精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、开发环境
- 三、视频展示
- 四、项目展示
- 五、代码展示
- 六、项目文档展示
- 七、总结
-
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻)
一、项目介绍
选题背景
随着现代社会生活节奏的加快和竞争压力的增大,心理压力问题已成为影响公众健康的重要因素。根据世界卫生组织发布的《全球心理健康状况报告》显示,全球约有27%的成年人经历过不同程度的心理压力困扰,而美国心理学会的年度压力调查数据表明,超过60%的受访者表示工作和生活压力对其身心健康造成了显著影响。国内相关研究机构的调研结果显示,我国城市居民中有接近40%的人群处于中高等压力状态,压力相关的心理疾病发病率呈现逐年上升趋势。传统的压力评估方法主要依赖心理量表测试和专业医生诊断,存在评估周期长、主观性强、难以实现连续监测等局限性。伴随着可穿戴设备技术的快速发展和智能手机的广泛普及,人们的生理指标、行为模式、社交活动等数据得以大量采集和记录,这些数据蕴含着丰富的压力状态信息。同时,大数据处理技术特别是Apache Spark分布式计算框架的日趋成熟,为处理和分析海量多维度压力相关数据提供了强有力的技术支撑,使得构建智能化、自动化的压力检测分析系统成为现实可能。
选题意义
本系统的建设具有重要的理论价值和广泛的实际应用意义。从技术创新层面来看,该系统将Hadoop分布式存储架构与Spark大数据处理引擎相结合,探索了大数据技术在心理健康数据分析领域的深度应用,为相关技术的跨领域融合提供了宝贵的实践经验和技术参考。从健康管理角度分析,系统通过整合个体的生理指标、行为模式、人格特质等多维度数据,能够建立起科学的压力状态量化评估模型,这对于早期识别和筛查高压力风险人群具有重要价值,可以帮助医疗机构和健康管理部门更及时地发现潜在的心理健康问题。从社会效益角度考虑,该系统的推广应用能够降低传统压力评估的人力成本和时间成本,提高压力检测的效率和准确性,为构建覆盖面更广的心理健康监测网络奠定技术基础。对于个人用户而言,系统提供的个性化压力分析报告和健康建议,能够帮助用户更好地了解自身的压力状况和影响因素,从而采取针对性的调节措施,改善生活质量和心理健康水平。
二、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
三、视频展示
计算机毕设选题推荐-基于大数据的压力检测数据分析系统【Hadoop、Spark、python】
四、项目展示
登录模块:

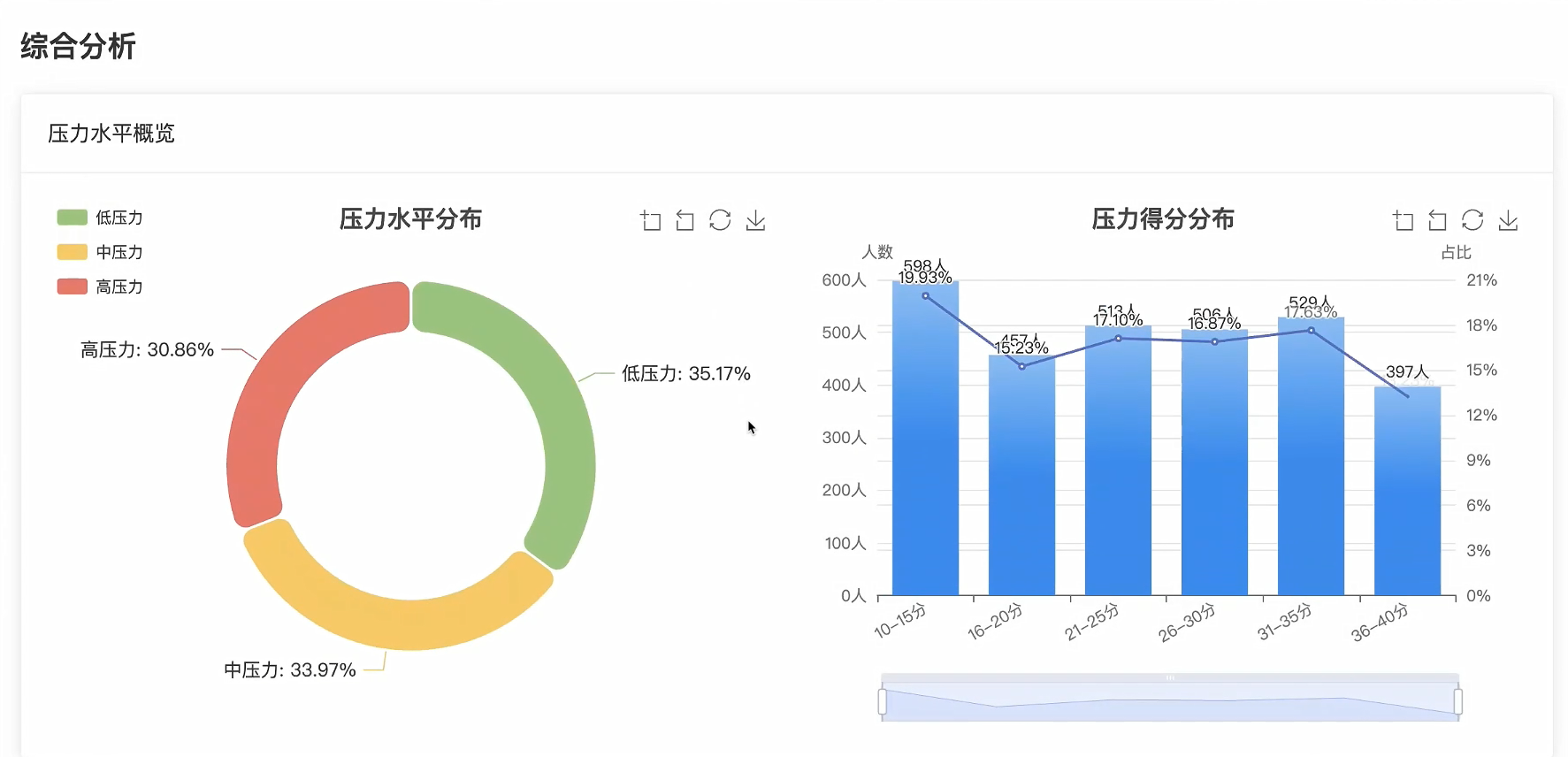
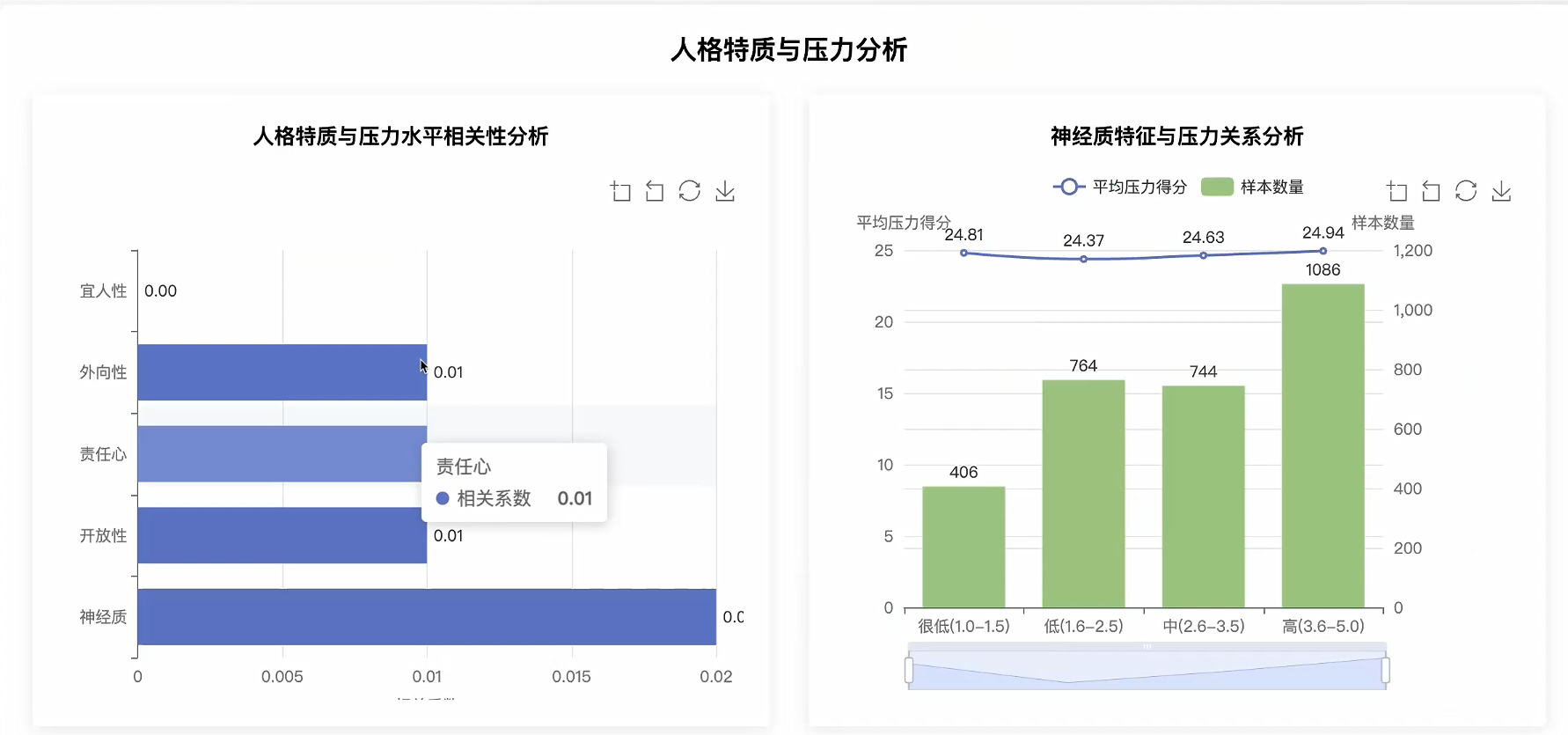
可视化分析模块:
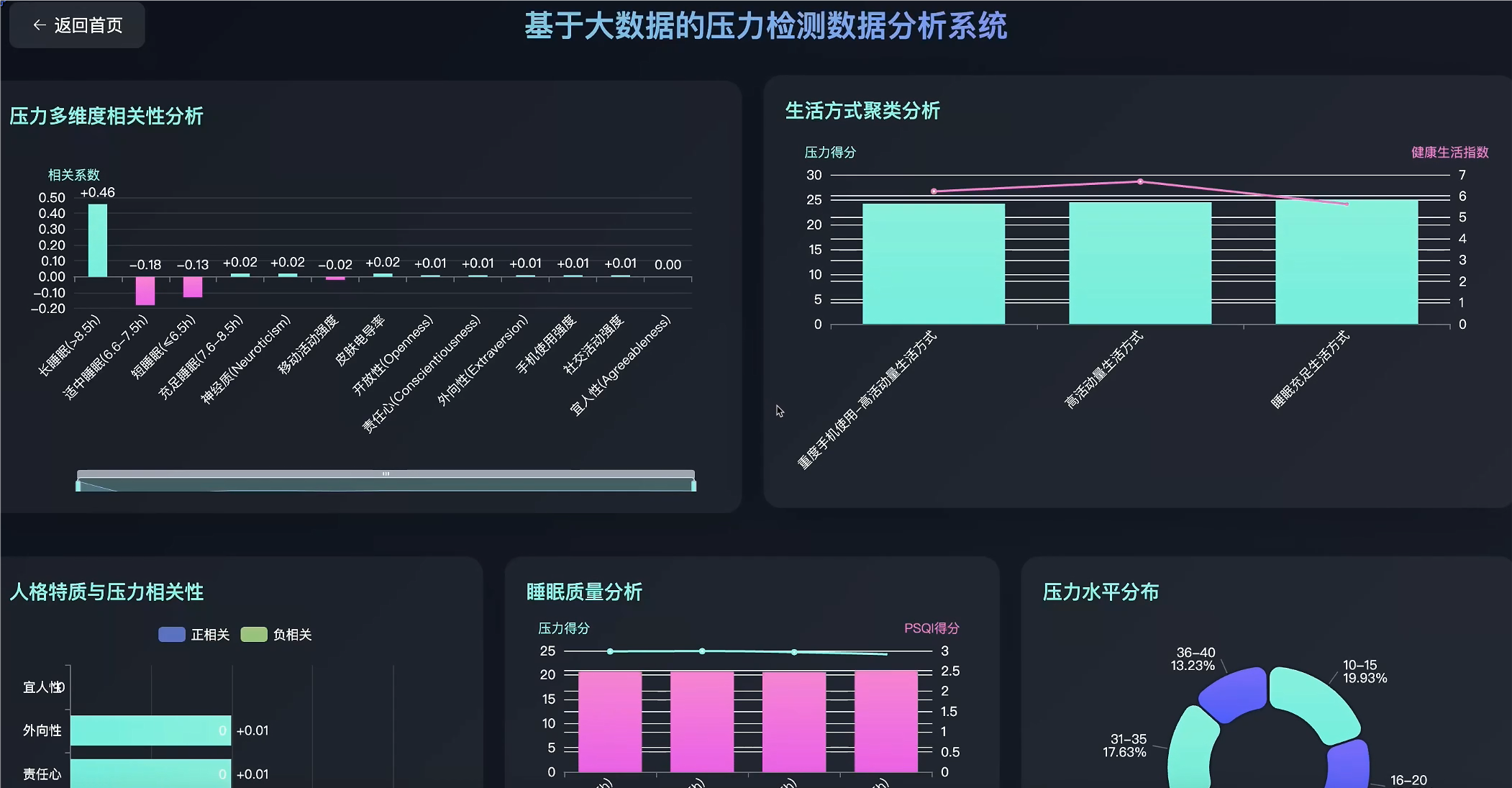
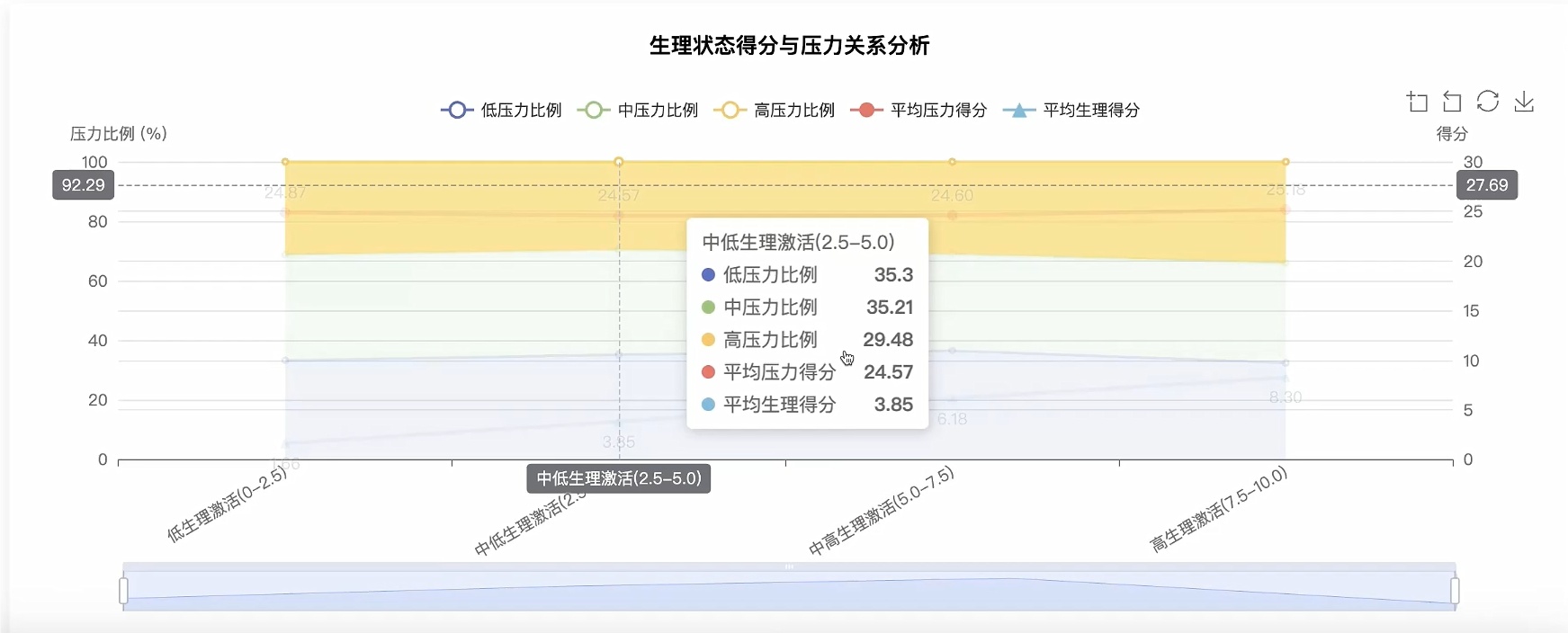
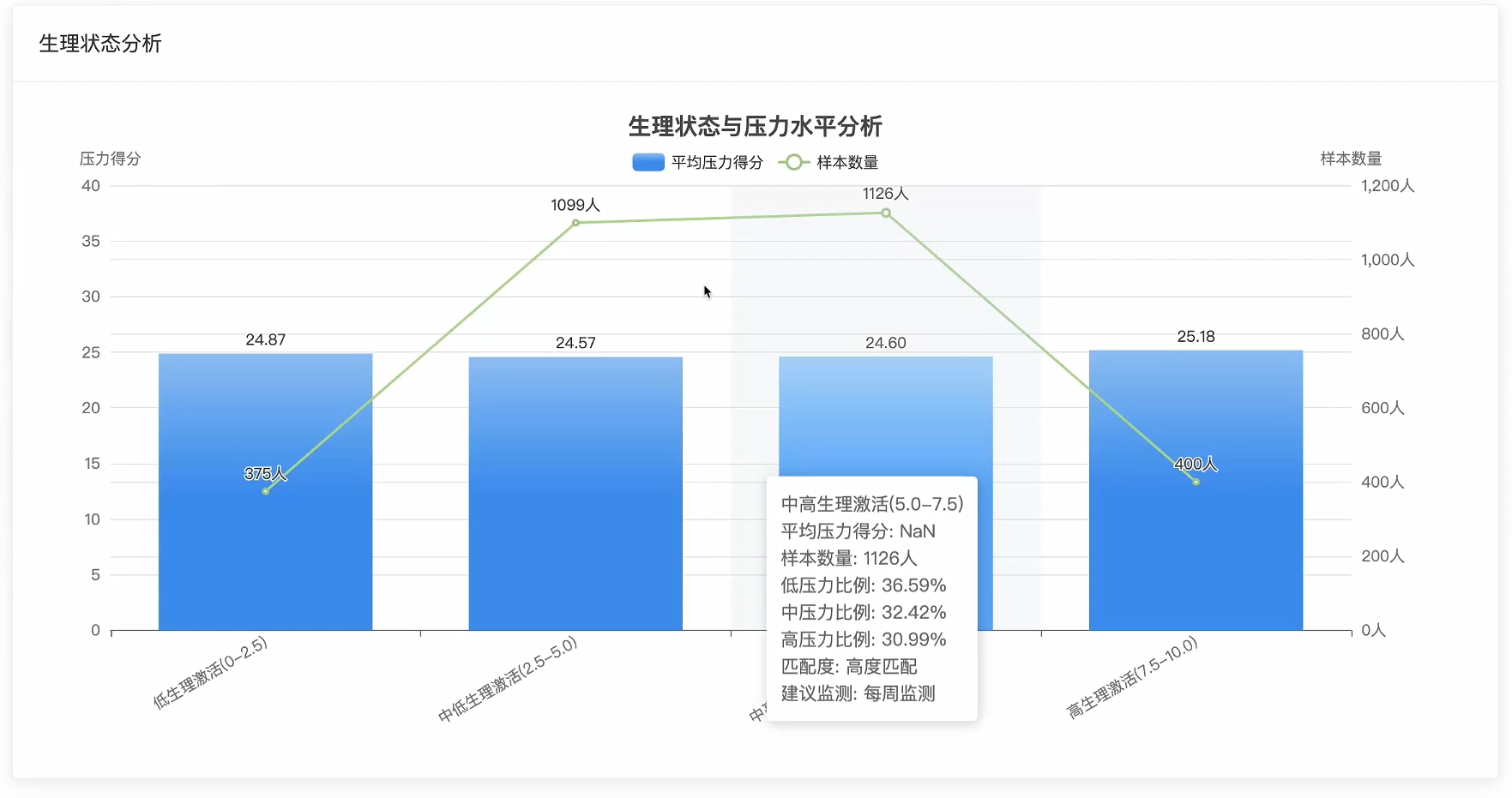
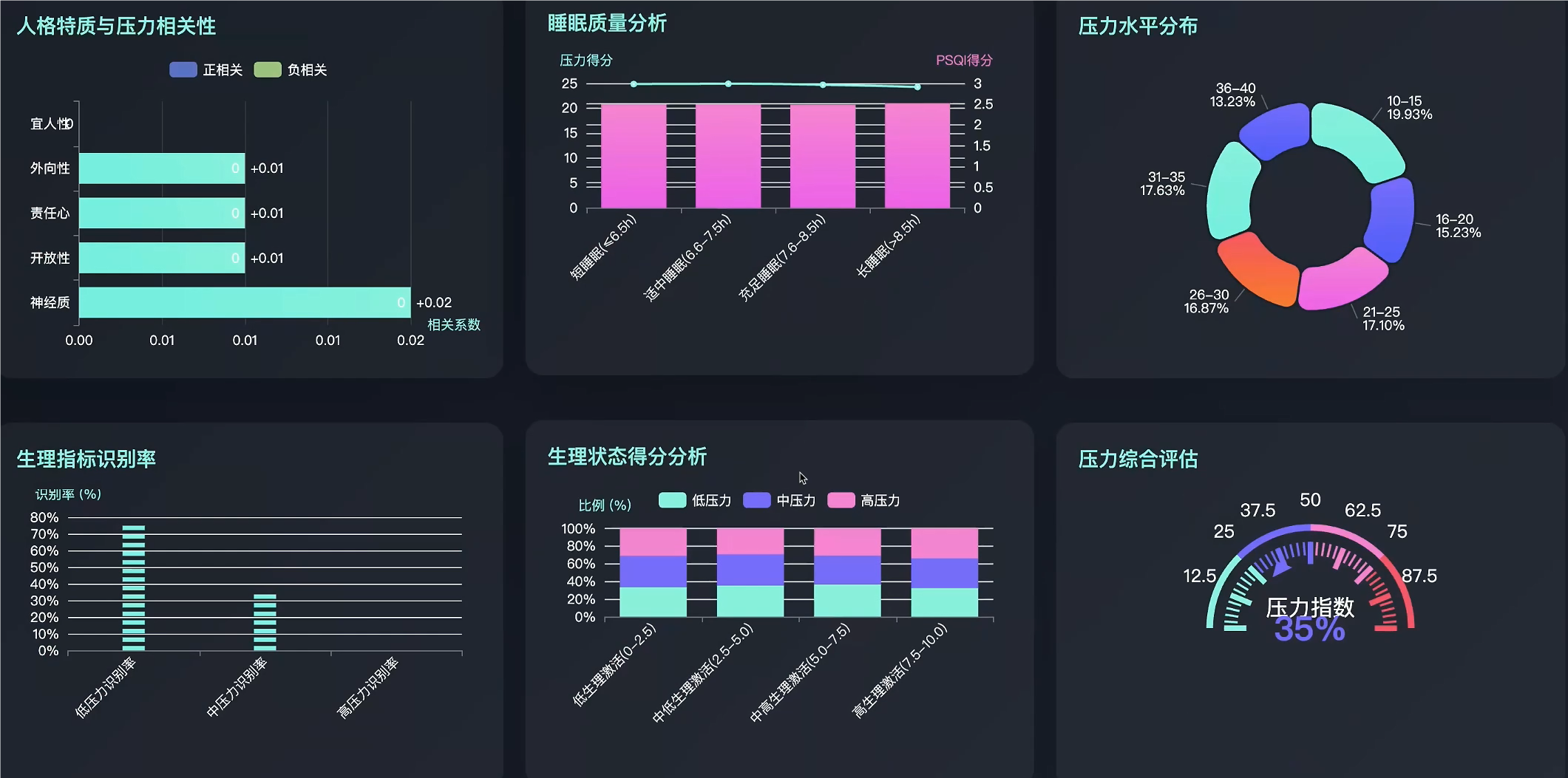
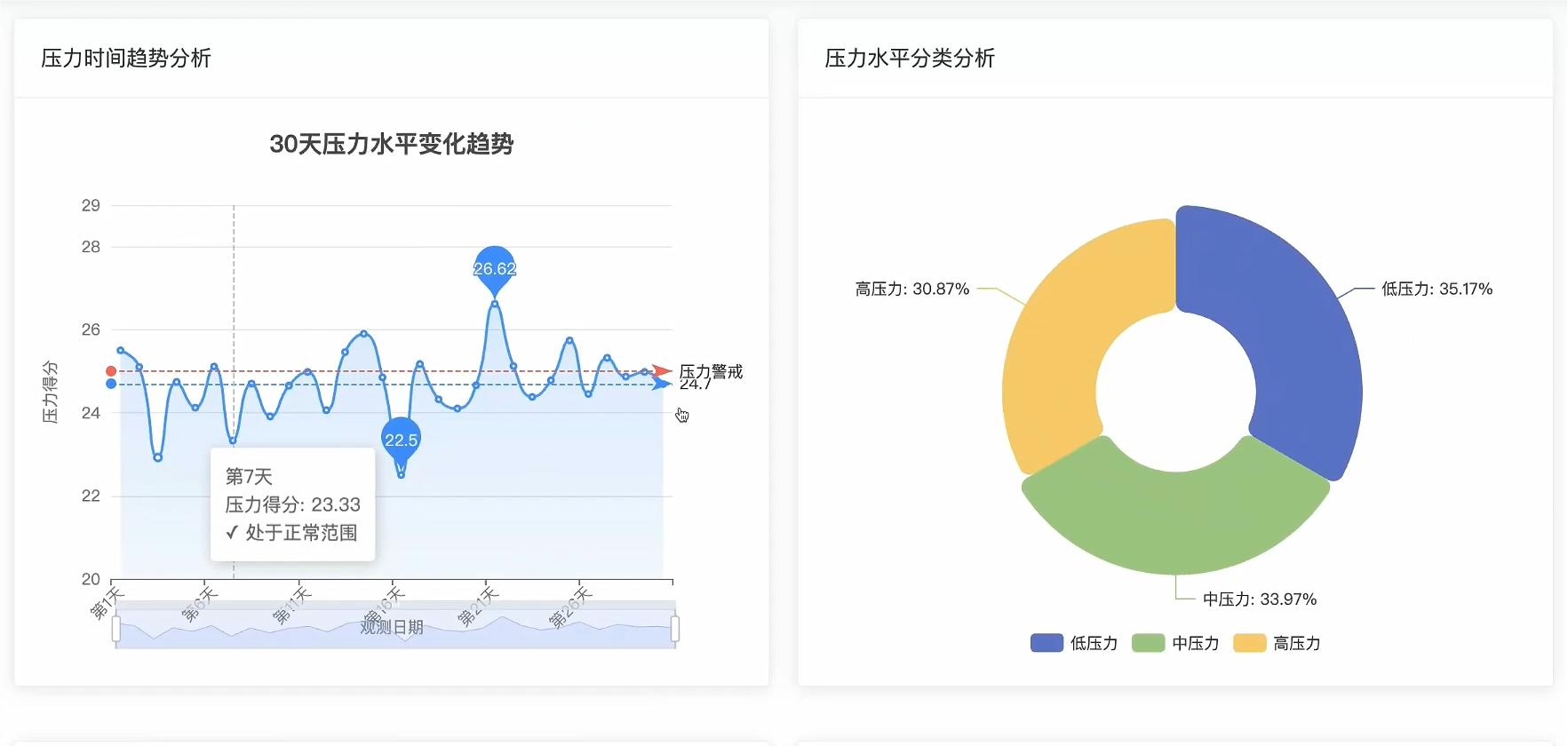
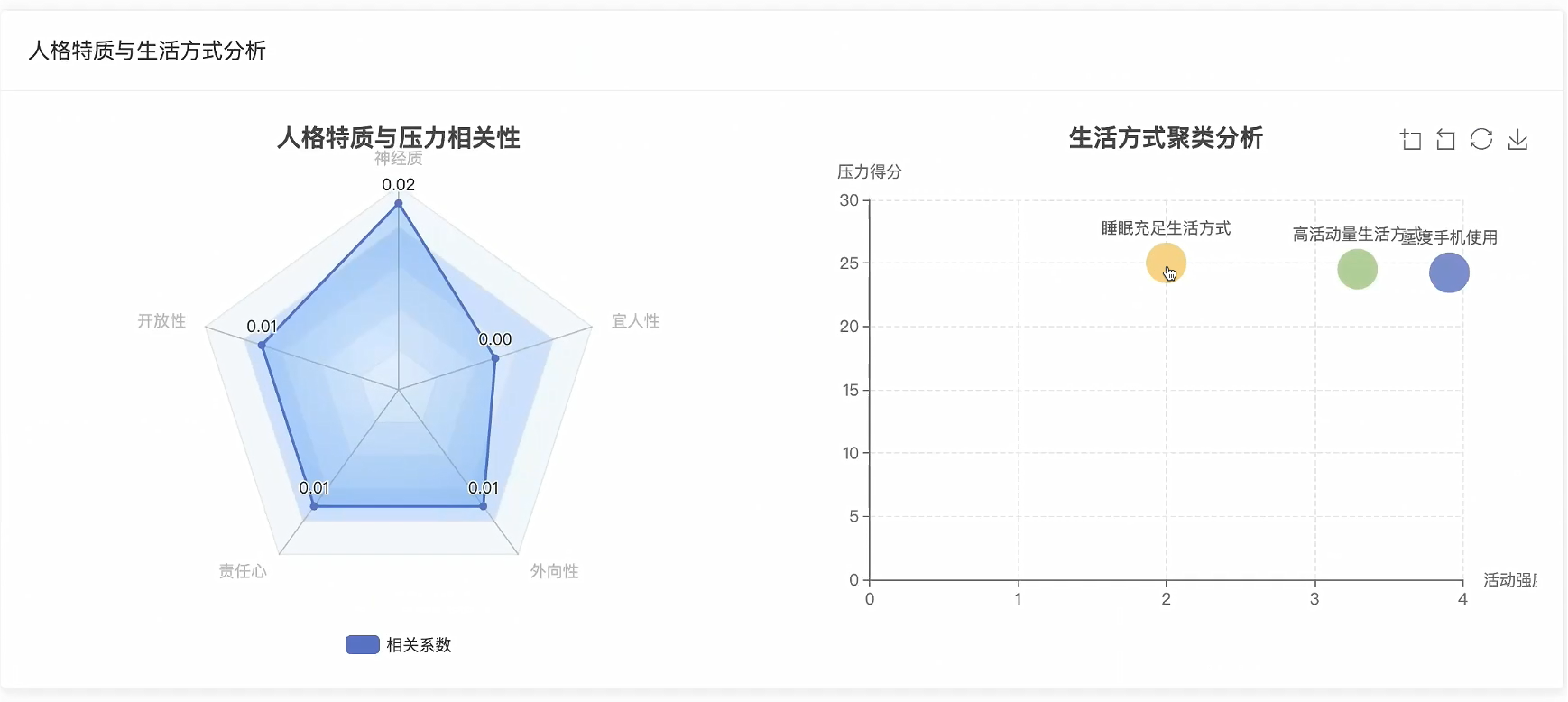
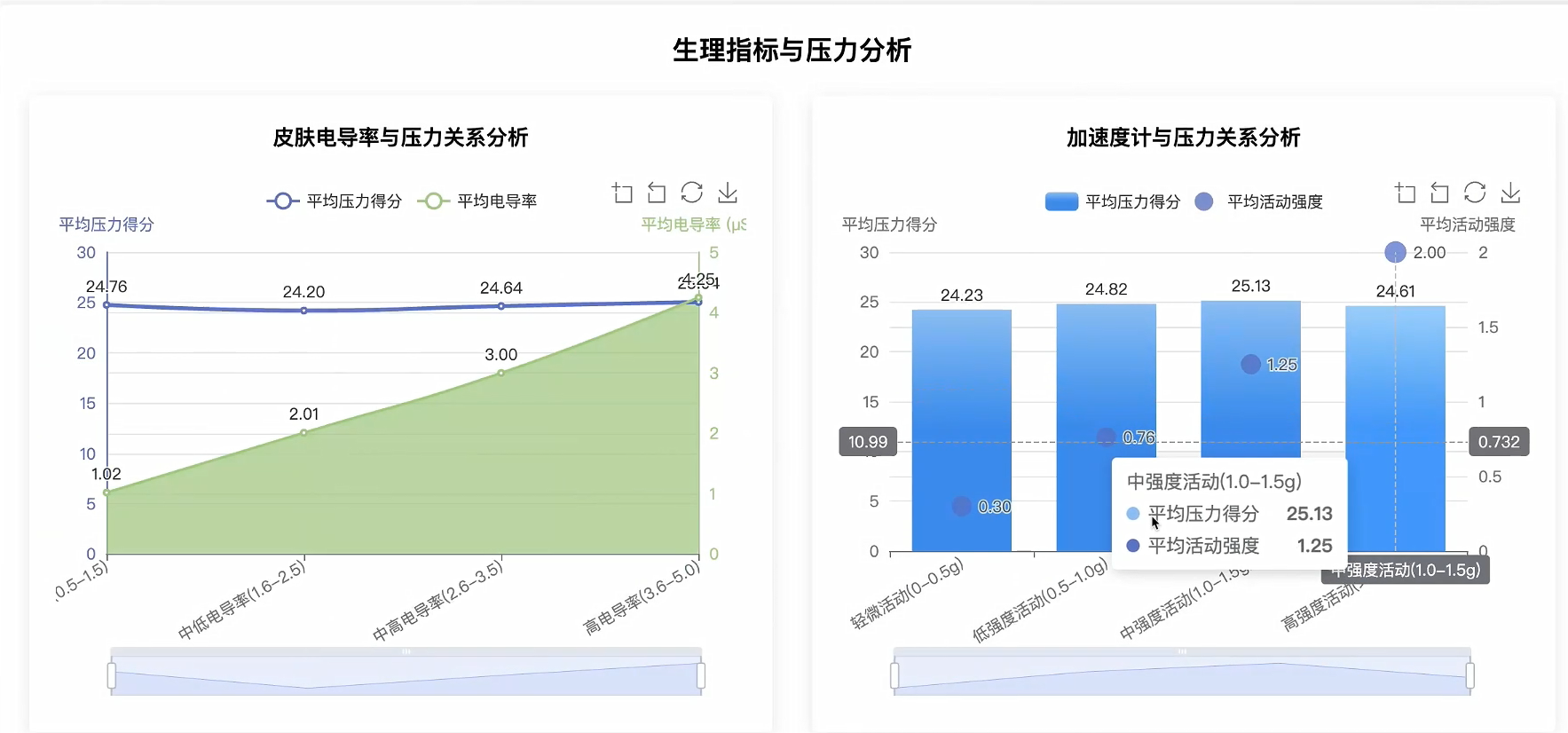
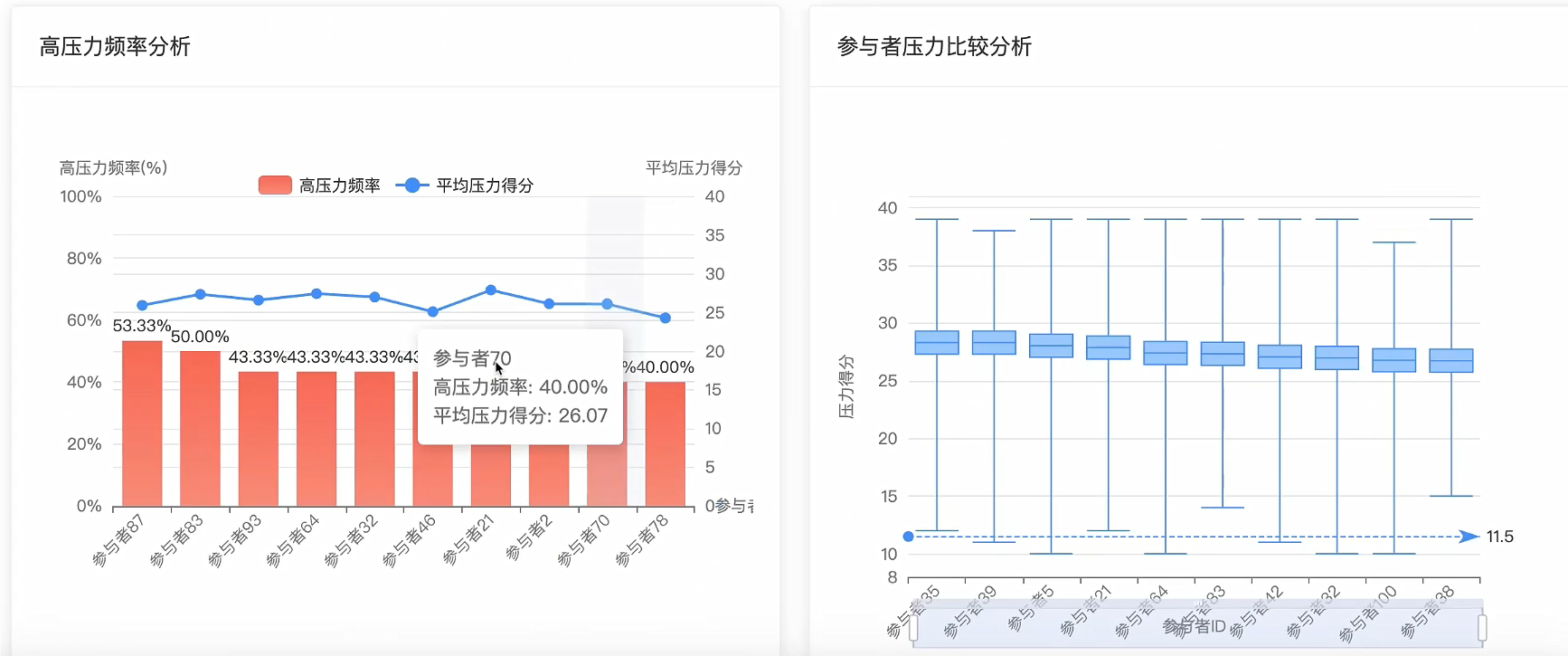
五、代码展示
bash
# 核心功能一:压力水平分布与变化特征分析
def analyze_pressure_distribution_and_trends(request):
try:
# 获取所有压力检测数据
pressure_data = spark.sql("""
SELECT participant_id, day, PSS_score,
ROW_NUMBER() OVER(PARTITION BY participant_id ORDER BY day) as day_seq
FROM stress_detection
WHERE PSS_score IS NOT NULL
""").collect()
# 计算压力水平分类统计
pressure_levels = {'低压力(10-20)': 0, '中压力(21-30)': 0, '高压力(31-40)': 0}
daily_pressure_trends = {}
participant_pressure_stats = {}
for record in pressure_data:
pss_score = record.PSS_score
participant_id = record.participant_id
day = record.day
# 压力水平分类
if 10 <= pss_score <= 20:
pressure_levels['低压力(10-20)'] += 1
elif 21 <= pss_score <= 30:
pressure_levels['中压力(21-30)'] += 1
elif 31 <= pss_score <= 40:
pressure_levels['高压力(31-40)'] += 1
# 时间趋势统计
if day not in daily_pressure_trends:
daily_pressure_trends[day] = []
daily_pressure_trends[day].append(pss_score)
# 个体压力统计
if participant_id not in participant_pressure_stats:
participant_pressure_stats[participant_id] = {'scores': [], 'high_pressure_days': 0}
participant_pressure_stats[participant_id]['scores'].append(pss_score)
if pss_score > 30:
participant_pressure_stats[participant_id]['high_pressure_days'] += 1
# 计算30天内平均压力变化趋势
trend_analysis = {}
for day, scores in daily_pressure_trends.items():
avg_pressure = sum(scores) / len(scores)
trend_analysis[day] = {
'average_pressure': round(avg_pressure, 2),
'participant_count': len(scores),
'pressure_variance': round(sum([(score - avg_pressure) ** 2 for score in scores]) / len(scores), 2)
}
# 识别持续高压力人群
high_risk_participants = []
for participant_id, stats in participant_pressure_stats.items():
avg_pressure = sum(stats['scores']) / len(stats['scores'])
high_pressure_ratio = stats['high_pressure_days'] / len(stats['scores'])
if high_pressure_ratio > 0.5: # 超过50%的天数为高压力
high_risk_participants.append({
'participant_id': participant_id,
'average_pressure': round(avg_pressure, 2),
'high_pressure_days': stats['high_pressure_days'],
'total_days': len(stats['scores']),
'risk_level': '高风险' if high_pressure_ratio > 0.7 else '中风险'
})
# 计算压力水平分布百分比
total_records = sum(pressure_levels.values())
pressure_distribution = {
level: {'count': count, 'percentage': round((count / total_records) * 100, 2)}
for level, count in pressure_levels.items()
}
analysis_result = {
'pressure_distribution': pressure_distribution,
'daily_trends': trend_analysis,
'high_risk_participants': high_risk_participants,
'total_participants': len(participant_pressure_stats),
'analysis_period': f"{min(daily_pressure_trends.keys())}-{max(daily_pressure_trends.keys())}"
}
return JsonResponse({
'status': 'success',
'data': analysis_result,
'message': '压力水平分布与变化特征分析完成'
})
except Exception as e:
return JsonResponse({'status': 'error', 'message': str(e)})
# 核心功能二:人格特质与压力关系分析
def analyze_personality_pressure_correlation(request):
try:
# 使用Spark SQL获取人格特质和压力数据
personality_pressure_data = spark.sql("""
SELECT participant_id, PSS_score, Openness, Conscientiousness,
Extraversion, Agreeableness, Neuroticism
FROM stress_detection
WHERE PSS_score IS NOT NULL AND Openness IS NOT NULL
""").collect()
# 数据预处理和相关性计算准备
pressure_scores = []
openness_scores = []
conscientiousness_scores = []
extraversion_scores = []
agreeableness_scores = []
neuroticism_scores = []
participant_personality_profiles = {}
for record in personality_pressure_data:
pressure_scores.append(record.PSS_score)
openness_scores.append(record.Openness)
conscientiousness_scores.append(record.Conscientiousness)
extraversion_scores.append(record.Extraversion)
agreeableness_scores.append(record.Agreeableness)
neuroticism_scores.append(record.Neuroticism)
# 构建个体人格档案
participant_id = record.participant_id
if participant_id not in participant_personality_profiles:
participant_personality_profiles[participant_id] = {
'pressure_records': [], 'personality_traits': {}
}
participant_personality_profiles[participant_id]['pressure_records'].append(record.PSS_score)
participant_personality_profiles[participant_id]['personality_traits'] = {
'openness': record.Openness,
'conscientiousness': record.Conscientiousness,
'extraversion': record.Extraversion,
'agreeableness': record.Agreeableness,
'neuroticism': record.Neuroticism
}
# 计算皮尔逊相关系数
def calculate_correlation(x_values, y_values):
n = len(x_values)
sum_x = sum(x_values)
sum_y = sum(y_values)
sum_xy = sum(x * y for x, y in zip(x_values, y_values))
sum_x2 = sum(x * x for x in x_values)
sum_y2 = sum(y * y for y in y_values)
numerator = n * sum_xy - sum_x * sum_y
denominator = ((n * sum_x2 - sum_x ** 2) * (n * sum_y2 - sum_y ** 2)) ** 0.5
return numerator / denominator if denominator != 0 else 0
# 计算各人格特质与压力的相关性
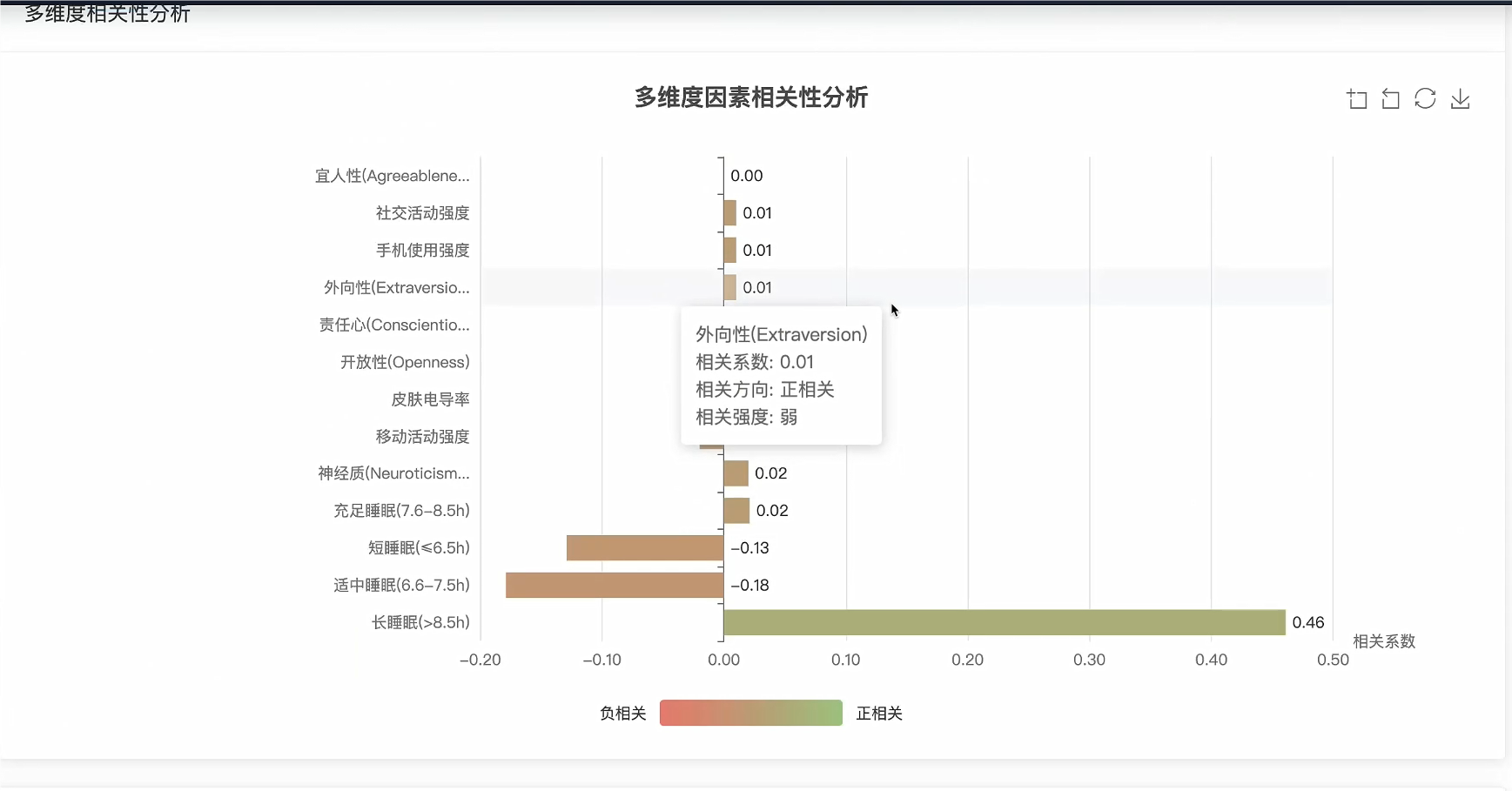
correlations = {
'openness': calculate_correlation(openness_scores, pressure_scores),
'conscientiousness': calculate_correlation(conscientiousness_scores, pressure_scores),
'extraversion': calculate_correlation(extraversion_scores, pressure_scores),
'agreeableness': calculate_correlation(agreeableness_scores, pressure_scores),
'neuroticism': calculate_correlation(neuroticism_scores, pressure_scores)
}
# 分析神经质与压力的具体关系
neuroticism_pressure_analysis = {}
neuroticism_groups = {'低神经质(1-3)': [], '中神经质(4-6)': [], '高神经质(7-9)': []}
for neuro_score, pressure_score in zip(neuroticism_scores, pressure_scores):
if 1 <= neuro_score <= 3:
neuroticism_groups['低神经质(1-3)'].append(pressure_score)
elif 4 <= neuro_score <= 6:
neuroticism_groups['中神经质(4-6)'].append(pressure_score)
elif 7 <= neuro_score <= 9:
neuroticism_groups['高神经质(7-9)'].append(pressure_score)
for group, pressure_list in neuroticism_groups.items():
if pressure_list:
avg_pressure = sum(pressure_list) / len(pressure_list)
neuroticism_pressure_analysis[group] = {
'average_pressure': round(avg_pressure, 2),
'sample_count': len(pressure_list),
'high_pressure_rate': round(len([p for p in pressure_list if p > 30]) / len(pressure_list) * 100, 2)
}
# 识别高风险人格类型
high_risk_personalities = []
for participant_id, profile in participant_personality_profiles.items():
avg_pressure = sum(profile['pressure_records']) / len(profile['pressure_records'])
traits = profile['personality_traits']
# 基于研究发现的高风险人格特征组合
if traits['neuroticism'] > 6 and traits['extraversion'] < 4:
risk_score = (traits['neuroticism'] * 0.4 + (10 - traits['extraversion']) * 0.3 +
(10 - traits['conscientiousness']) * 0.2 + avg_pressure * 0.1)
high_risk_personalities.append({
'participant_id': participant_id,
'risk_score': round(risk_score, 2),
'average_pressure': round(avg_pressure, 2),
'dominant_traits': f"高神经质({traits['neuroticism']}), 低外向性({traits['extraversion']})"
})
# 排序高风险人格
high_risk_personalities.sort(key=lambda x: x['risk_score'], reverse=True)
correlation_analysis_result = {
'personality_pressure_correlations': {
trait: round(corr, 3) for trait, corr in correlations.items()
},
'neuroticism_analysis': neuroticism_pressure_analysis,
'high_risk_personalities': high_risk_personalities[:10], # 取前10名高风险
'strongest_correlation': max(correlations.items(), key=lambda x: abs(x[1])),
'sample_size': len(pressure_scores)
}
return JsonResponse({
'status': 'success',
'data': correlation_analysis_result,
'message': '人格特质与压力关系分析完成'
})
except Exception as e:
return JsonResponse({'status': 'error', 'message': str(e)})
# 核心功能三:生活行为模式与压力关系分析
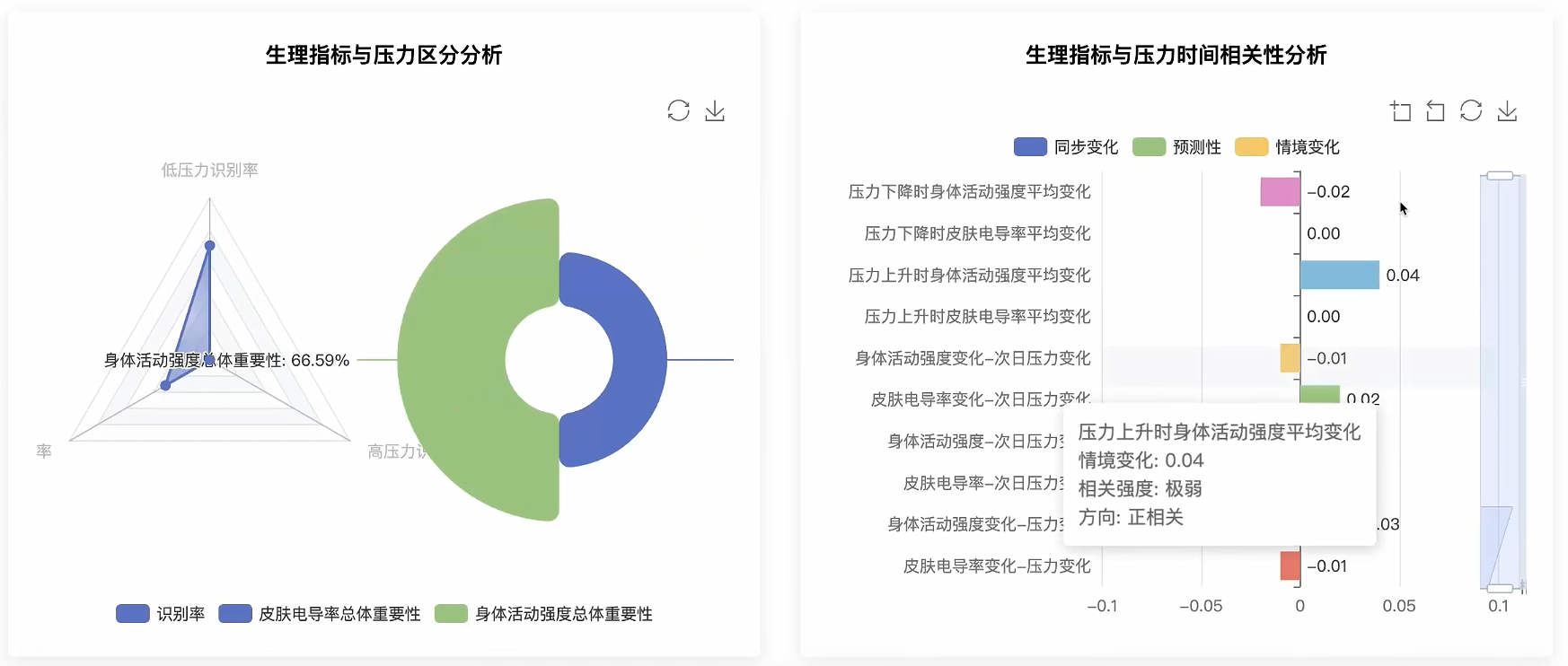
def analyze_lifestyle_pressure_relationship(request):
try:
# 使用Spark SQL获取生活行为和压力数据
lifestyle_data = spark.sql("""
SELECT participant_id, day, PSS_score, sleep_duration, PSQI_score,
sleep_time, wake_time, screen_on_time, num_calls, num_sms,
call_duration, mobility_radius, mobility_distance, skin_conductance, accelerometer
FROM stress_detection
WHERE PSS_score IS NOT NULL AND sleep_duration IS NOT NULL
""").collect()
# 数据分组和统计分析
sleep_quality_groups = {'优质睡眠': [], '一般睡眠': [], '差质睡眠': []}
digital_behavior_analysis = {'低使用': [], '中使用': [], '高使用': []}
mobility_pressure_data = {'低活动': [], '中活动': [], '高活动': []}
participant_behavior_profiles = {}
for record in lifestyle_data:
participant_id = record.participant_id
pss_score = record.PSS_score
sleep_duration = record.sleep_duration if record.sleep_duration else 0
psqi_score = record.PSQI_score if record.PSQI_score else 0
screen_time = record.screen_on_time if record.screen_on_time else 0
mobility_distance = record.mobility_distance if record.mobility_distance else 0
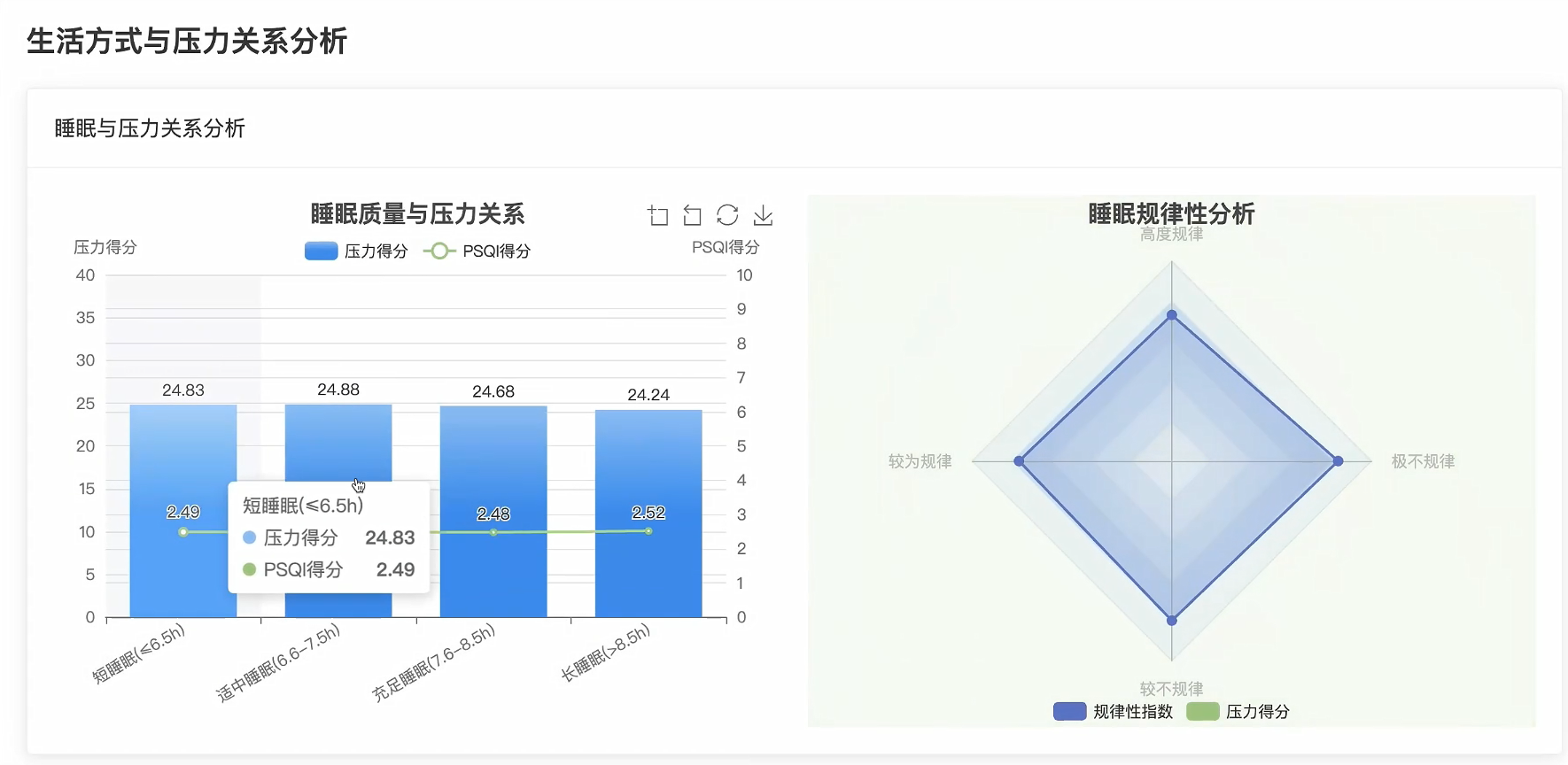
# 睡眠质量分组分析
if sleep_duration >= 7 and psqi_score <= 5:
sleep_quality_groups['优质睡眠'].append(pss_score)
elif sleep_duration >= 6 and psqi_score <= 10:
sleep_quality_groups['一般睡眠'].append(pss_score)
else:
sleep_quality_groups['差质睡眠'].append(pss_score)
# 数字设备使用行为分组
if screen_time <= 4:
digital_behavior_analysis['低使用'].append(pss_score)
elif screen_time <= 8:
digital_behavior_analysis['中使用'].append(pss_score)
else:
digital_behavior_analysis['高使用'].append(pss_score)
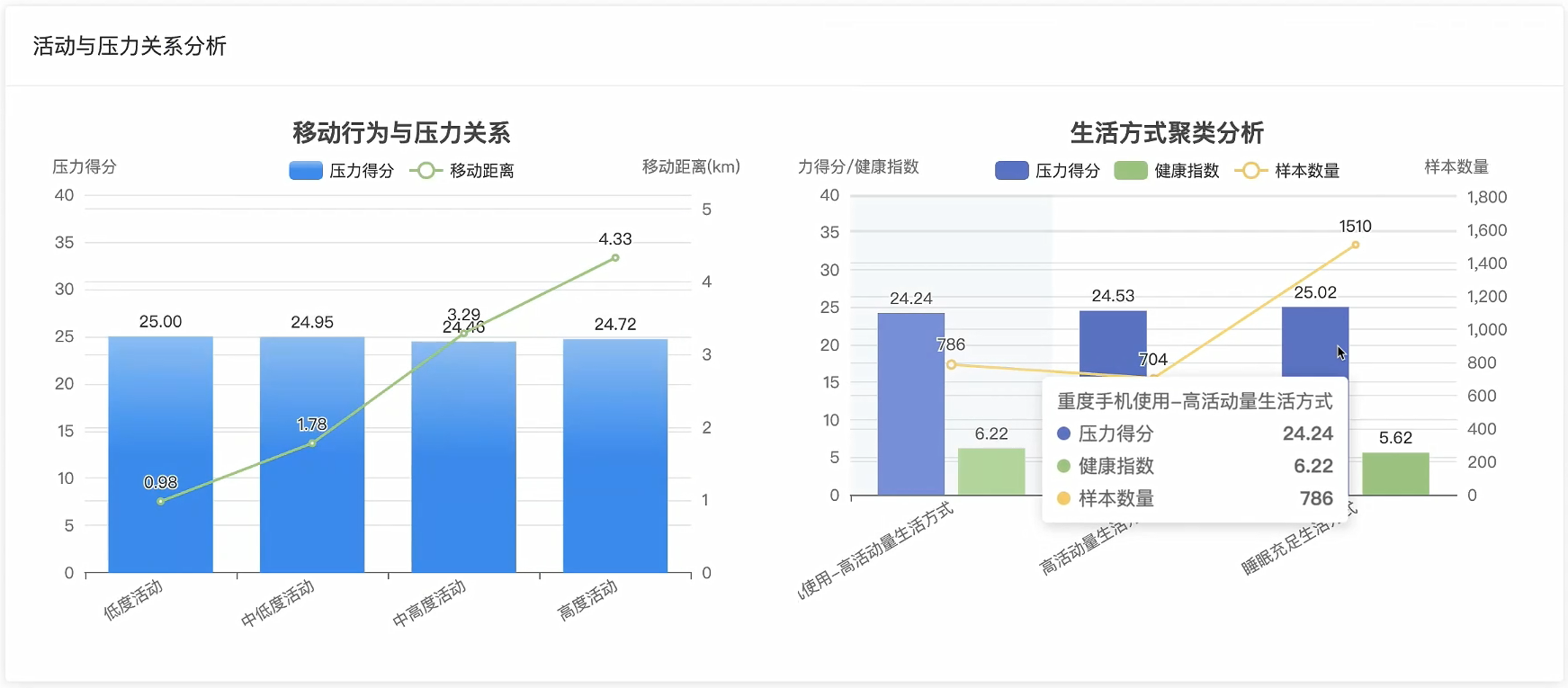
# 移动活动分组
if mobility_distance <= 2:
mobility_pressure_data['低活动'].append(pss_score)
elif mobility_distance <= 5:
mobility_pressure_data['中活动'].append(pss_score)
else:
mobility_pressure_data['高活动'].append(pss_score)
# 构建个体行为档案
if participant_id not in participant_behavior_profiles:
participant_behavior_profiles[participant_id] = {
'sleep_records': [], 'digital_usage': [], 'mobility_levels': [], 'pressure_records': []
}
participant_behavior_profiles[participant_id]['sleep_records'].append({
'duration': sleep_duration, 'quality': psqi_score
})
participant_behavior_profiles[participant_id]['digital_usage'].append(screen_time)
participant_behavior_profiles[participant_id]['mobility_levels'].append(mobility_distance)
participant_behavior_profiles[participant_id]['pressure_records'].append(pss_score)
# 睡眠质量与压力关系统计
sleep_pressure_analysis = {}
for quality_level, pressure_scores in sleep_quality_groups.items():
if pressure_scores:
avg_pressure = sum(pressure_scores) / len(pressure_scores)
high_pressure_count = len([p for p in pressure_scores if p > 30])
sleep_pressure_analysis[quality_level] = {
'average_pressure': round(avg_pressure, 2),
'sample_count': len(pressure_scores),
'high_pressure_rate': round((high_pressure_count / len(pressure_scores)) * 100, 2),
'pressure_std': round((sum([(p - avg_pressure) ** 2 for p in pressure_scores]) / len(pressure_scores)) ** 0.5, 2)
}
# 数字行为与压力关系分析
digital_pressure_analysis = {}
for usage_level, pressure_scores in digital_behavior_analysis.items():
if pressure_scores:
avg_pressure = sum(pressure_scores) / len(pressure_scores)
digital_pressure_analysis[usage_level] = {
'average_pressure': round(avg_pressure, 2),
'sample_count': len(pressure_scores),
'pressure_range': f"{min(pressure_scores)}-{max(pressure_scores)}"
}
# K-means聚类分析行为模式(简化版实现)
behavior_patterns = []
for participant_id, profile in participant_behavior_profiles.items():
if len(profile['pressure_records']) > 0:
avg_sleep_duration = sum([r['duration'] for r in profile['sleep_records']]) / len(profile['sleep_records'])
avg_screen_time = sum(profile['digital_usage']) / len(profile['digital_usage'])
avg_mobility = sum(profile['mobility_levels']) / len(profile['mobility_levels'])
avg_pressure = sum(profile['pressure_records']) / len(profile['pressure_records'])
# 基于行为特征进行简单分类
if avg_sleep_duration >= 7 and avg_screen_time <= 6 and avg_mobility >= 3:
pattern_type = '健康活跃型'
elif avg_sleep_duration < 6 and avg_screen_time > 8:
pattern_type = '数字依赖型'
elif avg_mobility < 2 and avg_screen_time > 6:
pattern_type = '静态生活型'
else:
pattern_type = '混合型'
behavior_patterns.append({
'participant_id': participant_id,
'pattern_type': pattern_type,
'avg_pressure': round(avg_pressure, 2),
'sleep_duration': round(avg_sleep_duration, 1),
'screen_time': round(avg_screen_time, 1),
'mobility_level': round(avg_mobility, 1)
})
# 统计各行为模式的压力水平
pattern_pressure_stats = {}
for pattern in behavior_patterns:
pattern_type = pattern['pattern_type']
if pattern_type not in pattern_pressure_stats:
pattern_pressure_stats[pattern_type] = []
pattern_pressure_stats[pattern_type].append(pattern['avg_pressure'])
pattern_analysis_result = {}
for pattern_type, pressure_list in pattern_pressure_stats.items():
avg_pressure = sum(pressure_list) / len(pressure_list)
pattern_analysis_result[pattern_type] = {
'average_pressure': round(avg_pressure, 2),
'participant_count': len(pressure_list),
'pressure_trend': '偏高' if avg_pressure > 25 else '正常'
}
lifestyle_analysis_result = {
'sleep_pressure_relationship': sleep_pressure_analysis,
'digital_behavior_impact': digital_pressure_analysis,
'mobility_pressure_correlation': {
level: {
'avg_pressure': round(sum(scores) / len(scores), 2) if scores else 0,
'sample_count': len(scores)
} for level, scores in mobility_pressure_data.items()
},
'behavior_pattern_analysis': pattern_analysis_result,
'high_risk_behavior_participants': [
p for p in behavior_patterns if p['avg_pressure'] > 30 and p['pattern_type'] in ['数字依赖型', '静态生活型']
]
}
return JsonResponse({
'status': 'success',
'data': lifestyle_analysis_result,
'message': '生活行为模式与压力关系分析完成'
})
except Exception as e:
return JsonResponse({'status': 'error', 'message': str(e)})六、项目文档展示

七、总结
本研究基于现代社会日益严重的心理压力问题,设计并实现了一套基于Spark的压力检测数据分析系统,该系统充分运用了Hadoop分布式存储、Spark大数据处理、Python开发以及Django框架等先进技术,构建了完整的压力数据分析解决方案。系统从压力水平分布与变化特征、人格特质与压力关系、生活行为模式与压力关系、生理指标与压力关系四个核心维度展开深度分析,实现了压力分数统计分析、时间趋势预测、个体差异比较、人格特质相关性分析、睡眠质量影响评估、数字行为模式研究等多项功能模块。通过对PSS压力评分、五大人格特质指标、睡眠数据、移动行为数据、皮肤电导率等多维度数据的综合处理和智能分析,系统能够为用户提供科学准确的压力评估报告和个性化的健康管理建议。该系统的成功实现不仅验证了大数据技术在心理健康数据分析领域的应用可行性,也为传统压力评估方法的数字化转型提供了技术路径,对于推动心理健康管理的智能化发展具有重要的理论意义和实际价值,为相关领域的进一步研究和应用奠定了坚实的技术基础。
大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖