文章目录
- 一、Redis是什么?
-
- [1. 核心特性](#1. 核心特性)
- [2. Redis和MySQL的区别](#2. Redis和MySQL的区别)
- [3. 应用(kv适合场景)](#3. 应用(kv适合场景))
- [4. 本地部署Redis](#4. 本地部署Redis)
- 二、Redis怎么组织数据的?
-
- [1. redis的存储结构](#1. redis的存储结构)
- [2. 为什么redis中字符串选择64字节为分界线](#2. 为什么redis中字符串选择64字节为分界线)
- [3. 增删改查指令](#3. 增删改查指令)
- 三、Redis的value编码
-
- [0. redis是怎么设计KV?](#0. redis是怎么设计KV?)
- [1. string](#1. string)
- [2. list](#2. list)
- [3. hash](#3. hash)
- [4. set](#4. set)
- [5. zset](#5. zset)
一、Redis是什么?
Redis是一个开源的、基于内存的键值型数据库,支持丰富的数据结构和高性能的操作。(Redis是内存数据库、KV数据库、数据结构数据)
1. 核心特性
数据存储在内存中
所有数据保存在内存中,访问速度非常快(微秒级),可选持久化机制(RDB 快照、AOF 日志)可以将数据写入磁盘以防丢失
KV键值存储 + 多种数据结构
Redis不只是传统的key → string,它还支持:list,hash,set,zset等
2. Redis和MySQL的区别
| 项目 | Redis | MySQL |
|---|---|---|
| 存储介质 | 内存为主(可持久化) | 磁盘 |
| 数据模型 | 键值+多结构 | 表格+关系型 |
| 性能 | 高速,适合缓存 | 较慢,适合存储 |
| 使用场景 | 缓存、排行榜、消息队列 | 持久化存储、复杂查询 |
| 支持事务 | 基础事务支持 | 完整事务机制(ACID) |
3. 应用(kv适合场景)

4. 本地部署Redis
python
[下载源码]
git clone https://gitee.com/mirrors/redis.git -b 6.2
cd redis
make
----------or------------
wget http://download.redis.io/releases/redis-7.2.4.tar.gz
tar -xzf redis-7.2.4.tar.gz
cd redis-7.2.4
[编译]
make -j4 # -j4 表示用4线程并行编译
# 默认安装在 /usr/local/bin
# redis-server 是服务端程序
# redis-cli 是客户端程序
-------------------------
[启动]
mkdir redis-data
# 把redis文件夹下 redis.conf 拷贝到 redis-data
# 修改 redis.conf
vim redis.conf
requirepass 123456
./src/redis-server redis.conf
# 用这个配置文件启动
# daemonize yes
cd redis-data
redis-server ./redis.conf
# 通过 redis-cli 访问 redis-server
redis-cli -h 127.0.0.1 -a 123456
--------------------------
[断开输入]
exit二、Redis怎么组织数据的?
1. redis的存储结构
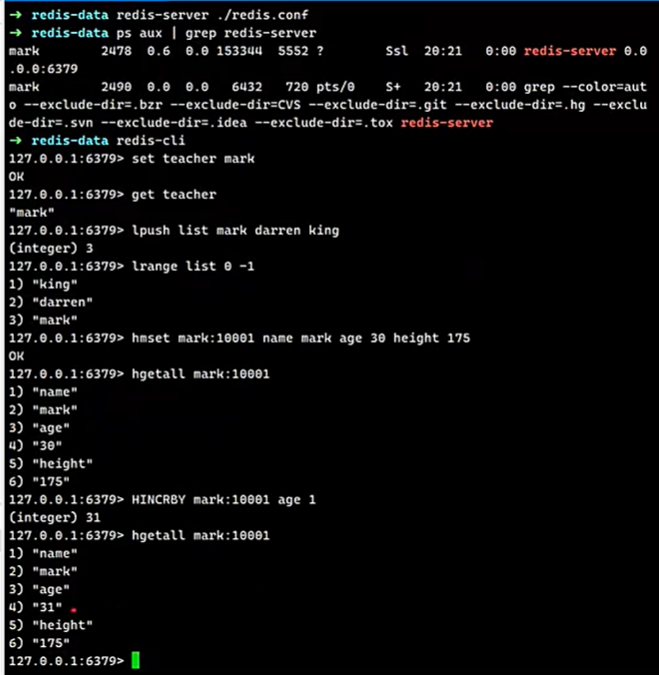
Redis 是典型的 键值对Key-Value数据库,每一个键值对的本质是:
c
dict<key, redisObject* value>
+ key:通常是字符串
+ value:是一个指针,内部根据实际类型存储数据

2. 为什么redis中字符串选择64字节为分界线
| 原因 | 说明 |
|---|---|
| 内存分配优化 | 小于64字节的字符串能映射到更小的内存块,避免浪费 |
| CPU缓存优化 | 64字节正好是cache line大小,提高访问效率 |
| SDS优化策略 | Redis会针对短字符串启用更激进的性能优化策略 |
| 内存碎片控制 | 避免频繁内存分配、释放引起的碎片化 |
3. 增删改查指令
- string\list\hash
- set\zset
三、Redis的value编码
0. redis是怎么设计KV?

Redis 会根据 数据的类型 + 内容大小 + 特性 来动态的选择最优的编码方式,即省内存又加快速度。

指令自己熟悉实现一遍, 带着场景思考怎么设计
1. string
基础命令
-
string字符数组,该字符串是动态字符串raw。
字符串长度小于1M时,加倍扩容;
超过1M每次多扩1M;字符串最大长度为512M;
-
注意:redis字符串是二进制安全字符串,可以存储图片,二进制协议等二进制数据。
python
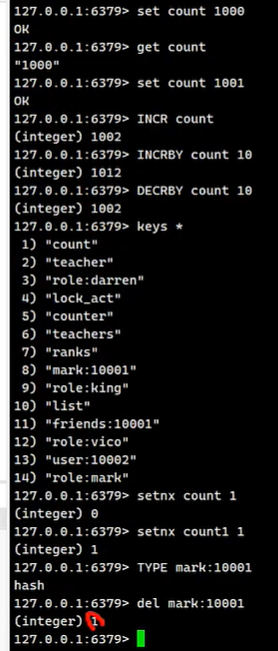
# 设置 key 的 value 值
SET key val
# 获取 key 的 value
GET key
# 执行原子加一的操作
INCR key
# 执行原子加一个整数的操作
INCRBY key increment
# 执行原子减一的操作
DECR key
# 执行原子减一个整数的操作
DECRBY key decrement
# 如果key不存在,这种情况下等同SET命令。 当key存在时,什么也不做
# set Not eXist ok 这个命令是否执行了 0,1 是不是操作结果是不是成功
SETNX key value
# 删除 key val 键值对
DEL key
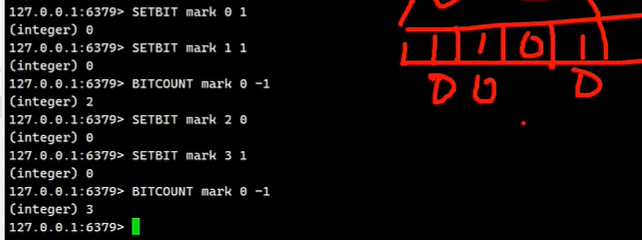
# 设置或者清空key的value(字符串)在offset处的bit值。 setbit embstr raw int
# 动态字符串 能够节约内存
SETBIT key offset value
# 返回key对应的string在offset处的bit值
GETBIT key offset
# 统计字符串被设置为1的bit数.
BITCOUNT key实操
存储结构
字符串长度<= 20 且能转成整数,则使用 int 存储;
字符串长度<= 44,则使用 embstr 存储;
字符串长度> 44,则使用 raw 存储;
应用(对象存储 |累加器 |分布式锁 |位运算)
cpp
【1.对象存储】
SET role:10001 '{["name"]:"kk",["sex"]:"male",["age"]:30}'
SET role:10002 '{["name"]:"mm",["sex"]:"male",["age"]:30}'
# 极少修改,对象属性字段很少改变的时候
GET role:10001
------------------------------------------
【2.累加器】
#统计阅读数 累计加1
incr reads
# 累计加100
incrby reads 100
------------------------------------------
【3.分布式锁】
# 加锁 加锁 和 解析 redis 实现是 非公平锁 ectd zk 用来实现公平锁
# 阻塞等待 阻塞连接的方式
# 介绍简单的原理: 事务
setnx lock 1 # 不存在才能设置 定义加锁行为 占用锁
setnx lock uuid # expire 30 过期
set lock uuid nx ex 30
# 释放锁
del lock
if (get(lock) == uuid)
del(lock);
------------------------------------------
【4.位运算】
# 猜测一下 string 是用的 int 类型 还是 string 类型
# 月签到功能 10001 用户id 202106 2021年6月份的签到 6月份的第1天
setbit sign:10001:202106 1 1
# 计算 2021年6月份 的签到情况
bitcount sign:10001:202106
# 获取 2021年6月份 第二天的签到情况 1 已签到 0 没有签到
getbit sign:10001:202106 22. list
双向链表实现,列表首尾操作(删除和增加)时间复杂度0(1); 查找中间元素时间复杂度为O(n);
列表中数据是否压缩的依据:
1.元素长度 < 48,不压缩;
2.元素压缩前后长度 <= 8,不压缩
基础命令
python
# 从队列的左侧入队一个或多个元素
LPUSH key value [value ...]
# 从队列的左侧弹出一个元素
LPOP key
# 从队列的右侧入队一个或多个元素
RPUSH key value [value ...]
# 从队列的右侧弹出一个元素
RPOP key
# 返回从队列的 start 和 end 之间的元素 0, 1 2 负索引
LRANGE key start end
# 从存于 key 的列表里移除前 count 次出现的值为 value 的元素
# list 没有去重功能 hash set zset
LREM key count value
# 它是 RPOP 的阻塞版本,因为这个命令会在给定list无法弹出任何元素的时候阻塞连接
BRPOP key timeout # 超时时间 + 延时队列存储结构
cpp
/* Minimum ziplist size in bytes for attempting compression. */
#define MIN_COMPRESS_BYTES 48
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually <
32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporary decompressed for
usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small
*/
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all
ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual
nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to
compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;实操
brpop key1 value, brpop指令表示当Key1为空无元素时,该条请求被redis阻塞;
想要解除阻塞则 需要另外一个客户端设向该 key1添加数据使得该条key1 list不为空,当前客户端才会解除阻塞,并显示key1的value结果 和timeout阻塞耗时。
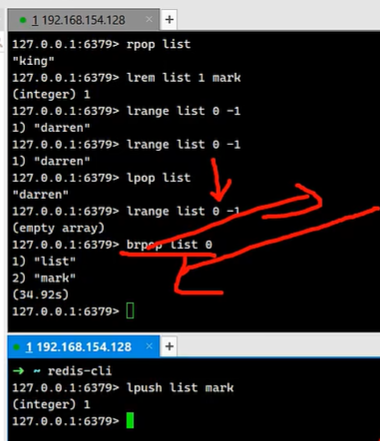
应用 (栈| 队列| 阻塞队列| 异步消息队列| 固定窗口记录)
栈、队列、阻塞队列、异步消息队列、获取固定窗口记录(裁剪维持最新的记录)
python
【1.栈(先进后出 FILO)】
LPUSH + LPOP
# 或者
RPUSH + LPOP
------------------------------------------
【2.队列(先进先出 FIFO)】
LPUSH + RPOP
# 或者
RPUSH + LPOP
------------------------------------------
【3.阻塞队列(blocking queue)】
LPUSH + BRPOP
# 或者
RPUSH + BLPOP
------------------------------------------
【4.异步消息队列】
#结合生产/消费模型,通过 List 实现轻量级消息队列,支持异步处理和消费速度差异
# 生产者写入日志消息
RPUSH logs:system "log1"
RPUSH logs:system "log2"
# 消费者阻塞式读取
BLPOP logs:system 0
------------------------------------------
【5.获取固定窗口记录】
#每次登录都插入新记录,只保留前 N 条,模拟滑动窗口效果
LPUSH login:user:1001 "2025-04-15T10:00"
LTRIM login:user:1001 0 4 # 保留最近5条3. hash
散列表,c++ unorder_map通过key快速索引value
基础命令
python
# 获取 key 对应 hash 中的 field 对应的值
HGET key field
# 设置 key 对应 hash 中的 field 对应的值
HSET key field value
# 设置多个hash键值对
HMSET key field1 value1 field2 value2 ... fieldn valuen
# 获取多个field的值
HMGET key field1 field2 ... fieldn
# 给 key 对应 hash 中的 field 对应的值加一个整数值
HINCRBY key field increment
# 获取 key 对应的 hash 有多少个键值对
HLEN key
# 删除 key 对应的 hash 的键值对,该键为field
HDEL key field存储结构
节点数量 > 512 或 所有字符串长度 > 64,(属性容易改变) 则使用dict实现;
节点数量 < 512 且 有一个字符串长度 < 64,(内容不易改变)则使用ziplist实现
应用(存储对象| 京东购物车)
不用考虑数据结构的创建,redis指令在设置的同时创建,添加的同时创建数据结构, 实际开发应用通常是组合 数据结构实现功能
-
存储对象
pythonhmset hash:10001 name mark age 18 sex male # 与 string 比较 set hash:10001 '{["name"]:"mark",["sex"]:"male",["age"]:18}' # 假设现在修改 mark的年龄为19岁 # hash: hset hash:10001 age 19 # string: get hash:10001 # 将得到的字符串调用json解密,取出字段,修改 age 值 # 再调用json加密 set hash:10001 '{["name"]:"mark",["sex"]:"male",["age"]:19}' -
购物车
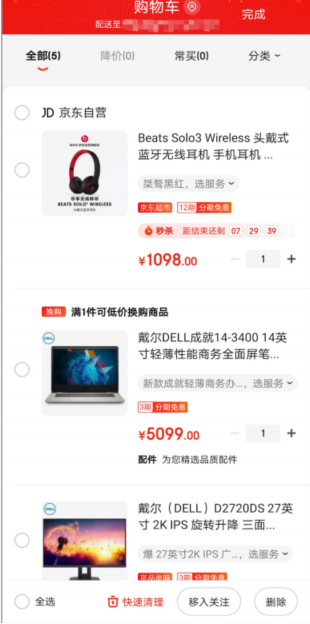 python
python# 将用户id作为 key # 商品id作为 field # 商品数量作为 value # 注意:这些物品是按照我们添加顺序来显示的; # 添加商品: hmset MyCart:10001 40001 1 cost 5099 desc "戴尔笔记本14-3400" lpush MyItem:10001 40001 # 增加数量: hincrby MyCart:10001 40001 1 hincrby MyCart:10001 40001 -1 // 减少数量1 # 显示所有物品数量: hlen MyCart:10001 # 删除商品: hdel MyCart:10001 40001 lrem MyItem:10001 1 40001 # 获取所有物品: lrange MyItem:10001 # 40001 40002 40003 hget MyCart:10001 40001 hget MyCart:10001 40002 hget MyCart:10001 40003
4. set
集合,用来存储唯一性字符,不要求有序; 存储不需要有序,
基础命令
python
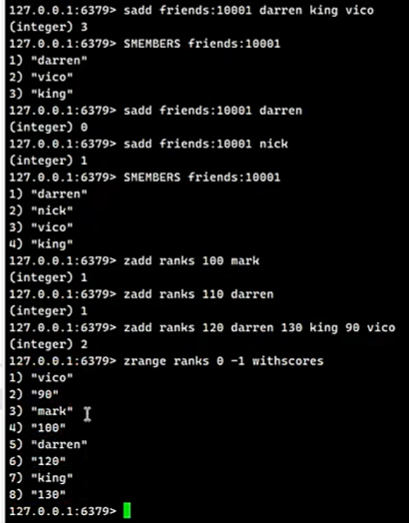
# 添加一个或多个指定的member元素到集合的 key中
SADD key member [member ...]
# 计算集合元素个数
SCARD key
# SMEMBERS key
SMEMBERS key
# 返回成员 member 是否是存储的集合 key的成员
SISMEMBER key member
# 随机返回key集合中的一个或者多个元素,不删除这些元素
SRANDMEMBER key [count]
# 从存储在key的集合中移除并返回一个或多个随机元素
SPOP key [count]
# 返回一个集合与给定集合的差集的元素
SDIFF key [key ...]
# 返回指定所有的集合的成员的交集
SINTER key [key ...]
# 返回给定的多个集合的并集中的所有成员
SUNION key [key ...]存储结构
元素都为整数且节点数量 <= 512,则使用整数数组存储;
元素当中有一个不是整数 或者 节点数量 > 512,则使用字典存储;
应用(抽奖| 共同关注| 推荐好友)
cpp
【1.抽奖】
# 添加抽奖用户
sadd Award:1 10001 10002 10003 10004 10005 10006
sadd Award:1 10009
# 查看所有抽奖用户
smembers Award:1
# 抽取多名幸运用户
srandmember Award:1 10
# 如果抽取一等奖1名,二等奖2名,三等奖3名,该如何操作?
------------------------------------------
【2.共同关注】
sadd follow:A mark king darren mole vico
sadd follow:C mark king darren
sinter follow:A follow:C
------------------------------------------
【3.推荐好友】
sadd follow:A mark king darren mole vico
sadd follow:C mark king darren
# C可能认识的人:
sdiff follow:A follow:C5. zset
有序集合,用来实现排行榜,有序唯一
基础命令
python
在# 添加到键为key有序集合(sorted set)里面
ZADD key [NX|XX] [CH] [INCR] score member [score member ...]
# 从键为key有序集合中删除 member 的键值对
ZREM key member [member ...]
# 返回有序集key中,成员member的score值
ZSCORE key member
# 为有序集key的成员member的score值加上增量increment
ZINCRBY key increment member
# 返回key的有序集元素个数
ZCARD key
# 返回有序集key中成员member的排名
ZRANK key member
# 返回存储在有序集合key中的指定范围的元素 order by id limit 1,100
ZRANGE key start stop [WITHSCORES]
# 返回有序集key中,指定区间内的成员(逆序)
ZREVRANGE key start stop [WITHSCORES]存储结构
节点数量 > 128 或者有一个字符串长度 > 64,则使用跳表(skiplist)
节点数量 <= 128 且 所有字符串长度 <= 64, 则使用ziplist
数据少的时候,节省空间, O(n)
数量多的时候,访问性能,O(n) & O(log2(n))
应用(百度热收榜 | 延时队列)
百度热榜、 延时队列、分布式定时器、时间窗口限流
-
百度热榜
 cpp
cpp# 点击新闻: zincrby hot:20230612 1 10001 zincrby hot:20230612 1 10002 zincrby hot:20230612 1 10003 zincrby hot:20230612 1 10004 zincrby hot:20230612 1 10005 zincrby hot:20230612 1 10006 zincrby hot:20230612 1 10007 zincrby hot:20230612 1 10008 zincrby hot:20230612 1 10009 zincrby hot:20230612 1 10010 # 获取排行榜: zrevrange hot:20230612 0 9 withscores -
延时队列
将消息序列化成一个字符串作为 zset 的 member;这个消息的到期处理时间作为 score,然后用多个线程轮询 zset 获取到期的任务进行处理。
pythondef delay(msg): msg.id = str(uuid.uuid4()) #保证 member 唯一 value = json.dumps(msg) retry_ts = time.time() + 5 # 5s后重试 redis.zadd("delay-queue", retry_ts, value) # 使用连接池 def loop(): while True: values = redis.zrangebyscore("delay-queue", 0, time.time(), start=0, num=1) if not values: time.sleep(1) continue value = values[0] success = redis.zrem("delay-queue", value) if success: msg = json.loads(value) handle_msg(msg) # 缺点:loop 是多线程竞争,两个线程都从zrangebyscore获取到数据,但是zrem一个成功一个失 败, # 优化:为了避免多余的操作,可以使用lua脚本原子执行这两个命令 # 解决:漏斗限流