写在文章开头
近期因为某些原因去阅读了解了一下redis中关于scan指令的设计与实现,刚好也有读者提问源码阅读的技巧,所以笔者就以scan指令的阅读过程为例,介绍一下笔者对于各种开源项目的阅读技巧,希望对你有帮助。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili ,也欢迎您了解我的开源项目 mini-redis:github.com/shark-ctrl/...
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
源码阅读的前置步骤
必要的调试环境搭建(附redis源码环境调试教程)
大型开源项目设计架构是非常复杂的,很多情况下我们无法通过肉眼调试的方式将流程梳理清楚,所以当我们需要阅读源码的时候,首先就是将源码环境拉下来并跑起来,为后续主线路调试做好铺垫,这是源码阅读的大前提也是最重要的一步。
我相信大部分人都会都是因为这一步而被劝退,原因很简单,搭建环境时或多或少会因为各种恶心的环境报错疑惑者是对于异构语言的不了解,在这里笔者的建议是大胆尝试一下,对于这些著名开源项目的拜读者还是很多的,我们可以非常容易的从github疑惑者是网上的各种帖子找到环境搭建的步骤。
以本文为例,笔者是一名java开发,对于c语言的基础也仅仅是停留在大学阶段,所以对于企业级c语言项目的了解也不是特别熟悉,在正式阅读redis源码时笔者也是详细的阅读了redis官网中对于源码环境的说明。
如下图所示,这是笔者近期阅读的redis 3.2.8的源码的readme文档,可以看到该文档中详尽的介绍redis项目拉取、编译、启动运行的所有步骤,我们完全可以沉下心去阅读了解大体步骤后,结合网上的一些关于c语言调试的开发工具得出一套综合的环境搭建过程将项目跑起来:
image-20250805130422876
知晓其工作流程
这是前置准备工作之后的又一个大前提,即阅读源码一定要清晰明确自己阅读源码与之对应的技术是做什么、怎么用、如何用,能达到什么样的效果。读源码本质上就是要了解技术实现的本质,这一切的大前提就是我们要了解技术实现的表象,只有知道了干什么,才能深入的去了解怎么干,从而完成知识点之间的关联,完成一次完整的源码阅读和学习。
以笔者为例,本次所要了解的就是redis中scan指令的实现细节,在正式的了解之前,笔者对该指令做了一定的了解,对其作用、输入输出、运用场景、使用注意事项等都有了深入的了解。本质上scan指令就是针对当前客户端操作的库的一次游标迭代。默认情况是扫描单个库的全键的,假设我们现在设置如下数据,对应abcd:

image-20250805225229440
默认我们调用scan 0即进行全表扫描:
makefile
127.0.0.1:6379> scan 0
1) "0"
2) 1) "b"
2) "c"
3) "a"
4) "d"同时,scan还支持有限count查询,如下所示,这代表的通过scan的游标0开始拿一条数据,需要注意的是默认情况下键入的count给redis指令只是做一个参考,在没有任何匹配规则的情况下count指令对应的输出结果可能是会多,不可能会少,这一点笔者会在后文做详尽分析,因为这也是笔者为什么要多读源码的原因:
makefile
127.0.0.1:6379> scan 0 count 1
1) "2"
2) 1) "b"
2) "c"最后我们再说明一点,scan指令也支持match参数,即支持模糊匹配,例如笔者希望找到c开头的key,对应的查询指令和输出指令如下,可以看到笔者键入count 1000希望检索到1000,因为键的数量限制最终的结果可能比预期的少,同时scan也变为了0这也就说明这个库已经全扫荡完成了:
ruby
127.0.0.1:6379> scan 0 match c* count 10000
1) "0"
2) 1) "c"详解scan指令的设计与实现
宏观实现思路
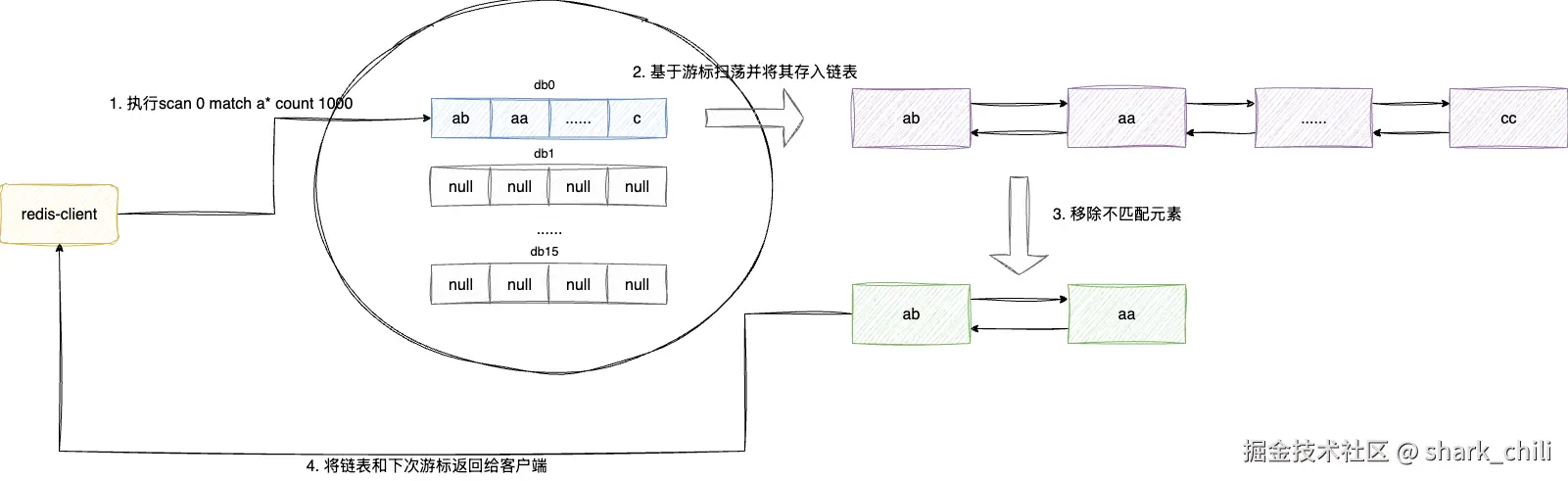
有了上述的使用经验的基础,我们就可以正式阅读源码了,首先自然是定位到指令核心实现的入口,对应笔者本次要阅读了解的源码位置即db.c下的scanCommand,因为知道scan的作用,所以我们可以宏观的阅读一下源码了解其对于单库扫描的整体流程:
- 解析scan参数:如果有count和match则解析这些参数后面的值,并校验合法性。
- 定位到客户端使用的数据库,并基于游标开始扫荡,将结果链表中
- 如果有match参数则基于步骤2的链表完成过滤
- 返回链表和下一次的游标
scan-command.drawio
对应的我们也给出scan指令的核心代码实现,整体逻辑和上述差不多,读者可以结合注释了解一下宏观的流程,本质上就是拿一个链表基于本次的游标获取数据在过滤后将结果写给客户端:
scss
void scanCommand(client *c) {
//......
//调用scanGenericCommand进行库扫描
scanGenericCommand(c,NULL,cursor);
}
void scanGenericCommand(client *c, robj *o, unsigned long cursor) {
int i, j;
//创建初始化链表
list *keys = listCreate();
listNode *node, *nextnode;
//.....
/* Step 1: Parse options. */
while (i < c->argc) {
//获取count的坐标
j = c->argc - i;
//如果参数存在count则解析count的值,若有问题则goto到cleanup完成资源释放
if (!strcasecmp(c->argv[i]->ptr, "count") && j >= 2) {
if (getLongFromObjectOrReply(c, c->argv[i+1], &count, NULL)
!= C_OK)
{
goto cleanup;
}
//如果count小于1则参数非法职介抛出异常执行goto后置清理
if (count < 1) {
addReply(c,shared.syntaxerr);
goto cleanup;
}
i += 2;
} else if (!strcasecmp(c->argv[i]->ptr, "match") && j >= 2) {//解析match的值并验证其合法性
pat = c->argv[i+1]->ptr;
patlen = sdslen(pat);
use_pattern = !(pat[0] == '*' && patlen == 1);
i += 2;
} else {
addReply(c,shared.syntaxerr);
goto cleanup;
}
}
//定位到客户端对应的库
ht = NULL;
if (o == NULL) {
ht = c->db->dict;
}
//......
if (ht) {
//数组一个用于存储key的值,来一个用于特殊类型的元素扫荡
privdata[0] = keys;
privdata[1] = o;
do {//基于传入的游标定位到元素触发scanCallback(本质就是将元素存入链表)
cursor = dictScan(ht, cursor, scanCallback, privdata);
} while (cursor &&
maxiterations-- &&
listLength(keys) < (unsigned long)count);//游标非0且还在最大尝试次数且链表未达到要求的count就可以继续循环
} else if (o->type == OBJ_SET) {
//......
} else if (o->type == OBJ_HASH || o->type == OBJ_ZSET) {
//......
} else {
serverPanic("Not handled encoding in SCAN.");
}
/* Step 3: Filter elements. */
node = listFirst(keys);
//遍历node执行过滤逻辑
while (node) {
robj *kobj = listNodeValue(node);
nextnode = listNextNode(node);
int filter = 0;
/* Filter element if it does not match the pattern. */
if (!filter && use_pattern) {
if (sdsEncodedObject(kobj)) {
if (!stringmatchlen(pat, patlen, kobj->ptr, sdslen(kobj->ptr), 0))//如果不匹配则将filter设置为1
filter = 1;
} else {
//......
}
}
//如果这个key过期了也将标识设置为1
if (!filter && o == NULL && expireIfNeeded(c->db, kobj)) filter = 1;
//若为1则将这个节点从链表中移除
if (filter) {
decrRefCount(kobj);
listDelNode(keys, node);
}
//......
node = nextnode;
}
//基于RESP协议规范将下次的cursor游标和链表结果写给客户端
addReplyMultiBulkLen(c, 2);
addReplyBulkLongLong(c,cursor);
addReplyMultiBulkLen(c, listLength(keys));
while ((node = listFirst(keys)) != NULL) {
robj *kobj = listNodeValue(node);
addReplyBulk(c, kobj);
decrRefCount(kobj);
listDelNode(keys, node);
}
cleanup://完成后释放链表指针
listSetFreeMethod(keys,decrRefCountVoid);
listRelease(keys);
}参数解析上的优化
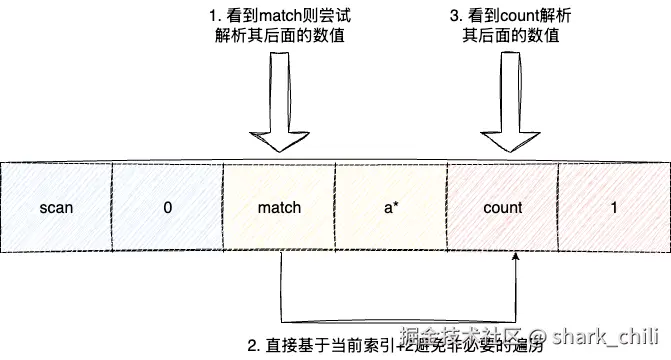
有了宏观的流程的基础之后,我们就可以针对性的去了解细节,上文中我们看到scan指令的首要核心步骤是解析参数,对应的就是基于索引的迭代,这里我们也可以看到redis设计者在这种细节上的优化,对于一般的开发者而言,拿到scan match count这套组合参数之后,一般都是采用顺序遍历的方式进行参数解析,即顺序遍历:
- 看到match解析match后面的参数
- 看到count解析count后面跟随的参数
而redis在循环迭代这方面就有了微观的操作,直接从索引2开始(scan游标后面的值),查看当前字符串是否上match如果是则直接解析其参数并验证合法性,然后索引直接+2直接尝试去解析count的值:
scan-command-2.drawio
同时参数解析阶段,也考虑到用户不规范的用法,即match后面直接跟个*导致基于全库扫荡的数据执行了过滤逻辑,进而造成非必要的耗时,所以redis在参数解析阶段,也会判断match后面的值是否是*,如果不是才执行过滤匹配。对应的我们给出参数解析这段代码实现的细节,读者可以基于笔者的说法自行参阅了解一下:
ini
//默认情况下,从索引2开始参数解析
while (i < c->argc) {
//获取count的坐标
j = c->argc - i;
//查看是否为count然后转换值存入count中,若报错直接进去goto语句块做后置的清理工作
if (!strcasecmp(c->argv[i]->ptr, "count") && j >= 2) {
if (getLongFromObjectOrReply(c, c->argv[i+1], &count, NULL)
!= C_OK)
{
goto cleanup;
}
if (count < 1) {
addReply(c,shared.syntaxerr);
goto cleanup;
}
//直接跳两步,避免非必要的遍历
i += 2;
} else if (!strcasecmp(c->argv[i]->ptr, "match") && j >= 2) {
pat = c->argv[i+1]->ptr;
patlen = sdslen(pat);
//避免非必要的过滤逻辑,看到匹配单词是*且长度为1,则use_pattern为0,后续不执行过滤逻辑
use_pattern = !(pat[0] == '*' && patlen == 1);
//直接跳两步,避免非必要的遍历
i += 2;
} else {
addReply(c,shared.syntaxerr);
goto cleanup;
}
}游标扫荡的算法实现
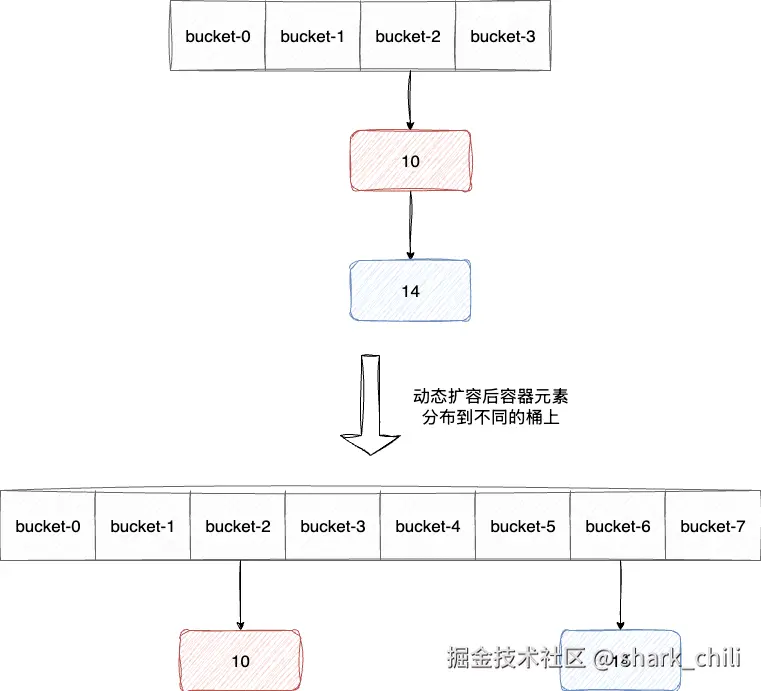
接下来就到了最重点的一环了,redis实现数据库用的是字典,也就是java开发常说的map,考虑到redis底层的存储键值对对应的数组会因为数据的增加而不断基于渐进式哈希的方式扩容,这就是得处于当前数组的数据可能会在下一刻跑到另一个容器中,例如我们当前存储键值对的字典空间容量为4,我们的元素存储在索引2中,随后redis因为空间不足触发动态扩容,按照redis的算法索引0的元素就有可能被迁移到新数组的索引2或者索引6中。
scan-command-3.drawio
同理针对其他bucket的情况也是类似:
- 对应索引0元素可能会被驱逐到0、4上
- 对应索引1元素可能会被驱逐到1、3上
- 对应索引3元素可能会被驱逐到3、7上
这就会引发一种非常极端的情况,如果我们按照常规的数组遍历的方式进行扫荡,当我们游标返回2时,对应原本扫描过的索引上的元素被迁移到了3上,而bucket-0迁移到bucket-4上,这就会导致游标扫描时,出现大量重复效率低下。
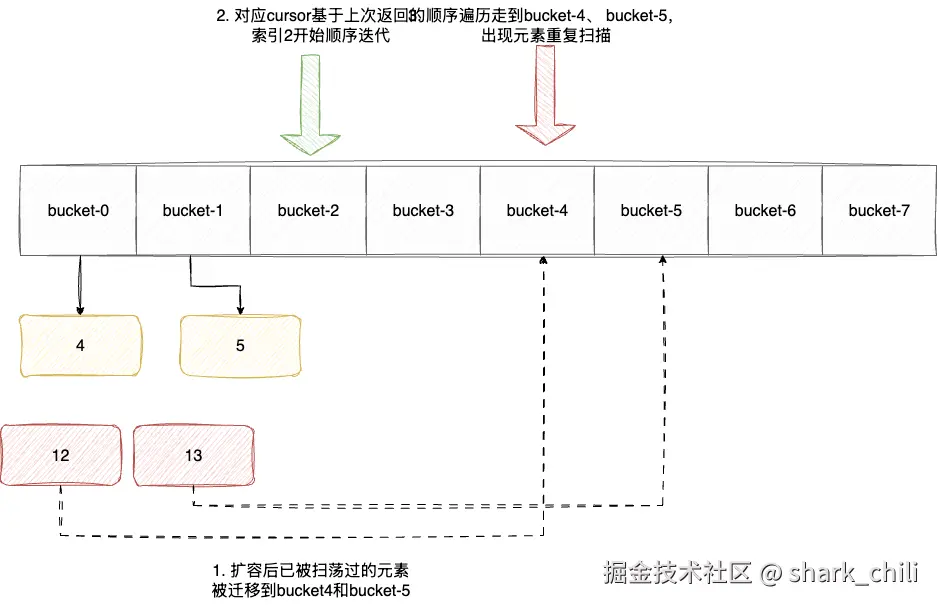
scan-command-4.drawio
而同理动态缩容也是一样,原本bucket-4和bucket-5的数据跑到了bucket-0和bucket-1上,顺序迭代没有办法知道准确的读取进度,必须从头开始扫荡,效率也还是低下。
对此,设计者们就在考虑是否存在一种算法,可以保证当前键值对不漏扫的情况下,尽可能少的出现重复扫荡的情况,于是就有了逆序二进制累加法。
这个算法整体思路稍微有点复杂,笔者打算先从整体的理念说起,然后落到代码实现的细节上,通俗来说,这套算法本质就是基于当前容器size所以对应的hash掩码进行高位反向累加,举个例子,当字典底层的数组容量为4的时候,对应的掩码为0011即元素具体落到数组的那个bucket的算法为元素hash值&0011,如下图所示:
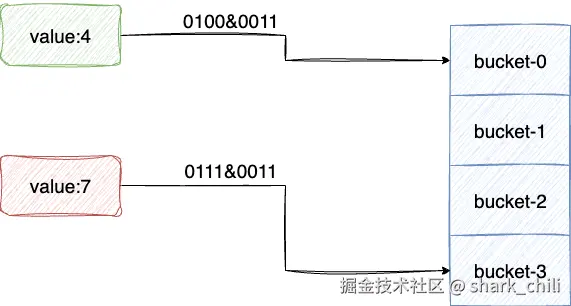
scan-command-5.drawio
这种hash算法本质上就是对应的%4,只不过是通过二进制的方式保证其运算的高效性,通过二进制的规律,设计者们发现这些元素对应的bucket永远是会落在mask掩码区间,例如本次size 4对应的掩码0011,对应元素会得到的bucket都处于如下区间:
yaml
0000
0001
0010
0011所以设计者们对应游标扫荡的策略就是从掩码最高位开始,不断自左向右的倒叙累加,即基于掩码的区间完成不重复的扫荡,我们还是以size 4的数组为例,我们从游标0开始推演一下其扫荡策略:
- 默认从0开始,对应二进制0000,从直观上掩码位最高位研究是0011即最高位是自左向右数第三位向左加1,得到2
- 数字2对应二进制0010,继续倒叙累加,得到0001,对应1
- 数字1对应0001继续累加得到0011对应3
- 数字3继续累加推进这些1全部往不存在的低位递进,最终得到0,这也就是为什么scan返回0的意思说明扫荡完成了
对应的计算过程如下图所示:
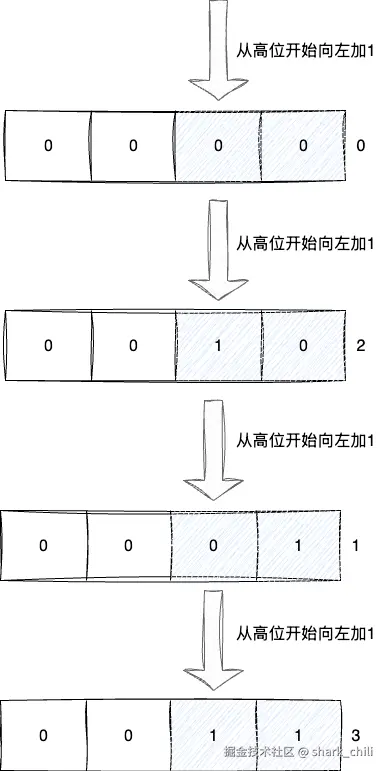
scan-command-6.drawio
采用高位累加的方式其实还有另一个目的,还记得上文中提及的扩容或者缩容导致的大量重复扫描的问题嘛?通过这种算法可以大量减少重复扫描的数据量,原因是这种算法可以保证原有数组扩容后的索引位置紧挨着避免非必要的重复扫荡,将重复扫荡控制在当前扩容的游标区间内。
举个例子,上文中对应的size 4的 对应各个索引扩容后的位置对照为:
- 索引0扩容可能迁移到4
- 索引1扩容可能迁移到5
- 索引2扩容可能迁移到6
- 索引3扩容可能迁移到7
对应二进制图解如下,可以看出这个迁移策略本质上就是利用扩容后的mask最高位的1进行按位或得到的结果,说的通俗一点就是拿着扩容后的mask最高位的那个1拼到对应位置即得到扩容后迁移到索引:
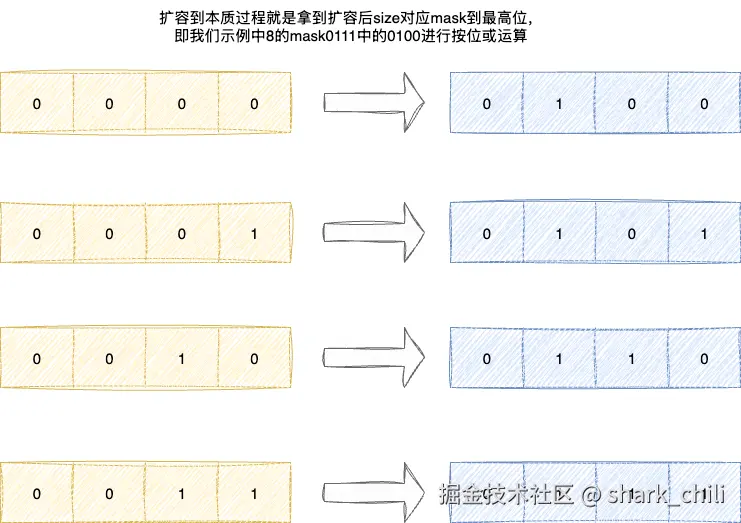
scan-command-7.drawio
所以倒叙累加也是利用这一规律,即获取扩容后的索引空间本质上就是利用扩容后的mask最高位的1进行反向累加不断扰动得到索引扩容前后的区间值。
我们还是举例说明,上文的size 4经过扩容后变为size 8,我们还是从游标0开始执行上述的反向累加算法,如下图所示,最终的扫荡结果为:0、4、2、6、1、5、3、7,可以发现反向累加不仅避免了重复索引的扫荡,也保证了扩容前后的索引紧挨在一起,例如0和4、2和6等等,这样做的好处就是假设我们扫描得到的游标为2,继续开始执行也仅仅只会重复扫荡2扩容后跑到6索引的元素,对应1和5还有3和7之间的扩容都在后面紧挨着,不会执行:
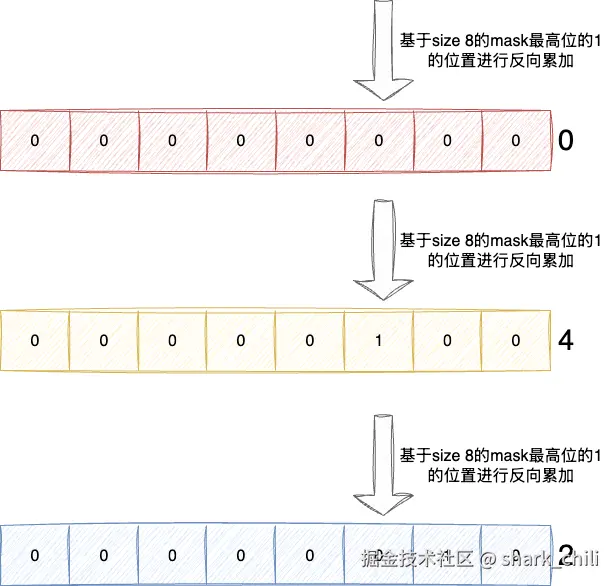
scan-command-8.drawio
所以有了上述的基础之后,我们终于可以讲scan对于这个累加操作的落地代码了,这个算法实现的比较巧妙,笔者直接以一个示例来说明,假设现在size为4,游标为2,下一次应该走到6即索引2的扩容后的索引位置,对应步骤为:
- 是将扩容后的size8的掩码0111取反变为1000
- 将1000和索引0的二进制0010按位或得到1010,这样做的目的是让当前所有高位置为1的同时保留mask为以内的数值即数值2的二进制。
- 通过步骤2我们可以得到1010,同二进制的角度来说,我们可以将其分为两部分,最高位的1还有二进制2的二进制值010,要想得到4,我们只需利用最高位的1向右累加即得到0110也就是6
- 所以步骤4就是要实现如何反向累加了,按照redis源码的做法,首先将1010取反让它以正常的顺序完成累加,然后再翻回去,即1010变0101,然后累加位0110,按照正常顺序累加后,再翻回去最终得到0110也就是6
而这就是scan算法的最终思路,对应的我们也给出这段代码的细节,也就是实际进行游标扫荡存储链表的dictScan方法的后半部分:
arduino
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
void *privdata)
{
dictht *t0, *t1;
const dictEntry *de;
unsigned long m0, m1;
if (dictSize(d) == 0) return 0;
if (!dictIsRehashing(d)) {
//获取本次游标v对应的元素存入链表
//高位取反通过按位或保留索引值
v |= ~m0;
/* Increment the reverse cursor */
//取反完成正常的累加、再取反完成倒叙运算,最终的v就是下一次的游标
v = rev(v);
v++;
v = rev(v);
} else {
//......
}
return v;
}过滤匹配的实现和优化上的微操
最后我们再来聊聊match参数的优化,相比于扫荡的算法这个实现就比较容易了,首先是参数解析阶段,为了避免用户传入*且有match执行时进行扫描结果全过滤的开销,参数解析阶段会查看当前的字符串是否是*,如果是则过滤标识use_pattern直接设置为0后续就不执行过滤:
ini
while (i < c->argc) {
//获取count的坐标
j = c->argc - i;
//查看是否为count然后转换值存入count中,若报错直接进去goto语句块做后置的清理工作
if (!strcasecmp(c->argv[i]->ptr, "count") && j >= 2) {
//......
} else if (!strcasecmp(c->argv[i]->ptr, "match") && j >= 2) {
pat = c->argv[i+1]->ptr;
patlen = sdslen(pat);
//避免非必要的过滤逻辑,看到匹配单词是*且长度为1,则use_pattern为0,后续不执行过滤逻辑
use_pattern = !(pat[0] == '*' && patlen == 1);
//直接跳两步,避免非必要的遍历
i += 2;
} else {
addReply(c,shared.syntaxerr);
goto cleanup;
}
}而过滤的逻辑也很简单,基于表达式进行匹配,如果不符合要求则将过滤标识filter设置为1,后续逻辑判断这个标识为1直接将其从链表中删除:
scss
if (!filter && use_pattern) {
if (sdsEncodedObject(kobj)) {
if (!stringmatchlen(pat, patlen, kobj->ptr, sdslen(kobj->ptr), 0))//如果不匹配则将filter设置为1
filter = 1;
} else {
//......
}
}
//如果获得的元素过期了,过滤标识也设置为1
if (!filter && o == NULL && expireIfNeeded(c->db, kobj)) filter = 1;
//如果过滤标识为1则将这个节点删除
if (filter) {
decrRefCount(kobj);
listDelNode(keys, node);
}小结
自此,笔者基于redis的scan指令完成了源码解析过程技巧的介绍,总的来说阅读源码时,我们要遵循:
- 搭建起调测环境,例如笔者本次的redis源码环境搭建
- 明确要调测的源码的输入和输出,对其使用有所感知,例如笔者本次的scan指令的使用场景和效果
- 带着阅读的目的去调试源码
- 宏观的了解细节,即scan指令大体的处理流程,并要时通过图解绘制出流程验证自己的了解程度
- 针对细节去逐步调试,观测数据的变化,理解其设置理念和实现细节
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili ,也欢迎您了解我的开源项目 mini-redis:github.com/shark-ctrl/...
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
参考
Redis SCAN 命令 递增地遍历key空间:redis.com.cn/commands/sc...
Redis中的数据库切换:从DB0到DB1的写操作详解-百度开发者中心:developer.baidu.com/article/det...
Redis Scan 原理解析与踩坑:www.lixueduan.com/posts/redis...
让人爱恨交加的Redis Scan遍历操作原理:chenzhenianqing.com/articles/14...
本文使用 markdown.com.cn 排版