(1)Spark基础入门
①什么是Spark
Spark是一款分布式内存计算的统一分析引擎。其特点就是对任意类型的数据进行自定义计算。Spark可以计算:结构化、半结构化、非结构化等各种类型的数据结构,同时也支持使用Python、Java、Scala、R以及SQL语言去开发应用程序计算数据 。Spark的适用面非常广泛,所以,被称之为 统一的(适用面广)的分析引擎(数据处理)
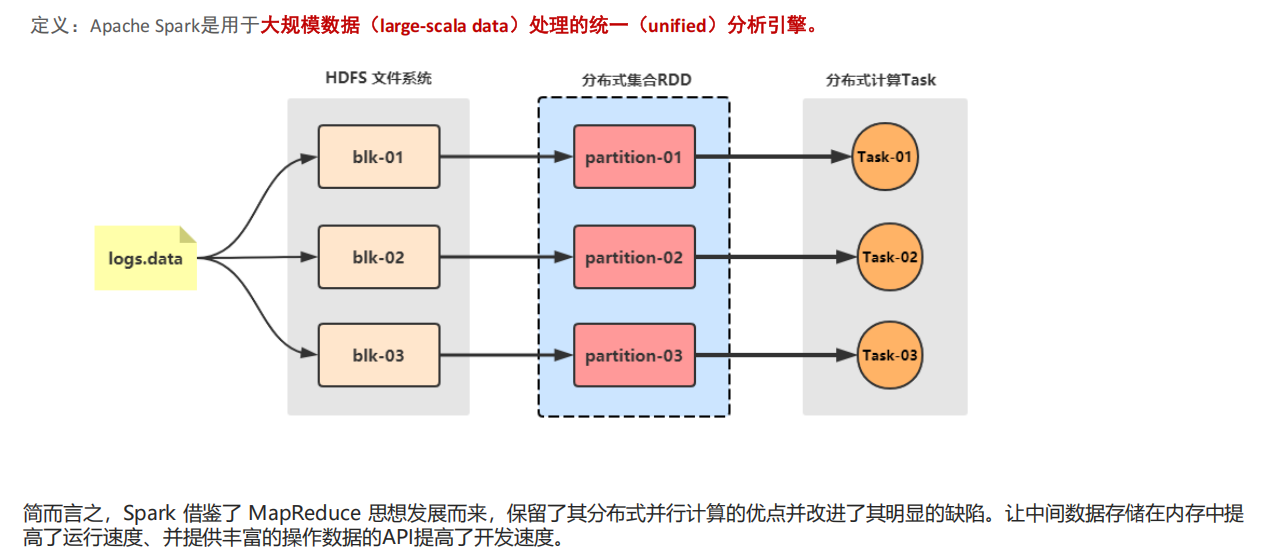
RDD 是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算 ,并且有一定的容错方式。而这也是整个 Spark 的核心数据结构,Spark 整个平台都围绕着RDD进行。可以说RDD就是一种数据结构抽象 。
RDD(Resilient Distributed Dataset),是指弹性分布式数据集。
①数据集:Spark中的编程是基于RDD的,将原始数据加载到内存变成RDD,RDD再经过若干次转化,仍为RDD 。
②分布式:读数据一般都是从分布式系统中去读,如hdfs、kafka等 ,所以原始文件存在磁盘是分布式的,spark加载完数据的RDD也是分布式的,换句话说RDD是抽象的概念,实际数据仍在分布式文件系统中;因为有了RDD,在开发代码过程会非常方便,只需要将原始数据理解为一个集合,然后对集合进行操作即可
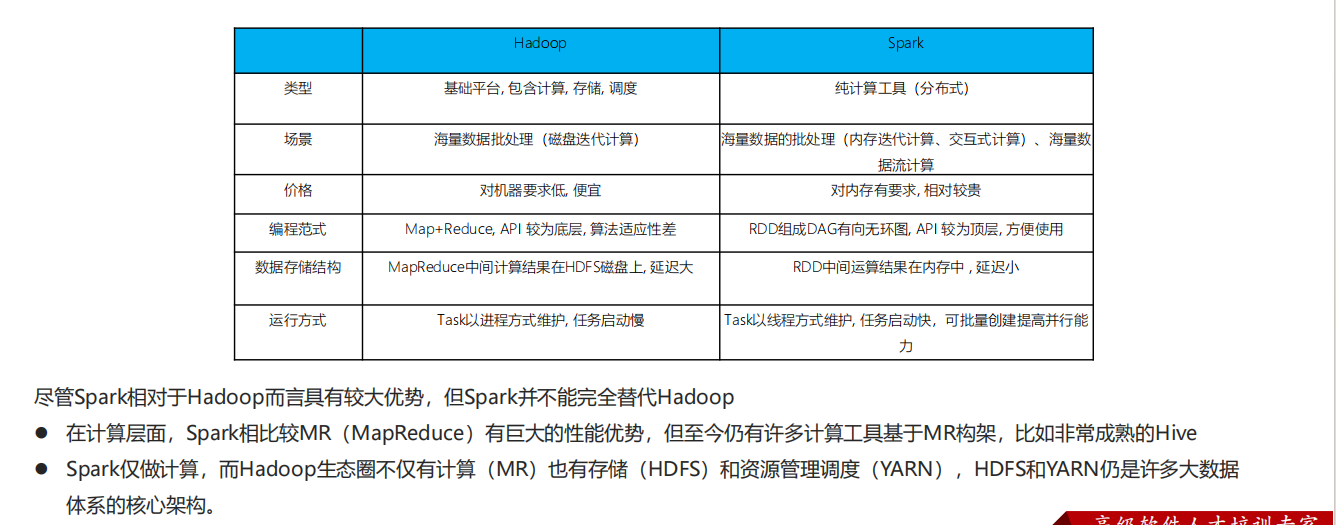
②Spark VS Hadoop(MapReduce)
③Spark 框架模块

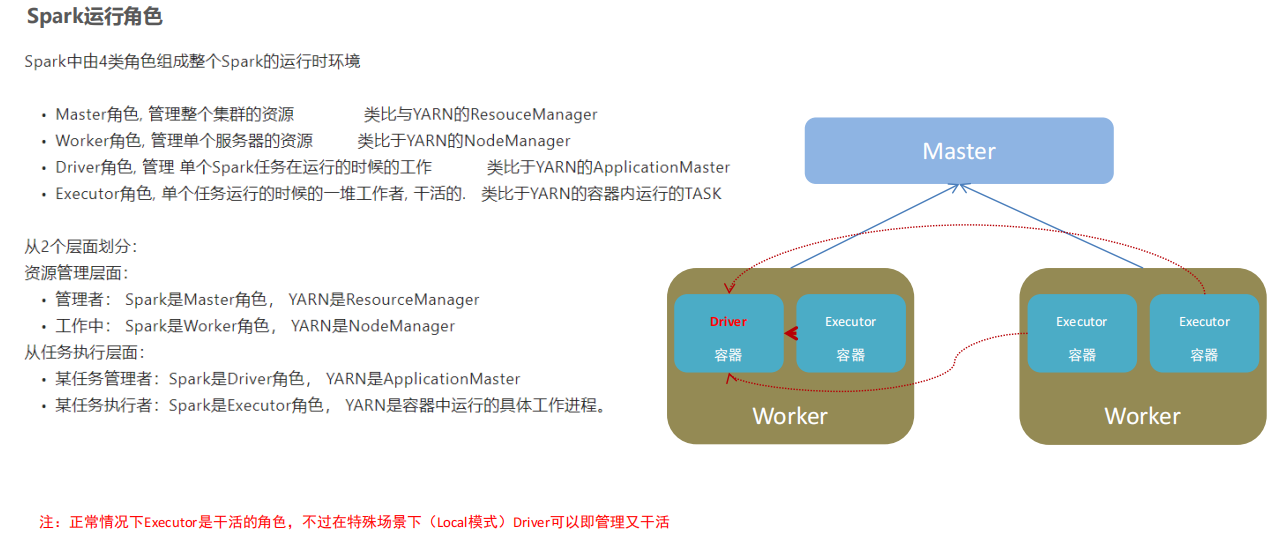
④Spark的架构角色
⑤Spark本地运行环境
"Local"指的是本地运行模式,即在单个机器上(而非集群)运行Spark应用程序的开发测试模式。这种模式允许开发者在没有分布式环境的情况下快速测试和调试Spark代码


这种模式下面有三种运行方式:
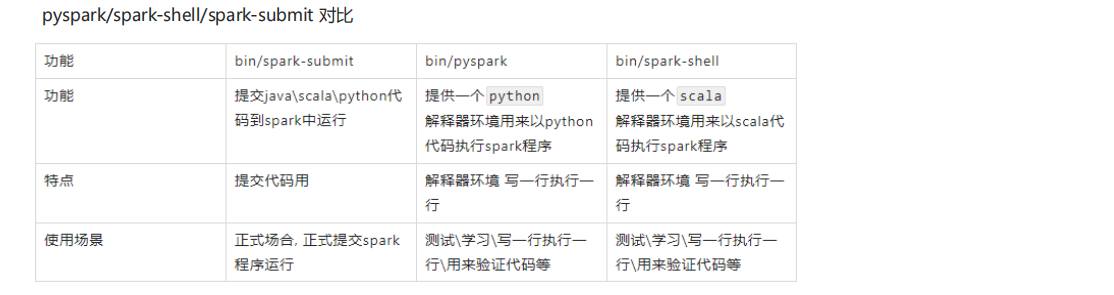
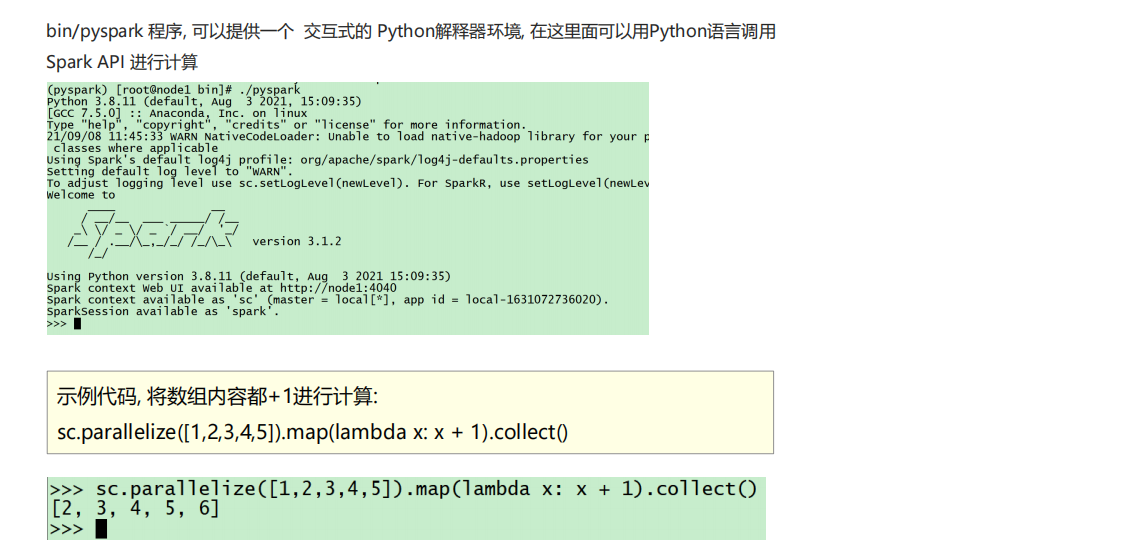
①以下是基于Pyspark的测试:
②以下是spark-submit的测试代码:
bash
代码格式为:./spark-submit [可选的一些选项] jar包或者python代码的路径 [代码的参数]
示例如下:./spark-submit /opt/spark/examples/src/main/python/pi.py 10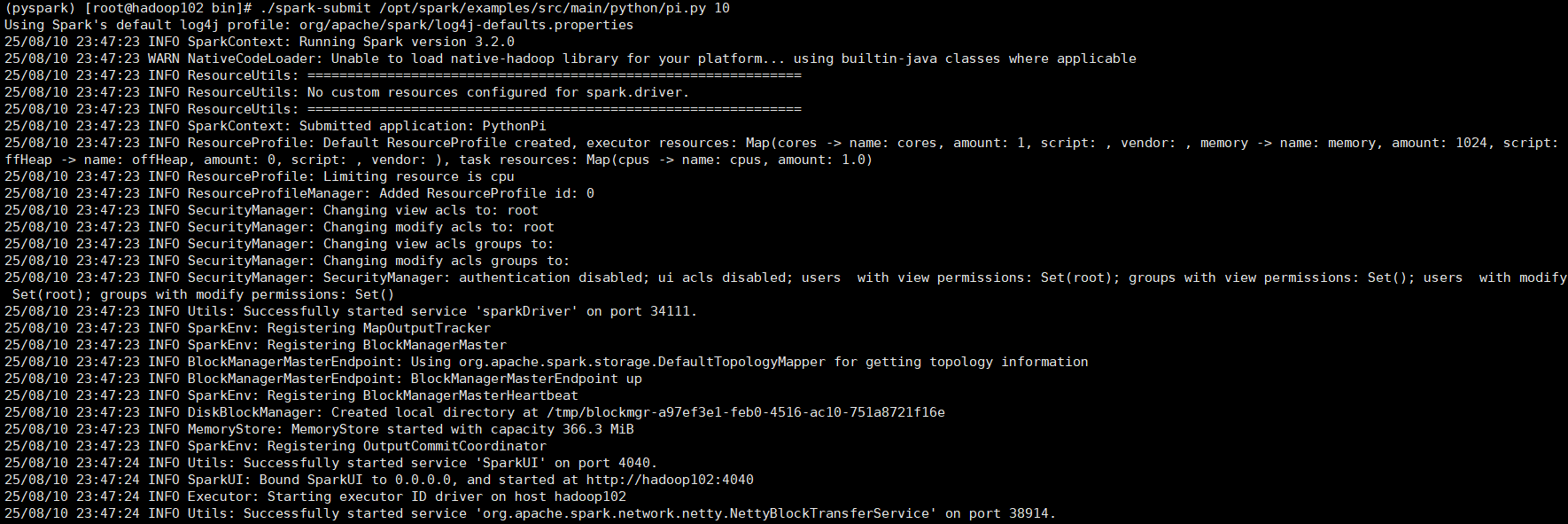

以下是总结:
①Local模式的运行原理:Local模式就是以一个独立进程配合其内部线程来提供完成Spark运行时环境. Local模式可以通过spark-shell/pyspark/spark-submit等来开启
②bin/pyspark是什么程序:**是一个交互式的解释器执行环境,环境启动后就得到了一个Local Spark环境,**可以运行Python代码去进行Spark计算,类似Python自带解释器
③Spark的4040端口是什么:Spark的任务在运行后,会在Driver所在机器绑定到4040端口,提供当前任务的监控页面供查看