(一)、虚拟机端安装scala
1.切换到install目录
cd /opt/install
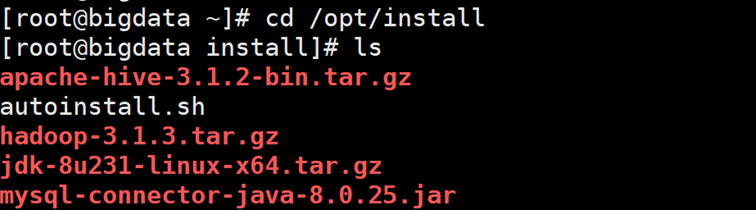
2. 上传Scala 的tgz 包到install 目录(通过WinSCP去上传)
3 去解压该文件包
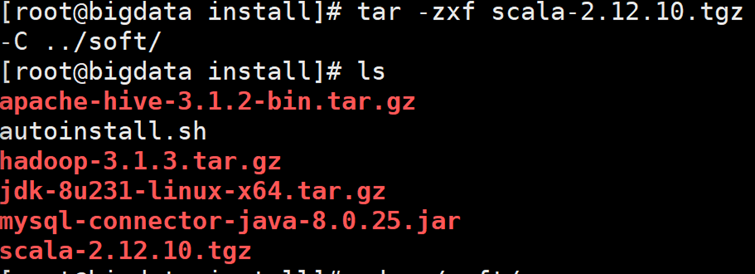
4. 切换到soft 目录
5. 将原来的scala 文件名字改为scala212
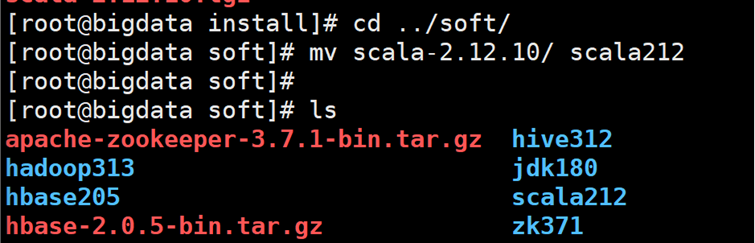
6. 切换到scala212 目录
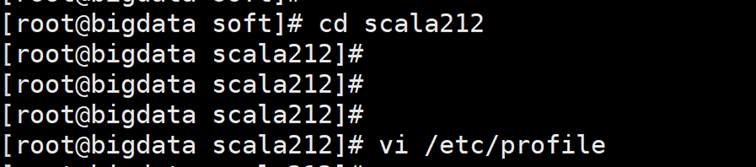
7.vi /etc/profile
去添加内容
在最下面末尾处添加:
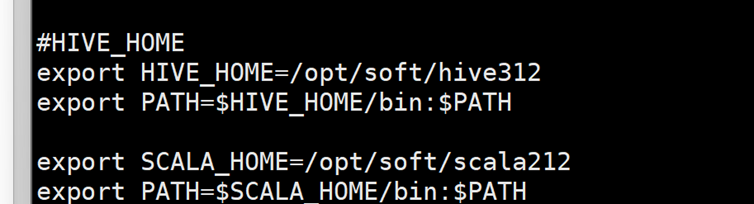
Export SCALA_HOME=/opt/soft/scala212
Export PATH=SCALA_HOME/bin:PATH
8.source /etc/profile
并且去测试
Scala
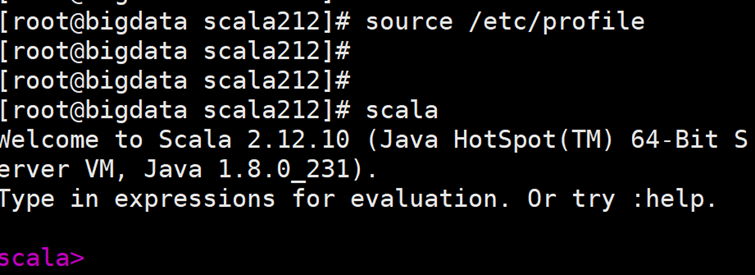
出现此形式则成功。
(二)、在windows 端安装scala
首先在安装之前,确保本地已经安装了JDK1.5以上的版本,在此安装的是1.8版本。并且已经设置了JAVA_HOME 环境变量及JDK的bin目录。
一、准备工作
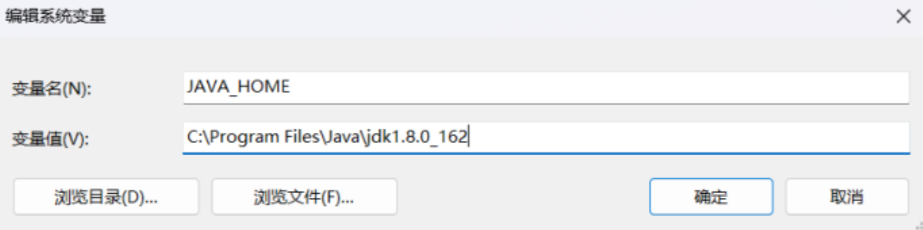
1、新建JAVA_HOME环境变量
桌面找到【此电脑】,右击【此电脑】--【属性】--【高级系统设置】--【环境变量】。
2、编辑path系统变量,添加%JAVA_HOME%\bin
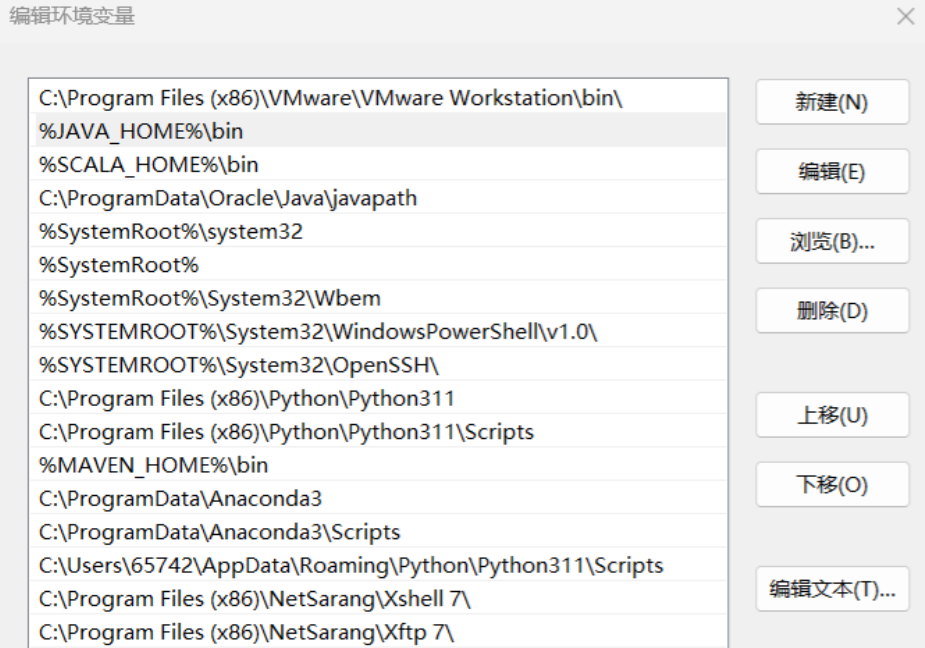
3、验证环境变量是否配置成功。

二、正式开始安装
1.下载Scala安装文件
接着我们从Scala官网地址 https://www.scala-lang.org/download/all.html 上下载Scala二进制的包。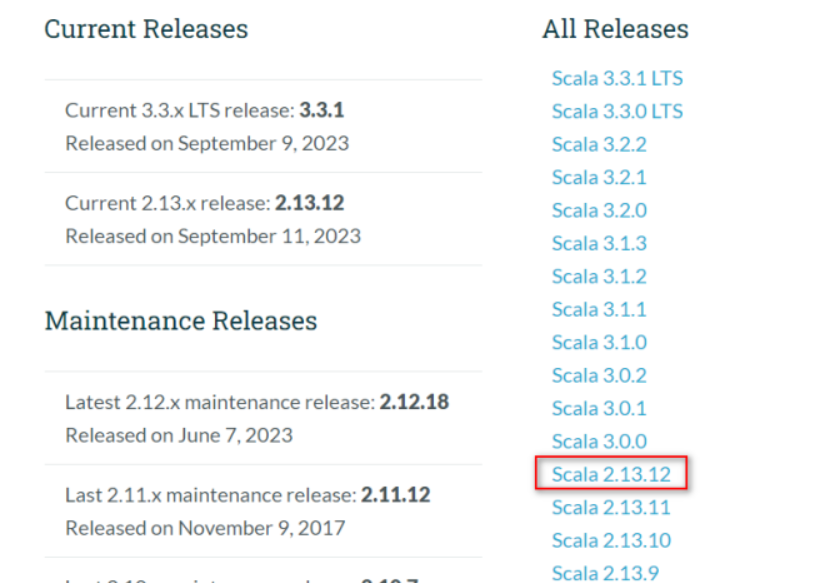
点击Scala2.13.12后进入到下载页面。
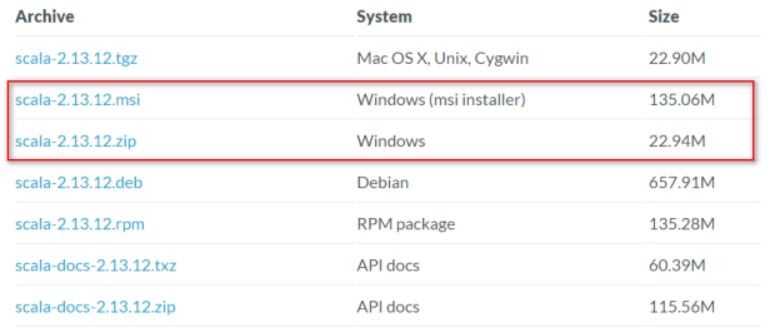
对于windows系统,可以下载的安装包有msi和zip,任选一个即可。
(1).msi
.msi文件是WindowsInstaller的数据包,它实际上是一个数据库,包含安装一种产品所需要的信息和在很多安装情形下安装(和卸载)程序所需的指令和数据,只要系统中包含windowsinstaller支持就能够使用。需要双击msi文件启动运行安装。
(2).zip
一种格式的压缩包,解压后配置环境变量即可使用。
这里 我 选择下载zip格式的文件 。
2.解压Scala-2.13.12.zip
解压后进入文件夹,可以看到如下:
三. 配置Scala的环境变量
1. 打开设置SCALA_HOME环境变量
桌面找到【此电脑】,右击【此电脑】--【属性】--【高级系统设置】--【环境变量】。
单击系统变量的新建,在变量名栏输入:SCALA_HOME: 变量值一栏输入 Scala 的安装目录。
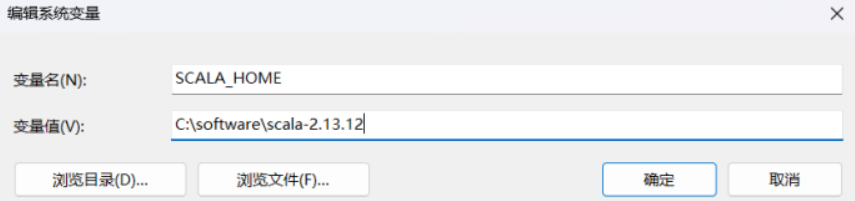
大家尽量不要安装在C盘
2. 设置 Path 变量
找到系统变量下的"Path"如图,单击编辑。然后新建,添加如下的路径: %SCALA_HOME%\bin;
3. 检查 scala是否配置成功
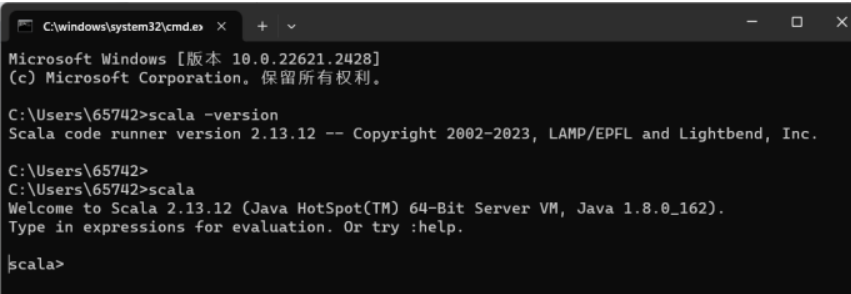
按住Win + R启动运行,在输入框中输入cmd,然后"回车",输入 scala,然后回车,如环境变量设置ok,你应该能看到这些信息。
4. 启动scala,执行程序
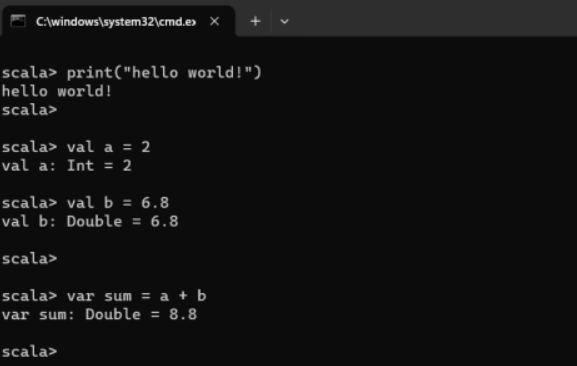
在命令行提示后输入scala,则会进入Scala的命令行模式,在此可以编写Scala表达式和程序。
scala> print("hello world!")
scala> val a = 2
scala> val b = 6.8
scala> var sum = a + b
结果如下:
说明:
val :value的缩写,用于定义Scala常量
var: variable的缩写,用于定义Scala变量
Scala里val定义的变量相当于Java里用final定义的变量,其实都是常量,不能再给它赋值