0. 简介
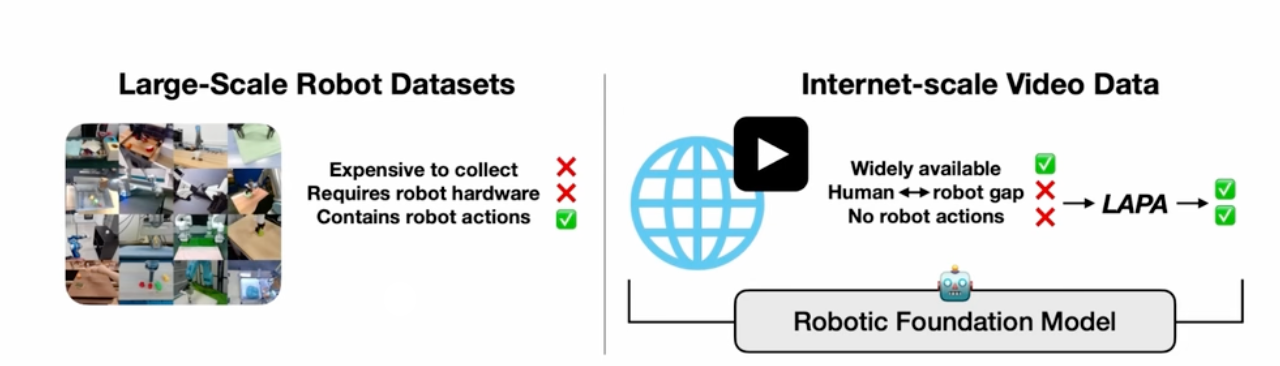
对于数据来说有很多类似OXE、Bridge、DROID的公开数据,但是这个相较于网络上视频来说其实是数量级很低的,而怎么样借助大量的互联网视频来进行学习,并学出一些范式还是非常有意思的一件事情。基本上技术都是比较通用,或者说大框架基本类似,但是这个发力方向还是非常值得关注的。下面是两个对比,相较于左边昂贵的数据,右边的操作其实还是挺有意义的,只需要我们能够解决人类和机器人之间的gap,并想办法获取机器人行为姿态即可。
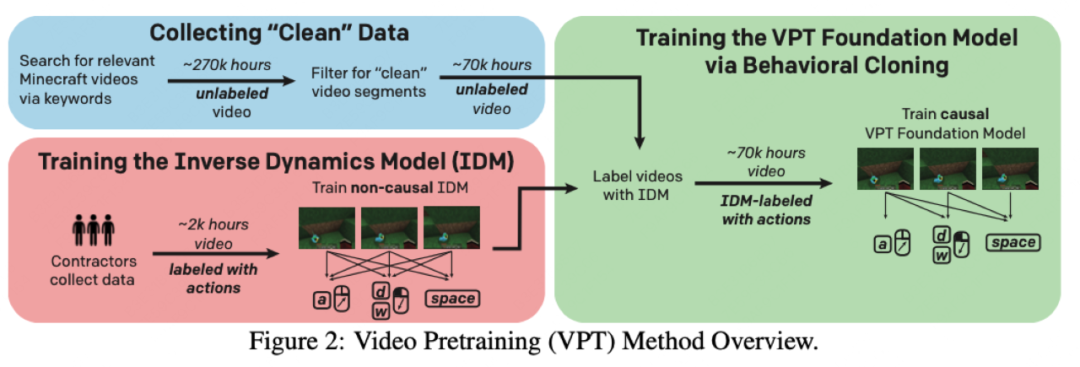
比如说OPENAI的VPT,就是去学一个classifier,把对应的action给解析出来。只能说OpenAI把这套范式玩明白了,训什么都用这个思路。但其中有个难点,就是预训练的时候视频数据没有自监督信号,因为模型要输出的是动作,而不是下一个画面。于是他们想了一个简单粗暴的解决办法,就是先让标注人员去玩游戏,记录他们的游戏画面和对应的动作(键盘、鼠标),再用这批数据训练一个模型(Inverse Dynamics Model),去给所有的视频数据预测出标签。这样就可以进行自回归视频预训练了。预训练的数据量是70k小时的视频,大概5B的token,模型参数量在0.5B。
1. latent action 是什么
latent action一般定义为:一种用于区分高性能和低性能区域的边界,下面给出了两个例子。
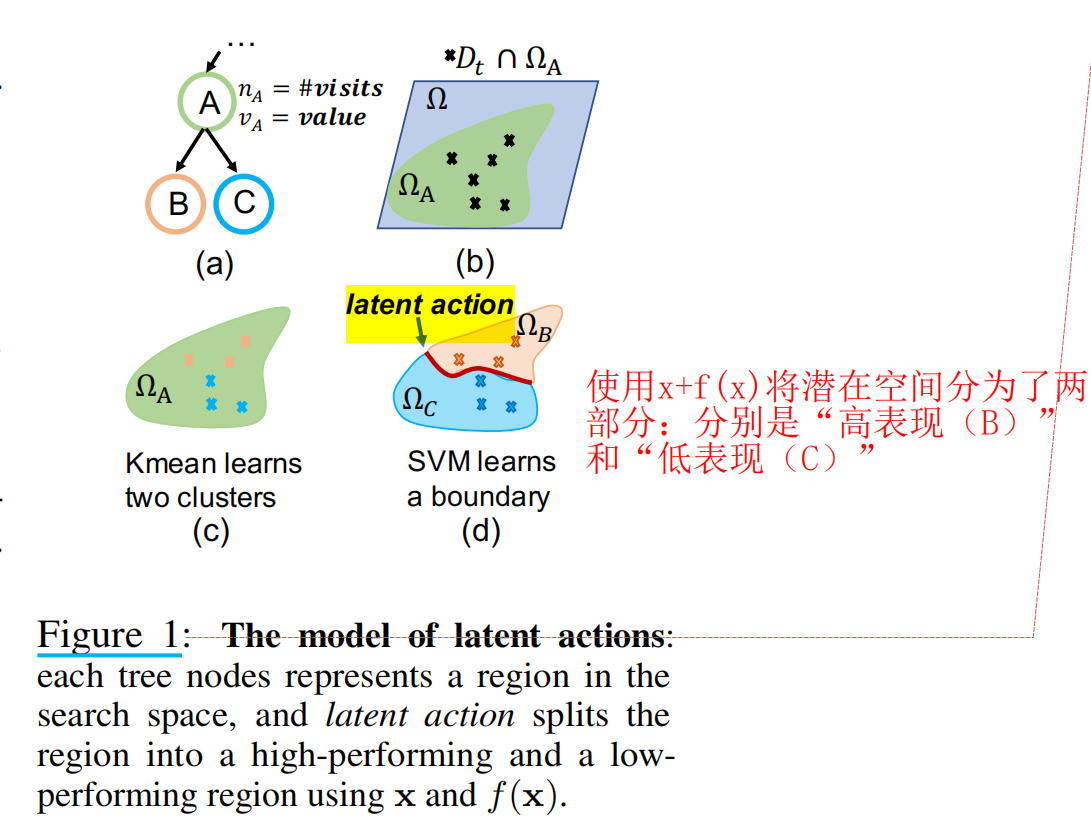
这里的latent action代表一个边界(分类器),用于将好的采样和差的采样划分开来,这里使用的划分边界的方式是:先使用Kmeans在特征向量上( x, f(x) )聚类,然后使用SVM划分出边界
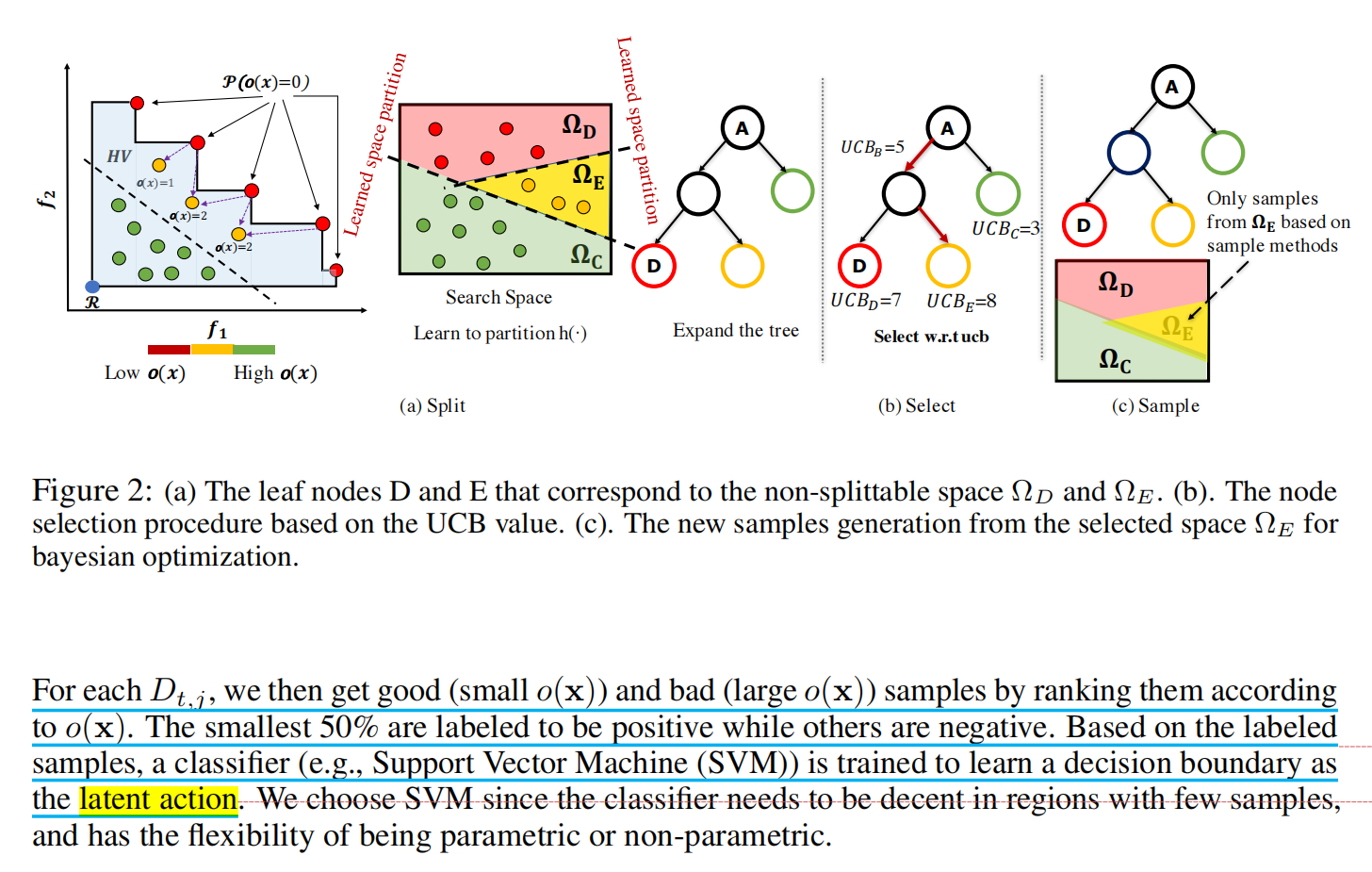
这里使用的划分边界的方式是:对于区域中的元素 D t , j D_{t,j} Dt,j,通过它们的支配数量进行rank,小的支配数量的元素(意味着是更好的性质)被label成positive,大的被label成negative,然后使用SVM划分出边界
2. 自监督Latent Action
相较于VPT而言,怎么样去更加通用一点,即不尝试去标action。这里我们可以利用自监督等方法来做。其实这里主要分为三步:
1、latent action量化作为第一部分,这里最核心的就是一个VQ-VAE的模块。通过一个 t t t时刻的图像帧和 t + h t+h t+h时刻的一个图像帧。然后将这两个作为输入,并通过自监督方法来告诉我这两个之间发生了什么样的行为。这个行为是一个大概行为,类似聚类的操作,相似的行为归结为一类。
编码部分是一个C-ViVit,把输入的两张图片构造成离散的embedding进行输出。这个时候就是一些离散的数据了,我们会提一个representation,这个离散的表达,这个decoder拿到了第一帧信息,以及对应的latent action,然后解算出第二帧的图像来。可以用 t + h t+h t+h时刻的一个图像帧和输出的decoder做loss完成自回归训练。
C-ViVit是ViViT的一个变种,它采用了条件处理机制,这意味着模型在处理视频数据时能够考虑前一帧或一系列帧的条件信息。这种模型特别关注于如何在时间维度上有效地整合信息,以便更好地理解视频内容的连续性和变化。C-ViViT通过使用条件或因果注意力机制,允许模型在预测当前帧时只考虑之前的帧,这有助于模型捕捉视频中的动态变化,并提高视频处理的效率和效果。
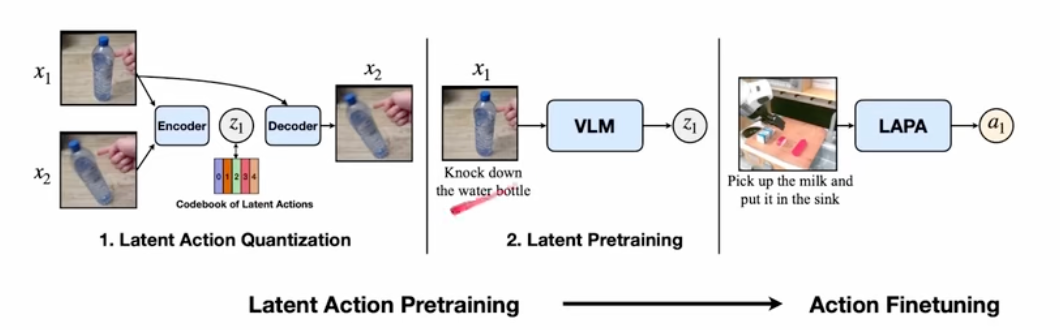
2、latent预训练:这一步是在我拿到了latent action 并且我希望去训练一个Policy,让这个VLM能够掌握到因果。就是希望我给出图片和文本,然后输出latent action,来让大模型理解我期望的行为。这里的大模型也最后不是词表了,这里我们会变成一个全联接层来使用。
这里我们针对VLM,会把视觉部分冻结,只去调语言模型和全链接层。去尝试拟合到假的VQ标签上。
3、最后就是行为微调,这里就会换成真正的机器人数据,然后去进行微调。这就是相信在第二部已经学习到知识了,只是把最后的全链接层换成和行为词典大小一致的head就行了。
3. LAPA微调手册
LAPA 是一种无监督的方法,用于对视觉-语言-行动(VLA)模型进行预训练,无需真实的机器人行动标签。该方法在多个方面表现出色,超越了当前基于真实行动训练的最先进 VLA 模型,建立了新的 SOTA VLA 模型。此外,LAPA 的预训练效率比传统 VLA 预训练高出超过 30 倍。
3.1 潜在动作量化
我们提供了潜在动作量化预训练的代码:
-
创建并激活一个新的 Conda 环境:
shconda create -n laq python=3.10 -y conda activate laq -
进入 laq 目录并安装:
shcd laq pip install -e . -
启动训练:
shaccelerate launch train_sthv2.py
请注意,当前数据加载代码基于 something-something v2 数据集结构,目录包含多个轨迹,每个轨迹包含多张图像。要在自定义数据集上训练,请更改数据结构或修改现有数据加载代码。
训练后,可以使用训练的量化模型作为逆动力学模型,以获得训练数据的潜在动作:
sh
python inference_sthv2.py根据训练参数添加参数。对于 input_file 参数,应该是一个包含 id、image、instruction 键作为元数据的 jsonl 文件,vision 是由 vqgan 模型输出的 256 个离散图像标记的输出。
3.2 潜在预训练
我们提供了从预训练的 LWM 检查点进行潜在预训练的代码。首先,在 lwm_checkpoints 目录下下载 LWM-Chat-1M-Jax 模型。然后,从此链接下载预训练数据集,放在数据目录下。运行以下命令进行潜在预训练:
sh
./scripts/latent_pretrain_openx.sh我们在 8 个 H100 GPU 上进行了 34 小时的实验。我们经验性地观察到,70K 步和批量大小为 256 即可在微调后在下游任务上获得良好性能。
3.3 开始使用 LAPA
要开始使用 LAPA,请按照以下步骤进行设置:
-
创建和激活 Conda 环境:
shconda create -n lapa python=3.10 -y conda activate lapa -
克隆 LAPA 仓库并安装依赖:
shgit clone https://github.com/LatentActionPretraining/LAPA.git pip install -r requirements.txt -
创建检查点目录并下载模型检查点:
shmkdir lapa_checkpoints && cd lapa_checkpoints wget https://huggingface.co/latent-action-pretraining/LAPA-7B-openx/resolve/main/tokenizer.model wget https://huggingface.co/latent-action-pretraining/LAPA-7B-openx/resolve/main/vqgan wget https://huggingface.co/latent-action-pretraining/LAPA-7B-openx/resolve/main/params -
运行 LAPA 检查点以进行推理:
shcd .. python -m latent_pretraining.inference
该命令将生成基于输入图像和自然语言指令的潜在动作。注意,输出空间为潜在动作空间(大小为 8x4),而非真实动作空间。要评估 LAPA,需要进行微调以将潜在空间映射到真实动作空间(例如,末端执行器)。
3.4 微调 LAPA
要在真实世界轨迹上微调 LAPA,首先需要预处理数据集以离散化动作空间。假设有一个包含以下格式的 JSON 文件(--input_path):
json
{
"id": "data/finetune_data/episode_0/step_0",
"image": "data/finetune_data/episode_0/step_0.jpg",
"conversations": [
{
"from": "human",
"value": "<image>\nWhat action should the robot take to `pick up the milk and put it in the sink`"
},
{
"from": "gpt",
"raw_actions": [
0.0004934221506118809,
-0.00011252239346504211,
-0.001941084861755371,
0.013634951062806884,
0.013678191591275368,
-0.004913635449167675,
0.0
],
"states": {
"eef_pos": [
0.24725835025310516,
-0.022094586864113808,
0.9283081889152527
],
"eef_euler": [
3.1202197128587876,
-0.7113159765223936,
-0.10937155062330725
],
"gripper_state": 0.0
}
}
]
}运行以下命令以预处理微调数据集并微调 LAPA:
sh
python data/finetune_preprocess.py --input_path "/path_to_json_file" --output_filename "data/real_finetune.jsonl" --csv_filename "data/real_finetune.csv"
./scripts/finetune_real.sh我们在 4 个 80GB-A100 GPU 上进行了实验。要更改使用的 GPU 数量,请在脚本中将 --mesh_dim 的第二个索引更改为 GPU 数量。