Dubbo2到Dubbo3服务发现机制的优化
在Apache Dubbo中,从版本2升级到版本3的过程中,服务发现机制经历了一次重要的优化
这一改进解决随着集群水平扩展而出现的数据冗余和注册中心容量瓶颈等问题
Dubbo2的服务发现流程
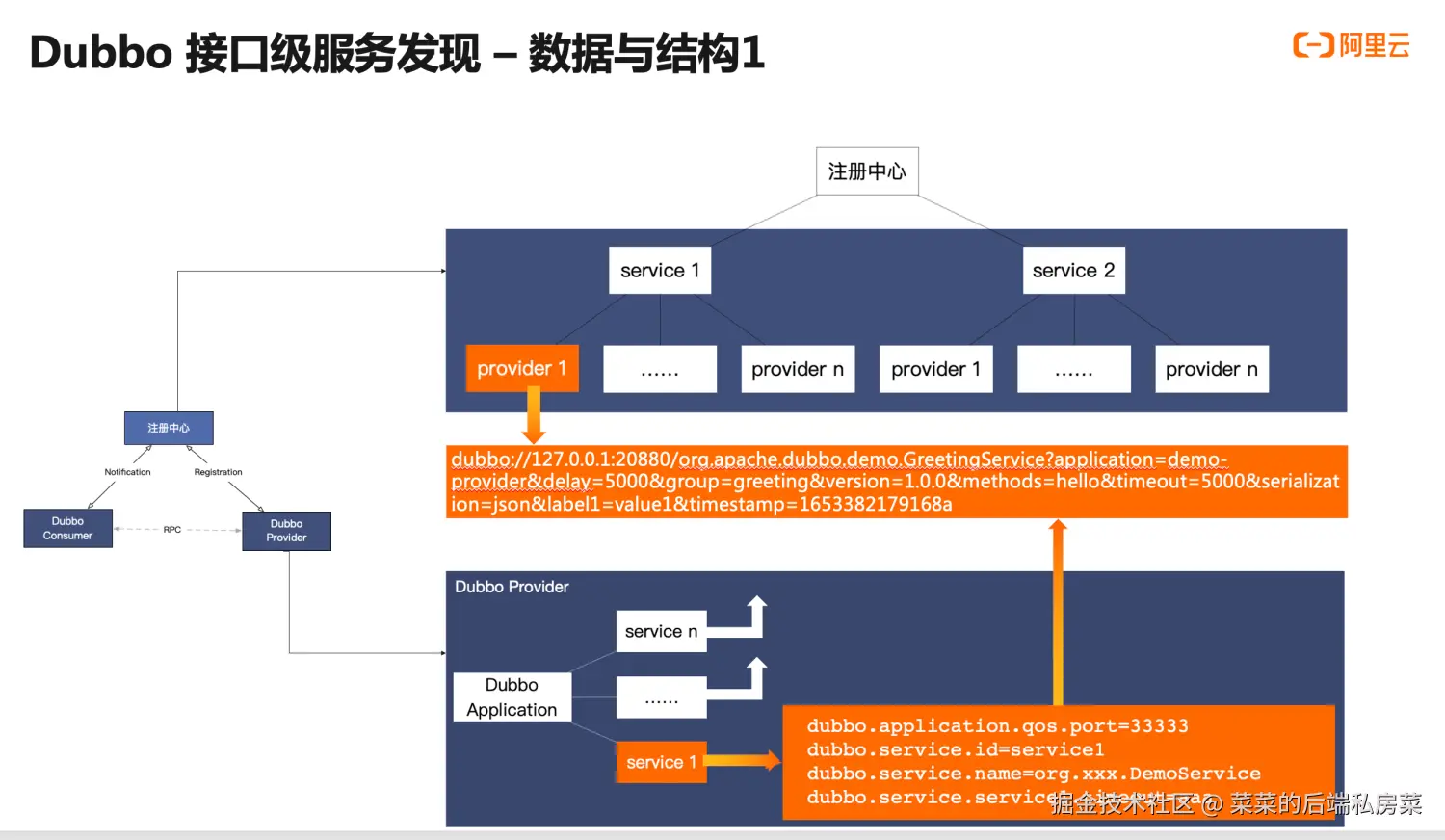
在Dubbo2中,消费者(Consumer)、提供者(Provider)以及注册中心之间的交互是通过一个特定的key进行的
简单来说,这个key由RPC需要使用什么协议、RPC调用的地址、RPC调用的服务以及其他RPC元数据组成
比如:dubbo://127.0.0.1:20880/org.apache.dubbo.demo.GreetingService?application=demo-provider&delay=5000&group=greeting&version=1.0.0&methods=hello&timeout=5000...
服务发现流程如下:
- 提供者根据配置的元数据组成key向注册中心注册
- 注册中心依据key来收集提供者的地址列表
- 消费者订阅所需的key,以便从注册中心获取提供者的地址列表
这种方法的优点在于处理粒度细,易于扩展和使用
同时它也存在明显的缺点:随着集群水平扩展,key的数据量庞大且存在大量的数据冗余
以一个提供者服务为例,如果它存在10个Service,并分布在100台机器上
其中这10个Service属于同一地址,但都会向注册中心进行注册,存在10倍的地址数据冗余
而10个Service存在10份唯一元数据,但部署在100台机器上,存在100倍的元数据冗余
同时当集群水平扩展至一定程度时,太多的数据会使注册中心的容量达到上限,占用带宽、推送性能下降,消费端也需要处理更多的内容,从而占用更多资源
Dubbo3的优化方案
为了解决上述问题,Dubbo3简化了服务发现中的key概念,Provider向注册中心同步的内容只包括协议和IP元数据(dubbo://127.0.0.1:20880)
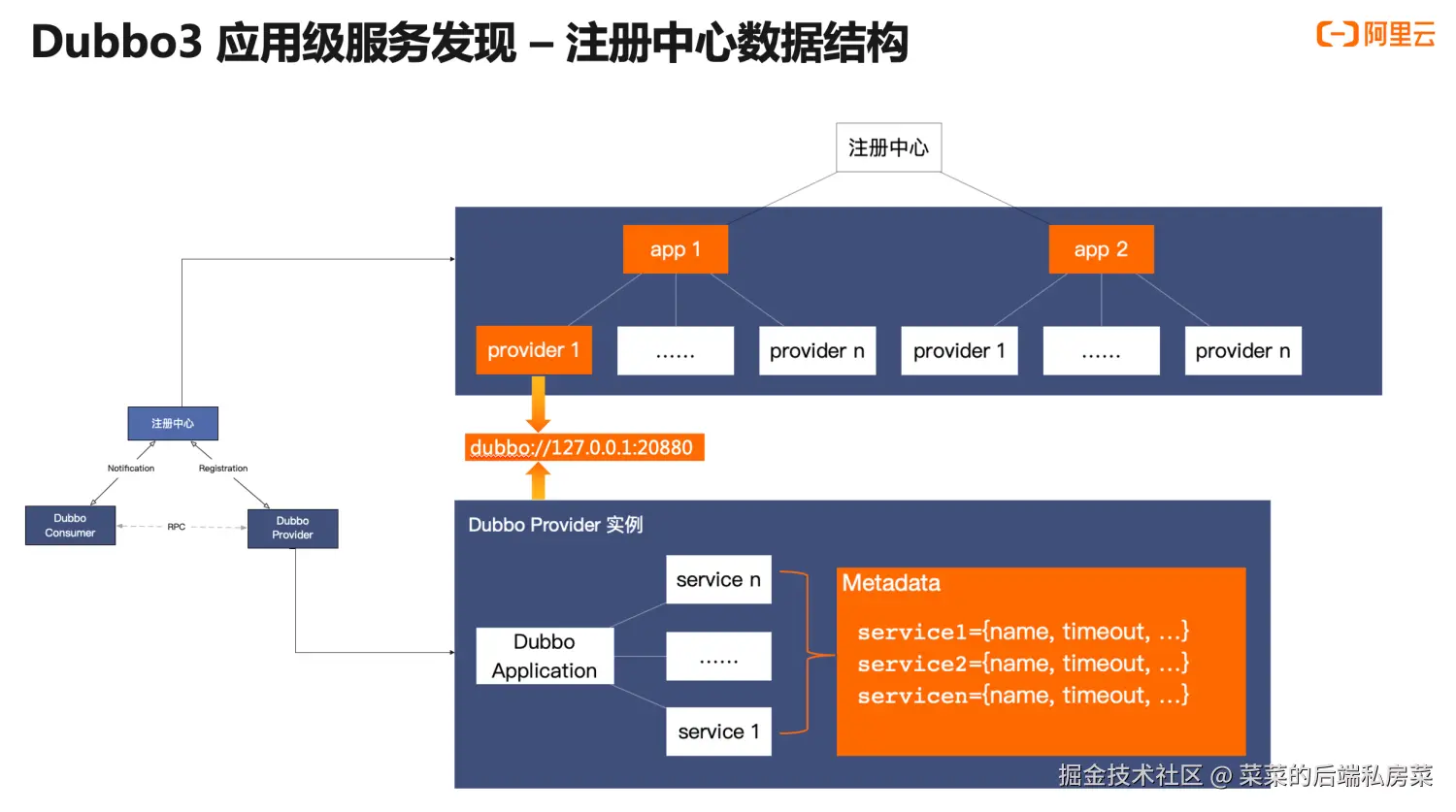
这样做虽然解决了数据冗余的问题,但也引入了一个新问题:RPC元数据不通过注册中心传递,要怎么获取?
Dubbo3采用的方式是消费者RPC调用前还需要从提供者处获取RPC元数据,以便组装出完整的RPC请求地址
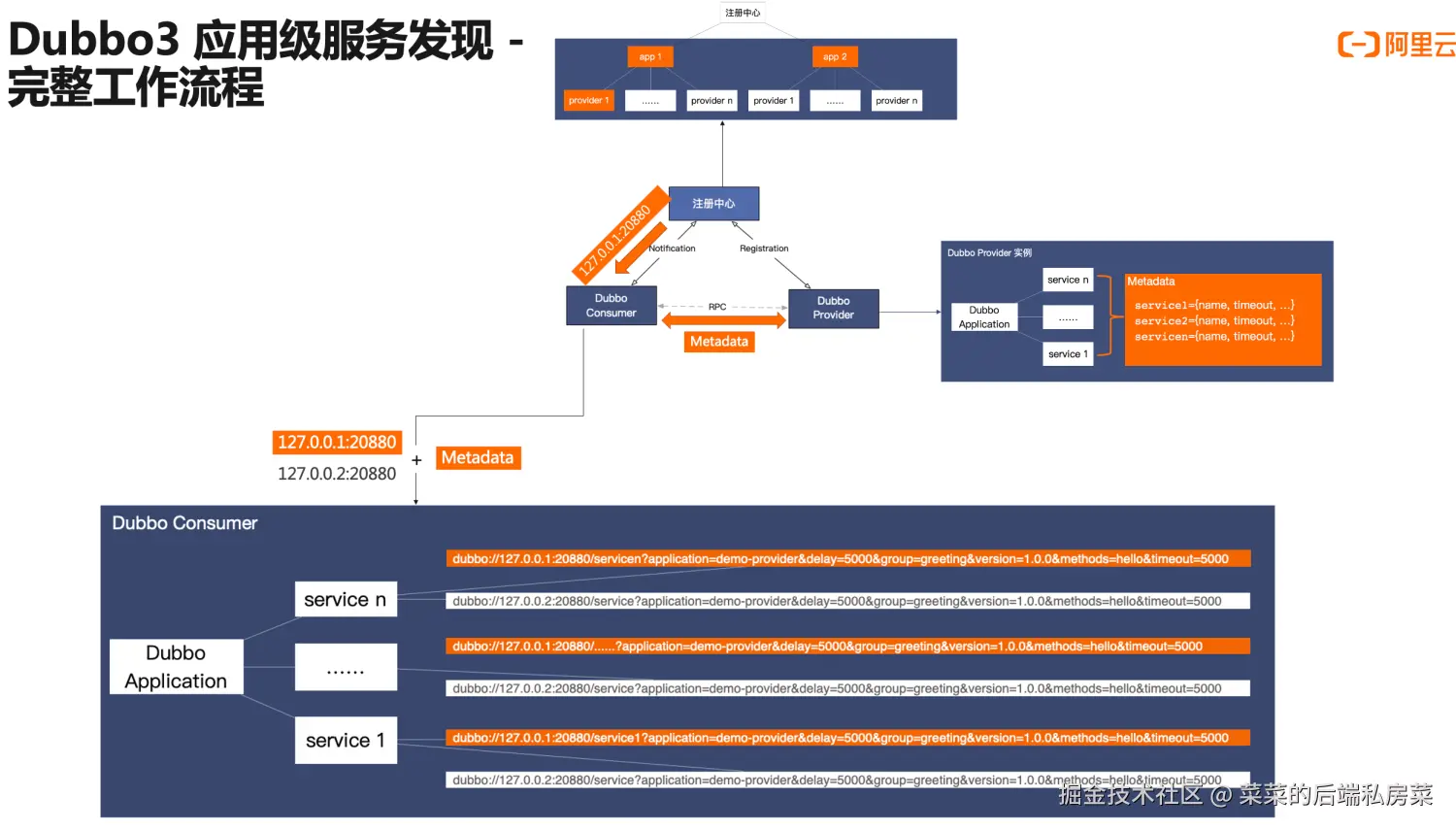
现在注册中心仅负责推送服务的应用地址,消费者通过MetadataService从提供者那里获取必要的元数据,组合后再进行RPC调用
参考:cn.dubbo.apache.org/zh-cn/overv...
总结
Dubbo2的服务发现机制,会在Provider将大量RPC元数据同步到注册中心,存在数据冗余的缺陷
数据冗余在服务节点少的场景下不易暴露问题,但在大规模集群水平扩展的场景下会导致注册中心容量上限、传输占用带宽、推送性能下降、消费端处理太多数据等问题
Dubbo3精简Provider向注册中心同步的数据,只保留协议与IP信息,同时RPC元数据存储在Provider,未向注册中心同
Consumer从注册中心收到订阅的Provider IP信息后,再向Provider获取RPC元数据,组合信息后再进行RPC调用
最后(一键三连求求拉~)
😁我是菜菜,热爱技术交流、分享与写作,喜欢图文并茂、通俗易懂的输出知识
📚在我的博客中,你可以找到Java技术栈的各个专栏:Java并发编程与JVM原理、Spring和MyBatis等常用框架及Tomcat服务器的源码解析,以及MySQL、Redis数据库的进阶知识,同时还提供关于消息中间件和Netty等主题的系列文章,都以通俗易懂的方式探讨这些复杂的技术点
🏆除此之外,我还是掘金优秀创作者、腾讯云年度影响力作者、华为云年度十佳博主....
👫我对技术交流、知识分享以及写作充满热情,如果你愿意,欢迎加我一起交流(vx:CaiCaiJava666),也可以持续关注我的公众号:菜菜的后端私房菜,我会分享更多技术干货,期待与更多志同道合的朋友携手并进,一同在这条充满挑战与惊喜的技术之旅中不断前行
🤝如果觉得菜菜写的不错,可以点赞、关注、收藏支持一下~
📖本篇文章被收入专栏 深入浅出微服务,感兴趣的同学可以持续关注喔
📝本篇文章笔记以及案例被收入 Gitee-CaiCaiJava、 Github-CaiCaiJava,除此之外还有更多Java进阶相关知识,感兴趣的同学可以starred持续关注喔~