 之前的文章XXX提到AI运算任务被切割成Stream、Task和Block,然后经过调度器给到NPU硬件进行加速运算,那么这些Task从哪里来?答案就是AI编译器。
之前的文章XXX提到AI运算任务被切割成Stream、Task和Block,然后经过调度器给到NPU硬件进行加速运算,那么这些Task从哪里来?答案就是AI编译器。
- 随着深度学习的应用场景不断泛化,AI算法也是千变万化。
- 在不同终端上运行计算机硬件差异化,特别是NPU针对应用定制后,也是变化多端。
面对软件和硬件的复杂性,系统又对性能和功耗有明显的需求,这时候就需要进行优化,而优化的主要工作就是在AI编译器中进行。
由于深度学习计算任务在现有的 AI 框架中往往以 DSL(Domain Specific Language)的方式进行编程和表达,这本身使得深度学习计算任务的优化和执行天然符合传统计算机语言的编译和优化过程。因此,深度学习的编译与优化就是将当前的深度学习计算任务通过一层或多层中间表达进行翻译和优化,最终转化成目标硬件上的可执行代码的过程。
传统编译器技术积累了几十年,非常成熟,换汤不换药,可以说传统编译器技术的很小一部分就够AI编译器用了。所以本文在介绍AI编译器之前需要先学习下编译器技术。
1 编译器基础
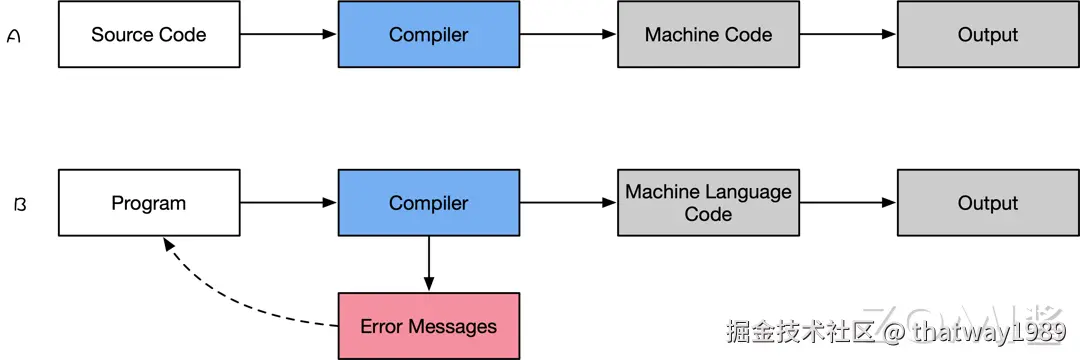
编译器可以将整个程序转换为目标代码(object code),这些目标代码通常存储在文件中。目标代码也被称为二进制代码,在进行链接后可以被机器直接执行。典型的编译型程序语言有 C 和 C++。
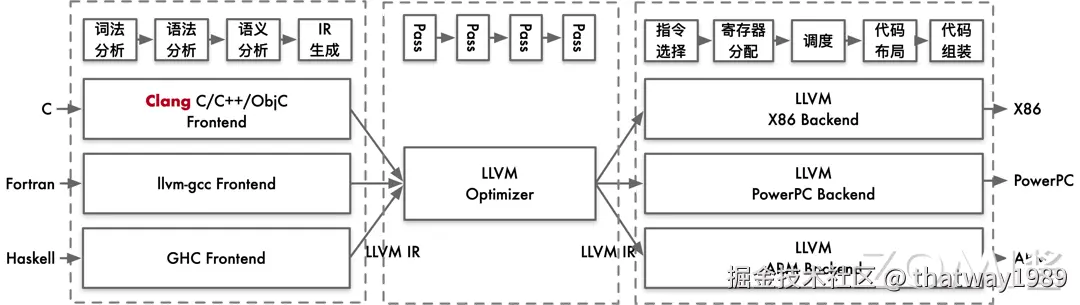
目前主流如 LLVM 和 GCC 等经典的开源编译器的类型分为前端编译器、中间层编译器、后端编译器。
- 编译器的分析阶段也称为前端编译器,将程序划分为基本的组成部分,检查代码的语法、语义和语法,然后生成中间代码。
- 中间层主要是对源程序代码进行优化和分析,分析阶段包括词法分析、语义分析和语法分析;优化主要是优化中间代码,去掉冗余代码、子表达式消除等工作。
- 编译器的合成阶段也称为后端,针对具体的硬件生成目标代码,合成阶段包括代码优化器和代码生成器。
编译器(Compiler)和解释器(Interpreter)的区别?
解释器在程序运行时将代码转换成机器码,编译器在程序运行之前将代码转换成机器码。解释器能够直接执行程序或脚本语言中编写的指令,而不需要预先将这些程序或脚本语言转换成目标代码或者机器码。典型的解释型语言有 Python、PHP 和 Matlab。
对比运行时解释执行和提前编译好执行,那当然的提前编译好的效率高。所以传统的基于Pytoch运行AI程序实际是基于解释性语言执行的,想提高效率就必须进行诊断硬件的编译。
在 C 语言的编译器有很多种,不同的平台下有不同的编译器,例如:
- Windows:常用的是微软编译器(cl.exe),被集成在 Visual Studio 或 Visual C++ 中,一般不单独使用;
- Linux:常用 GUN 组织开发的 GCC,很多 Linux 发行版都自带 GCC;
- Mac:常用的是 LLVM/Clang,被集成在 Xcode 中
编译器的几个重要的特点:
- 编译器读取源程序代码,输出可执行机器码,即把开发者编写的代码转换成 CPU 等硬件能理解的格式
- 将输入源程序转换为机器语言或低级语言,并在执行前并报告程序中出现的错误
- 编译的过程比较复杂,会消耗比较多的时间分析和处理开发者编写的程序代码
- 可执行结果,属于某种形式的特定于机器的二进制代码
经过编译器的黑盒操作,编程语言不断向高级语言进化,更加时候人去使用并且容错能力更强,估计有一天就不是通过键盘编程,而是说句话,智能编译器就能生成可以执行的程序了。
在 21 世纪后仍然有许多新兴的编程语言,如函数式编程语言 Haskell,优秀的内存安全性与性能的 Rust,用于分布式微服务的 Go,基于 JVM 平台的 Android 官方开发语言 Kotlin,Apple 平台的新编程语言 Swift 等。
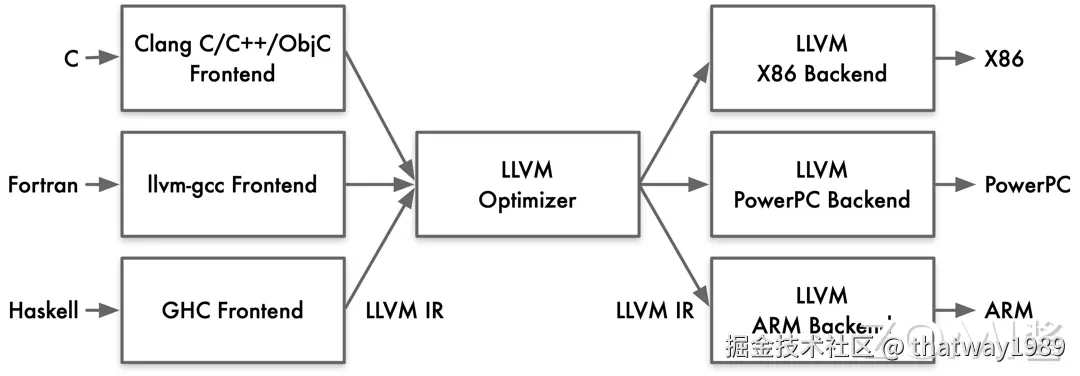
新兴编程语言的快速发展少不了基础设施的逐步完善。如 LLVM (Low Level Virtual Machine) 的出现,可以让任意编程语言前端编译到一个 LLVM 的中间表示(IR),再由 LLVM 中的后端编译至具体硬件平台,并且可以分不同阶段实现优化。

LLVM 和 GCC 如今已不再是某个具体的编译工具,而已然成为了一套编译基础设施。LLVM 和 GCC 不仅提供了一系列编译器,也主要提供了一些 C/C++ 语言相关配套工具,如 LLVM 的 Clang 工具链(包含 Clang-tidy、Clang-format)。
| 类型 | GCC | Clang/LLVM |
|---|---|---|
| 许可证 | GNU GPL | Apache 2.0 |
| 代码模块化 | 一体化架构 | 模块化 |
| 支持平台 | Uinx、Windows、MAC | Uinx、Windows、MAC |
| 代码生成 | 高效,有很多编译器选项可以使用 | 高效,LLVM 后端使用了 SSA 表单 |
| 语言独立类型系统 | 没有 | 有 |
| 构建工具 | Make Base | CMake |
| 解析器 | 最早采用 Bison LR,现在改为递归下解析器 | 手写的递归下降解析器 |
| 链接器 | LD | lld |
| 调试器 | GDB | LLDB |
GCC修改了必须开源,Clang/LLVM则修改后可以闭源,更加的自由。
此外配套的一些语言的分析工具:
- 代码格式化工具:自动格式化代码,使代码符合固定格式,提高代码可读性。
- 静态代码分析工具:编译期间运行,来检测出代码中的问题和漏洞。如 Clang-tidy、rust-clippy、Clangd(LSP)、rust-analyzer(LSP)
- 动态代码分析工具:运行时分析,比静态分析更能发现一些潜在的漏洞,诸如 C/C++ 的内存检测工具,用于检查内存泄露以及异常内存使用并能返回问题代码位置。
\实际开发中,除了编译器是必须的工具,往往还需要很多其他辅助软件,例如:
- 编辑器:用来编写代码,并且给代码着色,以方便阅读;
- 代码提示器:输入部分代码,即可提示全部代码,加速代码的编写过程;
- 调试器:观察程序的每一个运行步骤,发现程序的逻辑错误;
- 管理工具:对程序涉及到的所有资源进行管理,包括源文件、图片、视频、第三方库等;
- 开发的界面:各种按钮、面板、菜单、窗口等控件整齐排布,操作更方便。
这些工具通常被打包在一起,统一发布和安装,例如 Visual Studio、Dev C++、Xcode、Visual C++ 6.0、C-Free、Code::Blocks 等,统称为集成开发环境(IDE,Integrated Development Environment) 。
2 Gcc编译器介绍

GCC(GNU Compiler Collection,GNU 编译器集合)最初是作为 GNU 操作系统的编译器编写的,旨在为 GNU/Linux 系统开发一个高效的 C 编译器。其历史可以追溯到 1987 年,当时由理查德·斯托曼(Richard Stallman)创建,作为 GNU 项目的一部分。
GCC 具有以下主要特征:
- 可移植性:支持多种硬件平台,使得用户可以在不同的硬件架构上进行编译。
- 跨平台交叉编译:支持在一个平台上为另一个平台生成可执行文件,这对嵌入式开发尤为重要。
- 多语言前端:除了 C 语言,还支持 C++、Objective-C、Fortran、Ada、Go 和 D 等多种编程语言。
- 模块化设计:允许轻松添加新语言和 CPU 架构的支持,增强了扩展性。
- 开源自由软件:源代码公开,用户可以自由使用、修改和分发。

GCC 的编译过程可以大致分为预处理、编译、汇编和链接四个阶段。
- 预处理、编译属于编译器处理的前端。
- 汇编属于后端。
- 链接属于优化
GCC 编译过程的四个阶段与传统的三段式划分的前端、优化、后端三个阶段有一定的重合和对应关系,但 GCC 更为详细和全面地划分了编译过程,使得每个阶段的功能更加明确和独立。
2.1 预处理
例如把一个hell.c程序文件使用gcc进行编译
arduino
#include <stdio.h>
#define HELLOWORD ("hello world\n")
int main(void){
printf(HELLOWORD);
return 0;
}进行单独预处理命令:
gcc -E hello.c -o hello.i在预处理过程中,源代码会被读入,并检查其中包含的预处理指令和宏定义,然后进行相应的替换操作。此外,预处理过程还会删除程序中的注释和多余空白字符。最终生成的.i 文件包含了经过预处理后的代码内容。
2.2 编译
gcc -S hello.i -o hello.s将经过预处理的文件(hello.i)转换为特定汇编代码文件(hello.s)的过程。只是转换为了低级语言-汇编语言。在这个过程中,经过预处理后的 .i 文件作为输入,通过编译器(ccl)生成相应的汇编代码 .s 文件。编译器(ccl)是 GCC 的前端,其主要功能是将经过预处理的代码转换为汇编代码。编译阶段会对预处理后的 .i 文件进行语法分析、词法分析以及各种优化,最终生成对应的汇编代码。
2.3 汇编
将汇编代码转换成机器指令。这一步是通过汇编器(as)完成的。汇编器是 GCC 的后端,其主要功能是将汇编代码转换成机器指令。
汇编器的工作是将人类可读的汇编代码转换为机器指令或二进制码,生成一个可重定位的目标程序,通常以 .o 作为文件扩展名。
r
gcc -c hello.s -o hello.o2.4 链接
链接过程中,链接器的作用是将目标文件与其他目标文件、库文件以及启动文件等进行链接,从而生成一个可执行文件。在链接的过程中,链接器会对符号进行解析、执行重定位、进行代码优化、确定空间布局,进行装载,并进行动态链接等操作。通过链接器的处理,将所有需要的依赖项打包成一个在特定平台可执行的目标程序,用户可以直接执行这个程序。
gcc -o hello.o -o hello- 静态链接
静态链接是指在链接程序时,需要使用的每个库函数的一份拷贝被加入到可执行文件中。通过静态链接使用静态库进行链接,生成的程序包含程序运行所需要的全部库,可以直接运行。然而,静态链接生成的程序体积较大。
- 动态链接
动态链接是指可执行文件只包含文件名,让载入器在运行时能够寻找程序所需的函数库。通过动态链接使用动态链接库进行链接,生成的程序在执行时需要加载所需的动态库才能运行。相比静态链接,动态链接生成的程序体积较小,但是必须依赖所需的动态库,否则无法执行。
-
GCC 优点
- 支持多种编程语言:不仅支持 C,还扩展支持 C++、Fortran、Java、Ada 等,满足不同开发需求。
- 跨平台支持广泛:在多种硬件架构和操作系统上运行,包括 x86、ARM、PowerPC 等,是跨平台应用开发的首选编译器。
- 使用广泛且功能完备:在开源社区和商业开发中被广泛使用,提供丰富的优化和调试功能,适用于各种应用场景。
- 基于 C 的架构:核心使用 C 语言编写,仅需 C++ 编译器即可编译,简化了编译环境的设置和维护。
-
GCC 缺点
- 代码耦合度高:内部模块间耦合度高,独立集成到专用 IDE 中较为困难,需要大量定制和修改。
- 难以作为 API 集成:设计上未考虑作为 API 集成到其他工具中,使得与其他开发工具的无缝集成复杂。
- 后期版本代码质量下降:随着功能扩展和代码量增加,部分版本的代码质量和维护性下降,增加了开发和调试难度。
- 代码量庞大:代码库约 1500万行,新开发者上手和理解项目较困难,增加了维护和开发成本。
3 LLVM编译器介绍

最开始苹果使用Gcc,苹果在增强 Objective-C 和 C 语言方面投入了大量努力,但 GCC 开发者对苹果在 Objective-C 支持方面的努力表示不满。所以第一阶段苹果基于GCC自己拉分支进行开发支持Object-C语言。
GCC 的代码过于耦合,难以独立开发。随着版本更新,代码质量逐渐下降,而 GCC 无法以模块化方式调用实现 Apple 渴望的更好集成开发环境支持,这限制了 Apple 在编译器领域的发展。第二阶段,苹果聘请了编译器领域的专家克里斯·拉特纳来领导 LLVM 项目的实现。 LLVM 项目起源于 2000 年伊利诺伊大学厄巴纳-香槟分校的维克拉姆·艾夫(Vikram Adve)和克里斯·拉特纳(Chris Lattner)的研究,旨在为所有静态和动态语言创建动态编译技术。
最初LLVM定义为低级虚拟机(Low Level Virtual Machine)的首字母缩写,但是其发展迅速概念已经超出了虚拟机的范畴,现在 LLVM 已经成为一个品牌,用于指代 LLVM 项目下的所有子项目,包括 LLVM 中介码(LLVM IR)、LLVM 调试工具、LLVM C++标准库等。
虚拟机的概念基本用在不同硬件的屏蔽之上,例如软件来模拟硬件的服务。并且其上运行的软件也可以五花八门,例如windows或者Ubuntu。所以其对软件硬件是一个超级兼容的承接,这个概念用在编译器上可以做到大一统的作用。
LLVM 项目已经迅速发展成为一个庞大的编译器工具集合。LLVM 激发了许多人为多种编程语言开发新的编译器,其中最引人注目的之一是 Clang。作为一个新的编译器,Clang 提供对 C、Objective-C 和 C++ 的支持,并且得到了苹果公司的大力支持。Clang 的目标是取代 GCC 在系统中的 C 和 Objective-C 编译器,它能够更轻松地集成到现代开发环境(IDE)中,并且支持线程的更好处理。从 Clang 3.8 版本开始,它还开始支持 OpenMP。GCC 在 Objective-C 方面的发展已经停滞,苹果已经将其支持转移到其他维护分支上。
3.1 LLVM架构
LLV组件独立性强,分层协作更加的合理。在使用 LLVM 时,前端工程师只需实现相应的前端,而无需修改后端部分,从而使得添加新的编程语言变得更加简便。这是因为后端只需要将中间表示(IR)翻译成目标平台的机器码即可。
对于后端工程师而言,他们只需将目标硬件的特性如寄存器、硬件调度以及指令调度与 IR 进行对接,而无需干涉前端部分。这种灵活的架构使得编译器的前端和后端工程师能够相对独立地进行工作,从而极大地提高了开发效率和维护性。
在 LLVM 中,IR 扮演着至关重要的角色。它是一种类似汇编语言的底层语言,但具有强类型和精简指令集的特点(RISC),并对目标指令集进行了抽象。例如,在 IR 中,目标指令集的函数调用惯例会被抽象为 call 和 ret 指令,并使用明确的参数。
LLVM 支持三种不同的 IR 表达形式:人类可读的汇编形式、在 C++ 中的对象形式以及序列化后的 bitcode 形式。这种多样化的表达形式使得开发人员更好地理解和处理 IR,从而实现更加灵活和高效的编译工作。通过 IR 的抽象和统一,LLVM 极大地推动了编译体系的创新,为编程语言的快速开发和跨平台支持提供了强大的基础。
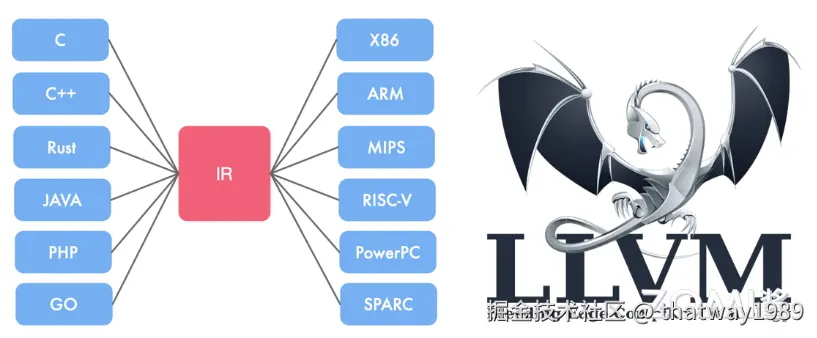
LLVM 提供了一套适用于编译器系统的中间语言(Intermediate Representation,IR),并围绕这个中间语言进行了大量的变换和优化。经过这些变换和优化,IR 可以被转换为目标平台相关的汇编语言代码。
LLVM IR 的优点包括:
- 更独立:LLVM IR 设计为可在编译器之外的任意工具中重用,使得轻松集成其他类型的工具,如静态分析器和插桩器成为可能。
- 更正式:拥有明确定义和规范化的 C++ API,使得处理、转换和分析变得更加便捷。
- 更接近硬件:LLVM IR 提供了类似 RISCV 的模拟指令集和强类型系统,实现了其"通用表示"的目标。具有足够底层指令和细粒度类型的特性使得上层语言和 IR 的隔离变得简单,同时 IR 的行为更接近硬件,为进一步在 LLVM IR 上进行分析提供了可能性。
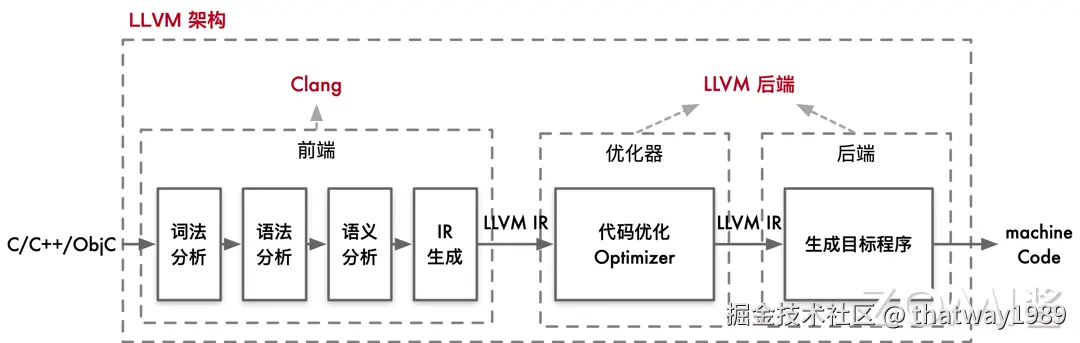
- 前端(Front-End):负责处理高级语言(如 C/C++/Obj-C)的编译,生成中间表示(IR)。
- 优化器(Optimizer):对中间表示进行各种优化,提高代码执行效率。
- 后端(Back-End):将优化后的中间表示转换为目标平台的机器码。
当用户编写的 C/C++/Obj-C 代码输入到 Clang 前端时,Clang 会执行以下步骤:
- 词法分析(Lexical Analysis):将源代码转换为标记(tokens)。
- 语法分析(Syntax Analysis):将标记转换为抽象语法树(AST)。
- 语义分析(Semantic Analysis):检查语义正确性,生成中间表示(IR)。
生成的抽象语法树(AST)通过进一步处理,转换为 LLVM 的中间表示(IR)。这个中间表示是一种平台无关的低级编程语言,用于连接前端和后端。
LLVM 的优化器通过多个优化 pass 来提升中间表示(IR)的性能。每个 pass 都对 IR 进行特定的优化操作,例如:
- 常量折叠(Constant Folding):将编译时已知的常量表达式直接计算并替换。
- 循环优化(Loop Optimizations):如循环展开、循环交换等,以提高循环执行效率。
- 死代码消除(Dead Code Elimination):移除不必要的代码,提高执行效率。 经过优化后的 IR 是一个更高效的中间表示,准备好进行后续的代码生成。
LLVM 的后端负责将优化后的中间表示转换为目标平台的机器码。这包含以下步骤:
- 指令选择(Instruction Selection):将 IR 转换为目标架构的汇编指令。
- 寄存器分配(Register Allocation):为指令分配合适的寄存器。
- 指令调度(Instruction Scheduling):优化指令执行顺序,以提高指令流水线的效率。
- 代码布局(Code Layout):调整代码的排列顺序,以适应目标硬件的执行特性。
- 代码生成(Code Generation):生成目标平台的汇编代码和最终的机器码。 最终,LLVM 后端输出目标平台的可执行文件。
LLVM 的整体架构清晰地分为前端、优化器和后端三个部分。用户与 Clang 前端直接交互,输入高级语言代码,而 Clang 将其转换为中间表示。之后,LLVM 的优化器和后端在后台处理,进行复杂的优化和代码生成步骤,最终输出高效的目标机器码。
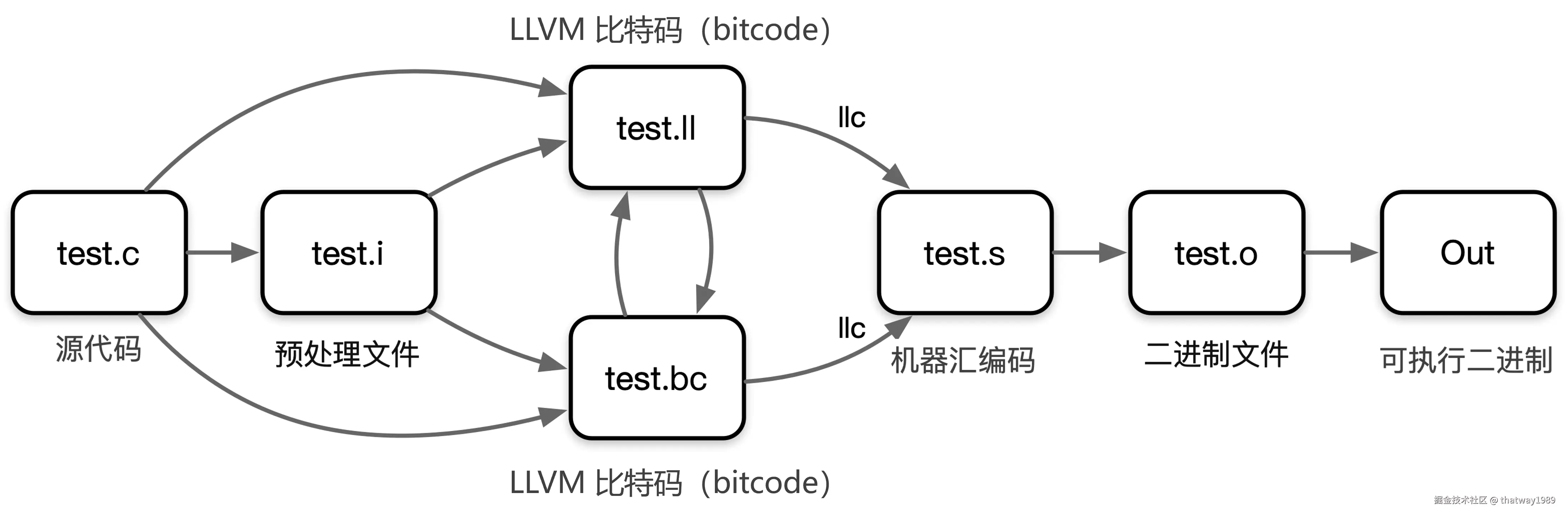
- 在使用 LLVM 时,我们会从原始的 C 代码开始。使用 Clang 的预处理器将 hello.c 文件中的所有预处理指令展开,生成预处理后的文件 hello.i。
r
clang -E -c .\hello.c -o .\hello.i- 接下来使用 LLVM 的前端工具将中间表示文件编译成 IR。IR 的表示有两种方式,一种是 LLVM 汇编语言(.ll 文件),另一种是 LLVM 比特码(.bc 文件)。LLVM 汇编语言更为易读,方便人类阅读和理解。
r
clang -emit-llvm .\hello.i -c -o .\hello.bc
clang -emit-llvm .\hello.c -S -o .\hello.ll-
IR 经过 LLVM 的后端编译器工具 llc 将 IR 转换为汇编代码(assembly code)。这个汇编代码是目标机器特定机器码指令的文本表示。
llc .\hello.ll -o .\hello.s
llc .\hello.bc -o .\hello2.s
最后的两个步骤是将汇编代码汇编(assemble)成机器码文件,然后链接(link)生成可执行二进制文件,使其可以在特定平台上运行。
clang .\hello.s -o hello3.2 LLVM IR介绍
LLVM IR 提供了一种抽象层,使程序员可以更灵活地控制程序的编译和优化过程,同时保留了与硬件无关的特性。通过使用 LLVM IR,开发人员可以更好地理解程序的行为,提高代码的可移植性和性能优化的可能性。
在 LLVM 中不管是前端、优化层、还是后端都有大量的 IR,使得 LLVM 的模块化程度非常高,可以大量的复用一些相同的代码,非常方便的集成到不同的 IDE 和编译器当中。
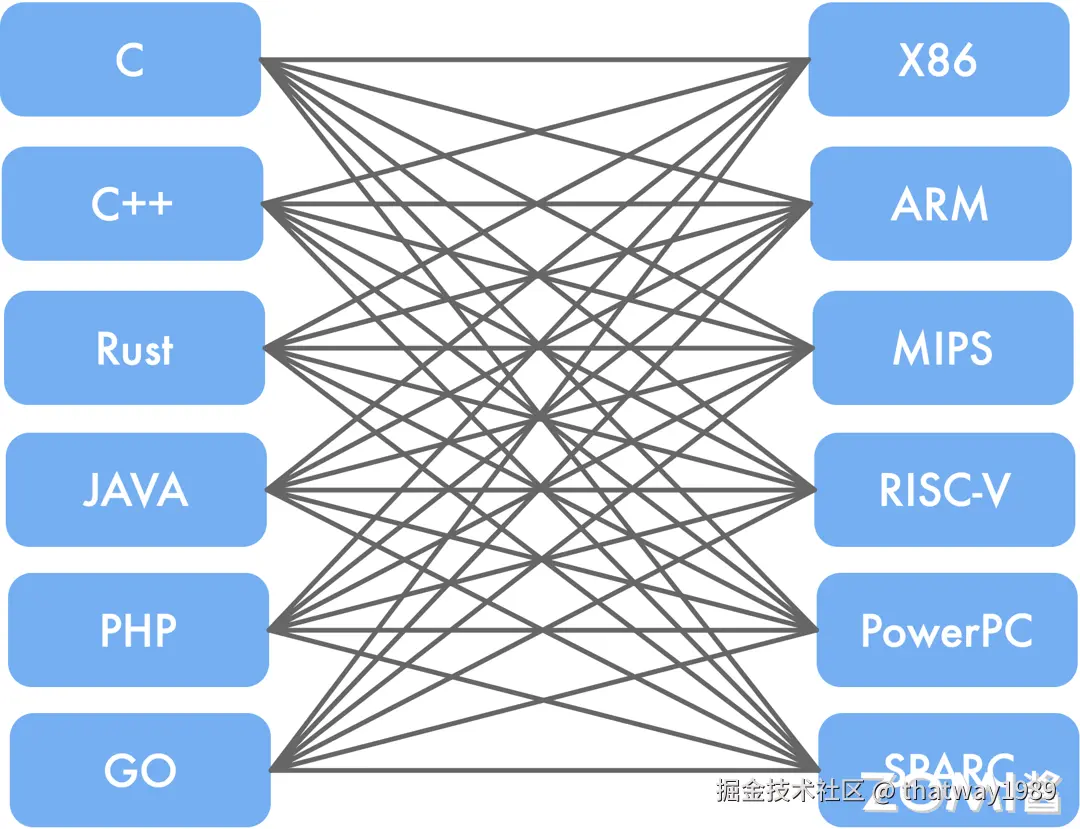
经过中间表示 IR 这种做法相对于直接将源代码翻译为目标体系结构的好处主要有两个:
- 有一些优化技术是目标平台无关的,我们只需要在 IR 上做这些优化,再翻译到不同的汇编,这样就能够在所有支持的体系结构上实现这种优化,这大大的减少了开发的工作量。
- 其次,假设我们有 m 种源语言和 n 种目标平台,如果我们直接将源代码翻译为目标平台的代码,那么我们就需要编写 m * n 个不同的编译器。然而,如果我们采用一种 IR 作为中转,先将源语言编译到这种 IR ,再将这种 IR 翻译到不同的目标平台上,那么我们就只需要实现 m + n 个编译器。
值得注意的是,LLVM 并非使用单一的 IR 进行表达,前端传给优化层时传递的是一种抽象语法树(Abstract Syntax Tree,AST)的 IR。因此 IR 是一种抽象表达,没有固定的形态。
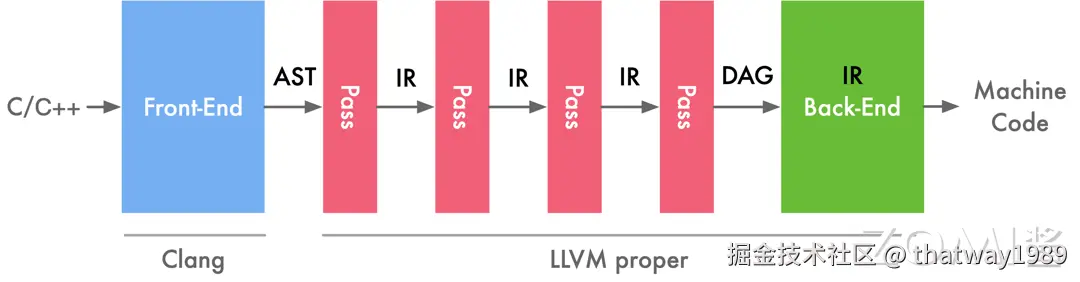
抽象语法树的作用在于牢牢抓住程序的脉络,从而方便编译过程的后续环节(如代码生成)对程序进行解读。AST 就是开发者为语言量身定制的一套模型,基本上语言中的每种结构都与一种 AST 对象相对应。
在中端优化完成之后会传一个 DAG 图的 IR 给后端,DAG 图能够非常有效的去表示硬件的指定的顺序。
DAG(Directed Acyclic Graph,有向无环图)是图论中的一种数据结构,它是由顶点和有向边组成的图,其中顶点之间的边是有方向的,并且图中不存在任何环路(即不存在从某个顶点出发经过若干条边之后又回到该顶点的路径)。
在计算机科学中,DAG 图常常用于描述任务之间的依赖关系,例如在编译器和数据流分析中。DAG 图具有拓扑排序的特性,可以方便地对图中的节点进行排序,以确保按照依赖关系正确地执行任务。
编译的不同阶段会产生不同的数据结构和中间表达,如前端的抽象语法树(AST)、优化层的 DAG 图、后端的机器码等。后端优化时 DAG 图可能又转为普通的 IR 进行优化,最后再生产机器码。
LLVM IR 具有三种表示形式,这三种中间格式是完全等价的:
- 在内存中的编译中间语言(无法通过文件的形式得到的指令类等)
- 在硬盘上存储的二进制中间语言(格式为.bc)
- 人类可读的代码语言(格式为.ll)
以.ll文件为例进行说明
arduino
#include <stdio.h>
int main()
{
int a = 10;
if(a%2 == 0)
return 0;
else
return 1;
}在经过编译后的 .ll 文件的内容如下所示:
perl
define i32 @main() #0 {
entry:
%retval = alloca i32, align 4
%a = alloca i32, align 4
store i32 0, i32* %retval, align 4
store i32 10, i32* %a, align 4
%0 = load i32, i32* %a, align 4
%rem = srem i32 %0, 2
%cmp = icmp eq i32 %rem, 0
br i1 %cmp, label %if.then, label %if.else
if.then: ; preds = %entry
store i32 0, i32* %retval, align 4
br label %return
if.else: ; preds = %entry
store i32 1, i32* %retval, align 4
br label %return
return: ; preds = %if.else, %if.then
%1 = load i32, i32* %retval, align 4
ret i32 %1
}icmp 指令是根据比较规则,比较两个操作数,将比较的结果以布尔值或者布尔值向量返回,且对于操作数的限定是操作数为整数或整数值向量、指针或指针向量。其中,eq 是比较规则,%rem 和 0 是操作数,i32 是操作数类型,比较 %rem 与 0 的值是否相等,将比较的结果存放到 %cmp 中。
br 指令有两种形式,分别对应于条件分支和无条件分支。该指令的条件分支在形式上接受一个"i1"值和两个"label"值,用于将控制流传输到当前函数中的不同基本块,上面这条指令是条件分支,类似于 c 中的三目条件运算符 < expression ?Statement:statement>;无条件分支的话就是不用判断,直接跳转到指定的分支,类似于 c 中 goto ,比如说这个就是无条件分支 br label %return。br i1 %cmp, label %if.then, label %if.else 指令的意思是,i1 类型的变量 %cmp 的值如果为真,执行 if.then 否则执行 if.else。
LLVM IR 的设计理念类似于精简指令集(RISC),这意味着它倾向于使用简单且数量有限的指令来完成各种操作。其指令集支持简单指令的线性序列,比如加法、减法、比较和条件分支等。这使得编译器可以很容易地对代码进行线性扫描和优化。
RISC 架构的一个重要特征是指令执行的效率较高,因为每条指令都相对简单,执行速度快。
IR中的三地址码和四元组,首先看三地址码:
每条指令最多包含三个操作数:两个源操作数和一个目标操作数。这些操作数可以是变量、常量或临时变量。
四元组:
scss
(运算符, 操作数 1, 操作数 2, 结果)- 运算符 (Operator):表示要执行的操作,例如加法(
+)、减法(-)、乘法(*)、赋值(=)等。 - 操作数 1(Operand1):第一个输入操作数。
- 操作数 2(Operand2):第二个输入操作数(有些指令可能没有这个操作数)。
- 结果(Result):操作的输出结果存储的位置。
| 指令类型 | 指令格式 | 四元组表示 |
|---|---|---|
| 赋值指令 | z = x | (=, x, ``, z) |
| 算术指令 | z = x op y | (op, x, y, z) |
| 一元运算 | z = op y | (op, y, ``, z) |
| 条件跳转 | if x goto L | (if, x, ``, L) |
| 无条件跳转 | goto L | (goto, , , L) |
| 函数调用 | z = call f(a, b) | (call, f, (a,b), z) |
| 返回指令 | return x | (return, x, , ) |
三地址码举例:
perl
%result = add i32 %a, %b在这条指令中,%a 和 %b 是输入操作数,add 是运算符,%result 是结果。因此这条指令可以表示为四元组:
perl
(add, %a, %b, %result)LLVM IR 基本单位
- Module
一个 LLVM IR 文件的基本单位是 Module。它包含了所有模块的元数据,例如文件名、目标平台、数据布局等。
ini
; ModuleID = '.\test.c'
source_filename = ".\test.c"
target datalayout = "e-m:w-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-w64-windows-gnu"Module 类聚合了整个翻译单元中用到的所有数据,是 LLVM 术语中的"module"的同义词。可以通过 Module::iterator 遍历模块中的函数,使用 begin() 和 end() 方法获取这些迭代器。
- Function
在 Module 中,可以定义多个函数(Function),每个函数都有自己的类型签名、参数列表、局部变量列表、基本块列表和属性列表等。
perl
; Function Attrs: noinline nounwind optnone uwtable
define dso_local void @test(i32 noundef %0, i32 noundef %1) #0 {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i32, align 4
store i32 %0, ptr %3, align 4
store i32 %1, ptr %4, align 4
%6 = load i32, ptr %3, align 4
%7 = load i32, ptr %4, align 4
%8 = add nsw i32 %6, %7
store i32 %8, ptr %5, align 4
ret void
}Function 类包含有关函数定义和声明的所有对象。对于声明(可以用 isDeclaration() 检查),它仅包含函数原型。无论是定义还是声明,它都包含函数参数列表,可通过 getArgumentList() 或者 arg_begin() 和 arg_end() 方法访问。
- BasicBlock
每个函数可以有多个基本块(BasicBlock),每个基本块由若干条指令(Instruction)组成,最后以一个终结指令(terminator instruction)结束。
BasicBlock 类封装了 LLVM 指令序列,可通过 begin()/end() 访问它们。你可以利用 getTerminator() 方法直接访问它的最后一条指令,还可以通过 getSinglePredecessor() 方法访问前驱基本块。如果一个基本块有多个前驱,就需要遍历前驱列表。
- Instruction
Instruction 类表示 LLVM IR 的运算原子,即单个指令。
可以通过一些方法获得高层级的断言,例如 isAssociative(),isCommutative(),isIdempotent() 和 isTerminator()。精确功能可以通过 getOpcode() 方法获知,它返回 llvm::Instruction 枚举的一个成员,代表 LLVM IR opcode。操作数可以通过 op_begin() 和 op_end() 方法访问,这些方法从 User 超类继承而来。
3.3 LLVM 前端-Clang输出AST
LLVM 的前端其实是把源代码也就是 C、C++、Python 这些高级语言变为编译器的中间表示 LLVM IR 的过程。
通过 Clang 的三个关键步骤:词法分析、语法分析和语义分析,源代码被逐步转化为高效的中间表示形式,为进一步的优化和目标代码生成做准备。
- 词法分析阶段负责将源代码分解为各种标记的流,例如关键字、标识符、运算符和常量等,这些标记构成了编程语言的基本单元。
- 语法分析器则负责根据编程语言的语法规则,将这些标记流组织成符合语言语法结构的语法树。
- 语义分析阶段则确保语法树的各部分之间的关系和含义是正确的,比如类型匹配、变量声明的范围等,以确保程序的正确性和可靠性。

每个编程语言前端都会有自己的词法分析器、语法分析器和语义分析器,它们的任务是将程序员编写的源代码转换为通用的抽象语法树(AST),这样可以为后续的处理步骤提供统一的数据结构表示。AST 是程序的一个中间表示形式,它便于进行代码分析、优化和转换。
3.3.1 词法分析器
lua
clang -cc1 -dump-tokens hello.c前端的第一个步骤处理源代码的文本输入,词法分析 lexical analyze 用于标记源代码,将语言结构分解为一组单词和标记,去除注释、空白、制表符等。每个单词或者标记必须属于语言子集,语言的保留字被变换为编译器内部表示。
ini
int 'int' [StartOfLine] Loc=<hello.c:5:1>
identifier 'main' [LeadingSpace] Loc=<hello.c:5:5>
l_paren '(' Loc=<hello.c:5:9>
void 'void' Loc=<hello.c:5:10>在编译器的工作流程中,这种精准的位置记录和符号切分过程至关重要,为后续阶段的处理提供了可靠的基础,也为代码分析提供了更深层次的支持。
3.3.2 语法分析器
分组标记的目的是为了形成语法分析器(Syntactic Analyze)可以识别并验证其正确性的数据结构,最终构建出抽象语法树(AST)。通过将代码按照特定规则进行分组,使得语法分析器能够逐级检查每个标记是否符合语法规范。
在分组标记的过程中,可以通过不同的方式对表达式、语句和函数体等不同类型的标记进行分类。这种层层叠加的分组结构可以清晰地展现代码的层次结构,类似于树的概念。对于语法分析器而言,并不需要深入分析代码的含义,只需验证其结构是否符合语法规则。
lua
clang -fsyntax-only -Xclang -ast-dump hello.c语法输出如下:
bash
TranslationUnitDecl 0x1c08a71cf28 <<invalid sloc>> <invalid sloc>
|-TypedefDecl 0x1c08a71d750 <<invalid sloc>> <invalid sloc> implicit __int128_t '__int128'
| `-BuiltinType 0x1c08a71d4f0 '__int128'
|-TypedefDecl 0x1c08a71d7c0 <<invalid sloc>> <invalid sloc> implicit __uint128_t 'unsigned __int128'
| `-BuiltinType 0x1c08a71d510 'unsigned __i以上输出结果反映了对源代码进行语法分析后得到的抽象语法树(AST)。AST 是对源代码结构的一种抽象表示,其中各种节点代表了源代码中的不同语法结构,如声明、定义、表达式等。这些节点包括:
TypedefDecl:用于定义新类型的声明,如__int128和char。RecordType:描述了记录类型,例如struct __NSConstantString_tag。FunctionDecl:表示函数声明,包括函数名称、返回类型和参数信息。ParmVarDecl:参数变量的声明,包括参数名称和类型。CompoundStmt:表示由多个语句组成的语句块。- 函数调用表达式、声明引用表达式和隐式类型转换表达式等,用于描述不同的语法结构。
- 各种属性信息,如内联属性和 DLL 导入属性,用于描述代码的特性和行为。
3.3.3 语义分析
语法分析(Syntactic Analyze)主要关注代码结构是否符合语法规则,而语义分析(Semantic Analyze)则负责确保代码的含义和逻辑正确。在语义分析阶段,编译器会检查变量的类型是否匹配、函数调用是否正确、表达式是否合理等,以确保代码在运行时不会出现逻辑错误。
语义分析的主要任务是检查代码的语义是否正确,并确保代码的类型正确。语义分析器检查代码的类型是否符合语言的类型系统,并确保代码的语义正确。
语义分析器的输出是类型无误的 AST,它是编译器后端的输入。
3.4 LLVM优化层输出IR
LLVM 优化层在输入的时候是一个 AST 语法树,输出的时候已经是一个 DAG 图。优化层每一种优化的方式叫做 pass,pass 就是对程序做一次遍历。
优化通常由分析 Pass 和转换 Pass 组成。
- 分析 Pass(Analysis Pass) :分析 Pass 用于分析程序的特定属性或行为而不对程序进行修改。它们通常用于收集程序的信息或执行静态分析,以便其他 Pass 可以使用这些信息进行进一步的优化。分析 Pass 通常是只读的,不会修改程序代码。
- 转换 Pass(Transformation Pass) :转换 Pass 用于修改程序代码以进行优化或重构。它们会改变程序的结构或行为,以改善性能或满足特定的需求。转换 Pass 通常会应用各种优化技术来重写程序的部分或整体,以产生更高效的代码。
分析 Pass 用于收集信息和了解程序的行为,而转换 Pass 则用于修改程序以实现优化或修改功能。在 LLVM 中,这两种 Pass 通常结合使用,以实现对程序进行全面优化和改进。
3.5 LLVM后端输出目标代码
LLVM 的后端是与特定硬件平台紧密相关的部分,它负责将经过优化的 LLVM IR 转换成目标代码,这个过程也被称为代码生成(Codegen)。不同硬件平台的后端实现了针对该平台的专门化指令集,例如 ARM 后端实现了针对 ARM 架构的汇编指令集,X86 后端实现了针对 X86 架构的汇编指令集,PowerPC 后端实现了针对 PowerPC 架构的汇编指令集。
在代码生成过程中,LLVM 后端会根据目标硬件平台的特性和要求,将 LLVM IR 转换为适合该平台的机器码或汇编语言。这个过程涉及到指令选择(Instruction Selection)、寄存器分配(Register Allocation)、指令调度(Instruction Scheduling)等关键步骤,以确保生成的目标代码在目标平台上能够高效运行。
LLVM 的代码生成能力使得开发者可以通过统一的编译器前端(如 Clang)生成针对不同硬件平台的优化代码,从而更容易实现跨平台开发和优化。同时,LLVM 后端的可扩展性也使得它能够应对新的硬件架构和指令集的发展,为编译器技术和工具链的进步提供了强大支持。
整个后端流水线涉及到四种不同层次的指令表示,包括:
- 内存中的 LLVM IR:LLVM 中间表现形式,提供了高级抽象的表示,用于描述程序的指令和数据流。
- SelectionDAG 节点:在编译优化阶段生成的一种抽象的数据结构,用以表示程序的计算过程,帮助优化器进行高效的指令选择和调度。
- Machinelnstr:机器相关的指令格式,用于描述特定目标架构下的指令集和操作码。
- MCInst:机器指令,是具体的目标代码表示,包含了特定架构下的二进制编码指令。
在将 LLVM IR 转化为目标代码需要非常多的步骤,其 Pipeline 如下图所示:
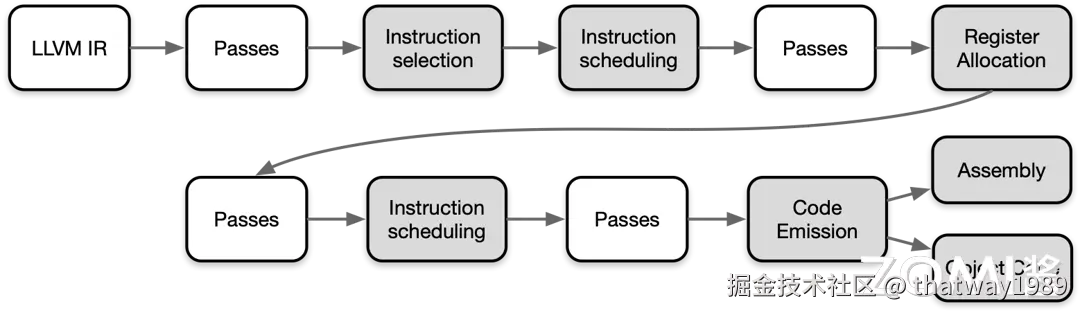 LLVM IR 会变成和后端非常很接近的一些指令、函数、全局变量和寄存器的具体表示,流水线越向下就越接近实际硬件的目标指令。其中白色的 pass 是非必要 pass,灰色的 pass 是必要 pass,叫做 Super Path
LLVM IR 会变成和后端非常很接近的一些指令、函数、全局变量和寄存器的具体表示,流水线越向下就越接近实际硬件的目标指令。其中白色的 pass 是非必要 pass,灰色的 pass 是必要 pass,叫做 Super Path
后端阶段总结为:
- 指令选择(Instruction Selection):根据目标平台特性选择合适的指令。
- 寄存器分配(Register Allocation):分配寄存器以最大程度减少内存访问。
- 指令调度(Instruction Scheduling):优化指令执行顺序以减少延迟。
在 LLVM 中,Code Emission 由以下组件共同完成:
- 指令选择器(Instruction Selector) 指令选择器负责从 LLVM IR 中选择合适的目标机器指令。LLVM 使用多种指令选择算法,包括基于树模式匹配的
SelectionDAG和基于表格驱动的GlobalISel。指令选择器将中间表示转化为机器指令的中间表示。 - 指令调度器(Instruction Scheduler) 指令调度器优化指令的执行顺序,以减少依赖关系和提高指令级并行性。LLVM 的调度器包括
SelectionDAG调度器和机器码层的调度器,后者在目标机器码生成前优化指令序列。 - 寄存器分配器(Register Allocator) 寄存器分配器负责将虚拟寄存器映射到物理寄存器。LLVM 提供了多种寄存器分配算法,包括线性扫描分配器和基于图着色的分配器。寄存器分配器的目标是最小化寄存器溢出和寄存器间的冲突。
- 汇编生成器(Assembly Generator) 汇编生成器将优化后的机器指令转化为汇编代码。LLVM 的汇编生成器支持多种目标架构,生成的汇编代码可以通过汇编器转化为目标机器码。
- 机器代码生成器(Machine Code Generator) 机器代码生成器将汇编代码转化为最终的二进制机器代码。LLVM 的机器代码生成器直接生成目标文件或内存中的可执行代码,支持多种目标文件格式和平台。
通过这些组件的协同工作,LLVM 在 Code Emission 阶段能够生成高效、正确的目标代码,满足不同应用场景的性能需求。LLVM 的模块化设计和丰富的优化技术使其成为现代编译器技术的领先者。
后记:
本节介绍了编译器的基础知识,接下来就是新的NPU硬件带来软件编译上的挑战,需要修改编译器把NPU硬件对应的机器指令用上,并且最大化的提高利用率,工作应该主要在LLVM后端针对硬件的优化,针对前端的优化应该有开源或者其他人给做了。