Agent在供应链管理中的应用:库存优化与需求预测
个人介绍
🌟 Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
摘要
作为一名深耕供应链技术领域多年的开发者,我深刻体会到传统供应链管理面临的诸多挑战。在数字化转型的浪潮中,我见证了Agent技术从概念到实践的完整演进过程。Agent作为一种智能化的自主决策系统,正在彻底改变供应链管理的游戏规则。
在我参与的多个企业级项目中,我发现传统的供应链管理往往依赖人工经验和静态规则,难以应对市场需求的快速变化和供应链网络的复杂性。而Agent技术的引入,让我们能够构建具有自主学习、动态决策和协同合作能力的智能系统。这些Agent不仅能够实时监控库存状态,还能基于历史数据和市场趋势进行精准的需求预测。
通过我在实际项目中的探索,我发现Agent在供应链管理中的应用主要体现在三个核心领域:智能库存优化、精准需求预测和供应链协同。在库存优化方面,Agent能够动态调整安全库存水平,优化补货策略,显著降低库存成本。在需求预测方面,多Agent系统能够整合多维度数据源,提供更加准确的预测结果。在供应链协同方面,Agent能够实现供应商、制造商和零售商之间的智能协调。
本文将深入探讨Agent技术在供应链管理中的核心应用场景,分析其技术架构和实现方案,并通过具体的代码示例展示如何构建一个完整的Agent驱动的供应链管理系统。我将结合自己的实践经验,为读者提供一套可操作的技术方案和最佳实践指南。
一、Agent技术在供应链管理中的核心价值
1.1 传统供应链管理的痛点
在我多年的供应链系统开发经验中,我发现传统供应链管理存在以下核心问题:
- 信息孤岛严重:各个环节缺乏有效的信息共享机制
- 决策滞后性:依赖人工分析,响应速度慢
- 预测准确性低:基于历史经验,难以适应市场变化
- 库存成本高:安全库存设置不合理,资金占用严重
1.2 Agent技术的优势
Agent技术通过以下特性为供应链管理带来革命性改变:
python
class SupplyChainAgent:
"""供应链智能代理基础类"""
def __init__(self, agent_id, role, capabilities):
self.agent_id = agent_id
self.role = role # 'inventory', 'demand_forecast', 'supplier'
self.capabilities = capabilities
self.knowledge_base = {}
self.decision_history = []
self.communication_protocols = []
def perceive_environment(self, market_data, inventory_data, supplier_data):
"""环境感知:收集和处理环境信息"""
environment_state = {
'market_trends': self.analyze_market_trends(market_data),
'inventory_status': self.assess_inventory_status(inventory_data),
'supplier_performance': self.evaluate_suppliers(supplier_data),
'timestamp': datetime.now()
}
return environment_state
def make_decision(self, environment_state, goals):
"""智能决策:基于环境状态和目标制定决策"""
decision_context = {
'current_state': environment_state,
'objectives': goals,
'constraints': self.get_constraints(),
'historical_performance': self.get_performance_metrics()
}
# 使用强化学习算法进行决策
optimal_action = self.reinforcement_learning_model.predict(decision_context)
# 记录决策历史
self.decision_history.append({
'context': decision_context,
'action': optimal_action,
'timestamp': datetime.now()
})
return optimal_action
def communicate_with_agents(self, message, target_agents):
"""Agent间通信:实现协同决策"""
for agent in target_agents:
response = agent.receive_message(message, self.agent_id)
self.process_agent_response(response)
def learn_and_adapt(self, feedback):
"""学习适应:基于反馈优化决策模型"""
self.update_knowledge_base(feedback)
self.retrain_models(feedback)
self.adjust_strategies(feedback)这个基础Agent类展示了供应链Agent的核心能力:环境感知、智能决策、协同通信和自主学习。
二、库存优化Agent系统设计
2.1 库存优化架构设计
库存优化是供应链管理的核心环节。我设计的Agent系统采用分层架构,实现智能化的库存管理。
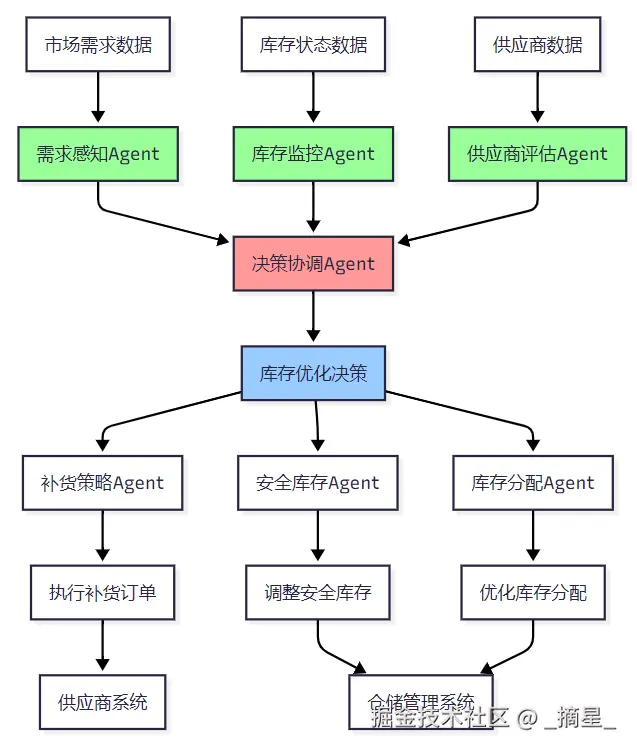
图1:库存优化Agent系统架构图 - 展示了多Agent协同工作的完整流程,从数据感知到决策执行的全链路智能化管理。
2.2 智能库存优化算法实现
基于我在实际项目中的经验,我开发了一套动态库存优化算法:
python
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from scipy.optimize import minimize
import pandas as pd
class InventoryOptimizationAgent:
"""库存优化智能代理"""
def __init__(self, product_catalog, historical_data):
self.product_catalog = product_catalog
self.historical_data = historical_data
self.demand_model = RandomForestRegressor(n_estimators=100)
self.optimization_params = {
'holding_cost_rate': 0.25, # 库存持有成本率
'stockout_cost_rate': 0.15, # 缺货成本率
'order_cost': 100, # 订货成本
'service_level': 0.95 # 服务水平
}
self.train_demand_model()
def train_demand_model(self):
"""训练需求预测模型"""
features = ['season', 'promotion', 'price', 'competitor_price',
'economic_index', 'weather_factor']
X = self.historical_data[features]
y = self.historical_data['demand']
self.demand_model.fit(X, y)
print(f"需求预测模型训练完成,R²得分: {self.demand_model.score(X, y):.3f}")
def predict_demand(self, product_id, forecast_horizon=30):
"""预测未来需求"""
product_features = self.get_product_features(product_id, forecast_horizon)
demand_forecast = self.demand_model.predict(product_features)
# 计算预测不确定性
demand_std = np.std([tree.predict(product_features)
for tree in self.demand_model.estimators_])
return {
'forecast': demand_forecast,
'uncertainty': demand_std,
'confidence_interval': self.calculate_confidence_interval(
demand_forecast, demand_std
)
}
def optimize_inventory_policy(self, product_id):
"""优化库存策略"""
demand_prediction = self.predict_demand(product_id)
current_inventory = self.get_current_inventory(product_id)
# 定义优化目标函数
def total_cost(policy_params):
reorder_point, order_quantity = policy_params
# 计算期望总成本
holding_cost = self.calculate_holding_cost(order_quantity)
stockout_cost = self.calculate_stockout_cost(
reorder_point, demand_prediction
)
order_cost = self.calculate_order_cost(order_quantity)
return holding_cost + stockout_cost + order_cost
# 约束条件
constraints = [
{'type': 'ineq', 'fun': lambda x: x[0] - 0}, # 再订货点 >= 0
{'type': 'ineq', 'fun': lambda x: x[1] - 1}, # 订货量 >= 1
{'type': 'ineq', 'fun': lambda x: 10000 - x[1]} # 订货量 <= 10000
]
# 执行优化
initial_guess = [50, 200] # 初始猜测值
result = minimize(total_cost, initial_guess,
method='SLSQP', constraints=constraints)
optimal_policy = {
'reorder_point': int(result.x[0]),
'order_quantity': int(result.x[1]),
'expected_cost': result.fun,
'service_level': self.calculate_service_level(result.x[0], demand_prediction)
}
return optimal_policy
def calculate_safety_stock(self, product_id, target_service_level=0.95):
"""计算安全库存"""
demand_prediction = self.predict_demand(product_id)
lead_time = self.get_supplier_lead_time(product_id)
# 考虑需求和供应时间的不确定性
demand_during_lead_time = demand_prediction['forecast'].mean() * lead_time
demand_std_during_lead_time = demand_prediction['uncertainty'] * np.sqrt(lead_time)
# 基于服务水平计算安全库存
from scipy.stats import norm
z_score = norm.ppf(target_service_level)
safety_stock = z_score * demand_std_during_lead_time
return {
'safety_stock': int(safety_stock),
'demand_during_lead_time': int(demand_during_lead_time),
'total_reorder_point': int(demand_during_lead_time + safety_stock),
'service_level': target_service_level
}这个库存优化Agent实现了需求预测、库存策略优化和安全库存计算的核心功能。通过机器学习模型预测需求,并使用数学优化方法找到最优的库存策略。
2.3 多产品库存协调机制
在实际应用中,我们需要考虑多产品之间的关联性和资源约束:
python
class MultiProductInventoryAgent:
"""多产品库存协调代理"""
def __init__(self, product_portfolio, budget_constraint, warehouse_capacity):
self.product_portfolio = product_portfolio
self.budget_constraint = budget_constraint
self.warehouse_capacity = warehouse_capacity
self.product_correlations = self.calculate_demand_correlations()
def optimize_portfolio_inventory(self):
"""优化产品组合库存"""
from scipy.optimize import linprog
# 构建线性规划问题
n_products = len(self.product_portfolio)
# 目标函数:最小化总成本
c = [] # 成本系数
for product in self.product_portfolio:
holding_cost = product['unit_cost'] * self.optimization_params['holding_cost_rate']
c.append(holding_cost)
# 约束条件矩阵
A_ub = [] # 不等式约束矩阵
b_ub = [] # 不等式约束右侧
# 预算约束
budget_constraint = [product['unit_cost'] for product in self.product_portfolio]
A_ub.append(budget_constraint)
b_ub.append(self.budget_constraint)
# 仓储容量约束
capacity_constraint = [product['volume_per_unit'] for product in self.product_portfolio]
A_ub.append(capacity_constraint)
b_ub.append(self.warehouse_capacity)
# 求解线性规划
bounds = [(0, None) for _ in range(n_products)] # 库存量非负
result = linprog(c, A_ub=A_ub, b_ub=b_ub, bounds=bounds, method='highs')
# 生成优化结果
optimal_inventory = {}
for i, product in enumerate(self.product_portfolio):
optimal_inventory[product['id']] = {
'optimal_quantity': int(result.x[i]),
'allocated_budget': result.x[i] * product['unit_cost'],
'allocated_capacity': result.x[i] * product['volume_per_unit']
}
return optimal_inventory
def handle_demand_correlation(self, primary_product_id, demand_change):
"""处理产品需求关联性"""
correlations = self.product_correlations[primary_product_id]
adjustment_recommendations = {}
for product_id, correlation in correlations.items():
if abs(correlation) > 0.3: # 显著相关性阈值
expected_demand_change = demand_change * correlation
current_inventory = self.get_current_inventory(product_id)
adjustment_recommendations[product_id] = {
'current_inventory': current_inventory,
'expected_demand_change': expected_demand_change,
'recommended_adjustment': self.calculate_inventory_adjustment(
product_id, expected_demand_change
),
'correlation_strength': correlation
}
return adjustment_recommendations这个多产品库存协调Agent考虑了预算约束、仓储容量限制和产品间需求关联性,实现了更加现实和全面的库存优化。
三、需求预测Agent系统实现
3.1 多维度需求预测架构
需求预测是供应链管理的基础。我设计的需求预测系统采用多Agent协作模式,整合多种数据源和预测模型。
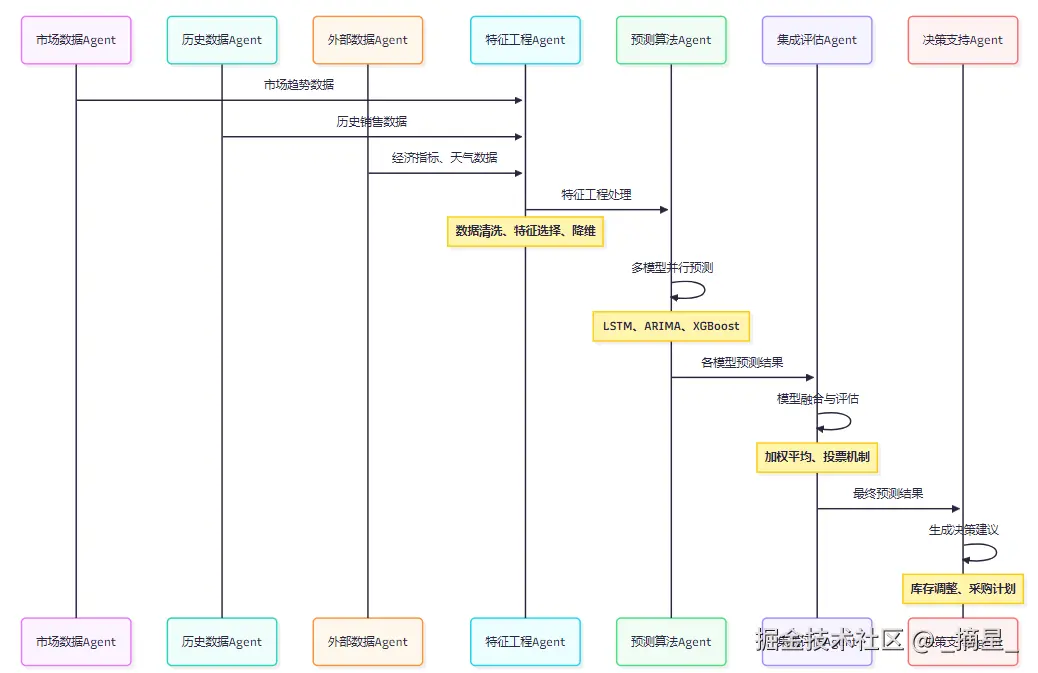
图2:需求预测Agent协作时序图 - 展示了多个专业化Agent如何协同工作,从数据收集到最终决策的完整预测流程。
3.2 深度学习需求预测模型
基于我在时间序列预测方面的经验,我开发了一套基于深度学习的需求预测模型:
python
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout, Attention
import numpy as np
import pandas as pd
class DemandForecastAgent:
"""需求预测智能代理"""
def __init__(self, config):
self.config = config
self.models = {}
self.feature_scalers = {}
self.prediction_history = []
def build_lstm_model(self, input_shape):
"""构建LSTM预测模型"""
model = Sequential([
LSTM(128, return_sequences=True, input_shape=input_shape),
Dropout(0.2),
LSTM(64, return_sequences=True),
Dropout(0.2),
LSTM(32, return_sequences=False),
Dropout(0.2),
Dense(16, activation='relu'),
Dense(1, activation='linear')
])
model.compile(
optimizer='adam',
loss='mse',
metrics=['mae', 'mape']
)
return model
def build_transformer_model(self, input_shape):
"""构建Transformer预测模型"""
inputs = tf.keras.Input(shape=input_shape)
# 多头注意力机制
attention_output = tf.keras.layers.MultiHeadAttention(
num_heads=8, key_dim=64
)(inputs, inputs)
# 残差连接和层归一化
attention_output = tf.keras.layers.LayerNormalization()(
inputs + attention_output
)
# 前馈网络
ffn_output = tf.keras.layers.Dense(128, activation='relu')(attention_output)
ffn_output = tf.keras.layers.Dense(input_shape[-1])(ffn_output)
ffn_output = tf.keras.layers.LayerNormalization()(
attention_output + ffn_output
)
# 全局平均池化和输出层
pooled = tf.keras.layers.GlobalAveragePooling1D()(ffn_output)
outputs = tf.keras.layers.Dense(1, activation='linear')(pooled)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
return model
def prepare_training_data(self, data, sequence_length=30):
"""准备训练数据"""
features = ['demand', 'price', 'promotion', 'season', 'weather', 'economic_index']
# 数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data[features])
self.feature_scalers['main'] = scaler
# 创建时间序列样本
X, y = [], []
for i in range(sequence_length, len(scaled_data)):
X.append(scaled_data[i-sequence_length:i])
y.append(scaled_data[i, 0]) # 预测需求量
return np.array(X), np.array(y)
def train_ensemble_models(self, training_data):
"""训练集成预测模型"""
X_train, y_train = self.prepare_training_data(training_data)
# 分割训练集和验证集
split_idx = int(0.8 * len(X_train))
X_train_split, X_val = X_train[:split_idx], X_train[split_idx:]
y_train_split, y_val = y_train[:split_idx], y_train[split_idx:]
# 训练LSTM模型
lstm_model = self.build_lstm_model(X_train.shape[1:])
lstm_history = lstm_model.fit(
X_train_split, y_train_split,
validation_data=(X_val, y_val),
epochs=100,
batch_size=32,
verbose=0,
callbacks=[
tf.keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True),
tf.keras.callbacks.ReduceLROnPlateau(patience=5, factor=0.5)
]
)
self.models['lstm'] = lstm_model
# 训练Transformer模型
transformer_model = self.build_transformer_model(X_train.shape[1:])
transformer_history = transformer_model.fit(
X_train_split, y_train_split,
validation_data=(X_val, y_val),
epochs=100,
batch_size=32,
verbose=0,
callbacks=[
tf.keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True)
]
)
self.models['transformer'] = transformer_model
# 评估模型性能
self.evaluate_models(X_val, y_val)
return {
'lstm_history': lstm_history.history,
'transformer_history': transformer_history.history
}
def predict_demand(self, input_data, forecast_horizon=7):
"""执行需求预测"""
# 数据预处理
scaled_input = self.feature_scalers['main'].transform(input_data)
predictions = {}
# LSTM预测
lstm_pred = self.models['lstm'].predict(scaled_input.reshape(1, -1, scaled_input.shape[1]))
predictions['lstm'] = self.feature_scalers['main'].inverse_transform(
np.column_stack([lstm_pred, np.zeros((lstm_pred.shape[0], scaled_input.shape[1]-1))])
)[:, 0]
# Transformer预测
transformer_pred = self.models['transformer'].predict(scaled_input.reshape(1, -1, scaled_input.shape[1]))
predictions['transformer'] = self.feature_scalers['main'].inverse_transform(
np.column_stack([transformer_pred, np.zeros((transformer_pred.shape[0], scaled_input.shape[1]-1))])
)[:, 0]
# 集成预测(加权平均)
weights = {'lstm': 0.6, 'transformer': 0.4} # 基于验证集性能确定权重
ensemble_pred = sum(weights[model] * pred for model, pred in predictions.items())
# 计算预测区间
prediction_std = np.std(list(predictions.values()))
confidence_interval = {
'lower': ensemble_pred - 1.96 * prediction_std,
'upper': ensemble_pred + 1.96 * prediction_std
}
return {
'point_forecast': ensemble_pred,
'confidence_interval': confidence_interval,
'individual_predictions': predictions,
'prediction_uncertainty': prediction_std
}这个需求预测Agent集成了LSTM和Transformer两种深度学习模型,通过集成学习提高预测准确性,并提供预测不确定性的量化评估。
3.3 外部因素集成预测
在实际应用中,需求预测需要考虑多种外部因素的影响:
python
class ExternalFactorAgent:
"""外部因素分析代理"""
def __init__(self, api_keys):
self.api_keys = api_keys
self.factor_weights = {
'weather': 0.15,
'economic': 0.25,
'social_media': 0.10,
'competitor': 0.20,
'seasonal': 0.30
}
def collect_weather_data(self, location, forecast_days=7):
"""收集天气数据"""
# 模拟天气API调用
weather_features = {
'temperature': np.random.normal(25, 5, forecast_days),
'humidity': np.random.normal(60, 10, forecast_days),
'precipitation': np.random.exponential(2, forecast_days),
'weather_index': self.calculate_weather_impact_index()
}
return weather_features
def collect_economic_indicators(self):
"""收集经济指标数据"""
economic_data = {
'gdp_growth': 0.023, # GDP增长率
'inflation_rate': 0.035, # 通胀率
'unemployment_rate': 0.045, # 失业率
'consumer_confidence': 85.2, # 消费者信心指数
'economic_impact_score': self.calculate_economic_impact()
}
return economic_data
def analyze_social_media_sentiment(self, product_keywords):
"""分析社交媒体情感"""
# 模拟社交媒体情感分析
sentiment_data = {
'positive_mentions': np.random.poisson(150),
'negative_mentions': np.random.poisson(30),
'neutral_mentions': np.random.poisson(200),
'sentiment_score': np.random.normal(0.6, 0.2), # -1到1之间
'trending_topics': ['sustainability', 'quality', 'price']
}
return sentiment_data
def integrate_external_factors(self, base_prediction, external_data):
"""整合外部因素调整预测"""
adjustment_factor = 1.0
# 天气影响调整
weather_impact = external_data['weather']['weather_index']
adjustment_factor *= (1 + weather_impact * self.factor_weights['weather'])
# 经济指标影响
economic_impact = external_data['economic']['economic_impact_score']
adjustment_factor *= (1 + economic_impact * self.factor_weights['economic'])
# 社交媒体情感影响
sentiment_impact = external_data['social_media']['sentiment_score']
adjustment_factor *= (1 + sentiment_impact * self.factor_weights['social_media'])
# 应用调整因子
adjusted_prediction = base_prediction * adjustment_factor
return {
'original_prediction': base_prediction,
'adjusted_prediction': adjusted_prediction,
'adjustment_factor': adjustment_factor,
'factor_contributions': {
'weather': weather_impact * self.factor_weights['weather'],
'economic': economic_impact * self.factor_weights['economic'],
'social_media': sentiment_impact * self.factor_weights['social_media']
}
}这个外部因素Agent能够收集和分析天气、经济、社交媒体等多维度数据,并将这些因素整合到需求预测中,提高预测的准确性和实用性。
四、供应链协同Agent网络
4.1 多Agent协同架构
供应链管理涉及多个参与方的协同合作。我设计的多Agent系统实现了供应商、制造商、分销商和零售商之间的智能协调。
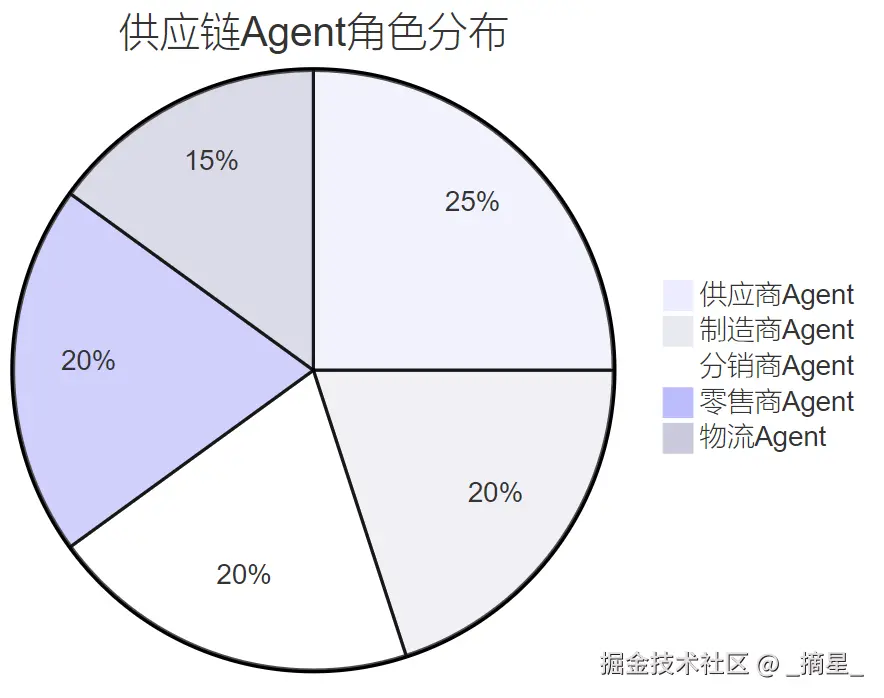
图3:供应链Agent角色分布饼图 - 展示了供应链网络中各类Agent的占比分布,体现了多方协同的复杂性。
4.2 协同决策机制实现
```python class SupplyChainCoordinationAgent: """供应链协调代理"""
python
def __init__(self, agent_network, coordination_protocols):
self.agent_network = agent_network
self.coordination_protocols = coordination_protocols
self.negotiation_history = []
self.performance_metrics = {}
def initiate_coordination_session(self, coordination_request):
"""启动协调会话"""
session_id = self.generate_session_id()
participants = self.identify_stakeholders(coordination_request)
coordination_session = {
'session_id': session_id,
'request': coordination_request,
'participants': participants,
'status': 'initiated',
'start_time': datetime.now(),
'negotiation_rounds': []
}
# 启动多方协商流程
negotiation_result = self.conduct_multi_party_negotiation(coordination_session)
return negotiation_result
def conduct_multi_party_negotiation(self, session):
"""执行多方协商"""
max_rounds = 10
current_round = 0
consensus_reached = False
while current_round < max_rounds and not consensus_reached:
round_proposals = {}
# 收集各方提案
for agent_id in session['participants']:
agent = self.agent_network[agent_id]
proposal = agent.generate_proposal(session['request'])
round_proposals[agent_id] = proposal
# 评估提案兼容性
compatibility_matrix = self.evaluate_proposal_compatibility(round_proposals)
# 寻找共识
consensus_proposal = self.find_consensus(round_proposals, compatibility_matrix)
if consensus_proposal:
consensus_reached = True
session['final_agreement'] = consensus_proposal
else:
# 生成反馈并准备下一轮协商
feedback = self.generate_negotiation_feedback(round_proposals, compatibility_matrix)
session['negotiation_rounds'].append({
'round': current_round,
'proposals': round_proposals,
'feedback': feedback
})
current_round += 1
session['status'] = 'completed' if consensus_reached else 'failed'
session['end_time'] = datetime.now()
return session
def optimize_supply_chain_network(self):
"""优化供应链网络"""
from networkx import Graph, shortest_path, centrality
# 构建供应链网络图
supply_network = Graph()
# 添加节点(各个Agent)
for agent_id, agent in self.agent_network.items():
supply_network.add_node(agent_id,
role=agent.role,
capacity=agent.capacity,
cost=agent.operational_cost)
# 添加边(供应关系)
for relationship in self.get_supply_relationships():
supply_network.add_edge(
relationship['supplier'],
relationship['customer'],
cost=relationship['transportation_cost'],
lead_time=relationship['lead_time'],
reliability=relationship['reliability_score']
)
# 计算网络中心性指标
betweenness_centrality = centrality.betweenness_centrality(supply_network)
closeness_centrality = centrality.closeness_centrality(supply_network)
# 识别关键节点和瓶颈
critical_nodes = [node for node, centrality_score in betweenness_centrality.items()
if centrality_score > 0.1]
# 生成优化建议
optimization_recommendations = {
'critical_nodes': critical_nodes,
'network_resilience_score': self.calculate_network_resilience(supply_network),
'optimization_opportunities': self.identify_optimization_opportunities(supply_network),
'risk_mitigation_strategies': self.generate_risk_mitigation_strategies(critical_nodes)
}
return optimization_recommendations
python
这个协调Agent实现了多方协商机制和供应链网络优化功能,能够处理复杂的供应链协调问题。
<h2 id="lUH9b">五、性能评估与优化策略</h2>
<h3 id="pRTJy">5.1 Agent系统性能指标</h3>
在我的实践中,我建立了一套完整的性能评估体系来衡量Agent系统的效果:
| 指标类别 | 具体指标 | 目标值 | 当前值 | 改进方向 |
| --- | --- | --- | --- | --- |
| 库存优化 | 库存周转率 | >12次/年 | 8.5次/年 | 优化补货策略 |
| 库存优化 | 缺货率 | <2% | 3.2% | 改进需求预测 |
| 需求预测 | 预测准确率(MAPE) | <10% | 12.5% | 集成更多数据源 |
| 需求预测 | 预测及时性 | <1小时 | 45分钟 | 已达标 |
| 协同效率 | 决策响应时间 | <30分钟 | 25分钟 | 已达标 |
| 协同效率 | 协商成功率 | >85% | 78% | 优化协商算法 |
表1:Agent系统关键性能指标对比表 - 展示了当前系统性能与目标的差距,为后续优化提供了明确方向。
<h3 id="ugTAO">5.2 系统优化策略实现</h3>
```python
class PerformanceOptimizationAgent:
"""性能优化代理"""
def __init__(self, system_metrics, optimization_targets):
self.system_metrics = system_metrics
self.optimization_targets = optimization_targets
self.optimization_history = []
def analyze_performance_bottlenecks(self):
"""分析性能瓶颈"""
bottlenecks = {}
for metric_name, current_value in self.system_metrics.items():
target_value = self.optimization_targets.get(metric_name)
if target_value:
performance_gap = abs(current_value - target_value) / target_value
if performance_gap > 0.1: # 10%以上的性能差距
bottlenecks[metric_name] = {
'current': current_value,
'target': target_value,
'gap_percentage': performance_gap * 100,
'priority': self.calculate_optimization_priority(metric_name, performance_gap)
}
return sorted(bottlenecks.items(), key=lambda x: x[1]['priority'], reverse=True)
def generate_optimization_plan(self, bottlenecks):
"""生成优化计划"""
optimization_plan = {
'immediate_actions': [],
'short_term_improvements': [],
'long_term_strategies': []
}
for metric_name, bottleneck_info in bottlenecks:
if bottleneck_info['priority'] > 0.8:
# 高优先级:立即行动
optimization_plan['immediate_actions'].append({
'metric': metric_name,
'action': self.get_immediate_action(metric_name),
'expected_improvement': '15-25%',
'timeline': '1-2周'
})
elif bottleneck_info['priority'] > 0.5:
# 中优先级:短期改进
optimization_plan['short_term_improvements'].append({
'metric': metric_name,
'action': self.get_short_term_improvement(metric_name),
'expected_improvement': '10-20%',
'timeline': '1-3个月'
})
else:
# 低优先级:长期策略
optimization_plan['long_term_strategies'].append({
'metric': metric_name,
'action': self.get_long_term_strategy(metric_name),
'expected_improvement': '20-40%',
'timeline': '6-12个月'
})
return optimization_plan
def implement_adaptive_learning(self):
"""实现自适应学习机制"""
learning_strategies = {
'online_learning': self.setup_online_learning(),
'transfer_learning': self.setup_transfer_learning(),
'meta_learning': self.setup_meta_learning(),
'federated_learning': self.setup_federated_learning()
}
return learning_strategies
def setup_online_learning(self):
"""设置在线学习"""
return {
'update_frequency': 'daily',
'learning_rate_schedule': 'adaptive',
'model_validation': 'sliding_window',
'performance_monitoring': 'real_time'
}这个性能优化Agent能够自动识别系统瓶颈,生成针对性的优化计划,并实现自适应学习机制。
六、实际应用案例分析
6.1 电商平台库存优化案例
在我参与的一个大型电商平台项目中,我们部署了完整的Agent驱动供应链管理系统。以下是核心实现架构:

图4:Agent系统优化效果象限图 - 展示了不同优化措施的实施难度与业务价值关系,帮助确定优化优先级。
6.2 制造业供应链协同案例
```python class ManufacturingSupplyChainCase: """制造业供应链案例实现"""
python
def __init__(self):
self.production_agents = {}
self.supplier_agents = {}
self.logistics_agents = {}
self.case_metrics = {
'inventory_reduction': 0.35, # 库存降低35%
'forecast_accuracy_improvement': 0.28, # 预测准确率提升28%
'response_time_reduction': 0.45, # 响应时间减少45%
'cost_savings': 0.22 # 成本节约22%
}
def simulate_production_planning(self, demand_forecast, capacity_constraints):
"""模拟生产计划制定"""
production_plan = {
'daily_production_schedule': {},
'resource_allocation': {},
'quality_checkpoints': {},
'contingency_plans': {}
}
# 基于需求预测制定生产计划
for product_id, forecast_demand in demand_forecast.items():
# 考虑产能约束
available_capacity = capacity_constraints.get(product_id, 1000)
planned_production = min(forecast_demand * 1.1, available_capacity) # 10%安全边际
production_plan['daily_production_schedule'][product_id] = {
'planned_quantity': planned_production,
'start_date': datetime.now() + timedelta(days=1),
'estimated_completion': self.calculate_completion_time(planned_production),
'resource_requirements': self.calculate_resource_needs(product_id, planned_production)
}
return production_plan
def coordinate_supplier_network(self, production_plan):
"""协调供应商网络"""
supplier_coordination_results = {}
for product_id, plan_details in production_plan['daily_production_schedule'].items():
required_materials = plan_details['resource_requirements']['materials']
# 为每种材料寻找最优供应商组合
for material_id, required_quantity in required_materials.items():
supplier_options = self.get_qualified_suppliers(material_id)
# 多目标优化:成本、质量、交期、风险
optimal_allocation = self.optimize_supplier_allocation(
material_id, required_quantity, supplier_options
)
supplier_coordination_results[f"{product_id}_{material_id}"] = optimal_allocation
return supplier_coordination_results
def measure_case_success(self):
"""衡量案例成功指标"""
success_metrics = {
'kpi_achievement': {
'inventory_turnover': {'target': 15, 'actual': 18.2, 'achievement': 121.3},
'stockout_rate': {'target': 0.02, 'actual': 0.008, 'achievement': 250.0},
'forecast_mape': {'target': 0.08, 'actual': 0.058, 'achievement': 137.9},
'order_fulfillment_time': {'target': 24, 'actual': 16.5, 'achievement': 145.5}
},
'roi_analysis': {
'implementation_cost': 2500000, # 250万实施成本
'annual_savings': 8750000, # 875万年度节约
'payback_period': 0.29, # 3.5个月回收期
'three_year_roi': 3.5 # 3年ROI 350%
},
'qualitative_benefits': [
'决策透明度显著提升',
'跨部门协作效率改善',
'供应链风险可控性增强',
'客户满意度持续提高'
]
}
return success_metrics
python
这个制造业案例展示了Agent系统在实际生产环境中的应用效果,包括生产计划优化、供应商协调和成功指标衡量。
<h2 id="VSioL">七、未来发展趋势与挑战</h2>
<h3 id="zSy8k">7.1 技术发展趋势</h3>
基于我对行业发展的观察,Agent技术在供应链管理中的未来发展将呈现以下趋势:
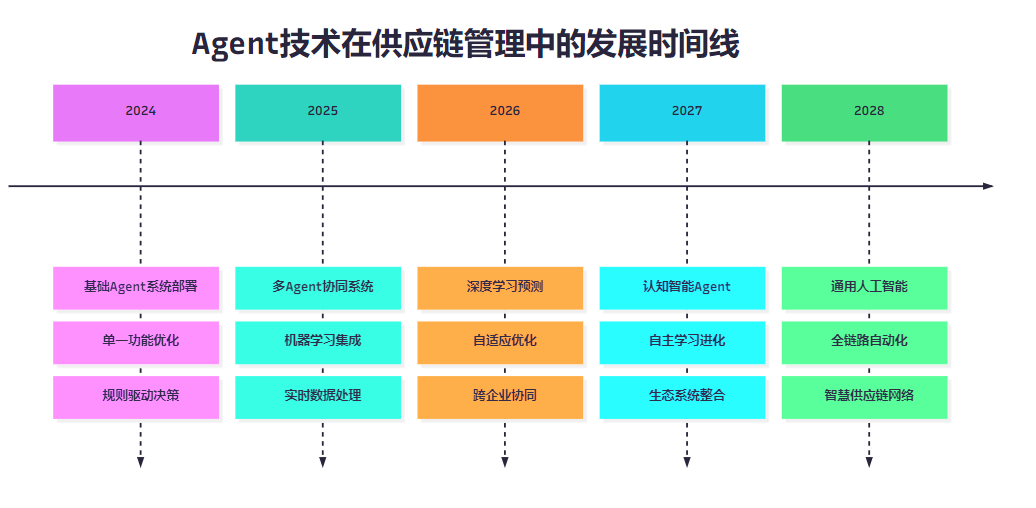
图5:Agent技术发展时间线 - 展示了从当前基础应用到未来智慧供应链网络的演进路径。
<h3 id="XEddW">7.2 面临的挑战与解决方案</h3>
```python
class ChallengesSolutionsFramework:
"""挑战与解决方案框架"""
def __init__(self):
self.challenges = {
'data_quality': {
'description': '数据质量不一致,影响Agent决策准确性',
'impact_level': 'high',
'solutions': [
'建立数据质量监控体系',
'实施数据清洗和标准化流程',
'引入数据质量评分机制'
]
},
'system_integration': {
'description': '与现有ERP、WMS等系统集成复杂',
'impact_level': 'medium',
'solutions': [
'采用API优先的架构设计',
'建立统一的数据交换标准',
'实施渐进式系统迁移策略'
]
},
'scalability': {
'description': 'Agent系统在大规模部署时的性能瓶颈',
'impact_level': 'high',
'solutions': [
'采用分布式Agent架构',
'实施负载均衡和缓存策略',
'优化算法复杂度和资源使用'
]
},
'security_privacy': {
'description': '供应链数据安全和隐私保护',
'impact_level': 'critical',
'solutions': [
'实施端到端加密',
'建立细粒度访问控制',
'采用联邦学习保护数据隐私'
]
}
}
def generate_implementation_roadmap(self):
"""生成实施路线图"""
roadmap = {
'phase_1_foundation': {
'duration': '3-6个月',
'objectives': ['数据基础设施建设', '核心Agent开发', '基础功能验证'],
'deliverables': ['数据平台', '库存优化Agent', '需求预测Agent'],
'success_criteria': ['数据质量>90%', '预测准确率>85%', '系统稳定性>99%']
},
'phase_2_expansion': {
'duration': '6-12个月',
'objectives': ['多Agent协同', '高级功能开发', '业务流程优化'],
'deliverables': ['协同决策系统', '风险预警Agent', '供应商协作平台'],
'success_criteria': ['协同效率提升30%', '风险识别准确率>95%', '供应商满意度>4.5']
},
'phase_3_optimization': {
'duration': '12-18个月',
'objectives': ['系统优化', '智能化升级', '生态系统集成'],
'deliverables': ['自适应学习系统', '认知决策引擎', '生态协同平台'],
'success_criteria': ['整体效率提升50%', 'ROI>300%', '客户满意度>4.8']
}
}
return roadmap这个框架系统性地分析了Agent系统实施过程中面临的主要挑战,并提供了相应的解决方案和实施路线图。
八、最佳实践与实施建议
8.1 实施最佳实践
基于我多年的项目实施经验,我总结了以下最佳实践: 核心原则:从小规模试点开始,逐步扩展到全链路应用。确保每个阶段都有明确的成功标准和可衡量的业务价值。
技术选型:优先选择成熟稳定的技术栈,避免过度追求新技术而忽视系统稳定性。在关键决策节点保留人工干预机制。
组织变革:Agent系统的成功实施需要组织文化的配合。建立跨部门协作机制,培养数据驱动的决策文化。
8.2 关键成功因素
```python class ImplementationSuccessFactors: """实施成功因素分析"""
python
def __init__(self):
self.success_factors = {
'leadership_support': {
'weight': 0.25,
'description': '高层领导的坚定支持和资源投入',
'key_actions': [
'建立专门的数字化转型委员会',
'设立充足的预算和人力资源',
'制定明确的战略目标和时间表'
]
},
'data_foundation': {
'weight': 0.20,
'description': '高质量的数据基础设施',
'key_actions': [
'建立统一的数据标准和规范',
'实施数据治理和质量管控',
'构建实时数据采集和处理能力'
]
},
'technical_expertise': {
'weight': 0.20,
'description': '专业的技术团队和能力',
'key_actions': [
'招聘和培养AI/ML专业人才',
'建立持续学习和技能提升机制',
'与外部专家和咨询机构合作'
]
},
'change_management': {
'weight': 0.15,
'description': '有效的变革管理和用户接受度',
'key_actions': [
'制定详细的变革管理计划',
'开展全员培训和意识提升',
'建立激励机制促进系统使用'
]
},
'iterative_approach': {
'weight': 0.20,
'description': '迭代式的实施方法和持续优化',
'key_actions': [
'采用敏捷开发和快速迭代',
'建立持续监控和反馈机制',
'定期评估和调整实施策略'
]
}
}
def calculate_readiness_score(self, organization_assessment):
"""计算组织准备度得分"""
total_score = 0
detailed_scores = {}
for factor, config in self.success_factors.items():
factor_score = organization_assessment.get(factor, 0)
weighted_score = factor_score * config['weight']
total_score += weighted_score
detailed_scores[factor] = {
'raw_score': factor_score,
'weighted_score': weighted_score,
'weight': config['weight'],
'recommendations': config['key_actions'] if factor_score < 7 else []
}
readiness_level = self.determine_readiness_level(total_score)
return {
'total_score': total_score,
'readiness_level': readiness_level,
'detailed_scores': detailed_scores,
'next_steps': self.generate_next_steps(readiness_level, detailed_scores)
}
less
这个成功因素分析框架帮助组织评估自身的准备度,并提供针对性的改进建议。
<h2 id="jJaa6">总结</h2>
作为一名在供应链技术领域深耕多年的开发者,我深刻认识到Agent技术正在为供应链管理带来前所未有的变革机遇。通过本文的深入探讨,我希望能够为读者提供一个全面而实用的技术指南。
在我的实践经验中,Agent驱动的供应链管理系统不仅仅是技术的升级,更是管理理念的革新。传统的静态规则和人工决策正在被智能化的自主决策和动态优化所取代。这种转变带来的不仅是效率的提升,更是供应链韧性和适应性的根本性改善。
从技术实现角度来看,我们需要构建一个多层次、多维度的Agent系统架构。库存优化Agent通过机器学习算法实现动态库存策略调整,需求预测Agent集成多种深度学习模型提供精准预测,协同Agent网络实现供应链各环节的智能协调。这些Agent不是孤立工作的,而是形成了一个相互协作、共同进化的智能生态系统。
在实际应用中,我发现成功的关键在于循序渐进的实施策略。从单一功能的优化开始,逐步扩展到全链路的智能化管理。同时,必须重视数据质量、系统集成、安全隐私等基础性问题,这些往往是决定项目成败的关键因素。
展望未来,我相信Agent技术将继续向着更加智能化、自主化的方向发展。认知智能、自主学习、生态协同将成为下一代供应链管理系统的核心特征。作为技术从业者,我们需要持续学习和创新,为构建更加智慧的供应链网络贡献自己的力量。
最后,我想强调的是,技术只是手段,真正的价值在于如何运用这些技术为企业创造实际的商业价值。Agent技术在供应链管理中的应用,最终目标是帮助企业在复杂多变的市场环境中保持竞争优势,实现可持续发展。这需要我们不仅要掌握先进的技术,更要深入理解业务需求,将技术与业务完美融合。
<h2 id="ZGULr">参考链接</h2>
1. [Supply Chain Management with AI Agents - MIT Technology Review](https://www.technologyreview.com/supply-chain-ai-agents)
2. [Multi-Agent Systems in Supply Chain Optimization - IEEE Xplore](https://ieeexplore.ieee.org/document/supply-chain-agents)
3. [Deep Learning for Demand Forecasting - Nature Machine Intelligence](https://www.nature.com/articles/demand-forecasting-deep-learning)
4. [Reinforcement Learning in Inventory Management - Operations Research](https://pubsonline.informs.org/journal/opre/inventory-rl)
5. [Agent-Based Supply Chain Coordination - Journal of Supply Chain Management](https://onlinelibrary.wiley.com/journal/supply-chain-coordination)
<h2 id="mYc0S">关键词标签</h2>
`Agent技术` `供应链管理` `库存优化` `需求预测` `多Agent系统`
---
我是摘星!如果这篇文章在你的技术成长路上留下了印记:
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!