大纲
1.Java中的SPI扩展机制
2.Dubbo如何扩展SPI机制
3.Dubbo的SPI扩展实现类的加载流程
4.Dubbo的SPI寻找Extension的流程
5.Extension实现类对象的构建过程分析
6.SPI自适应机制自动生成代码与动态编译
7.SPI自动激活机制源码分析
8.Dubbo过滤器链设计模式源码分析
9.Dubbo中各种过滤器源码分析
10.Dubbo Netty网络通信的线程模型
11.Dubbo全业务线程分发模型源码分析
12.Dubbo各种分发模型源码分析
13.Dubbo线程池模型源码分析
14.Dubbo Cluster模块源码梳理
15.Dubbo各种Router策略源码分析
16.ZooKeeper配置中心构建源码分析
17.ZooKeeper配置中心源码简析
1.Java中的SPI扩展机制
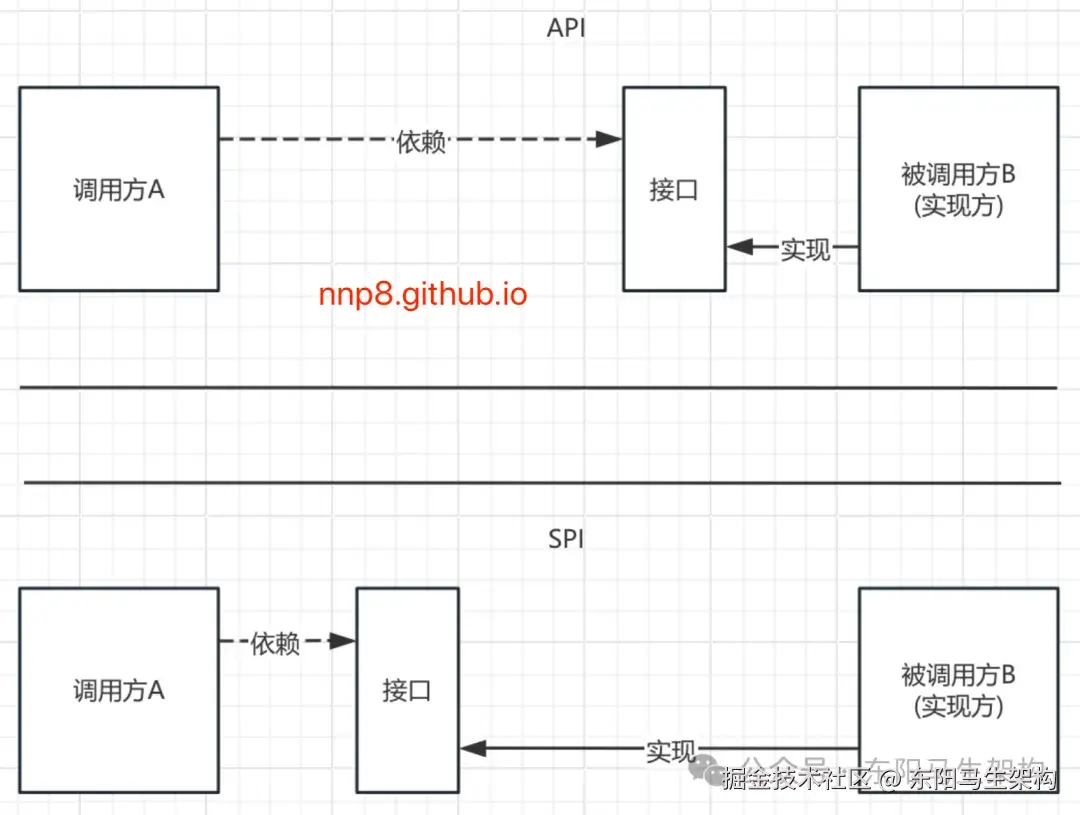
(1)SPI和API的区别
(2)JDK SPI机制的核心和入口
(3)JDK SPI核心总结
(4)Java SPI机制的缺点
SPI机制,就是把接口和具体运行时要使用的实现进行分离,在系统启动时根据配置信息,去动态识别接口的具体实现。
(1)SPI和API的区别
API(Application Programming Interface)是实现方制定接口并完成对接口的实现,调用方仅仅依赖接口调用且无权选择不同实现, 从使用人员上来说,API直接被应用开发人员使用。例如:service-provider-interface(调用方)。
SPI(Service Provider Interface)是调用方来制定接口规范提供给外部来实现,调用方在调用时则选择自己需要的外部实现,从使用人员上来说,SPI被框架扩展人员使用。例如:service-provider(提供者)。
一般模块之间都是通过接口进行通讯,我们会在服务调用方和服务提供者(实现方/被调用方)之间引入一个"接口"。当提供者提供了接口和实现,可以通过调用提供者的接口从而让调用方拥有提供者给我们提供的能力,这就是API。
在API中,接口和实现都是放在提供者的。在SPI中,接口是放在调用方这边,而实现是放在提供者这边。
(2)JDK SPI机制的核心和入口
Java的SPI机制是需要依赖ServiceLoader来实现的。ServiceLoader在加载具体的服务实现时会去扫描所有包下src目录的META-INF/services的内容,然后通过反射去生成对应的对象,保存在一个list列表里面,所以可以通过迭代或者遍历的方式得到需要的那个服务实现。
ServiceLoader是JDK提供的一个工具类, 位于"package java.util;"包下。它是一个final类型的,所以是不可被继承修改,同时它实现了Iterable接口。之所以实现了迭代器,是为了方便后续我们能够通过迭代的方式得到对应的服务实现。
ServiceLoader源码流程如下:
lua
步骤一:ServiceLoader.load(Class service)
步骤二:获取当前线程的ContextClassLoader调用重载load方法
步骤三:创建ServiceLoader对象返回
步骤四:创建LazyIterator用于扫描SPI配置文件(只有调用LazyIterator迭代器的next方法才会去反射创建实现类对象)
步骤五:获取ServiceLoader迭代器并遍历
步骤六:反射创建接口实现类对象(3)JDK SPI核心总结
SPI机制的具体实现本质上还是通过反射完成的,即我们按照规定将要暴露对外使用的具体实现类在META-INF/services/文件下声明。Java SPI的核心总结如下:
一.需要一个目录
css
a.META-INF/services
b.放到classpath下面二.目录下面放置一个配置文件
css
a.文件名是要扩展的接口全名
b.文件内部是要实现的接口实现类三.如何进行使用
scss
a.ServiceLoader.load(xxx.class)
b.ServiceLoader serviceLoader = ServiceLoader.load(Log.class)
c.serviceLoader.iterator().next()其实SPI机制在很多框架中都有应用:Spring框架的基本原理也是类似的反射,还有Dubbo框架提供同样的SPI扩展机制。
(4)Java SPI机制的缺点
通过SPI机制能够大大地提高接口设计的灵活性,但是SPI机制也存在一些缺点,比如:
arduino
缺点一:只能遍历所有的实现类,不管是否使用,都会全部实例化;
缺点二:配置文件中只简单列出所有的扩展实现,而没有给他们命名,导致在程序中很难去准确的引用它们;
缺点三:扩展如果依赖其他的扩展,做不到自动注入和装配;
缺点四:扩展很难和其他的框架集成,比如扩展里面依赖了一个Spring Bean,原生的Java SPI不支持;
缺点五:当多个ServiceLoader同时load时,会有并发问题;2.Dubbo如何扩展SPI机制
(1)Dubbo通过SPI机制提供组件的扩展实现
(2)为什么Dubbo要使用SPI
(3)Dubbo SPI机制的步骤
(4)Dubbo SPI机制的特点
Dubbo框架里有很多组件,比如Protocol、LoadBalance、Invoker、Exchange等接口实现类,就全面采用了SPI机制。Dubbo关键组件在代码里没有写死实现类,所有关键组件的实现类,都是在代码运行时动态去查找以及实例化出来的。这样给我们使用Dubbo时留出了充足的扩展空间,我们可以对Dubbo的各种组件进行定制。我们可以基于Dubbo SPI机制,做一些配置,就可以替换掉Dubbo默认的组件。
如果Dubbo要提供组件的扩展实现,此时没有SPI机制,那么就比较难实现了。因为Dubbo本身是一个框架,它没有使用Spring框架。我们使用Spring框架去写业务系统时,Spring已将接口和实现分离。Spring一般通过XML注解等去配置接口的实现类到底是什么,但Dubbo不可能为此又引入Spring框架。所以Dubbo自己实现一套SPI机制是最好的选择,这样可以随时对组件进行替换。
(2)为什么Dubbo要使用SPI
arduino
因为Dubbo本身是一个框架,不可能去使用类似于Spring这种其他的框架。
如果它要实现框架的高扩展性,那么SPI机制就是最好的选择,而在框架的源码里,主要是面向各种各样的接口来编程。
这样接口的实现类全部都可以通过ExtensionLoader组件,在运行时动态地根据配置来进行加载。(3)Dubbo SPI机制的步骤
kotlin
步骤一:针对接口Protocol,添加@SPI("dubbo")注解;
步骤二:在META-INF/dubbo/internal目录下,建立一个接口名字的文件,里面存放具体的接口实现类名称;
步骤三:通过ExtensionLoader.getExtensionLoader(Protocol.class).getExtension("dubbo")获取接口实现类的实例;(4)Dubbo SPI机制的特点
css
特点一:自动包装
扩展类会把其他的扩展类作为构造函数的参数,扩展类作为一个Wrapper包装类;
特点二:自动加载
扩展类是另一个扩展类的属性,通过setter方法,Dubbo会自动进行IOC接管这些扩展类的依赖注入;
特点三:自动适应
配合@Adaptive注解,根据URL参数去自动适应和匹配对应的实现类;
特点四:自动激活
同一个接口可以有多个实现类同时激活,Dubbo有很多高阶的特性来实现非常灵活的扩展机制;3.Dubbo的SPI扩展实现类的加载流程
ExtensionLoader.getExtensionLoader(Protocol.class).getExtension("dubbo")
scss
-> ExtensionLoader.getExtensionLoader()
-> ExtensionLoader.getExtension()
-> ExtensionLoader.getOrCreateHolder()
-> ExtensionLoader.createExtension()
-> ExtensionLoader.getExtensionClasses()
-> ExtensionLoader.loadExtensionClasses()
-> ExtensionLoader.cacheDefaultExtensionName()
-> ExtensionLoader.loadDirectory()
//这个ExtensionLoader类代表了Dubbo里的SPI机制的核心点
public class ExtensionLoader<T> {
//被缓存起来的实例集合
private final ConcurrentMap<String, Holder<Object>> cachedInstances = new ConcurrentHashMap<>();
...
@Deprecated
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
return ApplicationModel.defaultModel().getDefaultModule().getExtensionLoader(type);
}
public T getExtension(String name) {
T extension = getExtension(name, true);
if (extension == null) {
throw new IllegalArgumentException("Not find extension: " + name);
}
return extension;
}
public T getExtension(String name, boolean wrap) {
checkDestroyed();
if (StringUtils.isEmpty(name)) {
throw new IllegalArgumentException("Extension name == null");
}
if ("true".equals(name)) {
return getDefaultExtension();
}
//这是一个缓存key
String cacheKey = name;
if (!wrap) {
cacheKey += "_origin";
}
//基于缓存key去构建和创建一个Holder容器,getOrCreateHolder()方法中封装了查找cachedInstances缓存的逻辑
final Holder<Object> holder = getOrCreateHolder(cacheKey);
//对holder进行get()拿到里面封装的具体的实现类对象
Object instance = holder.get();
//如果是实现类对象是空,则去构建该实现类的对象,并使用多线程的double-check方法去构建
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
//创建一个实现类的对象,根据扩展名从SPI配置文件中查找对应的扩展实现类
instance = createExtension(name, wrap);
//把创建出来的实现类对象,设置到holder里面
holder.set(instance);
}
}
}
return (T) instance;
}
private Holder<Object> getOrCreateHolder(String name) {
//根据name名称,先去获取Holder
Holder<Object> holder = cachedInstances.get(name);
if (holder == null) {
//构建一个空的Holder,放入到缓存cachedInstances里
cachedInstances.putIfAbsent(name, new Holder<>());
holder = cachedInstances.get(name);
}
return holder;
}
private T createExtension(String name, boolean wrap) {
//获取cachedClasses缓存,根据扩展名从cachedClasses缓存中获取扩展实现类;
//如果cachedClasses未初始化,则会扫描前面介绍的三个SPI目录获取查找相应的SPI配置文件,
//然后加载其中的扩展实现类,最后将扩展名和扩展实现类的映射关系记录到cachedClasses缓存中;
//这部分逻辑在loadExtensionClasses()和loadDirectory()方法中;
Class<?> clazz = getExtensionClasses().get(name);
...
}
private Map<String, Class<?>> getExtensionClasses() {
//扩展类的缓存集合cachedClasses,通过double-check进行创建
Map<String, Class<?>> classes = cachedClasses.get();
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.get();
if (classes == null) {
try {
//做具体的load,去寻找对应的ExtensionClasses
classes = loadExtensionClasses();
} catch (InterruptedException e) {
logger.error("Exception occurred when loading extension class (interface: " + type + ")", e);
throw new IllegalStateException("Exception occurred when loading extension class (interface: " + type + ")", e);
}
cachedClasses.set(classes);
}
}
}
return classes;
}
private Map<String, Class<?>> loadExtensionClasses() throws InterruptedException {
checkDestroyed();
//缓存默认的扩展名称
cacheDefaultExtensionName();
//存放扩展类的集合
Map<String, Class<?>> extensionClasses = new HashMap<>();
//遍历不同的loading策略,去loadDirectory()
for (LoadingStrategy strategy : strategies) {
loadDirectory(extensionClasses, strategy, type.getName());
//compatible with old ExtensionFactory
if (this.type == ExtensionInjector.class) {
loadDirectory(extensionClasses, strategy, ExtensionFactory.class.getName());
}
}
return extensionClasses;
}
private void cacheDefaultExtensionName() {
//根据type从接口中拿到对应的SPI注解
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
if (defaultAnnotation == null) {
return;
}
//拿到注解里的值进行处理
String value = defaultAnnotation.value();
if ((value = value.trim()).length() > 0) {
String[] names = NAME_SEPARATOR.split(value);
if (names.length > 1) {
throw new IllegalStateException("More than 1 default extension name on extension " + type.getName() + ": " + Arrays.toString(names));
}
if (names.length == 1) {
cachedDefaultName = names[0];
}
}
}
...
}4.Dubbo的SPI寻找Extension的流程
scss
-> ExtensionLoader.getExtensionLoader()
-> ExtensionLoader.getExtension()
-> ExtensionLoader.getOrCreateHolder()
-> ExtensionLoader.createExtension()
-> ExtensionLoader.getExtensionClasses()
-> ExtensionLoader.loadExtensionClasses()
-> ExtensionLoader.cacheDefaultExtensionName()
-> ExtensionLoader.loadDirectory()
-> ExtensionLoader.loadDirectoryInternal()
-> ExtensionLoader.loadResource()
-> ExtensionLoader.getResourceContent()
-> ExtensionLoader.loadClass()
//这个ExtensionLoader类代表了Dubbo里的SPI机制的核心点
public class ExtensionLoader<T> {
...
private T createExtension(String name, boolean wrap) {
//获取cachedClasses缓存,根据扩展名从cachedClasses缓存中获取扩展实现类;
//如果cachedClasses未初始化,则会扫描前面介绍的三个SPI目录获取查找相应的SPI配置文件,
//然后加载其中的扩展实现类,最后将扩展名和扩展实现类的映射关系记录到cachedClasses缓存中;
//这部分逻辑在loadExtensionClasses()和loadDirectory()方法中;
Class<?> clazz = getExtensionClasses().get(name);
...
}
...
private void loadDirectory(Map<String, Class<?>> extensionClasses, LoadingStrategy strategy, String type) throws InterruptedException {
loadDirectoryInternal(extensionClasses, strategy, type);
...
}
private void loadDirectoryInternal(Map<String, Class<?>> extensionClasses, LoadingStrategy loadingStrategy, String type) throws InterruptedException {
//目录+type接口的名字,与Dubbo SPI配置的规则匹配上了
String fileName = loadingStrategy.directory() + type;
...
//使用了ClassLoader加载资源的方法,基于文件名拿出了资源集合
Enumeration<java.net.URL> resources = ClassLoader.getSystemResources(fileName);
if (resources != null) {
//对资源进行遍历执行涉及IO操作的loadResource()方法
while (resources.hasMoreElements()) {
loadResource(extensionClasses, null, resources.nextElement(),
loadingStrategy.overridden(),
loadingStrategy.includedPackages(),
loadingStrategy.excludedPackages(),
loadingStrategy.onlyExtensionClassLoaderPackages()
);
}
}
...
//基于SPI规则去读取各种配置文件,拿到对应的实现类,进行资源(-> ExtensionClass)的加载
Map<ClassLoader, Set<java.net.URL>> resources = ClassLoaderResourceLoader.loadResources(fileName, classLoadersToLoad);
resources.forEach(((classLoader, urls) -> {
loadFromClass(extensionClasses, loadingStrategy.overridden(), urls, classLoader,
loadingStrategy.includedPackages(),
loadingStrategy.excludedPackages(),
loadingStrategy.onlyExtensionClassLoaderPackages());
}
));
}
private void loadResource(Map<String, Class<?>> extensionClasses, ClassLoader classLoader, java.net.URL resourceURL, boolean overridden, String[] includedPackages, String[] excludedPackages, String[] onlyExtensionClassLoaderPackages) {
//通过IO操作获取内容
List<String> newContentList = getResourceContent(resourceURL);
String clazz;
//接下来根据获取的内容,把ExtensionClass加载出来,并对使用@Adaptive、@Activate不同机制修饰的类分别处理和缓存
for (String line : newContentList) {
...
//反射获取类名后加载类并进行缓存
loadClass(extensionClasses, resourceURL, Class.forName(clazz, true, classLoader), name, overridden);
...
}
...
}
private List<String> getResourceContent(java.net.URL resourceURL) throws IOException {
...
//IO操作一行一行读取
try (BufferedReader reader = new BufferedReader(new InputStreamReader(resourceURL.openStream(), StandardCharsets.UTF_8))) {
String line;
while ((line = reader.readLine()) != null) {
...
}
...
}
...
}
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name, boolean overridden) {
if (!type.isAssignableFrom(clazz)) {
throw new IllegalStateException("Error occurred ...");
}
if (clazz.isAnnotationPresent(Adaptive.class)) {
//缓存到cachedAdaptiveClass字段
cacheAdaptiveClass(clazz, overridden);
} else if (isWrapperClass(clazz)) {
//1.在isWrapperClass()方法中,会判断该扩展实现类是否包含拷贝构造函数(即构造函数只有一个参数且为扩展接口类型),
// 如果包含,则为Wrapper类,这就是判断Wrapper类的标准;
//2.将Wrapper类记录到cachedWrapperClasses(Set<Class<?>>类型)这个实例字段中进行缓存;
cacheWrapperClass(clazz);
} else {
if (StringUtils.isEmpty(name)) {
name = findAnnotationName(clazz);
if (name.length() == 0) {
throw new IllegalStateException("No such extension name for the class " + clazz.getName() + " in the config " + resourceURL);
}
}
String[] names = NAME_SEPARATOR.split(name);
if (ArrayUtils.isNotEmpty(names)) {
//将包含@Activate注解的实现类缓存到cachedActivates集合中
cacheActivateClass(clazz, names[0]);
for (String n : names) {
cacheName(clazz, n);
saveInExtensionClass(extensionClasses, clazz, n, overridden);
}
}
}
}
...
}5.Extension实现类对象的构建过程分析
注意构建的核心是:通过反射去构建扩展实现类的实例之后,会自动装配(依赖注入)扩展实现类对象里的属性和自动包装扩展实现对象。
typescript
-> ExtensionLoader.createExtension()
-> ExtensionLoader.createExtensionInstance()
-> InstantiationStrategy.instantiate()
-> ExtensionLoader.postProcessBeforeInitialization()
-> ExtensionLoader.injectExtension()
-> ExtensionLoader.postProcessAfterInitialization()
-> ExtensionLoader.initExtension()
//这个ExtensionLoader类代表了Dubbo里的SPI机制的核心点
public class ExtensionLoader<T> {
//缓存了扩展实现类和其实例的映射关系
private final ConcurrentMap<Class<?>, Object> extensionInstances = new ConcurrentHashMap<>(64);
...
private T createExtension(String name, boolean wrap) {
//获取cachedClasses缓存,根据扩展名从cachedClasses缓存中获取扩展实现类;
//如果cachedClasses未初始化,则会扫描前面介绍的三个SPI目录获取查找相应的SPI配置文件,
//然后加载其中的扩展实现类,最后将扩展名和扩展实现类的映射关系记录到cachedClasses缓存中;
//这部分逻辑在loadExtensionClasses()和loadDirectory()方法中;
Class<?> clazz = getExtensionClasses().get(name);
...
//根据扩展实现类从extensionInstances缓存中查找相应的实例;
//如果查找失败,会通过反射创建扩展实现类的对象;
T instance = (T) extensionInstances.get(clazz);
if (instance == null) {
//首先通过createExtensionInstance()会创建扩展类对应的实例,然后放到extensionInstances缓存里
extensionInstances.putIfAbsent(clazz, createExtensionInstance(clazz));
...
}
...
}
private Object createExtensionInstance(Class<?> type) throws ReflectiveOperationException {
return instantiationStrategy.instantiate(type);
}
...
}
public class InstantiationStrategy {
...
//通过反射去构建扩展实现类对应的实例
public <T> T instantiate(Class<T> type) throws ReflectiveOperationException {
//should not use default constructor directly, maybe also has another constructor matched scope model arguments
//1.try to get default constructor
Constructor<T> defaultConstructor = null;
try {
//首先反射获取扩展实现类的默认构造函数Constructor
defaultConstructor = type.getConstructor();
} catch (NoSuchMethodException e) {
// ignore no default constructor
}
//2.use matched constructor if found,匹配构造函数的列表
List<Constructor> matchedConstructors = new ArrayList<>();
//反射获取扩展实现类的多个构造函数
Constructor<?>[] declaredConstructors = type.getConstructors();
//对构造函数进行处理,找出匹配的构造函数放入list里
for (Constructor<?> constructor : declaredConstructors) {
if (isMatched(constructor)) {
matchedConstructors.add(constructor);
}
}
//remove default constructor from matchedConstructors
if (defaultConstructor != null) {
matchedConstructors.remove(defaultConstructor);
}
//match order:
//1. the only matched constructor with parameters
//2. default constructor if absent
//选择一个目标构造函数,通常就是匹配构造函数列表里的第一个
Constructor targetConstructor;
if (matchedConstructors.size() > 1) {
throw new IllegalArgumentException("...");
} else if (matchedConstructors.size() == 1) {
targetConstructor = matchedConstructors.get(0);
} else if (defaultConstructor != null) {
targetConstructor = defaultConstructor;
} else {
throw new IllegalArgumentException("None matched constructor was found for type: " + type.getName());
}
//create instance with arguments
//获取目标构造函数的参数类,并根据参数个数创建参数对象数组,然后遍历参数类,根据参数类型获取相应的参数对象
Class[] parameterTypes = targetConstructor.getParameterTypes();
Object[] args = new Object[parameterTypes.length];
for (int i = 0; i < parameterTypes.length; i++) {
args[i] = getArgumentValueForType(parameterTypes[i]);
}
//使用反射,传入参数对象数组,通过constructor构建一个扩展实现类的实例
return (T) targetConstructor.newInstance(args);
}
...
}
//这个ExtensionLoader类代表了Dubbo里的SPI机制的核心点
public class ExtensionLoader<T> {
...
private T createExtension(String name, boolean wrap) {
//获取cachedClasses缓存,根据扩展名从cachedClasses缓存中获取扩展实现类;
//如果cachedClasses未初始化,则会扫描前面介绍的三个SPI目录获取查找相应的SPI配置文件,
//然后加载其中的扩展实现类,最后将扩展名和扩展实现类的映射关系记录到cachedClasses缓存中;
//这部分逻辑在loadExtensionClasses()和loadDirectory()方法中;
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null || unacceptableExceptions.contains(name)) {
throw findException(name);
}
try {
//根据扩展实现类从extensionInstances缓存中查找相应的实例;
//如果查找失败,会通过反射创建扩展实现类的对象;
T instance = (T) extensionInstances.get(clazz);
if (instance == null) {
//首先通过createExtensionInstance()会创建扩展类对应的实例,然后放到extensionInstances缓存里
extensionInstances.putIfAbsent(clazz, createExtensionInstance(clazz));
instance = (T) extensionInstances.get(clazz);
//下面会对该实例对象进行初始化前的处理
instance = postProcessBeforeInitialization(instance, name);
//自动装配扩展实现对象中的属性(即调用其setter),这里涉及到ExtensionFactory以及自动装配的相关内容;
//其实就是依赖注入,Dubbo SPI机制扮演了类似Spring容器的机制,它会托管扩展实现类的对象
injectExtension(instance);
//下面会对该实例对象进行初始化后的处理
instance = postProcessAfterInitialization(instance, name);
}
//下面会对这个扩展实现类的实例对象进行包装
if (wrap) {
//自动包装扩展实现对象,这里涉及到Wrapper类以及自动包装特性的相关内容;
List<Class<?>> wrapperClassesList = new ArrayList<>();
if (cachedWrapperClasses != null) {
wrapperClassesList.addAll(cachedWrapperClasses);
wrapperClassesList.sort(WrapperComparator.COMPARATOR);
Collections.reverse(wrapperClassesList);
}
if (CollectionUtils.isNotEmpty(wrapperClassesList)) {
for (Class<?> wrapperClass : wrapperClassesList) {
Wrapper wrapper = wrapperClass.getAnnotation(Wrapper.class);
boolean match = (wrapper == null) || ((ArrayUtils.isEmpty(wrapper.matches()) || ArrayUtils.contains(wrapper.matches(), name)) && !ArrayUtils.contains(wrapper.mismatches(), name));
if (match) {
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
instance = postProcessAfterInitialization(instance, name);
}
}
}
}
//如果扩展实现类实现了Lifecycle接口,在initExtension()方法中会调用initialize()方法进行初始化;
initExtension(instance);
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance (name: " + name + ", class: " + type + ") couldn't be instantiated: " + t.getMessage(), t);
}
}
private T injectExtension(T instance) {
if (injector == null) {
return instance;
}
try {
for (Method method : instance.getClass().getMethods()) {
//如果不是setter方法,忽略该方法
if (!isSetter(method)) {
continue;
}
//如果方法上明确标注了@DisableInject这个禁用注入的注解,也忽略该方法
if (method.isAnnotationPresent(DisableInject.class)) {
continue;
}
if (method.getDeclaringClass() == ScopeModelAware.class) {
continue;
}
if (instance instanceof ScopeModelAware || instance instanceof ExtensionAccessorAware) {
if (ignoredInjectMethodsDesc.contains(ReflectUtils.getDesc(method))) {
continue;
}
}
//如果参数为简单类型,忽略该setter方法
Class<?> pt = method.getParameterTypes()[0];
if (ReflectUtils.isPrimitives(pt)) {
continue;
}
//下面就是具体的基于setter()方法进行依赖注入
try {
//根据setter方法的名称获取属性名称
String property = getSetterProperty(method);
//下面这行代码会加载并实例化扩展实现类
//如果注入的这个对象是其他SPI扩展实现类的对象,此时就直接从容器里进行获取,然后再注入到当前SPI扩展实现类对象
//下面的injector是一个注入器,它有多个实现
Object object = injector.getInstance(pt, property);
if (object != null) {
//调用setter方法进行装配,实现依赖注入
method.invoke(instance, object);
}
} catch (Exception e) {
logger.error("...", e);
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
return instance;
}
private void initExtension(T instance) {
if (instance instanceof Lifecycle) {
//扩展实现类一般可以实现一个Lifecycle接口
Lifecycle lifecycle = (Lifecycle) instance;
//这个方法是留给我们自己去实现的,里面一般是初始化中涉及的相关操作
lifecycle.initialize();
}
}
...
}6.SPI自适应机制自动生成代码与动态编译
需要注意:自适应扩展类的代码是动态生成的,使用了AdaptiveClassCodeGenerator来动态生成类代码。自适应扩展类的代码经过动态生成后,还需要进行动态编译,编译成Class字节码对象。
对于包含@Adaptive注解的SPI扩展类,若它有多个实现类,则可以根据url里的一些参数直接匹配和定位对应的一个实现类。createAdaptiveExtension()会动态生成出来一个自适应扩展类,但这个类不是一个直接给我们用的实现类。生成出来的这个自适应扩展类,核心要做的事情,就是根据url里提取出一些参数,动态去匹配真正的实现类。
scss
-> ExtensionLoader.getAdaptiveExtension()
-> ExtensionLoader.createAdaptiveExtension()
-> ExtensionLoader.getAdaptiveExtensionClass()
-> ExtensionLoader.getExtensionClasses()
-> ExtensionLoader.createAdaptiveExtensionClass()
-> AdaptiveClassCodeGenerator.generate()
-> ExtensionLoader.postProcessBeforeInitialization()
-> ExtensionLoader.injectExtension()
-> ExtensionLoader.postProcessAfterInitialization()
-> ExtensionLoader.initExtension()
//这个ExtensionLoader类代表了Dubbo里的SPI机制的核心点
public class ExtensionLoader<T> {
...
public T getAdaptiveExtension() {
//对于包含@Adaptive注解的SPI扩展类,如果它有多个实现类,那么就可以根据url里的一些参数直接匹配和定位对应的一个实现类
//createAdaptiveExtension()会动态生成出来一个类,但这个类不是一个直接给我们用的实现类
//生成出来的这个类,核心要做的事情,就是根据url里提取出一些参数,动态去匹配真正的实现类
checkDestroyed();
//检查cachedAdaptiveInstance字段中是否已缓存了适配器实例,如果已缓存,则直接返回该实例即可
Object instance = cachedAdaptiveInstance.get();
if (instance == null) {
if (createAdaptiveInstanceError != null) {
throw new IllegalStateException("...");
}
synchronized (cachedAdaptiveInstance) {
instance = cachedAdaptiveInstance.get();
if (instance == null) {
try {
instance = createAdaptiveExtension();
//将适配器实例缓存到cachedAdaptiveInstance字段,然后返回适配器实例
cachedAdaptiveInstance.set(instance);
} catch (Throwable t) {
createAdaptiveInstanceError = t;
throw new IllegalStateException("Failed to create adaptive instance: " + t.toString(), t);
}
}
}
}
return (T) instance;
}
private T createAdaptiveExtension() {
try {
//创建自适应扩展类对应的实例
T instance = (T) getAdaptiveExtensionClass().newInstance();
//下面会对该实例对象进行初始化前的处理
instance = postProcessBeforeInitialization(instance, null);
//调用injectExtension()方法进行自动装配,就能得到一个完整的适配器实例
injectExtension(instance);
//下面会对该实例对象进行初始化后的处理
instance = postProcessAfterInitialization(instance, null);
//如果扩展实现类实现了Lifecycle接口,在initExtension()方法中会调用initialize()方法进行初始化;
initExtension(instance);
return instance;
} catch (Exception e) {
throw new IllegalStateException("Can't create adaptive extension " + type + ", cause: " + e.getMessage(), e);
}
}
private Class<?> getAdaptiveExtensionClass() {
//调用getExtensionClasses()方法,其中就会触发loadClass()方法,完成cachedAdaptiveClass字段的填充
getExtensionClasses();
//如果存在@Adaptive注解修饰的扩展实现类,该类就是适配器类,通过newInstance()将其实例化即可
if (cachedAdaptiveClass != null) {
return cachedAdaptiveClass;
}
//如果不存在@Adaptive注解修饰的扩展实现类
//就需要通过createAdaptiveExtensionClass()方法扫描扩展接口中方法上的@Adaptive注解,动态生成适配器类,然后实例化
//所以光加载ExtensionClasses还不够,还需要创建adaptive自适应的扩展类实例
return cachedAdaptiveClass = createAdaptiveExtensionClass();
}
private Class<?> createAdaptiveExtensionClass() {
// Adaptive Classes' ClassLoader should be the same with Real SPI interface classes' ClassLoader
ClassLoader classLoader = type.getClassLoader();
try {
if (NativeUtils.isNative()) {
return classLoader.loadClass(type.getName() + "$Adaptive");
}
} catch (Throwable ignore) {
}
//下面使用了AdaptiveClassCodeGenerator来做类代码的动态生成并进行获取,也就是说自适应扩展类的代码是动态生成的
String code = new AdaptiveClassCodeGenerator(type, cachedDefaultName).generate();
//自适应扩展类的代码经过动态生成后,还需要进行动态编译,编译成Class字节码对象
org.apache.dubbo.common.compiler.Compiler compiler =
extensionDirector.getExtensionLoader(org.apache.dubbo.common.compiler.Compiler.class).getAdaptiveExtension();
return compiler.compile(type, code, classLoader);
}
...
}
public class AdaptiveClassCodeGenerator {
...
public String generate() {
return this.generate(false);
}
public String generate(boolean sort) {
// no need to generate adaptive class since there's no adaptive method found.
if (!hasAdaptiveMethod()) {
throw new IllegalStateException("No adaptive method exist on extension " + type.getName() + ", refuse to create the adaptive class!");
}
//动态拼接类代码的字符串
StringBuilder code = new StringBuilder();
code.append(generatePackageInfo());//生成包名
code.append(generateImports());//生成import
code.append(generateClassDeclaration());//生成类声明"public class ..."
Method[] methods = type.getMethods();
if (sort) {
//方法排序
Arrays.sort(methods, Comparator.comparing(Method::toString));
}
for (Method method : methods) {
code.append(generateMethod(method));//生成对应的方法
}
code.append('}');
if (logger.isDebugEnabled()) {
logger.debug(code.toString());
}
return code.toString();
}
...
}7.SPI自动激活机制源码分析
自动激活机制,其实就是根据@Activate注解,对SPI接口可以自动激活多个实现类。
typescript
-> ExtensionLoader.getActivateExtension()
//这个ExtensionLoader类代表了Dubbo里的SPI机制的核心点
//Dubbo SPI机制
//如果要设计一款框架,它会干很多的事情,但任何一个框架都是需要有扩展机制的
//那么扩展机制,会如何来设计呢?
//一般来说很多其他的框架,都会有自己的扩展机制;
//(1)比如在配置文件里,会做一些配置项:xx.xx.xx.Class = com.xxx.dd.xx.xMyClass
//这样框架在运行时,就会加载到这个配置,然后就会把你提供的类加载进来,作为具体的实现即可;
//这种方式存在的问题是:框架在运行过程中,一般只开放少数的一些组件能够可以让你去进行定制;
//(2)而Dubbo的SPI机制,做的就比较彻底了;
//由于其源码中的大量核心组件,都是可以替换,这让整个框架的扩展性和定制性做到了最大化;
//对于我们平时面对的一些业务系统,一般还不需要用到Dubbo的这种SPI机制来实现扩展;
public class ExtensionLoader<T> {
...
public List<T> getActivateExtension(URL url, String key) {
return getActivateExtension(url, key, null);
}
public List<T> getActivateExtension(URL url, String key, String group) {
String value = url.getParameter(key);
return getActivateExtension(url, StringUtils.isEmpty(value) ? null : COMMA_SPLIT_PATTERN.split(value), group);
}
//根据@Activate注解,对SPI接口可以自动激活多个实现类
public List<T> getActivateExtension(URL url, String[] values, String group) {
...
...
}
...
}总结Dubbo SPI机制:
如果要设计一款框架,它会干很多的事情,但任何一个框架都是需要有扩展机制的。那么扩展机制,会如何来设计呢?
一般来说很多其他的框架,都会有自己的扩展机制。比如在配置文件里做一些配置项:xx.xx.xx.Class = com.xxx.dd.xx.xMyClass。这样框架在运行时,就能加载到这个配置,然后就会把你提供的类加载进来,作为具体的实现即可。这种方式存在的问题是:框架在运行过程中,一般只开放少数的一些组件能够可以让你去进行定制。
而Dubbo的SPI机制,做得就比较彻底了。由于其源码中的大量核心组件,都是可以替换,这让整个框架的扩展性和定制性做到了最大化。当然,对于我们平时面对的一些业务系统,一般还不需要用到Dubbo的这种SPI机制来实现扩展。
8.Dubbo过滤器链设计模式源码分析
(1)Consumer端调用FilterChain链条的入口
(2)Provider端调用FilterChain链条的入口
(3)所有的Filter都要实现Filter接口即BaseFilter接口
Dubbo中会有一个过滤器机制,无论是在Provider端还是在Consumer端,都会去构建对应的FilterChain链条。
(1)Consumer端调用FilterChain链条的入口
scss
-> InvokerInvocationHandler.invoke() : invoker.invoke(rpcInvocation).recreate()
-> MigrationInvoker.invoke()
-> MockClusterInvoker.invoke()
-> AbstractCluster.ClusterFilterInvoker.invoke()
-> FilterChainBuilder.CallbackRegistrationInvoker.invoke()
-> FilterChainBuilder.CopyOfFilterChainNode.invoke()
-> ConsumerContextFilter.invoke()
-> FilterChainBuilder.CopyOfFilterChainNode.invoke()
-> FutureFilter.invoke()
-> FilterChainBuilder.CopyOfFilterChainNode.invoke()
-> MonitorFilter.invoke()
-> FilterChainBuilder.CopyOfFilterChainNode.invoke()
-> RouterSnapshotFilter.invoke()
-> AbstractClusterInvoker.invoke()
-> AbstractClusterInvoker.initLoadBalance()
-> FailoverClusterInvoker.doInvoke()
-> AbstractClusterInvoker.select()
-> AbstractClusterInvoker.doSelect()
-> AbstractLoadBalance.select()
-> RandomLoadBalance.doSelect()
-> AbstractClusterInvoker.invokeWithContext()
-> ListenerInvokerWrapper.invoke()
-> AbstractInvoker.invoke()
-> AbstractInvoker.doInvokeAndReturn()
-> DubboInvoker.doInvoke()
-> AbstractInvoker.waitForResultIfSync()
-> AsyncRpcResult.get()
@SPI(value = "default", scope = APPLICATION)
public interface FilterChainBuilder {
class CallbackRegistrationInvoker<T, FILTER extends BaseFilter> implements Invoker<T> {
public Result invoke(Invocation invocation) throws RpcException {
//下面会调用FilterChainBuilder$CopyOfFilterChainNode.invoke()
Result asyncResult = filterInvoker.invoke(invocation);
...
}
...
}
class CopyOfFilterChainNode<T, TYPE extends Invoker<T>, FILTER extends BaseFilter> implements Invoker<T> {
@Override
public Result invoke(Invocation invocation) throws RpcException {
Result asyncResult;
try {
InvocationProfilerUtils.enterDetailProfiler(invocation, () -> "Filter " + filter.getClass().getName() + " invoke.");
//下面会调用ConsumerContextFilter的invoke()方法
asyncResult = filter.invoke(nextNode, invocation);
} catch (Exception e) {
...
}
...
}
...
}
...
}
@Activate(group = CONSUMER, order = Integer.MIN_VALUE)
public class ConsumerContextFilter implements ClusterFilter, ClusterFilter.Listener {
...
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
...
//下面会调用FilterChainBuilder的内部类CopyOfFilterChainNode的invoke()方法
return invoker.invoke(invocation);
}
...
}(2)Provider端调用FilterChain链条的入口
scss
-> NettyServer
-> NettyServerHandler.channelRead()
-> NettyChannel.getOrAddChannel() : 读取请求,获取到NettyChannel
-> AbstractPeer.received()
-> MultiMessageHandler.received()
-> HeartbeatHandler.received()
-> AllChannelHandler.received()
-> WrappedChannelHandler.getPreferredExecutorService() 获取线程池
-> new ChannelEventRunnable()
-> AllChannelHandler.received()#executor.execute() 提交一个异步任务给线程池进行处理
-> ChannelEventRunnable.run() 启动任务处理请求
-> DecodeHandler.received()
-> HeaderExchangeHandler.received()
-> HeaderExchangeHandler.handleRequest() 对请求进行处理
-> DubboProtocol.requestHandler.reply()
-> FilterChainBuilder.FilterChainNode.invoke()
-> AbstractProxyInvoker.invoke() 在FilterChain中最终会跑到这个AbstractProxyInvoker.invke()
-> JavassistProxyFactory.getInvoker().doInvoke()
-> 目标实现类方法
public interface FilterChainBuilder {
class FilterChainNode<T, TYPE extends Invoker<T>, FILTER extends BaseFilter> implements Invoker<T> {
...
public Result invoke(Invocation invocation) throws RpcException {
...
//比如consumer端处理时下面会调用ConsumerContextFilter的invoke()方法
//provider端处理时下面会最终调用AbstractProxyInvoker.invoke()方法
asyncResult = filter.invoke(nextNode, invocation);
...
}
}
...
}(3)所有的Filter都要实现Filter接口即BaseFilter接口
java
@SPI(scope = ExtensionScope.MODULE)
public interface Filter extends BaseFilter {
}
public interface BaseFilter {
//将请求传给后续的Invoker进行处理
Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException;
//用于监听响应以及异常
interface Listener {
void onResponse(Result appResponse, Invoker<?> invoker, Invocation invocation);
void onError(Throwable t, Invoker<?> invoker, Invocation invocation);
}
}9.Dubbo中各种过滤器源码分析
(1)分析AccessLogFilter
(2)分析ExecuteLimitFilter
(3)分析ActiveLimitFilter
(1)分析AccessLogFilter
如果通过配置参数将AccessLogFilter开启了,那么它就会针对具体的Invoker调用时打印一些日志出来。Filter都会支持invoke()接口,并会对下一个Invoker进行invoke()调用。也就是写完日志之后会调用下一个Invoker,下一个Invoker有可能是真的Invoker也有可能是一个Filter,使用了责任链模式。
scss
-> AccessLogFilter.invoke()
//定时任务
-> AccessLogFilter.writeLogToFile()
-> AccessLogFilter.writeLogSetToFile()
-> AccessLogFilter.createIfLogDirAbsent()
-> AccessLogFilter.renameFile()
-> AccessLogFilter.processWithAccessKeyLogger()
//RPC调用
-> AccessLogFilter.buildAccessLogData()
-> invoker.invoke()
-> AccessLogFilter.log()
-> AccessLogFilter.writeLogSetToFile()
-> AccessLogFilter.createIfLogDirAbsent()
-> AccessLogFilter.renameFile()
-> AccessLogFilter.processWithAccessKeyLogger()
//如果通过配置参数将AccessLogFilter开启了,那么它就会针对具体的Invoker调用时打印一些日志出来
//Filter都会支持invoke()接口,并会对下一个Invoker进行invoke()调用
@Activate(group = PROVIDER, value = ACCESS_LOG_KEY)
public class AccessLogFilter implements Filter {
...
@Override
public Result invoke(Invoker<?> invoker, Invocation inv) throws RpcException {
if (scheduled.compareAndSet(false, true)) {
//通过共享线程池,启动一个定时任务,定期执行writeLogToFile()方法,完成日志写入
inv.getModuleModel().getApplicationModel().getFrameworkModel().getBeanFactory()
.getBean(FrameworkExecutorRepository.class).getSharedScheduledExecutor()
.scheduleWithFixedDelay(this::writeLogToFile, LOG_OUTPUT_INTERVAL, LOG_OUTPUT_INTERVAL, TimeUnit.MILLISECONDS);
}
Optional<AccessLogData> optionalAccessLogData = Optional.empty();
String accessLogKey = null;
try {
//获取ACCESS_LOG_KEY
accessLogKey = invoker.getUrl().getParameter(Constants.ACCESS_LOG_KEY);
//构造AccessLogData对象,其中记录了日志信息,例如,调用的服务名称、方法名称、version等
if (ConfigUtils.isNotEmpty(accessLogKey)) {
optionalAccessLogData = Optional.of(buildAccessLogData(invoker, inv));
}
} catch (Throwable t) {
logger.warn("Exception in AccessLogFilter of service(" + invoker + " -> " + inv + ")", t);
}
try {
//调用下一个Invoker,也就是写完日志之后会调用下一个Invoker,下一个Invoker有可能是真的Invoker也有可能是一个Filter
//这里使用了责任链模式
return invoker.invoke(inv);
} finally {
String finalAccessLogKey = accessLogKey;
optionalAccessLogData.ifPresent(logData -> {
logData.setOutTime(new Date());
log(finalAccessLogKey, logData);
});
}
}
private void writeLogToFile() {
//核心任务,把日志写到磁盘文件里去
//logEntries便是存储日志条目的map
if (!logEntries.isEmpty()) {
for (Map.Entry<String, Queue<AccessLogData>> entry : logEntries.entrySet()) {
String accessLog = entry.getKey();
Queue<AccessLogData> logSet = entry.getValue();
writeLogSetToFile(accessLog, logSet);
}
}
}
private void writeLogSetToFile(String accessLog, Queue<AccessLogData> logSet) {
try {
if (ConfigUtils.isDefault(accessLog)) {
//ACCESS_LOG_KEY配置值为true或是default
processWithServiceLogger(logSet);
} else {
//ACCESS_LOG_KEY配置既不是true也不是default
File file = new File(accessLog);
//创建目录
createIfLogDirAbsent(file);
if (logger.isDebugEnabled()) {
logger.debug("Append log to " + accessLog);
}
//创建日志文件,这里会以日期为后缀,滚动创建
renameFile(file);
//遍历logSet集合,将日志逐条写入文件
processWithAccessKeyLogger(logSet, file);
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
}
private void processWithAccessKeyLogger(Queue<AccessLogData> logQueue, File file) throws IOException {
//创建FileWriter,写入指定的日志文件
FileWriter writer = new FileWriter(file, true);
try {
while (!logQueue.isEmpty()) {
writer.write(logQueue.poll().getLogMessage());
writer.write(System.getProperty(LINE_SEPARATOR));
}
} finally {
writer.flush();
writer.close();
}
}
...
}(2)分析ExecuteLimitFilter
ExecuteLimitFilter可以根据配置,针对Provider端相关的类和方法,去限制同时调用的并发数量,例如通过可以设置并发数是100。
arduino
-> ExecuteLimitFilter.invoke()
-> RpcStatus.beginCount()
-> ExecuteLimitFilter.onResponse()
-> RpcStatus.endCount()
//ExecuteLimitFilter可以根据配置,针对provider端相关的类和方法,去限制同时调用的并发数量
//例如通过<dubbo:service executes="100" />可以设置并发数是100
@Activate(group = CommonConstants.PROVIDER, value = EXECUTES_KEY)
public class ExecuteLimitFilter implements Filter, Filter.Listener {
...
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
URL url = invoker.getUrl();
//获取方法名称
String methodName = invocation.getMethodName();
//根据配置去获取目标类和方法最多能发起的并发请求数max
int max = url.getMethodParameter(methodName, EXECUTES_KEY, 0);
//beginCount方法会去对目标接口的访问进行计数
//尝试增加active的值,当并发度达到executes配置指定的阈值,直接抛出异常
if (!RpcStatus.beginCount(url, methodName, max)) {
throw new RpcException(RpcException.LIMIT_EXCEEDED_EXCEPTION, "Failed to invoke method " + invocation.getMethodName() + " in provider " + url + ", cause: The service using threads greater than <dubbo:service executes="" + max + "" /> limited.");
}
invocation.put(EXECUTE_LIMIT_FILTER_START_TIME, System.currentTimeMillis());
return invoker.invoke(invocation);
}
public void onResponse(Result appResponse, Invoker<?> invoker, Invocation invocation) {
RpcStatus.endCount(invoker.getUrl(), getRealMethodName(invoker, invocation), getElapsed(invocation), true);
}
...
}
public class RpcStatus {
...
public static boolean beginCount(URL url, String methodName, int max) {
//默认不设置这个限制,max就是Integer最大值
max = (max <= 0) ? Integer.MAX_VALUE : max;
//获取服务对应的RpcStatus对象
RpcStatus appStatus = getStatus(url);
//获取服务方法对应的RpcStatus对象
RpcStatus methodStatus = getStatus(url, methodName);
if (methodStatus.active.get() == Integer.MAX_VALUE) {
//并发度溢出
return false;
}
for (int i; ; ) {
i = methodStatus.active.get();
//并发度超过max上限,直接返回false
if (i == Integer.MAX_VALUE || i + 1 > max) {
return false;
}
//通过CAS操作,去实现无锁化的线程安全的递增操作
if (methodStatus.active.compareAndSet(i, i + 1)) {
//更新成功后退出当前循环
break;
}
}
//单个服务的并发度加一
appStatus.active.incrementAndGet();
return true;
}
public static void endCount(URL url, String methodName, long elapsed, boolean succeeded) {
//服务维度
endCount(getStatus(url), elapsed, succeeded);
//服务方法维度
endCount(getStatus(url, methodName), elapsed, succeeded);
}
private static void endCount(RpcStatus status, long elapsed, boolean succeeded) {
status.active.decrementAndGet();//请求完成,降低并发度
status.total.incrementAndGet();//调用总次数增加
status.totalElapsed.addAndGet(elapsed);//调用总耗时增加
//更新最大耗时
if (status.maxElapsed.get() < elapsed) {
status.maxElapsed.set(elapsed);
}
if (succeeded) {
//如果此次调用成功,则会更新成功调用的最大耗时
if (status.succeededMaxElapsed.get() < elapsed) {
status.succeededMaxElapsed.set(elapsed);
}
} else {
//如果此次调用失败,则会更新失败调用的最大耗时
status.failed.incrementAndGet();
status.failedElapsed.addAndGet(elapsed);
if (status.failedMaxElapsed.get() < elapsed) {
status.failedMaxElapsed.set(elapsed);
}
}
}
...
}(3)分析ActiveLimitFilter
ActiveLimitFilter是放在Consumer端对并发进行控制的过滤器。在框架设计层面,或者对很多系统或者框架而言,都是必须要设计一个Filter机制的。这样通过Filter机制,对一些核心操作,进行过滤和拦截,并在此基础上做一些增强性的操作,以及允许我们自己去实现一些Filter,通过配置项的配置,加入到它的Filter链条去。
java
//ActiveLimitFilter是放在consumer端对并发进行控制的过滤器
//在框架设计层面,或者对很多系统或者框架而言,都是必须要设计一个filter机制的
//这样通过filter机制,对一些核心操作,进行过滤和拦截,并在此基础上做一些增强性的操作
//以及允许我们自己去实现一些filter,通过配置项的配置,加入到它的filter链条去
@Activate(group = CONSUMER, value = ACTIVES_KEY)
public class ActiveLimitFilter implements Filter, Filter.Listener {
...
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
//获得url对象
URL url = invoker.getUrl();
//获得方法名称
String methodName = invocation.getMethodName();
//计算获取最大并发数
int max = invoker.getUrl().getMethodParameter(methodName, ACTIVES_KEY, 0);
//获取该方法的状态信息,RpcStatus是RPC调用的状态数据,RpcStatus可以统计和获取指定接口方法的当前调用的状态数据
final RpcStatus rpcStatus = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName());
//如果设置了consumer端的ActiveLimit数值,而此时针对目标接口的方法活跃调用次数已超过了设置值,则RpcStatus.beginCount()为false
//尝试并发度加一
if (!RpcStatus.beginCount(url, methodName, max)) {
//如果活跃调用次数超过了设置的阈值,此时只能进行wait等待,超时时间
long timeout = invoker.getUrl().getMethodParameter(invocation.getMethodName(), TIMEOUT_KEY, 0);
long start = System.currentTimeMillis();
long remain = timeout;
//加锁
synchronized (rpcStatus) {
//再次尝试并发度加一
while (!RpcStatus.beginCount(url, methodName, max)) {
try {
//等待并发度降低
rpcStatus.wait(remain);
} catch (InterruptedException e) {
//ignore
}
//检测是否超时
long elapsed = System.currentTimeMillis() - start;
remain = timeout - elapsed;
if (remain <= 0) {
throw new RpcException(RpcException.LIMIT_EXCEEDED_EXCEPTION, "...");
}
}
}
}
//添加一个attribute
invocation.put(ACTIVE_LIMIT_FILTER_START_TIME, System.currentTimeMillis());
return invoker.invoke(invocation);
}
@Override
public void onResponse(Result appResponse, Invoker<?> invoker, Invocation invocation) {
//获取调用的方法名称
String methodName = invocation.getMethodName();
URL url = invoker.getUrl();
int max = invoker.getUrl().getMethodParameter(methodName, ACTIVES_KEY, 0);
//调用RpcStatus.endCount()方法完成调用监控的统计
RpcStatus.endCount(url, methodName, getElapsed(invocation), true);
//调用notifyFinish()方法唤醒阻塞在对应RpcStatus对象上的线程
notifyFinish(RpcStatus.getStatus(url, methodName), max);
}
...
}10.Dubbo Netty网络通信的线程模型
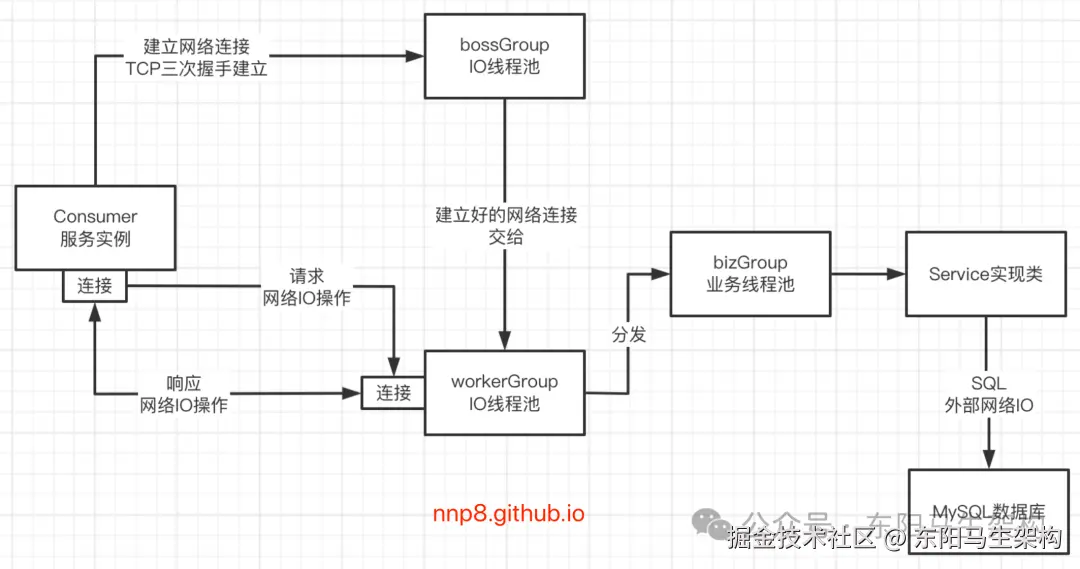
11.Dubbo全业务线程分发模型源码分析
AllDispatcher.dispatch()方法会构建一个AllChannelHandler(),将所有的网络事件分发给业务线程池bizGroup来进行处理:
java
public class AllDispatcher implements Dispatcher {
public static final String NAME = "all";
@Override
public ChannelHandler dispatch(ChannelHandler handler, URL url) {
return new AllChannelHandler(handler, url);
}
}而AllChannelHandler的涉及调用链如下:
scss
-> NettyServer
-> NettyServerHandler.channelRead()
-> NettyChannel.getOrAddChannel() : 读取请求,获取到NettyChannel
-> AbstractPeer.received()
-> MultiMessageHandler.received()
-> HeartbeatHandler.received()
-> AllChannelHandler.received()
-> WrappedChannelHandler.getPreferredExecutorService() 获取线程池
-> new ChannelEventRunnable()
-> AllChannelHandler.received()#executor.execute() 提交一个异步任务给线程池进行处理
-> ChannelEventRunnable.run() 启动任务处理请求
-> DecodeHandler.received()
-> HeaderExchangeHandler.received()
-> HeaderExchangeHandler.handleRequest() 对请求进行处理
-> DubboProtocol.requestHandler.reply()
-> FilterChainBuilder.FilterChainNode.invoke()
-> AbstractProxyInvoker.invoke() 在FilterChain中最终会跑到这个AbstractProxyInvoker.invke()
-> JavassistProxyFactory.getInvoker().doInvoke()
-> 目标实现类方法对于Consumer端发起的建立连接请求,会调用AllChannelHandler.connected()方法来处理:
java
-> AllChannelHandler.connected()
-> WrappedChannelHandler.getSharedExecutorService()
-> applicationModel.getExtensionLoader(ExecutorRepository.class).getDefaultExtension();
-> ExtensionLoader.getDefaultExtension()
-> DefaultExecutorRepository.createExecutorIfAbsent()
-> new ChannelEventRunnable()
-> ChannelEventRunnable.run()
public class AllChannelHandler extends WrappedChannelHandler {
...
@Override
//如果收到某consumer建立连接的请求
public void connected(Channel channel) throws RemotingException {
//获取公共线程池,也就是针对建立网络连接的事件获取到一个业务线程池
ExecutorService executor = getSharedExecutorService();
try {
//将CONNECTED事件的处理封装成ChannelEventRunnable提交到线程池中执行,线程池后面就会运行ChannelEventRunnable.run()方法
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.CONNECTED));
} catch (Throwable t) {
throw new ExecutionException("connect event", channel, getClass() + " error when process connected event .", t);
}
}
@Override
//如果与某consumer端的网络连接断开了
public void disconnected(Channel channel) throws RemotingException {
//获取线程池
ExecutorService executor = getSharedExecutorService();
try {
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.DISCONNECTED));
} catch (Throwable t) {
throw new ExecutionException("disconnect event", channel, getClass() + " error when process disconnected event .", t);
}
}
@Override
//如果收到某consumer端一个请求
public void received(Channel channel, Object message) throws RemotingException {
//获取线程池
ExecutorService executor = getPreferredExecutorService(message);
try {
//将消息封装成ChannelEventRunnable任务,提交到线程池中执行
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
//如果线程池满了,请求会被拒绝,这里会根据请求配置决定是否返回一个说明性的响应
if (message instanceof Request && t instanceof RejectedExecutionException){
sendFeedback(channel, (Request) message, t);
return;
}
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
}
@Override
//如果在网络通信过程中捕获到了一些异常
public void caught(Channel channel, Throwable exception) throws RemotingException {
ExecutorService executor = getSharedExecutorService();
try {
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.CAUGHT, exception));
} catch (Throwable t) {
throw new ExecutionException("caught event", channel, getClass() + " error when process caught event .", t);
}
}
...
}
public class WrappedChannelHandler implements ChannelHandlerDelegate {
...
public ExecutorService getSharedExecutorService() {
//Application may be destroyed before channel disconnected, avoid create new application model
if (url.getApplicationModel() == null || url.getApplicationModel().isDestroyed()) {
return GlobalResourcesRepository.getGlobalExecutorService();
}
//note: url.getOrDefaultApplicationModel() may create new application model
ApplicationModel applicationModel = url.getOrDefaultApplicationModel();
//ExecutorRepository主要是负责来获取线程池组件的,会通过ExtensionLoader,基于SPI扩展机制,去获取具体扩展实现类对象
ExecutorRepository executorRepository = applicationModel.getExtensionLoader(ExecutorRepository.class).getDefaultExtension();
//传入一个url,从url里提取一些参数出来,然后根据url参数来决定会获取到什么样的线程池
ExecutorService executor = executorRepository.getExecutor(url);
if (executor == null) {
//创建和构建线程池
executor = executorRepository.createExecutorIfAbsent(url);
}
return executor;
}
...
}
public class ExtensionLoader<T> {
...
public T getDefaultExtension() {
//根据SPI的规范去读取配置,加载扩展实现类
getExtensionClasses();
if (StringUtils.isBlank(cachedDefaultName) || "true".equals(cachedDefaultName)) {
return null;
}
//加载完毕后,此时可以根据缓存默认名称,去获取需要的实现类
return getExtension(cachedDefaultName);
}
...
}
public class DefaultExecutorRepository implements ExecutorRepository, ExtensionAccessorAware {
...
@Override
public synchronized ExecutorService createExecutorIfAbsent(URL url) {
Map<Integer, ExecutorService> executors = data.computeIfAbsent(getExecutorKey(url), k -> new ConcurrentHashMap<>());
//Consumer's executor is sharing globally, key=Integer.MAX_VALUE. Provider's executor is sharing by protocol.
//根据URL中的side参数值决定第一层key,根据URL中的port值确定第二层key
Integer portKey = CONSUMER_SIDE.equalsIgnoreCase(url.getParameter(SIDE_KEY)) ? Integer.MAX_VALUE : url.getPort();
if (url.getParameter(THREAD_NAME_KEY) == null) {
url = url.putAttribute(THREAD_NAME_KEY, "Dubbo-protocol-" + portKey);
}
URL finalUrl = url;
ExecutorService executor = executors.computeIfAbsent(portKey, k -> createExecutor(finalUrl));
//If executor has been shut down, create a new one
//如果缓存中相应的线程池已关闭,则同样需要调用createExecutor()方法
//创建新的线程池,并替换掉缓存中已关闭的线程持
if (executor.isShutdown() || executor.isTerminated()) {
executors.remove(portKey);
executor = createExecutor(url);
executors.put(portKey, executor);
}
return executor;
}
...
}
//实现的是JDK并发包里的Runnable接口
public class ChannelEventRunnable implements Runnable {
...
public ChannelEventRunnable(Channel channel, ChannelHandler handler, ChannelState state, Object message, Throwable exception) {
this.channel = channel;
this.handler = handler;
this.state = state;
this.message = message;
this.exception = exception;
}
@Override
public void run() {
InternalThreadLocal.removeAll();
if (state == ChannelState.RECEIVED) {
//接收到了请求
try {
//比如会调用DecodeHandler.received()方法
handler.received(channel, message);
} catch (Exception e) {
logger.warn("...", e);
}
}
...
}
}12.Dubbo各种分发模型源码分析
(1)不同的情况选择不同的分发策略
(2)DirectDispatcher
(3)MessageOnlyDispatcher
(4)ExecutionDispatcher
(1)不同的情况选择不同的分发策略
为什么需要不同的分发策略,这与不同的情况是有关系。
如果要执行的代码并没有外部数据库的IO操作,那么可以选择DirectDispatcher。
如果不关注网络连接和断开,只关注请求和响应的处理,那么可以选择MessageOnlyDispatcher或ExecutionDispatcher。
如果对网络连接和端口特别关注,那么可以选择ConnectionOrderedChannelHandler。
(2)DirectDispatcher
只有received情形才会通过判断线程池的类型来决定是否放到业务线程池里去进行处理,而connected、disconnected、caught这些情形,都没有放到业务线程池里去进行处理,它们都在网络IO线程里处理了。
java
public class DirectDispatcher implements Dispatcher {
public static final String NAME = "direct";
@Override
public ChannelHandler dispatch(ChannelHandler handler, URL url) {
return new DirectChannelHandler(handler, url);
}
}
//在这个DirectChannelHandler里面,只有received情形才会通过判断线程池的类型来决定是否放到业务线程池里去进行处理
//而connected、disconnected、caught这些情形,都没有放到业务线程池里去进行处理,它们都在网络IO线程里处理了
public class DirectChannelHandler extends WrappedChannelHandler {
...
@Override
public void received(Channel channel, Object message) throws RemotingException {
ExecutorService executor = getPreferredExecutorService(message);
if (executor instanceof ThreadlessExecutor) {
try {
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
} else {
//直接用handler来进行处理,也就是在IO线程上来进行处理
handler.received(channel, message);
}
}
}(3)MessageOnlyDispatcher
请求和响应的消息(received情形),一定会在业务线程池里来处理。
java
public class MessageOnlyDispatcher implements Dispatcher {
public static final String NAME = "message";
@Override
public ChannelHandler dispatch(ChannelHandler handler, URL url) {
return new MessageOnlyChannelHandler(handler, url);
}
}
public class MessageOnlyChannelHandler extends WrappedChannelHandler {
@Override
public void received(Channel channel, Object message) throws RemotingException {
//请求和响应的消息,一定会在业务线程池里来处理
ExecutorService executor = getPreferredExecutorService(message);
try {
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
if (message instanceof Request && t instanceof RejectedExecutionException){
sendFeedback(channel, (Request) message, t);
return;
}
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
}
...
}(4)ExecutionDispatcher
消息必须是请求类型,不能是响应类型,这时才会交给业务线程池来进行处理。
java
public class ExecutionDispatcher implements Dispatcher {
public static final String NAME = "execution";
@Override
public ChannelHandler dispatch(ChannelHandler handler, URL url) {
return new ExecutionChannelHandler(handler, url);
}
}
public class ExecutionChannelHandler extends WrappedChannelHandler {
...
@Override
public void received(Channel channel, Object message) throws RemotingException {
//先获取一个业务线程池
ExecutorService executor = getPreferredExecutorService(message);
//消息必须是请求类型,不能是响应类型,这时才会交给业务线程池来进行处理
if (message instanceof Request) {
try {
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
if (t instanceof RejectedExecutionException) {
sendFeedback(channel, (Request) message, t);
}
throw new ExecutionException(message, channel, getClass() + " error when process received event.", t);
}
} else if (executor instanceof ThreadlessExecutor) {
//针对ThreadlessExecutor这种线程池类型的特殊处理
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} else {
//其他情况都直接在IO线程里执行
handler.received(channel, message);
}
}
}DirectDispatcher、MessageOnlyDispatcher、ExecutionDispatcher、ConnectionOrderedDispatcher会将事件提交到业务线程池进行排队等待按顺序处理。
java
public class ConnectionOrderedDispatcher implements Dispatcher {
public static final String NAME = "connection";
@Override
public ChannelHandler dispatch(ChannelHandler handler, URL url) {
return new ConnectionOrderedChannelHandler(handler, url);
}
}
public class ConnectionOrderedChannelHandler extends WrappedChannelHandler {
...
public ConnectionOrderedChannelHandler(ChannelHandler handler, URL url) {
super(handler, url);
String threadName = url.getParameter(THREAD_NAME_KEY, DEFAULT_THREAD_NAME);
//注意,该线程池只有一个线程,队列的长度也是固定的,由URL中的connect.queue.capacity参数指定
connectionExecutor = new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(url.getPositiveParameter(CONNECT_QUEUE_CAPACITY, Integer.MAX_VALUE)),
new NamedThreadFactory(threadName, true),
new AbortPolicyWithReport(threadName, url)
); // FIXME There's no place to release connectionExecutor!
queueWarningLimit = url.getParameter(CONNECT_QUEUE_WARNING_SIZE, DEFAULT_CONNECT_QUEUE_WARNING_SIZE);
}
@Override
public void connected(Channel channel) throws RemotingException {
try {
//检查队列长度
checkQueueLength();
//提交到业务线程池进行排队等待按顺序处理
connectionExecutor.execute(new ChannelEventRunnable(channel, handler, ChannelState.CONNECTED));
} catch (Throwable t) {
throw new ExecutionException("connect event", channel, getClass() + " error when process connected event .", t);
}
}
...
}13.Dubbo线程池模型源码分析
(1)默认的线程池FixedThreadPool
(2)LimitedThreadPool
(3)EagerThreadPool
(4)CachedThreadPool
(1)默认的线程池FixedThreadPool
获取线程池的方法是WrappedChannelHandler的getSharedExecutorService(),其中也会通过SPI机制去获取线程池,默认的ThreadPool是FixedThreadPool。
java
-> WrappedChannelHandler.getSharedExecutorService()
-> DefaultExecutorRepository.createExecutorIfAbsent()
-> DefaultExecutorRepository.createExecutor()
-> FixedThreadPool.getExecutor()
public class WrappedChannelHandler implements ChannelHandlerDelegate {
...
public ExecutorService getSharedExecutorService() {
//Application may be destroyed before channel disconnected, avoid create new application model
if (url.getApplicationModel() == null || url.getApplicationModel().isDestroyed()) {
return GlobalResourcesRepository.getGlobalExecutorService();
}
//note: url.getOrDefaultApplicationModel() may create new application model
ApplicationModel applicationModel = url.getOrDefaultApplicationModel();
//ExecutorRepository主要是负责来获取线程池组件的,会通过ExtensionLoader,基于SPI扩展机制,去获取具体扩展实现类对象
ExecutorRepository executorRepository = applicationModel.getExtensionLoader(ExecutorRepository.class).getDefaultExtension();
//传入一个url,从url里提取一些参数出来,然后根据url参数来决定会获取到什么样的线程池
ExecutorService executor = executorRepository.getExecutor(url);
if (executor == null) {
//创建和构建线程池
executor = executorRepository.createExecutorIfAbsent(url);
}
return executor;
}
...
}
public class DefaultExecutorRepository implements ExecutorRepository, ExtensionAccessorAware {
...
@Override
public synchronized ExecutorService createExecutorIfAbsent(URL url) {
Map<Integer, ExecutorService> executors = data.computeIfAbsent(getExecutorKey(url), k -> new ConcurrentHashMap<>());
//Consumer's executor is sharing globally, key=Integer.MAX_VALUE. Provider's executor is sharing by protocol.
//根据URL中的side参数值决定第一层key,根据URL中的port值确定第二层key
Integer portKey = CONSUMER_SIDE.equalsIgnoreCase(url.getParameter(SIDE_KEY)) ? Integer.MAX_VALUE : url.getPort();
if (url.getParameter(THREAD_NAME_KEY) == null) {
url = url.putAttribute(THREAD_NAME_KEY, "Dubbo-protocol-" + portKey);
}
URL finalUrl = url;
ExecutorService executor = executors.computeIfAbsent(portKey, k -> createExecutor(finalUrl));
//If executor has been shut down, create a new one
//如果缓存中相应的线程池已关闭,则同样需要调用createExecutor()方法
//创建新的线程池,并替换掉缓存中已关闭的线程持
if (executor.isShutdown() || executor.isTerminated()) {
executors.remove(portKey);
executor = createExecutor(url);
executors.put(portKey, executor);
}
return executor;
}
private ExecutorService createExecutor(URL url) {
//通过SPI机制去创建线程池,默认的ThreadPool是FixedThreadPool
return (ExecutorService) extensionAccessor.getExtensionLoader(ThreadPool.class).getAdaptiveExtension().getExecutor(url);
}
...
}
//Dubbo默认的线程池策略
public class FixedThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
String name = url.getParameter(THREAD_NAME_KEY, (String) url.getAttribute(THREAD_NAME_KEY, DEFAULT_THREAD_NAME));
int threads = url.getParameter(THREADS_KEY, DEFAULT_THREADS);//默认的线程数量为DEFAULT_THREADS=200个
int queues = url.getParameter(QUEUES_KEY, DEFAULT_QUEUES);//默认的队列大小为0
return new ThreadPoolExecutor(threads, threads, 0, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new MemorySafeLinkedBlockingQueue<Runnable>()//内存安全的无界队列?
: new LinkedBlockingQueue<Runnable>(queues)),//有界队列
new NamedInternalThreadFactory(name, true),
new AbortPolicyWithReport(name, url)
);
}
}(2)LimitedThreadPool
该线程池的线程数量会随着你的繁忙的任务量而增加,但是最大的线程数量是不会超过最大阈值的。同时创建出来的线程,是不会因为空闲而被回收。
java
//LimitedThreadPool线程池,它的线程数量会随着你的繁忙的任务量而增加,但是最大的线程数量是不会超过最大阈值的
//同时创建出来的线程,是不会因为空闲而被回收
public class LimitedThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
String name = url.getParameter(THREAD_NAME_KEY, (String) url.getAttribute(THREAD_NAME_KEY, DEFAULT_THREAD_NAME));
int cores = url.getParameter(CORE_THREADS_KEY, DEFAULT_CORE_THREADS);//cores默认是0
int threads = url.getParameter(THREADS_KEY, DEFAULT_THREADS);//threads默认是200
int queues = url.getParameter(QUEUES_KEY, DEFAULT_QUEUES);//queues默认是0
return new ThreadPoolExecutor(cores, threads, Long.MAX_VALUE, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new MemorySafeLinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedInternalThreadFactory(name, true),
new AbortPolicyWithReport(name, url)
);
}
}(3)EagerThreadPool
eager表示渴望之意,如果线程池里的线程都是忙碌的状态,此时会创建新的线程出来,而不是放到queue里去排队。这种线程池一般要慎用,因为有可能会导致一下子创建出过多的线程。一旦太多的线程被创建出来,则可能会导致机器负载很高。除非可以确认即使是在负载和并发最高时,也不会有太多的线程同时运行,则可以放心使用。
java
//eager表示渴望之意
//如果线程池里的线程都是忙碌的状态,此时会创建新的线程出来,而不是放到queue里去排队
//这种线程池一般要慎用,因为有可能会导致一下子创建出过多的线程
//一旦太多的线程被创建出来,则可能会导致机器负载很高
//除非可以确认即使是在负载和并发最高时,也不会有太多的线程同时运行,则可以放心使用
public class EagerThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
String name = url.getParameter(THREAD_NAME_KEY, (String) url.getAttribute(THREAD_NAME_KEY, DEFAULT_THREAD_NAME));
int cores = url.getParameter(CORE_THREADS_KEY, DEFAULT_CORE_THREADS);//默认是0
int threads = url.getParameter(THREADS_KEY, Integer.MAX_VALUE);//线程数为Integer最大值
int queues = url.getParameter(QUEUES_KEY, DEFAULT_QUEUES);//默认是0
int alive = url.getParameter(ALIVE_KEY, DEFAULT_ALIVE);//默认60秒
// init queue and executor
TaskQueue<Runnable> taskQueue = new TaskQueue<Runnable>(queues <= 0 ? 1 : queues);
EagerThreadPoolExecutor executor = new EagerThreadPoolExecutor(cores,
threads,
alive,
TimeUnit.MILLISECONDS,
taskQueue,
new NamedInternalThreadFactory(name, true),
new AbortPolicyWithReport(name, url)
);
taskQueue.setExecutor(executor);
return executor;
}
}(4)CachedThreadPool
CachedThreadPool表示如果有空闲的线程就进行回收,如果有新的任务就创建新的线程。默认如果线程出现60秒空闲就会被回收,从而实现线程动态可回收。
java
//CachedThreadPool表示如果有空闲的线程就进行回收,如果有新的任务就创建新的线程
//默认如果线程出现60秒空闲就会被回收,从而实现线程动态可回收
public class CachedThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
String name = url.getParameter(THREAD_NAME_KEY, (String) url.getAttribute(THREAD_NAME_KEY, DEFAULT_THREAD_NAME));
int cores = url.getParameter(CORE_THREADS_KEY, DEFAULT_CORE_THREADS);
int threads = url.getParameter(THREADS_KEY, Integer.MAX_VALUE);
int queues = url.getParameter(QUEUES_KEY, DEFAULT_QUEUES);
int alive = url.getParameter(ALIVE_KEY, DEFAULT_ALIVE);//默认60秒,如果线程出现60秒空闲就会被回收
return new ThreadPoolExecutor(cores, threads, alive, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new MemorySafeLinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedInternalThreadFactory(name, true),
new AbortPolicyWithReport(name, url)
);
}
}14.Dubbo Cluster模块源码梳理
(1)Dubbo Cluster模块的核心组件
(2)Dubbo Cluster模块的核心接口
(3)Dubbo Cluster层的核心流程
(1)Dubbo Cluster模块的核心组件
Dubbo Cluster模块包括:DynamicDirectory、ClusterInvoker、LoadBalance、Router等。
Cluster和ClusterInvoker是成对出现的,比如FailoverCluster和FailoverClusterInvoker。Cluster和ClusterInvoker可以认为主要用于进行mock机制、集群容错、降级等方面的处理。
Directory则是主要用于进行动态服务发现,比如RegistryDirectory、DynamicDirectory。
Router会和Directory进行配合使用,用于根据不同的路由策略从Directory中获取合适的Invoker。
总结:Dubbo Cluster模块的主要功能是将多个Provider伪装成一个Provider供Consumer调用,其中涉及集群的容错处理、路由规则的处理以及负载均衡。
(2)Dubbo Cluster模块的核心接口
下面Cluster核心接口图展示了dubbo-cluster的核心组件:
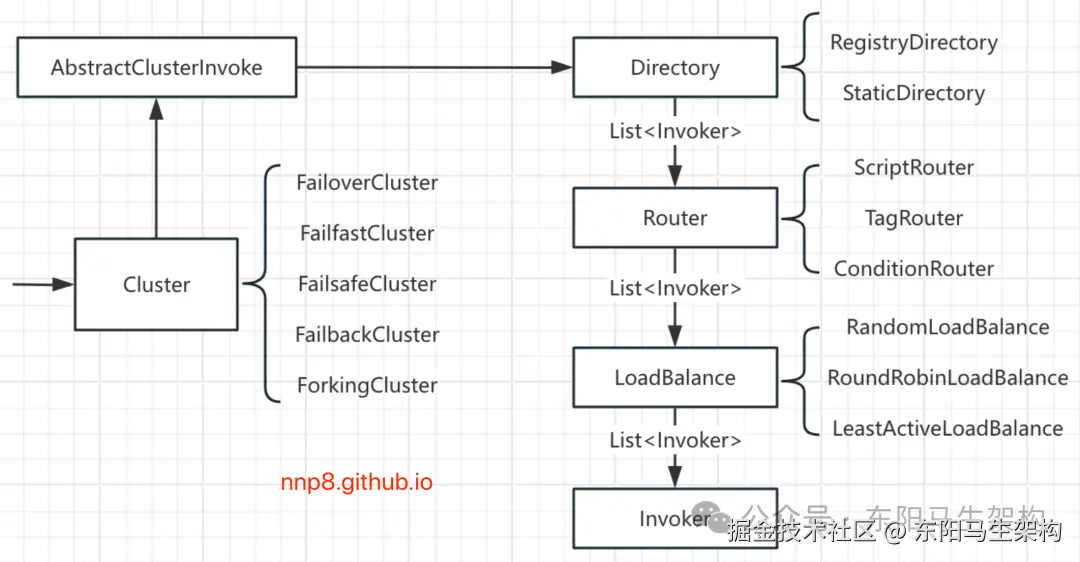
由上图可以看出,Dubbo Cluster模块主要包括以下四个核心接口:
一.Cluster接口
这是集群容错的接口,主要是在某些Provider节点发生故障时,让Consumer的调用请求能够发送到正常的Provider节点,从而保证整个系统的可用性。
二.Directory接口
表示多个Invoker的集合,是后续路由规则、负载均衡策略以及集群容错的基础。
三.Router接口
抽象的路由器,请求经过Router的时候,会按照用户指定的规则匹配出符合条件的Provider(Invoker)。
四.LoadBalance接口
这是负载均衡接口,Consumer会按照指定的负载均衡策略,从Provider集合中选出一个最合适的Provider节点(Invoker)来处理请求。
(3)Dubbo Cluster层的核心流程
当调用进入Cluster时,Cluster会创建一个AbstractClusterInvoker对象。在这个AbstractClusterInvoker中,首先会从Directory中获取当前Invoker集合。然后按照Router集合进行路由,得到符合条件的Invoker集合。接下来按照LoadBalance指定的负载均衡策略得到最终要调用的Invoker对象。
15.Dubbo各种Router策略源码分析
(1)RouterChain
(2)ConditionStateRouter
(3)ScriptStateRouter
(1)RouterChain
Router的主要功能就是根据用户配置的路由规则以及请求携带的信息,过滤出符合条件的Invoker集合,供后续负载均衡逻辑使用。
Consumer端在服务引用的过程中,部分调用链如下,期间会调用到RouterChain.route()方法。
scss
-> InvokerInvocationHandler.invoke() : invoker.invoke(rpcInvocation).recreate()
-> MigrationInvoker.invoke()
-> MockClusterInvoker.invoke()
-> AbstractCluster.ClusterFilterInvoker.invoke()
-> FilterChainBuilder.ClusterFilterChainNode.invoke()
-> AbstractClusterInvoker.invoke()
-> AbstractClusterInvoker.list()
-> AbstractDirectory.list()
-> DynamicDirectory.doList()
-> RouterChain.route()在RouterChain.buildChain()方法中,会在传入的URL参数中查找router参数值,并根据该值获取确定激活的RouterFactory。之后通过Dubbo SPI机制加载这些激活的RouterFactory对象,由RouterFactory创建当前激活的内置Router实例。RouterChain.route()方法会遍历routers字段,逐个调用Router对象的route()方法,对invokers集合进行过滤。
(2)ConditionStateRouter
ConditionStateRouter是基于条件表达式的路由实现类,下面就是一条基于条件表达式的路由规则:
ini
host = 192.168.0.100 => host = 192.168.0.150 在上述规则中:
"=>"之前的为Consumer匹配的条件(matchWhen),该条件中的所有参数会与Consumer的URL进行对比,当Consumer满足匹配条件时,会对该Consumer的此次调用执行"=>"后面的过滤规则。
"=>"之后为Provider地址列表的过滤条件(matchThen),该条件中的所有参数会和Provider的URL进行对比,Consumer最终只拿到过滤后的地址列表。
如果Consumer匹配条件为空,表示"=>"之后的过滤条件对所有Consumer生效。例如:=> host != 192.168.0.150,含义是所有Consumer都不能请求192.168.0.150这个Provider节点。
如果Provider过滤条件为空,表示禁止访问所有Provider。例如:host = 192.168.0.100 =>,含义是192.168.0.100这个Consumer不能访问任何Provider节点。
typescript
//基于一些自定义的条件,去进行Router路由,如果一个Invoker是符合条件,那么就可以返回出来去进行调用
public class ConditionStateRouter<T> extends AbstractStateRouter<T> {
...
//Consumer匹配的条件集合,通过解析条件表达式rule的=>之前半部分,可以得到该集合中的内容
protected Map<String, MatchPair> whenCondition;
//Provider匹配的条件集合,通过解析条件表达式rule的=>之后半部分,可以得到该集合中的内容
protected Map<String, MatchPair> thenCondition;
...
//在ConditionStateRouter的构造方法中,会根据URL中携带的相应参数初始化force、enable等字段
//然后从URL的rule参数中获取路由规则进行解析,具体的解析逻辑是在init()方法中实现的
public ConditionStateRouter(URL url) {
super(url);
this.setUrl(url);
this.setForce(url.getParameter(FORCE_KEY, false));
this.enabled = url.getParameter(ENABLED_KEY, true);
if (enabled) {
//下面会从URL的rule参数中获取路由规则进行解析
init(url.getParameterAndDecoded(RULE_KEY));
}
}
public void init(String rule) {
...
//将路由规则中的"consumer."和"provider."字符串清理掉
rule = rule.replace("consumer.", "").replace("provider.", "");
//按照"=>"字符串进行分割,得到whenRule和thenRule两部分
int i = rule.indexOf("=>");
String whenRule = i < 0 ? null : rule.substring(0, i).trim();
String thenRule = i < 0 ? rule.trim() : rule.substring(i + 2).trim();
//解析whenRule和thenRule,得到whenCondition和thenCondition两个条件集合
Map<String, MatchPair> when = StringUtils.isBlank(whenRule) || "true".equals(whenRule) ? new HashMap<String, MatchPair>() : parseRule(whenRule);
Map<String, MatchPair> then = StringUtils.isBlank(thenRule) || "false".equals(thenRule) ? null : parseRule(thenRule);
this.whenCondition = when;
this.thenCondition = then;
...
}
//parseRule()方法会解析表达式生成MatchPair
private static Map<String, MatchPair> parseRule(String rule) throws ParseException {
...
...
}
...
}(3)ScriptStateRouter
ScriptStateRouter支持JDK脚本引擎的所有脚本,如JavaScript、JRuby、Groovy等。通过type=javascript参数设置脚本类型,缺省为javascript。
ScriptStateRouter.doRoute()方法的实现:其中首先会创建调用function函数所需的入参,也就是Bindings对象。然后调用function函数得到过滤后的Invoker集合,最后通过getRoutedInvokers()方法整理Invoker集合得到最终的返回值。
typescript
public class ScriptStateRouter<T> extends AbstractStateRouter<T> {
//这是一个static集合;其中的Key是脚本语言的名称,Value是对应的ScriptEngine对象;
//这里会按照脚本语言的类型复用ScriptEngine对象;
private static final Map<String, ScriptEngine> ENGINES = new ConcurrentHashMap<>();
//当前ScriptRouter使用的ScriptEngine对象
private final ScriptEngine engine;
//当前ScriptRouter使用的具体脚本内容
private final String rule;
//根据rule这个具体脚本内容编译得到
private CompiledScript function;
...
public ScriptStateRouter(URL url) {
super(url);
this.setUrl(url);
//根据URL中的type参数值,从ENGINES集合中获取对应的ScriptEngine对象
engine = getEngine(url);
//获取URL中的rule参数值,即为具体的脚本
rule = getRule(url);
Compilable compilable = (Compilable) engine;
//编译rule字段中的脚本,得到function字段
function = compilable.compile(rule);
}
//ScriptStateRouter.doRoute()方法的实现:
//其中首先会创建调用function函数所需的入参,也就是Bindings对象;
//然后调用function函数得到过滤后的Invoker集合;
//最后通过getRoutedInvokers()方法整理Invoker集合得到最终的返回值;
@Override
protected BitList<Invoker<T>> doRoute(BitList<Invoker<T>> invokers, URL url, Invocation invocation, boolean needToPrintMessage, Holder<RouterSnapshotNode<T>> nodeHolder, Holder<String> messageHolder) throws RpcException {
if (engine == null || function == null) {
if (needToPrintMessage) {
messageHolder.set("Directly Return. Reason: engine or function is null");
}
return invokers;
}
//创建Bindings对象作为function函数的入参
Bindings bindings = createBindings(invokers, invocation);
//调用function函数,并在getRoutedInvokers()方法中整理得到的Invoker集合
return getRoutedInvokers(invokers, AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
try {
return function.eval(bindings);
} catch (ScriptException e) {
logger.error("route error, rule has been ignored...", e);
return invokers;
}
}, accessControlContext));
}
...
}16.ZooKeeper配置中心构建源码分析
配置中心可以是携程开源的apollo,阿里开源的nacos,还有默认的ZooKeeper。
ZooKeeper配置中心是通过ZookeeperDynamicConfigurationFactory的createDynamicConfiguration()方法构建的。
scala
-> ZookeeperDynamicConfigurationFactory.createDynamicConfiguration()
-> new ZookeeperDynamicConfiguration()
-> AbstractZookeeperTransporter.connect()
-> Curator5ZookeeperTransporter.createZookeeperClient()
-> new Curator5ZookeeperClient()
public class ZookeeperDynamicConfigurationFactory extends AbstractDynamicConfigurationFactory {
private ZookeeperTransporter zookeeperTransporter;
private ApplicationModel applicationModel;
public ZookeeperDynamicConfigurationFactory(ApplicationModel applicationModel) {
this.applicationModel = applicationModel;
this.zookeeperTransporter = ZookeeperTransporter.getExtension(applicationModel);
}
@Override
protected DynamicConfiguration createDynamicConfiguration(URL url) {
//构建ZooKeeper配置中心
return new ZookeeperDynamicConfiguration(url, zookeeperTransporter);
}
}
public class ZookeeperDynamicConfiguration extends TreePathDynamicConfiguration {
...
ZookeeperDynamicConfiguration(URL url, ZookeeperTransporter zookeeperTransporter) {
super(url);
this.cacheListener = new CacheListener();
final String threadName = this.getClass().getSimpleName();
//初始化线程池executor,用于执行监听器的逻辑,线程数量为1,队列大小为10000
this.executor = new ThreadPoolExecutor(
DEFAULT_ZK_EXECUTOR_THREADS_NUM,
DEFAULT_ZK_EXECUTOR_THREADS_NUM,
THREAD_KEEP_ALIVE_TIME,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(DEFAULT_QUEUE),
new NamedThreadFactory(threadName, true),
new AbortPolicyWithReport(threadName, url)
);
//初始化Zookeeper客户端,基于zookeeperTransporter连接到zk
zkClient = zookeeperTransporter.connect(url);
boolean isConnected = zkClient.isConnected();
if (!isConnected) {
throw new IllegalStateException("Failed to connect with zookeeper, pls check if url " + url + " is correct.");
}
}
@Override
protected String doGetConfig(String pathKey) throws Exception {
//直接从Zookeeper中读取对应的Key
return zkClient.getContent(pathKey);
}
@Override
protected boolean doPublishConfig(String pathKey, String content) throws Exception {
//在Zookeeper中创建对应ZNode节点
zkClient.create(pathKey, content, false);
return true;
}
...
}
public abstract class AbstractZookeeperTransporter implements ZookeeperTransporter {
...
@Override
public ZookeeperClient connect(URL url) {
ZookeeperClient zookeeperClient;
// address format: {[username:password@]address}
List<String> addressList = getURLBackupAddress(url);
// The field define the zookeeper server , including protocol, host, port, username, password
if ((zookeeperClient = fetchAndUpdateZookeeperClientCache(addressList)) != null && zookeeperClient.isConnected()) {
logger.info("find valid zookeeper client from the cache for address: " + url);
return zookeeperClient;
}
// avoid creating too many connections, so add lock
synchronized (zookeeperClientMap) {
if ((zookeeperClient = fetchAndUpdateZookeeperClientCache(addressList)) != null && zookeeperClient.isConnected()) {
logger.info("find valid zookeeper client from the cache for address: " + url);
return zookeeperClient;
}
zookeeperClient = createZookeeperClient(url);
logger.info("No valid zookeeper client found from cache, therefore create a new client for url. " + url);
writeToClientMap(addressList, zookeeperClient);
}
return zookeeperClient;
}
protected abstract ZookeeperClient createZookeeperClient(URL url);
...
}
public class Curator5ZookeeperTransporter extends AbstractZookeeperTransporter {
@Override
public ZookeeperClient createZookeeperClient(URL url) {
//创建CuratorZookeeperClient实例
return new Curator5ZookeeperClient(url);
}
}
public class Curator5ZookeeperClient extends AbstractZookeeperClient<Curator5ZookeeperClient.NodeCacheListenerImpl, Curator5ZookeeperClient.CuratorWatcherImpl> {
...
public Curator5ZookeeperClient(URL url) {
super(url);
try {
//连接超时时间
int timeout = url.getParameter(TIMEOUT_KEY, DEFAULT_CONNECTION_TIMEOUT_MS);
//session过期时间
int sessionExpireMs = url.getParameter(SESSION_KEY, DEFAULT_SESSION_TIMEOUT_MS);
//基于curator框架去构建zk client,curator框架是对zk原生client做了一层包装,正如Redisson和Jedis封装了redis一样,提供了大量高阶功能
CuratorFrameworkFactory.Builder builder = CuratorFrameworkFactory.builder()
//zk地址(包括备用地址)
.connectString(url.getBackupAddress())
//重试参数
.retryPolicy(new RetryNTimes(1, 1000))
//超时时间
.connectionTimeoutMs(timeout)
//session过期时间
.sessionTimeoutMs(sessionExpireMs);
String userInformation = url.getUserInformation();
if (userInformation != null && userInformation.length() > 0) {
builder = builder.authorization("digest", userInformation.getBytes());
builder.aclProvider(new ACLProvider() {
@Override
public List<ACL> getDefaultAcl() {
return ZooDefs.Ids.CREATOR_ALL_ACL;
}
@Override
public List<ACL> getAclForPath(String path) {
return ZooDefs.Ids.CREATOR_ALL_ACL;
}
});
}
client = builder.build();
//添加连接状态的监听
client.getConnectionStateListenable().addListener(new CuratorConnectionStateListener(url));
client.start();
//阻塞等待直到连接Zookeeper集群成功,超时时间为5秒,5秒过后还没连接上则抛异常
boolean connected = client.blockUntilConnected(timeout, TimeUnit.MILLISECONDS);
if (!connected) {
throw new IllegalStateException("zookeeper not connected");
}
} catch (Exception e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
...
}17.ZooKeeper配置中心源码简析
typescript
public class ZookeeperDynamicConfiguration extends TreePathDynamicConfiguration {
...
@Override
protected boolean doPublishConfig(String pathKey, String content) throws Exception {
//在Zookeeper中创建对应ZNode节点,需要定义一个pathKey和对应的内容content
//下面会调用AbstractZookeeperClient.create()方法
zkClient.create(pathKey, content, false);
return true;
}
//利用了zookeeper的数据版本来实现CAS
@Override
public boolean publishConfigCas(String key, String group, String content, Object ticket) {
try {
if (ticket != null && !(ticket instanceof Stat)) {
throw new IllegalArgumentException("zookeeper publishConfigCas requires stat type ticket");
}
String pathKey = buildPathKey(group, key);
//下面会调用AbstractZookeeperClient.createOrUpdate()方法
zkClient.createOrUpdate(pathKey, content, false, ticket == null ? 0 : ((Stat) ticket).getVersion());
return true;
} catch (Exception e) {
logger.warn("zookeeper publishConfigCas failed.", e);
return false;
}
}
@Override
protected String doGetConfig(String pathKey) throws Exception {
//直接从Zookeeper中读取对应的Key
//下面会调用AbstractZookeeperClient.getContent()方法
return zkClient.getContent(pathKey);
}
...
}
public abstract class AbstractZookeeperClient<TargetDataListener, TargetChildListener> implements ZookeeperClient {
...
@Override
public void create(String path, String content, boolean ephemeral) {
if (checkExists(path)) {
delete(path);
}
int i = path.lastIndexOf('/');
if (i > 0) {
create(path.substring(0, i), false);
}
if (ephemeral) {
createEphemeral(path, content);
} else {
createPersistent(path, content);
}
}
@Override
public void createOrUpdate(String path, String content, boolean ephemeral, int version) {
int i = path.lastIndexOf('/');
if (i > 0) {
create(path.substring(0, i), false);
}
if (ephemeral) {
createOrUpdateEphemeral(path, content, version);
} else {
createOrUpdatePersistent(path, content, version);
}
}
@Override
public String getContent(String path) {
if (!checkExists(path)) {
return null;
}
return doGetContent(path);
}
...
}