本文作者为 Rstack 团队 - ahabhgk。
Tree shaking 在如今的前端打包领域已成为极为重要且不可或缺的一部分。由于各个 bundler 的适用场景和侧重点存在差异,因此各个 bundler 之间的 tree shaking 实现方式也各不相同。例如,webpack 主要用于前端应用打包,侧重于正确性,其 tree shaking 主要关注跨模块级别的优化;而 Rollup 主要用于库打包,侧重于优化效率,其 tree shaking 以 AST 节点为粒度进行优化,打包产物通常更小,但对于一些边界情况的执行正确性缺乏保障。
本文将以概述的视角简要介绍各个 bundler 的 tree shaking 原理,以及各个 bundler 的 tree shaking 之间的差异。
什么是 tree shaking:你可以将应用程序想象成一棵树。绿色表示实际用到的源码和库,是树上活的树叶。灰色表示未引用代码,是秋天树上枯萎的树叶。为了除去死去的树叶,你必须摇动(shake)这棵树,使它们落下。
欢迎查看 Rspack 文档 了解更多。
Tree shaking in webpack / Rspack
目前 Rspack(v1.4)的 tree shaking 原理与 webpack 保持一致,因此下文将以 webpack 的实现方案为例进行介绍。与此同时,我们也在探索 Rspack 未来更加高效的 tree shaking 方案。
webpack 的 tree shaking 分三部分:
-
module-level:
optimization.sideEffects删除没有用到任何导出且没有副作用的模块-
import "./module";没有用到任何导出,且无副作用,可以删除 -
重导出模块(barrel file),本身没有任何导出被用到,且无副作用,可以删除
js// index.js import { a } from "./re-exports"; console.log(a); // re-exports.js export * from "./module"; // index -(a)-> re-exports -(a)-> module 优化为 index -(a)-> module 后,re-exports.js 本身没有任何导出被用到,且无副作用,可以删除 // module.js export const a = 42;
-
-
export-level:
optimization.providedExports和optimization.usedExports,删除没有用到的导出optimization.providedExports用来分析模块有哪些导出optimization.usedExports用来分析模块的哪些导出被用到,没用到则在代码生成时删除export:export const a = 42=>const a = 42,然后通过 minimizer 删除剩余声明部分,如果变量在模块内也没被用到的话
-
code-level:
optimization.minimize使用 swc / terser 等 minifier 对代码进行 inline、eval 等分析,删除无用代码并压缩,尽可能减小代码体积- minifier 都是通过
optimization.minimizer插件的方式与 bundler 进行集成,对 bundler 的产物进行后处理,并不属于 bundler 本身的职责范围
- minifier 都是通过
除此之外还有很重要的一部分:静态分析,module-level 和 export-level 需要 webpack 对代码进行静态分析,分析出模块是否有 side effects,以及模块有哪些导出、模块使用了哪些导出这些信息作为这些优化阶段的输入,所以理论上只要 webpack 的 javascript parser 能够静态分析出这些信息,就能够做 tree shaking,这也使得 cjs、dynamic import 这些虽然是动态的,但在静态写法下,只要能静态分析出这些信息,就能够 tree shaking。但目前来说 webpack 对 cjs 和 dynamic import 仅对很有限的场景做了静态分析,还有很多能够分析出来的场景没做,仍有一定的提升空间。
这三部分完成之后 tree shaking 已经能够工作了,但仍然会有些 cases 有问题:
-
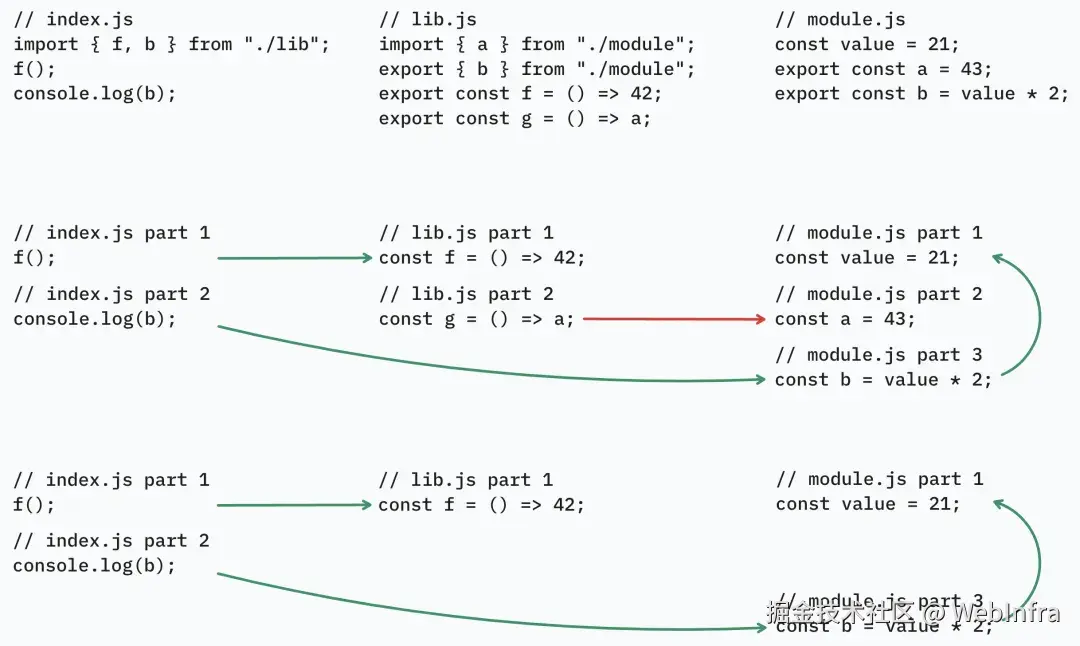
导出
a被另一个模块中没被使用的导出g使用,导致a不能被 tree shaking,此时需要optimization.innerGraph对lib.js分析出 top-level statements 之间的依赖关系,只有a所在的 top-level statement 被使用到时,a才会标记为被使用,否则为未被使用js// index.js import { f } from "./lib"; f(); // lib.js import { a } from "./module"; export const f = () => 42; export const g = () => a; // g 没有被用到,生成 const g = () => a,导致 a 被使用,a 不能被 tree shaking // module.js export const a = 42; -
一些 minifier 能优化的 cases,由于 webpack 生成的 runtime 对每个 module 包了一层函数,导致 minifier 不能优化,比如以下 case:
js// index.js import { aVeryLongLongLongName } from "./constants.js" console.log(aVeryLongLongLongName ? 1 : 2) // constants.js export const aVeryLongLongLongName = 42; // webpack 打包: // output.js const __webpack_modules__ = { "./index.js": (__webpack_require__) => { const _constants__WEBPACK_MODULE__ = __webpack_require__("./constants.js"); console.log(_constants__WEBPACK_MODULE__.A ? 1 : 2); }, "./constants.js": (__webpack_require__) => { __webpack_require__.d({ A: () => A, }) const A = 42; } }-
一般来说通过
optimization.concatenateModules可以解决,但复杂场景下能够被 concatenate 的模块通常很少js// 开启 optimization.concatenateModules,对 minifier 更友好,能压缩得更小 ;// CONCATENATED MODULE: ./constants.js const A = 42 ;// CONCATENATED MODULE: ./index.js console.log(A ? 1 : 2) // now this can be optimized by minifier -
minifier 能够很好的将变量名 mangle 的更短,但这层函数导致 minifier 不能 mangle 模块导出的变量,此时需要
optimization.mangleExports来进行 manglediff// output.js const __webpack_modules__ = { "./index.js": (__webpack_require__) => { const _module__WEBPACK_MODULE__ = __webpack_require__("./constants.js"); - console.log(_constants__WEBPACK_MODULE__.aVeryLongLongLongName ? 1 : 2); + console.log(_constants__WEBPACK_MODULE__.a ? 1 : 2); }, "./constants.js": (__webpack_require__) => { __webpack_require__.d({ - aVeryLongLongLongName: () => aVeryLongLongLongName, + a: () => aVeryLongLongLongName, }) const aVeryLongLongLongName = 42; } } -
其他更多优化,比如 Rspack v1.4 引入的 experiments.inlineConst
js// output.js const __webpack_modules__ = { "./index.js": (__webpack_require__) => { console.log(42 ? 1 : 2); // now this can be optimized by minifier }, }
-
Tree shaking in esbuild
esbuild 的 tree shaking 分为以下步骤:
- 每个模块按照 top-level statements 进行切分,每个 top-level statement 作为一个 part
- 分析 part 中定义的变量以及被其他 part 使用的变量,并让模块的导入指向对应的导出(linking)
- 从 entry 模块中的 part 开始自顶向下的对 part 进行进行一次遍历,如果 part 中有被其他 part 使用到,或者有副作用,则会标记为
IsLive = true - 最终代码生成时只会生成被标记为
IsLive = true的 part,其他没被标记的 part 则会被删除掉
提前切分 top-level statements 使得 esbuild 天然地解决了 innerGraph 的问题,经过切分后每个 top-level statement 都作为一个 part,以 part 粒度(part-level)进行分析优化,而不是像 webpack 一样以 module 粒度进行分析优化,这样主要有以下好处:
- 不仅能够分析了导入导出变量,同时也分析了模块内的变量,覆盖了 webpack 需要 innerGraph 来完成的工作
- 能够将 bundler 对 module-level 的优化应用到模块内的 top-level statements 上,比如 esbuild 的 side effects optimization 能够删除无用且无副作用的 top-level statement,而 webpack 只能做模块级别的删除
值得注意的是 esbuild 在早期版本还支持让这些 top-level statement 参与 code splitting,也就是我们现在说的 "module splitting",但由于 esbuild 并没有和 webpack 的产物一样,将每个 module 包了一层函数,分离模块的加载与执行,导致难以处理好 top-level await,所以 esbuild 在后续版本放弃了对 module splitting 的支持。
目前 esbuild/docs/architecture/code-splitting 中仍然是对应支持 module splitting 的版本,code splitting 是以 part 为粒度做分割的,shared chunk 仅包含两个入口共有的 top-level statements。在 esbuild playground 中复刻了一版,可以看到 shared chunk 会包含两个入口共有的 modules,code splitting 是以 module 为粒度进行分割。

之前支持 module splitting 的结果
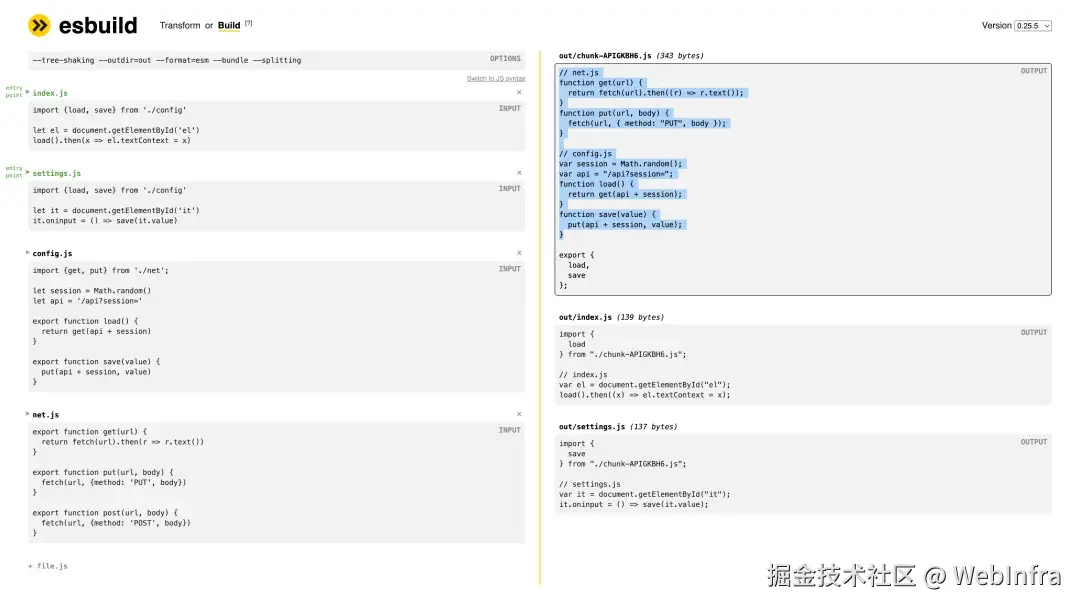
现在放弃支持 module splitting 的结果
另外除了 top-level await 以外,还有一个因为没有分离模块的加载与执行导致 esbuild 对于 module splitting 有额外的复杂度:ES Module 的静态 import 导的值是 read-only 的,这意味着 esbuild 进行 code splitting 时不能将模块变量的赋值操作移至与该变量声明所在的不同 chunk 中,在 esbuild 放弃 module splitting 后该问题也不再需要特殊处理。
Tree shaking in Turbopack
module splitting 其实更适合 webpack 这种能够将模块的加载与执行分离的产物,天然地保证了模块执行的正确性,也不需要对模块内变量的声明与使用有额外处理。
除此之外也能将更多 module-level 的优化应用到模块内的 top-level statements 上,比如 esbuild 所缺失或不足的一些优化:code splitting、runtime optimization、chunk splitting 等,做更进一步的优化。
那么有没有 bundler 即有类似 webpack 一样的 runtime 将模块的加载与执行分离,又支持 module splitting 呢?有的:Turbopack。
首先看 Turbopack 的产物格式如何解决不允许跨 chunk 进行变量的赋值与声明问题,使用 esbuild 中例子的打包结果:
js
// PS: Turbopack 相关代码经过简化与修改,目前 Turbopack 暂未提供细粒度控制拆包相关配置
// chunk for entry1.js
module.exports = {
"entry1.js": (__turbopack_context__) => {
var _data_1__TURBOPACK_MODULE__ = __turbopack_context__.i("data.js <part 1>");
console.log(_data_1__TURBOPACK_MODULE__.data);
},
}
// chunk for entry2.js
module.exports = {
"entry2.js": (__turbopack_context__) => {
var _data_2__TURBOPACK_MODULE__ = __turbopack_context__.i("data.js <part 2>");
_data_2__TURBOPACK_MODULE__.setData(123);
},
"data.js <part 2>": (__turbopack_context__) => {
__turbopack_context__.s({
setData: () => setData,
});
var _data_1__TURBOPACK_MODULE__ = __turbopack_context__.i("data.js <part 1>");
function setData(value) {
_data_1__TURBOPACK_MODULE__.data = value; // <--- this will tigger the setter
}
},
}
// chunk for shared code
module.exports = {
"data.js <part 1>": (__turbopack_context__) => {
__turbopack_context__.s({
data: [
() => data, // <--- getter
(new_data) => data = new_data, // <--- setter
]
});
let data;
},
}Turbopack 使用一套和 webpack 类似的产物格式,对每个模块包一层函数,分离模块的加载与执行,与 webpack 不同的是,定义模块导出的 runtime __turbopack_context__.s 除了提供导出的 getter 以外,还需要额外增加导出的 setter,在该模块的其他 part 对该变量进行赋值操作时,会触发该 setter 进行更新,以此来保证执行的正确性。
对于 top-level await 也和 webpack 一样,使用一套 runtime 来保证包含 top-level await 的模块及其被引入的模块的执行顺序正确,比如在 data.js 第一行添加 await 1; 后打包结果如下:
js
// chunk for shared code
module.exports = {
// ...
"data.js <part 0>": (__turbopack_context__) => {
__turbopack_context__.a(async (__turbopack_handle_async_dependencies__, __turbopack_async_result__) => {
try {
await 1; // <--- the added `await 1;`, wrapped by __turbopack_context__.a runtime to ensure top-level await is correctly executed
__turbopack_async_result__();
} catch(e) { __turbopack_async_result__(e) }
}, true);
},
// ...
}当然 module splitting 也有缺点,经过分割后,在产物中每个 top-level statement 都会有一层函数进行包裹,虽然解决了执行正确性的问题,但也放大了这层函数所带来的缺点:
- 导致这层函数过多的重复引入,增大了产物体积(尽管这部分重复字符很多,gzip 能够有效减少这部分体积)
- 导致更多变量需要通过
_data_0__TURBOPACK_MODULE__.data这种 object property 的方式来访问,降低代码执行性能(当然这点仍需在现代浏览器下进行相关 benchmark 进行验证)
这两点都需要更加依赖 scope hoisting 来进行优化。
Tree shaking in Rollup
如果说 Webpack 是针对 export 语句和 module 做 tree shaking,esbuild 针对 top-level statement 做 tree shaking,那么 Rollup 会自顶向下针对所有的 statement 和部分更细粒度的 AST node 做 tree shaking,且 side effects 判定更加精细。

rollup 会对 statements,以及部分更细粒度的 AST node 做 tree shaking
Rollup 的 tree shaking 与 esbuild 比较相似,但略有不同,Rollup 的 tree shaking 过程如下:
- 开始时会在模块上调用 include()
- 从顶层 AST 节点开始: a. 判断 AST 节点是否有 side effects b. 有则进行 include() c. 继续对 AST 节点的相关节点进行 side effects 判定和 include(),即 a、b 过程
- 在遍历完成后再会判断是否有新的 AST node 被 include(),如果有则会再触发一次新的遍历,即 1、2 过程
2.c 中的相关节点指:部分节点的子节点、变量使用时对应的变量声明节点、obj.a.b 使用时对应 obj 的声明和 a、b 属性的节点等
Rollup 相比其他 bundler 的 tree skaking 效果往往更好原因在于:
- 分析的粒度更细,AST node 粒度的分析和删除,其他 bundler 仅进行 top-level statement 或者更粗粒度的分析和删除,更细粒度往往交给 minifier 进行死代码删除。
- side effects 的分析粒度更细,同样以 AST node 为粒度,且能够简易地根据上下文做 side effects 的判定,其他 bundler 的 side effects 分析粒度更粗,且是上下文无关的。
Rollup 这种细粒度的分析中自然也覆盖了export 语句和 top-level statement 的粗粒度的分析,所以 Rollup 不仅能对跨模块的 export 语句做删除,也能覆盖一部分模块内的 DCE。接下来我们主要关注模块内的 DCE 部分,并结合几个 cases 来阐述以上两点:
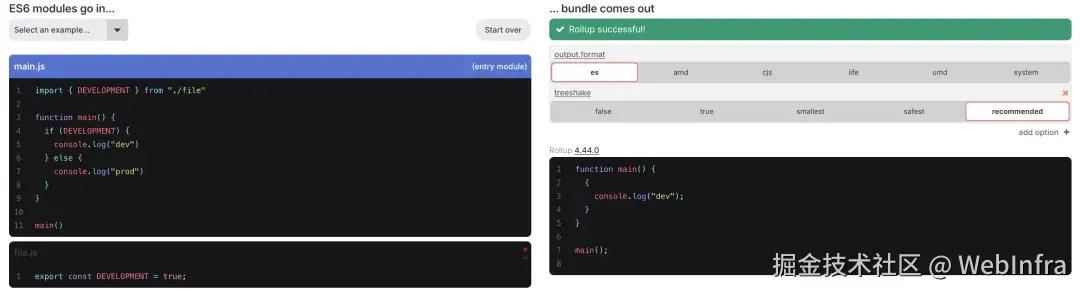
Rollup 的 Define 功能和其他 bundler 的实现是不太一样的,rollup-plugin-replace 只会在 transform 阶段将匹配到的 Define 节点做替换,不像 webpack、esbuild 除了在 parse 阶段做替换以外,还会去分析 dead branch,dead branch 中的代码直接跳过分析,也不会引入 dead branch 中的任何依赖到模块图中,但这种 parse 阶段的 dead branch 分析并不能跨模块。
由于 Rollup 的 tree shaking 粒度是 AST node 级别的,使得函数内部的 statement 节点也能被 tree shaking 分析到,所以 Rollup 的分析部分交给了 tree shaking 阶段,dead branch 的删除也依赖于 tree shaking。
在这个例子中,会尝试将 if (DEVELOPMENT) 中的 DEVELOPMENT 变量进行 compile-time eval,结果为常量,所以能够将 else branch 作为 dead branch 删去,且不会标记 file.js 中的 DEVELOPMENT 变量为被使用,使得最终能够 tree shaking 掉 export const DEVELOPMENT 声明以及 file.js 模块。
这样做的坏处在于 dead branch 中引入的依赖仍然会被加到模块图中,引入更多的模块使 Rollup 需要处理更多工作,降低性能。
好处在于能够跨模块的分析和删除 dead branch,删除更多无用代码带来更小的产物体积。其他 bundler 则需要够靠 scope hoisting 将模块合并到一个作用域内,依赖 minifier 来删除这些跨模块的 dead branch,但对于为了保证执行正确性不得不放弃 scope hoisting 的部分模块则无能为力,可能未来需要引入新的优化来处理。
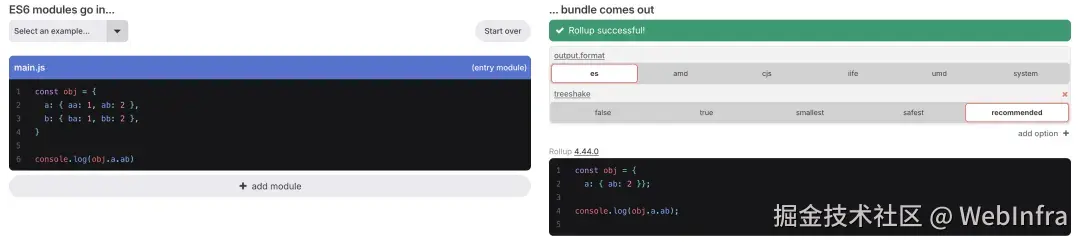
Rollup 在分析 console.log(obj.a.ab) 时,由于有副作用,会对该 statement 进行 include(),在 include(obj.a.ab) 时,会触发相关节点的 include(),包括 obj 声明节点、a: 属性节点、ab: 属性节点,AST node 级别的 tree shaking 让 Rollup 能够仅保留用到的 a: 属性和 ab: 属性,将其他无用的属性 tree shaking 掉,带来更小的产物体积。
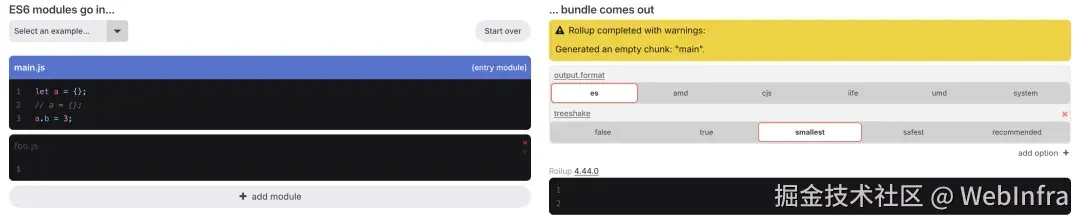
在该 case 中,如果注释掉 a = {} 会发现所有代码都被 tree shaking 了,但只要去掉注释后则不会 tree shaking,这是因为 Rollup 会根据变量 a 有没有被 reassiginment 判断 a.b = 3 是否有 side effects,这体现了 Rollup 有一定根据上下文进行 side effects 分析的能力,当然相比上下文无关的 side effects 分析这带来了一定程度上的性能损耗。
当然这种根据上下文的 side effects 分析也比较简易,一般仅会对特定的比较简单的场景生效,比如上述场景只会判断是否被 reassign,不会分析 reassign 是否有真正的改变,不会做过于深入细致的分析。
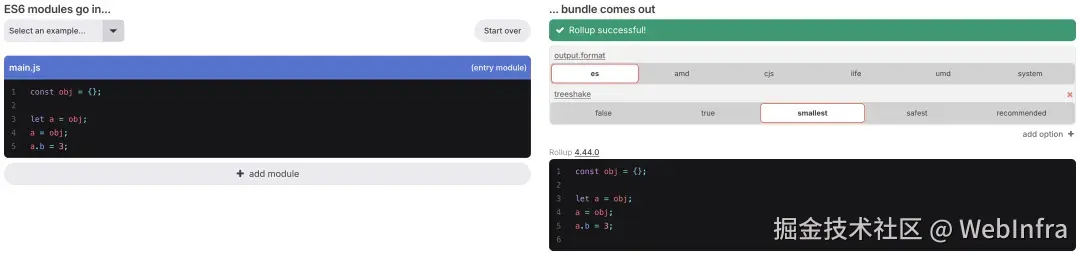
即使 reassign 了同一个变量,实际没有真正的改变,但仍然会判定 a.b = 3 为有 side effects
Rollup v3 仅支持 statement-level 的 tree shaking,但 v4 开始尝试更细粒度的 AST Node 的 tree shaking(上述 object properties 的 tree shaking),以及优化特定场景下对 unused 节点的追踪,比如:
- tree shaking 函数的默认参数,但由于需要 bailout 的场景过多目前已被 revert。
- 根据函数的"常量参数" tree shaking 函数内部的 dead branch,该特性由 tree shaking 函数的默认参数演进而来,在函数仅调用一次,或多次调用且参数不变,使用同一个变量时,则会分析参数使用的变量,根据该变量做特定的优化。
这使得更多场景的 tree shaking 成为可能,例如: