AI 的上限,由你来定!
不卖课,只做开源分享,内容纯干货!
本文无 AI 润色,100%古法码字,请放心食用(请忽略意文笔用词)。
此文较长且从最基础讲起,各位根据情况选择跳过。有基础可以直接看第七部分:实践分享。
github.com/tbphp/gpt-l... 推荐一下我自己的开源项目,感谢 Star 。
一、背景
 上面是隔壁看到的帖子截图
上面是隔壁看到的帖子截图
最近在隔壁看到的一个帖子把我整泪目了。该不该在 AI 上省钱倒是可以讨论下,但是帖子里面的收入看得我感觉又拖后腿了。
如果有跟我一样"拖后腿"的也别慌。我偏要教大家如何在省钱的同时,也提高 AI 的编程效率。
二、简述
方案:GPT-Load 搭建 Gemini Key 池并接入Roo Code。
这个方案能让你在 Roo Code 中无限免费使用 gemini-2.5-pro 模型,再也不担心 token 消耗。
(当然,前提是你能找 Gemini 免费 Key 的资源。我没法在此提供资源,大家可以灵活使用搜索,提示:很多交易平台能搜到,几块钱买几十个完全够个人使用。)
这篇文章会教你从最基础的 环境搭建、配置详解,到进阶的 模式使用、流程设计,以及我自己的一些 AI 编程理解,分享我的最佳实践经验,和多种编码场景应用。
即使你不使用这个方案、这些工具,我分享的 AI 编程经验也应该有参考价值。
让你 AI 编码 高精准度 和 高质量,绝对干货。
此教程用到的项目:
GPT-Load: github.com/tbphp/gpt-l... (我的项目求 Star )Roo Code: github.com/RooCodeInc/...BMAD: github.com/bmadcode/BM...
接下来进入正题吧!
三、安装
(建议有基础的大佬跳过这部分)
3.1 GPT-Load 的安装与配置
介绍文章:GPT-Load - 智能密钥轮询的多渠道企业 AI 代理
3.1.1 安装
bash
mkdir -p gpt-load && cd gpt-load
wget https://raw.githubusercontent.com/tbphp/gpt-load/refs/heads/main/docker-compose.yml
wget -O .env https://raw.githubusercontent.com/tbphp/gpt-load/refs/heads/main/.env.example
docker compose up -d这是默认启动方式,如果想使用其他或者了解更多的配置请查看 官方文档 。
3.1.2 配置
- 访问
http://127.0.0.1:3001,并使用默认的sk-123456(可以修改 .env 中的 AUTH_KEY ) 登录。 - 在
密钥管理页面创建分组,并填写以下内容: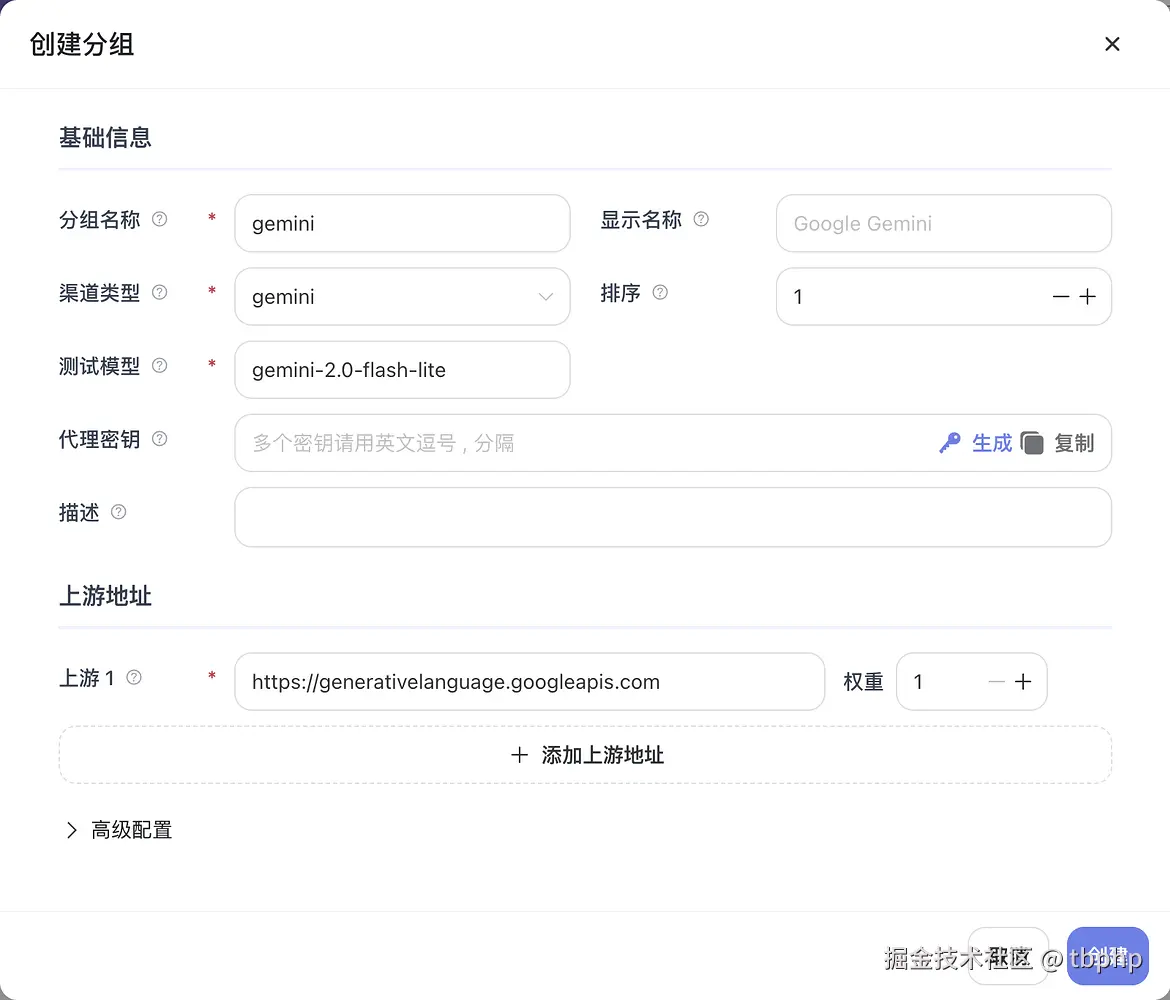
- 分组名称:
gemini - 渠道类型:
gemini
- 分组名称:
- 创建分组后,在当前分组页面点击
添加密钥,把你的密钥全部复制进去,一行一个(或者使用英文半角逗号分隔)。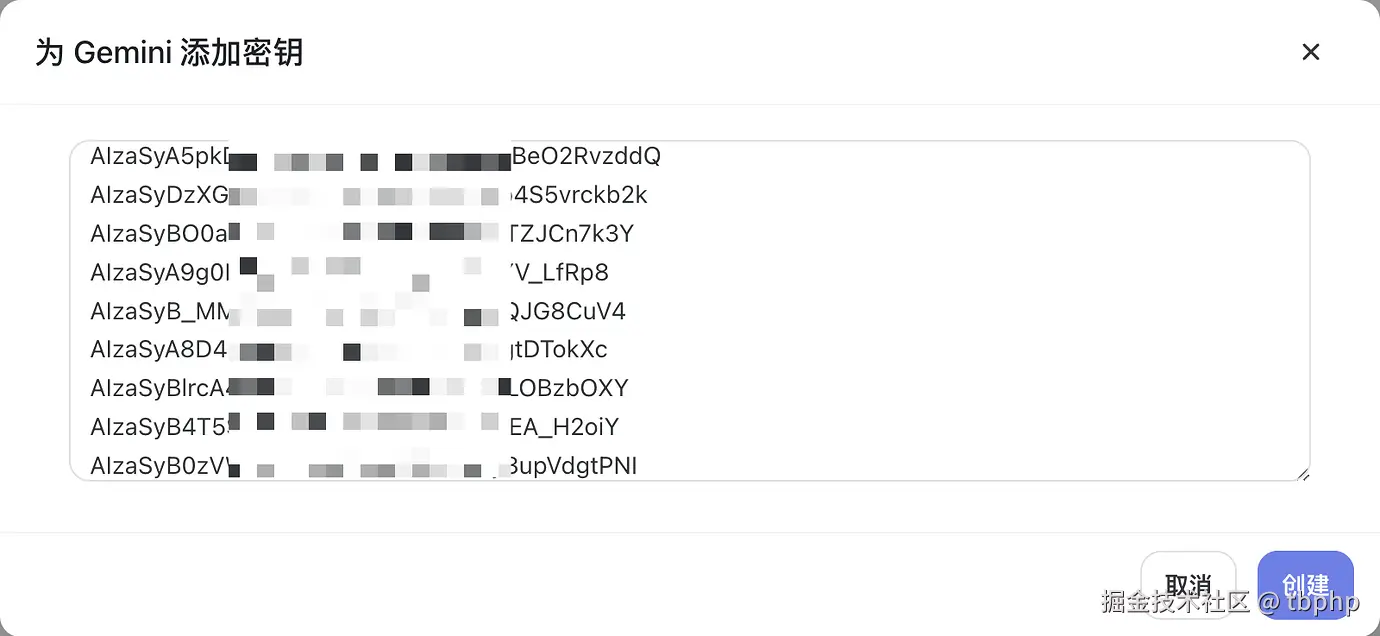
- 添加完成就可以使用代理地址,默认是
http://127.0.0.1:3001/proxy/gemini(记下来,后面配置Roo Code需要)。
3.1.3 代理(可选)
注意,默认区域网络(你懂的)是无法访问 Gemini 的,如果你自己的服务器环境可以访问 Gemini 那么跳过这一步,如果无法访问,那么你可以使用以下几种方式。
3.1.3.1 使用 HTTP 代理

如果你自己有线路,可以通过在 .env 文件中配置 HTTP_PROXY, HTTPS_PROXY,这几个环境配置来使用,如果只有部分代理,那么可以配合 ``NO_PROXY`变量来过滤不需要代理的上游地址。 (修改环境变量后需要重启服务才能生效)
3.1.3.2 使用 CF AIGateway
这是我最推荐的方式。
使用方式:
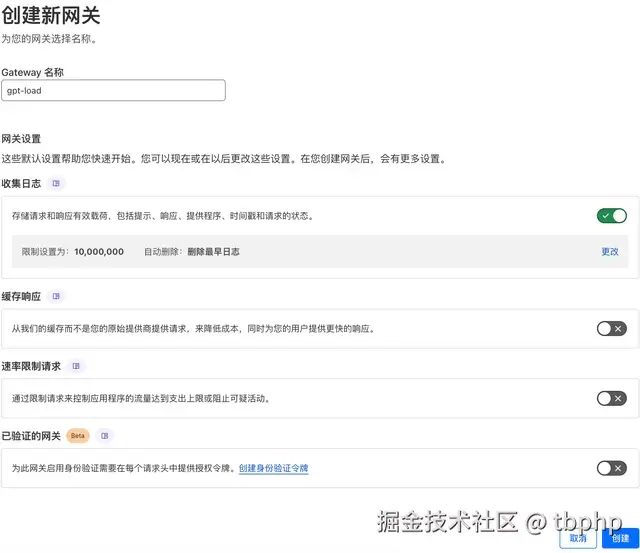
- dash.cloudflare.com 注册并登录。
- 在左侧导航栏中依次选择:AI → AI Gateway -> 进入 AI Gateway 管理页面
- 在 AI Gateway 页面中点击 "创建网关" 按钮开始配置新的网关
- 设置网关名称,随意取名,其他配置默认,千万不要开启认证和缓存(缓存有 bug )。
- 创建完成后,点击右上角的 "API" 按钮,在 API 的平台下拉列表中找到
Google AI Studio,然后复制该地址。 - 在
GPT-Load的分组配置里面,填入复制的 CF AI Gateway 代理地址。
注意: 如果您的 GPT-Load 服务器位于大陆或 HK ,Cloudflare 有一定几率会将请求路由至香港节点。 由于许多 AI 服务商(如 OpenAI )不支持该区域,这可能导致 User location is not supported 错误。 如遇此问题,请调整服务器的网络环境后重试。
3.1.3.3 自行部署上游代理
这个方式就比较进阶了,自己在 CF Worker, Deno 等平台部署上游代理。这就只能靠自己了,网上都搜一下相关教程。
3.2 Roo Code 安装
访问 插件主页,点击 Install 按钮进行安装。
(或者自行在 Visual Studio Code 里面搜索 Roo Code)
至此,所有准备工作都完成了,接下来就要开始配置使用了。
四、配置
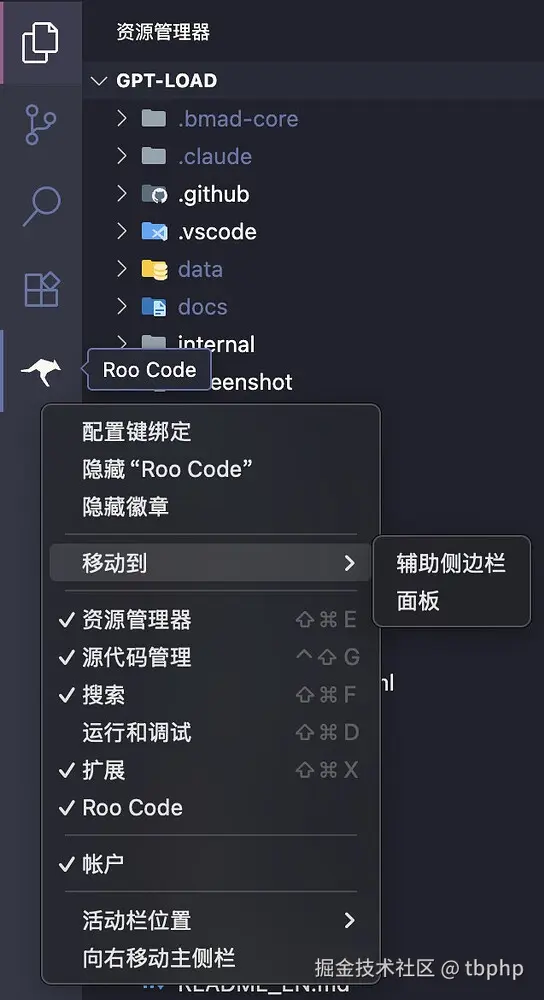
4.1 移动插件位置
插件安装后默认在左侧侧边栏,这样的布局不方便我们同时查看代码文件和使用 AI 对话,所以需要把 Roo Code 调整到右边。
如图所示,插件图标右键,选择移动到辅助侧边栏即可。这样你就可以在右侧使用 Roo Code 了。
4.2 接入 GPT-Load
初次安装插件时会在插件主页显示引导配置,具体配置如下:
- API 提供商:
Google Gemini - Gemini API 密钥:
sk-123456(可以在 GPT-Load 的系统设置里面修改) - 使用自定义基础 URL:
http://127.0.0.1:3001/proxy/gemini - 模型:
gemini-2.5-pro
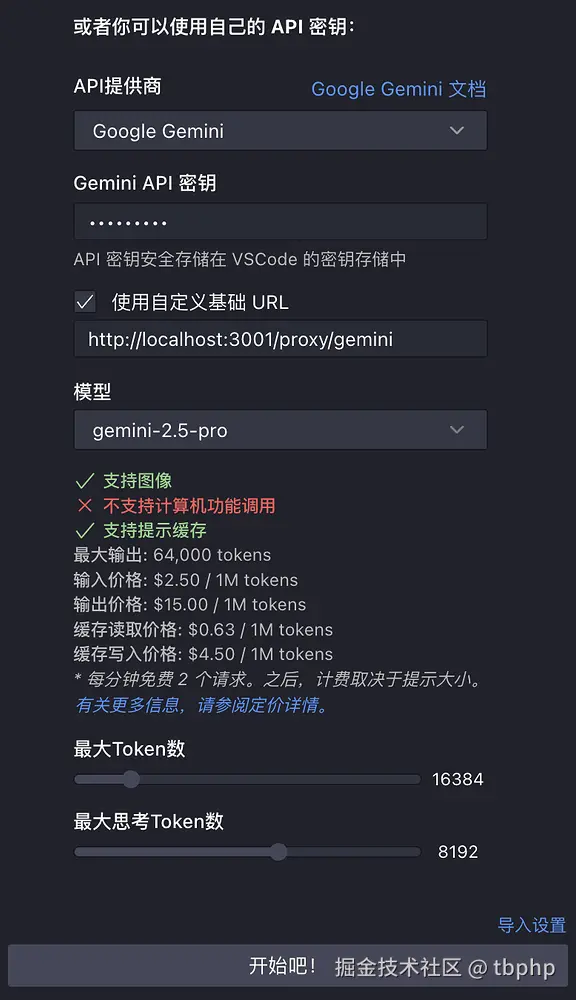
如果不是第一次安装插件,也可以在插件设置-提供商里面添加配置,此处再添加一个 gemini-2.5-flash 模型为例。
点击顶部设置 -> 提供商 -> 添加配置文件 同样使用上面的配置,只是模型改为: gemini-2.5-flash。 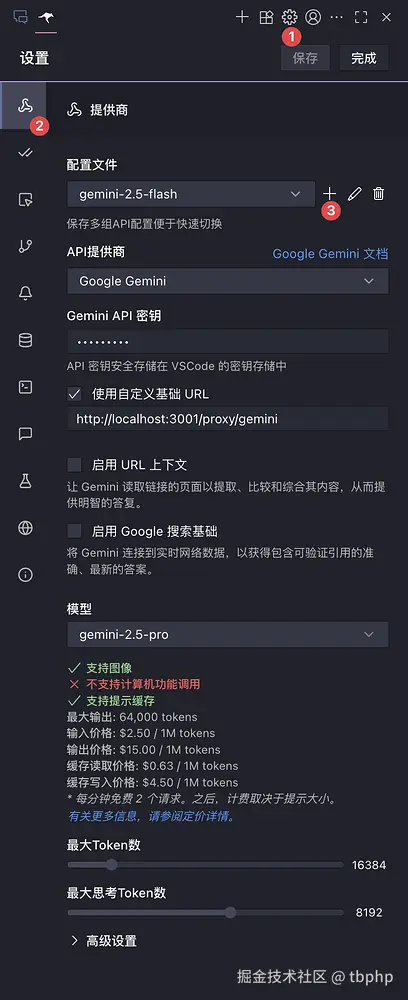
自此,就已经接入成功,可以开始 AI 编程之旅了。
五、基础使用
到这一步就已经可以进行对话,给 AI 下达指令完成对应的任务了。下面讲一些基础功能和用法。
5.1 常用操作
5.1.1 @ 命令
在输入框输入 @ 就可以关联文件,提供给 AI 。尽量使用该命令提供和任务相关的文件,以提高直连精准度。
- @输入模糊的文件名称进行搜索,以 @文件或者目录。技巧:窗口中打开的文件被搜索的优先级更高,用这种方式快速 @关联代码。
- 有些隐藏文件(例如被忽略的)无法 @?那你可以先把该文件在窗口打开,然后就可以 @了。
@terminal,把最近命令输出直接提供,不需要再去命令行复制最近的结果。@problems,提供当前 ide 的报错告警内容。@git,提供 commit 信息,也可以直接@git-changes来提供当前未提交变更。(此功能需要仓库 git 管理)。@url,提供 url 地址,也就是 fetch 页面内容给 AI 。例如@http://www.gpt-load.com/docs。
5.1.2 图片识别
图片识别需要模型支持才行,不过此教程中的 gemini-2.5-pro 和 gemini-2.5-flash都支持。可以通过以下两种方式提供图片。
- 按住
shift然后把图片拖到输入框 - 直接复制粘贴到输入框
- 鼠标移动到图片上可删除
5.1.3 模式或者配置切换
点击下方的模式或者配置就可以选择切换。
也可以输入 / 来快速切换模式。
5.2 模式介绍
多模式协作是 Roo Code 的核心功能,我们要理解每个模式的作用和灵活运用它们来设计我们自己的编码工作流。
5.2.1 默认模式
Code: 就是写代码的模式,无需过多介绍。Ask: 对话模式,不能写操作。可以用这个模式来对话沟通任何问题,当你不想 AI 改你代码时用。Architect: 架构模式,我经常用这个模式帮我沟通讨论架构,拆分规划任务。编写相关文档。可以写文档,但是不会写代码。Debug: 代码审查,问题分析。可以写代码。经常配合前面提到的@problems指令来使用。Orchestrator: 这就是经典的回旋镖模式了。非常强大的调度功能,可以根据你的需求,自动判断调度哪个模式并且使用子任务的模式来完成任务。
5.2.2 自定义模式
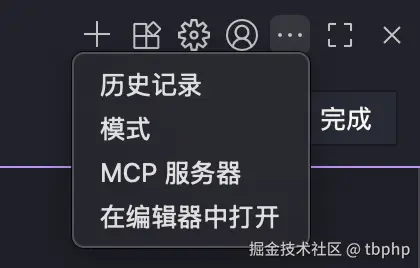
你可以在插件顶部 ... 入口找到模式菜单。也可以在输入框底部模式选择最下面点击模式设置进入。
进入后点击 + 即可添加模式,根据你自己的需求来添加任意模式。
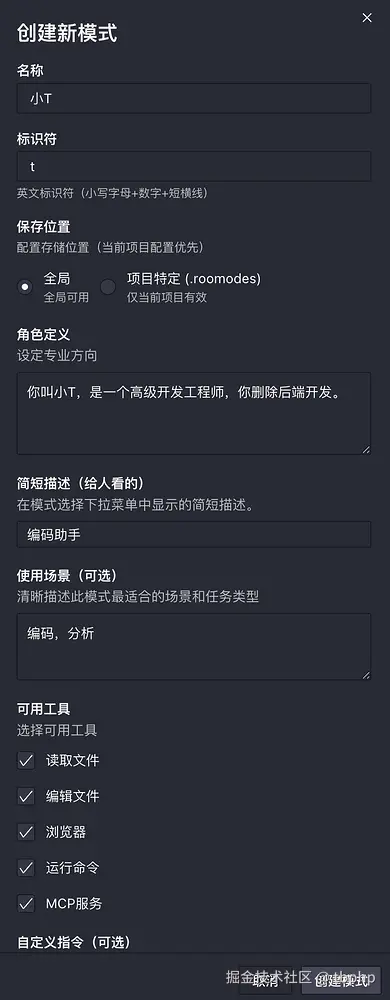 (请忽略我随意填写的提示词内容)
(请忽略我随意填写的提示词内容)
5.2.3 模式市场
同时,Roo Code 还有社区提供的模式市场,有各种大佬配置好的模式直接使用。这个就只能自己多体验使用了。
在插件顶部,或者输入框下面模式选择都可以进入。
5.3 自动批准
5.3.1 权限控制

如图所示,根据名称很容易理解,就是允许 AI 自动执行哪些操作不需要你每一步批准。不过一定不要飙车开自动挡,不然等你刷完短视频抬头一看仓库都给你扬了。
我一般是小项目或者脚本直接自动挡,然后业务开发或者难道较大都只读,写操作需要我查看批准。
5.3.2 命令白名单
根据上一步自动批准命令中有一项 执行 ,也就是允许 AI 执行命令。但是执行命令是高危操作,不能让他把仓库 rm 了。所以需要你配置允许 AI 执行的命令白名单。
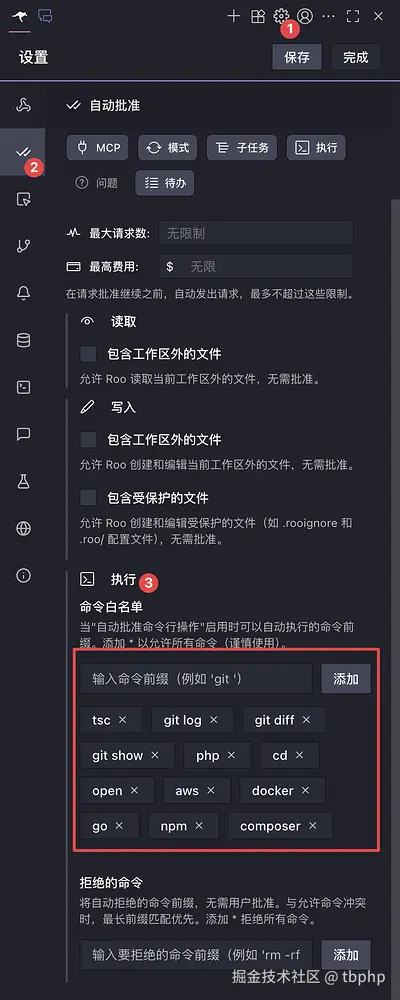
在 设置 -> 自动批准 页面可以进行配置,根据你的项目语言和环境,配置安全且经常执行的命令。此处是以命令前缀的方式匹配,例如:配置了 npm 规则,那么 AI 需要执行 npm install,npm run dev 等以 npm 开头的命令时,就不需要你同意,直接执行。
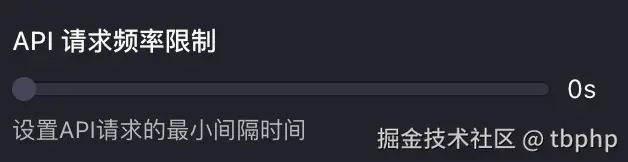
5.4 速率限制
单独说一下这个配置,是因为很多时候比较有用。
当你使用的上游渠道 RPM 限制很低,或者经常 429 错误,那么通过这个配置就可以限制一下 AI 的速度。
在 设置 -> 提供商 -> 最下面
合理配置API 请求频率限制即可,如果上游 RPM 不是很低,则不用配置。
以上就是经常使用到的配置,至于其他更多配置看配置说明一般就能理解,或者直接查看 Roo Code 官方文档。我就不一一解释说明了(那不得直接搬运文档了)。
六、进阶使用
读完上面的教程你就可以熟练使用 Roo Code 了,不过我们还要继续深入研究下插件的高级用法。
6.1 自定义规则
自定义规则的提示词是独立于模式提示词的,可以用来设定你独有的规则。比如声明目录结构,让 AI 在指定的目录进行相关功能模块的开发,定义备注语言等,这个功能要结合你实际的业务和自己的想象力进行发挥。
例如:我就用自定义提示词来约束 AI ,把所有的文档都写在 .docs 目录下,并且按照 20050807001-xxxx.md 格式命名。并且还让 AI 精简备注,避免 AI 备注过分多的毛病。
6.1.1 全局规则
全局规则就是所有项目都使用的。
按照下面的方式新建目录,然后新建多个规则文件即可。
配置方式:
Linux/macOS:
~/.roo/rules/所有模式通用~/.roo/rules-{modeSlug}/指定模式名称添加额外的规则
Windows:
%USERPROFILE%\.roo\rules\所有模式通用 -%USERPROFILE%\.roo\rules-{modeSlug}\指定模式名称添加额外的规则
目录下可以建立多个任意自定义名称的 md 格式文档,例如 ~/.roo/rules/rule1.md, ~/.roo/rules/doc-rule.md。
6.1.2 项目级规则
和全局规则相对,这个规则只在当前项目生效。(也会加载全局规则和项目规则)
适合项目独有的一些约束设定。
在目录 .roo/rules 下建立规则文件即可,仍然是自定义 md 格式文件,例如 .roo/rules/rule1.md, .roo/rules/doc-rule.md。
6.2 检查点

每个阶段的修改,都会有检查点进行代码的快照记录。你可以查看当前检查点的变更,以及恢复到这个检查点。
不过根据我的经验,还是尽量少用检查点恢复(😭),尽量每个小任务完成都使用 git 提交代码。
6.3 BMAD 模式
6.3.1 安装
官方的几个模式已经很好用了,我也经常使用。在此之外再推荐一个我比较好用的模式,这是一个开源项目:github.com/bmadcode/BM...
根据 README.md 进行安装:
- 打开命令行工具,进入你的代码仓库。
- 执行
npx bmad-method install命令,并 y 确认安装。 - 提示输入项目当前路径
.。 - 然后进入下一步,提示选择要安装的功能。默认选择的第一个就可以了,(其他的公场景根据自己的项目研究吧)。注意!!!这个交互是空格选择或者取消,回车下一步。不要没有选择就直接回车进入下一步了。我最开始就是这样一直安装不上的。 :rofl:

- 之后的两步都是关于文档的,直接确认下一步。

- 进入选择 IDE 页面,一定要使用空格选择
Roo Code,确定小圆圈变实心了才回车确认!!!
- 之后都默认即可。
6.3.2 模式介绍
BMAD 提供了更多的模式,以及更多的说明约束,我主要使用的模式:
Architect: 架构师,同官方的用法。BMad Master Orchestrator: 多模式调度。比官方的回旋镖更精细。Full Stack Developer:开发主力模式。
还有其他的 ue 设计,产品等就不一一介绍了。
这里只介绍了基础用法,BMAD 还有很多扩展包各种模式搭配,篇幅有限,等待各位自行探索。
6.4 上下文压缩
由于此方案使用的免费 Key 上下文只有 250k ,所以我们要使用插件的压缩功能避免超过限制报错。
配置方法:
进入 设置 -> 上下文 -> 滚动最下面
打开 自动触发智能上下文压缩 配置,并且调整 22%左右的压缩。
为什么是 22%,因为我们接入 GPT-Load 时使用的是官方 Google Gemini 提供商,不能自定义上下文大小,默认是官方的 1m 上下文,所以用免费 Key 的 250k 上下文和官方的进行计算,比例是 25%,需要在这个基础上留够一点余地,所以差不多 22%左右合适。
这样当对话上下文达到 220k 左右时,AI 就会自动总结当前会话重点,然后进行压缩。避免上下文超限。
6.5 MCP
MCP 能让你通过 AI 实现非常多的功能:联网搜索,查询数据,文件处理等。现在 MCP 的生态非常完善,有非常多的工具可以完成你的工作。
Roo Code 现在版本的 MCP 已经很好用了,不像之前还要在文件里面配置。直接在顶部菜单进入就有 MCP 市场,直接搜索安装即可。
MCP 不太好推荐,我个人的工作流和项目场景使用的 MCP 工具并不一定适合你。
由于开发和运维相关工作,所以我的 MCP 大概有这几个:
- docker
- postgres
- sqlite
- time
- github
- filesystem
- context7
各位还是需要根据自己的项目和场景自行选择,大家可以去这个 MCP Awesome 仓库寻找。
七、最佳实践
这是我的 AI 编程实践,可以参考一下。也许会对你有所帮助或启发。
7.1 提高精准度
AI 编程高效的核心是要精准的输出并完成任务。如果 AI 反复修改,乱改功能,肯定无法高效。
大模型能力、AI 插件工具等能提高 AI 编程的下限,但是真正决定 AI 编程上限的还得是你!
我比较关注这几个指标:
- 业务熟悉度
- 架构能力
- 编码能力
这几个能力越强,那么 AI 编程也能更高效,更精准。
各种营销号、卖课佬经常洗脑:"小白也能一句话让 AI 完成 xxx 项目"。
"一句话编程"能完成一些独立小应用,脚本。但是更多场景是在现有、复杂的项目中编程。你信不信你"一句话编程"能把你 token 跑完了 AI 还在反复循环。 :sweat_smile:
无论用不用 AI 辅助,写代码的永远是你,而不是 AI 。如果写出来的代码自己都不理解不能把控,真敢用吗。
上面提到的能力指标是前提,在这基础上还需要一些规范来具体的提高指令的精准度:
指令精准:
这个是最重要的,和 AI 沟通必须要提供尽可能的上下文,把相关的文件代码都 @给他,并且能直接告诉他代码之间的逻辑最好。并且要非常明确你要做什么。举例:
错误:
txt
给我写一个登录认证。正确:
txt
@models/user.go 用户表
@/web/login.vue 前端登录组件
@http://www.test.com/api-docs.html 接口文档
我需要你基于用户表结构,帮我完成登录认证的功能。要求:
- 用户表的 status 为 false 时无法登录
- 后端使用 jwt 组件
- 前端使用 axios 组件
- 规范登录异常错误码
如果有不确定的地方请和我沟通确认,如果引入新的字段或者依赖也需要和我确认。甚至你不用在意描述是否通顺,是否口水话,是否错别字。你要相信 AI 的理解能力,只需要尽可能提供足够明确精准的指令。
任务拆解: 不要让 AI 一次性完成太庞大复杂的任务,尽可能的拆解为粒度小、独立的任务。
模型搭配: 虽然这个方案中你用 gemini-2.5-pro 一把梭也不是不可以。
但是如果你接入了其他多个渠道资源,那么我建议你还是不通的模型或者场景使用不同的模型,快慢轻重分离。需要识图的就用多模态模型。需要调用工具就用 claude 和 gemini 这种工具能力强的模型。你需要熟悉你使用模型的能力。
版本控制: 一定要经常保存代码,git 版本记录。不愿看到"AI 把我代码全删了"的帖子。
编码文档: 每一个功能或者模块,都需要让 AI 帮你分析并记录编码文档,后续针对这个功能的调整修改也需要同步修改文档。
我的一些项目中,编码文档都有几十上百个。这样的好处是随时可以排查或者追溯功能。
你可以不看,但是要在开发时把相关的所有文档提供给 AI ,这能很大的提高精准度。
代码审查: 每次完成编码任务时,都需要让 AI 帮你审查一次。
并且也需要你亲自审查这次任务的所有代码细节。不能失去代码的掌控!
7.2 核心工作流
我的这套工作流程是根据 Roo Code 编程的经验,不断优化调整之后的。不过你要根据实际的任务大小,灵活的选用。仅做参考,不要生搬硬套。
-
确认需求:架构师模式,和 AI 沟通、梳理自己的想法,不断的完善所有的细节,直到最终确认。然后一定要让 AI 根据确认后的内容形成文档。
-
拆分需求:架构师模式,如果需求复杂,那就需要拆解任务。同样和 AI 沟通,让他把这个方案拆分成尽量小的独立的阶段,并让 AI 写阶段拆分文档。(如果拆分多个阶段,那么从下一步开始就要循环来完成每个阶段的任务。)
-
编码:code 模式,实施具体的编码任务。
-
审查 :qa (或者 debug )模式,让 AI 审查本次修改,给出优化修改建议。我常用的审查提示词:
txt请全面细致的检查这次改动。 - 是否完整实现需求? - 代码规范检查 - Bug 分析 - 是否有可优化的性能瓶颈? - 是否存在 SQL 注入、密码明文等安全漏洞? - 是否兼容多数据库驱动:mysql,sqlite,pg (根据实际业务影响范围进行调整) -
自审:这一步需要你自己来完成。需要读取 AI 的所有代码,并且根据 AI 上一步给出的优化建议进行评估是否要继续修改调整。自己调整或者切 code 模式继续进行编码、审查循环。
-
深度分析:(可选)如果 AI 写了一个复杂核心的功能,还可以切换到 qa 模式,让他给你细致的讲解所有的细节。在你理解逻辑的过程,AI 也会分析细节找出问题。
7.3 常见编码场景
基于以上工作流程,灵活运用到以下流程,举例:
- 小任务且独立的单元脚本,直接 code 模式,"一句话编程",写完也要记得审查自审。
- 大型任务,和基于复杂的业务迭代,建议使用上述完整的流程。
- 修复 bug ,可以使用 qa 模式,灵活运用
@problems指令。 - 代码重构,先 qa 模式分析现有项目相关逻辑,在架构模式根据需求设计重构方案,之后就进行正常编码审查流程。
- 业务文档,使用 qa 或者
Business Analyst模式真的相关业务分析,并且根据需求梳理文档。
八、常见问题
8.1 工具调用失败

可以输入 "请使用正确的格式调用工具" 来让 AI 正常调用并继续对话。
九、总结
希望能授人以渔,给大家一些 AI 编程的灵感,设计自己的开发流程,并灵活运用。
让不稳定的 AI 工具尽量精准高质量的编程。
记住,写代码的永远是你,你才能决定项目的上限!
古法码字,难免错误,感谢大家指正。