前言
在当今的数字化时代,企业级 IT 系统的复杂性和规模日益增长,监控和告警成为了保障业务连续性和系统稳定性的关键环节。然而,传统的监控和告警系统往往存在诸多痛点:告警数据源分散、告警策略单一、告警触达不及时、告警数据分析不足等。这些问题不仅增加了运维人员的工作负担,还可能导致关键告警被忽略,进而影响业务的正常运行。因此,建设一个统一的监控、告警平台,成为了集团性企业的迫切需求。本文将详细介绍我们在集团性企业落地统一监控告警的部分场景。
告警数据源
统一监控告警平台的首要任务是整合各类数据源。该企业的监控数据源是来自集团总部、分支机构的 Zabbix、Prometheus、Splunk 等第三方监控系统。通过观测云 DataKit(统一采集器)和 Function(数据处理平台),我们帮助客户实现了各监控系统数据的迅速接入。
集成多套监控工具
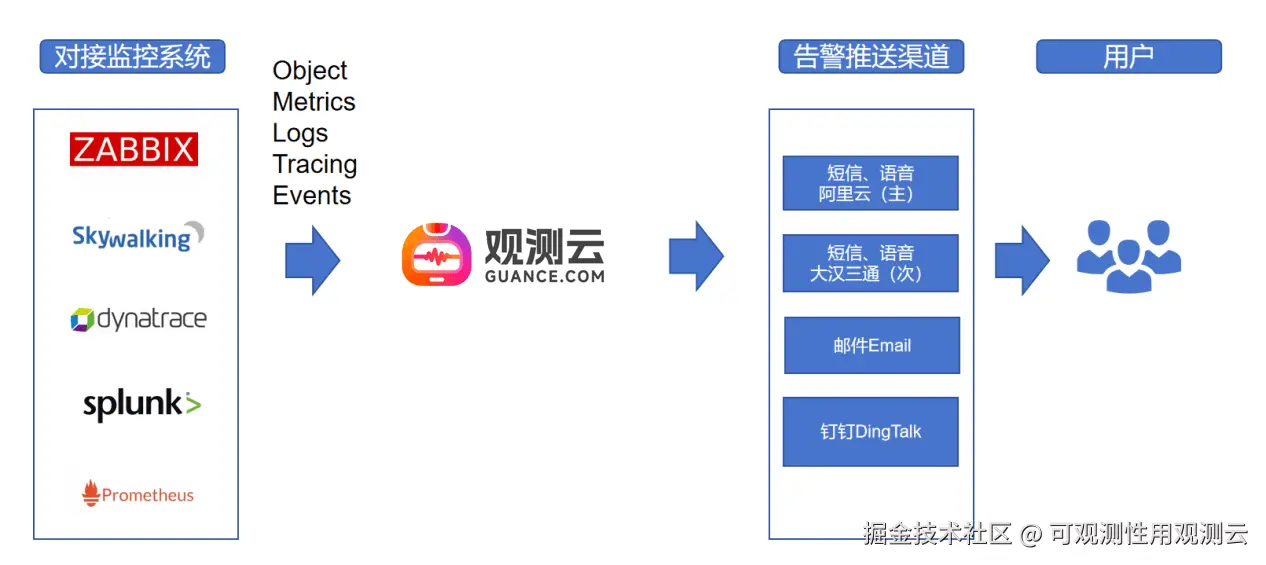
在下面的表格中,我们列举了本项目中所使用到的告警数据源和相应监控器。
| 监控器类型 | 告警数据源 |
|---|---|
| 外部事件检测器 | 从Zabbix、syslog接收到的events |
| 日志监控器 | 从Splunk采集到的logs数据 |
| 阈值监控器 | 从Zabbix、prometheus采集到的metrics数据 |
| 应用性能管理监控器 | 从Skywalking采集到的tracing数据 |
| 可用性监控器 | 基于观测云的synthetic monitoring数据配置的告警 |
该客户的告警大部分来自于 Zabbix,并基于 Zabbix 上的 host tag(主机标签)和 trigger tag(触发器标签)实现面向不同用户分发的需求。在本项目中,我们迁移了用户已有的近 2000 个告警策略,实现了从原告警平台至新统一监控告警平台的无缝切换。
另一部分告警则来自于 Metrics、Logs、Tracing 从各监控系统汇聚到观测云之后,基于观测云丰富的监控器来配置的告警。无论是基于 promQL 语句直接配置监控器,还是基于数据的同环比趋势对比,以及多种组合条件的复杂判断条件,用户的各种告警需求总是得到快速满足。
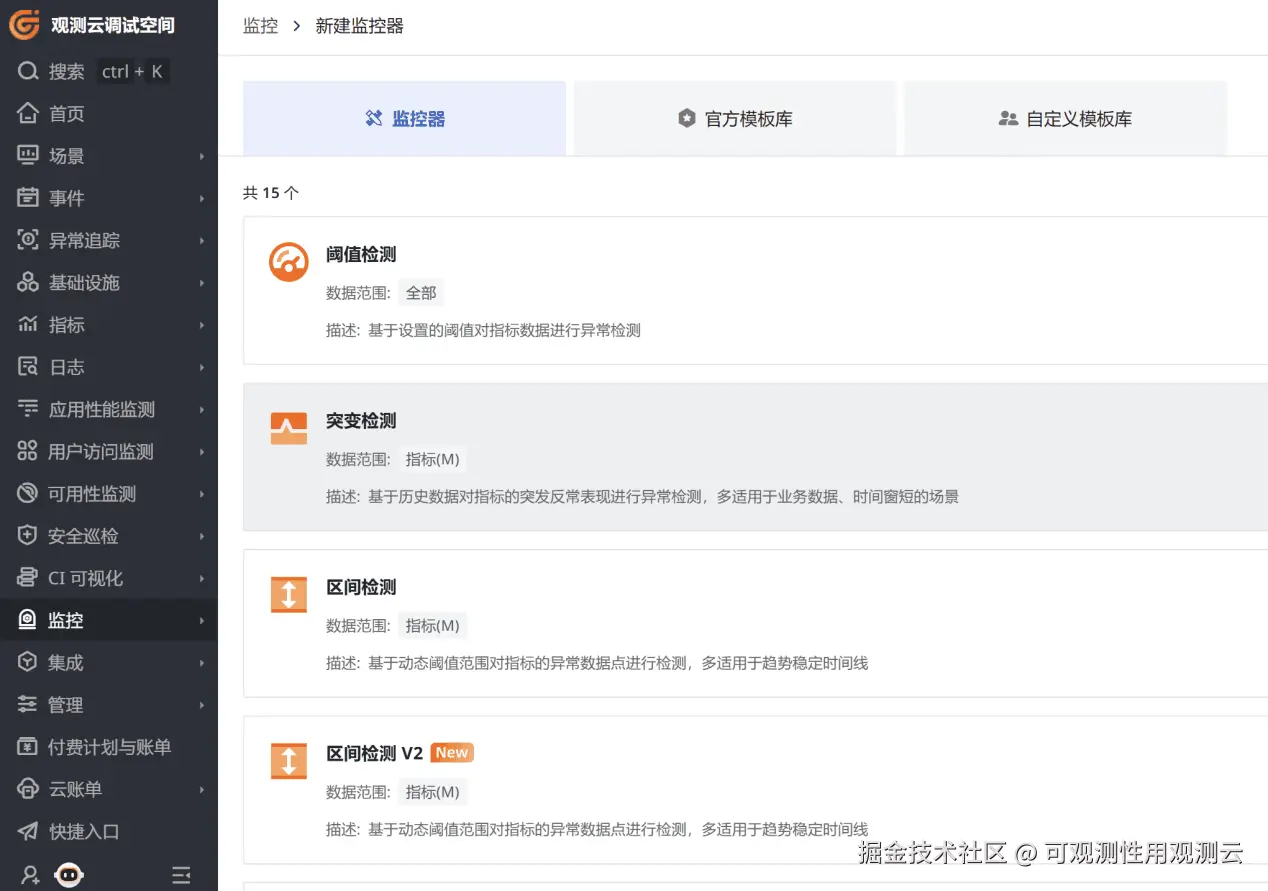
支持十余种开箱即用的监控器和 500+ 官方模板库
此外,我们还结合客户的 CMDB(配置管理数据库)进行告警富集。CMDB 中存储了丰富的基础设施和业务信息,通过将告警消息与 CMDB 中的资产信息关联,我们能够为每条告警消息添加更多的上下文信息。例如,告警消息不仅会显示具体的故障设备,还会关联到该设备所属的业务系统、负责人等信息,极大地提升了告警消息的可读性和可操作性。下面为根据 CMDB 做告警富集的部分字段。
| 字段名 | 字段含义 |
|---|---|
| app_name | 告警对象所属的应用名称 |
| appId | 告警对象所属的应用ID |
| className | 告警对象的资源类别,如Linux、Windows等 |
| Company | 告警对象所属公司 |
| Service_type | 告警对象所对应的服务器用途,如APP、MySQL、Oracle等 |
告警策略
告警策略是统一监控告警平台的核心功能之一。在面对庞大、复杂的集团企业级告警场景,我们需要具备灵活的基于自定义标签的过滤功能,以便海量告警通过自定义标签,精准分发给对应的用户。
例如,我们在本项目中接入 OCP(OceanBase Cloud Platform)的指标数据,并根据集群 ID、租户 ID 等重要 tag,实现了告警精准分发给应用团队。DBA 团队原先独自接收、处理该公司全集团的数据库告警,工作压力巨大。现在则可以将影响到应用系统的数据库告警发送给对应应用团队,有效提升了告警的处理效率,减少了应用损失。
基于自定义标签、组合条件实现告警的精准分发
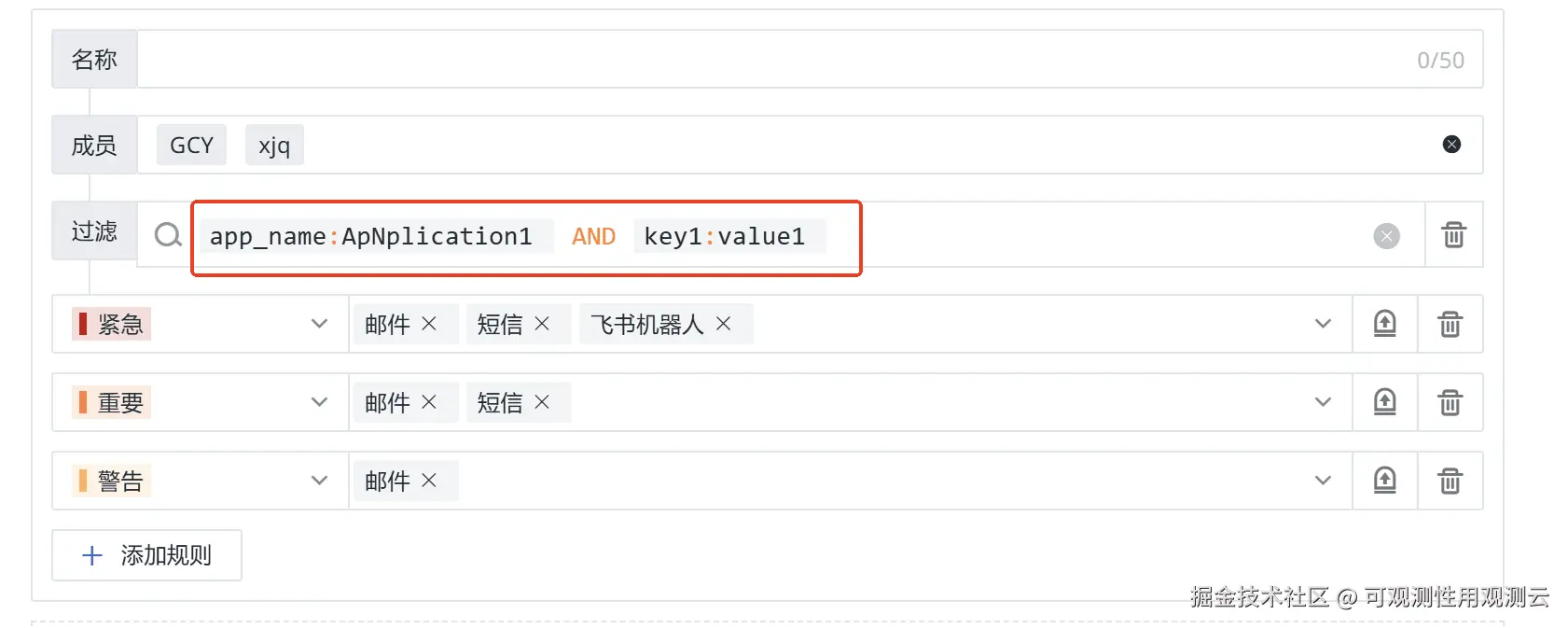
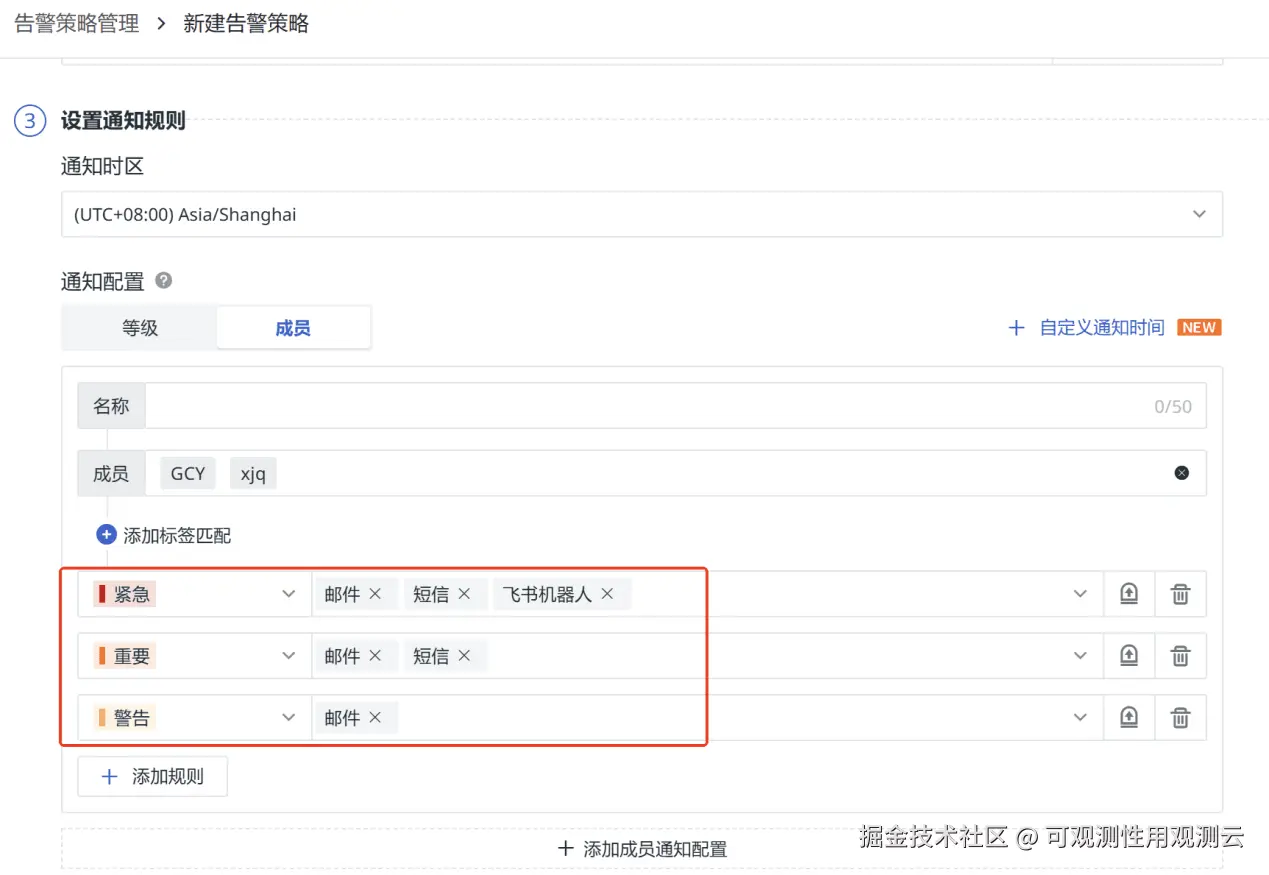
此外,我们还支持基于不同成员和通知对象的灵活告警通知。用户可以根据告警的严重程度、业务影响范围等因素,设置不同的告警接收人和通知方式。例如,对于高优先级的告警,可以同时通过邮件、短信、语音等多种方式通知相关人员,确保告警能够及时触达。
基于成员的多渠道通知方式
告警触达与协作
告警触达是确保告警能够及时传达给相关人员的关键环节。统一监控不仅支持多种通知方式,还提供了丰富的告警详情页面。用户可以通过点击告警事件,查看与该告警相关的详细信息,包括告警的触发时间、影响范围、关联的基础设施仪表板等。通过这种方式,运维人员不仅能够快速了解告警的具体情况,还能够通过关联的仪表板,进一步分析告警的根源,从而更快地定位和解决问题。
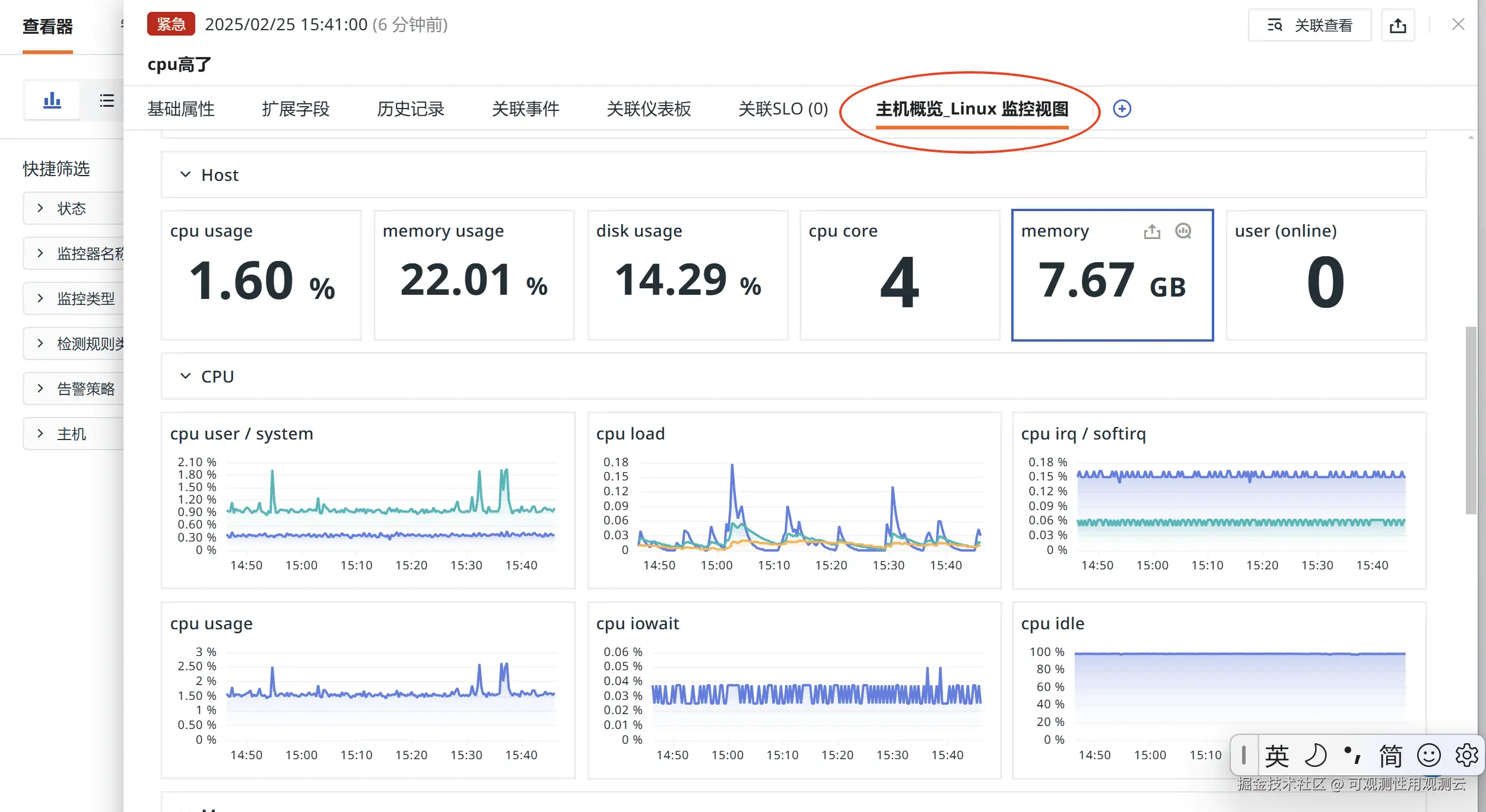
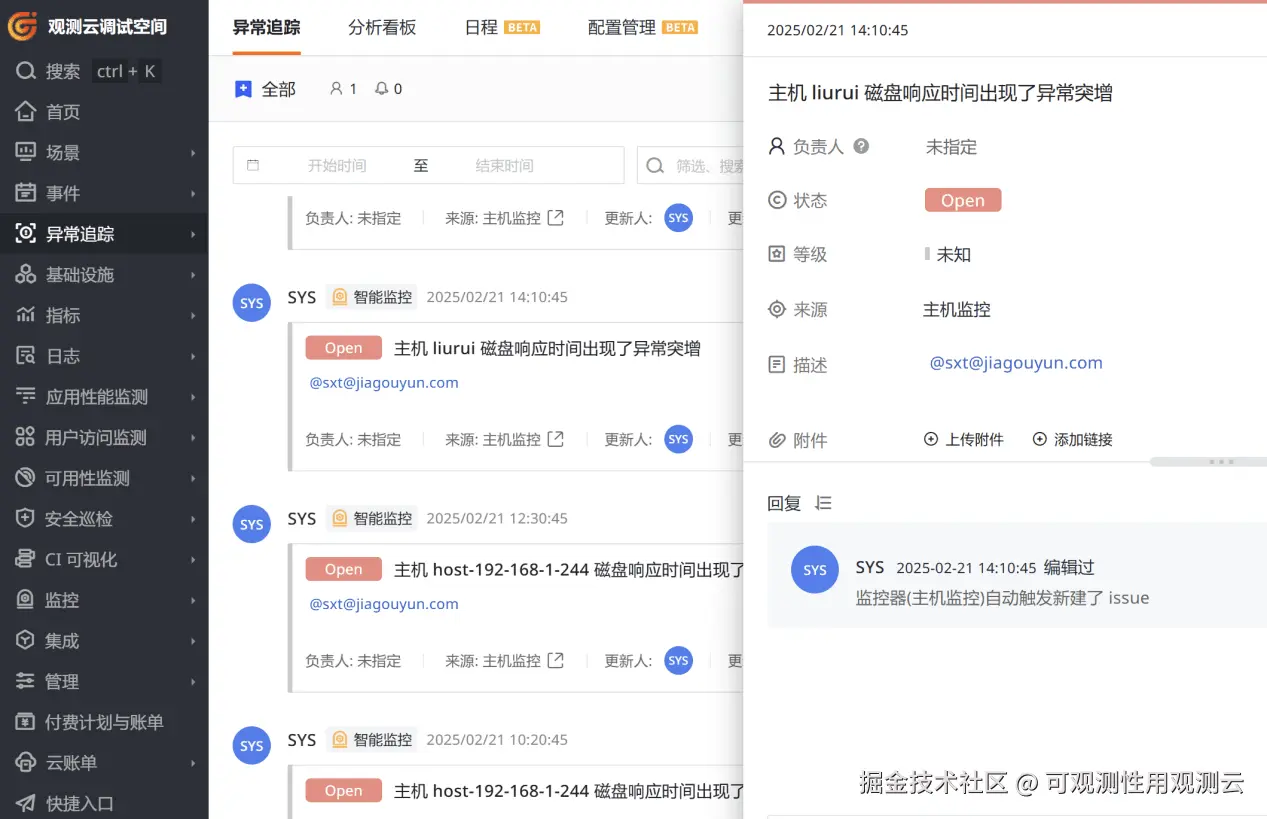
出于该企业的告警管理要求,一旦监控工具发出 Critical 告警之后需要同步创建一个 issue,7*24 小时值班成员需第一时间通知用户,而告警接收者也需迅速对故障进行处置。通过观测云的"异常追踪(Incident)"功能,我们帮助用户迅速组织资源对 issue 进行处置:
- 在 Critical 级别告警产生后,IM(本项目中使用企业部署版钉钉)将自动向告警负责人推送钉钉卡片,对方可基于卡片实现告警确认、查看详情、回复等操作;
- 值班人员起到 7*24 小时服务台的作用,语音联系告警负责人,并可在 issue 中记录对方的首次反馈;
- 告警负责人开始处置后 issue 状态将变为 working,可@其他成员,对方将会收到 IM 通知,迅速进行协同;
- 处理完成后,issue 详情内的评论/回复将成为故障回溯非常重要的过程数据,为后续类似的故障处理形成宝贵知识;
- 管理部门可基于分析看板实现对 issue 处理情况的统计和分析,从而对资源配置进行优化。
异常追踪功帮助用户进行事件管理
告警数据分析
告警数据分析是统一监控告警平台的另一大亮点。我们为用户提供了多种数据分析看板,帮助用户及时发现和解决告警系统中的潜在问题。例如,我们提供了通知对象失效看板,用户可以及时发现哪些通知对象已经失效,从而避免告警无法触达的情况。
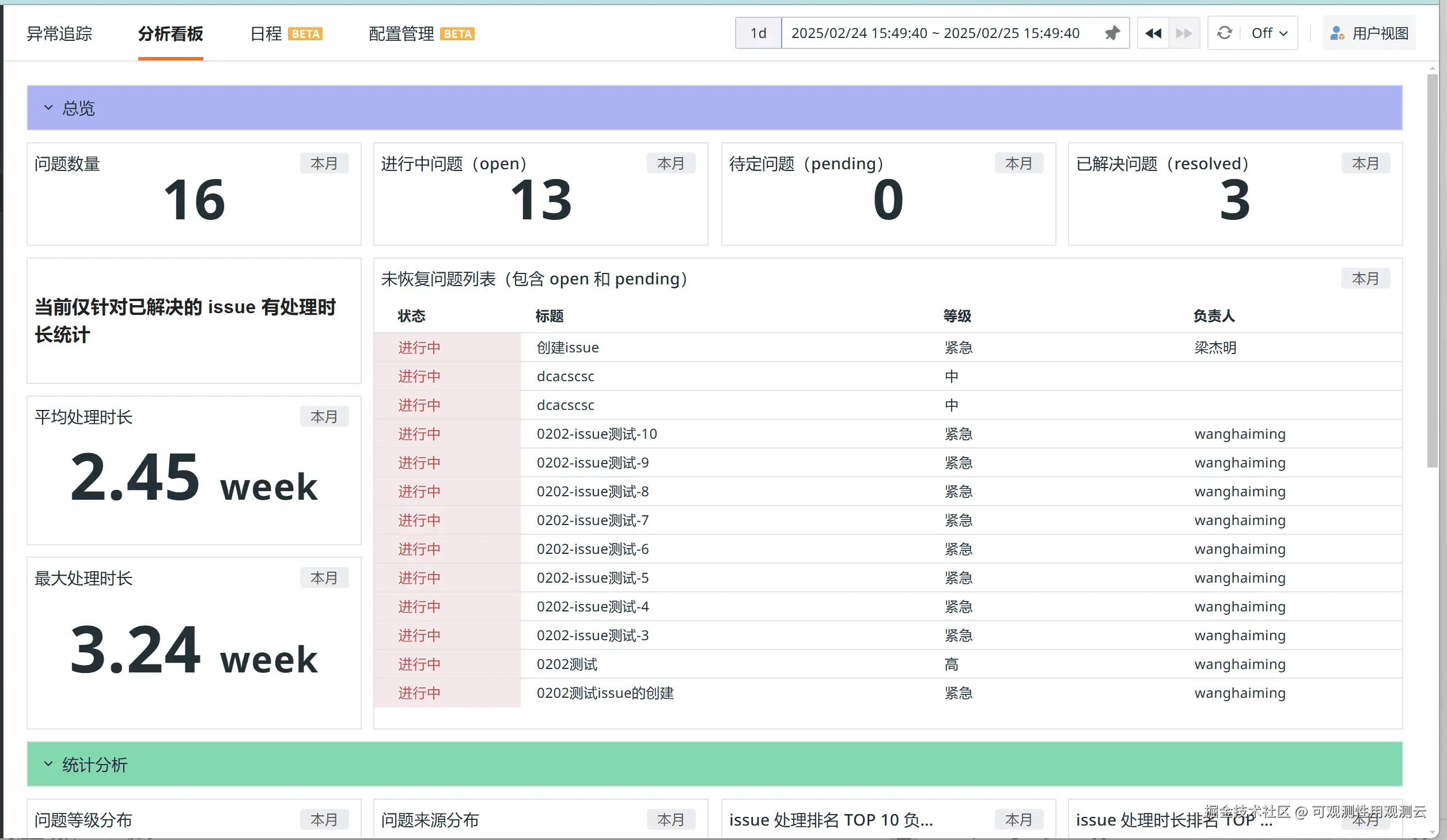
此外,我们还为用户提供了诸多看板,包括异常追踪分析看板、告警未命中策略看板、通知人失效看板、通知通道成功率看板等,并通过定时报告每天发送到用户团队的邮箱,用户会基于这些数据来不断调整和优化告警策略。
总结
通过建设统一监控、告警平台,我们成功解决了企业级告警中心的诸多痛点。平台不仅整合了各类告警数据源,还提供了灵活的告警策略、高效的告警触达机制和全面的告警数据分析功能。这些功能的结合,不仅大大提升了运维人员的工作效率,还为企业业务的连续性和稳定性提供了有力保障。未来,我们将继续优化和扩展平台的功能,为企业创造更大的价值。