一、项目背景与初始问题
本项目的核心功能是提供短链跳转服务。除了基本的跳转,还需要精确记录每一次点击事件,包括来源、设备、IP 等信息。
- 部署架构: 项目前后端在本地运行,Redis 部署在远程云服务器,MySQL 在本地。
- 性能痛点 : 初始设计中,每次跳转 (
302 Redirect) 都会同步执行两次数据库写操作(增加当日点击数和总点击数),导致严重的性能瓶颈。 - 技术考量: 之所以未使用 Docker,是因为在当时的环境下,容器网络带来的额外开销(特别是访问远端 Redis 的 58ms RTT)被认为是不可接受的。
- 初始同步写操作
Java
@Async
@Transactional
public void recordClick(String shortCode) {
//当日点击数
dailyClickRepo.incrementClick(shortCode);
//总数增加一次
shortUrlRepository.incrementClickCount(shortCode);
}2.记录点击事件,解析用户信息
Java
public void recordClickEvent(String shortCode, HttpServletRequest request) {
String referer = request.getHeader("Referer");
String ua = request.getHeader("User-Agent");
String ip = extractIp(request);
String host = extractHost(referer);
String device = detectDevice(ua);
clickRecorderService.recordClickEvent(shortCode, referer, ua, ip, host, device);
}二、压测对比
1.注释两次写操作
压测结果显示:
- 吞吐量 (RPS) : 稳定且高。
- 延迟 (http_req_duration) : P95 约 3.07ms,平均约 1.15ms。
- 错误率: 几乎为 0。
- 结论: 无写操作时,跳转接口性能极佳,瓶颈明确指向写操作。
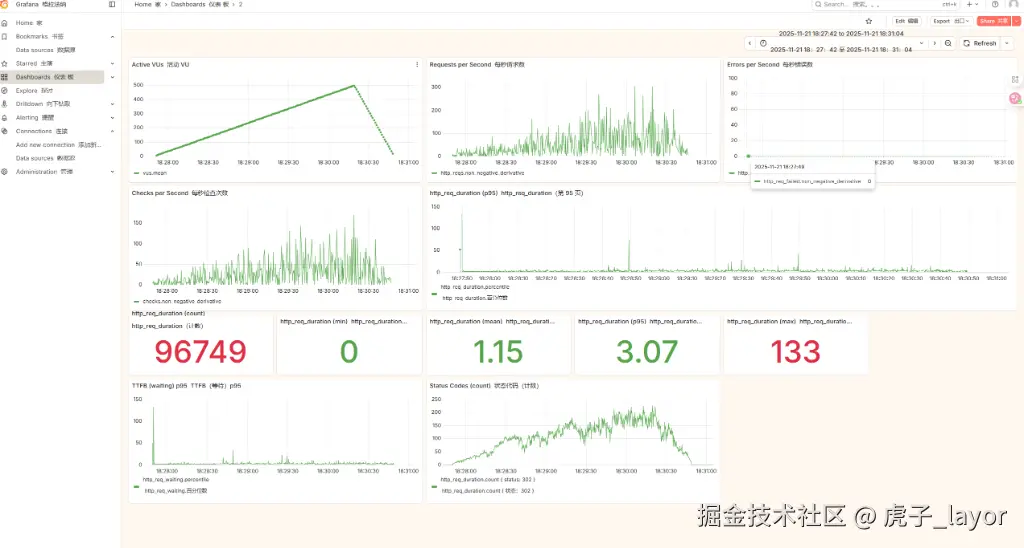
2.启用同步写操作
压测结果显示:
- 吞吐量 (RPS) : 明显下降。
- 延迟 (http_req_duration) : P95 飙升至约 1956ms,最大延迟达 7181ms。TTFB (Time To First Byte) P95 也达到了约 3 秒。
- 错误率: 仍接近 0,说明功能正确,但性能严重受损。
- 结论 : 同步写操作成为性能瓶颈。频繁的远程 Redis 写入和本地 MySQL 更新,在热点路径上造成显著的"写放大"效应和资源争用(如连接池、磁盘 IO),拖慢了整个响应过程。
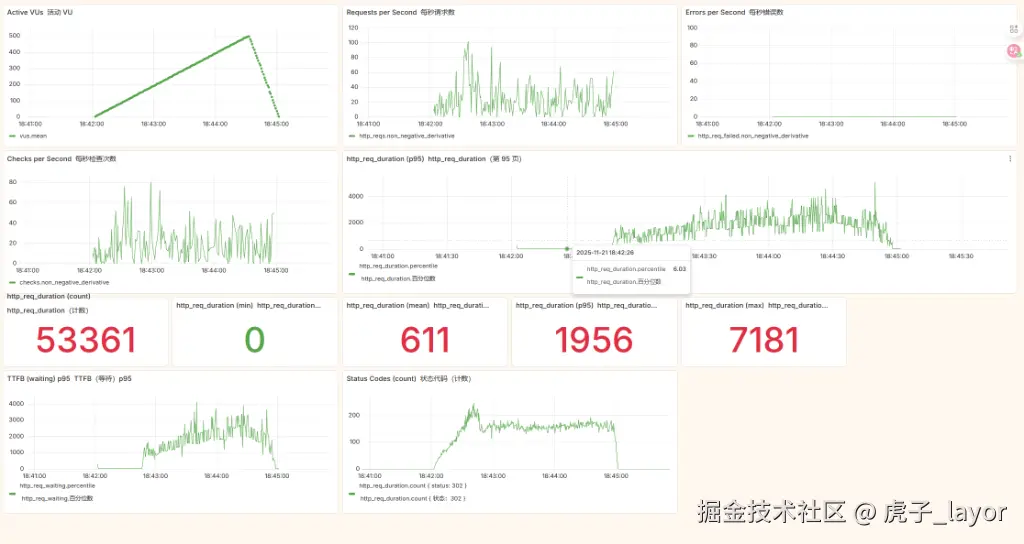
三、优化
针对上述问题,我们采取了循序渐进的优化措施。
第一阶段:异步解耦写操作
问题 : 主流程被同步写操作阻塞。 优化 : 利用 Spring 的 @Async 注解,将写操作移出主线程。 实现:
java
// 优化前:同步写入(阻塞)
public void recordClick(String shortCode) {
dailyClickRepo.incrementClick(shortCode);
shortUrlRepository.incrementClickCount(shortCode);
}
// 优化后:异步写入(不阻塞)
@Async
public void recordClick(String shortCode) {
dailyClickRepo.incrementClick(shortCode);
shortUrlRepository.incrementClickCount(shortCode);
}配置线程池:
java
@SpringBootApplication
@EnableAsync
@EnableScheduling
public class TinyFlowApplication {
@Bean
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(32); // 默认很小,扩容
executor.setMaxPoolSize(128);
executor.setQueueCapacity(20000);
executor.setThreadNamePrefix("async-");
executor.initialize();
return executor;
}
}效果: 主流程立即返回,用户感知延迟大幅降低。但数据库写压力依然存在。
第二阶段:Redis 原子计数
问题 : 数据库写入频率过高。 优化 : 将计数操作下沉到高性能的 Redis,利用其原子自增指令。 实现:
java
// 使用 Redis 原子计数
@Async
public void recordClick(String shortCode) {
// Redis 原子自增
redisTemplate.opsForValue().increment("click:daily:" + shortCode, 1);
redisTemplate.opsForValue().increment("click:total:" + shortCode, 1);
}效果: 数据库写入频率大幅降低,Redis 承担计数压力
第三阶段:内存缓冲与定时批量刷库
问题: Redis 写入虽快,但仍需最终持久化到数据库。
优化: 在应用内存中累积计数变更,通过定时任务批量更新数据库。
实现:
java
@Service
public class ShortUrlService {
// 内存累加器(原子计数)
private final ConcurrentHashMap<String, AtomicLong> clickBuffer = new ConcurrentHashMap<>();
// 异步写入(不阻塞主流程)
@Async
public void recordClick(String shortCode) {
clickBuffer.computeIfAbsent(shortCode, k -> new AtomicLong(0)).incrementAndGet();
}
// 定时批量刷库(每2秒)
@Scheduled(fixedRate = 2000)
public void flushClicksToDB() {
if (clickBuffer.isEmpty()) return;
// 快照并重置计数器(避免并发问题)
Map<String, Long> snapshot = new HashMap<>();
clickBuffer.forEach((code, count) -> {
long value = count.getAndSet(0); // 原子读取并重置
if (value > 0) snapshot.put(code, value);
});
// 批量更新数据库(减少连接消耗)
for (Map.Entry<String, Long> entry : snapshot.entrySet()) {
dailyClickRepo.incrementClick(entry.getKey(), entry.getValue());
shortUrlRepository.incrementClickCount(entry.getKey(), entry.getValue());
}
}
}效果: 数据库写入从"每次请求"变为"每2秒批量",效率大幅提升
第四阶段:引入本地缓存 (Caffeine)
问题: 查询长链时,即便使用了 Redis,跨公网访问仍有 10ms 级别的延迟。
优化: 在应用本地引入高性能缓存 Caffeine,构建 L1 (本地) + L2 (Redis) + L3 (DB) 三级缓存体系。
实现:
java
// 简单 HashMap 缓存
private Map<String, String> localCache = new ConcurrentHashMap<>();
public String getLongUrlByShortCode(String shortCode) {
// L1: 本地 HashMap 缓存
String cachedUrl = localCache.get(shortCode);
if (cachedUrl != null) return cachedUrl;
// L2: Redis 缓存
// L3: 数据库
}效果: 本地缓存命中后响应时间从 10ms级降至毫秒级
第五阶段:连接池优化 + 缓存预热
问题 : 高并发下可能出现连接池耗尽,冷启动时缓存未命中导致延迟尖刺。 优化:
- 扩大连接池: 增加数据库和 Redis 连接池的最大连接数。
- 缓存预热: 应用启动时主动加载热点数据到 L1 缓存。
实现:
- 扩大连接池配置
yaml
# 连接池优化
spring:
datasource:
hikari:
maximum-pool-size: 50
data:
redis:
lettuce:
pool:
max-active: 400
server:
tomcat:
threads:
max: 400 - 实现缓存预热机制
java
@Service
public class ShortUrlService {
@Value("${cache.warmup.enabled:true}")
private boolean warmupEnabled;
@Value("${cache.warmup.size:1000}")
private int warmupSize;
@PostConstruct
public void warmupCache() {
if (!warmupEnabled) return;
try {
log.info("Starting cache warmup, loading top {} hot URLs...", warmupSize);
Pageable topN = PageRequest.of(0, warmupSize);
Page<ShortUrl> hotUrls = shortUrlRepository.findAll(topN);
int loaded = 0;
for (ShortUrl url : hotUrls.getContent()) {
localCache.put(url.getShortCode(), url.getLongUrl());
loaded++;
}
log.info("Cache warmup completed: {} URLs loaded to L1 cache", loaded);
} catch (Exception e) {
log.error("Cache warmup failed: {}", e.getMessage(), e);
}
}
}效果: 系统稳定性提升,冷启动不再慢
第六阶段:本地缓存升级为 Caffeine
问题: HashMap 无淘汰策略,可能内存溢出
优化: 使用 Caffeine 替代 HashMap
实现:
java
// CacheConfig.java
@Configuration
public class CacheConfig {
@Bean("localUrlCache")
public Cache<String, String> localUrlCache() {
return Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build();
}
}
// ShortUrlService.java
@Service
public class ShortUrlService {
@Autowired
@Qualifier("localUrlCache")
private Cache<String, String> localCache;
public String getLongUrlByShortCode(String shortCode) {
// L1: 本地缓存(毫秒级响应)
String cachedUrl = localCache.getIfPresent(shortCode);
if (cachedUrl != null) return cachedUrl;
// L2: Redis 缓存(网络延迟)
String redisUrl = redisTemplate.opsForValue().get("short_url:" + shortCode);
if (redisUrl != null) {
localCache.put(shortCode, redisUrl);
return redisUrl;
}
// L3: 数据库(最慢)
ShortUrl shortUrl = shortUrlRepository.findByShortCode(shortCode);
if (shortUrl != null) {
String longUrl = shortUrl.getLongUrl();
redisTemplate.opsForValue().set("short_url:" + shortCode, longUrl, Duration.ofHours(24));
localCache.put(shortCode, longUrl);
return longUrl;
}
return null;
}
}效果: 自动淘汰冷数据,支持统计信息,更专业的缓存管理
第七阶段:精细化调优
问题 : 系统仍有优化空间,且需要防止突发流量打垮系统。 优化:
- 参数微调: 根据压测反馈,进一步精细调整连接池、线程池、Tomcat 线程数等参数。
- 实施限流: 使用 Resilience4j 等组件,在入口处限制请求速率,保护下游服务。
yaml
# 精细化配置
spring:
datasource:
hikari:
maximum-pool-size: 100 # 50 → 100
data:
redis:
lettuce:
pool:
max-active: 600 # 400 → 600
resilience4j:
ratelimiter:
instances:
redirectLimit:
limitForPeriod: 3000 # 基于实测调整效果: 系统能稳定支撑 3000 QPS,性能达到最优状态
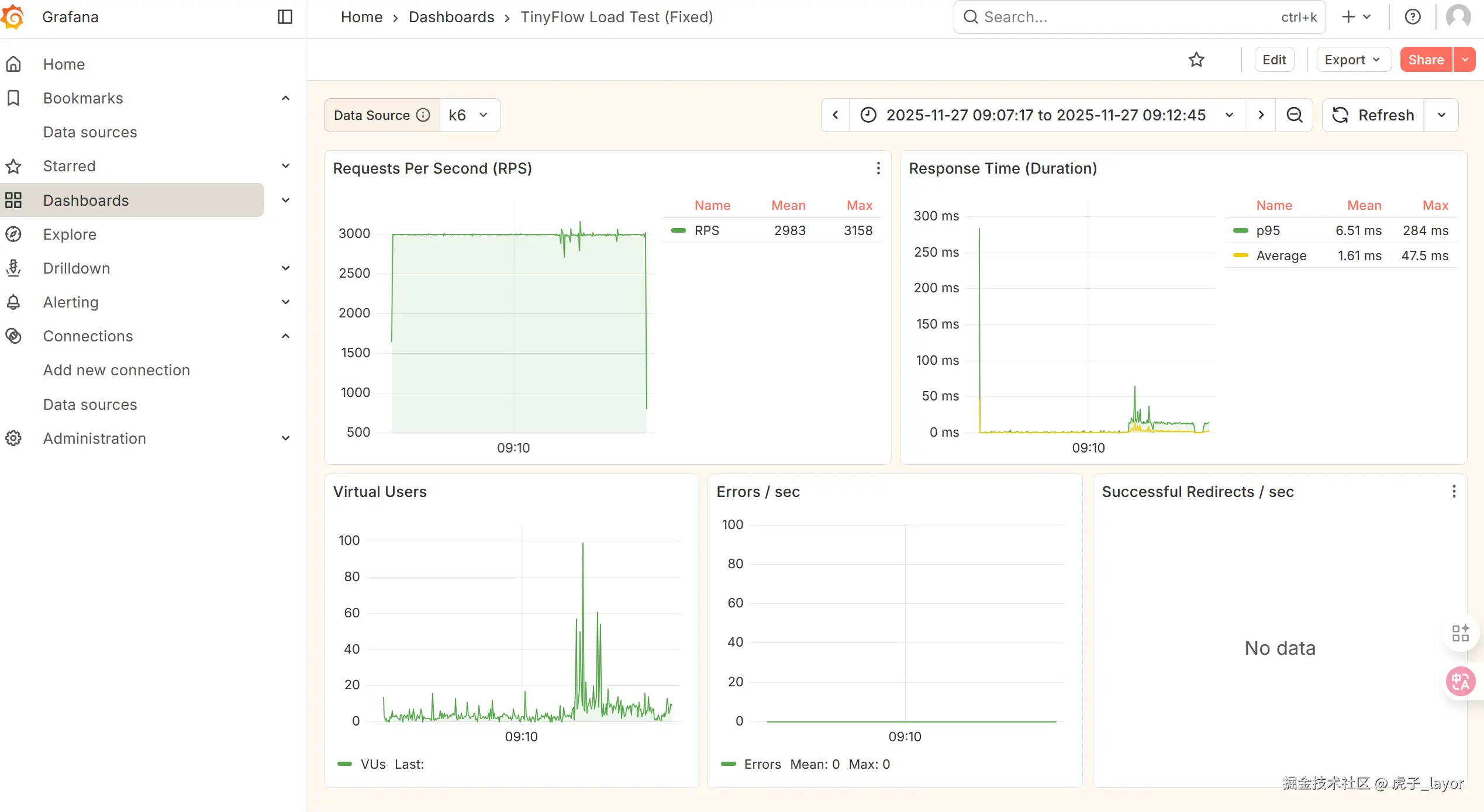 如果不限流,把qps提到5000的效果:并不稳定,所以我先流至3000qps保护系统正常运行。
如果不限流,把qps提到5000的效果:并不稳定,所以我先流至3000qps保护系统正常运行。
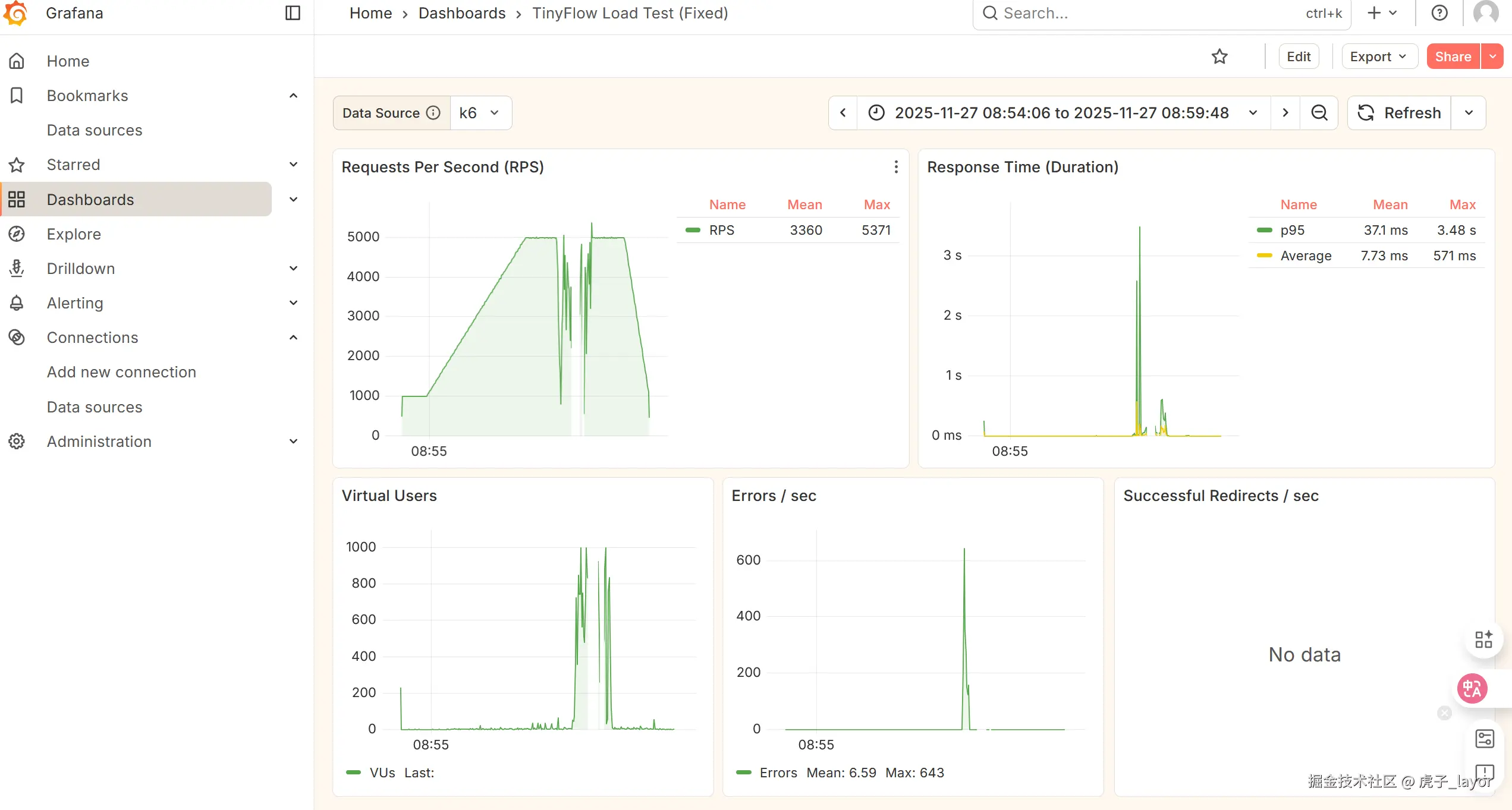
总结:
对比优化前:
| 指标 | 优化前 | 优化后(3000 QPS) | 提升 |
|---|---|---|---|
| P95 延迟 | ~1956ms | 8.05ms | 降低 99.6% |
| 最大延迟 | ~7181ms | 585ms | 降低 91.8% |
| 失败率 | 0% | 0% | 保持稳定 |
| 吞吐量 | 100-500 QPS | 稳定3000 QPS | 提升 500% |
关键的优化:
- 异步解耦: 将耗时操作移出主流程。
- 线程池调优: 为异步任务配置合适的线程池。
- 计数下沉: 利用 Redis 原子操作替代数据库写入。
- 批量刷盘: 将高频写合并为低频批量写。
- 本地缓存 (Caffeine) : 构建多级缓存体系,极致压缩读延迟。
- 缓存预热: 消除冷启动延迟尖刺。
- 连接池/Tomcat 调优: 提升高并发承载力。
- 限流保护: 保障系统稳定性。
后续的优化方向,后续更新:
- JVM调优+监控
- 熔断器
- 消息队列
- 水平扩展
- 读写分离
- 压测报告
写在最后:
这是作者第一次记录调优,中间也出现了许多问题,性能优化也不是稳定提升的,但主要还是上升的趋势,没有记录那么完整平滑的优化过程,只能大概的优化可以以图片的形式展示: