功能介绍
Grafana Loki是一组组件,可以组成一个功能齐全的日志聚合系统。Loki与其他日志系统不同是,它只会索引日志的元数据即labels(类似Prometheus的labels),日志数据本身会被压缩并分块(chunck)存储在对象存储中,也可以存储在本地文件系统中。小的索引和高度压缩的分块简化了操作,大大降低了Loki的成本。
基本特性
● 高效地利用内存为日志建立索引: 通过在一组标签上建立索引,索引可以比其他日志聚合产品小得多。更少的内存使其运行成本更低。
● 多租户: 允许多个租户使用一个Loki实例。不同租户的数据与其他租户是完全隔离的。多租户是通过在代理中分配一个租户ID来配置的。
● LogQL,Loki的查询语言: Prometheus的查询语言PromQL的用户会发现LogQL在生成针对日志的查询方面非常熟悉和灵活。该语言还有助于从日志数据中生成指标,这是一个强大的功能,远远超出了日志聚集的范围。
● 可扩展性: Loki可以作为一个单一的二进制文件运行;所有的组件都在一个进程中运行。Loki是为可扩展性设计的,因为Loki的每个组件都可以作为微服务运行。配置允许单独扩展微服务。
● 灵活性: 许多Agent都有插件支持。这使得当前的可观察性技术栈可以添加Loki作为他们的日志聚合工具,而不需要切换观察技术栈的现有部分。
● Grafana集成: Loki与Grafana无缝集成,提供了一个完整的可观察性栈。
系统架构
组件介绍
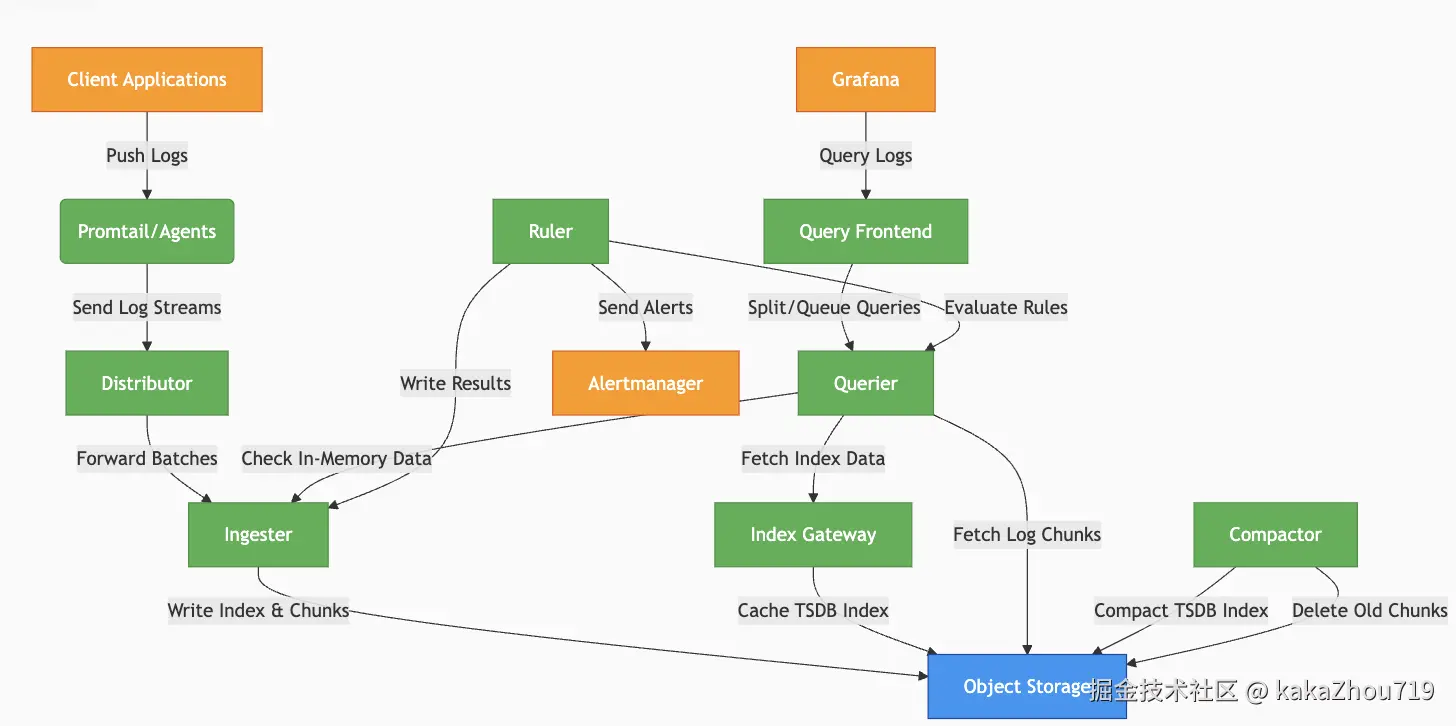
● distributor: 数据接收器,采样数据验证,分发,和限流。
● ingester:生成索引,同时写入索引和日志块到对象存储。
● compactor:s3数据整合压缩。
● query-frontend:内置查询请求队列,聚合缓存查询请求。
● querier:执行logQL语言,从s3查询数据,从ingester查询最近数据
● Ruler: 执行告警/记录规则,结果写回 Loki 或推给 Alertmanager
● Index gateway: 索引缓存层,提供 TSDB 索引的快速查询。
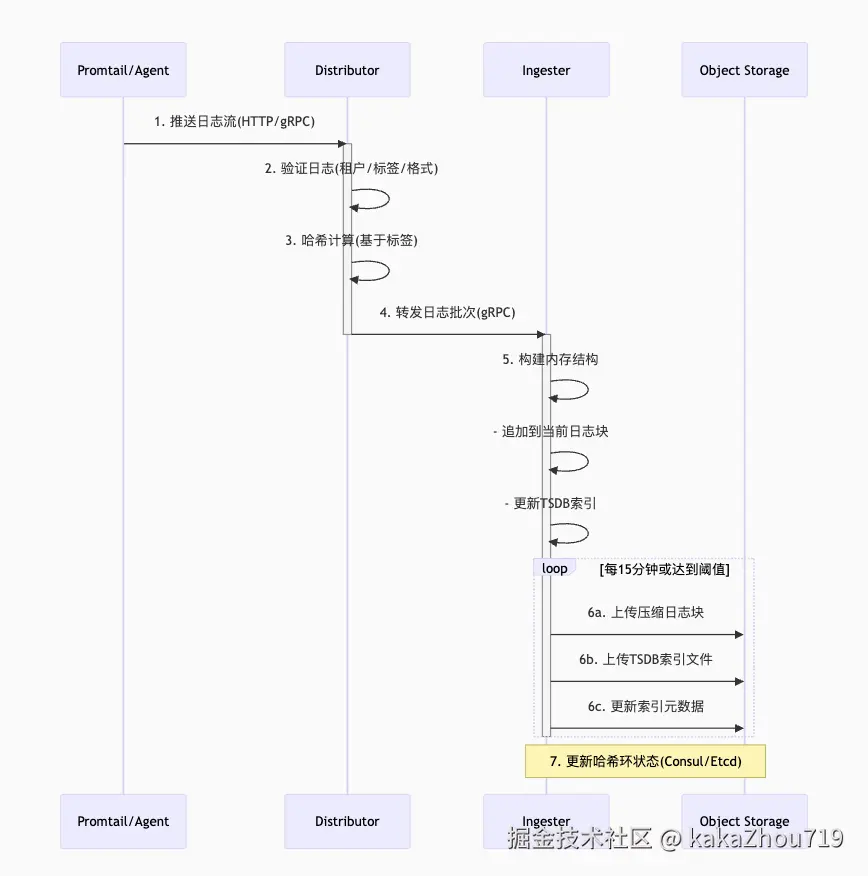
写流程
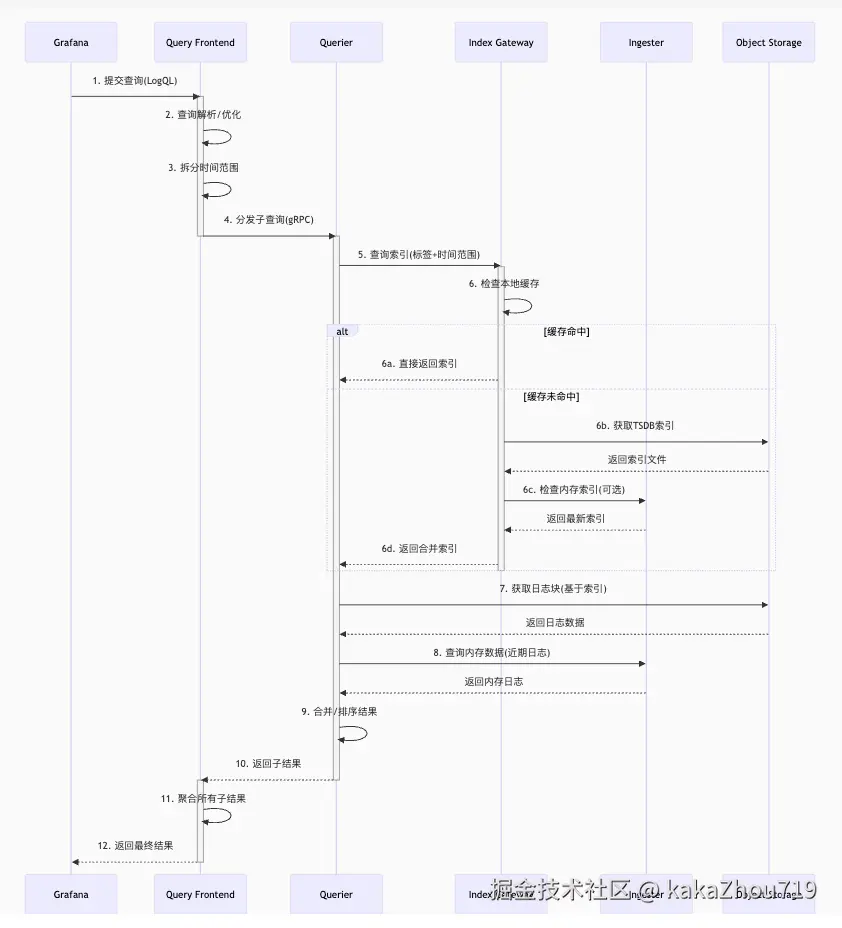
读流程
索引设计
BoltDB(已废弃)
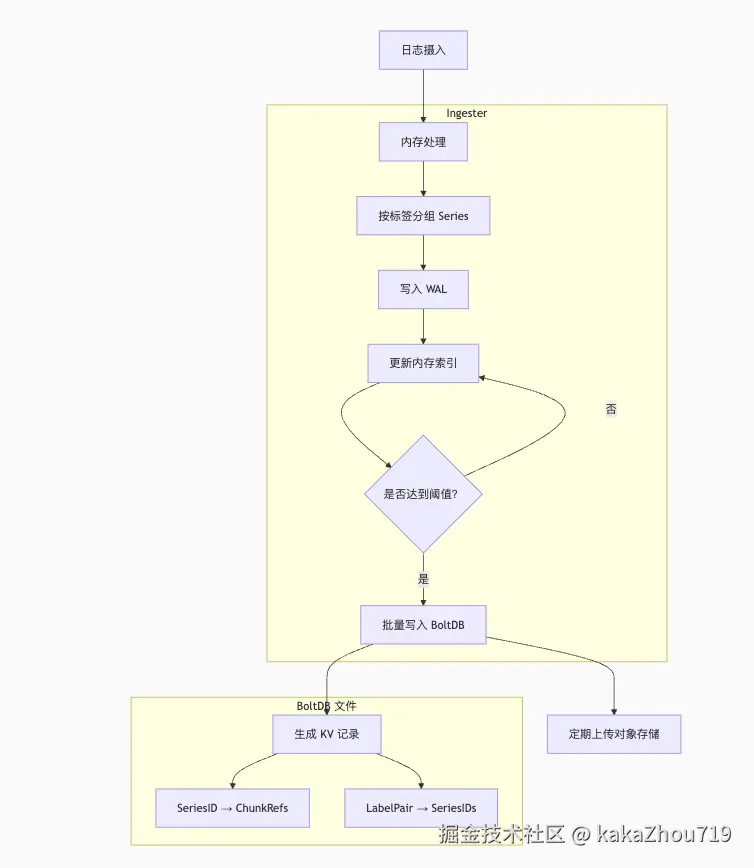
TSDB
存储示意图
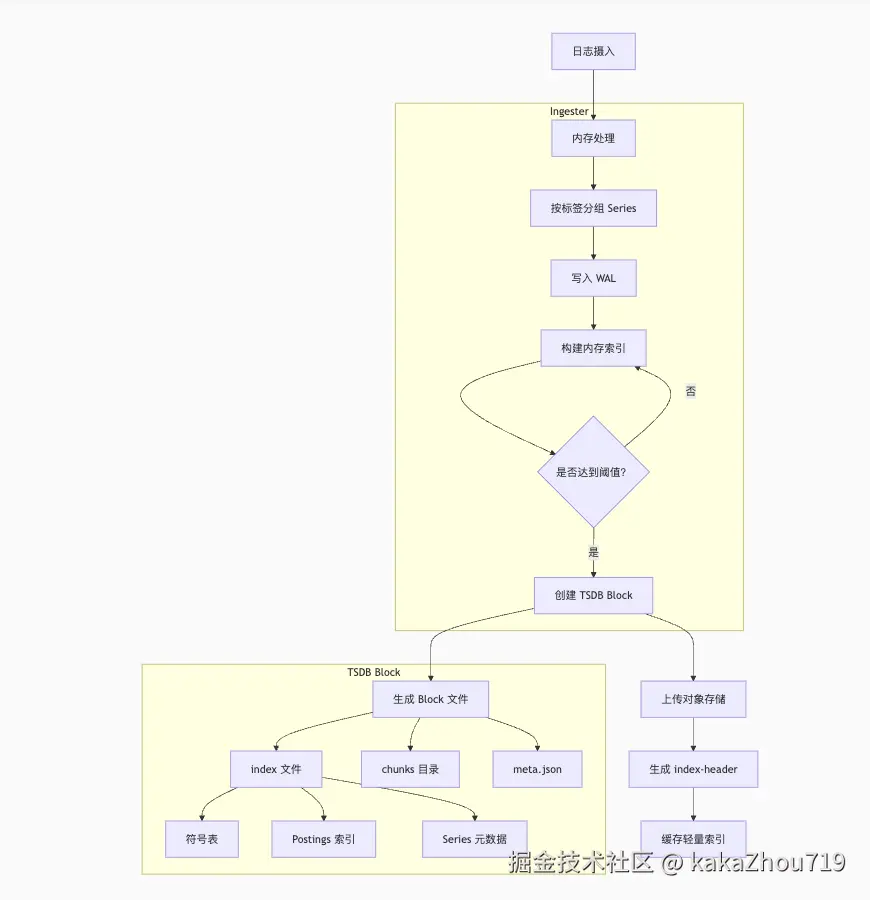
TSDB 带来的关键优化点:
-
高效倒排索引: 基于标签的快速 Series 查找是查询性能的核心。TSDB 的 Postings Lists 和符号化极大加速了流选择器匹配。
-
时间分区剪枝: 按固定时间窗口(Block)组织索引,使得 Querier 能快速跳过大量不相关的历史数据索引,显著减少需要加载和处理的索引量。这是相对于旧版 BoltDB 索引(单一大文件)的革命性改进。
-
index-header 机制: 避免了加载整个巨大的 index 文件(可能 GB 级别)。轻量级的 index-header 使得快速定位成为可能,大大降低了索引访问开销,尤其对于对象存储(高延迟)。
-
高基数处理: TSDB 专为 Prometheus 的高基数监控指标设计,其索引压缩和存储格式(如 Roaring Bitmaps 处理 Postings Lists)天然适合 Loki 日志标签可能产生的高基数场景。
-
压缩: 符号表、Postings Lists 的压缩存储显著减少了索引存储空间和网络传输量(尤其是 index-header)。
-
并行性: 查询分片 (Query Frontend) 和 chunk 下载/处理的并行性充分利用了分布式资源
存储格式:
每个时间段内,按照tenant ID分别存储不同的 .tsdb
配置样例:
yaml
schema_config:
configs:
# Old boltdb-shipper schema. Included in example for reference but does not need changing.
- from: "2023-01-03" # <---- A date in the past
index:
period: 24h
prefix: index_
object_store: gcs
schema: v12
store: boltdb-shipper
# New TSDB schema below
- from: "2023-01-05" # <---- A date in the future
index:
period: 24h
prefix: index_
object_store: gcs
schema: v13
store: tsdb
storage_config:
# Old boltdb-shipper configuration. Included in example for reference but does not need changing.
boltdb_shipper:
active_index_directory: /data/index
build_per_tenant_index: true
cache_location: /data/boltdb-cache
index_gateway_client:
# only applicable if using microservices where index-gateways are independently deployed.
# This example is using kubernetes-style naming.
server_address: dns:///index-gateway.<namespace>.svc.cluster.local:9095
# New tsdb-shipper configuration
tsdb_shipper:
active_index_directory: /data/tsdb-index
cache_location: /data/tsdb-cache
index_gateway_client:
# only applicable if using microservices where index-gateways are independently deployed.
# This example is using kubernetes-style naming.
server_address: dns:///index-gateway.<namespace>.svc.cluster.local:9095
query_scheduler:
# the TSDB index dispatches many more, but each individually smaller, requests.
# We increase the pending request queue sizes to compensate.
max_outstanding_requests_per_tenant: 32768
querier:
# Each `querier` component process runs a number of parallel workers to process queries simultaneously.
# You may want to adjust this up or down depending on your resource usage
# (more available cpu and memory can tolerate higher values and vice versa),
# but we find the most success running at around `16` with tsdb
max_concurrent: 16日志存储
存储格式

如上图所示,将一条日志分为: label 组合 + 日志message
index: 存储每个label组合 streamID,
chunks:存储原始的日志message内容,可以根据streamID被查询下载到。
存储流程
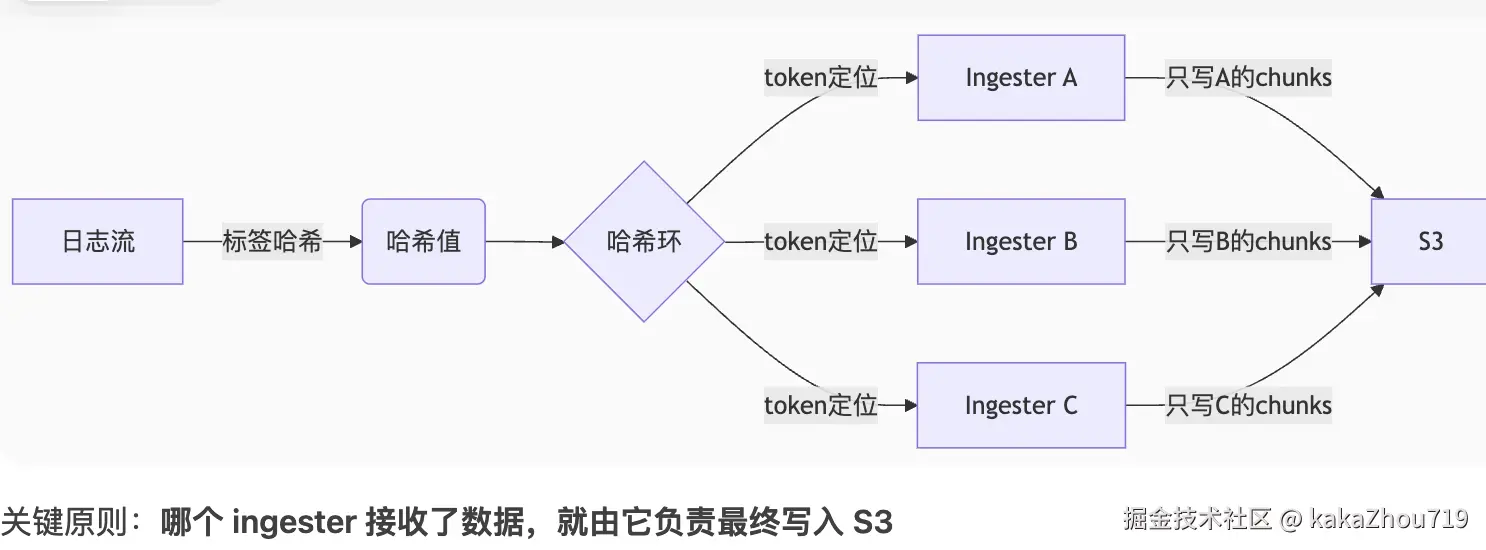
-
在数据上传之前,三个副本的本地缓存数据是相同的。
-
只有主副本负责上传(正常情况下)。
-
从副本在上传成功后丢弃数据,因此它们不会重复上传。
-
如果主副本失败,从副本会接替上传任务。
每条日志会被distributor计算hash,并同时分发到ingrester中,因为ingester使用memberlist存储hash ring, 各自ingester的处理范围不一样,就只能有一个ingester去写s3.
亮点设计
hash ring
hash 每一条日志的label,负载均衡的选择不同ingester来处理数据。每个ingester包含不同范围的token。hash ring 的数据结构存储在memberlist集群中。
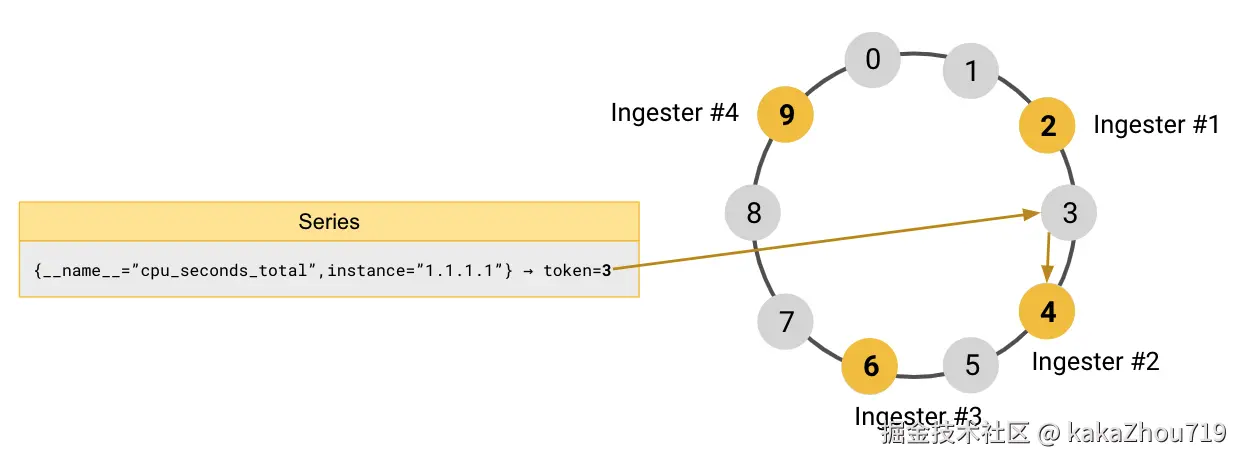
hash ring数据,3个backend的节点,分别纳管不同范围的token,当hash label命中某个范围的backend的时候,就由它来处理数据。

bloom filter
WIP
配置详情
部署模式
● SingleBinary
all in one 部署
所有组件在一个进程中, 命令行指定 -target=all。
● SimpleScalable
读写分离部署
读组件:Query Frontend和Querier, 命令行指定-target=write
写组件:Distributor和Ingester, 命令行指定-target=read
后端组件:Compactor,Index Gateway,Query Scheduler,Ruler . 命令行指定-target=backend
● Distributed
分布式微服务模式部署,组件清单:
| 组件名称 | 默认 replica 个数 |
|---|---|
| Compactor | 1 |
| Distributor | 3 |
| IndexGateway | 2 |
| Ingester | 3 |
| Querier | 3 |
| QueryFrontend | 2 |
| QueryScheduler | 2 |
配置介绍
yaml
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
log_level: debug
grpc_server_max_concurrent_streams: 1000
common:
instance_addr: 127.0.0.1
path_prefix: /tmp/loki
storage:
filesystem:
chunks_directory: /tmp/loki/chunks
rules_directory: /tmp/loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
query_range:
results_cache:
cache:
embedded_cache:
enabled: true
max_size_mb: 100
limits_config:
metric_aggregation_enabled: true
enable_multi_variant_queries: true
schema_config:
configs:
- from: 2020-10-24
store: tsdb
object_store: filesystem
schema: v13
index:
prefix: index_
period: 24h
pattern_ingester:
enabled: true
metric_aggregation:
loki_address: localhost:3100
ruler:
alertmanager_url: http://localhost:9093
frontend:
encoding: protobuf安装配置demo
使用kind创建3个noded的k8s集群
yaml
# kind-3-node.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: workerrun below cmd:
css
kind create cluster --name my-cluster --config kind-3-node.yaml- loki 微服务模式部署
values.yaml
yaml
loki:
auth_enabled: true # 开启认证:要求必须传递tenant ID 在header里。
schemaConfig:
configs:
- from: "2024-04-01"
store: tsdb
object_store: s3
schema: v13
index:
prefix: loki_index_
period: 24h
ingester:
chunk_encoding: snappy
querier:
# Default is 4, if you have enough memory and CPU you can increase, reduce if OOMing
max_concurrent: 4
pattern_ingester:
enabled: true
limits_config:
allow_structured_metadata: true
volume_enabled: true
ui:
# Disabled by default for backwards compatibility. Enable to use the Loki UI.
enabled: true
gateway:
enabled: true
deploymentMode: Distributed # 微服务模式部署
ingester:
replicas: 3 # To ensure data durability with replication
zoneAwareReplication:
enabled: false
querier:
replicas: 3 # Improve query performance via parallelism
maxUnavailable: 2
queryFrontend:
replicas: 2
maxUnavailable: 1
queryScheduler:
replicas: 2
distributor:
replicas: 3
maxUnavailable: 2
compactor:
replicas: 1
indexGateway:
replicas: 2
maxUnavailable: 1
bloomPlanner:
replicas: 0
bloomBuilder:
replicas: 0
bloomGateway:
replicas: 0
backend:
replicas: 0
read:
replicas: 0
write:
replicas: 0
singleBinary:
replicas: 0
# This exposes the Loki gateway so it can be written to and queried externaly
gateway:
service:
type: LoadBalancer
# Enable minio for storage
minio:
enabled: true
rootUser: root
rootPassword: supersecretpassword
users:
- accessKey: logs-user
secretKey: supersecretpassword
policy: readwrite
arduino
helm install -n loki --create-namespace -f values.yaml loki grafana/loki
- fluent-bit配置
ini
[OUTPUT]
Name loki
Match *
host loki-distributor.loki.svc.cluster.local
uri /loki/api/v1/push
tenant_id kakazhou
Labels job=fluent-bit
arduino
helm install -n fluent-bit --create-namespace fluent-bit fluent/fluent-bit -f values.yaml- grafana
arduino
helm install -n grafana --create-namespace grafana grafana/grafana- 访问
bash
# 访问minio
kubectl port-forward --namespace loki svc/loki-minio-console 9001:9001 &
# 访问loki gateway
kubectl port-forward --namespace loki svc/loki-gateway 3100:80 &
# 访问grafana
kubectl port-forward --namespace grafana svc/grafana 3000:80 &