Fast and Accurate Gigapixel Pathological Image Classification with Hierarchical Distillation Multi-Instance Learning
应用领域
计算病理
研究现状
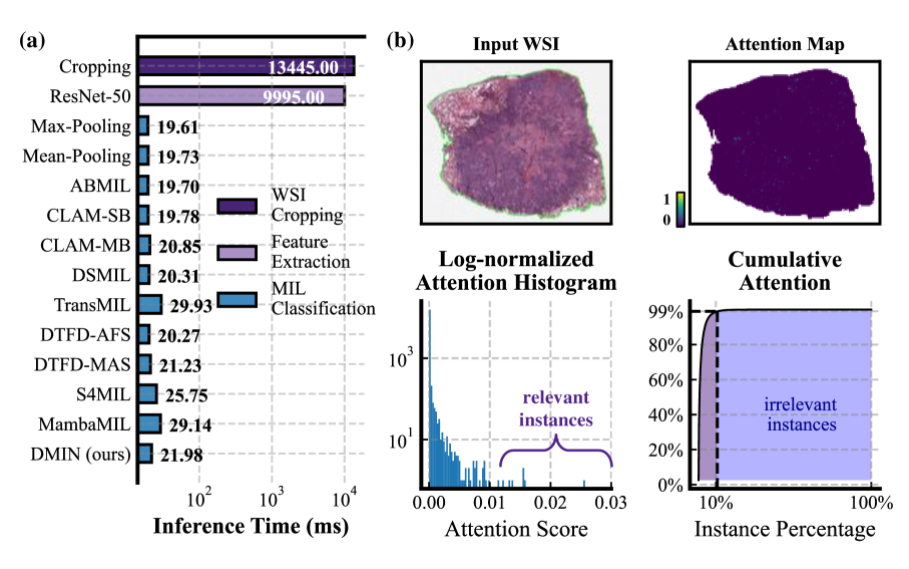
在模型推理中,WSI的裁剪和特征提取占据主要时间消耗,可见数据预处理(裁剪和特征提取)是主要的速度瓶颈。
另外,许多实例的注意力分数极低,对bag级别的分类贡献最小,可以看做是冗余的不相关的patch。
计算注意力分数,需要提取所有patch的特征。
SMT:采用级联视觉转换器 (ViT) 块来逐步搜索"可疑"区域,并最终仅使用整个 WSI 的一小部分区域进行分类。 SMT的分类性能在很大程度上依赖于准确识别潜在的肿瘤区域。 然而,作为SMT初始输入的低分辨率缩略图提供的病理信息不足,容易导致不适当的感兴趣区域被聚焦。 因此,与其他非加速MIL方法相比,错误的累积导致SMT的分类性能较差。Hundredfold Accelerating for Pathological Images Diagnosis and Prognosis through Self-reform Critical Region Focusing
MIL:用于 WSI 分类的 MIL 可分为两类:基于实例和基于嵌入。
基于实例:首先对每个实例进行分类,然后使用 Max-Pooling、Mean-Pooling 或其他预定义的池化作聚合预测,以生成最终的袋级预测。
基于嵌入:使用网络评估每个实例的重要性,并相应地对所有实例进行加权,从而生成用于分类的袋级表示。 对于基于嵌入的方法,观察到每个WSI中的不同实例对袋级表示有不同的贡献。
动态神经网络:可以根据输入数据动态调整其架构,从而自适应地控制计算冗余。
在ViT的研究中,许多研究都是通过减少toekn冗余来提高推理效率。可以利用动态网络减少实例和加快推理速度来弥合计算病理学的差距。
**Kolmogorov-Arnold Networks:**大多数以前的研究在 KAN 之前利用原有的2层结构,探索了基于柯尔莫哥洛夫-阿诺德表示定理构建神经网络的可能性。 KAN 将该定理扩展到任意宽度和深度的网络,探索其作为"人工智能+科学"基本模型的潜力。 随后的研究主要集中在改进 KAN 与各种任务的集成或修改其架构。
解决问题
如何快速识别出不相关的patch,从而实现快速准确的分类?
如何将基于切比雪夫多项式的柯尔莫哥洛夫-阿诺德分类器并将其应用于计算病理学?
如何解决要想计算冗余patch的注意力分数,就需要先提取其特征的问题?
方法论
研究理论
动态多实例网络(应用于高分辨率图像)
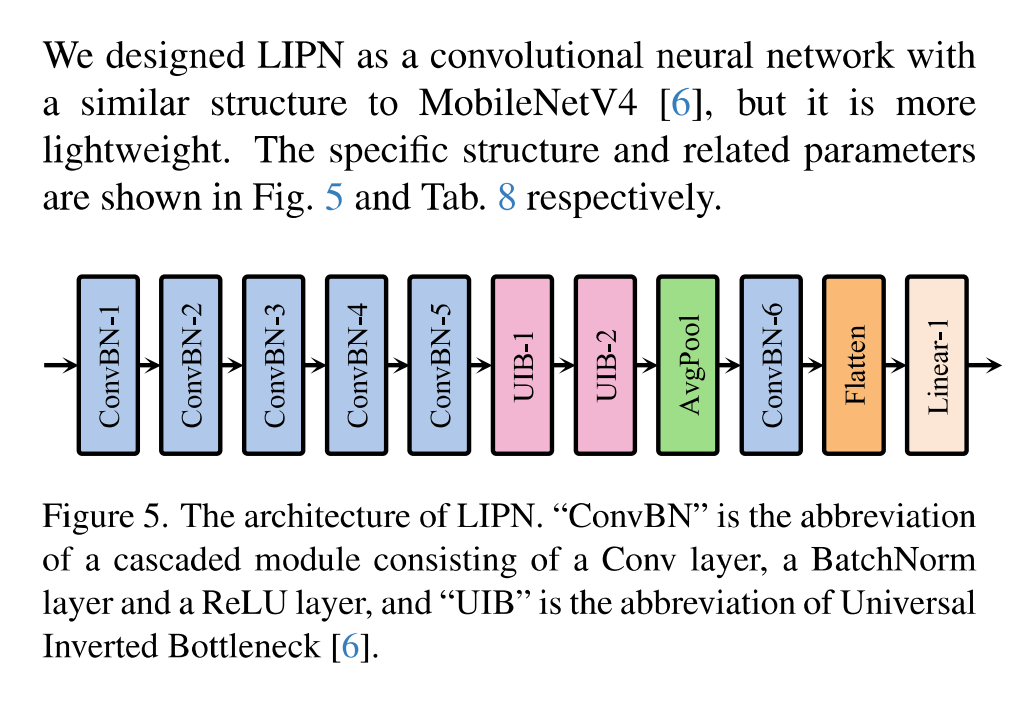
轻量级实例预筛选网络(应用于低分辨率图像)
在训练过程中,利用从高分辨率 WSI 中所有裁剪的补丁中提取的实例级特征来训练具有自蒸馏策略的动态多实例网络 (DMIN)。 这种自蒸馏策略约束了DMIN中分别使用全部实例和部分实例进行分类的教师和学生分支,以获得一致的结果,从而使学生分支选择的实例不无关紧要。 之后,我们可以根据实例是否被认为与幻灯片分类相关,为每个实例获取一个二进制掩码。 然后利用掩码来指导轻量级实例预筛选网络(LIPN)的训练,该网络学习识别相应低分辨率WSI中每个补丁的二进制相关性。
在测试过程中,在LIPN指示不相关的低分辨率补丁后,我们可以确定可以跳过哪些高分辨率补丁,从而节省推理时间。
进一步设计了计算病理学中第一个基于切比雪夫多项式的柯尔莫哥洛夫-阿诺德分类器,它通过可学习的激活层增强了HDMIL的性能。
模型架构
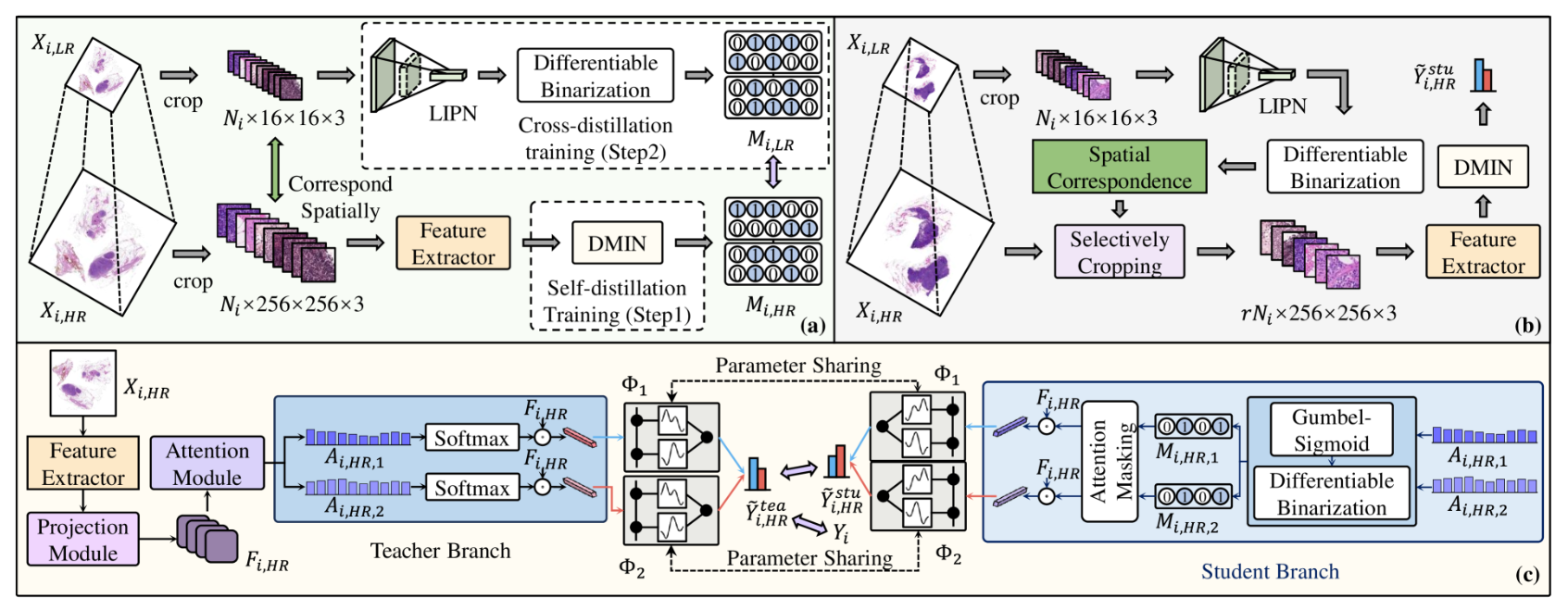
(a)LIPN的交叉蒸馏训练
在训练阶段,首先采用自蒸馏训练策略,在高分辨率WSI上训练DMIN,进行袋级分类和指示不相关区域。 在训练有素的DMIN的指导下,我们进行交叉蒸馏训练,使用低分辨率WSI得到LIPN,以极低的计算成本实现对每个区域的二元重要性(重要与否)的区分。
尽管DMIN可以成功识别WSI中不相关的区域,但并没有提高推理速度,因为它仍然提取了所有patch的特征,而这实际上才是WSI推理速度的瓶颈。
研究中使用DMIN来提炼LIPN,这是一个专门为低分辨率WSI定制的轻量级实例筛选网路,经过训练后LIPN可以快速识别低分辨率中WSI中的不相关区域。
具体的,将低分辨率的patch,Xilr直接输入LIPN,生成对于两个类别的双分支预测矩阵P。由于低分辨率patch包含的信息相对较少,因此不需要像DMIN那样具体了解每个patch对bag级分类的具体贡献分数。相反,LIPN更容易了解每个patch是否有助于bag级分类,(这个公式怎么理解)
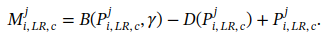
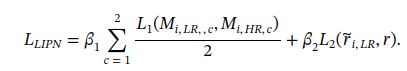
L2用来约束相关patch的比例。L1表示1范数损失函数,研究采用了在ImageNet上预训练的广泛使用的ResNet50作为特征提取器,并使用了MobileNetV4的轻量级辩题。
(b)
在推理阶段,LIPN依靠低分辨率WSI快速识别与分类无关的区域,并丢弃高分辨率WSI中的相应补丁。 随后,将剩余的补丁输入到特征提取器和 DMIN 中以生成分类结果。
(c)DMIN的自蒸馏训练
DMIN旨在对高分辨率WSI进行分类,并识别与bag分类无关的实例。包括投影模块、注意力模块、教师分支、学生分支和CKA分类器五个模块。
投影和注意力模块: 训练期间,从高分辨率WSI中提取所有的patch,Xihr,输入到预训练的特征提取魔铠中生成一组实例级特征,随后通过投影模块进行降维(这个投影模块是如何实现降维的,有具体结构吗),产生的新的特征集Fihr,缩减后的特征维度为Q。降维特征再输入到注意力模块以计算未归一化的注意力分数:
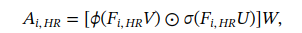
ϕ(⋅) 表示tanh函数,σ(⋅)表示sigmoid函数,权重矩阵U,V和W 是可以学习的参数,这里的注意力模块使用的是CLAM中的双分支注意力网络。第一类和第二类对应的注意力矩阵不是一样的(为什么,计算方式是一样的吗)。
教师分支: 降维后的特征通过每个类别的注意力矩阵进行线性加权,生成bag级的特征表示,用于最终分类:
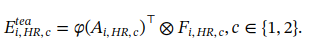
φ(⋅) 表示softmax函数,(这里的E脚标需要详细解释)
学生分支和自蒸馏模型(这个自蒸馏体现在哪里): 学生分支旨在仅使用具有较大注意力分数的实例子集来计算bag级表示,施加约束以确保学生分支中的包级表示与使用所有实例在教师分支中获得的表示尽可能保持一致。通过这种方式,鼓励注意力模块更多的关注对bag级分类很重要的实例,过滤掉不相关的实例。
训练时如果只使用高注意力实例,本质上是离散选择,这样会导致不可导、梯度断掉、无法实现端到端的训练。采用Gumbel-sigmoid+直通估计的可微二值化来解决这个问题。
用Gumbel-sigmoid让硬选择软化微可微概率:
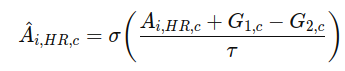
通过把每个实例的注意力分数变成∈(0,1)的选择概率,并且是可导的。其中温度τ控制A的平滑程度。
可微二值化:
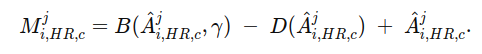
这里B是硬阈值,a>γ就输出1,否则输出0,仅用于前向传播;
-D+A:实现直通估计,前向时,两项数值相互抵消,整体仍等于B,反向时,D不传梯度,A传递A的梯度,等价于用A的软阈值替代硬阈值。
这样做的目的在于,先把是否选中变成可微的概率,再把概率变成真正0/1的掩膜M,表示哪些实例是被选中的。
此外,研究还提出一种注意力掩蔽机制,来消除掩码值为0(上述提到的掩码用来表示是否被选中的实例)的实例对bag级表示的影响:
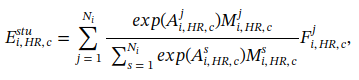
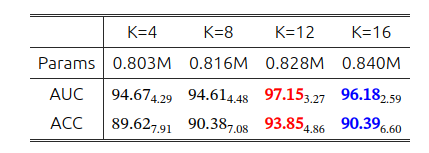
CKA分类器:为了增强MIL分类器的能力,我们建议使用Kolmogorov-Arnold网络来学习非线性激活函数,而不是在分类器中使用固定的激活函数。
基函数表示:
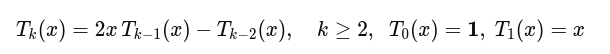
把原始特征映射到一个可控阶数 KKK 的多项式特征空间,提供比线性层/固定激活更强的可学习非线性容量。
分类器的预测:
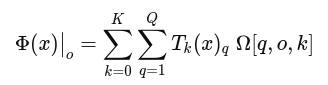
相较 FC/MLP,这里把非线性放进了"基展开",参数可控、表达力强且稳定。其中O表示预测结果的维度,研究使用的是双分支注意力模块,因此会单独计算两个分支的预测结果,O等于1,Ω表示可学习系数张量。
教师分支和学生分支的预测:

让双分支注意力 各自学习、各自判别,再在输出层融合;教师与学生对应分支的输出用于蒸馏对齐。
混合损失函数:DMIN的三个训练目标------教师分支能正确分类;学生分支和教师分支的分类结果一致;选择实例的比例要可控。
通过一个交叉熵损失确保教师分支的准确分类:
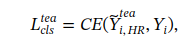
接下来,通过知识蒸馏越苏学生分支中的bag级表示和分类:
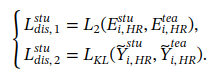
L2和Lkl分别表示2范数和KL发散损失函数。
最后,约束学习到的相关实例的比例接近预设的保留率r:
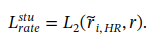
最后得出总的损失函数:
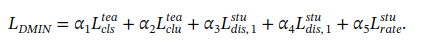
对于不同项的损失函数,没有使用超参数搜索,而是根据CLAM和DynamicViT的经验值设定。
实验设计及结果
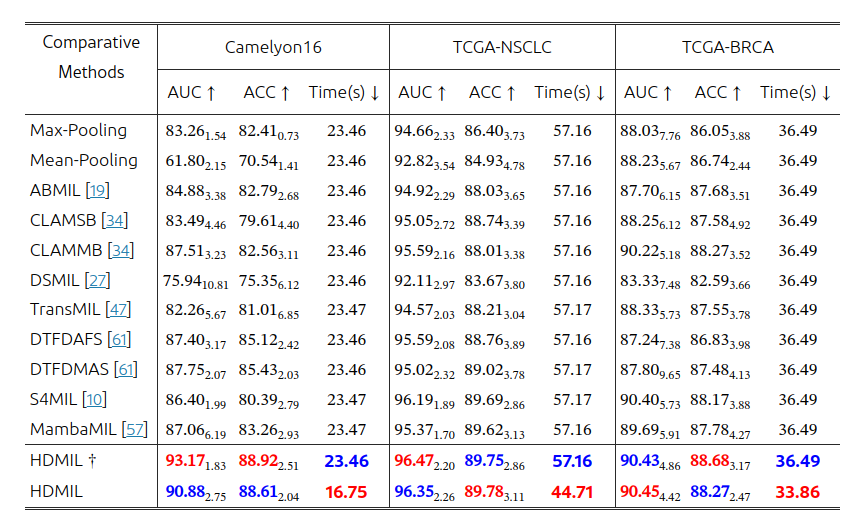
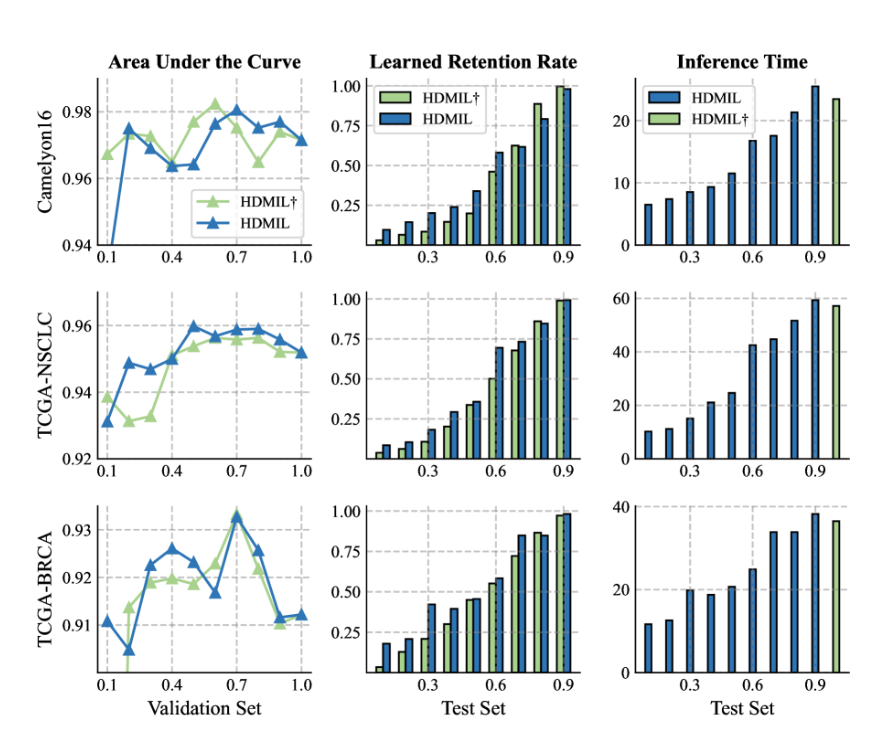
HDMIL与最先进的MIL方法对三个数据集的比较,加标记的HDMIL表示仅使用DMIN进行推理:
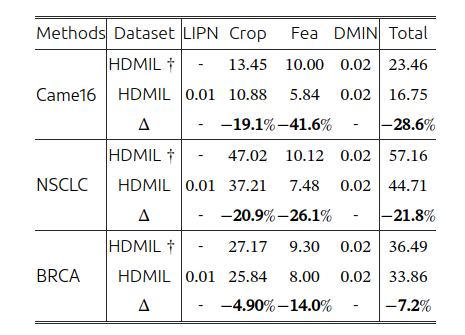
HDMIL在各个阶段所需时间,包括实例筛选、裁剪、特征提取、bag分类:
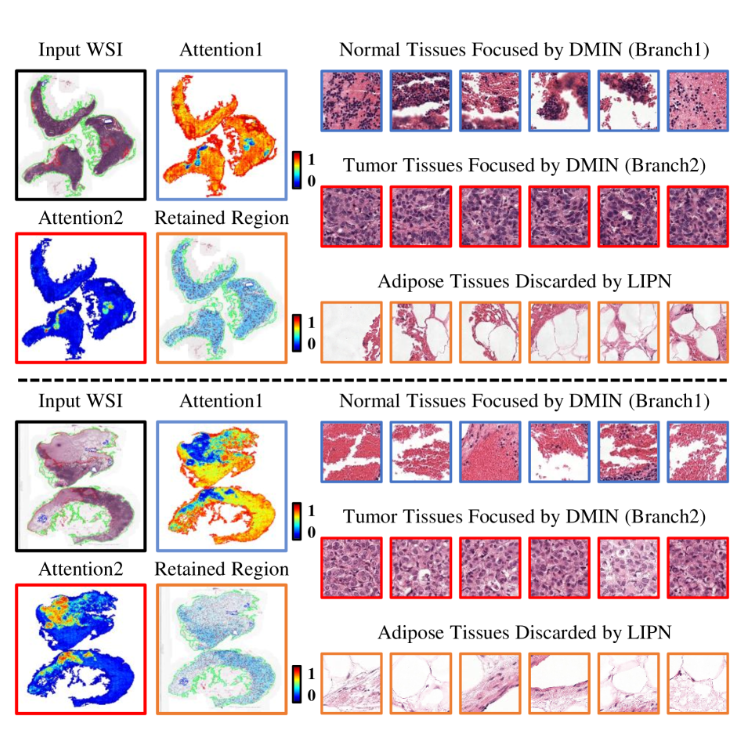
可视化分析,红色表示肿瘤区域,蓝色表示掩码区域(保留用以分析的区域):
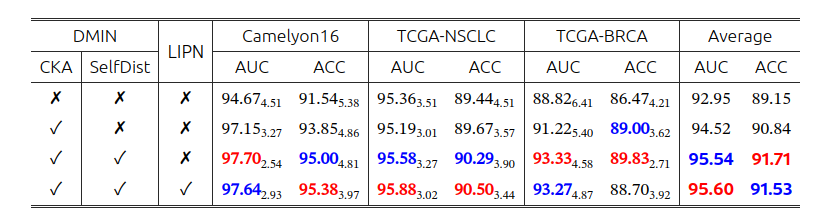
模型各组件对性能的影响(SelfDist是自蒸馏):
CKA层位置的比较
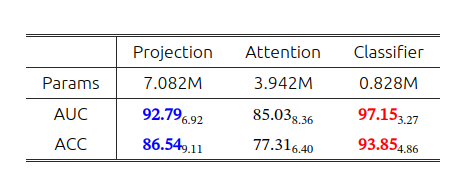
不同分类器的比较:
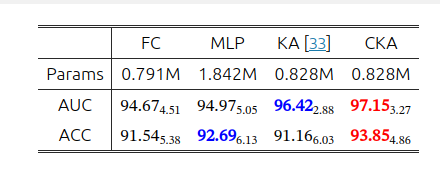
CKA层不同阶数的比较:
自蒸馏通过强制注意力模块关注关键实例来增强分类性能,从而减少不相关区域的影响。这可以看作是一种"去噪"。 为了验证这一观点,通过考虑三种类型的实例来代表每个bag,评估了自蒸馏"去噪"效果后的bag质量:每个WSI内的所有实例、训练的DMIN选择的实例和随机采样的实例:

两种蒸馏方式,一种是让LIPN去回归DMIN注意力分数,得到低分的预测分数;另一种训练LIPN直接预测自己的二值掩膜去对齐高分辨率的。使用不同蒸馏方法时,HDMIL在验证集上的性能**:**
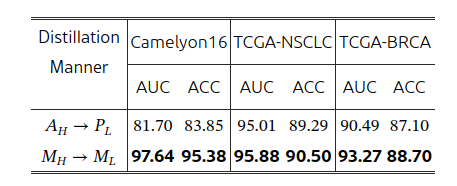
总结就是,只学 "留还是删" 的二分类,对低分辨率来说更容易、更稳。
预设实例留存率的影响:
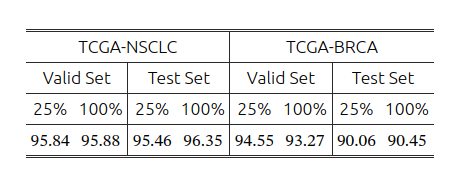
数据集大小的影响:
蒸馏(Knowledge Distillation)是把一个更强的模型学到的"经验"传给另一个模型的训练方法。常见是老师---学生模式:
老师(teacher):性能更好、通常更大,先学会任务。
学生(student) :更小更快,在训练时不仅对真标签学习,还模仿老师的输出或中间特征。