1. BFF 架构设计
什么是BFF
BFF(Backend For Frontend)是一种架构模式,字面意思是"为前端服务的后端"。简单来说,就是在前端和后端服务之间增加一个中间层,专门为前端应用提供定制化的数据服务。
想象一下,你是一个餐厅的服务员(BFF),客人(前端)点餐时,你不需要让客人直接跑到厨房(后端微服务)去找厨师要菜,而是由你来统一收集客人的需求,然后去厨房协调各个厨师,最后把配好的菜端给客人。
为什么要用BFF
在微服务架构中,我们经常遇到以下问题:
- 数据聚合困难:前端可能需要调用多个微服务来获取一个页面的数据
- 接口不匹配:后端微服务的接口设计往往不符合前端的使用习惯
- 网络请求过多:前端需要发起大量HTTP请求,影响性能
- 版本兼容性:不同端(Web、Mobile、小程序)需要不同的数据格式
BFF的优势:
- 数据聚合:一次请求获取多个服务的数据
- 接口适配:为不同端提供定制化的接口
- 减少网络请求:降低前端复杂度
- 业务逻辑下沉:把一些展示逻辑放到BFF层处理
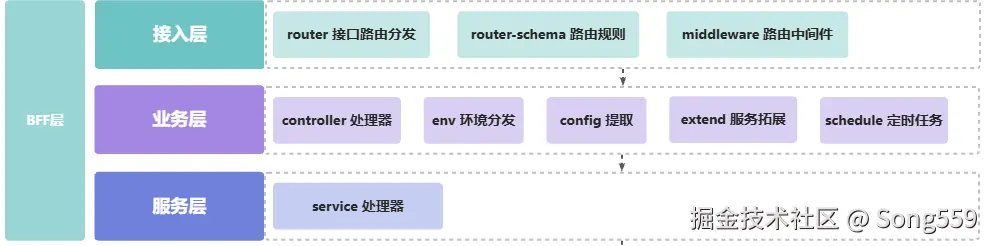
2. 规则设计
elpis-core 通过 loader 将项目文件进行解析成运行时,其实是一个简化版的 egg.js,约定优于配置。
文件目录规范详解
我们的框架采用约定优于配置的设计理念,开发者只需要按照约定的目录结构编写代码,框架会自动加载和管理这些文件:
目录结构示例
csharp
app/
├── middleware/ # 中间件目录
│ ├── auth.js # 认证中间件
│ └── cors.js # 跨域中间件
├── router-schema/ # 路由校验规则
│ └── user.js # 用户相关接口校验
├── router/ # 路由定义
│ └── user.js # 用户路由
├── controller/ # 控制器
│ └── user.js # 用户控制器
├── service/ # 服务层
│ └── user.js # 用户服务
├── config/ # 配置文件
│ ├── default.js # 默认配置
│ └── prod.js # 生产环境配置
└── extend/ # 框架扩展
└── logger.js # 日志扩展3. loader 的作用
loader是我们框架的核心组件,负责将约定的文件结构转换为运行时可用的对象。每个loader都有特定的职责:
- router 负责接口分发,定义URL路径和处理函数的映射关系。
- router-schema 负责请求参数校验,确保接口收到的数据格式正确。
- middleware 洋葱圈中间件(各种各样的拦截器),在业务处理前后做相应的处理,如日志记录、权限验证等。
- controller 业务层处理业务逻辑,作为请求的入口点,调用各种service来进行业务处理。
- service 处理原子化能力,封装具体的业务逻辑,如数据库操作、外部API调用等。
- config 负责不同环境加载不同的配置文件,支持开发、测试、生产等多环境配置。
- extend 用于扩展自定义框架内置对象的属性和方法,从而实现功能复用、逻辑封装和框架行为的定制,如: logger 日志工具。
4. middleware 洋葱圈模型
什么是洋葱圈模型
洋葱圈模型是Koa.js的核心设计理念,就像剥洋葱一样,请求会一层一层地穿过中间件,然后再一层一层地返回。
执行原理
- 原则:先进后出(LIFO - Last In First Out)
想象一下穿衣服的过程:
- 穿衣服:内衣 → 衬衫 → 外套
- 脱衣服:外套 → 衬衫 → 内衣
中间件的执行也是这样:
API请求 → 中间件1 → 中间件2 → 中间件3 → 业务逻辑处理 → 中间件3 → 中间件2 → 中间件1 → 响应请求代码示例
javascript
// 中间件1 - 日志记录
app.use(async (ctx, next) => {
console.log('1. 开始处理请求');
await next(); // 执行下一个中间件
console.log('6. 请求处理完成');
});
// 中间件2 - 权限验证
app.use(async (ctx, next) => {
console.log('2. 验证用户权限');
await next();
console.log('5. 权限验证结束');
});
// 中间件3 - 业务处理
app.use(async (ctx, next) => {
console.log('3. 执行业务逻辑');
ctx.body = '处理结果';
console.log('4. 业务逻辑执行完成');
});执行顺序:1 → 2 → 3 → 4 → 5 → 6
业务逻辑处理流程
在洋葱圈的最中心,是我们的业务逻辑处理:
5. 内核实现
5.1 入口文件统筹loader
js
// ...
module.exports = {
/**
* 启动项目服务
* @param {object} options 项目配置
*/
start(options = {}) {
// ...
middlewareLoader(app); // 加载 middleware
routerSchemaLoader(app); // 加载 routerSchema
controllerLoader(app); // 加载 controller
serviceLoader(app); // 加载 service
configLoader(app); // 加载 config
extendLoader(app); // 加载 extend
elpisMiddleware(app); // 注册全局中间件
routerLoader(app); // 注册 router
// ...
},
};5.2 核心 loader
middleware , router-schema , controller , service , config , extend , router 这些loader的核心思路:读取 app/{loader}/*/*.js 把所有的文件挂载到 app.{loader} 中,下面以middleware-loader 为例,大家可以举一反三:
js
const glob = require("glob");
const path = require("path");
const { sep } = path; // 兼容不同操作系统中的斜杆
/**
* middleware loader
* @param {object} app Koa 实例
* 加载所以 middleware,可以通过 'app.middlewares.${目录}.${文件}' 访问
*
*/
module.exports = (app) => {
const middlewares = {};
// 读取 app/middleware/**/**.js 下所有的文件
const elpisMiddlewarePath = path.resolve(__dirname, `..${sep}..${sep}app${sep}middleware`);
const elpisFileList = glob.sync(
path.resolve(elpisMiddlewarePath, `.${sep}**${sep}**.js`)
);
// 遍历app/middleware/下所有文件目录,把内容加载到 app.middleware
elpisFileList.forEach((file) => {
handlerFile(file);
});
function handlerFile(file) {
// 提取文件名称
let name = path.resolve(file);
// 路径截取, app/middleware/custom-module/custom-middleware.js => custom-module/custom-middleware
name = name.substring(
name.lastIndexOf(`middleware${sep}`) + `middleware${sep}`.length,
name.lastIndexOf(".")
);
// 把 '-' 统一改为驼峰式, custom-module/custom-middleware => customModule.customMiddleware
name = name.replace(/[_-][a-z]/gi, (s) => s.substring(1).toUpperCase());
// 挂载 middleware 到内存 app 对象中
let tempMiddleware = middlewares;
const names = name.split(sep);
for (let i = 0, len = names.length; i < names.length; ++i) {
if (i === len - 1) {
tempMiddleware[names[i]] = require(path.resolve(file))(app);
} else {
if (!tempMiddleware[names[i]]) {
tempMiddleware[names[i]] = {};
}
tempMiddleware = tempMiddleware[names[i]];
}
}
}
app.middlewares = middlewares;
};loader实现要点说明
- 路径解析 :使用
glob模块递归扫描目录下的所有JavaScript文件 - 命名规范:将文件路径转换为驼峰式命名,便于访问
- 动态加载 :使用
require动态加载模块 - 树形结构:按照目录结构构建对象树,支持多级目录
其中 config loader 需要注意配置的覆盖顺序,自定义配置文件覆盖默认配置文件。router loader 需要有兜底路由处理,避免 404。
5.3 loader 使用
以 middleware中的error-handler错误处理中间件为例,我们谈谈loader如何将我们编写的内核使用起来:
js
// \app\middleware\error-handler.js
/**
* 运行时异常错误处理,兜底所有异常
* @param {object} app koa 实例
*/
module.exports = (app) => {
return async (ctx, next) => {
try {
await next();
} catch (error) {
// 异常处理
const { status, message, detail } = error;
app.logger.info(JSON.stringify(error));
app.logger.error(`[-- exception --]: ${error}`);
app.logger.error(`[-- exception --]: ${status} ${message} ${detail}`);
// 对找不到的页面进行重定向
if (message && message.indexOf("template not found") > -1) {
// 页面临时重定向
ctx.status = 302;
ctx.redirect(`${app.options?.homePage}`);
return;
}
const resBody = {
success: false,
code: 50000,
message: "网络异常 请稍后重试",
};
ctx.status = 200;
ctx.body = resBody;
}
};
};使用示例
javascript
// 在其他地方使用加载的中间件
app.use(app.middlewares.errorHandler);
// 或者在路由中使用特定的中间件
router.get('/api/users', app.middlewares.auth, userController.getUsers);7. 总结
本文介绍了基于Node.js实现的BFF微服务内核引擎的设计与实现。主要特点包括:
- 约定优于配置:采用统一的目录结构和命名规范,减少配置复杂度
- 洋葱圈中间件模型:提供强大而灵活的请求处理能力
- 模块化加载机制:通过loader自动发现和加载应用组件
- 微服务聚合能力:为前端提供统一的数据服务接口
通过这套BFF框架,我们可以快速构建高性能、易维护的前端服务层,有效解决微服务架构下前后端协作的痛点问题。
如果你觉得这篇文章对你有帮助,欢迎点赞收藏,也欢迎在评论区分享你的想法和经验!
学习资源:抖音-哲玄前端 大全栈实践课