近年来,增量视图维护(Incremental View Maintenance, IVM) 成为了数据系统领域备受关注的话题。无论是在数据库、数据仓库,还是在前端同步引擎中,越来越多的系统开始尝试支持以更高效的方式维护物化视图。比如,ClickHouse 在数据仓库层面提供了 IVM 支持,dbt 也引入了增量模型机制(尽管仍基于批处理);在 PostgreSQL 生态中,pg_ivm 等扩展也正在探索增量视图的原生实现。
与此同时,也有一部分平台正在尝试将 IVM 能力更实用化、工程化地融入到日常的数据集成和服务化场景中。TapData 就是其中之一,它通过对源库变更日志(CDC)的实时捕获与处理,结合 MongoDB 等灵活的数据引擎,实现了对跨库、跨表、跨系统数据的低延迟聚合与增量视图维护。通过可视化的构建器与 SQL 支持,TapData 将这一能力封装在易于使用的平台能力之中,广泛用于 API 服务、实时报表、主数据同步等业务场景。
本文将简要介绍什么是增量视图维护,为何重要,以及可以如何实现。
什么是增量物化视图维护(IVM)?
想要搞懂增量视图维护(IVM, Incremental View Maintenance) ,我们首先需要理解什么是"视图"。在这里,视图是以特定方式对数据的投影。比如数据透视表就是一种视图:你有一个包含原始数据的电子表格,通过创建数据透视表来对原始表格中的数据进行筛选和聚合。同样地,数据库中的表可以被看作是电子表格,而数据库视图则类似于数据透视表。不同的是,数据库中的视图是通过 SQL 定义的,而不是像 Excel 或 Google Sheets 那样通过图形化界面操作。
继续使用数据透视表的类比:当用户更新了电子表格中的数据,数据透视表也需要进行更新,以反映其筛选和聚合结果的变化。数据库表和视图之间的关系也是如此。
视图的更新方式有多种,其中最简单的一种是:每次访问视图时都重新执行查询。这就像在 Excel 中,每次打开数据透视表时,系统都会重新读取并计算源数据;数据库中的视图也遵循类似的机制。
但如果每次查询都刷新视图,对于大规模数据集来说,这种方式会非常缓慢且成本高昂。例如,包含数百万行的电子表格可能会导致用户卡顿数秒;而一个包含数十亿甚至数万亿行数据的数据库,其查询延迟可能更为严重。因此,一种替代方式是使用物化视图(Materialized View)。物化视图是查询结果的缓存版本。相比每次读取时都重新计算视图,物化视图采用定期刷新。一旦刷新过程完成,用户查询的就是最新版本的缓存结果。
这种方式------定期重算整个数据集------在降低读取延迟的同时,也牺牲了一定的数据实时性。由于数据已经预计算完成,查询的速度会更快;但查询结果只能反映上一次刷新的数据状态。此外,重新处理整个数据集的过程本身也存在浪费。例如,源数据中只修改了一行,系统却需要对所有数据重新处理,以生成新的物化视图。比如一个简单的 SELECT COUNT(*) 查询,也需要重新统计所有行,仅仅是因为插入了一条新记录。
这正是增量视图维护要解决的问题。与每次变更都重算整个数据集不同,IVM 仅重新处理受影响的部分数据(即变更增量 delta)。这种方式极大地降低了维护物化视图的成本。《DBSP》论文对此提供了很好的解释:
粗略来看,我们的算法生成的增量查询 QΔ,相比每次全量执行原始查询 Q,速度可以快出一个量级,其复杂度大致为 O(|DB| / |ΔDB|)。实际效果往往更加显著。放到示例里,假设源数据量 |DB| 约为 10⁹,而变更量 |ΔDB| 仅为 10²------也就是说,增量查询比原始查询快了一千万倍。
更新成本的大幅下降,使我们可以更频繁地刷新物化视图,从而使其与源数据的同步程度更高,降低数据延迟。更重要的是,查询延迟几乎不会受到影响,因为查询仍然是针对预计算好的数据进行的。
增量视图维护引擎是如何工作的?
了解了什么是增量视图维护(IVM)之后,我们接下来探讨它在历史上的实现方式。这主要涉及两个核心问题:
-
增量更新是在什么时候发生的?
-
系统如何知道哪些数据需要更新?
第一个问题的答案相对直接:增量物化视图本质上也是一种计算,因此它们可以按计划周期性运行、按需执行,或由某种"触发机制"驱动。在实际应用中,最常见的方式是使用触发器来监控新增或变更的数据。
在数据仓库场景中,像 Airflow 的 Trigger 和 Sensor 就被用于检测数据的变化;而在 OLTP 数据库中,开发者可以为源表定义触发器,使得每当表数据发生变更时,对应的视图自动更新。部分原生支持 IVM 的 OLTP 数据库也会在底层自动完成这种视图的同步更新。而在流处理系统中,这一机制则表现为:随着新事件的到来,系统的状态会实时更新。
第二个问题------系统如何知道需要更新哪些数据------则更为复杂。
最直观的方法,是针对触发器写相应的逻辑代码或临时查询来更新数据。例如,我们有一个 orders 订单表和一个 customer_order_totals 的汇总视图,那么我们可以通过如下触发器函数,每当有新订单插入时,自动更新汇总视图:
sql
CREATE OR REPLACE FUNCTION orders_insert_trigger_fn()
RETURNS TRIGGER AS $$
BEGIN
INSERT INTO customer_order_totals (customer_id, total_amount)
VALUES (NEW.customer_id, NEW.amount)
ON CONFLICT (customer_id)
DO UPDATE SET total_amount = customer_order_totals.total_amount + EXCLUDED.total_amount;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;这种触发器或临时代码的方式适用于简单场景。但一旦涉及复杂的增量逻辑,例如多表连接(JOIN)、窗口函数、递归算法等,就会变得难以手动编写和维护。此时,我们就需要一种更加系统化的方法。
目前许多数据库采用的系统方法是基于 Bag Algebra(集合代数)。用户首先用标准 SQL 定义一个需要增量维护的物化视图,然后数据库系统会将该 SQL 查询转换成一组关系代数操作(如选择 SELECT、投影 PROJECT、并集 UNION、交集 INTERSECT、连接 JOIN、差集 DIFFERENCE 等)。在转换为关系代数表达式后,数学上可以证明:只要提供源表中新增或删除的部分(称为增量 delta),系统就可以计算出这部分变更对视图应产生的具体影响。
如果你想进一步了解,这方面 PostgreSQL 的 IVM Wiki 页面 是个很好的起点。
听起来问题已经解决了,对吧?开发者仍可以用熟悉的 SQL 定义视图,而数据库引擎通过复杂的数学模型,仅对变更的部分(而非整个数据集)进行处理,实现高效的增量更新。
但现实却没那么理想。事实证明,Bag Algebra 在处理复杂查询时并不高效,尤其是递归结构或多层嵌套查询。在提高表达能力和用户便利性的同时,IVM 本身的计算代价也被显著拉高,失去了原本"低成本"更新的优势。
现代数据库系统的底层探索:重构增量视图维护引擎
这也引出了本文开头提到的三篇关键论文:《Naiad: a timely dataflow system》、《Differential Dataflow》以及《DBSP: Incremental Computation on Streams and Its Applications to Databases》。这些论文共同构建了一种与传统方式截然不同的 IVM 实现路径,它具备以下特性:
-
足够快速,可以在每次数据变更时都更新物化视图
-
足够具表现力,允许开发者使用 SQL 或 Datalog 等查询语言定义视图
-
足够灵活,可用于流处理系统,也可集成在数据库之中
该领域的代表人物 Frank McSherry 将这些新技术描述为一组"具有不同灵活度与设计约束的工具集"。其中:
-
最底层、最灵活的是 Timely Dataflow;
-
构建在其之上的 Differential Dataflow 引入了一些约束,以支持可计算的增量更新;
-
DBSP 再进一步增加约束,以换取更简洁的实现方式。
接下来我们逐一来看这三个系统之间是如何逐层构建的。
Timely Dataflow:为增量计算引入"时间"
Timely Dataflow 的关键贡献,是它为增量计算建立了一种强大且可扩展的"时间模型",在不损失表达能力的前提下,使 IVM 的计算变得更容易管理。在这个模型中,时间被表示为一个向量,其中既包含"Epoch"(时间周期),也包含"Loop Counter"(循环计数器)。
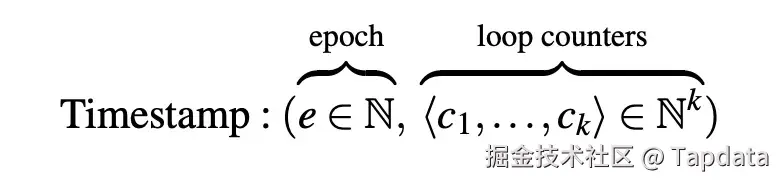
来自论文《Naiad: a timely dataflow system》第 2.1 节
顾名思义,循环计数器用于追踪某个事件当前处于第几次迭代。虽然这背后的具体原理比较复杂(详见论文),但这种机制使得 Timely Dataflow 可以非常自然地支持深层次的嵌套循环计算,尤其适用于图计算等场景,该论文大量篇幅正是用于探讨此类应用。
Timely Dataflow 的另一个创新点,是它对"时间推进"的处理方式。传统的数据流系统中,时间的推进通常通过特殊事件(如"Punctuation"标记)内嵌在数据流中,这种做法会导致所有算子必须顺序接力式地推进时间,从而形成瓶颈。
而 Timely Dataflow 使用了"Out-of-Band Watermarks"。听起来很复杂,其实它的核心思想就是将数据面与控制面分离,每个任务会独立告诉其他任务自己已处理到哪个"时间点",而不是通过数据本身来传递时间。这种全局视角使得任务可以判断是否可以推进自身的计算逻辑。
更重要的是:不同的任务可以在不同时间点、甚至多个时间点并发处理数据,这意味着整体计算流程可以并行推进,比传统基于集合代数(Bag Algebra)的处理模型更快、更具弹性。
实际上,Timely Dataflow 的 API 设计也相对简洁,仅包含四个核心方法:
-
SendBy: 发送事件 -
NotifyAt: 指定时间触发通知 -
OnRecv: 事件接收处理逻辑 -
OnNotify: 时间推进时的处理逻辑
这个接口模型让 Timely Dataflow 很容易让人联想到早期的 Hadoop Map/Reduce:功能强大,但属于较底层的通用数据处理框架。它提供的是基础构件,需要上层再封装,才能更易用地用于实际的数据库或流处理系统。
Differential Dataflow:引入"微分计算"的增量引擎
Differential Dataflow 在 Timely Dataflow 的基础上,引入了一个关键概念:微分计算(Differential Computation)。
论文中这样定义其创新点:
微分计算的创新体现在两个方面:第一,计算状态的版本不是按照传统的全序列(totally ordered sequence)组织,而是基于一个偏序集合(partially ordered set)来表示多个状态版本;第二,为了能够还原任意版本的状态,系统保留了每次更新操作的集合,并存储在可索引的数据结构中。而传统的增量系统通常会将每次更新合并到"当前版本"中,然后立即丢弃这些更新记录。
这篇论文相对艰涩,但其核心思想是:系统不是只记录一个线性的"当前状态",而是维护一整套处于偏序结构中的多个状态版本。这些状态由 Timely Dataflow 中的时间戳机制追踪和管理。
正是由于这种结构,系统能够有选择地重用之前的计算结果,在数据发生更新时极大减少了需要重新执行的计算量。
一旦"微分计算"这一核心机制定义完成,论文在第 4.3 节进一步展示了如何基于这一底层引擎,构建标准的类 SQL 运算符。这意味着,开发者可以用熟悉的高层查询语言(如 SQL 或 Datalog)来表达增量视图逻辑,而系统会自动处理底层的连接、聚合,甚至递归逻辑等复杂操作。
这种自动化能力大大降低了构建和维护复杂 IVM 系统的门槛,尤其适用于如图分析(Graph Analytics)或多层嵌套查询等高复杂度场景。
继续之前的比喻:如果说 Timely Dataflow 是类比于 Hadoop 的 MapReduce,那 Differential Dataflow 就像是 Pig 或 Cascading------在底层计算框架之上构建的表达层,更易用、更高效。
DBSP:用"数字信号处理"思维重构增量查询系统
了解过电路基础课程的朋友们应该会了解,任意一个逻辑电路都可以仅通过 NAND 门(与非门)来实现**。** 这种特性被称为函数完备性(functional completeness),NOR 门也具有这一性质。
无论是 AND、OR 还是更复杂的逻辑函数,都可以仅通过组合 NAND 门来构建。甚至,整个处理器也能只用 NAND 门实现。
之所以提起这个,是因为 DBSP 的设计灵感正是来源于数字信号处理(DSP, Digital Signal Processing)。论文作者意识到,增量视图维护在本质上与 DSP 中的"微分(Differentiation)"与"积分(Integration)"操作具有某种相似性。
正如与非门一样,DBSP 论文提出:只需四个基本算子(Lift、Delay 以及两个用于递归程序的操作符)就足以构建 SQL 中的所有关系代数操作。这四个算子就像与非门一样,构成了整个 DBSP 系统的"计算原语"。
以 Lift 操作为例,它其实就是一个 Map 函数的表达方式:

而 Delay 操作也非常直观,在论文中用符号 z⁻¹ 表示,它的作用是将输出延迟一个步骤:

利用电路设计与关系代数,论文展示了如何将任意 SQL 查询转换为 DBSP 计算电路。一旦完成这种转换,再将其进一步转化为"增量化的 DBSP 电路"。这背后揭示了一个非常有力的观点:
DBSP 能够将任意批处理风格的 SQL 查询,转化为可增量执行的查询流程。

当然,相较于 Differential Dataflow,DBSP 在设计上做出了一些取舍。它通过简化时间与状态管理机制,降低了编程模型的复杂度。这种简化也带来了一定代价:在并发性方面不如 Timely 和 Differential Dataflow 那样灵活高效。不过作为交换,DBSP 提供了一个更简单、更易上手的框架,更适合典型的数据库和流处理类工作负载。
这些引擎层的创新,为后续平台级别的实现提供了重要启发。与此同时,也有不少系统选择绕过底层重构,以更工程化、平台化的方式实现对增量视图的支持 ------ 这正是我们接下来要探讨的方向。
平台化路径:TapData 等数据系统的现实探索
尽管许多数据库系统正在尝试从引擎底层重构增量视图维护的能力,但另一条更贴近工程实践的路径也正在被越来越多数据平台采用:不重建计算引擎,而是通过平台化方式实现可配置、可扩展的增量视图维护能力。这类平台通常不直接介入 SQL 查询引擎的执行流程,而是围绕变更捕获(CDC)机制与目标端视图维护策略构建起独立的处理链路。
TapData 正是这一路径的代表之一。作为一个面向实时数据同步与服务的统一平台,TapData 通过多种增量采集方式(如日志 API、日志文件解析、字段轮询等)实时捕获源系统中的变更数据,并结合用户配置的转换逻辑、聚合规则,将结果持续写入 MongoDB 等目标数据库中,从而实现对物化视图的自动维护。相比引擎级方案,TapData 的优势在于:
-
源端兼容性强:支持主流数据库的多种 CDC 模式,包括 MySQL、PostgreSQL、Oracle、MongoDB、SQL Server 等,适应多样化生产环境;
-
构建方式灵活:支持 SQL 或可视化方式定义视图逻辑,适配不同团队角色与技术背景;
-
目标端实时写入:以 MongoDB 为主要承载引擎,结合去重、聚合、更新策略,生成结构清晰、低延迟的数据视图;
-
无需重构系统架构:平台作为旁路式部署,无需改造源库或应用逻辑。
这些能力使 TapData 能够广泛应用于实时报表加速、客户数据统一、主数据管理、实时 API 接口等业务场景中,将复杂的数据流动与计算封装为稳定、可复用的数据服务能力。
虽然路径并不一致,但它们在设计理念有着高度一致的目标:以更低的成本、更高的效率实现增量视图的自动化更新,并服务于实际业务需求。