一、设计原则
1、水平扩展:通过增加服务器而非提升单机性能来扩展
2、无状态化:服务节点不存储会话状态,便于横向扩展。
3、数据分片:通过Sharding分散数据库压力。
4、异步处理:使用消息队列削峰填谷。
5、服务解耦:微服务架构
6、缓存优先:多级缓存降低后端负载。
7、过载保护:限流、熔断防止系统雪崩。
8、最终一致性:在可用性和一致性间取得平衡
二、分层设计
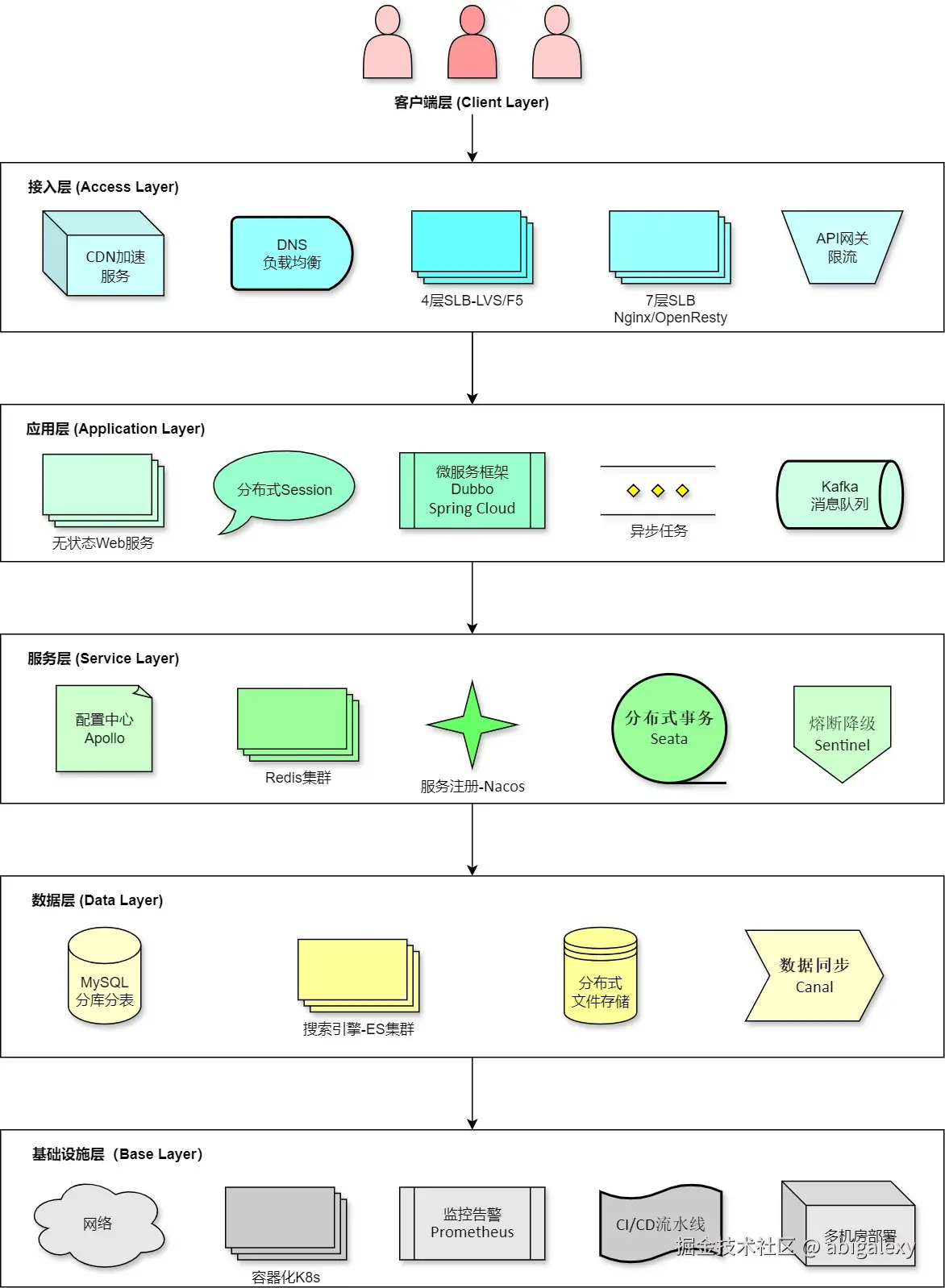
(一)客户端层
1、CDN(内容分发网络):缓存静态资源(图片、JS/CSS文件)、AWS CloudFront/Akamai(静态资源缓存 + 动态加速),减少源站压力
2、Web/移动端应用:用户直接交互的界面(如浏览器、APP)。
3、SDK/API客户端:封装业务逻辑的客户端库(如支付SDK、地图API)。
4、客户端缓存:浏览器本地存储LocalStorage/SessionStorage、HTTP缓存策略ETag/Max-Age、Cache-Control/ETag
5、请求合并:批量API调用(如GraphQL)
(二)接入层(Load Balancing)
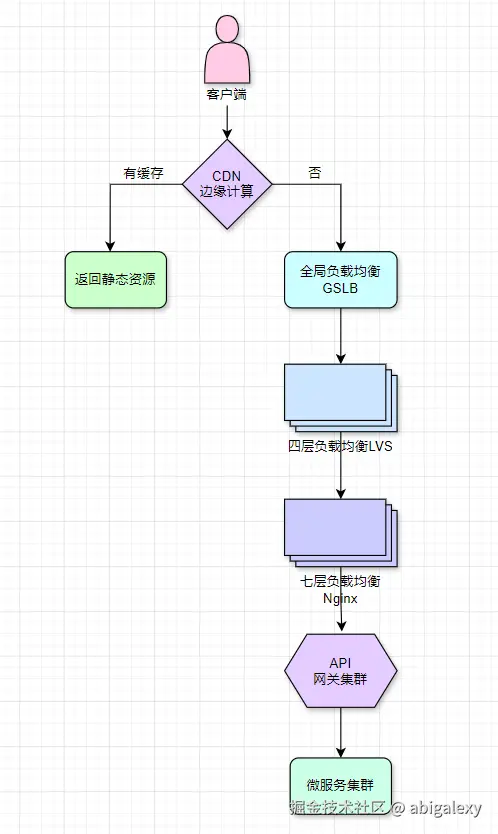
1、负载均衡器(LB)
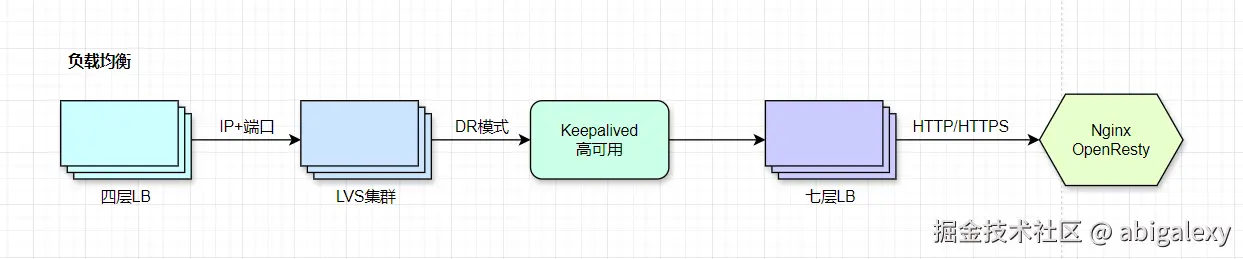
1.1 硬件LB
F5硬件、A10(百万级SSL/TPS/TLS,高并发场景需配合软件LB使用)、LVS(Direct Routing模式)+ TCP协议优化,LVS使用DPDK加速(可达200万PPS),DPDK提升网络包处理能力
SSL终端:TLS硬件加速卡(如Intel QAT)
1.2 软件LB
Nginx(OpenResty动态路由,Worker进程数=CPU核心数)、HAProxy、Envoy(支持L4/L7层负载均衡)、Nginx启用epoll多路复用(C1000K连接)
1.3 云服务
AWS ALB/NLB(AWS)、阿里云SLB(自动扩展,支持百万级QPS),CLB(腾讯云)
2、API网关
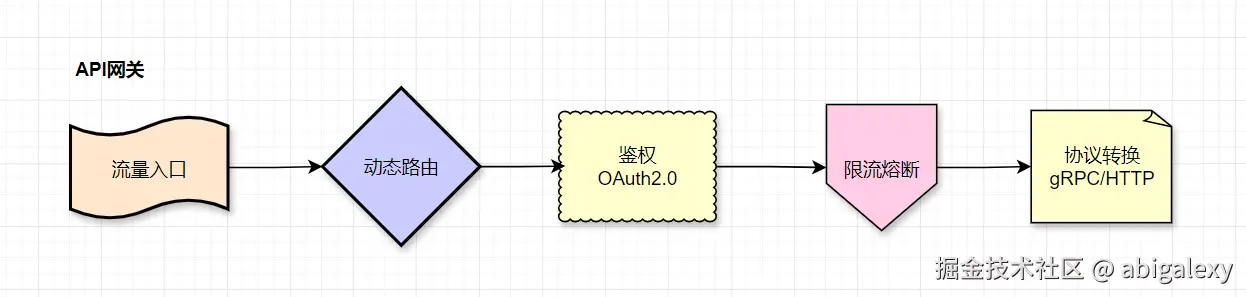
2.1 组件:Kong(插件化限流/JWT验证)、Envoy(xDS动态配置)、Traefik、Apache APISIX(动态上游+服务发现)、自研网关(基于Netty实现长连接管理)
2.2 云服务:AWS API Gateway、阿里云API网关。
2.3 动态限流:Redis + 令牌桶算法(如lua-resty-limit-traffic),自适应阈值
2.4 统一鉴权/限流
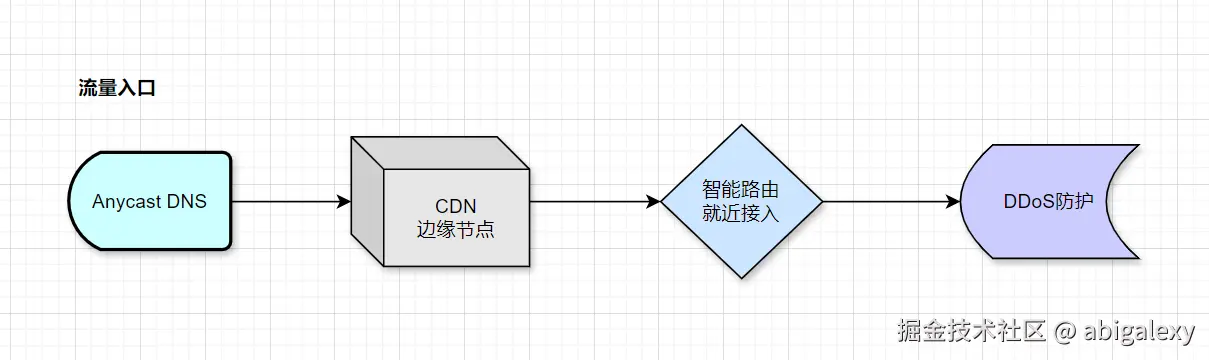
3、动态DNS
云服务:AWS Route53、阿里云DNS。
Anycast:实现全球就近接入(如Cloudflare)
GeoDNS + Anycast(实现地域就近解析)
4、安全防护
1)WAF:ModSecurity(防CC攻击/SQL注入)
2)防护:Cloudflare/AWS Shield(抗DDoS + WAF)
5、缓存与加速
1)Nginx: proxy_cache内存缓存
2)网关: Redis集群缓存热点API
3)连接与协议优化
开启TCP/UDP加速(如DPDK)
长连接代替短连接,长连接优化,减少TCP握手开销
连接池优化
IO多路复用
(三)应用层-无状态化设计
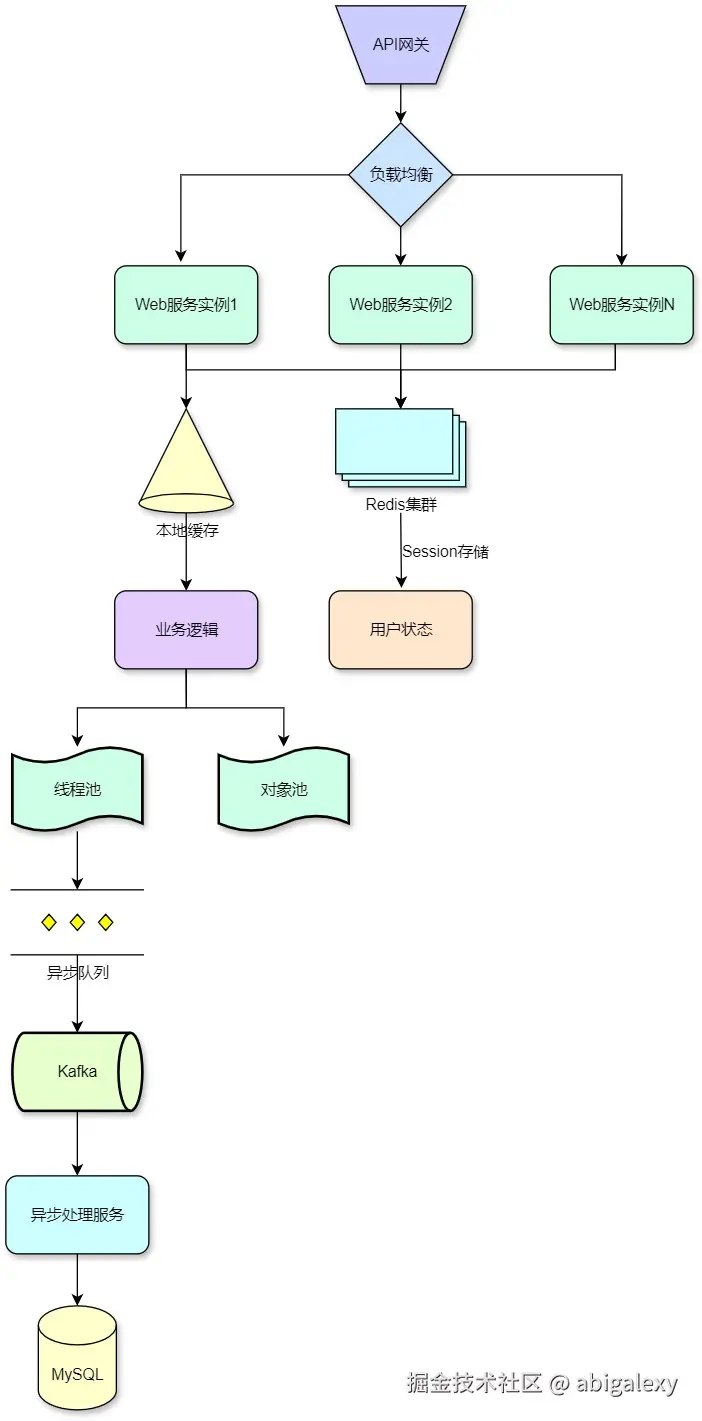
1、微服务集群-按业务垂直拆分
1.1 Spring Cloud:Eureka(服务发现)、Feign(声明式RPC)、Hystrix(熔断)、Spring Cloud Alibaba(Sentinel熔断+Nacos注册中心)
1.2 Dubbo:阿里开源的RPC框架,适合高并发场景、一致性Hash负载均衡
1.3 Thrift:二进制高效序列化
1.4 gRPC:高性能RPC框架,支持HTTP/2和Protobuf序列化、gRPC(ProtoBuf编码+HTTP/2多路复用)
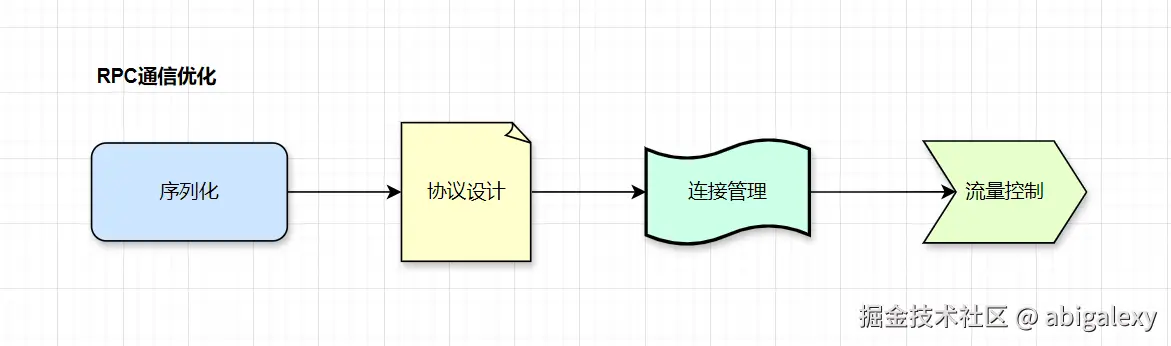
1)高性能实现
序列化:Protobuf(比JSON小60%)
协议:HTTP/2(多路复用)+ gRPC
连接池:每个客户端维护10-20个长连接
2)关键指标
单连接QPS≥5万
平均延迟<3ms(同机房)
3)代码示例(gRPC优化)
java
// 1、高性能gRPC服务端
Server server = ServerBuilder.forPort(8080)
.executor(Executors.newFixedThreadPool(32)) // 独立线程池
.addService(new MyServiceImpl())
.build();
// 2、客户端连接池
ManagedChannel channel = NettyChannelBuilder.forTarget("dns:///serviceA")
.keepAliveTime(30, TimeUnit.SECONDS) // 保活检测
.maxInboundMessageSize(100_000_000) // 100MB消息支持
.build();负载均衡策略对比
| 策略类型 | 适用场景 | QPS影响 | 实现示例 |
|---|---|---|---|
| 轮询(RoundRobin) | 实例性能均衡 | 低开销 | Dubbo默认 |
| 最少活跃调用 | 处理能力动态调整 | 中开销 | Ribbon |
| 一致性哈希 | 需要会话保持 | 高开销 | Ketama算法 |
2、消息队列-削峰填谷
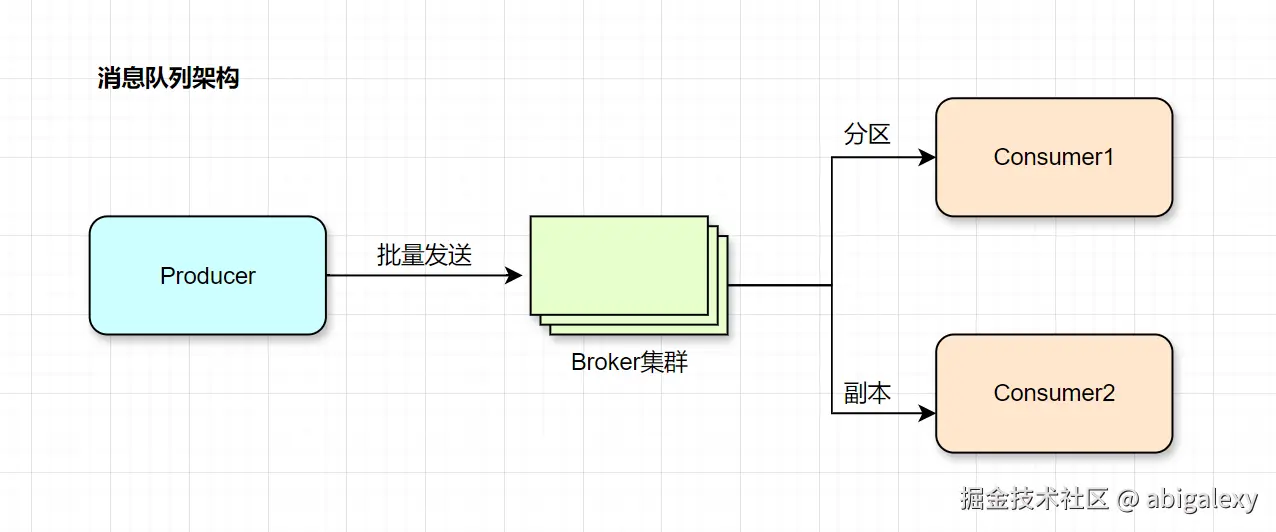
Kafka(日志场景):高吞吐量、低延迟的消息中间件(用于日志、事件流处理)。
RocketMQ(事务消息)/Pulsar集群(百万级TPS)分区+副本:阿里云消息队列,支持百万级TPS。
1)Kafka优化配置
sh
# 生产者
linger.ms=20 # 批量发送延迟
batch.size=16384 # 16KB批次
# Broker
num.io.threads=8 # 磁盘IO线程
log.flush.interval.messages=10000
# 消费者
max.poll.records=500 # 单次拉取量2)吞吐能力
单分区:10万QPS(1KB消息)
集群:百万QPS(10分区×3副本)
预分配Partition,使用Zero-Copy技术,消费者组水平扩展
3)MQ写操作合并批量提交:每批100ms或500条
3、异步处理

非核心流程异步处理,线程池+MQ削峰,CompletableFuture并行调用
3.1 事件驱动:Reactive Spring(WebFlux非阻塞IO)
3.2 线程池:动态大小(核心线程数=CPU*2)
3.3 补偿机制:死信队列+重试
3.4 线程模型优化
1)Boss线程:1-2个(仅处理连接)
2)Worker线程:CPU核数×2
3)业务线程池:动态大小(队列容量≤1000)
3.5 对象池化:减少GC压力(Young GC<50ms)
1)数据库连接池(HikariCP)
2)JSON解析器池(Gson实例)
3)线程池复用(避免频繁创建)
java
// 1. 无状态Session存取
@GetMapping("/user")
public User getUser(@RequestHeader String token) {
return redisTemplate.opsForValue().get(token); // 集中存储
}
// 2. 本地缓存+异步更新
@Cacheable(cacheNames = "products", cacheManager = "caffeine")
public Product getProduct(String id) {
return productDao.get(id); // 自动缓存
}
// 3. 并行调用优化
public CompletableFuture<Result> process() {
return CompletableFuture.supplyAsync(this::step1, pool)
.thenCombine(CompletableFuture.supplyAsync(this::step2, pool),
this::mergeResults);
}4、无状态服务集群
Session集中存储(Redis)
实例管理:通过Sidecar模式(Istio流量镜像/金丝雀发布)实现服务网格化治理。
(四)服务层-解耦核心逻辑
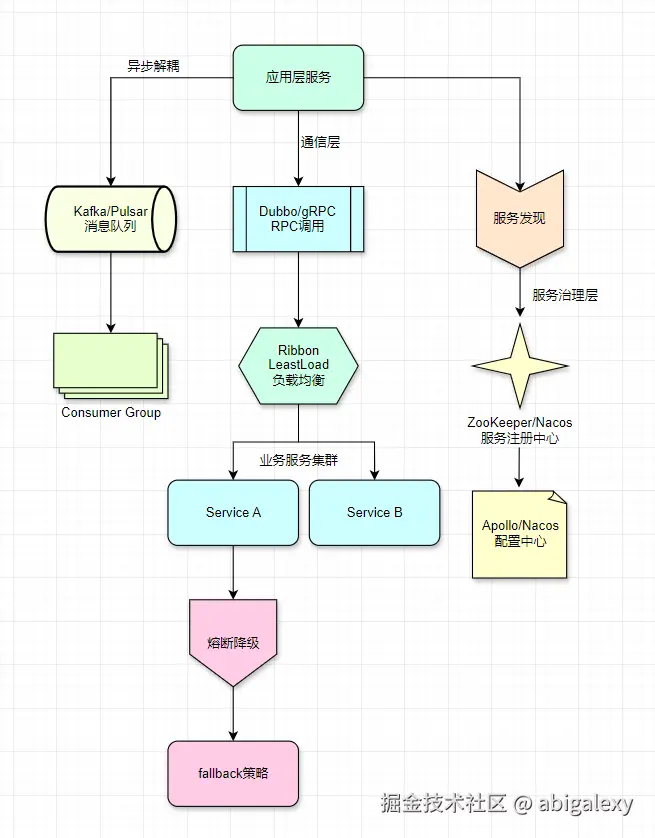
1、配置中心
Apollo:携程开源的配置管理平台,支持灰度发布。
Nacos:阿里开源的动态服务发现和配置管理。
Etcd(Watch机制动态生效)
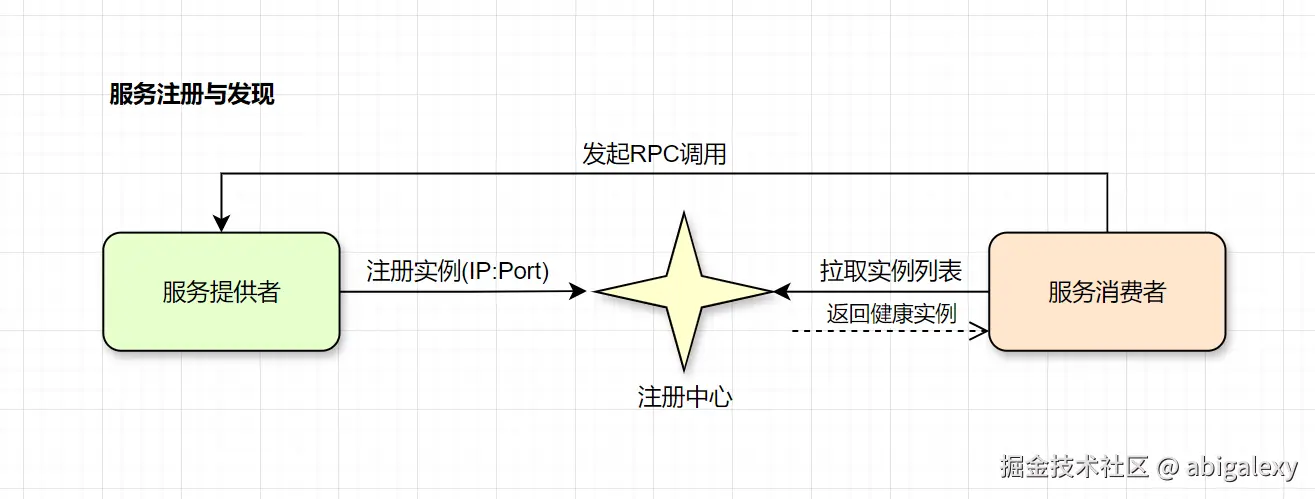
Zookeeper/Consul:服务注册与发现
1.1 技术选型
CP模型:ZooKeeper(强一致性)
AP模型:Nacos/Eureka(高可用性)
1.2 优化要点
客户端缓存服务列表(防注册中心雪崩)
心跳检测间隔≤5s(快速感知下线)
1.3 组件功能对比
| 维度 | ZooKeeper | Nacos | Consul | Apollo |
|---|---|---|---|---|
| 定位 | 分布式协调服务 | 动态服务发现与配置管理平台 | 服务网格与多数据中心管理 | 分布式配置中心 |
| 核心功能 | 分布式锁、集群管理、Leader 选举、服务注册(早期)、元数据存储 | 服务注册与发现、动态配置管理、DNS 服务、健康检查 | 服务发现、健康检查、键值存储、多数据中心支持、安全通信(TLS/ACL) | 配置集中管理、实时推送、权限控制、灰度发布、版本审计 |
| 数据模型 | 树形结构(ZNode) | 分组Group+ 数据ID(Data ID) | 键值对(KV Store) | 命名空Namespace+ 集群+应用 |
| 一致性协议 | ZAB(类似 Paxos) | CP默认或 AP | Raft | 最终一致性(数据库+缓存) |
| 生态集成 | Kafka、Hadoop、Dubbo | Spring Cloud Alibaba | Envoy、Kubernetes | 无直接生态依赖 |
| 性能 | 高(读多写少场景) | 中(依赖数据库) | 中(Raft协议开销) | 中(依赖数据库和缓存) |
| 优势 | 成熟稳定、高性能、低延迟 | 一体化解决方案、支持多协议(DNS/GRPC) | 开箱即用、支持多数据中心、安全性强 | 配置实时生效、权限控制精细、支持灰度 |
| 劣势 | 功能单一、API 复杂、无原生 UI | 生态成熟度不如 Zookeeper | 配置复杂度较高、性能不如 Zookeeper | 依赖数据库、学习曲线较陡 |
| 适合团队 | 大数据、分布式系统专家 | 微服务开发团队 | 跨地域、安全敏感型团队 | 企业级应用开发团队 |
1)ZooKeeper
核心功能:
分布式协调:通过临时节点(Ephemeral Node)实现Leader选举、分布式锁。
服务注册:早期用于服务发现(如 Dubbo 默认注册中心),但需自行实现健康检查。
元数据存储:存储集群配置、路由信息等关键数据。
仅需分布式协调功能(如锁、选举)。
与 Kafka、Hadoop 等大数据生态深度集成。
典型场景:
Kafka 分区Leader选举、Hadoop HDFS NameNode协调。
分布式锁(如防止重复下单)。
2)Nacos
核心功能:
服务发现:支持基于DNS和GRPC的服务发现,自动剔除不健康实例。
动态配置:支持多环境(DEV/TEST/PROD)配置管理,配置变更实时推送。
服务治理:结合Sentinel实现熔断降级,与Spring Cloud Alibaba深度集成。
微服务架构需要一体化解决方案(服务发现 + 配置管理)。
基于Spring Cloud或Dubbo开发,追求开箱即用。
典型场景:
微服务架构中的服务注册与配置管理(如 Spring Cloud应用)。
动态调整服务参数(如线程池大小、超时时间)。
3)Consul
核心功能:
服务网格支持:与Envoy集成,实现服务间通信的加密和流量管理。
多数据中心:支持跨数据中心的服务发现和数据同步。
安全通信:内置TLS加密和ACL权限控制。
跨数据中心或需要服务网格支持。
对安全性要求高(如金融、医疗行业)。
典型场景:
跨地域的微服务架构(如全球部署的SaaS服务)。
需要强安全性的金融或政务系统。
4)Apollo
核心功能:
配置灰度发布:指定部分客户端接收新配置,逐步验证后再全量发布。
权限审计:记录配置变更历史,支持回滚和操作审计。
多环境隔离:开发、测试、生产环境配置完全隔离。
配置复杂度高,需多环境、多集群管理。
需要灰度发布或精细权限控制。
典型场景:
电商大促活动配置(如动态调整限流阈值)。
需要精细权限控制的企业级应用(如银行核心系统)。
2、服务治理
Hystrix/Resilience4j:Netflix开源的容错框架。
Sentinel:流量控制、熔断降级、系统自适应保护。
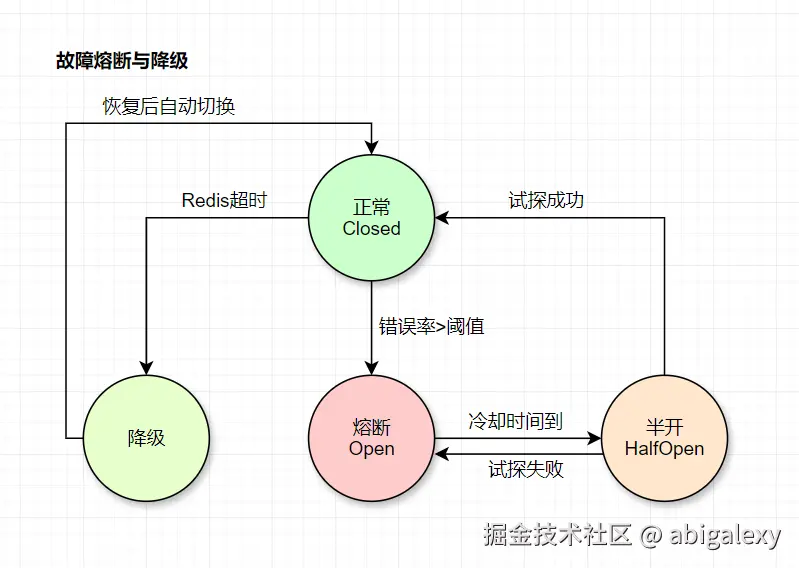
Sentinel配置:
java
// 熔断规则:5秒内异常比例>50%触发
DegradeRule rule = new DegradeRule("resA")
.setGrade(RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO)
.setCount(0.5) // 阈值50%
.setTimeWindow(10); // 熔断10秒分级降级策略
| 故障级别 | 措施 | 影响范围 |
|---|---|---|
| 1级 | 限流(80%流量) | 非核心功能 |
| 2级 | 熔断下游服务 | 单个业务线 |
| 3级 | 返回本地缓存/默认值 | 全局 |
3、分布式缓存
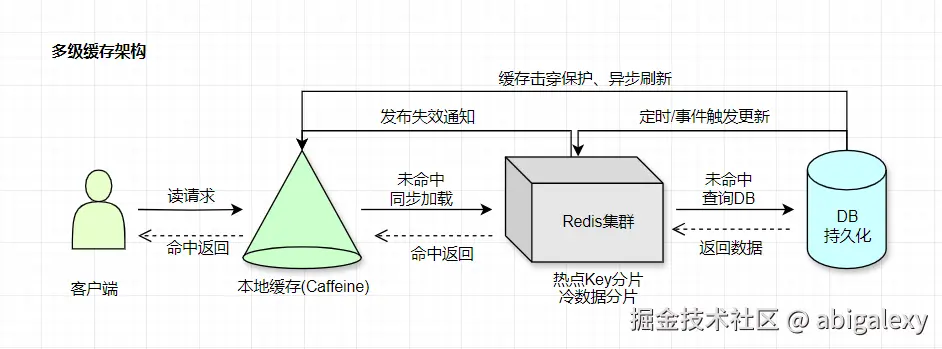
3.1 Redis集群(Pipelining批量操作,Codis/Twemproxy3),16分片+3副本(单分片10万QPS),TLS+多线程、支持数据分片和主从复制
3.2 Proxy模式:Twemproxy/Codis(透明分片)
3.3 Memcached:简单键值缓存,适合读多写少场景。
3.4 本地缓存:Caffeine(多级缓存降级)、Guava Cache(堆外内存+软引用)
1)Caffeine:W-TinyLFU算法(99%命中率)
2)失效策略:TTL + 主动刷新
3)大小限制:堆内存20%(防OOM)
3.5 优化策略:
1)缓存预热
2)多级缓存架构:LocalCache → Redis → DB
3)热点Key:本地缓存+二级Hash分片
4)缓存雪崩:随机过期时间(基础300s±60s)
5)缓存穿透:布隆过滤器,过滤无效请求,减少数据库压力。
6)大Value:压缩(Snappy)+ 分块存储
代码示例
java
// 1. 多级缓存查询
public Product getProduct(String id) {
// 1. 查本地缓存
Product product = localCache.get(id);
if (product == null) {
// 2. 查Redis
product = redis.get(id);
if (product == null) {
// 3. 查DB + 回填
product = db.query(id);
redis.setEx(id, product, 300);
}
localCache.put(id, product);
}
return product;
}4、分布式锁
Redlock:基于Redis的分布式锁算法。
Zookeeper:通过临时节点实现锁机制。
5、分布式事务
Seata:阿里开源的分布式事务解决方案(AT模式)。
Saga模式:长事务补偿机制,适合跨服务操作。
| 方案 | 适用场景 | 所属层级 |
|---|---|---|
| 2PC/XA | 强一致性,数据库事务 | 数据层(数据库协调) |
| TCC | 高并发,业务补偿 | 应用层+服务层 |
| Saga | 长事务,最终一致性 | 应用层+服务层(MQ) |
| 本地消息表 | 异步确保,可靠性 | 应用层+数据层 |
(五)数据层-高并发存储
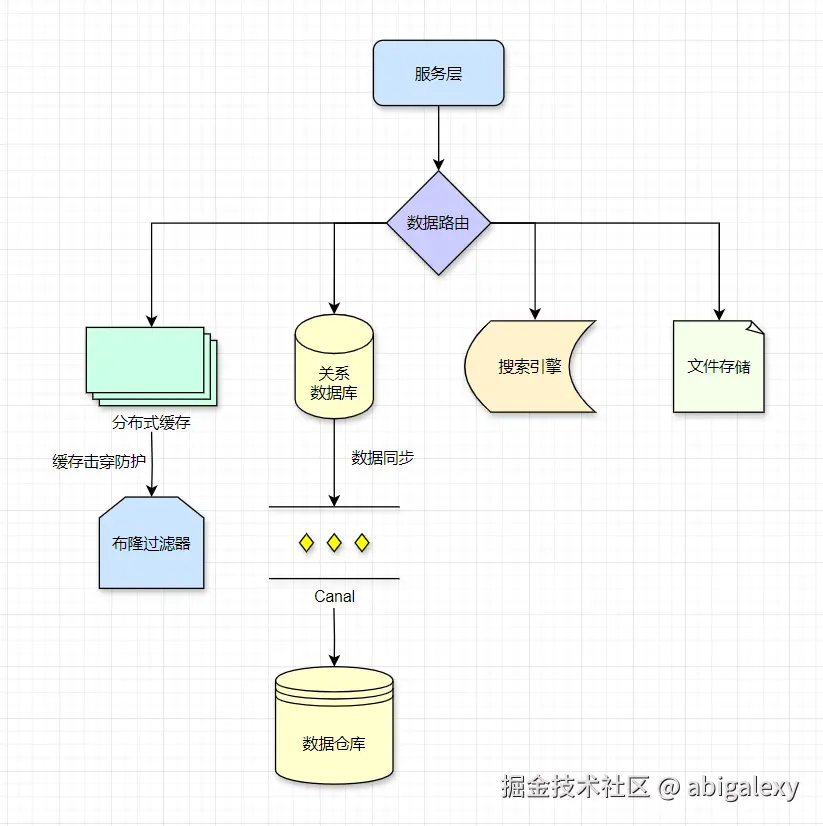
1、数据库
1.1 OLTP:MySQL(Vitess分库分表)+ PXC集群
MySQL分库分表(ShardingSphere),水平拆分+垂直拆分,32分库(单库5000QPS)
1)分片策略:
水平分库:按用户ID哈希(16个库)
水平分表:按时间范围(每月1表)
基因法:关联数据同库(如用户和订单)
2)性能配置:
sh
# MySQL 8.0优化
# 总内存70%
innodb_buffer_pool_size = 64G
# SSD配置
innodb_io_capacity = 4000
# 组提交优化
binlog_group_commit_sync_delay = 100
java
// 分库分表路由
String shardKey = "user_" + userId.hashCode() % 16;
DataSource ds = determineDataSource(shardKey);1.2 OLAP:ClickHouse(列式存储)+ TiFlash(实时分析)
1.3 分库分表:MyCat、ShardingSphere(支持水平拆分)。
1.4 NewSQL:TiDB、CockroachDB(HTAP能力,兼容MySQL,支持分布式事务)。
1.5 云数据库:AWS Aurora、阿里云PolarDB(自动分片,百万级QPS支持)。
1.6 NoSQL:MongoDB(分片集群+读写关注配置)、Cassandra(多DC部署+QUORUM一致性)
1.7 时序数据库:InfluxDB
2、数据同步与备份
Canal:MySQL binlog解析,实现数据同步。
Debezium:基于Kafka的CDC(变更数据捕获)工具。
3、搜索引擎
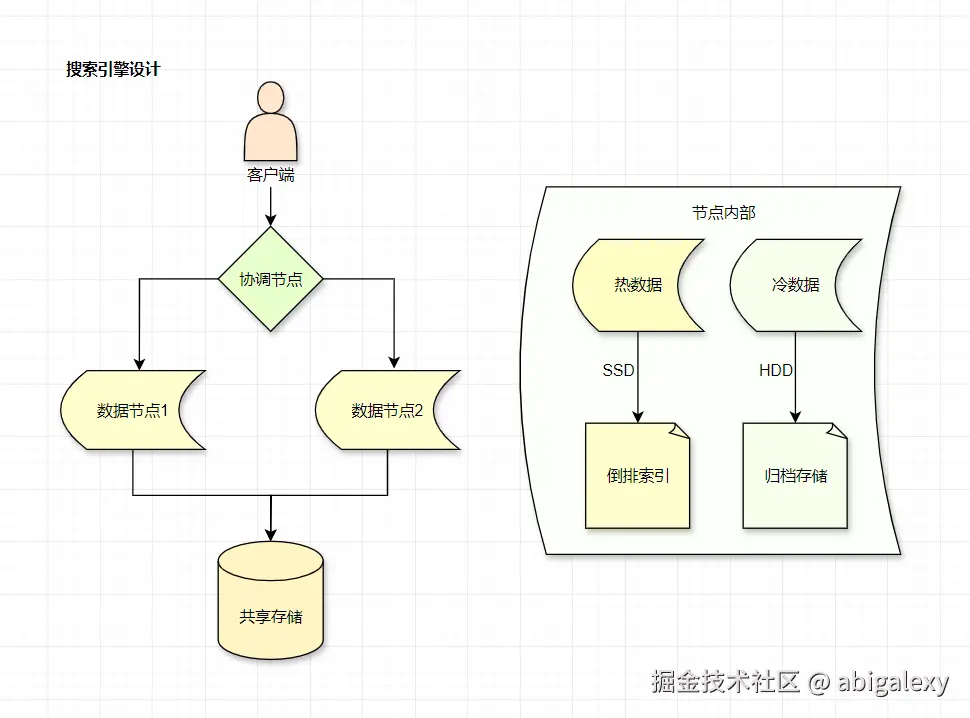
Solr:企业级搜索平台,适合复杂查询场景。
Elasticsearch:分布式全文检索,支持高并发查询,多副本,倒排索引+冷热数据分离(查询<10ms)
1)分片策略:主分片=节点数×1.5(如10节点→15分片)
2)写入优化:批量提交(每批1000条或1MB)
3)查询优化:预聚合+并行scroll
4、文件存储
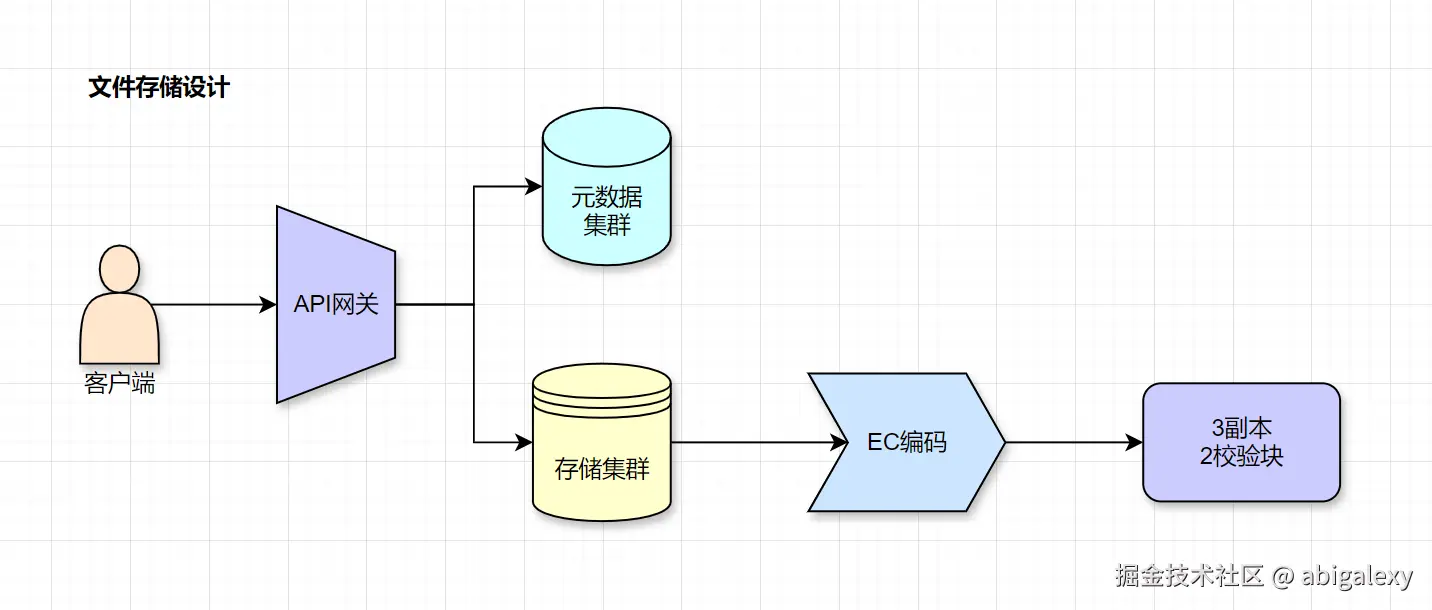
1)Ceph/MinIO(EB级扩展)
2)分布式文件系统HDFS
EC编码 vs 传统副本技术
| 特性 | EC编码 | 传统副本(如3副本) |
|---|---|---|
| 存储开销 | m/k(如k=6, m=3时为50%) | 200%(3副本需3倍存储) |
| 容错能力 | 可容忍m个块丢失 | 仅容忍2个副本丢失(需3副本) |
| 计算开销 | 编码/解码需要额外计算(CPU密集型) | 无额外计算,直接复制数据 |
| 适用场景 | 冷数据、大规模存储、成本敏感型系统 | 热数据、低延迟、高可用性需求场景 |
小文件问题
问题:EC编码对小文件(如KB级)的存储效率低,因编码开销可能超过数据本身。
合并小文件:将多个小文件打包为一个大文件后再编码。
混合策略:对热数据使用副本,对冷数据使用EC编码。
| 存储类型 | 吞吐量 | 适用场景 |
|---|---|---|
| 对象存储 | 10GB/s | 图片/视频 |
| 文件存储 | 5GB/s | 日志/备份 |
| 块存储 | 低延迟IOPS | 数据库 |
5、数据优化
5.1 冷热分离:热数据内存,温数据SSD,冷数据HDD
5.2 TiFlash列式存储
5.3 读写分离:主库写,从库读(使用ProxySQL),主从架构+Proxy路由
5.4 主从复制与多副本****
5.5 数据压缩
5.6 缓存与DB一致性
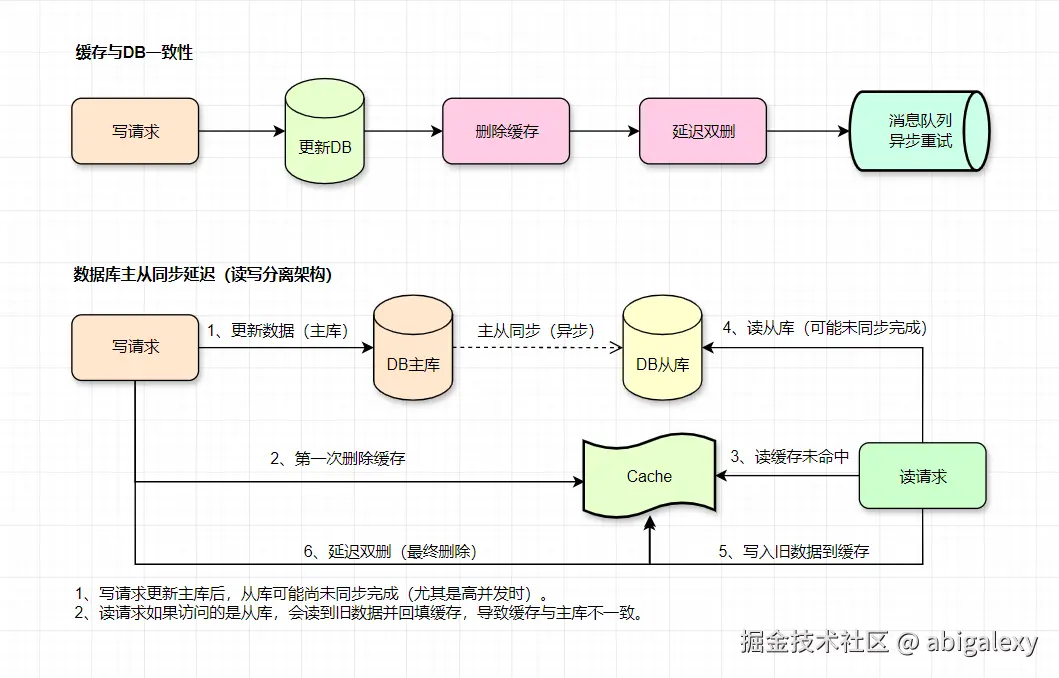
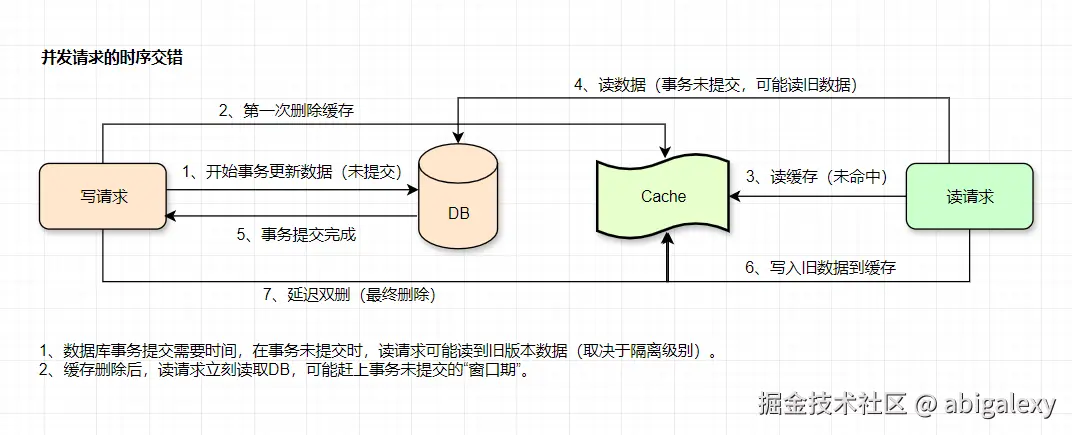
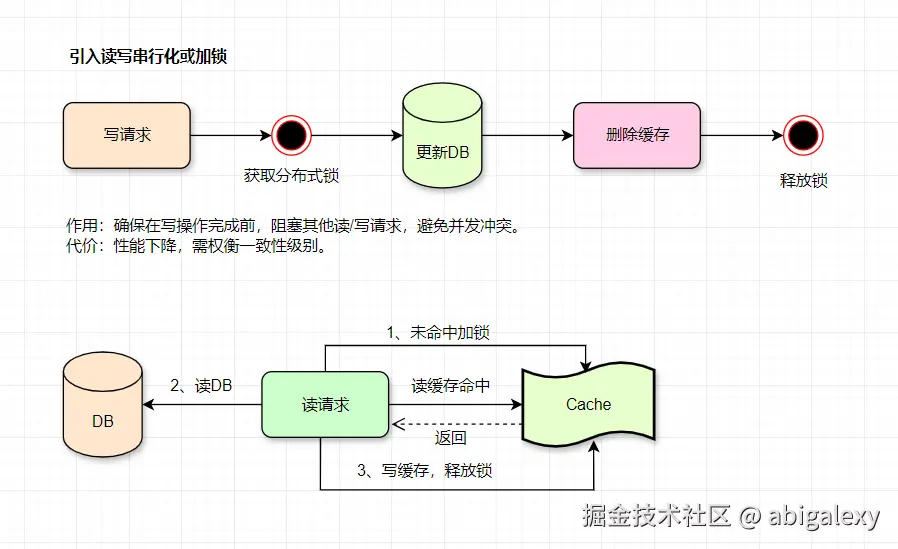
延迟双删的时机问题
延迟时间难以确定(例如固定延迟1秒):
如果延迟过长:可能仍有新读请求写入旧数据。
如果延迟过短:可能无法覆盖DB主从同步延迟(若DB是读写分离架构)。
消息队列重试的可靠性
消息队列可能因积压或消费失败导致重试不及时。
多次重试可能引发缓存频繁删除,影响性能。
解决方案:
1)强制读主库(避免主从延迟)
写操作后一段时间内,让读请求直接访问主库(可通过中间件或注解控制)。
缺点:主库压力增大。
2)延迟双删 + 合理延迟时间
第二次删除缓存的延迟需覆盖主从同步时间 + 事务提交时间(例如经验值500ms-1s)。
优化:动态调整延迟(例如监听主从同步位点)。
3)引入版本号或时间戳
写DB时记录数据版本号,读请求回填缓存时校验版本号,仅当缓存版本≤DB版本时才允许写入。
java
// 写请求
updateDB(data);
// 从DB获取最新版本
version = getCurrentVersion();
deleteCache();
// 读请求
data = readCache();
if (data == null) {
data = readDB();
if (data.version >= cache.version) {
// 校验版本
writeCache(data);
}
}4)最终一致性
监听DB Binlog(如Canal、Debezium)
通过订阅DB变更日志异步删除/更新缓存,避免业务代码耦合。
设置缓存过期时间:
为缓存设置较短过期时间(如1s),即使出现不一致,数据最终会通过过期时间自我修复。
(六)基础设施层-保障SLA
1、网络
专线:AWS Direct Connect(跨AZ低延迟)
弹性IP:浮动IP实现快速故障转移
网络优化:SRIOV/DPDK内核旁路
SDN:Calico/Flannel(容器网络隔离)
Anycast网络:通过BGP实现就近接入
2、计算资源
云主机:AWS EC2 Spot实例(成本优化)
裸金属:物理机部署Redis/MySQL(避免虚拟化开销)
弹性:Cluster Autoscaler + Spot实例
隔离:cgroups + namespaces
多活:单元化部署架构
存储:NVMe SSD+RDMA
成本控制:混部+Spot实例+弹性资源池
3、容器化与编排
3.1 Kubernetes(K8s):多AZ部署、容器编排、自动化部署、HPA自动扩缩容、服务发现
3.2 Docker:轻量级容器化技术,实现环境隔离。
3.3 动态扩缩容
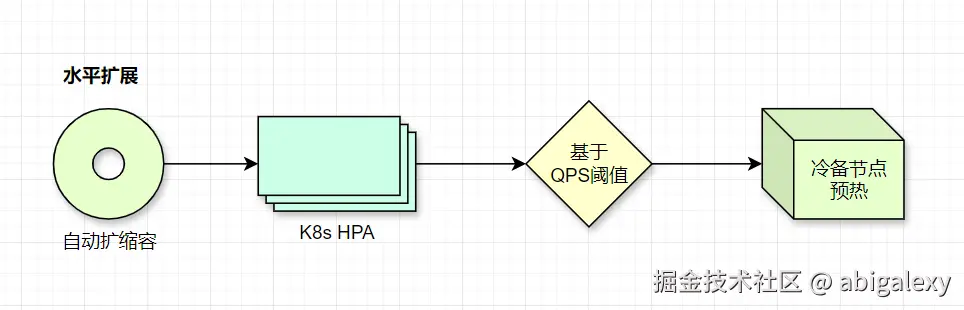
1)K8s HPA:基于CPU/自定义指标自动扩缩
2)预热机制:扩容时先加载缓存数据****
3)横向扩展:无状态节点可快速扩容
4)扩容:Kubernetes + Cluster Autoscaler
5)负载均衡:动态权重调整(如Consul-Template)
6)配置健康检查自动剔除故障节点
4、监控与告警
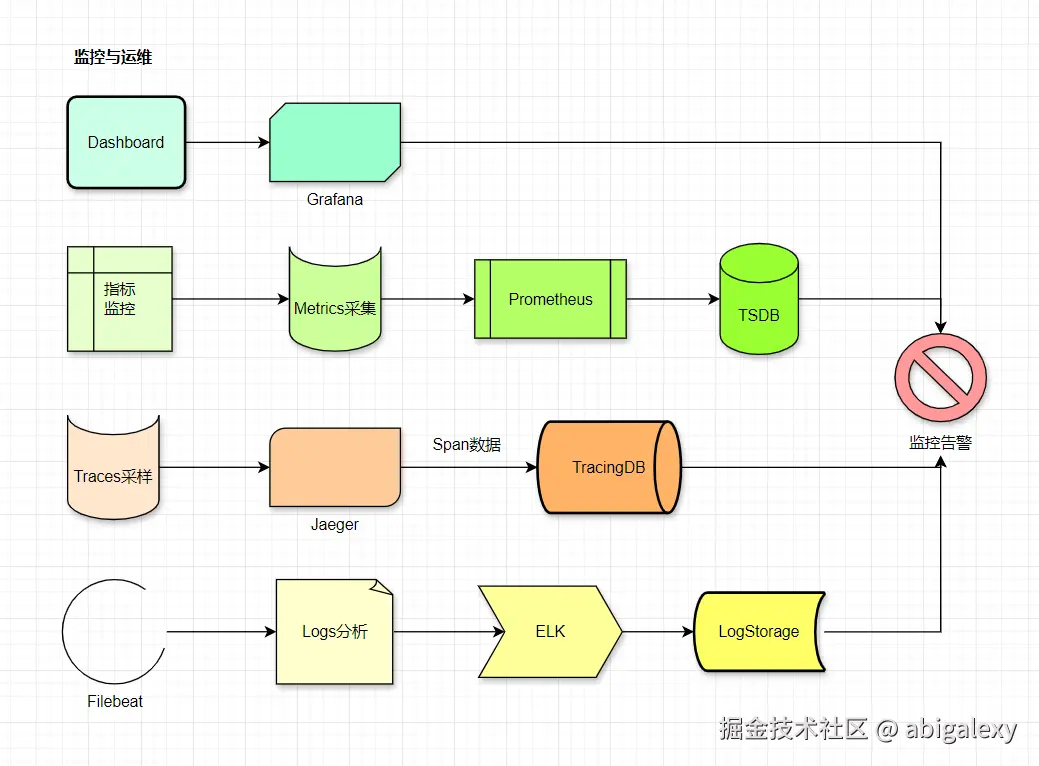
4.1 监控组件
指标监控:Prometheus(VictoriaMetrics集群)、Grafana 、AlertManager
日志分析:ELK(Elasticsearch + Logstash管道优化 + Kibana)、Filebeat、ELK Stack(每秒处理100万条日志)、Loki+ClickHouse(低成本存储)
全链路追踪:Jaeger/SkyWalking(采样率100%),分布式追踪,SkyWalking(自动埋点),Pinpoint
自愈:Ansible+Argo Rollouts
4.2 网关层监控
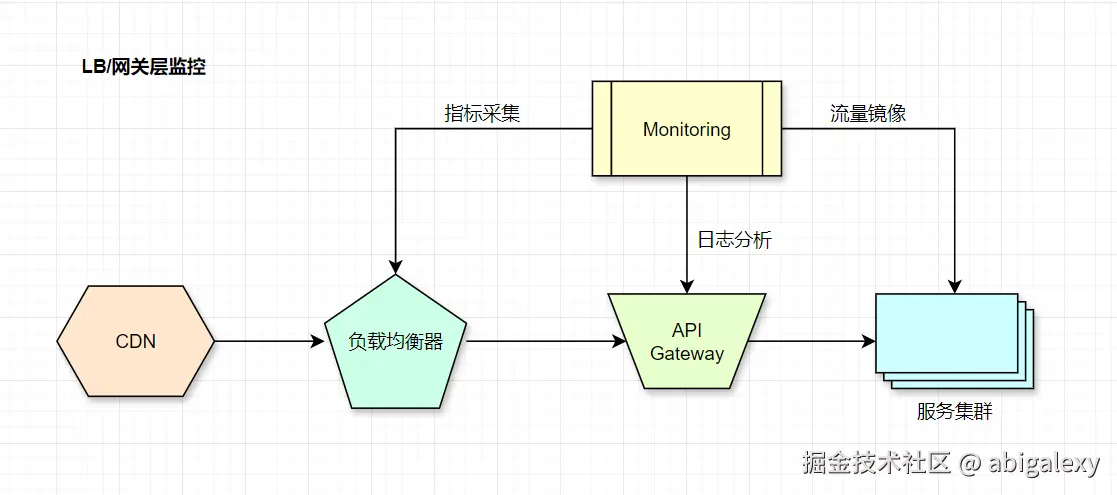
流量指标:QPS、连接数、响应时间(P99/P95)、5xx错误率
健康检查:节点存活状态、熔断比例
安全防护:DDoS攻击检测、WAF拦截日志
4.3 应用服务监控
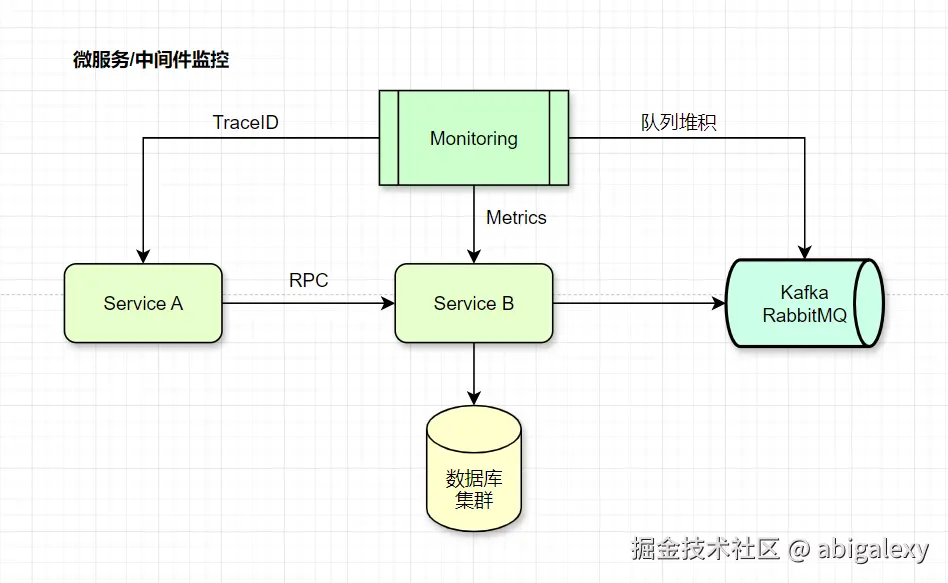
服务治理:接口成功率、线程池状态、GC频率
依赖调用:RPC耗时、熔断器状态、跨机房延迟
消息队列:积压量、消费延迟、分区健康度
性能关键指标
| 组件 | 优化目标 | 监控指标 | 告警阈值 |
|---|---|---|---|
| 本地缓存 | 命中率>95% | cache.hit.rate | <90% |
| 线程池 | 队列积压<1000 | threadpool.queue.size | >800 |
| Redis访问 | P99延迟<5ms | redis.cmd.latency | >10ms |
| Young GC | 频率<2次/秒 | jvm.gc.young.count | >5次/秒 |
| 异步任务 | 积压<1万条 | mq.backlog | >5000 |
性能指标监控
| 核心指标 | 目标值 | 工具链 |
|---|---|---|
| QPS | ≥1,000,000 | Prometheus |
| 延迟(P99) | ≤50ms(P99≤200ms) | Jaeger/Datadog |
| 错误率 | <0.01% | ELK日志 |
| 5xx错误率 | >0.5% 持续5分钟 | Prometheus+Alert |
| 扩容速度 | 30秒/节点 | K8s+HPA |
| 消息积压 | ≤1000条 | Prometheus+Grafana+Burrow(作为数据源) |
| GC停顿时间 | >200ms/次 | Grafana+JVM监控 |
| Redis内存使用率 | >85% | Zabbix+自定义脚本 |
| 节点CPU LOAD | >核心数*2 | Nagios+Telegraf |
4.4 数据存储监控
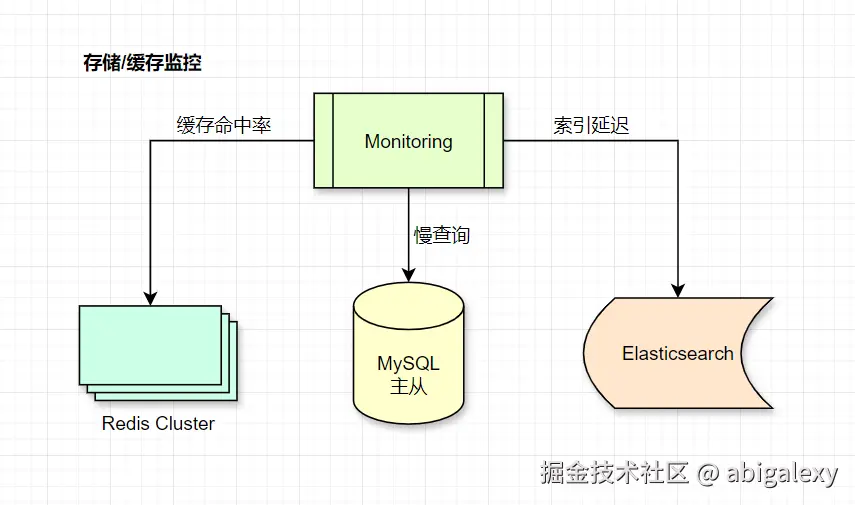
缓存层:命中率、内存碎片率、大Key扫描
数据库:主从延迟、锁等待时间、连接池水位
大数据组件:HDFS块状态、Spark任务堆积
监控指标
| 层级 | 关键指标 | 告警阈值 |
|---|---|---|
| 缓存 | 命中率 | <90% |
| 数据库 | 主从延迟 | >1s |
| 搜索 | 查询延迟(P99) | >500ms |
| 文件 | 上传失败率 | >0.1% |
5、CI/CD流水线
Jenkins/GitLab CI:自动化构建、测试、部署。
ArgoCD:GitOps持续交付工具。
智能运维(AIOps):基于历史数据的故障预测
6、混合云/多云管理
Terraform:基础设施即代码(IaC),实现多云资源编排。
KubeSphere:多集群管理平台,简化运维复杂度。
Ansible:配置批量下发
三、各层扩展
(一)客户端层
1、性能数据
1)移动端RTT:50-300ms
2)Web端首屏时间: <1s
3)缓存命中率: 60-80%
2、扩展方式
CDN边缘节点分发;请求合并与批处理;客户端本地缓存
3、主要瓶颈点
网络抖动和丢包;DNS解析延迟;弱网环境性能差
4、解决方案
HTTP/3(QUIC)协议;预加载+懒加载;智能DNS+IP直连
(二)接入层
1、性能数据
1)LVS: 1M+ CPS
2)Nginx: 50K-100K RPS
3)TLS握手: 1-5ms(硬件加速)
2、扩展方式
水平扩展LB集群;Anycast+BGP;自动弹性伸缩
3、主要瓶颈点
SSL/TLS加解密开销;四层转发瓶颈;DDoS攻击风险
4、解决方案
SSL硬件加速卡;DPDK优化网络栈;多活流量调度
(三)应用层
1、性能数据
1)单节点: 10K-50K RPS
2)线程切换开销: 1-5μs
3)序列化耗时: 10-100μs
2、扩展方式
无状态水平扩展;容器化+K8s HPA;请求分片路由
3、主要瓶颈点
GC停顿(STW);线程竞争;序列化瓶颈
4、解决方案
协程/纤程模型;Zero-Copy序列化;分级线程池隔离
(四)服务层
1、性能数据
1)RPC延迟: 0.5-3ms(同机房)
2)服务网格开销: <5%
3)熔断阈值: 50-100ms
2、扩展方式
微服务独立扩缩容;读写分离;功能分片
3、主要瓶颈点
分布式事务;服务雪崩;热点调用
4、解决方案
最终一致性;熔断降级策略;本地缓存+防穿透
(五)数据层
1、性能数据
1)Redis: 100K+ OPS
2)MySQL: 5K-10K TPS
3)磁盘IOPS: 10K-100K
2、扩展方式
读写分离+多副本;分库分表;冷热数据分层
3、主要瓶颈点
锁竞争;索引效率;持久化延迟
4、解决方案
无锁数据结构;内存数据库;异步刷盘+WAL
(六)基础设施层
1、性能数据
1)网络带宽: 10-100Gbps
2)跨机房延迟: 1-5ms
3)虚拟化开销: <3%
2、扩展方式
混合云资源池;裸金属+容器混部;网络功能虚拟化
3、主要瓶颈点
NUMA效应;虚拟网络瓶颈;资源争抢
4、解决方案
RDMA/SmartNIC;SR-IOV直通;精细化cgroup控制
(七)各层优化
1、高并发读场景
客户端缓存 -> CDN -> 应用层缓存 -> Redis集群 -> DB只读副本
2、高并发写场景
接入层限流 -> 消息队列削峰 -> 分库分表写入 -> 异步刷盘****
3、低延迟交易场景
QUIC协议 -> DPDK负载均衡 -> 内存计算 -> 持久化日志
4、各层平衡CAP原则
1)接入层/应用层优先保证AP
2)数据层根据场景选择CP或AP
3)基础设施层确保C为前提的可用性
四、容灾与高可用
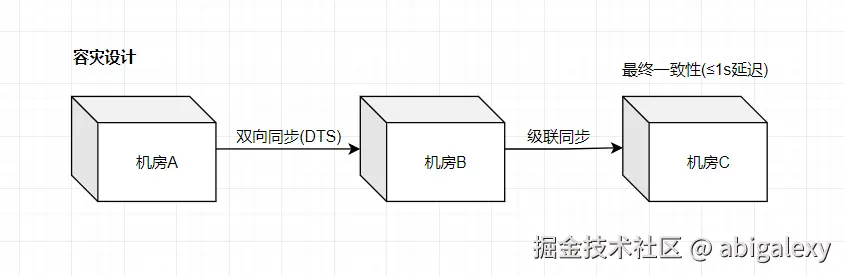
1、多机房部署
同城双活:两个机房同时提供服务,延迟<1ms
异地多活:跨地域数据同步(使用DRC复制)
混沌工程:模拟故障演练,定期注入故障测试系统韧性,定期模拟机房断电/网络分区,通过Chaos Mesh模拟网络分区/节点宕机
2、容灾策略
多活架构:3个以上可用区(如AWS us-east-1a/1b/1c),单元化部署(如阿里云EDAS)
限流降级:非核心接口返回兜底数据
1)服务熔断(Hystrix/Sentinel)
2)流量控制(令牌桶/漏桶算法)
流量调度:DNS秒级切换 + GSLB健康检查
3、故障自动转移: 服务自动摘除与恢复
4、突发流量处理
1)监控告警:QPS突破阈值 → 触发AutoScaling策略
2)扩容动作:K8s自动扩容Pod → LB动态注册新节点
3)降级预案:非核心服务降级 → 保障主干链路
5、安全防护
网络层: Anycast IP + DDoS清洗
传输层: TLS 1.3 + 证书轮换
应用层: JWT鉴权 + API签名
数据层: 敏感字段加密(AES-256)
五、全链路压测
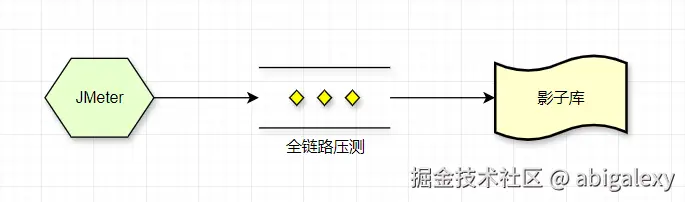
基于影子库的流量回放,定期模拟真实流量测试
工具:JMeter + InfluxDB + Grafana
1、实施步骤:
1)线上流量镜像回放
2)逐步加压至200%预期QPS
3)监控CPU/内存/网络IOPS
4)从单服务压测到全链路压测
5)从低负载逐步增加到峰值负载
2、基准测试:
使用wrk进行HTTP基准测试
wrk -t12 -c1000 -d60s --latency api.example.com/v1/endpoint
峰值流量测试:
wrk -t100 -c5000 -d60s --latency http://seckill-api/start?item_id=123
3、性能压测指标
| 层级 | QPS指标 | 延迟要求 | 监控指标 |
|---|---|---|---|
| 客户端层 | 100万+ | <100ms(P99) | 请求成功率、缓存命中率、重试率 |
| 接入层 | 150万+(冗余) | <5ms(P99) | 连接数、吞吐量、错误率、CPU使用率 |
| 应用层 | 120万+ | <50ms(P99) | 线程池状态、GC时间、服务响应时间 |
| 服务层 | 80万+/服务 | <30ms(P99) | 缓存命中率、队列深度、消息处理延迟 |
| 数据层 | 50万+/分片 | <20ms(读) | 查询耗时、IOPS、连接数、复制延迟 |
| 20万+/分片 | <50ms(写) | ||
| 基础设施 | 节点健康状态、网络带宽、磁盘IO |
六、演进路线
1、初期:单体架构 + 垂直扩展(单机488核),云服务托管(如ALB+RDS)
2、中期:服务拆分 + 水平扩展(K8s集群),自建K8s+Redis Cluster
3、成熟期:Serverless架构 + 边缘计算,全栈自研(如DPDK网关、智能调度)
4、注意事项:
1)避免过早优化,先通过压测定位瓶颈
2)考虑使用eBPF技术进行内核级优化
3)关注CPU缓存行对齐等底层优化
七、百万级QPS-电商秒杀示例
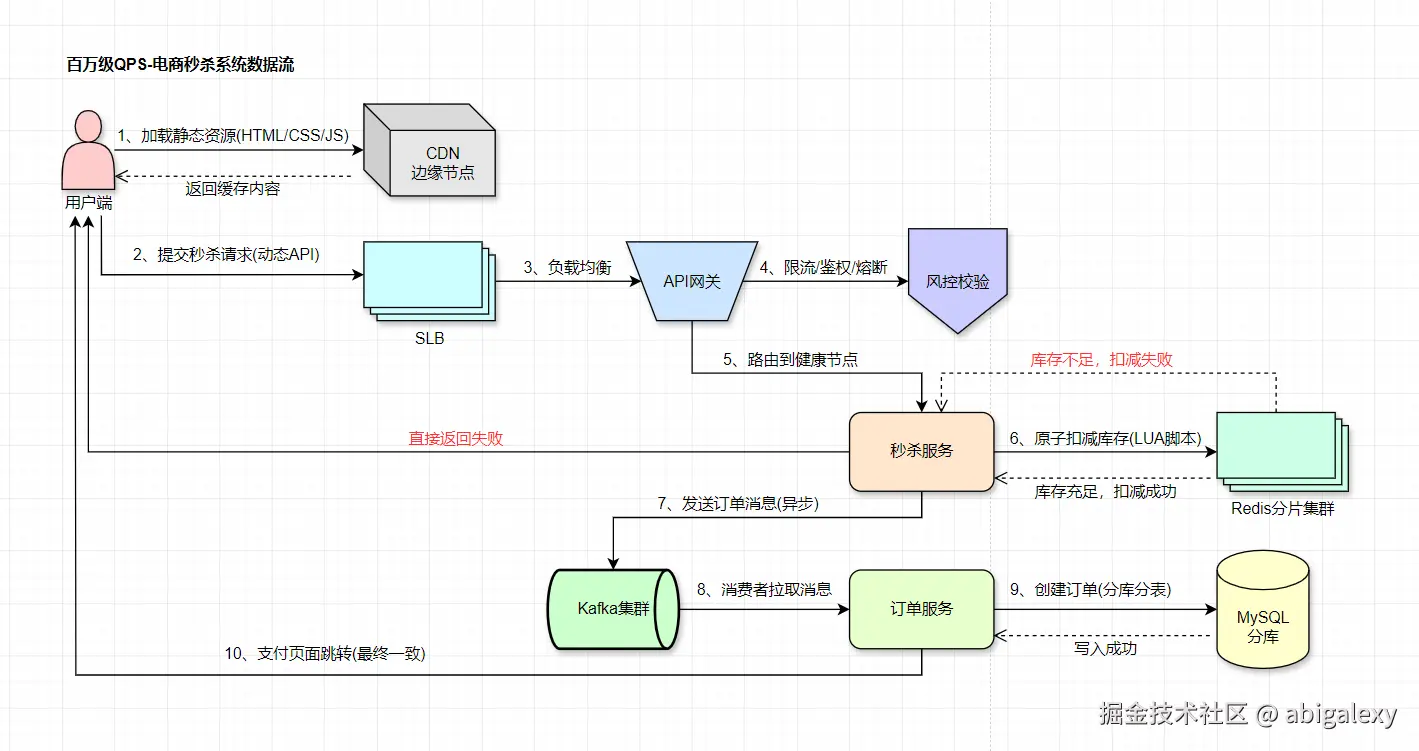
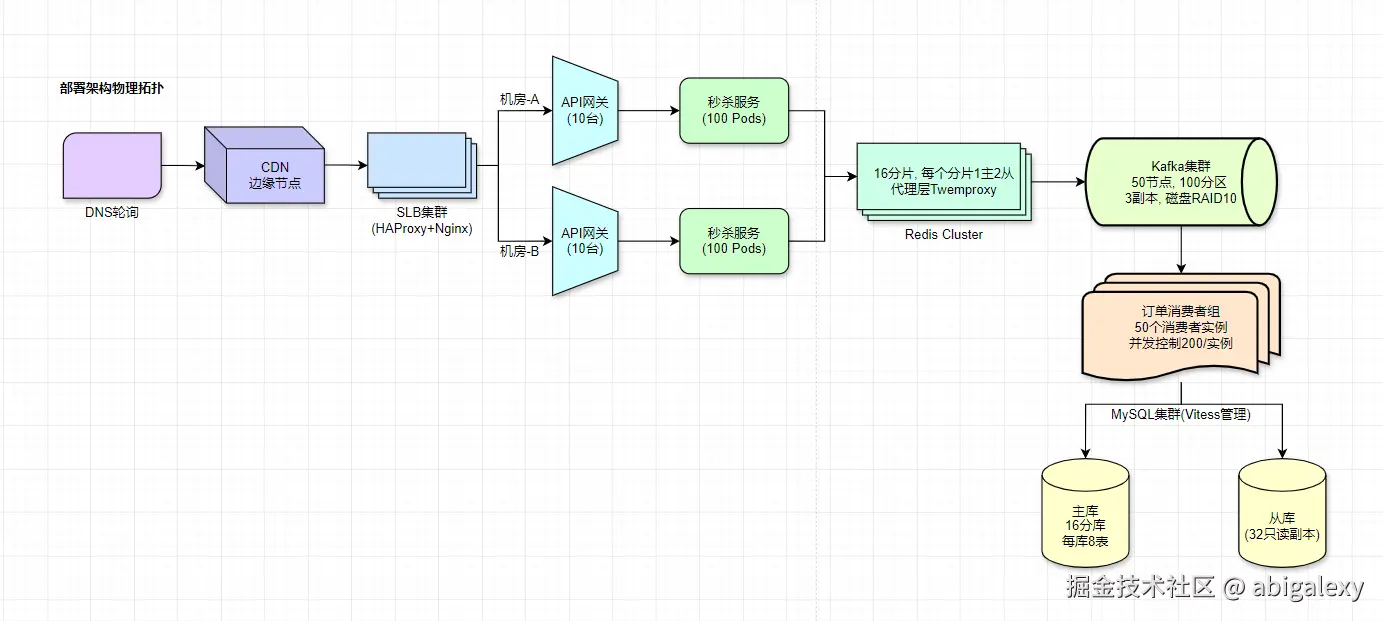
部署规格参考
| 组件 | 配置 | 数量 | 高可用方案 | 特殊优化 |
|---|---|---|---|---|
| API网关 | 16C32G/万兆网卡 | 20 | 双机房互备+VIP漂移 | 内核调优: net.ipv4.tcp_tw_reuse=1 |
| 秒杀服务Pod | 4C8G/500并发 | 200 | K8s HPA自动扩缩容 | JVM参数: -XX:+UseZGC |
| Redis分片 | 64G内存/禁用持久化 | 32 | 每个分片1主2从+哨兵 | 大页内存: transparent_hugepage=always |
| Kafka节点 | 32C128G/4TB NVMe SSD | 100 | 3副本+机架感知 | num.io.threads=16 |
| MySQL分库 | 64C256G/16TB SSD | 16 | 半同步复制+MGR | innodb_buffer_pool_size=192G |