一、 例子
大家好,我是阿赵。有时候,我们想在某些网页上面自动的收集数量比较大的数据。如果正规的去操作,每个页面打开,选择内容,复制,保存。这样会很慢,所以我们都希望可以通过某些办法自动的去进行以上的操作。
相比起"爬虫",我还是比较喜欢把这个过程叫做"自动化收集资料"。
下面举一个小例子,比如我想通过百度图片网页,搜索"八神庵"的图片,并且自定义多少页,把图片全部自动收集起来。
自动下载图片工具
二、 准备工作
为了实现上面的例子的目的,我打算使用python来写一个自动化工具。python的selenium可以自动化操作浏览器和网页内容,比较合适。
1、 安装python
如果不知道Python是什么的朋友,我建议自己去百度一下,这里就不啰嗦。
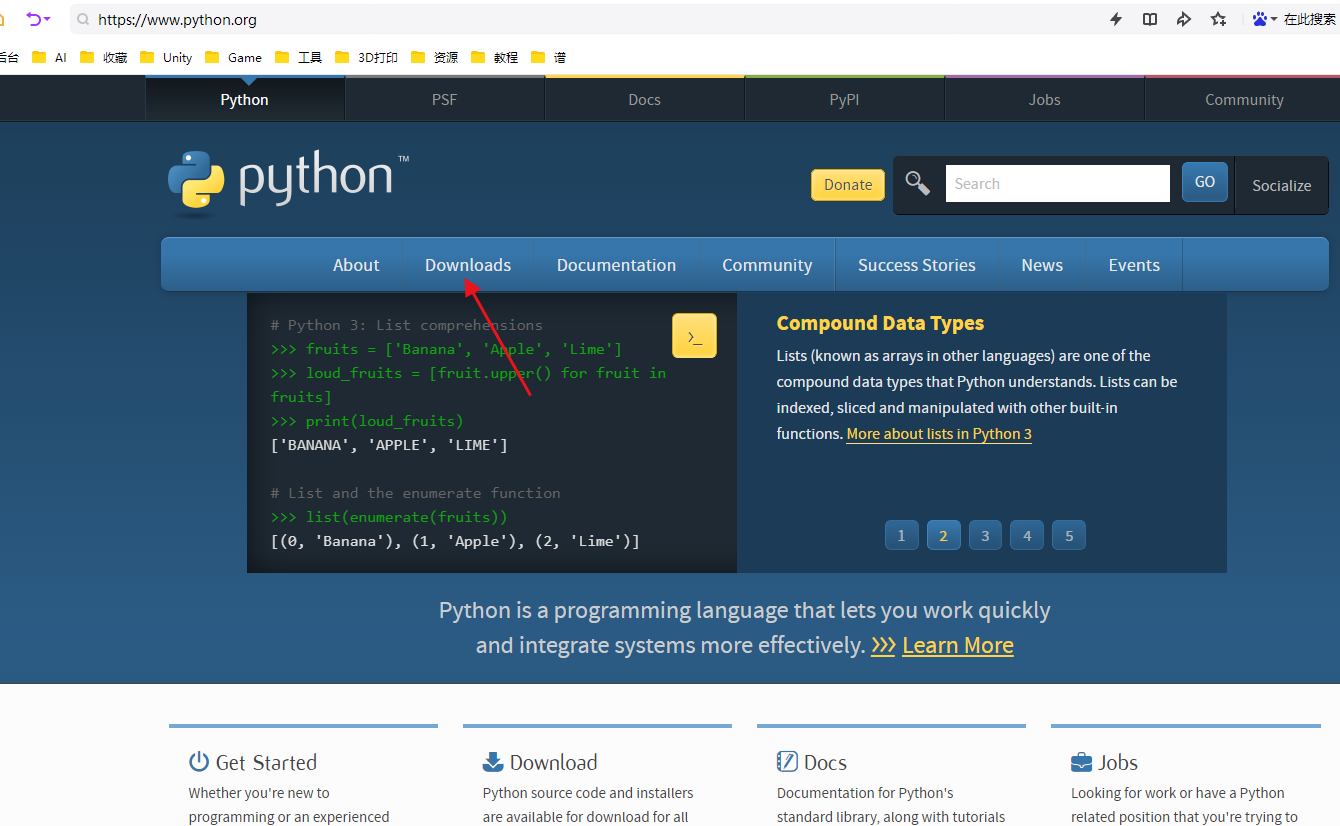
直接去官网下载:
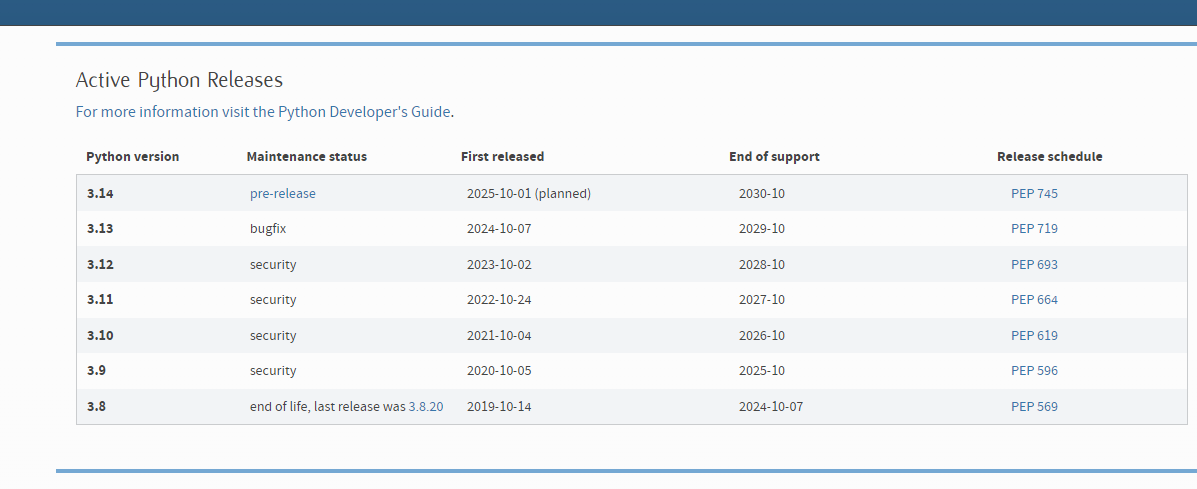
值得注意的是,python有很多版本:
不同版本之间,有可能支持的库和方法都有点差异。

然后阿赵我本地的Python版本比较旧了,是3.6.3的,但由于配合着本地的一些工具使用,所以一直没有升级。所以下面如果写的Python在各位的电脑上有报错,可以查询一下是否Python版本的问题。
2、 安装selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。
接下来我们需要通过Python来操作Selenium工具,达到操控浏览器和网页内容。所以第一步我们需要先安装Selenium。
最简单的方法就是,先安装好python,然后在命令行输入:
pip install selenium

由于我的电脑已经安装过了,所以显示会有点不一样。
3、 安装webdriver
Selenium需要与WebDriver一起使用,后者是与特定浏览器交互的接口。例如,如果你使用的是Chrome浏览器,你需要下载ChromeDriver。或者你使用的是火狐浏览器,那么你需要下载下载GeckoDriver。
以Chrome浏览器为例,你需要先查看一下自己的浏览器的具体版本:
打开Chrome浏览器,然后点击右上角的三个点:
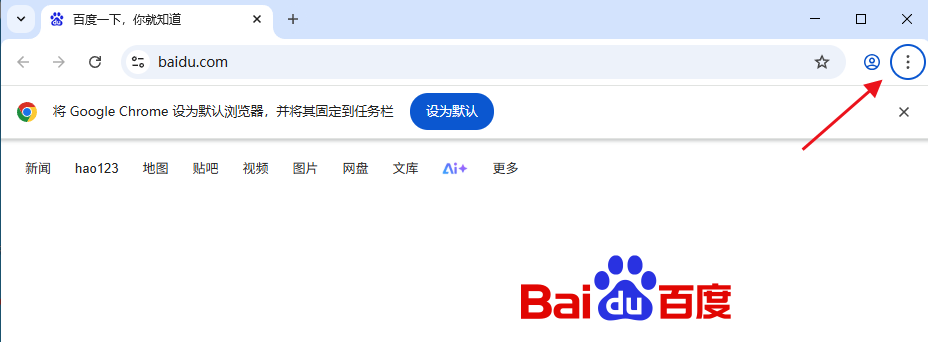
选择帮助------关于Google Chrome
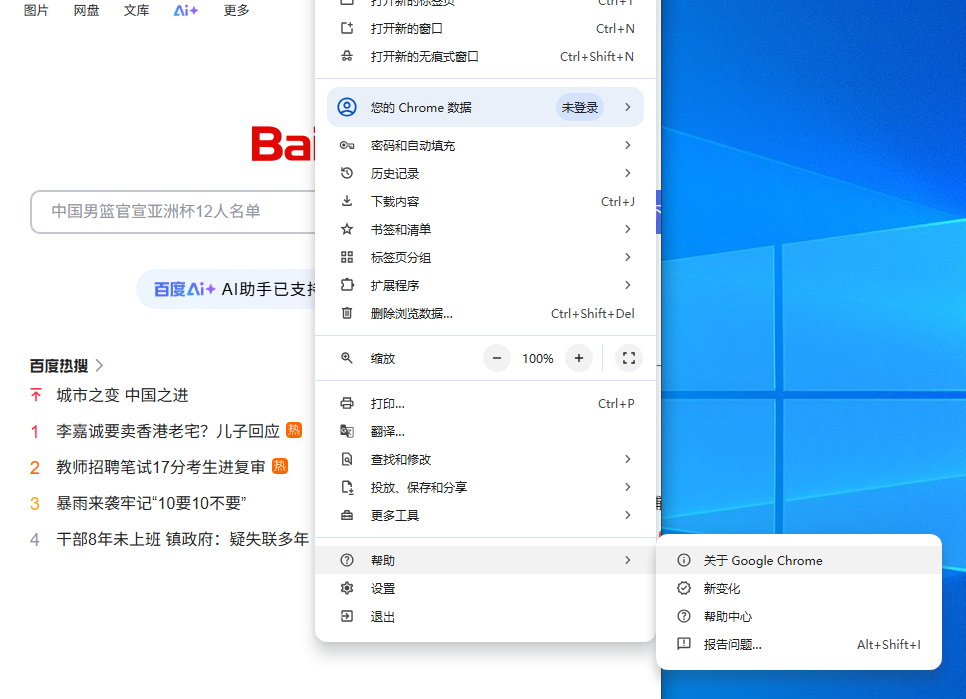
然后就可以找到具体的版本号。
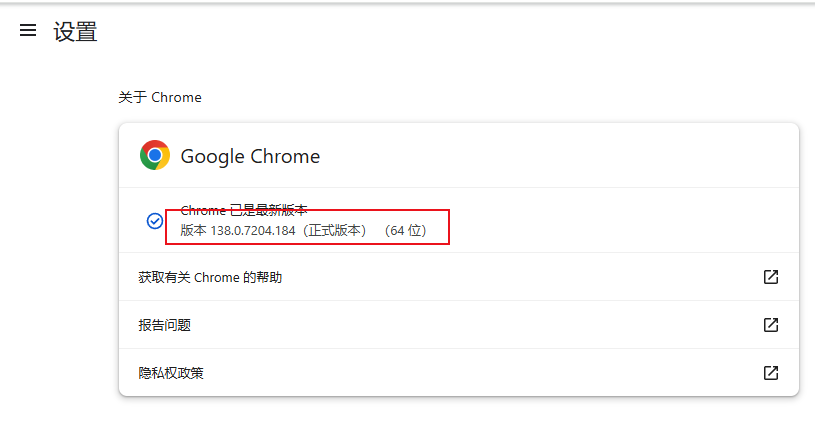
接下来可以去官网下载
https://sites.google.com/a/chromium.org/chromedriver/
也可以通过下面这个链接下载:
https://storage.googleapis.com/chrome-for-testing-public/你的Chrome版本/平台/chromedriver-平台.zip
比如我是Windows64位的操作系统,然后Chrome的版本是138.0.7204.184,那么下载地址就是:
https://storage.googleapis.com/chrome-for-testing-public/138.0.7204.184/win64/chromedriver-win64.zip
下载完之后是一个压缩包,把它解压了就行,放在一个你能比较容易找到的地方,比如我是放在了D盘的D:\webDriver\chromedriver-win64文件
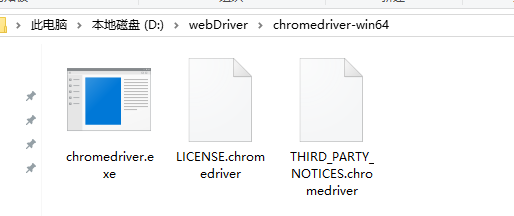
以下的代码都用Chrome作为例子,其他浏览器可以修改成对应的driver。
三、 开始自动收集数据
接下来开始使用Python来写工具代码了。先建一个空的txt文件,然后把文件名改成你喜欢的名字,然后扩展名改成py。比如我这里是改成了baiduPic.py。接下来用你喜欢的代码编辑器打开这个文件,然后开始写代码了。
1、 打开百度图片网站
首先,需要导入webdriver,所以写:
bash
from selenium import webdriver
from selenium.webdriver.chrome.service import Service然后,需要指定driver的路径
bash
chrome_driver_path = r'D:\webDriver\chromedriver-win64\chromedriver.exe' #替换成安装webDriver的地址然后创建一个driver
bash
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(chrome_driver_path) # (service=service)最后,通过这个driver打开一个URL:
bash
url = 'https://image.baidu.com/'
driver.get(url) # 打开浏览器于是整个代码会变成:
bash
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
chrome_driver_path = r'D:\webDriver\chromedriver-win64\chromedriver.exe' #替换成安装webDriver的地址
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(chrome_driver_path) # (service=service)
url = 'https://image.baidu.com/'
driver.get(url) # 打开浏览器 打开cmd命令行工具,然后找到我们刚写的baiduPic.py,然后执行python baiduPic.py,应该就可以看到,自动打开了一个Chrome浏览器,并且跳转到百度图片的页面了:
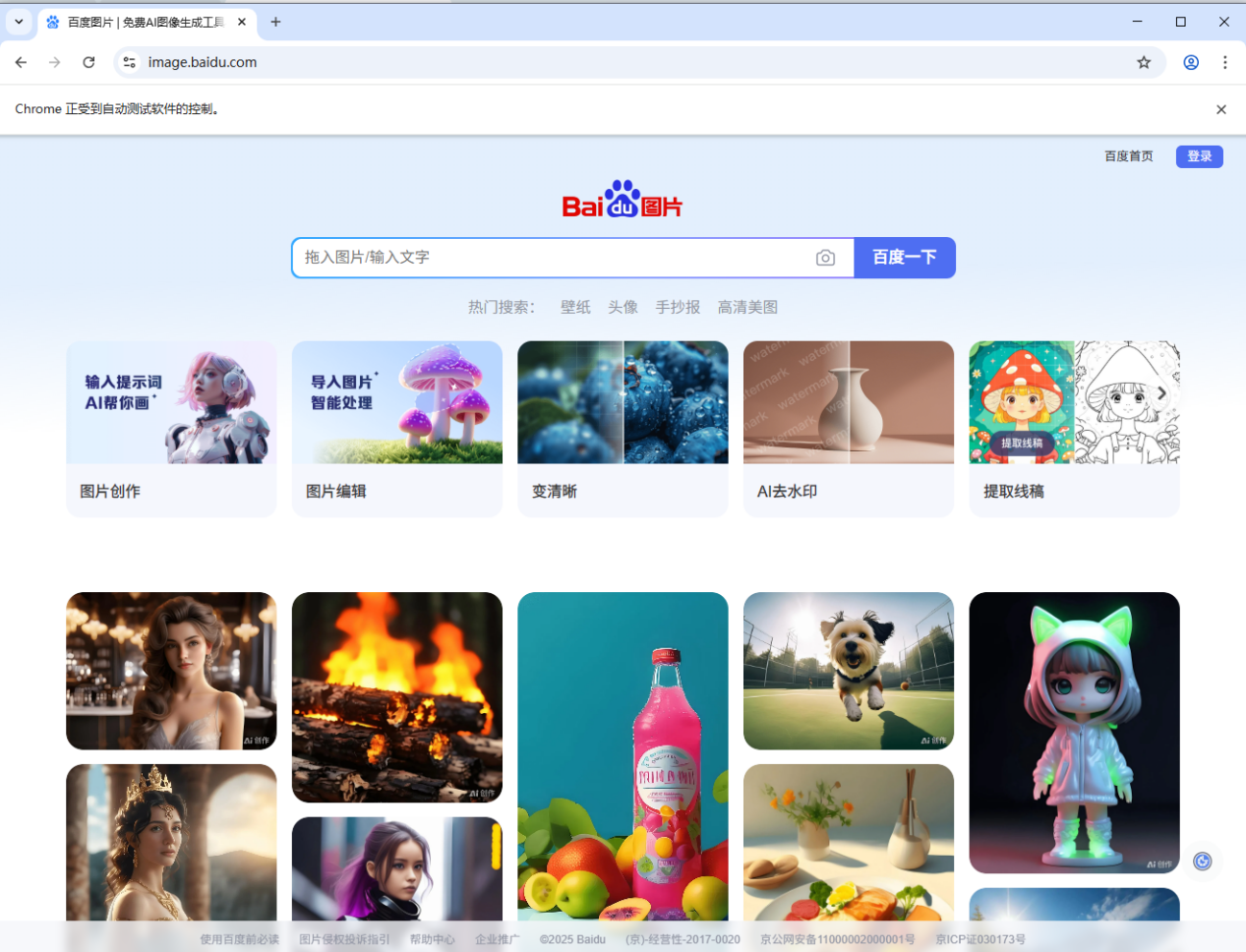
上面的代码有几个问题:
首先,网页不一定能打开,所以最好加一个try。
然后,打开了浏览器,等我们工作完之后,应该要把浏览器关掉。
所以代码会改成这样:
bash
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
chrome_driver_path = r'D:\webDriver\chromedriver-win64\chromedriver.exe' #替换成安装webDriver的地址
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(chrome_driver_path) # (service=service)
url = 'https://image.baidu.com/'
try:
driver.get(url) # 打开浏览器
finally:
driver.quit() # 关闭浏览器执行一下,会发现这次Chrome刚打开就被关闭了。这是因为我们执行打开之后,立刻就quit了。为了能看清网页的内容,我们可以加上等待时间:
bash
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
chrome_driver_path = r'D:\webDriver\chromedriver-win64\chromedriver.exe' #替换成安装webDriver的地址
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(chrome_driver_path) # (service=service)
url = 'https://image.baidu.com/'
try:
driver.get(url) # 打开浏览器
time.sleep(10) # 等待10秒
finally:
driver.quit() # 关闭浏览器这里使用time.sleep来等待。下面会说一下几种不同的等待方式的实现。
2、 从网页上获取控件
使用过Chrome的朋友应该都知道在Chrome打开时按F12键,就可以打开调试工具:
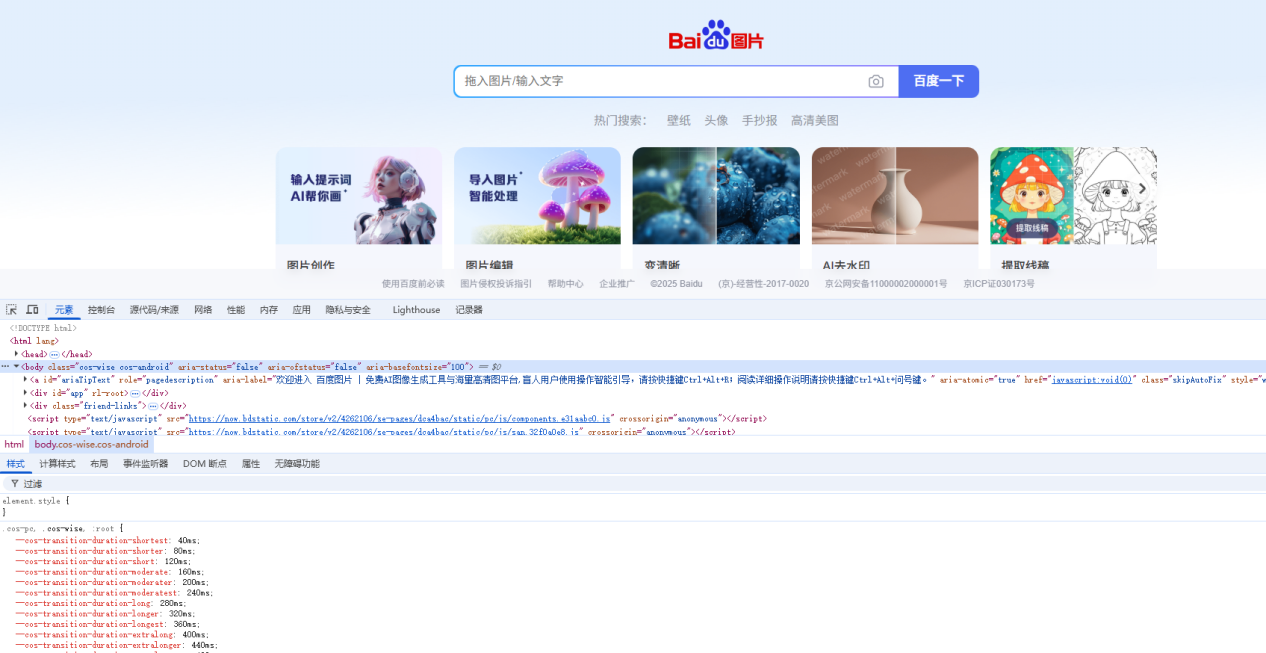
接下来我们就用这个调试工具,来找到我们需要操作的网页空间。比如,我接下来需要做的事情是,找到百度搜索的输入框,在里面输入"八神庵"。
通过这个选取工具,我们可以对网页元素进行直接选取:
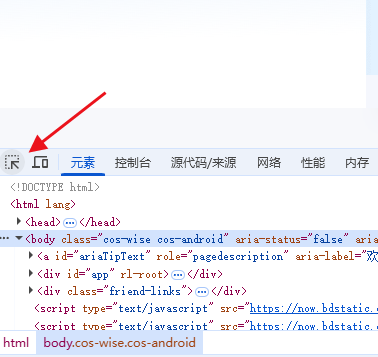
然后找到输入框:
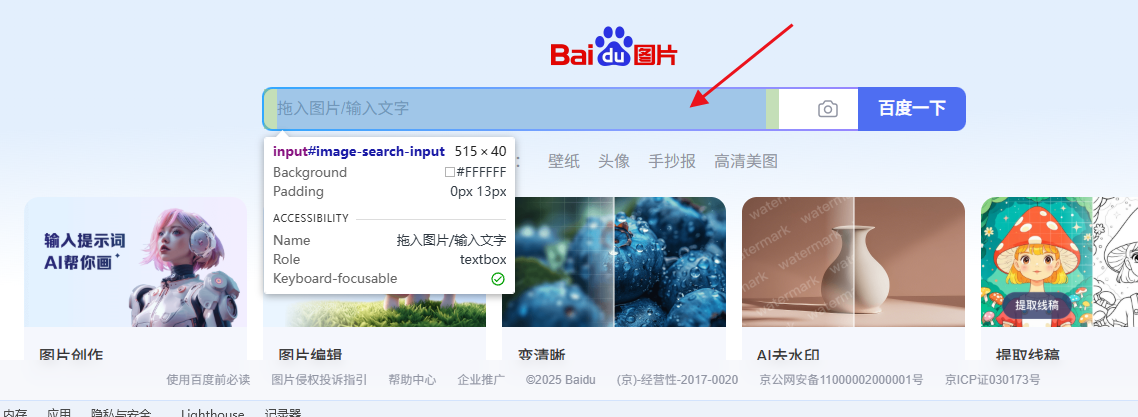
在这里,我们有多种选择网页控件的办法,但我们需要在对应的网页上面看看,是不是可以获取。
这里需要一点HTML的知识。首先,假如空间的属性里面有指定id,我们就可以通过id来获取定义的内容。
所以先去看属性里面的id字段,看有没有分配具体的id:
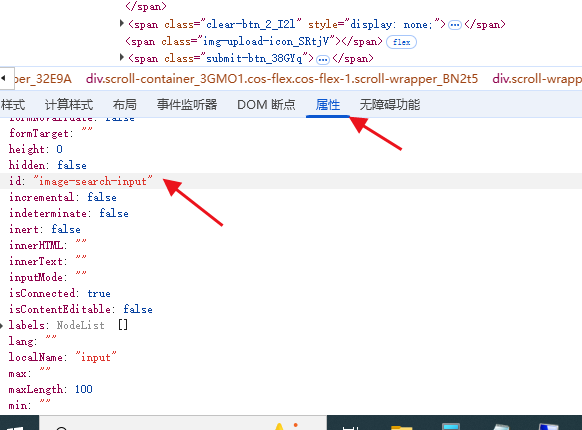
很幸运,这个输入框是有id 的,所以可以鼠标右键,复制一下它的id:
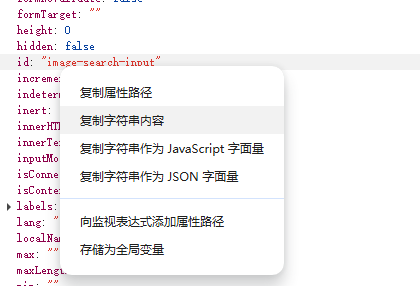
通过driver.find_element_by_id的方法,我们可以找到这个输入框,然后通过send_keys方法,把我们需要输入的内容输进去:
bash
driver.find_element_by_id('image-search-input').send_keys("八神庵")完整的代码变成这样:
bash
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
chrome_driver_path = r'D:\webDriver\chromedriver-win64\chromedriver.exe' #替换成安装webDriver的地址
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(chrome_driver_path) # (service=service)
url = 'https://image.baidu.com/'
try:
driver.get(url) # 打开浏览器
time.sleep(1) # 等待1秒
driver.find_element_by_id('image-search-input').send_keys("八神庵")
time.sleep(10) # 等待10秒
finally:
driver.quit() # 关闭浏览器执行Python代码,会发现,Chrome浏览器打开百度图片后,真的就自动输入了"八神庵"了:
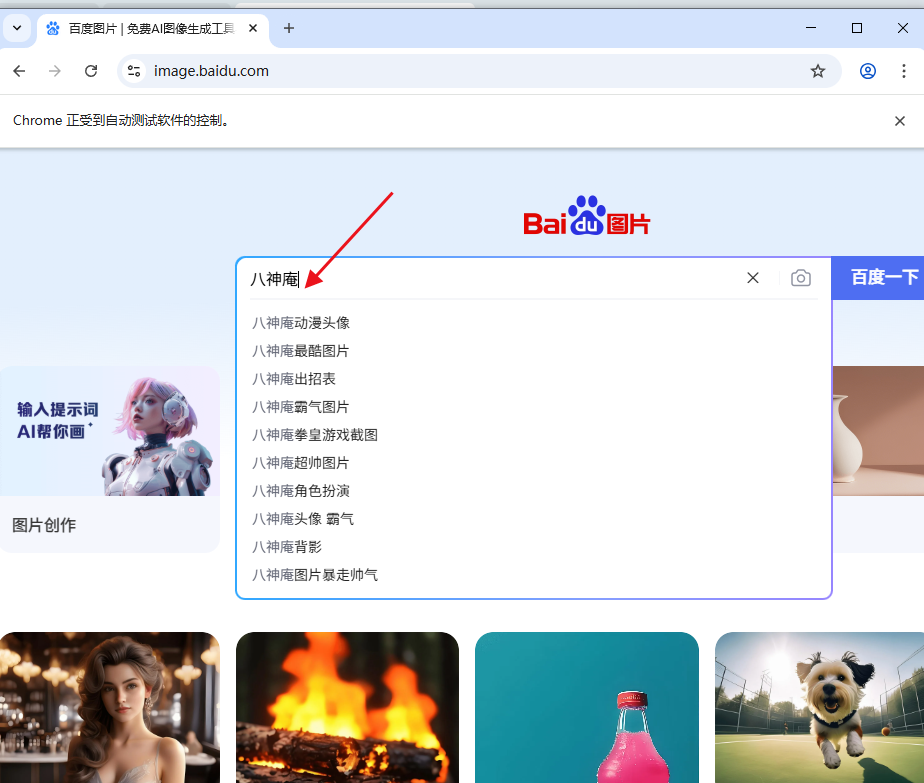
接下来我需要自动点击"百度一下"的按钮,让百度帮我们去搜索图片。
同样的操作,用小箭头选择搜索按钮:
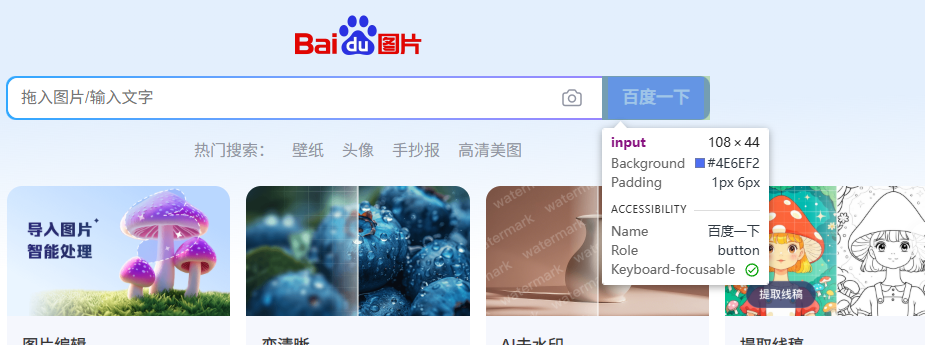
很可惜,这次的搜索按钮并没有指定id:
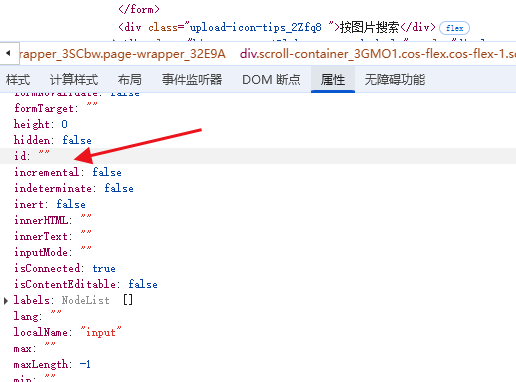
所以我们要换一种方式去获取了,这里可以使用CSS选择器。CSS选择器是什么?简单的说,就是我们做网页的时候,想要定位某个组件修改样式时的一个规则。比如可以通过标签名称,比如div之类获取,或者通过指定的类名来获取,等等。
选中按钮之后,选择样式,然后可以看到这个按钮的CSS选择器:
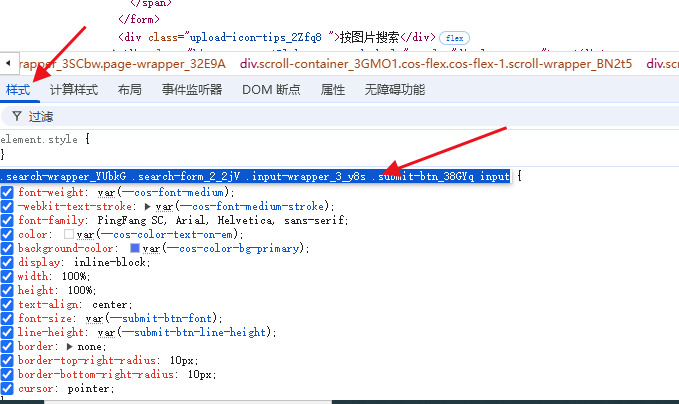
鼠标右键,选择复制selector,可以把选择器复制下来:
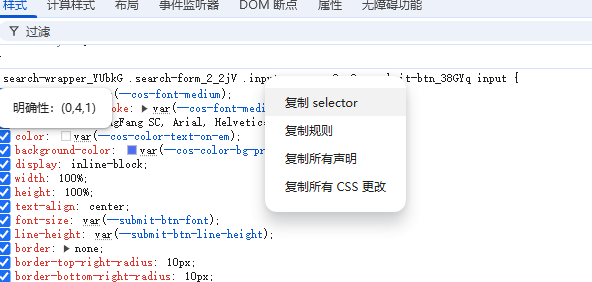
通过方法:
bash
driver.find_element_by_css_selector来获取到对应按钮,然后通过onclick方法来模拟点击,所以代码会变成:
driver.find_element_by_css_selector(".search-wrapper_YUbkG .search-form_2_2jV .input-wrapper_3_y8s .submit-btn_38GYq input").click() 这是完整的代码是:
bash
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
chrome_driver_path = r'D:\webDriver\chromedriver-win64\chromedriver.exe' #替换成安装webDriver的地址
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(chrome_driver_path) # (service=service)
url = 'https://image.baidu.com/'
try:
driver.get(url) # 打开浏览器
time.sleep(1) # 等待1秒
driver.find_element_by_id('image-search-input').send_keys("八神庵")
driver.find_element_by_css_selector(".search-wrapper_YUbkG .search-form_2_2jV .input-wrapper_3_y8s .submit-btn_38GYq input").click()
time.sleep(10)
finally:
driver.quit() # 关闭浏览器运行代码,可以看到百度图片把我们想要的内容搜索出来了:
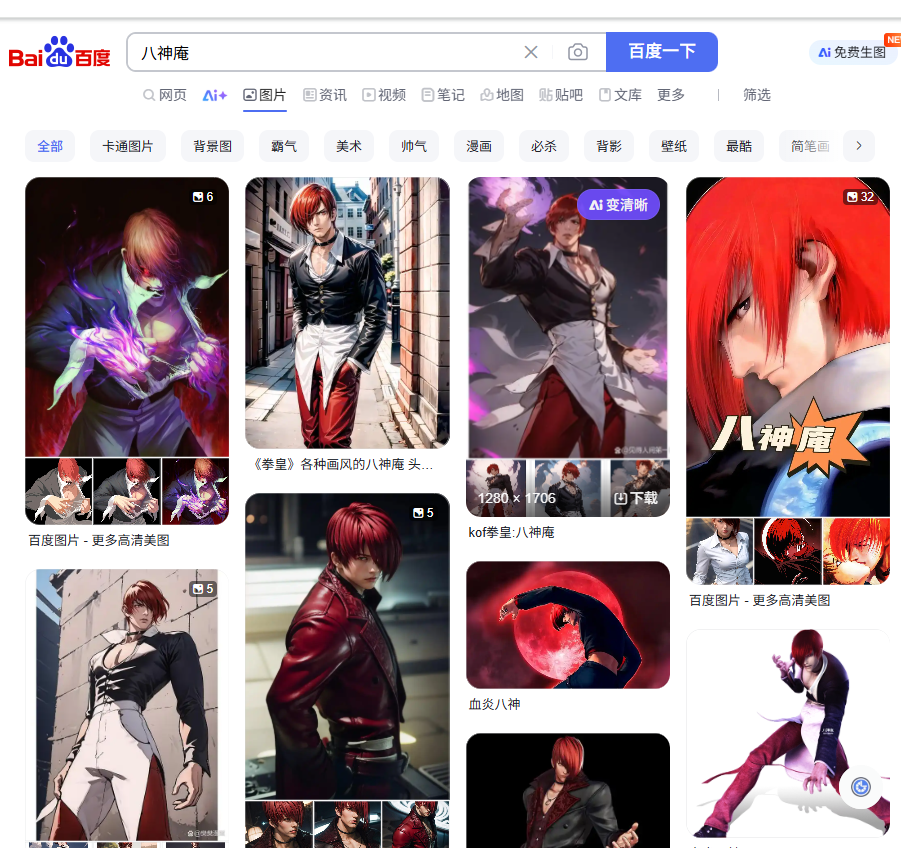
查找元素,除了靠id和css选择器还有其他的一些,总结一下:
find_element_by_id() 通过属性里面的id字段来获取
find_element_by_name() 通过属性里面的name字段获取
find_element_by_class_name() 通过类名获取,也就是属性里面的class
find_element_by_tag_name() 通过属性里面的标签获取
find_element_by_link_text() 通过超链接内容获取
find_element_by_partial_link_text() 通过部分匹配超链接内容获取
find_element_by_xpath() 通过元素的xpath路径获取
find_element_by_css_selector() 通过css选择器获取
3、 等待网页加载
在刚才那个过程,我们让百度搜索图片,这里存在一个问题,百度搜索是需要时间的,得到结果的网页有可能不是瞬间就能刷新出来。如果在结果还没刷出来的时候,我们就去上面获取想要的内容,是可能获取不到的。所以这里我们理论上需要等待网页刷新完,再进行下一步操作。
上面已经使用过等待方法了,这里来讲一下我们有哪些方法可以用来等待网页加载
1. 固定等待时间
time.sleep(等待秒数)
这个方法上面已经使用过了,具体的作用很明显,就是指定等待的秒数。
2. 显式等待
上面的方法很直接,想等多长时间直接指定了。不过有一个问题,网页的刷新时间是不固定的,如果我们设置了很短的时间,可能网页还是没刷出来。如果我们设置很长的时间,也许是在浪费时间。
下面这种方式,我们可以达到一种效果:等网页里面的某个元素找到了,我们再继续往下走:
先
bash
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC然后在打开某个页面之后:
bash
wait = WebDriverWait(driver, 10) # 最长等待时间为10秒
element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,你需要的选择器)))这样,当我们需要的目标元素被找到之后,就可以离开执行后续的内容。
这里的By和上面的获取元素的方法是一样的:
By.ID:通过元素的id查找
By.NAME:通过元素的name属性查找
By.XPATH:通过XPath表达式查找
By.LINK_TEXT:通过完全匹配的链接文本查找
By.PARTIAL_LINK_TEXT:通过部分匹配的链接文本查找
By.TAG_NAME:通过标签名查找。
By.CLASS_NAME:通过元素的class属性查找
By.CSS_SELECTOR:通过css选择器查找元素
显式等待有个问题,假如我们连续查找的页面,元素都是相同的,那么很有可能根本没有等待页面刷新,我们就已经找到了我们想要的元素。
3. 隐式等待
bash
driver.implicitly_wait(10) # 设置隐式等待为10秒隐式等待的意思是告诉 WebDriver 在查找元素时,等待一段固定的时间,直到元素出现。如果在设置时间内找不到元素,抛出 NoSuchElementException 异常。
隐式等待的优点是使用简单,只要给driver设置一次,后续的操作都会生效,缺点是,每次都需要等待相同的时间,才会开始查找元素,不灵活,很慢。
综上所述,每种等待加载的方式都有其优缺点,所以我觉得需要根据自己的实际情况来选择每一步的等待策略。由于我这里只是一个小例子,所以都直接用time.sleep来固定等待。
4、 获取多个元素
接着做例子。上面已经搜索出了我们想要的图片列表了,接下来的工作,其实就是选择其中一张,然后点击打开。
通过调试工具,我们会发现在列表里面有很多相同类名的元素:
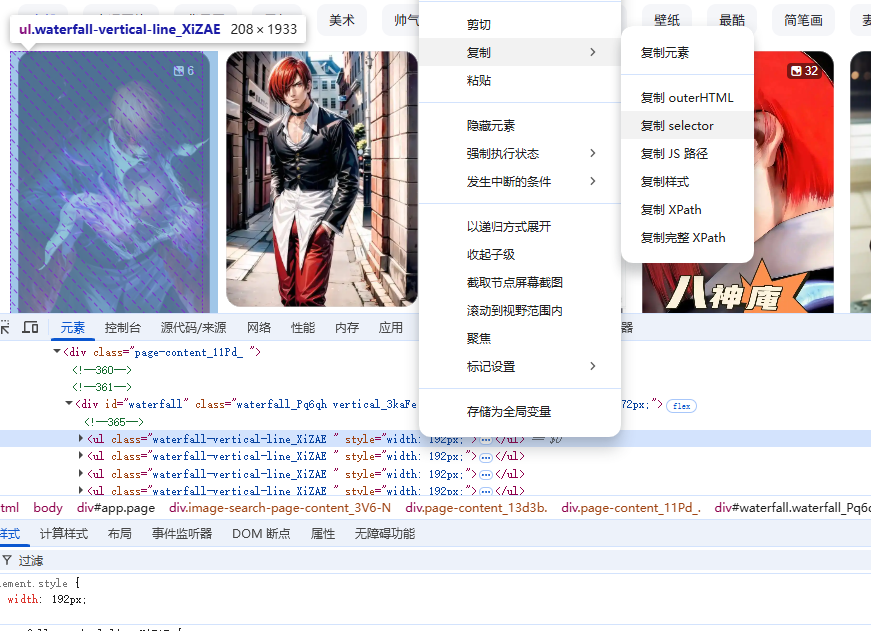
我们可以将它们获取成一个数组:
bash
elements = driver.find_elements(By.CSS_SELECTOR,"#waterfall > ul")然后打印一下它的长度:
bash
print(len(elements))这里需要注意一下,由于不同网站显示列表的策略不一样,比如百度地图,它是使用了滚动复用的列表显示策略,所以虽然看起来好像搜索出来很多图片,但实际上同时显示的内容只有2行。
完整的代码会是这样:
bash
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
chrome_driver_path = r'D:\webDriver\chromedriver-win64\chromedriver.exe' #替换成安装webDriver的地址
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(chrome_driver_path) # (service=service)
url = 'https://image.baidu.com/'
try:
driver.get(url) # 打开浏览器
time.sleep(1) # 等待1秒
driver.find_element_by_id('image-search-input').send_keys("八神庵")
driver.find_element_by_css_selector(".search-wrapper_YUbkG .search-form_2_2jV .input-wrapper_3_y8s .submit-btn_38GYq input").click()
time.sleep(1)
elements = driver.find_elements(By.CSS_SELECTOR,"#waterfall > ul")
print(len(elements))
time.sleep(10) # 等待10秒
finally:
driver.quit() # 关闭浏览器如果我们想打开第一个图片,可以:
bash
elements[1].click()完整的代码是:
bash
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
chrome_driver_path = r'D:\webDriver\chromedriver-win64\chromedriver.exe' #替换成安装webDriver的地址
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(chrome_driver_path) # (service=service)
url = 'https://image.baidu.com/'
try:
driver.get(url) # 打开浏览器
time.sleep(1) # 等待1秒
driver.find_element_by_id('image-search-input').send_keys("八神庵")
driver.find_element_by_css_selector(".search-wrapper_YUbkG .search-form_2_2jV .input-wrapper_3_y8s .submit-btn_38GYq input").click()
time.sleep(1)
elements = driver.find_elements(By.CSS_SELECTOR,".waterfall-vertical-line_XiZAE")
print(len(elements))
elements[1].click()
time.sleep(10) # 等待10秒
finally:
driver.quit() # 关闭浏览器5、 切换窗体
运行了上面的代码之后,会发现一个问题,浏览器打开了新的窗口(标签页):
这个时候就涉及到了一个问题:
如果我们继续在之前的代码上面查找元素,会查找到旧的标签页上面的内容。所以现在需要切换一下窗口:
bash
handle=driver.window_handles#获取句柄,得到的是一个列表
driver.switch_to.window(handle[-1])#切换至最新句柄为了测试是否切换成功,我打印一下切换后的窗体的标题,还有获取一下网页里面图片的URL:
bash
print(driver.title)
element = driver.find_element_by_css_selector(".image-contain-y_1fkDN")
print(element.get_attribute('src'))完整的代码:
bash
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
chrome_driver_path = r'D:\webDriver\chromedriver-win64\chromedriver.exe' #替换成安装webDriver的地址
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(chrome_driver_path) # (service=service)
url = 'https://image.baidu.com/'
try:
driver.get(url) # 打开浏览器
time.sleep(1) # 等待1秒
driver.find_element_by_id('image-search-input').send_keys("八神庵")
driver.find_element_by_css_selector(".search-wrapper_YUbkG .search-form_2_2jV .input-wrapper_3_y8s .submit-btn_38GYq input").click()
time.sleep(1)
elements = driver.find_elements(By.CSS_SELECTOR,".waterfall-vertical-line_XiZAE")
print(len(elements))
elements[1].click()
time.sleep(1)
handle=driver.window_handles#获取句柄,得到的是一个列表
driver.switch_to.window(handle[-1])#切换至最新句柄
print(driver.title)
element = driver.find_element_by_css_selector(".image-contain-y_1fkDN")
print(element.get_attribute('src'))
time.sleep(10)
finally:
driver.quit() # 关闭浏览器6、 保存数据
假如我们只是需要把文字给保存起来,那就很简单了,把需要的网页元素找出来,然后通过.text就能获取到这个元素里面所有的文字,然后通过file保存起来。
比如:
bash
content = driver.find_element_by_css_selector(你需要的元素选择器).text
with open('你的文件名',mode='w',encoding='utf-8') as file:
file.write(content)假如需要保存图片,那么就需要配合其他的库来保存,我在网上找了一段保存图片的代码:
bash
import time
import requests
import os
def image_save(image_url, path):
if not os.path.exists(path): # 如果文件夹不存在,则创建
os.makedirs(path)
# 发送 GET 请求获取图片数据
response = requests.get(image_url)
# 确保请求成功
if response.status_code == 200:
image_name = int(time.time())
image_name = "{}.png".format(image_name)
# 指定图片保存路径
save_path = os.path.join(path, image_name) # 这里将图片保存在名为 images 的文件夹中
# 将图片数据写入文件
with open(save_path, 'wb') as f:
f.write(response.content)
print(f'图片已保存为: {save_path}')
return save_path
else:
print(f'下载图片失败,状态码: {response.status_code}')于是现在我们的代码变成:
bash
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
import requests
import os
def image_save(image_url, path):
if not os.path.exists(path): # 如果文件夹不存在,则创建
os.makedirs(path)
# 发送 GET 请求获取图片数据
response = requests.get(image_url)
# 确保请求成功
if response.status_code == 200:
image_name = int(time.time())
image_name = "{}.png".format(image_name)
# 指定图片保存路径
save_path = os.path.join(path, image_name) # 这里将图片保存在名为 images 的文件夹中
# 将图片数据写入文件
with open(save_path, 'wb') as f:
f.write(response.content)
print(f'图片已保存为: {save_path}')
return save_path
else:
print(f'下载图片失败,状态码: {response.status_code}')
chrome_driver_path = r'D:\webDriver\chromedriver-win64\chromedriver.exe' #替换成安装webDriver的地址
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(chrome_driver_path) # (service=service)
url = 'https://image.baidu.com/'
try:
driver.get(url) # 打开浏览器
time.sleep(1) # 等待1秒
driver.find_element_by_id('image-search-input').send_keys("八神庵")
driver.find_element_by_css_selector(".search-wrapper_YUbkG .search-form_2_2jV .input-wrapper_3_y8s .submit-btn_38GYq input").click()
time.sleep(1)
elements = driver.find_elements(By.CSS_SELECTOR,".waterfall-vertical-line_XiZAE")
print(len(elements))
elements[1].click()
time.sleep(1)
handle=driver.window_handles#获取句柄,得到的是一个列表
driver.switch_to.window(handle[-1])#切换至最新句柄
print(driver.title)
element = driver.find_element_by_css_selector(".image-contain-y_1fkDN")
imgUrl = element.get_attribute('src')
image_save(imgUrl, "images")
time.sleep(10)
finally:
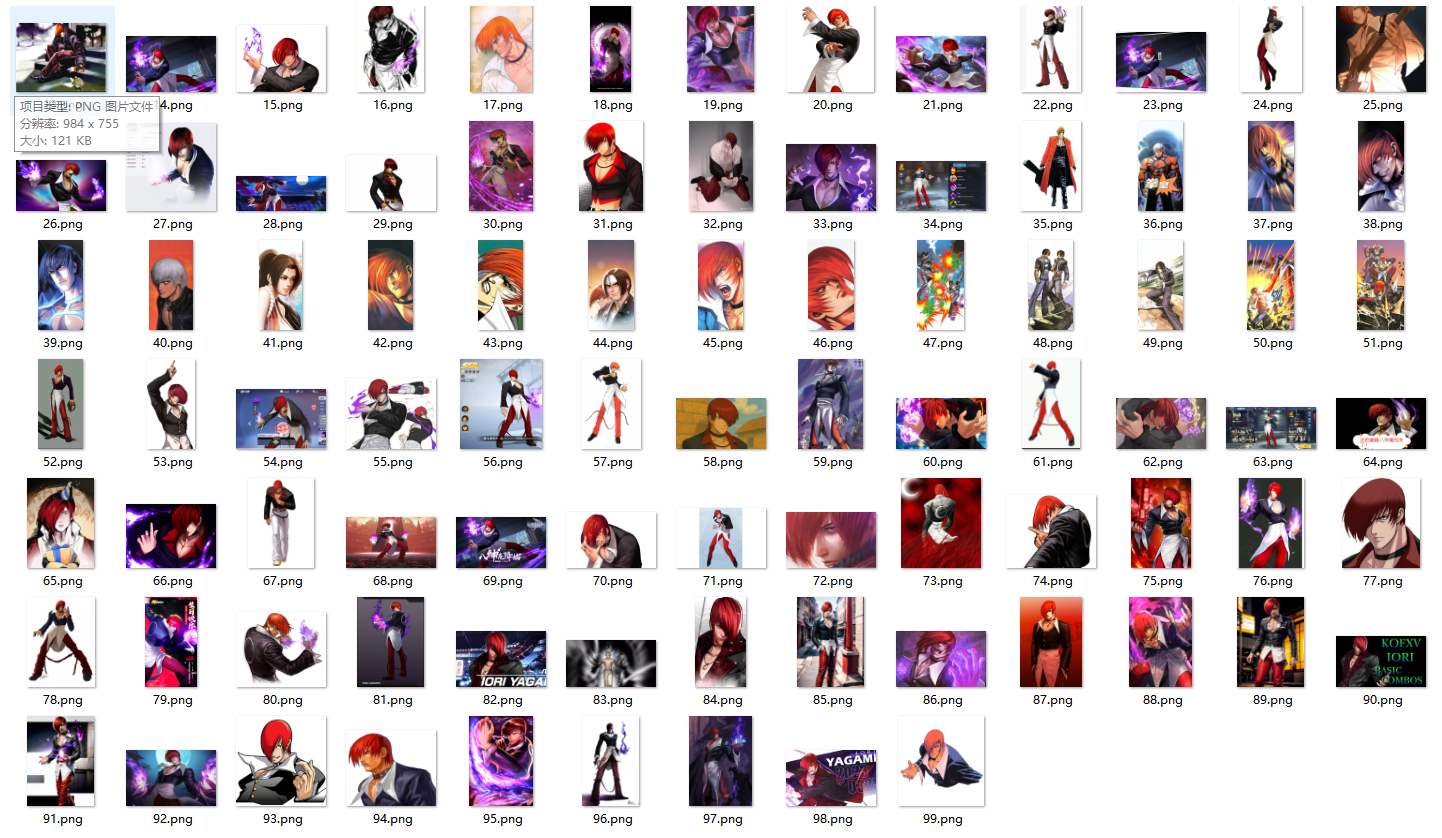
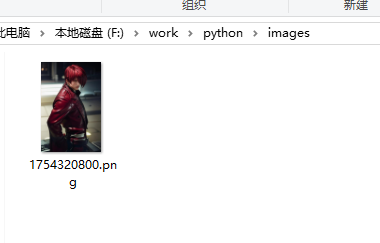
driver.quit() # 关闭浏览器运行一下,看到图片已经被保存了:
7、 循环获取
到了这个时候,我们其实已经接近成功了,最后要做的事情,就是要输入一个我们想要收集的数量,然后通过一个循环,不同的点下一页,然后保存:
现在的代码:
bash
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
import requests
import os
def image_save(image_url, path):
if not os.path.exists(path): # 如果文件夹不存在,则创建
os.makedirs(path)
# 发送 GET 请求获取图片数据
response = requests.get(image_url)
# 确保请求成功
if response.status_code == 200:
image_name = int(time.time())
image_name = "{}.png".format(image_name)
# 指定图片保存路径
save_path = os.path.join(path, image_name) # 这里将图片保存在名为 images 的文件夹中
# 将图片数据写入文件
with open(save_path, 'wb') as f:
f.write(response.content)
print(f'图片已保存为: {save_path}')
return save_path
else:
print(f'下载图片失败,状态码: {response.status_code}')
chrome_driver_path = r'D:\webDriver\chromedriver-win64\chromedriver.exe' #替换成安装webDriver的地址
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(chrome_driver_path) # (service=service)
url = 'https://image.baidu.com/'
tryCount = 50 #想获取的页数
try:
driver.get(url) # 打开浏览器
time.sleep(1) # 等待1秒
driver.find_element_by_id('image-search-input').send_keys("八神庵")
driver.find_element_by_css_selector(".search-wrapper_YUbkG .search-form_2_2jV .input-wrapper_3_y8s .submit-btn_38GYq input").click()
time.sleep(1)
elements = driver.find_elements(By.CSS_SELECTOR,".waterfall-vertical-line_XiZAE")
print(len(elements))
elements[1].click()
time.sleep(1)
handle=driver.window_handles#获取句柄,得到的是一个列表
driver.switch_to.window(handle[-1])#切换至最新句柄
print(driver.title)
for i in range(tryCount):
element = driver.find_element_by_css_selector(".image-contain-y_1fkDN")
imgUrl = element.get_attribute('src')
image_save(imgUrl, "images")
driver.find_element_by_css_selector(".next_3Z4tx").click()
time.sleep(1)
finally:
driver.quit() # 关闭浏览器执行代码,发现是开始自动保存图片了,但到了25张左右的时候,程序就停下来,并且报错说找不到.image-contain-y_1fkDN元素。后来我检查了一下,发现百度图片在切换到一定数量的图片之后,中间的图片的xpath和css选择器都发生了变化。于是我只能修改了一下选择器,由于它的父级是不会变的,所以我把选择器改成了".image-inner-wrapper_YrQGw img",这时候,就能正常的下载了。
最终的代码变成了:
bash
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import requests
import os
def image_save(image_url, path,fileName):
if not os.path.exists(path): # 如果文件夹不存在,则创建
os.makedirs(path)
# 发送 GET 请求获取图片数据
response = requests.get(image_url)
# 确保请求成功
if response.status_code == 200:
image_name = fileName
image_name = "{}.png".format(image_name)
# 指定图片保存路径
save_path = os.path.join(path, image_name) # 这里将图片保存在名为 images 的文件夹中
# 将图片数据写入文件
with open(save_path, 'wb') as f:
f.write(response.content)
print(f'图片已保存为: {save_path}')
return save_path
else:
print(f'下载图片失败,状态码: {response.status_code}')
chrome_driver_path = r'D:\webDriver\chromedriver-win64\chromedriver.exe' #替换成安装webDriver的地址
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(chrome_driver_path) # (service=service)
wait = WebDriverWait(driver, 100) # 最长等待时间为10秒
url = 'https://image.baidu.com/'
tryCount = 100 #想获取的页数
try:
driver.get(url) # 打开浏览器
time.sleep(1) # 等待1秒
driver.find_element_by_id('image-search-input').send_keys("八神庵")
driver.find_element_by_css_selector(".search-wrapper_YUbkG .search-form_2_2jV .input-wrapper_3_y8s .submit-btn_38GYq input").click()
time.sleep(1)
elements = driver.find_elements(By.CSS_SELECTOR,".waterfall-vertical-line_XiZAE")
print(len(elements))
elements[1].click()
time.sleep(1)
handle=driver.window_handles#获取句柄,得到的是一个列表
driver.switch_to.window(handle[-1])#切换至最新句柄
for i in range(tryCount):
element = driver.find_element_by_css_selector(".image-inner-wrapper_YrQGw img")
imgUrl = element.get_attribute('src')
image_save(imgUrl, "images",i)
driver.find_element_by_css_selector(".next_3Z4tx").click()
time.sleep(0.01)
element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,".image-inner-wrapper_YrQGw")))
time.sleep(1)
finally:
driver.quit() # 关闭浏览器执行之后,就得到了我们想要保存的图片了: