买的电子书没有目录书签看着不舒服,手动加书签加到想吐。想有没有办法快速加书签。这要分为PDF目录部分可以被复制和不可被复制两种情况。不可复制时,要用到工具把目录提取出来,变成文字。
工具:Foxit Phantom福昕阅读器(下载链接:Foxit Phantom福昕阅读器官网)、excel、在线文字转换网址。
文字可复制
观察书签的格式,想办法变成我们需要的样子
先添加两个书签,然后导出,保存在一个你能找到的地方。
打开这个书签,观察它。可以发现,它的NAME和PAGE表示的是PDF的位置和书签的名字,我们要做的就是,把这部分内容替换成我们自己的内容 思考完发现,只要我们得到这两列数据,就可以
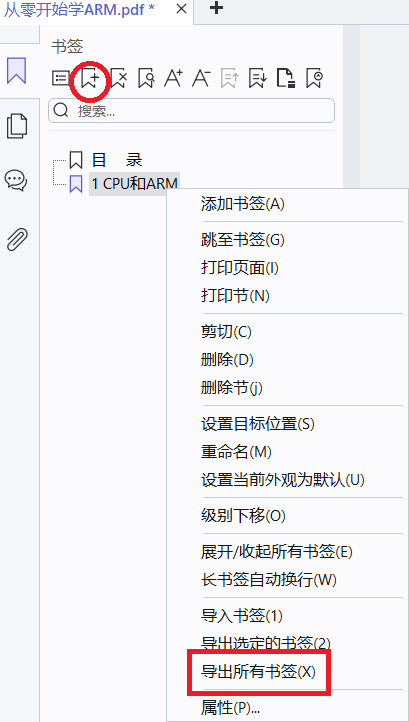
想办法得到"目录"和"页码"两列数据
替换的宗旨就是,把目录和页码分成两列
-
直接复制目录到一个文本文件中
-
全局替换页码前的"......"为"#"(其他符号也行,但是是点号、顿号和/经常出现在目录文字描述中,不要用)
-
文字复制到excel中
-
替换技巧:先替换"...",然后替换"#."为"#",要不然会把1.2.1中的"."替换掉。最后把"##"替换为"#"。
-
看一遍文本,确认是目录后是#和页码,才算干净

-
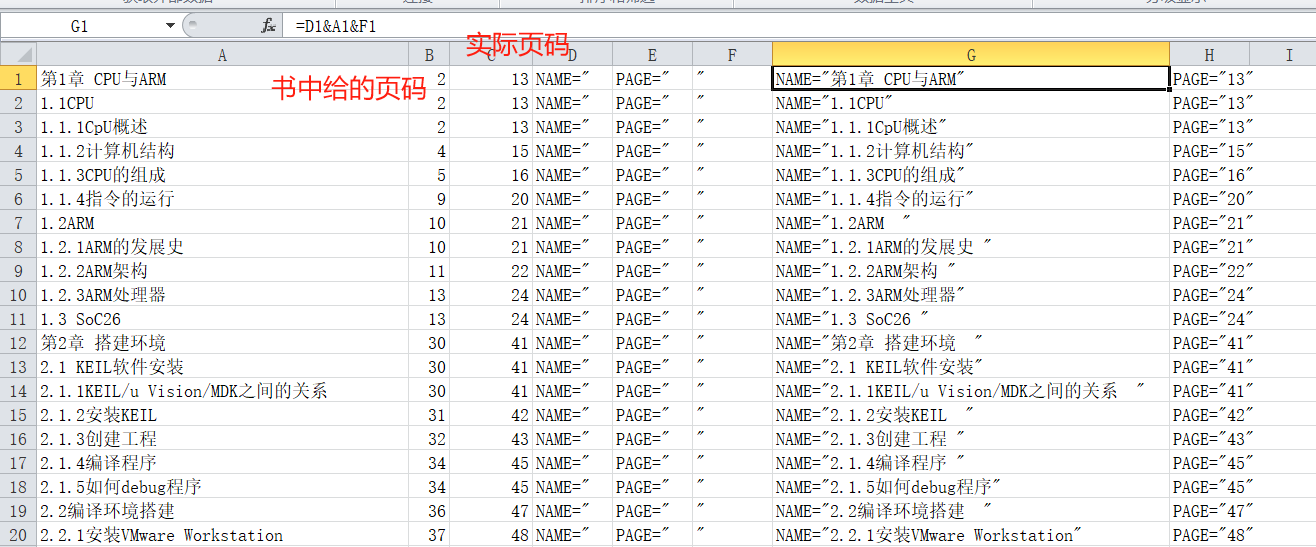
把处理好的文本文件粘贴到excel中,然后以"#"分列,标题和页码就分成了两列。
-
这里的页码是书的页码,还要都加上一个数字11(前面有几页,可以根据你导出的page值和实际值对应)变成PDF的页码
-
然后利用excel的函数功能&把单元格中的内容拼装成书签需要的格式。公式为"=A1&A3&A5"
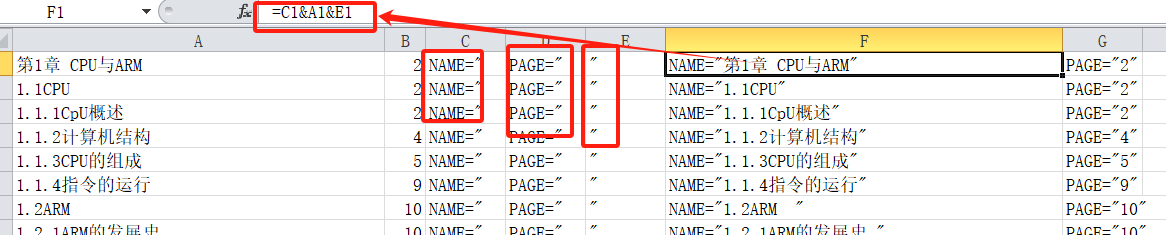
把目录按照一定的格式放进书签的xml中
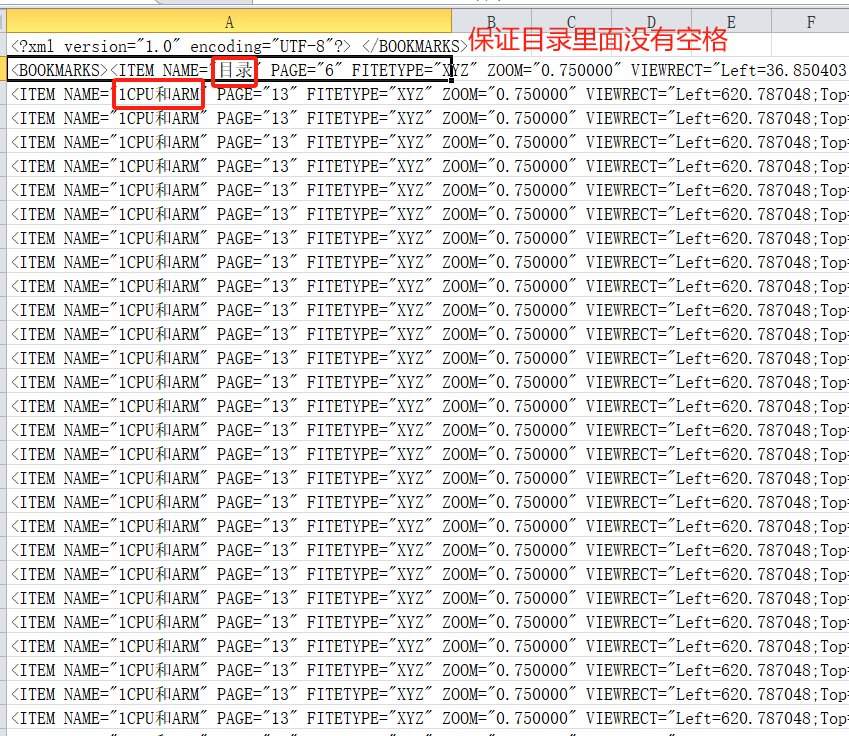
- 最后一行的""先粘贴出来放个位置
- 用下拉的方式,复制出很多的行的格式(目录有几个行就拉几个行)
- 再把""粘贴到最后一行去
- 数据--分列--"按照空格分列",然后就把NAME和PAGE分离出来了。
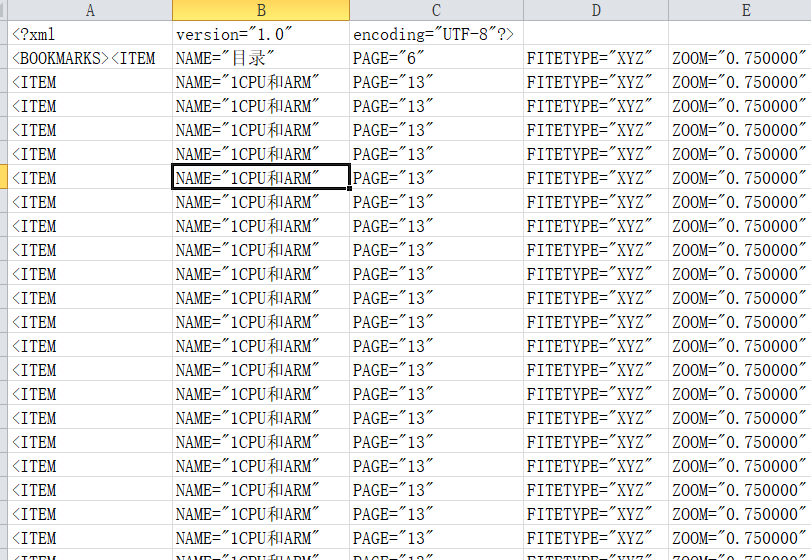
接下来把我们需要的NAME和PAGE填进去
- 步骤5中准备好的NAME和PAGE,覆盖书签图中的B和C列,注意以"123"只粘贴值的方式粘贴

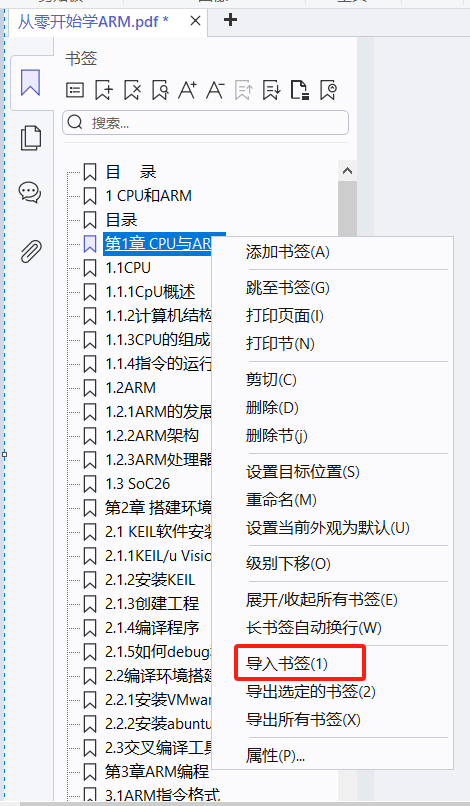
- 然后把excel中的内容粘贴回书签的xml中
- 打开书的书签,"导入书签"
- 分级的话,自己动手分级也挺方便
文字不可复制
用图片转文字功能,将文字提取出来,得到想要的格式。有一下几种途径:
- deepseek图片转文字(缺点:没页码,要自己加)
- https://ocr.wdku.net/,有点儿慢,但是可以在线使用
- 豆包等AI工具(缺点:要登录)