css定位元素
1.什么是css?
CSS(Cascading Style Sheets)层叠样式表,是一种语言,用来描述html或者xml的显示样式。在css语言中有css选择器,在selenium中同样适用。
提示:在selenium中相比较xpath,更推荐使用css选择器,因为css速度更快
2.css定位方法
driver.find_element_by_css_selector()
3.css定位常用策略
- id选择器,通过id属性定位
- class选择器,通过class属性定位
- 元素选择器,通过元素定位
- 属性选择器,通过属性定位
- 层级选择器,用空格或者大于号表示层级关系
3.1 id选择器
以百度首页为例,通过id选择就只需要:#su
driver.find_element_by_css_selector('#su')
#表示后面跟的是id的属性值,'#su'意思是id属性为'su'的元素
3.2 class选择器
上面的例子可以找到"百度一下"这个按钮,如果想通过class属性找的话,就:.bg s_btn
'.'这个点表示后面跟的是class属性的值,driver.find_element_by_css_selector('.bg s_btn')就是通过class属性查找属性值为'bg s_btn'的元素
3.3元素选择器
input就是查找所有input元素
driver.find_element_by_css_selector('input')
3.4 属性选择器
id = 'su'查找id属性为'su'的元素,等同于#su
driver.find_element_by_css_selector('name='ie'')
3.5 层级选择器
根据元素的父子关系来选择,格式为 element > element 大于号可以用空格代替
driver.find_element_by_css_selector('div > name='ie'')这个就是查找div下的name属性为ie的元素
注意:直接子节点才可以用>
3.6 css延伸
inputtype\^='P' 找一个input元素,type属性的值以P开头
inputtype$='d' 找一个input元素,type属性的值以d结尾
inputtype\*='w' 找一个input元素,type属性的值包含w
xpath路径选择器定位元素
xpath简介
使用路径表达式来定位xml或者html中文档中选取节点。在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)
假设xml文档为:
XML
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>- 文档节点:<bookstore>
- 元素节点:<author>J K. Rowling</author>
- 属性节点:lang="en"
- 文本:2005
- 父节点(Parent):每个元素以及属性都有一个父。book 元素是 title、author、year 以及 price 元素的父
- 子节点(Children):节点可有零个、一个或多个子节点。title、author、year 以及 price 元素都是 book 元素的子
- 同胞(Sibling):拥有相同的父的节点。title、author、year 以及 price 元素都是同胞
- 先辈(Ancestor):某节点的父、父的父,等等。title 元素的先辈是 book 元素和 bookstore 元素
- 后代(Descendant):某个节点的子,子的子,等等。bookstore 的后代是 book、title、author、year 以及 price 元素
基础语法
路径表达式
|----------|-------------------------------------|
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。(可以理解为后面跟的是绝对路径) |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。(相对路径) |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。后面跟属性名 |
谓语(Predicates)
放在方括号\[\]中,相当于筛选条件,用来查找\[\]中指定的特定节点或者包含某个指定的值的节点。在下面的表格中,列出了带有谓语的一些路径表达式,以及表达式的结果:
|---------------------------------------|----------------------------------------------------------------------------------------------------------------|
| 路径表达式 | 结果 |
| /bookstore/book1 | 选取属于 bookstore 子元素的第一个 book 元素。 /表示绝对路径,所以后面跟的是根节点bookstore,\[\]内部的数字表示第几个\[\]前面的元素,也就是第1个book元素,注意这里的编号是从1开始。 |
| /bookstore/booklast() | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/booklast()-1 | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/bookposition()\<3 | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title@lang | @lang表示lang属性,//title表示选取所有title元素,这个表达式表示的是选取所有带 lang 属性的 title 元素。 |
| //title@lang='eng' | 选取所有 title 元素,且元素的lang属性值为eng |
| /bookstore/bookprice\>35.00 | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/bookprice\>35.00/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
XPath 通配符可用来选取未知的 XML 元素。
|--------|------------|
| 通配符 | 描述 |
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
在下面的表格中,列出了一些路径表达式,以及这些表达式的结果:
|----------------|------------------------|
| 路径表达式 | 结果 |
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title@\* | 选取所有带有属性的 title 元素。 |
xpath轴
亲属关系匹配
|------------------------|--------------------------------------------------------------------------|
| 例子 | 结果 |
| /bookstore/child::book | child表示子节点,child::book就是子节点名为book的节点,整个表达式就是说bookstore节点的所有子节点名字为book的节点 |
| attribute::lang | attribute表示属性名,表达式为选取当前节点的 lang 属性。 |
| child::* | 选取当前节点的所有子元素。 |
| attribute::* | 选取当前节点的所有属性。 |
| child::text() | 选取当前节点的所有文本子节点。 |
| child::node() | 选取当前节点的所有子节点。 |
| descendant::book | 选取当前节点的所有 book 后代。 |
| ancestor::book | 选择当前节点的所有 book 先辈。 |
| ancestor-or-self::book | 选取当前节点的所有 book 先辈以及当前节点(如果此节点是 book 节点) |
| child::*/child::price | 选取当前节点的所有 price 孙节点。 |
| parent::* | 找到父级元素 |
| following::* | 选取文档中当前节点的结束标签之后的所有节点 |
| preceding::* | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling::* | 选取当前节点之前的所有同级节点 |
| following-sibling::* | 选取当前节点之后的所有同级节点 |
| descendant::* | 选取当前节点的所有后代元素(子、孙等) |
例如有一段html的内容如下
<div>
<span>text</span>
<input id = '123'>
</div>
此时如果想要获取第二个span标签,可以这样写:
//input@id='123'/preceding-sibling::span
input标签比较好找,先找到input标签,然后找它的兄弟节点。preceding-sibling表示找前面的元素的同级元素,后面的::span表示找的是span标签。
Xpath运算符
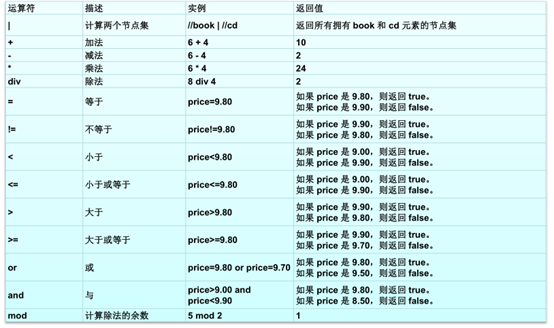
-
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
|----------------------------------|-----------------------------------------------------------|
| 路径表达式 | 结果 |
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 ||------------|-----------------------|
| 实例 | 返回值 |
| last() | 返回当前上下文中的最后一个节点的位置号码数 |
| position() | 返回当前节点的位置的数字,位于第多少个 |//bookposition()=2等价于//book2
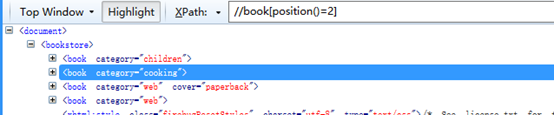
例子:
|-------------------------------------------------------------|------------------------------|
| 路径表达式 | 结果 |
| //divlast() | 最后一个div |
| //divlast()-1 | 倒数第二个div |
| //divposition()\<3 | 前两个div |
| //div@id='id3'//plast() | 第三个div中最后一个p标签对象 |
| //div@href='http://www.baidu.com' | 选取连接为http://www.baidu.com的属性 |
| //*@id='id3'//pcontain(.,'20') | 在第3个div中找包含20的文本节点 |
| //*@id='id3'//pcontain(.,'20')//fowing-sibiling::p | 选取包含字符串20文本节点的下一个节点的p节点 |补充几个常用方法
contains
包含,比如//divcontains(@class,'xx')
查找div元素,元素的class属性值包含xx
starts-with
以某某开头,例如
//inputstarts-with(@class,'xx')
查找input元素,元素的class属性值以xx开头
ends-with
以某某结尾,例如:
//inputends-with(@class,'xx')
查找input元素,元素的class属性值以xx结尾
not
否定的意思,比如:
inputnot(id='123')
查找id值不是123的input元素。
//spannot(contains(text(),'123'))
查找一个文本内容不包含123的span标签。
*通配符
*表示通配符,比如://span@\*='123'
span标签的任何属性为123的元素
定位原则
以百度首页为例
bash1) 用id定位,比如//input[@id="su"] 2) 用元素文本 比如//input[@value="百度一下"] 3) 用元素的唯一属性,找到这个元素的唯一属性,写法同上 4) 用元素的多个属性组合,比如//*[@id="kw" and @name ="wd"] 5) contains模糊匹配,比如//div[@id="u"]/a[contains(.,"录")]。或者可以写//div[@id="u"]/a[contains(@href,"passport")] 6) 找到已查找的元素,然后基于此元素的相对位置定位,比如先找到一个div,再通过找到的这个div找他的父亲或者兄弟,子女。//div[@id="u"]/child::node(),先找到一个id属性为u的div,再找到这个div的所有孩子节点,后面跟[1],就是这些孩子节点的第一个节点。css元素定位和xpath元素定位的对比
|-------|--------------------------------------------------------------------------------|------------------------------------------------------------------|
| 定位方式 | xpath | css |
| 元素名 | //input | input |
| id | //input@id='su' | #su |
| class | //input@class='su' | .su |
| 属性 | //*starts_with(@属性名,'XXX') //*contains(@属性名,'XXX') //*text()="" | inputtype$='XXX' inputtype\*='XXX' inputtype\^='XXX' |