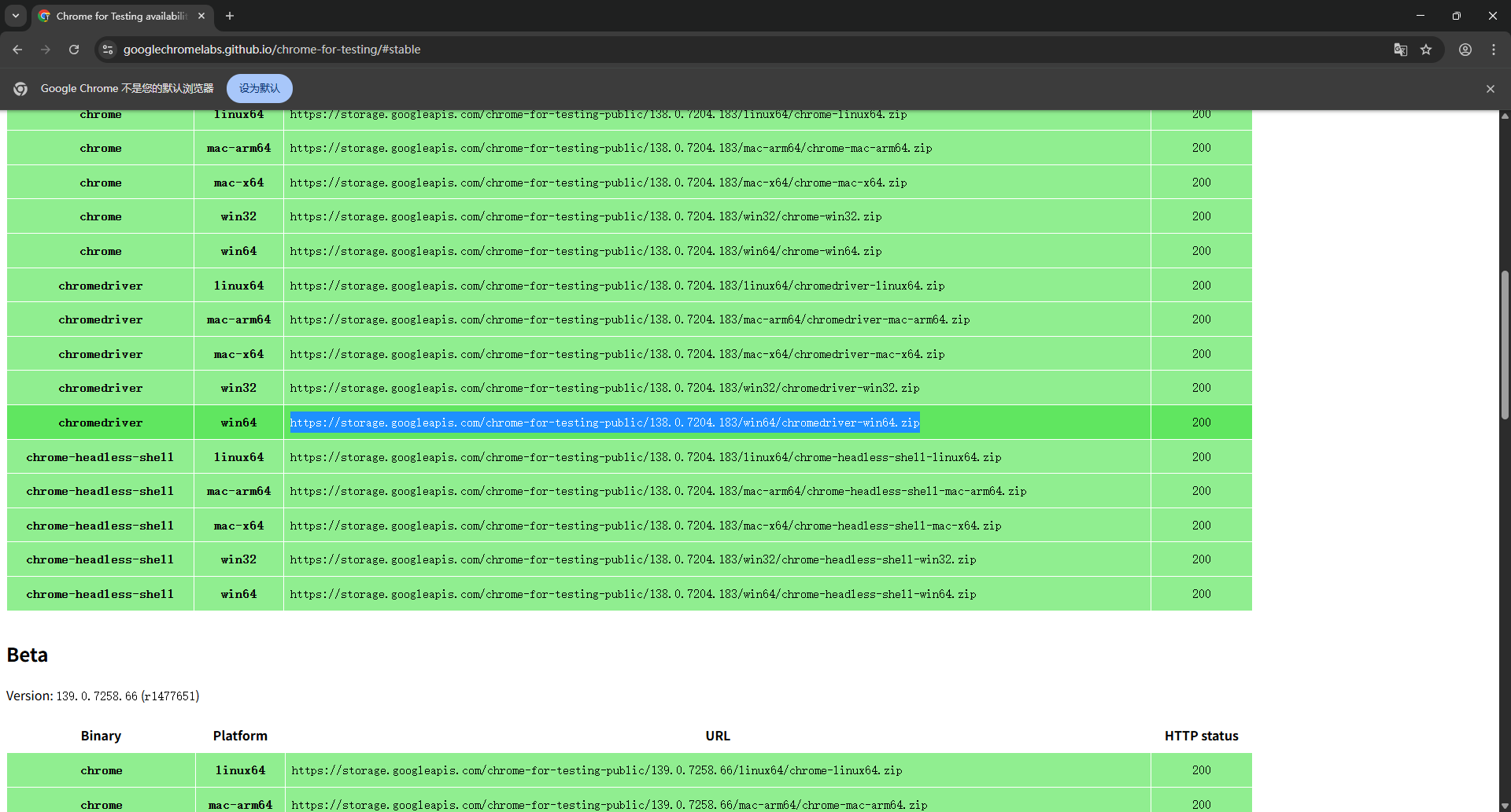
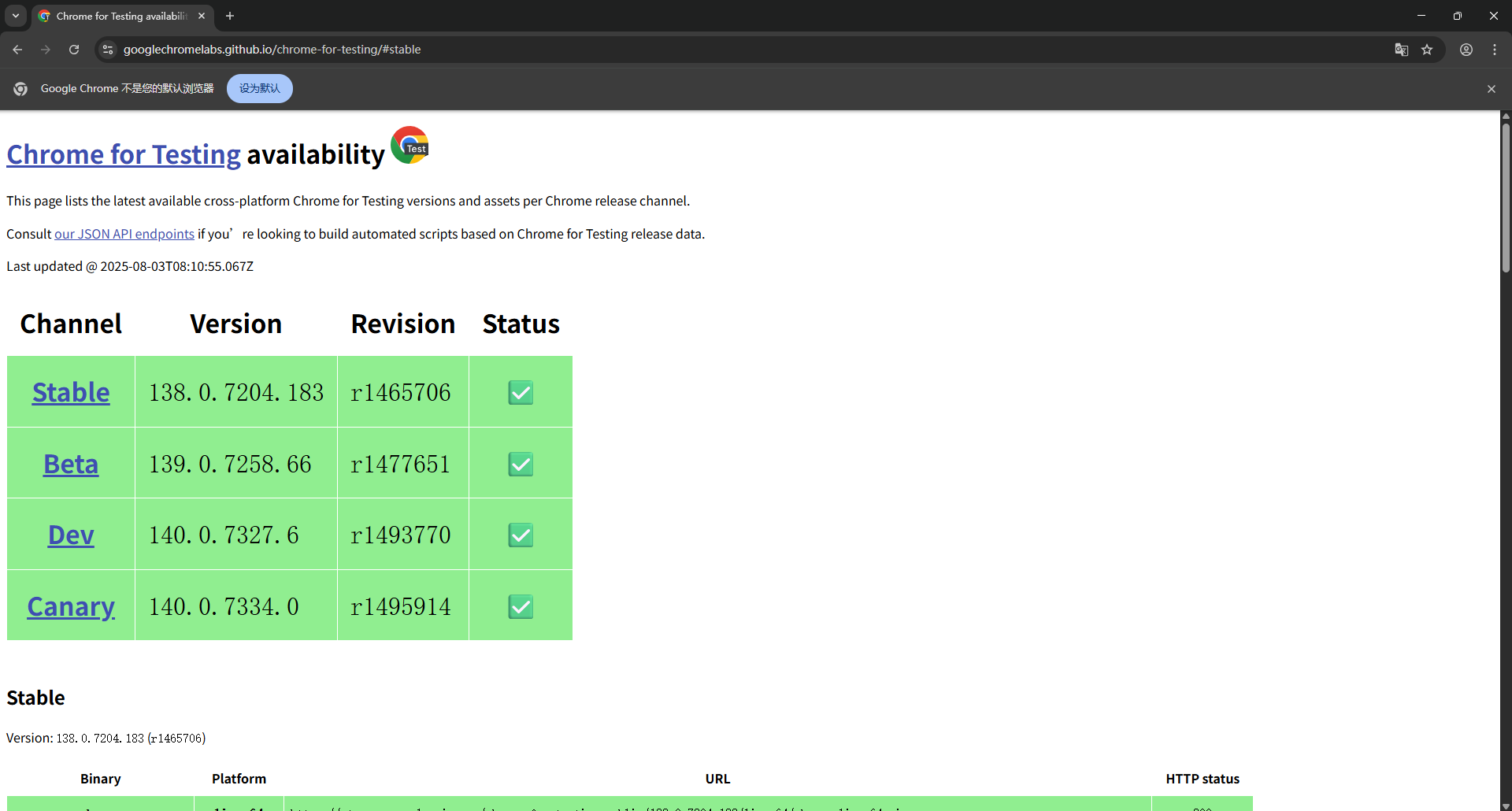
驱动下载:Chrome for Testing availability
点击对应版本注意:驱动版本号要和浏览器版本号对应符合(至少大版本对应,如138.0.xxx)
跳转到对应界面后选择自己的电脑版本(我的是win64),然后复制打开下载地址即可获得驱动
注意:所下载的项目是 chromedriver
4、打开压缩包,将chromedriver.exe复制到pycharm的工程下
这样方便后续项目的进行(只需要在项目中使用相对路径)
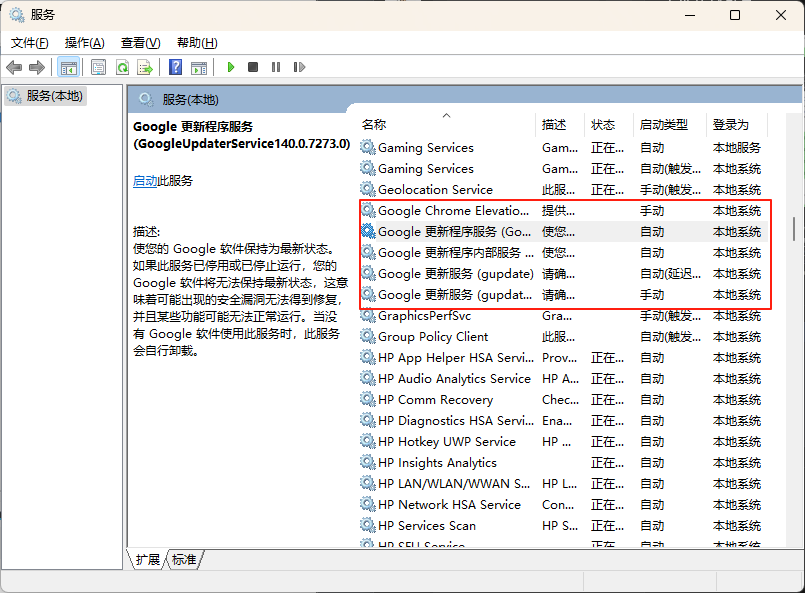
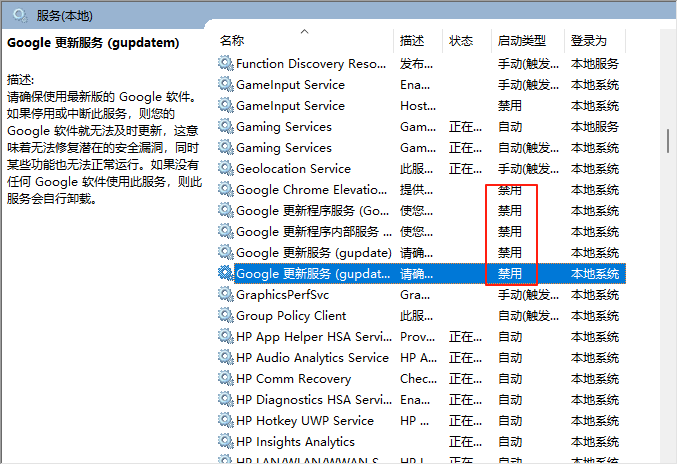
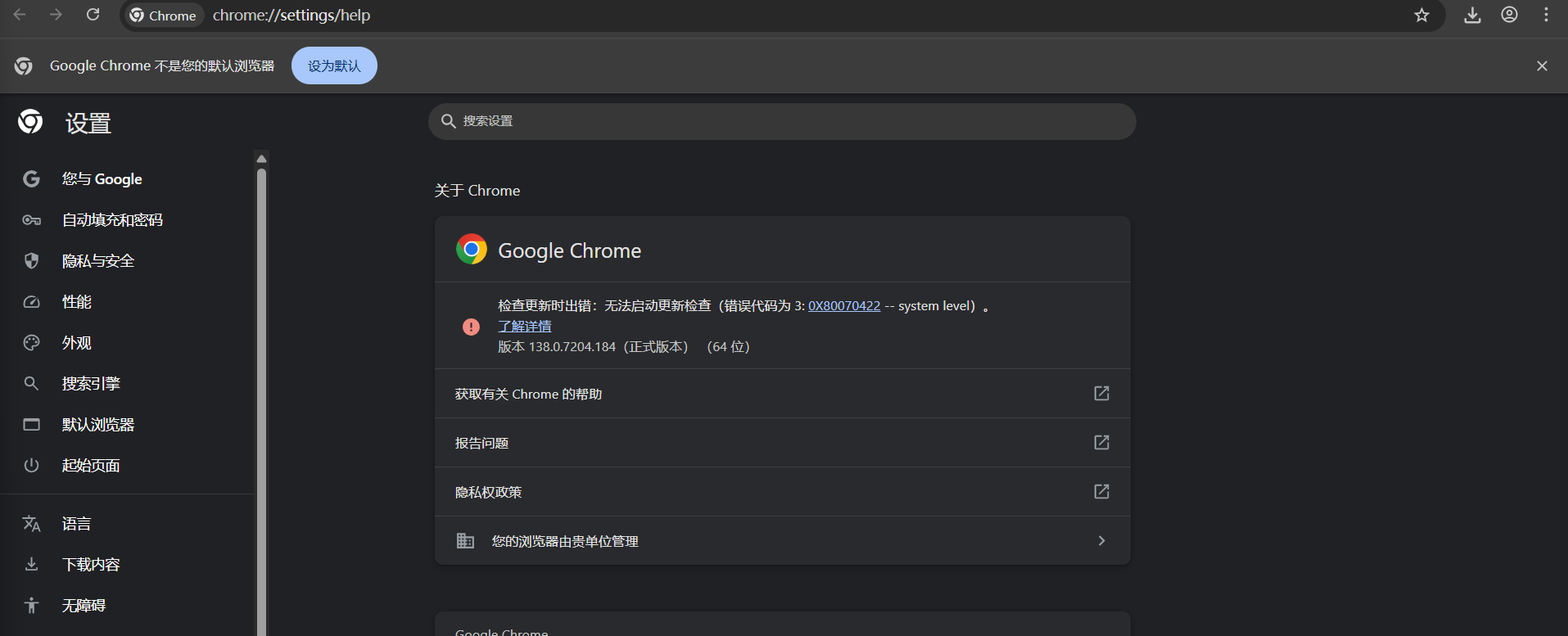
5、关闭浏览器的自动更新(否则更新导致驱动失效)
开始(win键)内搜索 servise.msc 找到 google更新组件全部禁用
全部右击鼠标点击属性,选择禁用,点击应用
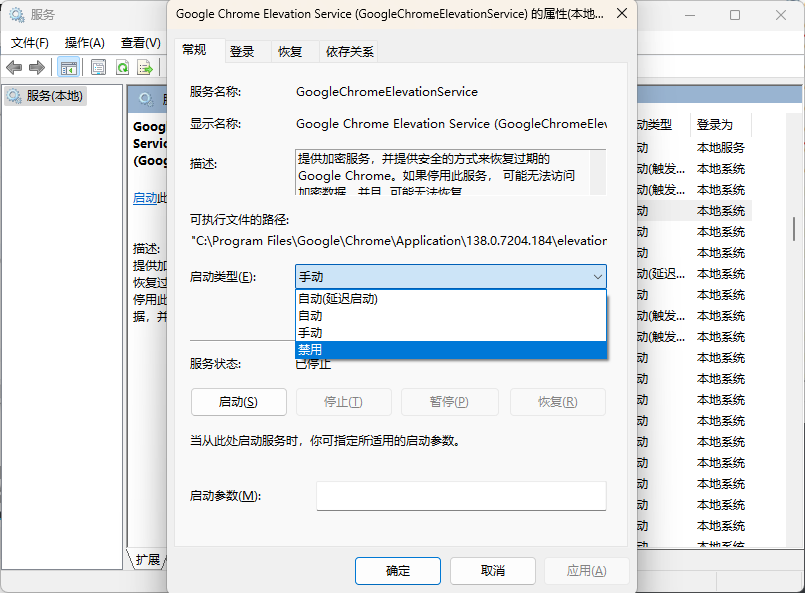
这时再查看浏览器版本就会看到检查更新出错
6、安装三方库:selenium
在PyCharm中安装Python第三方库是一个相对简单的过程,可以通过多种方法实现。以下是几种常用的方法:
方法1:使用PyCharm内置功能安装
- 打开PyCharm并加载项目:
启动PyCharm并打开需要安装第三方库的项目。
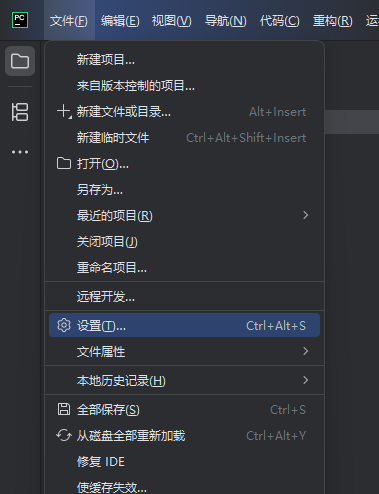
进入设置界面:
点击顶部菜单栏中的"File"(文件)选项,然后选择"Settings"(设置)。
选择Python解释器:
在设置窗口中,选择"Project: Your Project Name"(项目名称),然后点击"Python Interpreter"(Python解释器)。
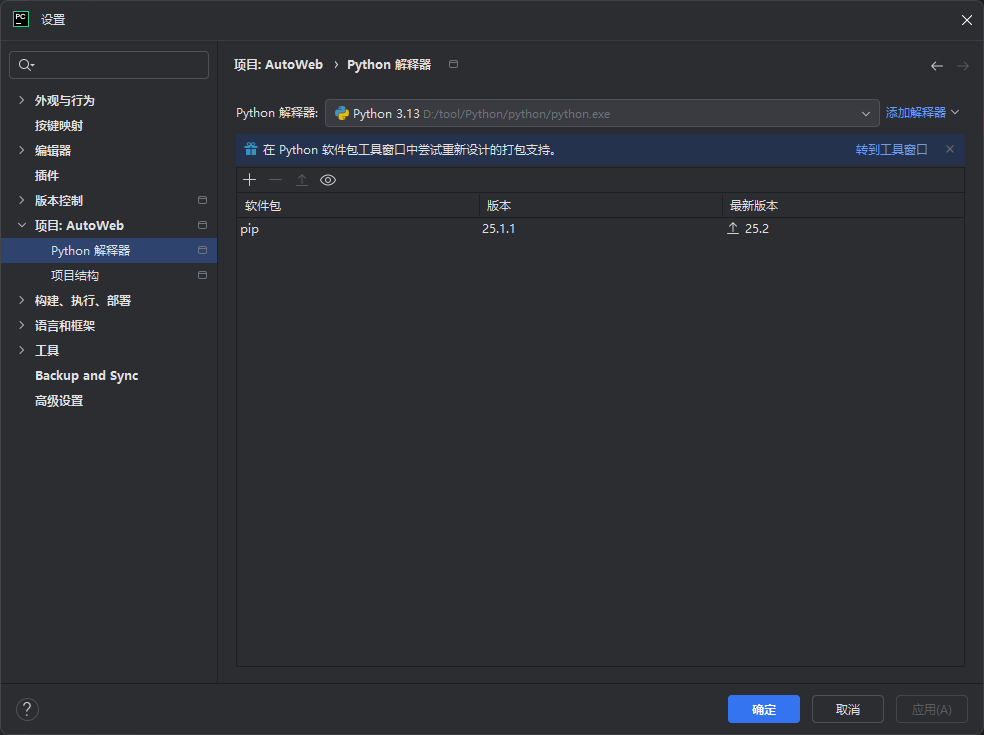
添加第三方库:
在弹出的窗口中,将看到项目当前使用的Python解释器以及已安装的包列表。
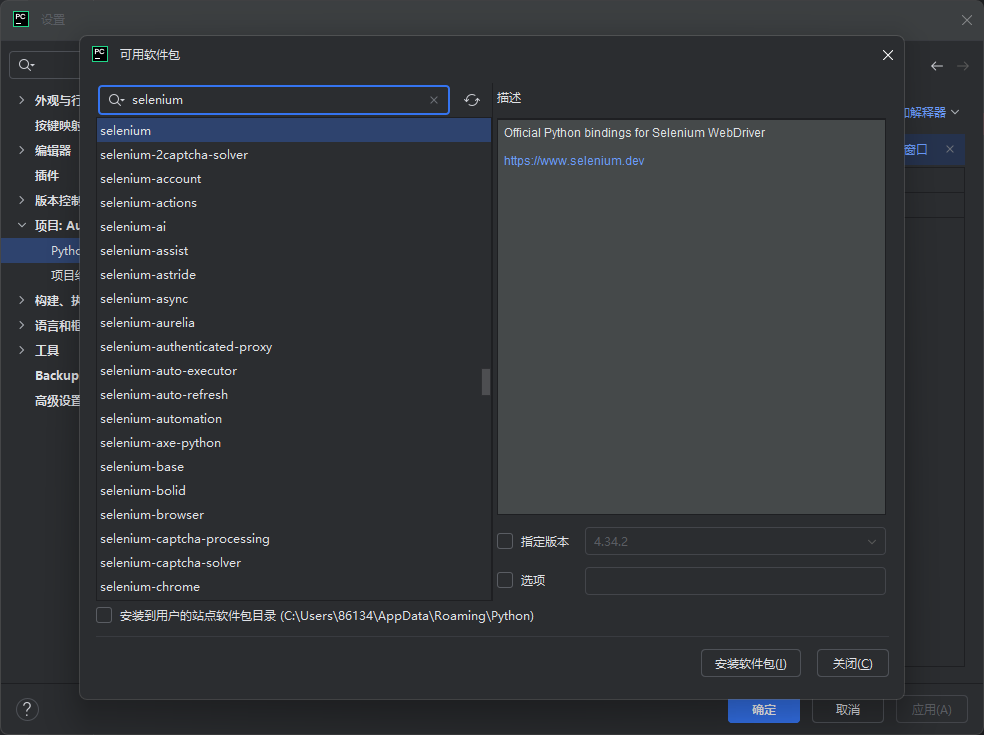
点击右下角的"+"号按钮,然后在弹出的窗口中搜索要安装的第三方库。
找到目标库后,点击其名称,然后点击"Install Package"(安装包)按钮进行安装。
方法2:使用pip命令安装
打开PyCharm终端:
在PyCharm中,可以通过底部工具栏的"Terminal"(终端)窗口打开命令行界面。
输入pip命令:
在终端窗口中,输入pip install 库名来安装所需的第三方库。例如,要安装numpy库,可以输入pip install numpy。
注意:如果pip的下载速度较慢,可以考虑更改pip的下载源为国内的镜像源,如清华大学的镜像源等。
方法3:通过下载wheel文件安装
下载wheel文件: 在PyPI网站或其他可信的第三方库发布网站上,找到目标库的wheel文件(.whl文件)。
将wheel文件放入项目目录: 将下载的wheel文件复制到PyCharm项目的根目录下或指定的文件夹中。
在终端中安装: 打开PyCharm的终端窗口,输入pip install 路径/库名.whl来安装wheel文件。例如,如果wheel文件名为numpy-1.19.4-cp39-cp39-win_amd64.whl,并且位于项目根目录下的wheels文件夹中,则可以输入pip install wheels/numpy-1.19.4-cp39-cp39-win_amd64.whl。
方法4:通过PyCharm的提示安装
引入第三方库: 在PyCharm的编辑器中编写代码时,如果尝试引入一个尚未安装的第三方库,PyCharm会在代码旁边显示一个红色的波浪线或提示信息。
根据提示安装: 将鼠标移动到红色的波浪线或提示信息上,PyCharm会显示一个快捷菜单。在菜单中选择"Install 库名"选项,PyCharm将自动下载并安装该库。
注意事项
在安装第三方库之前,请确保已正确配置Python解释器,并且已经安装了与项目兼容的pip版本。
如果在安装过程中遇到问题,可以检查PyCharm中的Python解释器设置,或尝试在终端中使用pip命令进行安装。
有些第三方库可能需要额外的依赖项或配置才能正常工作。在这种情况下,建议查阅相关文档或使用官方网站上的说明进行安装和配置。
通过以上方法,可以轻松地在PyCharm中安装所需的Python第三方库,从而扩展Python程序的功能和性能。

一、基础操作
1、创建、设置、打开浏览器
①导包
python
# 导包
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动这三行代码都是 Selenium 自动化测试框架中用于导入必要组件的语句,分别对应不同的功能模块,解释如下:
from selenium import webdriver
从 Selenium 库中导入
webdriver模块,这是 Selenium 的核心组件之一。
webdriver提供了操作各种浏览器(如 Chrome、Firefox、Edge 等)的接口,通过它可以创建浏览器实例、打开网页、模拟用户操作(点击、输入等)。例如后续代码中
webdriver.Chrome()就是通过这个模块创建 Chrome 浏览器实例。
from selenium.webdriver.chrome.options import Options
从 Selenium 的 Chrome 驱动模块中导入
Options类,专门用于配置 Chrome 浏览器的启动参数。通过
Options可以设置浏览器的各种选项,比如:是否禁用启动时最大化窗口、禁用弹窗、设置无头模式(无界面运行)、保持浏览器不自动关闭等。代码中的
q1 = Options()就是创建了一个选项对象,用于后续配置 Chrome 的启动行为。
from selenium.webdriver.chrome.service import Service
从 Selenium 的 Chrome 驱动模块中导入
Service类,用于管理 ChromeDriver(Chrome 浏览器驱动程序)的服务。ChromeDriver 是连接 Selenium 代码和 Chrome 浏览器的桥梁,
Service类负责启动、管理这个驱动程序的进程。代码中
Service('chromedriver.exe')就是通过该类指定 ChromeDriver 的路径,确保 Selenium 能正确找到并启动驱动。简单来说,这三行代码分别导入了:
操作浏览器的核心接口(
webdriver)配置 Chrome 浏览器选项的工具(
Options)管理 Chrome 驱动程序的服务(
Service)它们共同构成了 Selenium 启动和控制 Chrome 浏览器的基础依赖。
②设置浏览器
python
# 创建设置浏览器对象
q1 = Options()
# 禁用沙盒模式(通常用于Linux环境,Windows环境可省略,但不影响)
q1.add_argument('--no-sandbox')
# 保持浏览器的打开状态(正确设置为布尔值True)
q1.add_experimental_option("detach", True)
# 创建并启动浏览器
a1 = webdriver.Chrome(service=Service('chromedriver.exe'), options=q1) # 绑定浏览器驱动路径
# 可选:打开一个测试网页验证
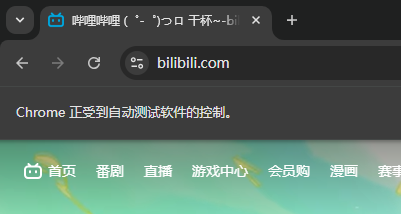
a1.get("https://www.bilibili.com")
q1 = Options()创建一个 Chrome 浏览器配置对象,用于设置浏览器的启动参数和行为。对象名自己起
q1.add_argument('--no-sandbox')向浏览器配置中添加命令行参数--no-sandbox,作用是禁用 Chrome 的沙盒模式。沙盒模式是 Chrome 的安全机制,在 Linux 系统中可能因权限问题导致浏览器无法启动,禁用后可解决此类问题(Windows 系统通常无需此设置,但加上也不影响)。
q1.add_experimental_option("detach", True)设置实验性选项detach为True,作用是让浏览器在脚本执行完毕后保持打开状态(默认情况下,脚本结束后浏览器会自动关闭)。
a1 = webdriver.Chrome(service=Service('chromedriver.exe'), options=q1)根据配置启动 Chrome 浏览器:
Service('chromedriver.exe')指定 Chrome 驱动程序的路径 (确保chromedriver.exe与代码同目录或填写完整路径)
options=q1将之前配置的浏览器参数应用到启动过程最终返回一个浏览器实例
a1,后续可通过该实例操作浏览器
a1.get("https://www.bilibili.com")调用浏览器实例的get()方法,在浏览器中打开指定网址(这里是 B 站首页)。
总结:
-
创建浏览器配置对象:对象名 = Options()
-
向浏览器配置中添加命令行参数: 对象名.add_argument('命令行参数')
-
配置浏览器行为:对象名.add_experimental_option("实验性选项名称", 值)
detach 主要用于控制浏览器进程与驱动程序的关联关系
-
仅适用于 Chrome 浏览器,其他浏览器(如 Firefox、Edge)不支持该选项。
-
必须传入布尔值(
True或False),传入其他类型(如字符串、列表)会导致参数解析错误。 -
正式环境的自动化脚本通常不需要开启(保持默认关闭),避免残留大量未关闭的浏览器进程占用资源。
-
-
创建 Chrome 浏览器实例并应用配置:浏览器实例变量 = webdriver.Chrome(service=Service(驱动路径), options=配置对象)
-
浏览器实例变量:自定义变量名(如driver、browser、a1),用于接收创建的浏览器实例,后续通过该变量操作浏览器。 -
webdriver.Chrome():固定语法,用于初始化 Chrome 浏览器。 -
service=Service(驱动路径):必选参数,通过Service类指定 ChromeDriver 的路径(支持相对路径或绝对路径,如Service('D:/tools/chromedriver.exe'))。 -
options=配置对象:可选参数,传入通过Options()创建的配置对象(如q1),用于应用浏览器启动参数、实验性选项等配置。
-
这些基本上就是一个脚本框架,后续代码在此基础上编辑就行
python
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
import time #导入标准库中的 time 模块
#设置浏览器,启动浏览器
def she():
# 创建设置浏览器对象
q1 = Options()
# 禁用沙盒模式(通常用于Linux环境,Windows环境可省略,但不影响)
q1.add_argument('--no-sandbox')
# 保持浏览器的打开状态(正确设置为布尔值True)
q1.add_experimental_option("detach", True)
# 创建并启动浏览器
a1 = webdriver.Chrome(service=Service('chromedriver.exe'), options=q1) # 绑定浏览器驱动路径
return a1
a1=she()2、打开、关闭网页、关闭浏览器
① 导入标准库中的 time 模块的语句
import time
说明 :time模块用于提供时间相关的功能,在自动化脚本中常用来添加等待(如time.sleep(秒数)实现强制等待),避免操作执行过快导致元素未加载完成。
② 打开指定网址
a1.get("https://www.bilibili.com")
应用格式 :driver对象.get(网址) 说明:
-
a1是初始化的浏览器驱动对象(如a1 = webdriver.Chrome()) -
传入的网址必须包含协议(如
http://或https://),否则可能无法正常打开 -
执行该方法后,浏览器会自动加载并显示目标网页
③ 关闭标签页
a1.close()
说明:
-
仅关闭当前正在操作的标签页,其他标签页保持打开状态
-
如果当前只有一个标签页,执行后浏览器窗口会保留(但无标签页),驱动进程仍在运行
④ 退出浏览器并释放驱动
a1.quit()
说明:
-
彻底关闭整个浏览器(包括所有标签页),并终止驱动进程,释放系统资源
-
脚本结束时推荐使用
quit(),避免驱动进程残留占用内存 -
区别于
close():quit()是 "完全退出",close()是 "关闭当前页"
3、浏览器的最大化和最小化
3.1 浏览器最大化 maximize_window ()
a1.maximize_window()
应用格式 :driver对象.maximize_window() 说明:
-
将浏览器窗口调整到当前屏幕的最大尺寸
-
常用于确保网页元素在可视区域内,避免因窗口过小导致元素被隐藏或布局错乱
3.2 浏览器最小化 minimize_window ()
a1.minimize_window()
应用格式 :driver对象.minimize_window() 说明:
-
将浏览器窗口最小化到任务栏
-
一般在需要暂时隐藏浏览器操作时使用(如执行后台处理任务时)
4、浏览器的打开位置和打开尺寸
4.1 浏览器的打开位置 set_window_position (0,0)
a1.set_window_position(300, 100)
应用格式 :driver对象.set_window_position(x坐标, y坐标) 参数说明:
-
x坐标:窗口左上角距离屏幕左侧的像素值 -
y坐标:窗口左上角距离屏幕顶部的像素值 注意点: -
坐标原点 (0,0) 为屏幕左上角
-
若坐标值超过屏幕尺寸,窗口可能会被部分隐藏
4.2 浏览器的打开尺寸 set_window_size (0,0)
a1.set_window_size(800, 1000)
应用格式 :driver对象.set_window_size(宽度, 高度) 参数说明:
-
宽度:窗口的像素宽度 -
高度:窗口的像素高度(不含标题栏和工具栏,仅内容区域) 注意点: -
常用于模拟特定分辨率下的网页显示效果
-
结合
set_window_position()可精确控制窗口在屏幕中的位置和大小
5、浏览器截图和刷新当前网页
5.1 浏览器截图 get_screenshot_as_file ()
示例:
a1.get_screenshot_as_file('1.png')
应用格式 :driver对象.get_screenshot_as_file(文件路径) 说明:
-
截取当前浏览器窗口的可视区域,保存为 PNG 格式图片
-
文件路径可传入相对路径(如'screenshots/1.png')或绝对路径(如'C:/test/1.png') -
若路径不存在(如
screenshots文件夹未创建),会抛出IOError异常,建议提前确保路径有效 -
常用于脚本执行失败时保存现场,辅助排查问题
5.2 刷新当前网页 refresh ()
示例:
a1.refresh()
应用格式 :driver对象.refresh() 说明:
-
等价于浏览器的 "刷新" 按钮功能,重新加载当前网页
-
常用于网页内容更新后需要重新获取数据的场景
-
刷新后页面会回到初始状态,之前输入的临时数据(如未提交的表单)可能会丢失
6、元素定位(8种定位方式)
①导包,使用前先导入By类
from selenium.webdeier.common.by import By
②查找单个元素 find_element(By.ID,value)
示例:
a1.find_element(By.ID, 'kw')定位一个元素,找到的话返回结果,找不到的话就报错
③查找多个元素fint_elements(By.ID,value)
示例:
a1.find_elements(By.ID,'k')
④doucument.getElementById('元素值')
先查出来自己要操作的元素有几个再决定使用element还是elements
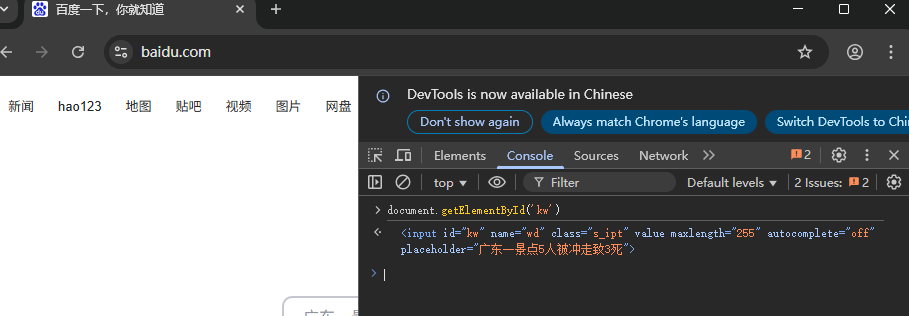
在谷歌浏览器的控制台中输出doucument.getElementById('元素值')命令语句就能列举出符合条件的元素
其他元素查找方式: doucument.getElementBy类型('元素值')
1.
document.getElementById('id值')作用 :通过元素的
id属性获取唯一元素(id在页面中应唯一)。 参数 :元素的id字符串(无需加#)。 返回值 :匹配的单个元素对象(如果找不到则返回null)。示例: 如果页面中有
<input id="username" type="text">,则:
const input = document.getElementById('username'); console.log(input); // 输出该input元素对象 input.value = "测试内容"; // 设置输入框内容
2.
document.getElementsByClassName('类名')作用 :通过元素的
class属性获取所有匹配的元素。 参数 :元素的类名(无需加.)。 返回值 :一个HTMLCollection(类数组对象),包含所有所有匹配的元素(即使只有一个匹配,也返回集合)。示例: 如果页面中有
<div class="box">1</div><div class="box">2</div>,则:
const boxes = document.getElementsByClassName('box'); console.log(boxes); // 输出包含2个div的集合 console.log(boxes[0]); // 获取第一个元素(索引从0开始) boxes[0].style.color = 'red'; // 给第一个第一个个元素设置红色文字
3.
document.getElementsByTagName('标签名')作用 :通过 HTML 标签名获取所有匹配的元素。 参数 :标签名(如
'div'、'p'、'a'等)。 返回值:HTMLCollection(类数组对象),包含所有匹配的标签元素。示例: 获取页面中所有
<p>标签:
const paragraphs = document.getElementsByTagName('p'); console.log(paragraphs.length); // 输出p标签的数量 paragraphs[0].textContent = "修改内容"; // 修改第一个p标签的文本
4.
document.getElementsByName('name值')作用 :通过元素的
name属性获取所有匹配的元素(常见用于表单元素,如<input name="username">)。 参数 :元素的name属性值。 返回值:NodeList(类数组对象),包含所有匹配的元素。示例: 对于
<input name="username" type="text">:
const inputs = document.getElementsByName('username'); if (inputs.length > 0) { inputs[0].value = "张三"; // 设置第一个匹配的input设置值 }
6.1 ID定位
一般使用格式:
find_element(By.ID,value)
通过元素里面查看到代码有ID类型的,然后书写其对应值来找到他的ID
特点:
-
通过id定位元素一般比较准确
-
并非所有网页或元素都有id
示例:
a1.get('https://baidu.com/')
id=a1.find_element(ById.'icon')6.2、NAME定位
一般使用格式:
find_element(By.NAME,value)
特点:
通过id定位元素一般比较准确
并非所有网页或元素都有id
示例:
a1.get('https://baidu.com/')
name=a1.findelement(By.name,'dev')6.3 CLASS_NAME定位
一般使用格式:
find_elements(By.CLASS_NAME,value)num
num是切片标号
特点:
class值不能有空格,否则会报错
class值重复的有很多,需要切片(即选择同名的第n-1个元素)
class值在有的网址是随机的(可能是为了防止用户使用自动化脚本)
浏览器查找命令句:document.getElementsClassName('value')
示例:
a1.get('https://baidu.com/')
_class=a1.find_elements(By.CLASS_NAME,'channel-link')[1].click()6.4 TAG_NAME定位
HTML是通过tag来定义功能的,比如input是输入,table是表格等等。每个元素其实就是一个tag,一个tag往往用来定义一类功能,我们查看百度首页的html代码,可以看到有很多同类 tag,所以其实很难通过tag去区分不同的元素。
一般格式:
find_elements(By.TAG_NAME,value)num
特点:
-
找出<开头标签名字>
-
重复的标签名特别多,需要切片出来
示例:
a1.get('https://baidu.com/')
tag=a1.find_elements(By.TAG_NAME,'p')[1].click()6.5 LINK_TEXT定位
文本链接就是能跳到某一链接的文字,比如百度左上角的文字
一般格式:
find_elements(By.LINK_TEXT,value)num
value是文本内容
特点:
-
通过精确连接文本找到a标签 的元素(精准文本定位)
-
有重复的文本需要切片
示例:
a1.get('https://baidu.com/')
text=a1.find_element(By.LINK_TEXT,'新闻').click()6.6 PARTIAL_LINK_TEXT定位
一般格式:
find_elements(By.PARTIAL_LINK_TEXT,value)num
value是文本内容
特点:
-
通过精确连接文本找到a标签 的元素(模糊文本定位)
-
有重复的文本需要切片
示例:
a1.get('https://baidu.com/')
text=a1.find_element(By.PARTIAL_LINK_TEXT,'闻').click() 6.7 CSS_SELECTOR定位
万能
一般格式:
find_element(By.CSS_SELECTOR,#id值)
find_element(By.CSS_SELECTOR,'.class')
find_elements(By.CSS_SELECTOR,'value')num
find_element(By.CSS_SELECTOR,'任意类型')
特点:
-
#id=井号+id值 通过id定位
-
.class=点+class值,通过class定位
-
不加修饰符=标签贴
-
通过任意类型定位:"类型=精确值"
-
通过任意类型定位:"类型\*=模糊值"
-
通过任意类型定位:"类型\^='开头值'"
-
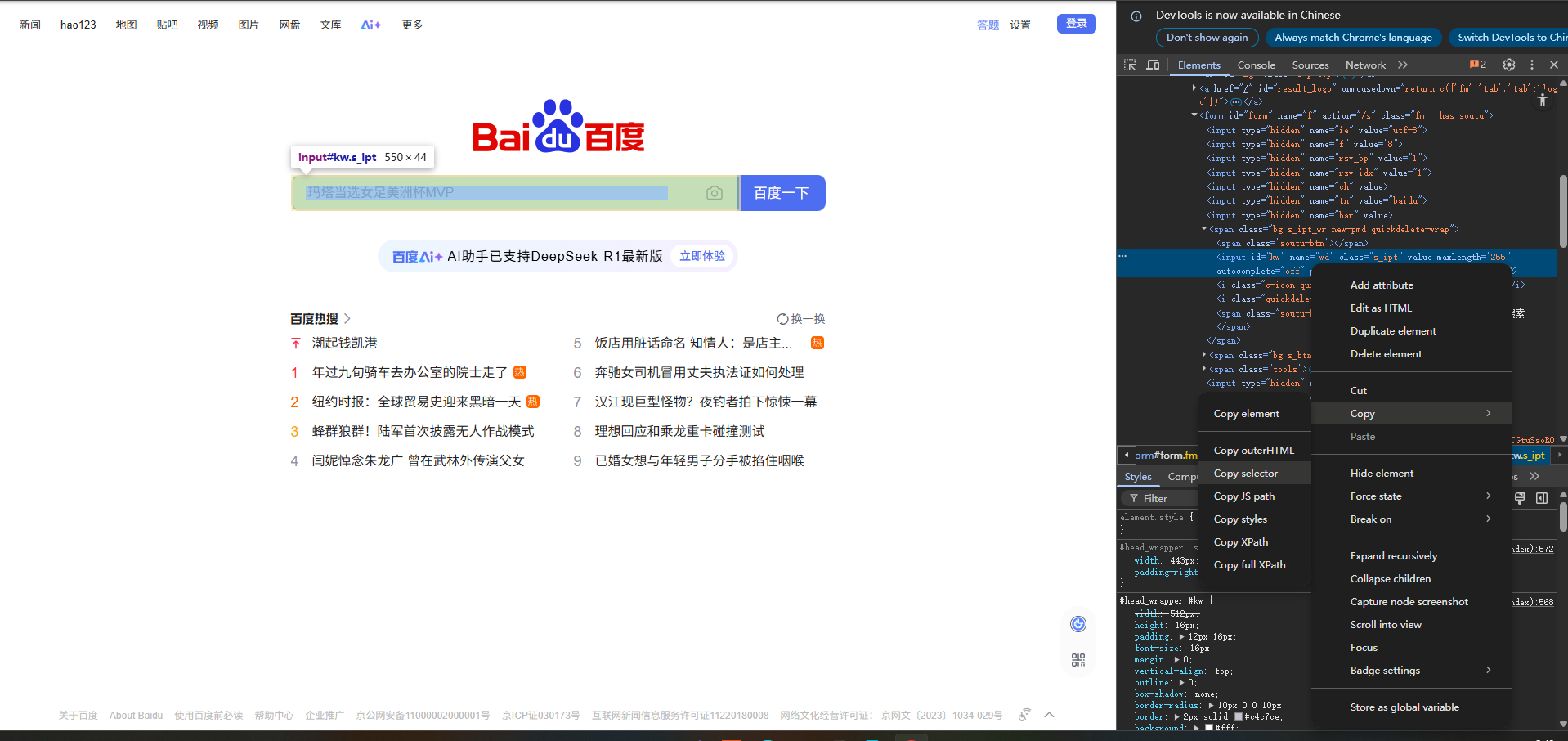
通过任意类型定位:"类型$='结尾值'" 以上都是理论定位法
-
更简单的方式:在控制台直接复制selector(唯一的定位值) 单击元素-右击检查-找到元素-右击复制(copy)-复制选择器(Copy select)
示例:
a2.find_element(By.CSS_SELECTOR,'#kw').send_keys('baidu') # #id=井号+id值 通过id定位
a2.find_element(By.CSS_SELECTR,'.s_ipt').send_keys('baidu') # .class=点+class值,通过class定位
a2.find_elements(By.CSS_SELECTR,'input')[7].send_keys('baidu') #不加修饰符=标签贴
a2.find_element(By.CSS_SELECTOR,[autocomplete='off']).send_keys('baidu')#任意类型(精确值)
a2.find_element(By.CSS_SELECTOR,[autocomplete*='of']).send_keys('baidu')#任意类型(模糊值)
a2.find_element(By.CSS_SELECTOR,[autocomplete^='o']).send_keys('baidu')#任意类型(开头值)
a2.find_element(By.CSS_SELECTOR,[autocomplete$='f']).send_keys('baidu')#任意类型(结尾值)6.8 XPATH定位
一般格式:
find_element(By.XPATH,'value')
value取自单击元素-右击检查-找到元素-右击复制(copy)-复制xpath
特点
-
复制谷歌浏览器Xpath(通过属性+路径定位,属性如果是随机的可能定位不到)
-
复制个浏览器Xpath 完整路径(full Xpath)
示例:
text=a1.find_element(By.XPATH,'//*[@id="kw"]').send_keys('baidu')
text=a1.find_element(By.XPATH,'/html/body/div[1]/div[1]/div[6]/div/div/form/span[1]/input').send_keys('baidu')6.9 隐性等待
在 Selenium 中,隐性等待(Implicit Wait) 是一种全局的元素定位等待机制,用于设置一个最长等待时间。当 Selenium 尝试定位某个元素时,如果元素未立即出现,会在指定时间内持续尝试定位,直到元素出现或超时为止。这种机制可以有效解决因页面加载延迟导致的元素定位失败问题。
隐性等待的核心特点
-
全局生效:设置后对后续所有元素定位操作都有效(直到浏览器对象被关闭或重新设置等待时间)。
-
超时时间 :指定一个最大等待时长(单位:秒),若超过该时间元素仍未出现,则抛出
NoSuchElementException错误。 -
非阻塞等待:仅在元素未立即出现时才等待,若元素快速加载,会立即执行后续操作,不浪费额外时间。
隐性等待的设置方法
driver.implicitly_wait (时间)
通过 WebDriver 对象的 implicitly_wait() 方法设置,语法如下:
# 导入必要模块
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 初始化浏览器
service = Service("chromedriver.exe")
driver = webdriver.Chrome(service=service)
# 设置隐性等待:最长等待 10 秒(全局生效)
driver.implicitly_wait(10) # 单位:秒应用场景与示例
当页面加载较慢(如异步加载内容、网络延迟)时,隐性等待能确保 Selenium 有足够时间等待元素出现。以下是完整示例:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
# 1. 初始化浏览器并设置隐性等待
service = Service("chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.implicitly_wait(10) # 全局等待 10 秒
# 2. 打开目标网页(如 B站)
driver.get("https://www.bilibili.com")
# 3. 定位元素(若元素未立即出现,会等待最多 10 秒)
# 示例:定位搜索框(class 为 "nav-search-input")
search_box = driver.find_element(By.CLASS_NAME, "nav-search-input")
# 4. 执行操作(如输入内容)
search_box.send_keys("鬼畜")
# 5. 关闭浏览器
driver.quit()注意事项
设置时机:建议在初始化浏览器后立即设置,确保后续所有定位操作都受其保护。
时间选择:根据页面实际加载速度设置合理时间(通常 5-10 秒),过短可能导致超时,过长会增加脚本执行时间。
与显性等待的区别
:
隐性等待是全局的、针对所有元素的 "被动等待",无需指定具体元素。
显性等待(
WebDriverWait)是针对特定元素的 "主动等待",可设置更精细的条件(如元素可点击)。两者可以同时使用,但隐性等待的超时时间不会与显性等待叠加(以最长的时间为准)。
局限性
:
仅对
find_element()/find_elements()方法有效,对其他操作(如页面加载、弹窗出现)无效。若元素存在但不可交互(如未加载完成),隐性等待无法判断,可能导致后续操作失败(此时需用显性等待)。
最佳实践
-
简单场景下,隐性等待足以应对大多数元素延迟问题,使用便捷。
-
复杂场景(如需要等待元素可点击、文本出现等),建议结合显性等待使用,例如:
pythonfrom selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC # 显性等待:等待搜索框可点击(最长 10 秒) search_box = WebDriverWait(driver, 10).until( EC.element_to_be_clickable((By.CLASS_NAME, "nav-search-input")) )
通过合理使用隐性等待,可以大幅提高 Selenium 脚本的稳定性,减少因元素加载延迟导致的报错。
7、元素交互
先通过浏览器对象打开网页
定位到具体的元素(比如 B 站的搜索框)
对元素对象调用具体方法
示例:
a1.get('https://www.bilibili.com/')
_input = a1.find_element(By.CLASS_NAME, 'nav-search-input') # 定位搜索框
_input.send_keys('鬼畜') # 执行输入操作7.1 元素点击:click()
用于点击可交互元素(如按钮、链接、复选框等)。
示例:
# 定位按钮后点击
button = a1.find_element(By.ID, 'submit-btn')
button.click() # 点击元素7.2 输入框元素输入:send_keys(value)
向输入框、文本域等可输入元素发送文本内容。
示例:
# 向搜索框输入内容
search_box = a1.find_element(By.NAME, 'search')
search_box.send_keys('csdn') # 发送文本“csdn”7.3 输入框元素清空:clear()
清除输入框中已有的文本内容。
示例:
# 清空输入框内容
search_box = a1.find_element(By.ID, 'username')
search_box.clear() # 清空输入框7.4 单选、多选、下拉元素交互
①单选按钮
单选按钮(<input type="radio">)通常一组中只能选择一个,通过 click() 方法选择。
示例:
a1.get('https://mail.qq.com/')
# 定位单选按钮并点击选择
radio_btn = a1.find_element(By.XPATH, '//*[@id="QQMailSdkTool_auto_login"]')
radio_btn.click()②多选框
多选框(<input type="checkbox">)可选择多个选项,逐个定位并点击即可。
示例:
python
a1.get("C:\\Users\\86134\\Desktop\\演示.html") # 打开本地HTML文件
# 依次点击3个多选框
a1.find_element(By.XPATH, '//*[@id="demoForm"]/div[2]/div/div[1]/label').click()
time.sleep(1) # 等待1秒,便于观察
a1.find_element(By.XPATH, '//*[@id="demoForm"]/div[2]/div/div[2]/label').click()
time.sleep(1)
a1.find_element(By.XPATH, '//*[@id="demoForm"]/div[2]/div/div[3]/label').click()③下拉菜单
普通下拉菜单(<select> 标签)可通过定位选项并点击选择。
示例:
# 定位下拉菜单中的第3个选项并点击
option = a1.find_element(By.XPATH, '//*[@id="dropdown"]/option[3]')
option.click() # 选择该选项7.5 上传元素交互
文件上传元素(<input type="file">)可直接通过 send_keys() 传入文件绝对路径实现上传。
示例:
# 定位上传按钮并传入文件路径
upload_btn = a1.find_element(By.ID, 'file-upload')
upload_btn.send_keys('C:\\Users\\test\\Documents\\example.txt') # 传入文件全路径7.6 警告框元素交互
警告框(alert)是浏览器弹出的提示框,仅有 "确定" 按钮。
-
点击确定按钮:
a1.switch_to.alert.accept() # 关闭警告框 -
获取弹窗文字:
alert_text = a1.switch_to.alert.text # 获取弹窗文本内容 print(alert_text) # 打印文本
7.7 确认框元素交互
确认框(confirm)有 "确定" 和 "取消" 两个按钮,用于确认操作。
-
点击确定:
a1.switch_to.alert.accept() # 确认操作 -
点击取消:
a1.switch_to.alert.dismiss() # 取消操作
7.8 提示框元素交互
提示框(prompt)可让用户输入文本,需先输入内容再确认或取消。
示例:
# 向提示框输入内容并确认
alert = a1.switch_to.alert # 切换到提示框
alert.send_keys('hello') # 输入文本“hello”
alert.accept() # 点击确定提交7.9 iframe 嵌套页面的进入、退出
iframe 是嵌套在主页面中的子页面,需先切换到 iframe 内才能操作其元素。
核心操作流程:
获取 iframe 元素:
iframe = a1.find_element(By.XPATH, '/html/body/iframe') # 定位iframe进入 iframe:
a1.switch_to.frame(iframe) # 切换到iframe内在 iframe 内操作元素:
# 在iframe内定位搜索框并点击 a1.find_element(By.CLASS_NAME, 'nav-search-input').click()退出 iframe 回到主页面:
a1.switch_to.default_content() # 退出所有iframe,返回主页面
7.10 获取元素文本内容、是否可见
①获取元素文本内容
通过 text 属性获取元素的可见文本(非输入框内容)。
示例:
# 定位元素并获取文本
element = a1.find_element(By.XPATH, '//*[@id="title"]')
text = element.text # 获取文本内容
print(text) # 打印文本②检查元素是否可见
通过 is_displayed() 方法判断元素是否在页面中可见(返回 True 或 False)。
示例:
# 检查元素是否可见
element = a1.find_element(By.XPATH, '//*[@id="banner"]')
is_visible = element.is_displayed() # 返回布尔值
print(is_visible) # 打印结果(True表示可见,False表示隐藏)8、获取句柄和切换标签页
在 Selenium 中,每个浏览器标签页 / 窗口都有一个唯一的标识符,称为 "句柄(handle)"。通过句柄可以实现标签页之间的切换,这在多标签页操作场景中非常重要。
8.1 获取全部标签页句柄
作用:获取当前浏览器中所有打开的标签页 / 窗口的句柄,返回一个列表(按标签页打开顺序排列)。
一般应用格式:
操作对象 = 浏览器对象.window_handles
print(操作对象) # 打印所有句柄示例:
# 假设a1是初始化的浏览器对象
all_handles = a1.window_handles
print("所有标签页句柄:", all_handles) # 输出类似:['CDwindow-xxx', 'CDwindow-yyy']8.2 获取当前标签页的句柄
作用:获取当前正在操作的标签页 / 窗口的句柄(单个字符串)。
一般应用格式:
操作对象 = 浏览器对象.current_window_handle # 注意:无复数s
print(操作对象) # 打印当前句柄示例:
current_handle = a1.current_window_handle
print("当前标签页句柄:", current_handle) # 输出类似:'CDwindow-xxx'8.3 切换标签页
作用:通过句柄切换到指定的标签页 / 窗口,后续操作将在目标标签页执行。
一般应用格式:
浏览器对象.switch_to.window(操作对象[num]) # num为标签页索引(从0开始)示例:
# 1. 打开新标签页前,先记录原始标签页句柄
original_handle = a1.current_window_handle
# 2. 假设通过点击链接打开了新标签页(此处用示例模拟)
a1.find_element(By.LINK_TEXT, "打开新页面").click()
# 3. 获取所有句柄,切换到新标签页(索引1,因为原始页是索引0)
all_handles = a1.window_handles
a1.switch_to.window(all_handles[1])
# 4. 在新标签页执行操作(如打印标题)
print("新标签页标题:", a1.title)
# 5. 切回原始标签页
a1.switch_to.window(original_handle)注意事项:
-
句柄是字符串类型,每次打开新标签页都会生成新句柄,关闭标签页后句柄会失效。
-
切换标签页后,建议通过
driver.title或driver.current_url验证是否切换成功。 -
若标签页数量不确定,可通过循环遍历句柄找到目标页,例如:
for handle in all_handles: if handle != original_handle: a1.switch_to.window(handle) # 切换到非原始页的新标签页 break
9、多线程执行自动化脚本
在自动化测试或批量操作场景中,单线程脚本执行效率较低。通过多线程可以同时启动多个浏览器实例,并行执行任务,大幅提升脚本运行效率。
9.1 多线程的核心概念
-
线程:程序执行的最小单位,一个进程可以包含多个线程,线程共享进程资源。
-
并行执行:多线程可同时运行多个自动化任务(如同时打开多个浏览器操作不同页面)。
-
适用场景:批量数据处理、并发测试、多账号同时操作等场景。
9.2 多线程的基础依赖
Python 中通过标准库 threading 实现多线程,需导入以下模块:
import threading # 多线程核心库
from selenium import webdriver # Selenium浏览器驱动
from selenium.webdriver.common.by import By # 元素定位
import time # 用于等待9.3 多线程执行自动化的基本结构
-
定义任务函数:封装单个自动化任务的逻辑(如打开网页、执行操作)。
-
创建线程对象:将任务函数和参数传入线程。
-
启动线程 :通过
start()方法启动所有线程。 -
等待线程结束 :通过
join()方法等待所有线程执行完成。
9.4 应用格式与示例
示例:多线程并行打开多个网页并执行操作
python
# 1. 定义自动化任务函数(每个线程执行的任务)
def auto_task(url, task_name):
# 初始化浏览器(每个线程独立的浏览器实例)
driver = webdriver.Chrome()
driver.implicitly_wait(10) # 设置隐性等待
try:
# 执行任务:打开网页并打印标题
driver.get(url)
print(f"线程[{task_name}]打开网页:{url},标题:{driver.title}")
# 模拟操作(如搜索)
if "baidu" in url:
search_box = driver.find_element(By.ID, "kw")
search_box.send_keys(f"多线程 {task_name}")
search_box.submit()
time.sleep(2) # 等待搜索结果加载
except Exception as e:
print(f"线程[{task_name}]出错:{e}")
finally:
# 关闭浏览器,释放资源
driver.quit()
print(f"线程[{task_name}]执行完毕")
# 2. 主程序:创建并启动多线程
if __name__ == "__main__":
# 定义任务列表(url和任务名称)
tasks = [
("https://www.baidu.com", "任务1"),
("https://www.bilibili.com", "任务2"),
("https://www.csdn.net", "任务3")
]
# 存储线程对象的列表
threads = []
# 创建线程并启动
for url, name in tasks:
# 创建线程:target为任务函数,args为传入函数的参数
thread = threading.Thread(target=auto_task, args=(url, name))
threads.append(thread)
thread.start() # 启动线程
# 等待所有线程执行完成
for thread in threads:
thread.join() # 阻塞主线程,直到该线程执行完毕
print("所有线程执行完成!")9.5 注意事项
-
浏览器实例独立性 :每个线程需单独初始化浏览器对象(
webdriver.Chrome()),避免线程间资源冲突。 -
线程安全问题:
-
避免多个线程操作同一个浏览器实例或共享变量,可能导致数据混乱或报错。
-
若需共享数据,需使用线程锁(
threading.Lock())控制访问。
-
-
性能控制:
- 线程数量并非越多越好,过多线程会占用大量系统资源(内存、CPU),建议根据硬件性能合理设置(一般 5-10 个线程为宜)。
-
异常处理 :每个线程的任务函数需单独添加
try-except捕获异常,避免单个线程出错导致整个程序崩溃。 -
驱动兼容性:确保浏览器驱动版本与浏览器一致,多线程场景下驱动路径需正确配置(建议添加到环境变量)。
9.6 多线程与单线程对比
| 类型 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| 单线程 | 逻辑简单、无资源冲突 | 执行效率低,耗时久 | 简单任务、调试阶段 |
| 多线程 | 并行执行、效率高 | 逻辑复杂、需处理线程安全问题 | 批量任务、并发测试 |
通过多线程执行自动化脚本,能有效提升批量操作的效率,尤其适合需要重复执行相似任务的场景(如多账号登录、多页面数据爬取等)。
10、网页前进后退
在浏览器操作中,前进和后退是常用功能,Selenium 提供了对应的方法实现网页历史记录的导航。
10.1 网页前进
作用:模拟浏览器的 "前进" 按钮,跳转到历史记录中的下一个页面(需先有后退操作,否则无效果)。
一般应用格式:
浏览器对象.forward()示例:
# 1. 打开第一个网页
a1.get("https://www.baidu.com")
print("第一个页面标题:", a1.title)
# 2. 打开第二个网页(产生历史记录)
a1.get("https://www.bilibili.com")
print("第二个页面标题:", a1.title)
# 3. 先后退到第一个页面
a1.back()
print("后退后页面标题:", a1.title)
# 4. 前进到第二个页面
a1.forward()
print("前进后页面标题:", a1.title)10.2 网页后退
作用:模拟浏览器的 "后退" 按钮,跳转到历史记录中的上一个页面(需先有多个页面访问记录,否则无效果)。
一般应用格式:
浏览器对象.back()示例:
# 1. 打开首页
a1.get("https://www.example.com")
# 2. 点击链接进入子页面(假设存在跳转)
a1.find_element(By.LINK_TEXT, "子页面").click()
print("子页面标题:", a1.title)
# 3. 后退到首页
a1.back()
print("后退后标题:", a1.title) # 输出首页标题注意事项
-
历史记录依赖 :
forward()和back()仅对通过get()方法或点击链接产生的历史记录有效,新标签页的历史记录相互独立。 -
操作顺序 :需先有 "前进" 的历史记录(即先执行过
back()),forward()才能生效;若直接打开页面后未跳转,back()无效果。 -
与刷新的区别 :前进 / 后退是导航历史记录,
refresh()是重新加载当前页面,二者功能不同。
通过前进和后退方法,可灵活在已访问的页面间切换,适合需要来回验证页面状态的场景。
11、操作已有浏览器页面(连接现有浏览器实例)
在实际自动化场景中,有时需要在用户已手动打开并操作过的网页上继续执行自动化操作(如手动登录后执行后续任务、连点操作等)。通过 Chrome 调试模式可实现 Selenium 连接到已存在的浏览器实例,以下是详细实现方法。
11.1 核心原理与应用场景
核心原理
Chrome 浏览器支持通过 远程调试模式(Remote Debugging) 允许外部程序(如 Selenium)连接到已运行的浏览器实例。其本质是通过指定端口建立通信,让 Selenium 接管现有浏览器的操作权。
应用场景
-
需在手动登录后的页面执行自动化(避免重复处理登录验证,如验证码、短信验证)。
-
对已有页面中的元素进行批量操作(如连点、数据提取)。
-
调试复杂流程时,手动完成前置步骤后再启动自动化。
11.2 实现步骤
步骤 1:启动调试模式的 Chrome 浏览器
需先关闭所有 Chrome 窗口,再通过命令行启动带调试参数的浏览器:
Windows 系统操作
-
关闭所有正在运行的 Chrome 窗口(确保无残留进程)。
-
打开「命令提示符」(Win+R → 输入
cmd→ 回车)。 -
输入以下命令启动 Chrome(注意替换路径):
# 默认安装路径(64位系统) "C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222 --user-data-dir="C:\ChromeDebugProfile"-
--remote-debugging-port=9222:指定调试端口(固定为 9222,后续脚本需对应)。 -
--user-data-dir="C:\ChromeDebugProfile":指定独立的用户数据目录(避免干扰默认浏览器配置)。
-
Mac/Linux 系统操作
-
关闭所有 Chrome 窗口。
-
打开终端,输入命令:
# Mac 系统 /Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --remote-debugging-port=9222 --user-data-dir="/Users/你的用户名/ChromeDebugProfile" # Linux 系统 google-chrome --remote-debugging-port=9222 --user-data-dir="/home/你的用户名/ChromeDebugProfile"
验证启动成功
启动后会自动打开一个新的 Chrome 窗口,在地址栏输入 http://127.0.0.1:9222,若显示调试页面则说明启动成功。
步骤 2:获取目标元素的定位信息
在调试模式的 Chrome 中手动打开目标网页,获取需要操作的元素定位信息(如 CSS 选择器、XPath 等):
-
右键点击目标元素 → 选择「检查」(打开开发者工具)。
-
在开发者工具的 Elements 面板中,右键点击元素代码 → 「Copy」→ 选择定位方式:
- 推荐「Copy selector」(CSS 选择器)或「Copy XPath」(XPath 路径)。
步骤 3:编写 Selenium 脚本连接现有浏览器
通过脚本连接到调试模式的浏览器,并执行自动化操作(以连点为例)。
11.3 完整代码示例(连点器案例)
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
def connect_existing_browser(debug_port=9222):
"""连接到已启动调试模式的Chrome浏览器实例"""
# 配置浏览器选项,指定调试端口
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", f"127.0.0.1:{debug_port}")
try:
# 连接到现有浏览器
driver = webdriver.Chrome(options=chrome_options)
print(f"✅ 成功连接到已有浏览器!当前页面:{driver.title}")
return driver
except Exception as e:
print(f"❌ 连接失败:{str(e)}")
print("请确认已按要求启动Chrome调试模式(关闭所有Chrome后重新执行命令)")
return None
def auto_click_element(driver, by=By.CSS_SELECTOR, value=None, interval=0.1, click_count=None):
"""
自动点击已有页面中的目标元素
:param driver: 浏览器驱动对象(连接到现有浏览器的实例)
:param by: 元素定位方式(如By.CSS_SELECTOR、By.XPATH)
:param value: 定位值(如CSS选择器字符串、XPath路径)
:param interval: 点击间隔时间(秒,默认0.1秒/次)
:param click_count: 总点击次数(None表示无限循环)
"""
if not driver or not value:
print("❌ 参数错误:请确保浏览器已连接且定位值有效")
return
try:
# 定位目标元素(依赖步骤2获取的定位信息)
target_element = driver.find_element(by, value)
print(f"✅ 已找到目标元素,开始执行点击(间隔{interval}秒)")
click_total = 0 # 记录总点击次数
while True:
# 检查元素是否可见且可点击
if target_element.is_displayed() and target_element.is_enabled():
target_element.click() # 执行点击
click_total += 1
print(f"已点击 {click_total} 次", end="\r") # 实时刷新显示
else:
print("\n❌ 元素不可见或不可点击,停止操作")
break
# 若指定点击次数,达到后停止
if click_count and click_total >= click_count:
print(f"\n✅ 已完成 {click_count} 次点击,任务结束")
break
time.sleep(interval) # 控制点击间隔
except KeyboardInterrupt:
print(f"\n✅ 用户手动终止,共点击 {click_total} 次")
except Exception as e:
print(f"\n❌ 操作出错:{str(e)}(可能元素已消失或页面已刷新)")
if __name__ == "__main__":
# 1. 连接到现有浏览器(端口需与启动命令一致,默认9222)
browser_driver = connect_existing_browser(debug_port=9222)
if browser_driver:
# 2. 配置点击参数(根据步骤2获取的定位信息修改)
click_config = {
"by": By.CSS_SELECTOR, # 定位方式(与复制的类型对应)
"value": "button.submit-btn", # 替换为实际元素的CSS选择器/XPath
"interval": 0.1, # 点击速度(越小越快,建议≥0.1避免被拦截)
"click_count": None # 无限循环(如需有限次,改为数字如100)
}
# 3. 执行自动点击
auto_click_element(browser_driver, **click_config)
# 4. 保持脚本运行(手动关闭浏览器或按Ctrl+C终止)
input("按回车键退出程序...")11.4 关键配置说明
| 参数 / 步骤 | 作用说明 |
|---|---|
调试端口 9222 |
浏览器与脚本通信的端口,必须与启动命令和脚本中的 debug_port 保持一致。 |
定位方式 by |
需与步骤 2 中复制的定位类型匹配(如复制的是 CSS 选择器,则用 By.CSS_SELECTOR)。 |
点击间隔 interval |
控制点击速度,过快可能触发网页反自动化机制(建议≥0.1 秒)。 |
点击次数 click_count |
设置为 None 时无限循环,按 Ctrl+C 手动终止;设置数字时固定次数后停止。 |
11.5 注意事项
-
版本匹配:确保 Chrome 浏览器版本与 ChromeDriver 版本一致(驱动版本需 ≥ 浏览器主版本)。
-
浏览器状态:启动调试模式前必须关闭所有 Chrome 窗口,否则会启动失败。
-
页面稳定性:若目标页面刷新或跳转,元素可能失效,需重新定位或重启脚本。
-
反自动化机制:部分网站会检测自动化工具,可能导致点击无效,可尝试延长点击间隔或禁用自动化提示(脚本中已包含相关配置)。
-
权限问题 :
user-data-dir路径需有读写权限,建议选择用户目录下的文件夹(如C:\Users\你的用户名\ChromeDebugProfile)。
二、设置定时任务
Selenium 脚本可以通过结合定时任务机制,实现在北京时间特定时刻自动执行网页自动化操作(如测试、数据采集等)。以下是两种常用实现方案,适用于不同场景需求。
方案一:使用 Python 定时库(轻量级)
适合简单场景(如本地调试、短期定时任务),通过 schedule 库实现代码级定时调度,无需依赖系统工具,操作灵活。
1. 依赖安装
首先需安装
schedule库(定时调度核心)和selenium库:
pip install schedule selenium2. 应用格式与示例
pythonimport schedule import time from datetime import datetime from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By def run_automation_task(): """定义自动化任务的核心逻辑""" print(f"任务开始执行:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}") # 配置浏览器(无头模式适合后台运行,不显示窗口) chrome_options = Options() chrome_options.add_argument("--headless") # 无头模式 chrome_options.add_argument("--disable-gpu") # 禁用GPU加速(避免部分环境报错) chrome_options.add_argument("--window-size=1920,1080") # 设置窗口尺寸 # 初始化浏览器驱动 driver = webdriver.Chrome(options=chrome_options) driver.implicitly_wait(10) # 设置隐性等待 try: # 执行自动化操作(示例:打开网页并执行搜索) driver.get("https://www.baidu.com") print(f"打开网页:{driver.current_url},标题:{driver.title}") # 定位搜索框并输入内容 search_box = driver.find_element(By.ID, "kw") search_box.send_keys("Selenium 定时任务") search_box.submit() # 提交搜索 time.sleep(2) # 等待结果加载 print(f"搜索完成,当前页面标题:{driver.title}") except Exception as e: print(f"任务执行出错:{str(e)}") # 捕获并打印错误 finally: driver.quit() # 无论成功与否,均关闭浏览器 print(f"任务执行结束:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n") # 设置定时任务(北京时间) # 示例1:每天上午9:30执行 schedule.every().day.at("09:30").do(run_automation_task) # 示例2:每周一至周五的14:00执行(取消注释即可启用) # schedule.every().monday.at("14:00").do(run_automation_task) # schedule.every().tuesday.at("14:00").do(run_automation_task) # schedule.every().wednesday.at("14:00").do(run_automation_task) # schedule.every().thursday.at("14:00").do(run_automation_task) # schedule.every().friday.at("14:00").do(run_automation_task) # 启动定时任务监听 if __name__ == "__main__": print(f"定时任务已启动,等待执行... 当前时间:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}") while True: schedule.run_pending() # 检查是否有任务需要执行 time.sleep(60) # 每60秒检查一次(减少资源占用)3. 使用说明
运行方式:直接执行脚本,脚本会持续运行并在指定时间触发任务。
无头模式 :
--headless参数可隐藏浏览器窗口,适合在服务器或后台运行;本地调试时可注释该参数,直观查看操作过程。脚本稳定性 :需保持脚本持续运行(可通过
nohup命令或后台窗口实现,如 Linux 中nohup python3 task.py &)。
方案二:使用系统级定时任务(推荐)
通过操作系统自带的定时工具(如 Windows 任务计划程序、Linux 的 crontab)实现调度,无需脚本持续运行,稳定性更高,适合生产环境长期使用。
1. Windows 系统设置步骤
步骤 1:准备可独立运行的脚本
确保 Selenium 脚本(如
auto_task.py)可单独执行,建议添加日志输出(便于排查问题)。示例脚本框架:
python# auto_task.py from selenium import webdriver import time from datetime import datetime def main(): log_file = "task_log.txt" with open(log_file, "a", encoding="utf-8") as f: f.write(f"[{datetime.now()}] 任务开始\n") try: driver = webdriver.Chrome() driver.get("https://www.example.com") # 执行具体操作... time.sleep(3) f.write(f"[{datetime.now()}] 任务成功\n") except Exception as e: f.write(f"[{datetime.now()}] 任务失败:{str(e)}\n") finally: driver.quit() if __name__ == "__main__": main()步骤 2:通过 "任务计划程序" 设置定时任务
打开「任务计划程序」(可通过 Windows 搜索栏搜索)。
点击「创建基本任务」,输入任务名称(如 "Selenium 定时任务"),点击「下一步」。
触发条件:选择触发时间(如 "每天"),设置具体时间(如 9:30),点击「下一步」。
操作:选择 "启动程序",点击「下一步」。
程序 / 脚本 :点击「浏览」,选择 Python 可执行文件路径(如
C:\Python39\python.exe)。添加参数 :输入脚本完整路径(如
D:\scripts\auto_task.py),点击「下一步」。点击「完成」,任务创建成功,系统会在指定时间自动执行脚本。
2. Linux 系统设置步骤
步骤 1:准备脚本并赋予执行权限
将脚本保存为
auto_task.py,并添加执行权限:
chmod +x auto_task.py # 赋予执行权限步骤 2:通过 crontab 设置定时任务
打开 crontab 配置文件:
crontab -e # 编辑当前用户的定时任务添加定时任务(北京时间),格式如下:
python# 每天9:30执行脚本,并将日志输出到 log 文件 30 9 * * * /usr/bin/python3 /home/user/scripts/auto_task.py >> /home/user/scripts/task_log.log 2>&1
格式说明:
分 时 日 月 周 命令,30 9 * * *表示每天 9:30 执行。
>> task_log.log 2>&1:将输出日志写入文件,便于后续查看。保存退出(按
Ctrl+X→Y→ 回车),crontab 会自动生效。3. 关键注意事项
时区校准 :确保系统时区为北京时间(UTC+8),避免时间偏差(Linux 可通过
timedatectl命令查看和设置时区)。环境一致性 :定时任务执行时使用的 Python 环境需与脚本开发环境一致,避免依赖缺失(可通过
which python3确认 Python 路径)。驱动配置 :确保浏览器驱动(如 chromedriver)已添加到系统环境变量
PATH中,避免 "驱动未找到" 错误。日志记录:建议在脚本中添加详细日志输出,方便排查执行结果和错误。
两种方案对比与选择
| 方案 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| Python 定时库 | 配置简单、代码可控性高 | 需脚本持续运行,稳定性依赖脚本 | 本地调试、短期轻量任务 |
| 系统级定时任务 | 稳定性高、无需脚本持续运行 | 配置稍复杂,依赖系统工具 | 生产环境、长期定时任务 |
建议:日常调试或短期任务选方案一,长期稳定运行的生产环境选方案二,可靠性和维护性更优。
三、Selenium 自动化综合案例:
1、多页面交互与定时执行示例
以下案例综合了元素定位、交互操作、等待机制、窗口切换、截图与异常处理等核心知识点,实现定时打开网页执行搜索并记录结果的自动化流程。
python
# 导入必要模块
import schedule # 定时任务库
import time # 时间相关操作
from datetime import datetime # 日期时间处理
from selenium import webdriver # 浏览器驱动核心库
from selenium.webdriver.common.by import By # 元素定位工具类
from selenium.webdriver.support.ui import WebDriverWait # 显式等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件
from selenium.common.exceptions import TimeoutException, NoSuchElementException # 异常类
def automation_task():
"""自动化任务核心函数:打开网页、执行搜索、切换窗口、记录结果"""
# 记录任务开始时间
start_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(f"\n===== 任务开始于:{start_time} =====")
# 初始化浏览器配置(无头模式适合后台运行)
driver = None # 定义driver变量,确保finally中可引用
try:
# 配置Chrome浏览器
chrome_options = webdriver.ChromeOptions()
# chrome_options.add_argument("--headless") # 本地调试时可注释此行,显示浏览器窗口
chrome_options.add_argument("--disable-gpu") # 禁用GPU加速,避免部分环境报错
chrome_options.add_argument("--window-size=1200,800") # 设置窗口尺寸
# 初始化浏览器驱动并设置隐性等待(全局生效)
driver = webdriver.Chrome(options=chrome_options)
driver.implicitly_wait(10) # 所有元素定位最多等待10秒
# 1. 打开百度首页并执行搜索
driver.get("https://www.baidu.com")
print(f"已打开网页:{driver.title}({driver.current_url})")
# 显式等待搜索框可点击(针对关键元素加强等待)
search_box = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, "kw")) # 等待ID为"kw"的元素可点击
)
# 执行搜索操作
search_box.clear() # 清空输入框
search_box.send_keys("Selenium 自动化教程") # 输入搜索关键词
driver.find_element(By.ID, "su").click() # 点击搜索按钮
time.sleep(2) # 简单等待搜索结果加载(实际可替换为显式等待)
# 截图保存搜索结果页面
driver.get_screenshot_as_file(f"baidu_search_{start_time.replace(':', '-')}.png")
print("百度搜索结果已截图保存")
# 2. 打开新窗口(B站)并执行搜索
# 记录当前窗口句柄(用于后续切换)
original_handle = driver.current_window_handle
# 在新标签页打开B站(通过JS实现新窗口打开)
driver.execute_script("window.open('https://www.bilibili.com');")
# 切换到新窗口(获取所有句柄,排除原始句柄)
all_handles = driver.window_handles
for handle in all_handles:
if handle != original_handle:
driver.switch_to.window(handle)
break
print(f"已切换到新窗口:{driver.title}({driver.current_url})")
# 在B站执行搜索(显式等待搜索框加载)
b站_search_box = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "nav-search-input")) # 等待搜索框存在
)
b站_search_box.clear()
b站_search_box.send_keys("Python 自动化案例") # 输入搜索关键词
driver.find_element(By.CLASS_NAME, "nav-search-btn").click() # 点击搜索按钮
time.sleep(2)
# 截图保存B站搜索结果
driver.get_screenshot_as_file(f"bilibili_search_{start_time.replace(':', '-')}.png")
print("B站搜索结果已截图保存")
# 3. 切换回原始窗口并关闭
driver.switch_to.window(original_handle)
print(f"已切回原始窗口:{driver.title}")
# 异常处理:捕获常见错误并记录
except TimeoutException:
print("错误:元素等待超时,可能页面加载过慢")
except NoSuchElementException:
print("错误:未找到目标元素,可能定位方式已失效")
except Exception as e:
print(f"任务执行出错:{str(e)}")
finally:
# 无论成功与否,均关闭浏览器释放资源
if driver:
driver.quit()
print("浏览器已关闭")
# 记录任务结束时间
end_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(f"===== 任务结束于:{end_time} =====")
# 定时任务配置(北京时间)
if __name__ == "__main__":
# 设置定时任务:每天10:00执行(可根据需求修改)
schedule.every().day.at("10:00").do(automation_task)
# 测试用:每30秒执行一次(实际使用时注释此行,启用上面的每日定时)
# schedule.every(30).seconds.do(automation_task)
print(f"定时任务已启动,当前时间:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print("等待任务执行...(按Ctrl+C终止程序)")
# 持续监听任务队列
while True:
schedule.run_pending() # 检查是否有任务需要执行
time.sleep(10) # 每10秒检查一次(减少资源占用)代码注释说明
-
模块导入:整合了 Selenium 核心库、定时任务库、日期处理及异常类,满足综合场景需求。
-
核心任务函数
automation_task:-
浏览器配置:使用无头模式(可注释切换为可视化),设置窗口尺寸避免元素布局问题。
-
隐性等待 :通过
driver.implicitly_wait(10)全局设置元素定位超时时间,应对页面加载延迟。 -
百度搜索流程
:
-
显式等待搜索框可点击(
WebDriverWait+EC.element_to_be_clickable),确保元素交互稳定性。 -
执行
clear()清空输入框、send_keys()输入关键词、click()点击搜索按钮,完成核心交互。
-
-
窗口切换 :通过
window_handles获取所有窗口句柄,结合switch_to.window()实现多窗口切换,适应多页面操作场景。 -
B 站搜索流程:复用定位与交互逻辑,展示不同网站的自动化适配方法。
-
截图功能 :通过
get_screenshot_as_file()保存操作结果,便于事后验证和问题排查。 -
异常处理 :捕获
TimeoutException(等待超时)、NoSuchElementException(元素未找到)等常见错误,避免程序崩溃。 -
资源释放 :
finally块中确保浏览器关闭(driver.quit()),防止资源泄露。
-
-
定时任务配置:
-
使用
schedule库设置每日 10:00 执行任务,支持灵活调整执行时间(如每周、每小时等)。 -
测试阶段可改用
every(30).seconds实现秒级循环执行,快速验证逻辑。 -
主循环通过
schedule.run_pending()持续监听任务,确保定时触发。
-
运行说明
-
环境准备:确保已安装
selenium和schedule库(pip install selenium schedule),并配置好浏览器驱动。 -
调试建议:本地测试时注释
--headless参数,可视化观察浏览器操作流程,便于定位问题。 -
生产使用:启用无头模式,通过系统定时任务(如 Windows 任务计划程序、Linux crontab)启动脚本,实现无人值守运行。
-
结果查看:操作截图会保存在脚本运行目录,命名格式包含时间戳,便于追溯每次执行结果。
2、本地 HTML 按钮循环点击计数器脚本
python
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
import os
def auto_click_counter(html_path):
# 1. 配置 Chrome 浏览器
chrome_options = Options()
# 保持浏览器打开(方便观察效果)
chrome_options.add_experimental_option("detach", True)
# 禁用自动化控制提示(避免网页检测)
chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"])
# 2. 启动浏览器(指定 ChromeDriver 路径,若已配置环境变量可简化为 Service())
# 若 ChromeDriver 不在同级目录,需替换为实际路径,例如:Service("D:/tools/chromedriver.exe")
service = Service("chromedriver.exe")
driver = webdriver.Chrome(service=service, options=chrome_options)
# 3. 打开本地 HTML 文件(需转换为 file:// 协议路径)
# 转换本地路径为浏览器可识别的格式(兼容 Windows/macOS/Linux)
absolute_path = os.path.abspath(html_path)
file_url = f"file:///{absolute_path.replace(os.sep, '/')}" # 统一路径分隔符为 /
driver.get(file_url)
print(f"已打开本地文件:{absolute_path}")
# 4. 循环点击按钮(每隔 5 秒一次)
try:
# 定位按钮元素(根据 HTML 中的按钮特征,这里用 class 定位)
button = driver.find_element(By.CLASS_NAME, "increment-btn")
click_count = 0 # 记录点击次数
while True: # 无限循环,可按 Ctrl+C 终止
button.click() # 点击按钮
click_count += 1
print(f"第 {click_count} 次点击完成,等待 0.1 秒...")
time.sleep(0.1) # 等待 5 秒
except KeyboardInterrupt:
print("\n脚本已手动终止")
except Exception as e:
print(f"发生错误:{e}")
finally:
# 若需自动关闭浏览器,可取消下面一行的注释
# driver.quit()
pass
# 执行脚本(指定本地 web.html 文件路径,若与脚本同级可直接写文件名)
if __name__ == "__main__":
auto_click_counter("C:\\Users\\86134\\Desktop\\WebTest.html") # 替换为你的 web.html 实际路径3、网页元素连点器(操作已有浏览器页面)
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
def connect_existing_browser(debug_port=9222):
"""连接到已打开的Chrome浏览器实例"""
chrome_options = Options()
# 配置调试端口,需与浏览器启动参数一致
chrome_options.add_experimental_option("debuggerAddress", f"127.0.0.1:{debug_port}")
try:
driver = webdriver.Chrome(options=chrome_options)
print(f"成功连接到已有浏览器,当前页面:{driver.title}")
return driver
except Exception as e:
print(f"连接失败:{str(e)}")
print("请确认已按要求启动Chrome调试模式")
return None
def auto_click_element(driver, by=By.CSS_SELECTOR, value=None, interval=0.1, click_count=None):
"""
自动点击指定元素
:param driver: 浏览器驱动对象
:param by: 定位方式(By.ID, By.CLASS_NAME等)
:param value: 定位值
:param interval: 点击间隔时间(秒)
:param click_count: 点击次数(None表示无限循环)
"""
if not driver or not value:
print("参数错误,无法执行点击")
return
try:
# 定位目标元素
element = driver.find_element(by, value)
print(f"已找到目标元素,开始点击(间隔{interval}秒)")
count = 0
while True:
# 检查元素是否仍可点击
if element.is_displayed() and element.is_enabled():
element.click()
count += 1
print(f"已点击 {count} 次", end="\r")
else:
print("\n元素不可点击,停止操作")
break
# 控制点击次数
if click_count and count >= click_count:
print(f"\n已完成 {click_count} 次点击")
break
time.sleep(interval)
except KeyboardInterrupt:
print(f"\n用户手动终止,共点击 {count} 次")
except Exception as e:
print(f"\n操作出错:{str(e)}")
if __name__ == "__main__":
# 1. 连接已有浏览器(默认调试端口9222)
driver = connect_existing_browser(debug_port=9222)
if driver:
# 2. 配置点击参数(请根据实际元素修改)
# 定位方式参考:
# By.ID: 元素的id属性
# By.CLASS_NAME: 元素的class属性
# By.CSS_SELECTOR: CSS选择器(推荐,可通过浏览器开发者工具复制)
# By.XPATH: XPath路径(可通过浏览器开发者工具复制)
click_config = {
"by": By.CSS_SELECTOR,
"value": "button.submit-btn", # 替换为目标元素的定位值
"interval": 0.1, # 点击间隔(秒)
"click_count": None # 点击次数(None表示无限循环)
}
# 3. 执行自动点击
auto_click_element(driver, **click_config)
# 4. 保持浏览器连接(手动关闭)
input("按回车键退出程序...")