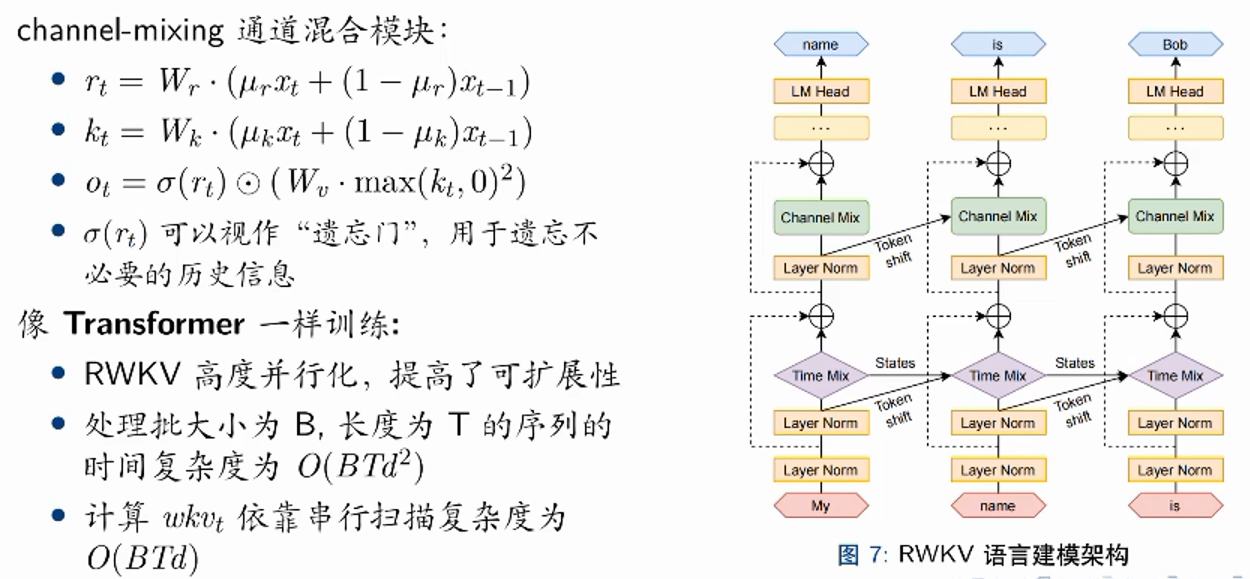
RWKV
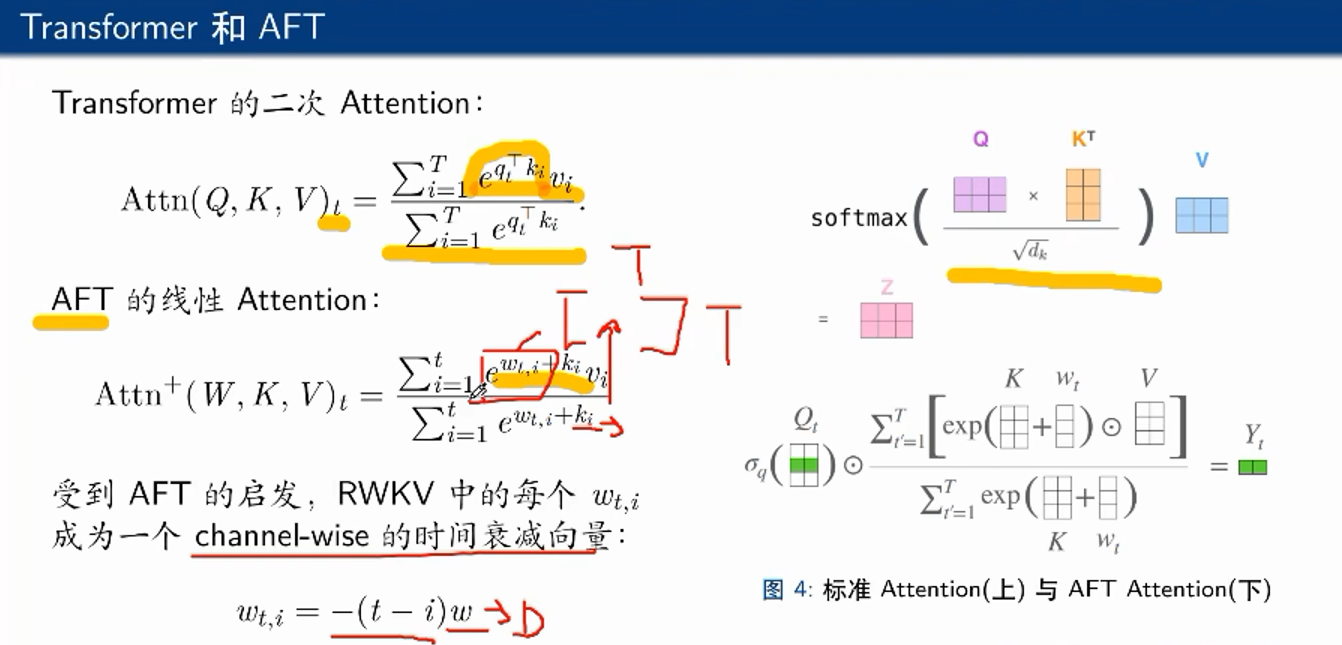
AFT是RWKV的灵感来源之一,不需要q和k进行运算来对v加权,而是在运行代码前设定一个固定的w矩阵,表示一个位置的token对另一个位置的positional bias
不太好,太静态了,所以加上k,去在一定程度上根据现在的背景调整一下w的值,形成了某种线性的attention
RWKV中的channel就是指隐藏层的维度D中每个维度上的值,当前token的前一个向量就是-1w,前两个就是-2w,做到了距离当前token越远的token,衰减越多
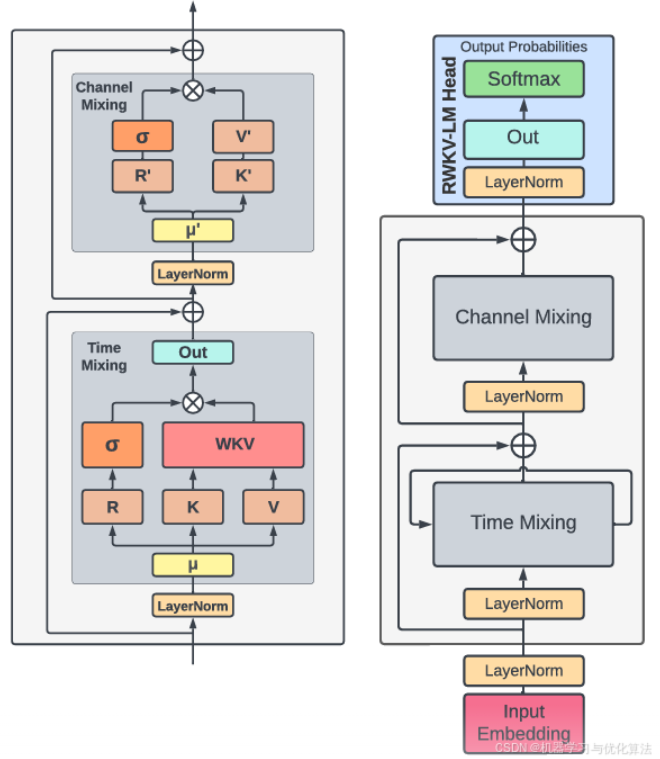
R:作为过去信息的接受程度的接受程度的向量
W:位置权重衰减向量。可训练的模型参数
K:键向量,类似于传统注意力机制中的 K
V:值向量,类似于传统注意力机制中的 V
time mixing:整合历史token的信息
channel mixing:没有考虑每个词和每个维度之间的非线性,而是对这个词本身的channel进行一个混合和非线性
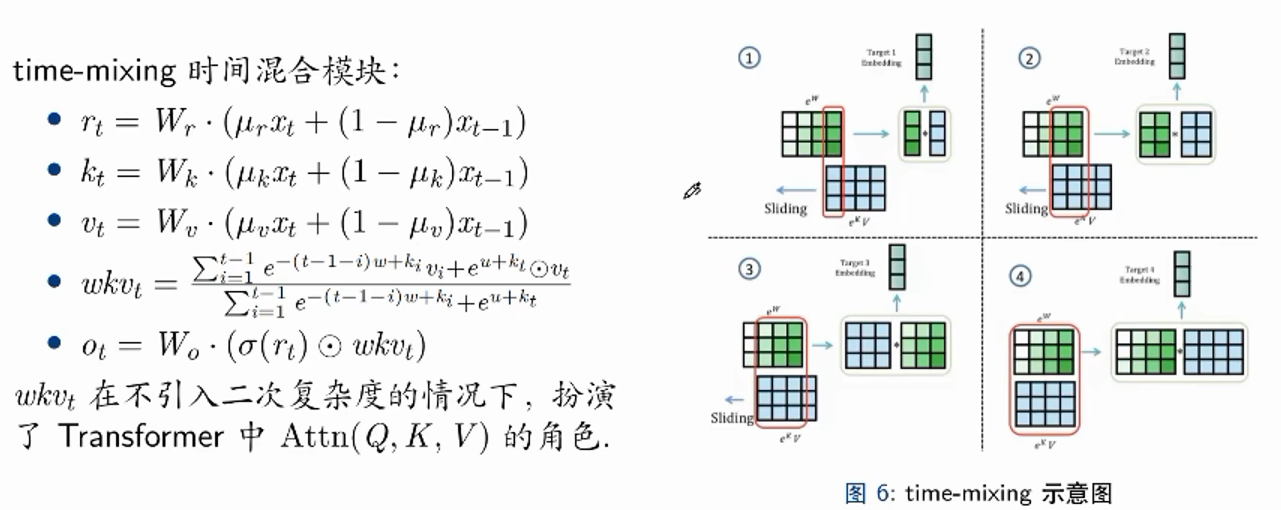
如图,让kv和w不断相乘,让k把时间衰减的w从后往前乘一遍
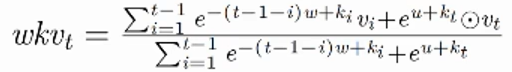
分子左边的式子代表当前token之前的历史token信息线性聚合;右边的式子代表当前token的信息,其中u是单独设计来标明当前token,区分历史token的
另外,左边的式子是可以提取算好的,只需要每次加一下新token就可以算出wkv了
对k用Squared ReLU增强非线性
通过token shift增大后面层的感受野
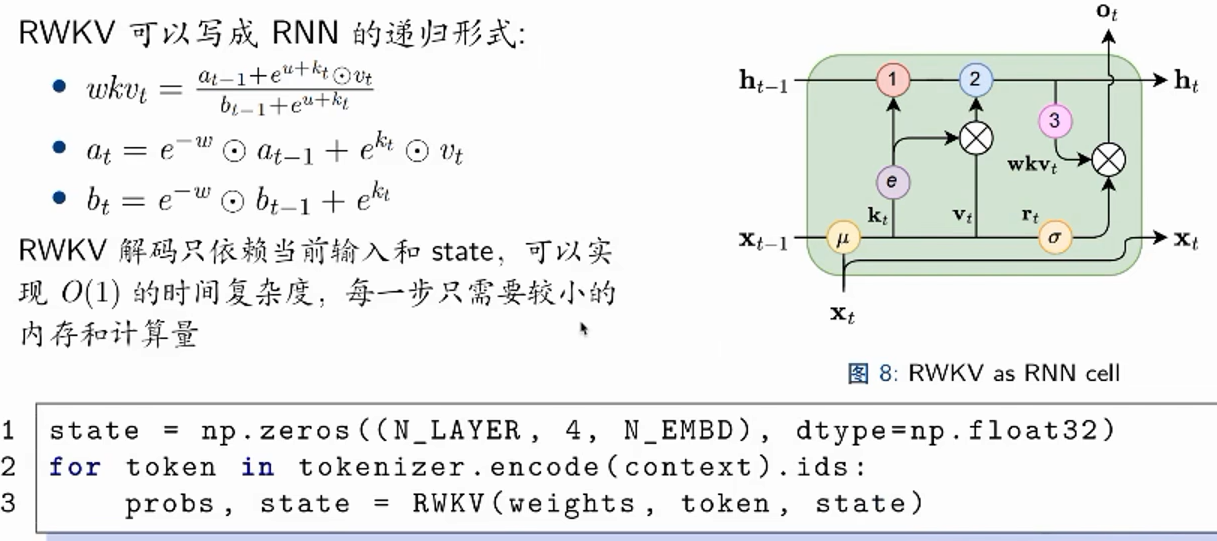
可以写成递归,把历史token的信息提取算好传进来,再去算一下现在token的信息,就可以输入state得到state
循环:通过时间步传递局部信息和捕捉序列中的复杂关系
时间衰减:通过逐渐减小过去信息的影响,隐式地引入位置信息
token-shift::引入 bi-gram,在当前输入和上一个输入之间线性插值,模型自然地聚合和控制输入通道中的信息
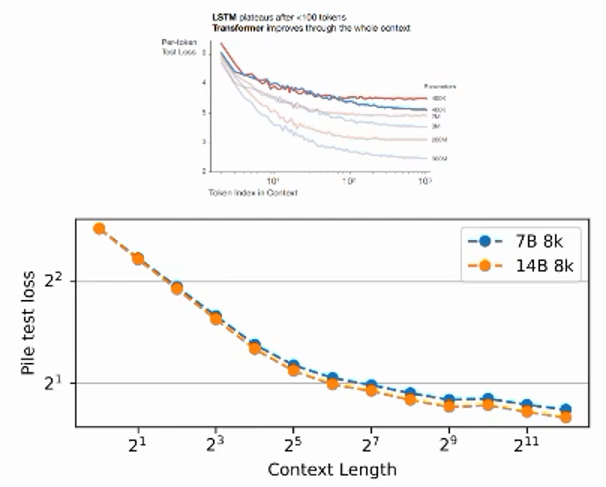
上图是LSTM,在100token之后就几乎饱和,说明把100个之前的信息忘了,而RWKV可以做到4096及以上的记忆
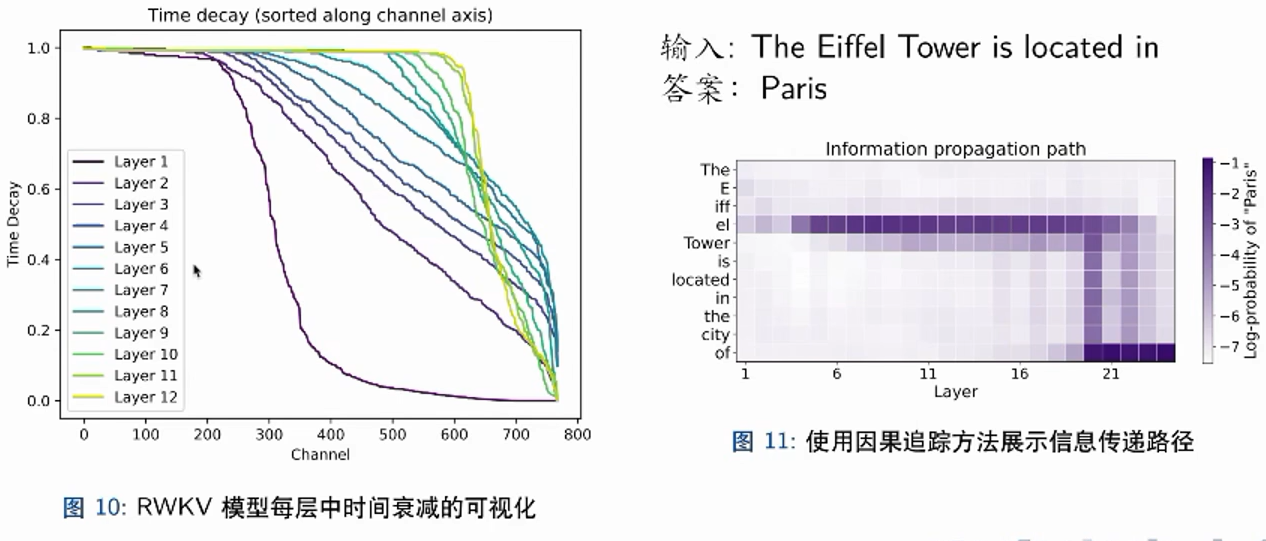
左图是channel的可视化,第一层在后面的维度不再被关注,而第十二层这样的信息可以以很高的信息水平被保留到很后面的维度
右图是channel的因果可视化,可以看到在输入到eiffel之后,信息被一口气提取到了21层左右,在后续的输入过程中一直保留这些信息,到最后输出结果时输出paris
limitations
模型的循环架构本质上限制了其"回望"之前信息的能力。虽然时间衰减有助于防止信息丢失,但与完全的自注意力机制相比,它在机制上存在一定的限制
与标准 Transformer 模型相比,prompt engineering 的重要性增加,因为要让它在一开始就保留重要信息不能忘
VRWKV
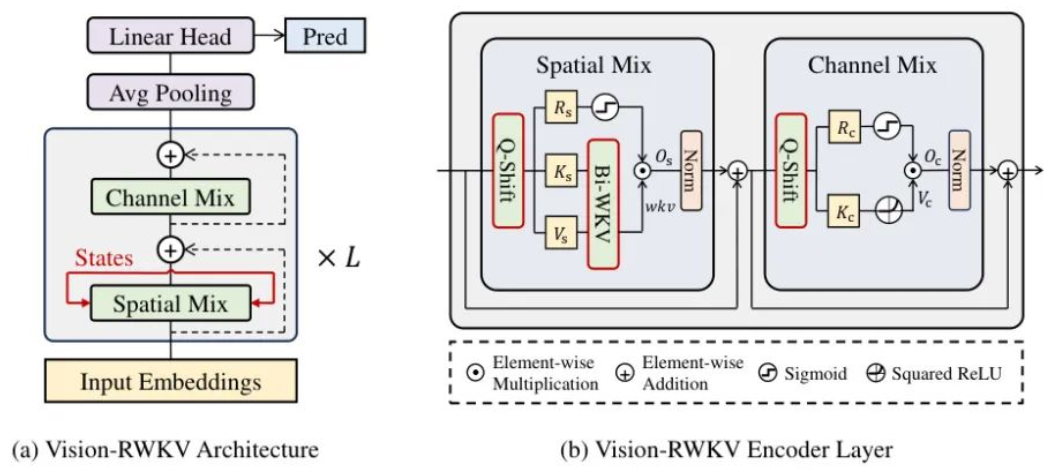
Bi-WKV
一是将原始 RWKV 的因果注意力扩展为双向注意力,使每个 token 能关注到所有其他 token(而非仅当前及之前的 token),确保全局信息交互;
二是引入相对偏置,通过计算 token 间时间差的绝对值与总 token 数的比值,来适配不同尺寸图像的位置信息;
三是采用灵活衰减策略,解除对衰减参数 w 的正值限制,允许模型关注更远距离的 token,增强长程依赖建模能力
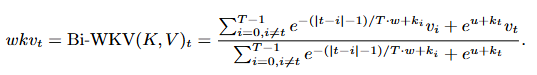
时间衰减加了个绝对值,两边的距离都算
解除正值限制后,衰减项变为双向可调节的指数权重:
当w > 0时,保留局部优先的衰减特性(近邻 token 权重更高);
当w < 0时,指数项变为增长趋势,强制关注远距离 token,建模图像中的长程语义关联(如物体边缘与整体结构)
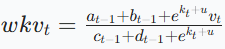
同样可以递归计算,a 和 c 分别累计当前 token 之前的加权和与权重和,b 和 d 分别累计当前 token 之后的加权和与权重和
Q-shift
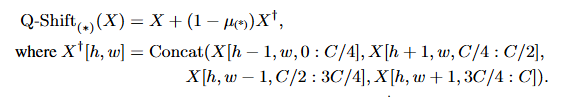
X 为输入 token;X^ 是经四向移位后的 token;μ 是可学习向量
对输入 token X 进行四个方向的移位及通道切片后拼接得到,也就是把这个token上下左右的四个token分别放到C/4的通道上