海量数据读写方式选择
高并发读写场景分析
无论任何业务系统,无非就是两个操作:写和读。 在海量数据和高并发的场景下,写和读就会成为系统性能的瓶颈。下面分析不同业务场景下面临的问题:
侧重"高并发读"的系统
- 场景1:搜索引擎。 C端用户包括网页发布者(写)和网页搜索者(读), 但是读和写明显不是一个数量级。
- 场景2:电商的商品搜索。
- 场景3:电商的商品详情
侧重"高并发写"的系统
场景1:广告扣费系统。
广告通常要么按浏览付费,要么按点击付费(业界叫作 CPC或 CPM)。具体来说,就是广告主在广告平台开通一个账号,充一笔钱进去,然后投放自己的广告。C端用户看到了这个广告后,可能点击一次扣一块钱(CPC);或者浏览这个广告,浏览1000次扣10块(CPM)。
扣款要尽可能实时,如果慢扣了, 就可能造成广告主没有钱了,但是广告仍在播放。
同时侧重"高并发读写"的系统
- 场景1:秒杀系统
- 场景2: 12306网站的火车售卖
- 场景3:支付系统和微信红包。 用户需要实时查看自己的余额,这个值需要实时并且准确;另外,在转账场景,A /B两个用户余额变动也要尽可能快,并且要求强一致性。
- 场景4:IM、微博、朋友圈。 C端用户要进行发消息和接受消息。这种用户规模在亿级别,无论读还是写,要求处理都要非常及时。
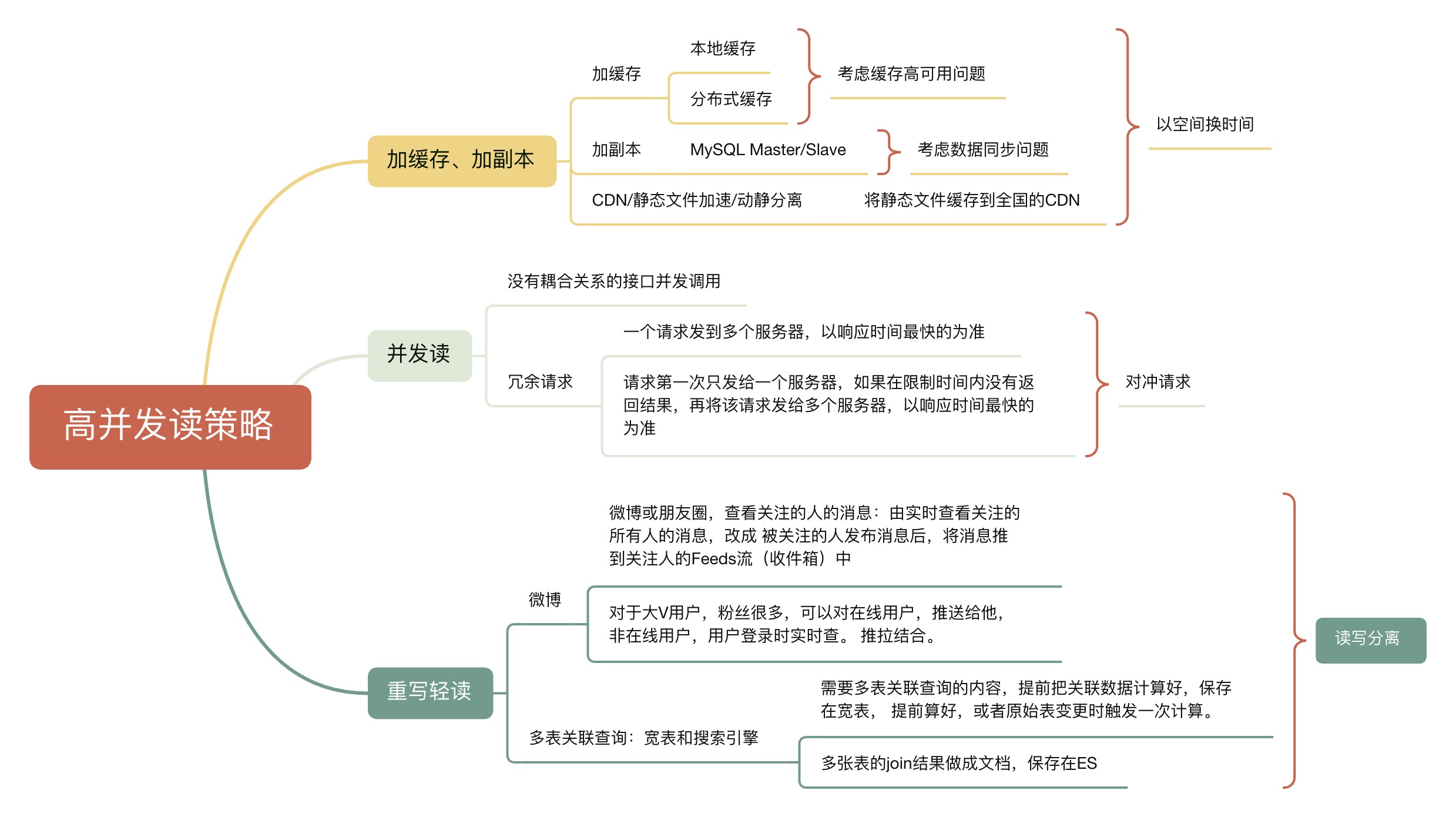
高并发读策略
本质:以空间换时间
高并发读的特征:读写分析,设计出是和高并发读的存储结构或者数据模型。
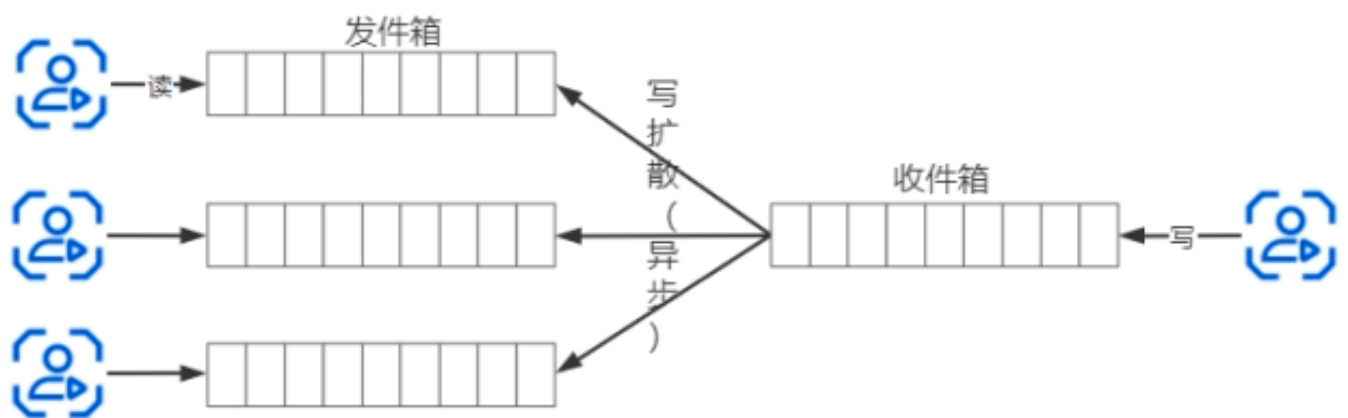
高并发写策略
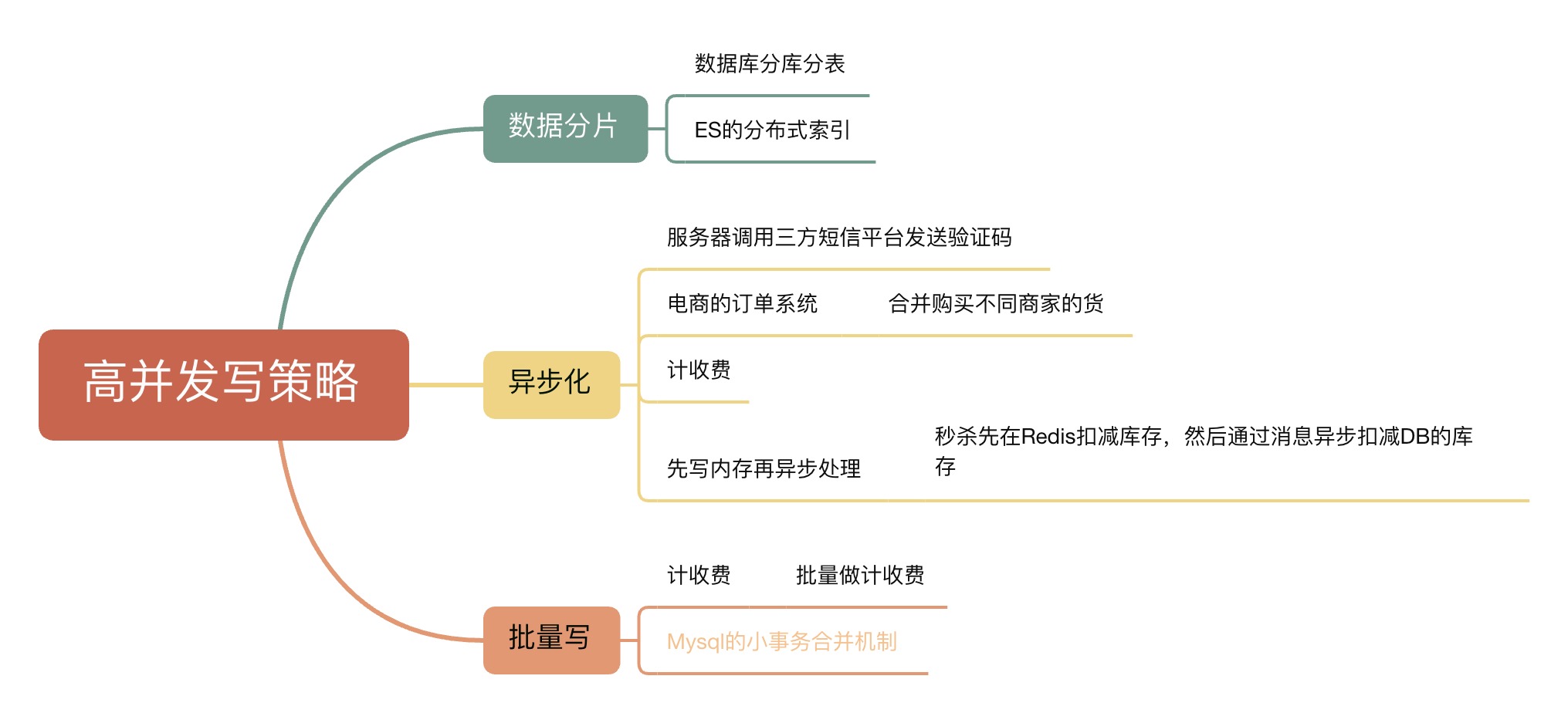
海量数据存储方式选择
存储系统(数据结构),往往决定了系统的上限;计算⽅式(算法)决定了能否发挥这个上限以及系统的下限。
选择时考虑的因素
-
在线业务系统 or 分析系统
-
数据量:存量和增量,对未来数据量可以考虑两三年的业务量
- 1GB以下:任意存储
- 1~10GB(1亿内):单机存储系统的处理上限
- 10GB以上:分布式存储
- TB : ⼀般需要事先对数据做聚合计算
3.成本:运维成本、学习成本
分析类系统常用的存储方式
- 一些列式数据库,比如Hbase、Cassandra、ClickHouse 等
- ES, 为搜索⽽⽣的存储产品
当数据量级超过TB 级的时候,做数据统计分析,⽆论使⽤哪种存储系统,速度都快不了,这⾥的性能瓶颈主要在于磁盘IO和⽹络带宽。这么⼤量级的数据,⼀般是选择存储在HDFS中,配合Spark、 Hive等⼤数据⽣态圈产品,对数据进⾏聚合和计算。
Hadoop:是一个分布式计算的开源框架
**HDFS:**是Hadoop的三大核心组件之一
**Hive:**用户处理存储在HDFS中的数据,hive的意义就是把好写的hive的sql转换为复杂难写的map-reduce程序。
**Hbase:**是一款基于HDFS的数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
RocksDB
RocksDB是Facebook开源的⼀个⾼性能、持久化的KV存储引擎。简单理解成单机版的Redis.
Redis只是⼀个内存数据库,并不是⼀个可靠的存储引擎。在 Redis 中,数据写到内存中就算成功了,其并不能保证将数据安全地保存到磁盘上。⽽ RocksDB则是⼀个持久化的KV存储引擎,它需要保证每条数据都已安全地写到磁盘上。
RocksDB采⽤了⼀个⾮常复杂的数据存储结构(数据结构LSM-Tree),采⽤了内存和磁盘混合存储的⽅式,它使⽤磁盘来保证数据的可靠存储 的,并且会利⽤速度更快的内存来提升读写性能。
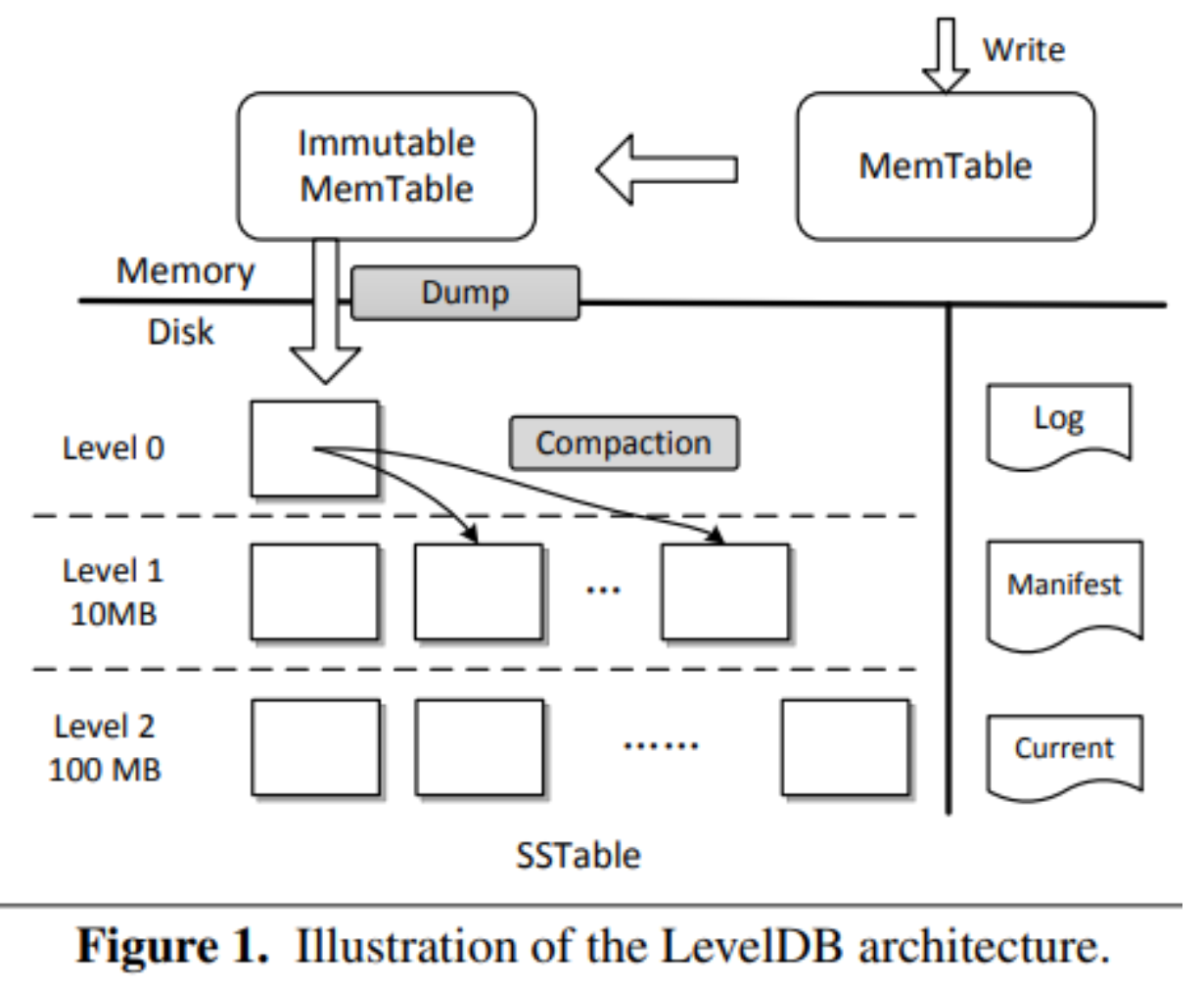
-
MemTable(内存)有⼀个固定的上限⼤⼩,⼀般是32MB; SSTable容量也是有限的。
-
Log : 顺序写磁盘,对应的磁盘WAL日志。唯⼀作⽤就是从故障中恢复系统数据
-
有⼀个后台线程,不停地把 ImmutableMemTable复制到磁盘⽂件中,然后释放内存空间
-
写入:MemTable(有序表) ->Immutable MemTable(不允许再写) ->磁盘文件(SSTable)-> 合并到下一层(并删除已合并的SSTable)
-
查找:分层查找。MemTable/Immutable MemTable -> SSTable -> 下一层SSTable
ES检索
ElasticSearch(简称ES)是一个分布式 、RESTful 风格的搜索和数据分析引擎,是用Java开发并且是当前最流行的开源的企业级搜索引擎,能够达到近实时搜索,稳定,可靠,快速,安装使用方便。客户端支持Java、.NET(C#)、PHP、Python、Ruby等多种语言。
应用场景
- 站内搜索
- 日志管理与分析
- 大数据分析
- 应用性能监控
- 机器学习
站内检索使用步骤
- 确定业务检索内容
比如,商城首页,根据关键字查询、根据品牌查询、商品类别、商品属性信息、价格区间、是否有库存、排序(销量、价格、上架时间等)
- 文档建模
- 确定要做分词的字段,分词器
- 确定keyword(不需要分词)
- 商户与属性的关联关系
-
定义mapping, 创建索引库
-
索引文档(检索文档)