生成模型实战 | MuseGAN详解与实现
-
- [0. 前言](#0. 前言)
- [1 数字音乐表示](#1 数字音乐表示)
-
- [1.1 音符、音阶和音高](#1.1 音符、音阶和音高)
- [1.2 多音轨音乐](#1.2 多音轨音乐)
- [1.3 音乐的数字化表示](#1.3 音乐的数字化表示)
- [2. MuseGAN 模型分析](#2. MuseGAN 模型分析)
-
- [2.1 用和弦、风格、旋律和节奏构建音乐](#2.1 用和弦、风格、旋律和节奏构建音乐)
- [2.2 训练 MuseGAN 的步骤](#2.2 训练 MuseGAN 的步骤)
- [3. 训练数据集处理](#3. 训练数据集处理)
-
- [3.1 下载训练数据](#3.1 下载训练数据)
- [3.2 将多维对象转换为音乐作品](#3.2 将多维对象转换为音乐作品)
- [4. 构建 MuseGAN](#4. 构建 MuseGAN)
-
- [4.1 MuseGAN 中的判别器](#4.1 MuseGAN 中的判别器)
- [4.2 MuseGAN 中的生成器](#4.2 MuseGAN 中的生成器)
- [4.3 优化器和损失函数](#4.3 优化器和损失函数)
- [5. 训练 MuseGAN 生成音乐](#5. 训练 MuseGAN 生成音乐)
-
- [5.1 训练 MuseGAN](#5.1 训练 MuseGAN)
- [5.2 使用训练好的MuseGAN生成音乐](#5.2 使用训练好的MuseGAN生成音乐)
0. 前言
人工智能音乐生成领域已引起了广泛关注,MuseGAN 是其中一个重要的模型。MuseGAN 是一个深度神经网络,利用生成对抗网络 (Generative Adversarial Network, GAN)创造多音轨音乐,其中 "Muse" 代表着音乐背后的创意灵感。该模型能够理解不同音轨之间的复杂互动,这些音轨代表着不同的乐器或不同的声音(训练数据就是这种情况)。
MuseGAN 由两个主要组成部分构成:生成器和评论家(评论家提供一个连续的度量标准,来衡量样本的真实度,而不是将样本分类为真或假)。生成器的任务是生成音乐,而评论家评估音乐的质量并向生成器提供反馈。这种对抗性的互动使得生成器能够逐渐改进,从而创作出更真实、更具吸引力的音乐。
MuseGAN 生成的音乐风格受训练数据的影响。本节我们将使用 JSB Chorales 数据集来训练 MuseGAN,该数据集包含巴赫创作的四音轨合唱曲。在生成图像时,生成器使用的是来自潜在空间的单一噪声向量来生成不同格式的内容;而在 MuseGAN 中,生成器将使用四个噪声向量来生成一段音乐,旨在增强音乐生成过程中的可控行和多样性。每个噪声向量代表音乐的不同方面,通过单独调整这些向量,模型可以生成更复杂、更细腻的音乐作品。
1 数字音乐表示
在本节中,我们将介绍基本的音乐理论,然后使用钢琴卷帘表示法对音乐进行数字化表示。我们将学习如何加载并播放示例 MIDI 文件。还会介绍 music21 库,并使用它来可视化与音乐作品相关的乐谱音符。最后,将学习如何将一段音乐表示为形状为 (4, 2, 16, 84) 的多维对象。
1.1 音符、音阶和音高
在本节中,我们将数据集中的音乐作品表示为 4D 对象。为了理解训练数据中音乐作品的含义,首先必须了解一些基本的音乐理论概念,如音符 (notes)、音阶 (octave) 和音高 (pitch),这些概念相互关联,对于理解数据集至关重要。下图展示了这些概念之间的关系。
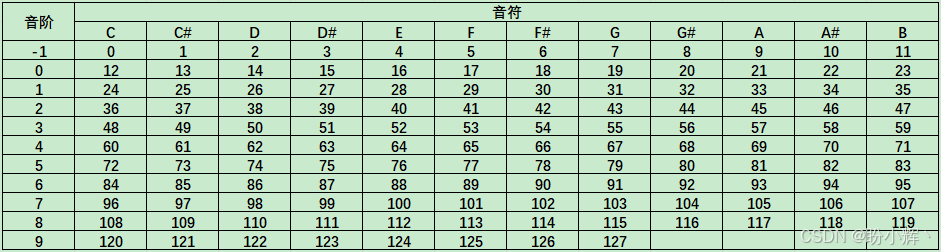
音符是代表特定音乐声音的符号。音符是音乐的基本元素,用于创作旋律、和弦和节奏。每个音符都有一个名称(如 A、B、C、D、E、F、G),并对应一个特定的频率,这个频率决定了音符的音高:即音符是高音还是低音。例如,中音 C (C4) 的频率通常约为 262 赫兹,意味着其声波每秒震动 262 次。
C4 中的数字 4 表示音阶,音阶是指一个音高等级到下一个音高等级之间的距离。上图中,最左列展示了 11 个音阶,范围从 -1 到 9。音频的频率在每升高一个音阶时会翻倍。例如,A4 音符的频率通常为 440 赫兹,而 A5 比A4高一个音阶,频率为 880 赫兹。
在西方音乐中,一个音阶被分为 12 个半音,每个半音对应一个特定的音符。上图列出了这 12 个半音:C、C#、D、D#、...、B。上下移动 12 个半音,可以到达同样的音符名称,但在更高或更低的音阶。例如,A5 是 A4 的上一个音阶。
每个音符在特定音阶中都被分配了一个音高编号,范围从 0 到 127,如上图所示。例如,C4 的音高编号是 60,而 F3 的音高编号是 53。音高编号是一种更有效的表示音符的方式,因为它同时指定了音阶等级和半音,正因如此,本节使用的训练数据就是采用音高编号进行编码的。
1.2 多音轨音乐
在电子音乐制作中,音轨 (track) 通常指的是音乐的独立层次或组成部分,如鼓轨、贝斯轨或旋律轨。在古典音乐中,音轨可能代表不同的声部,如女高音、女中音、男高音和男低音。例如,我们在本节使用的训练数据集------JSB Chorales 数据集由四个音轨组成,分别对应四个声部。在音乐制作中,每个音轨可以在数字音频工作站 (digital audio workstation, DAW) 中单独编辑和处理。这些音轨由各种音乐元素组成,包括小节、音级和音符。
小节 (bar) 是由一定数量的节拍 (beat) 构成的时间段,每个节拍都有一个特定的音符时值。在许多流行音乐类型中,一个小节通常包含 4 个节拍,但这可以根据乐曲的拍号有所不同。一个曲目的总小节数由曲目的长度和结构决定。轨道中的小节总数由轨道的长度和结构决定。例如,在我们的训练数据集中,每个轨道包含两个小节。
在步进编程中(一种常用于编程电子音乐节奏和旋律的技术),音级代表一个小节的细分。在标准的 4/4 拍号(每小节 4 节拍,每节拍 4 音级)中,每个小节可能包含 16 个音级,每个音级对应小节的 1/16。
最后,音级包含一个音乐音符。在我们的数据集中,我们限制了音符的范围为 84 个最常用的音符(音高编号从 0 到 83)。因此,音级中的音符被编码为一个包含 84 个值的独热编码向量。
为了用实际例子来说明这些概念,我们使用数据集中的 example.midi 文件,将其保存到 ./files/ 目录下。文件 example.midi 是从训练数据集中的一段音乐转换而来的。之后,我们将学习如何将训练数据集中形状为 (4, 2, 16, 84) 的音乐作品转换成可以播放的 MIDI 文件。
music21 库是一个功能强大、全面的 Python 库,旨在进行音乐分析、创作和处理,用于可视化各种音乐概念的工作方式。使用 pip 命令安装 music21 库:
shell
$ pip install music21music21 库能够将音乐可视化为五线谱,从而更好地理解轨道、小节、音级和音符的关系。为了实现这一点,首先需要安装 MuseScore 应用,下载适合本机操作系统的 MuseScore 应用并进行安装。需要使用 MuseScore 应用的安装位置。例如,在 Windows 系统中,路径为 C:\Program Files\MuseScore 4\bin\MuseScore4.exe,则可以使用以下代码可视化 example.midi 文件的五线谱:
python
from music21 import midi, environment
mf = midi.MidiFile()
# 打开 MIDI 文件
mf.open("files/example.midi")
mf.read()
mf.close()
stream = midi.translate.midiFileToStream(mf)
us = environment.Environment()
# 定义 MuseScore 应用位置
path = r'C:\Program Files\MuseScore 4\bin\MuseScore4.exe'
us['musescoreDirectPNGPath'] = path
# 可视化
stream.show()对于 macOS 操作系统,需要将路径更改为 /Applications/MuseScore 4.app/Contents/MacOS/mscore,而在 Linux 系统中,下载可执行文件后可以放置在 util/ 文件夹中。执行代码将得到一个类似于下图所示的五线谱。

JSB Chorales 数据集由巴赫的合唱音乐作品组成,通常用于训练音乐生成任务中的机器学习模型。数据集中每个音乐作品的形状 (4, 2, 16, 84) ,其含义如下:
4代表合唱中的四个声部:女高音、女低音、男高音和男低音,每个声部在数据集中被视为单独的音轨- 每个音轨被划分为
2个小节,这种格式化方式旨在标准化音乐作品的长度,以便用于训练 16代表每小节中的音级数量- 最后,音符通过一个包含
84个值的独热编码来表示,表示每个音级中可能出现的音高(或音符)的数量
1.3 音乐的数字化表示
钢琴卷帘是一种音乐的视觉表现,通常用于 MIDI 编排软件和数字音频工作站中。它的名字来源于传统的钢琴卷帘,这些卷帘曾被用于自动钢琴中,里面的纸卷上会打上孔洞来表示音符。在数字化环境中,钢琴卷轴以虚拟格式完成类似的功能。
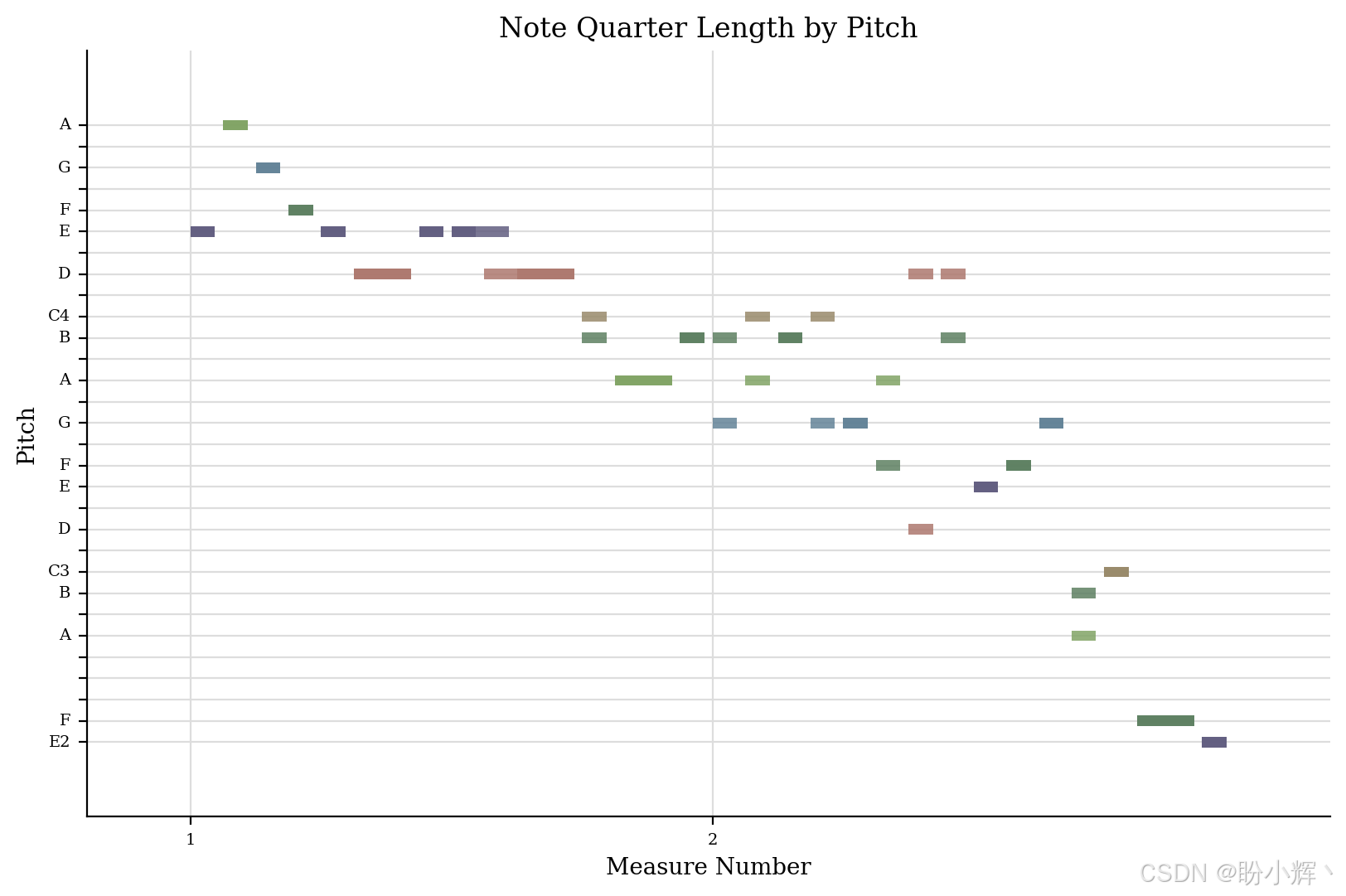
钢琴卷帘通常以网格的形式呈现,时间在水平轴上表示(从左到右),音高在垂直轴上表示(从下到上)。每一行对应一个特定的音符,高音位于网格顶部,低音位于底部,这与钢琴键盘的布局类似。音符在网格上用条形或块状表示。音符块在垂直轴上的位置表示其音高,而在水平轴上的位置则表示该音符的时序。音符块的长度代表音符的持续时间。
(1) 使用 music21 库来可视化钢琴卷帘:
python
stream.plot()输出结果如下图所示:
(2) music21 库还可以查看钢琴卷帘对应的量化音符:
python
for n in stream.recurse().notes:
print(n.offset, n.pitches)输出结果如下所示,可以看到音符的偏移量和对应的音高:
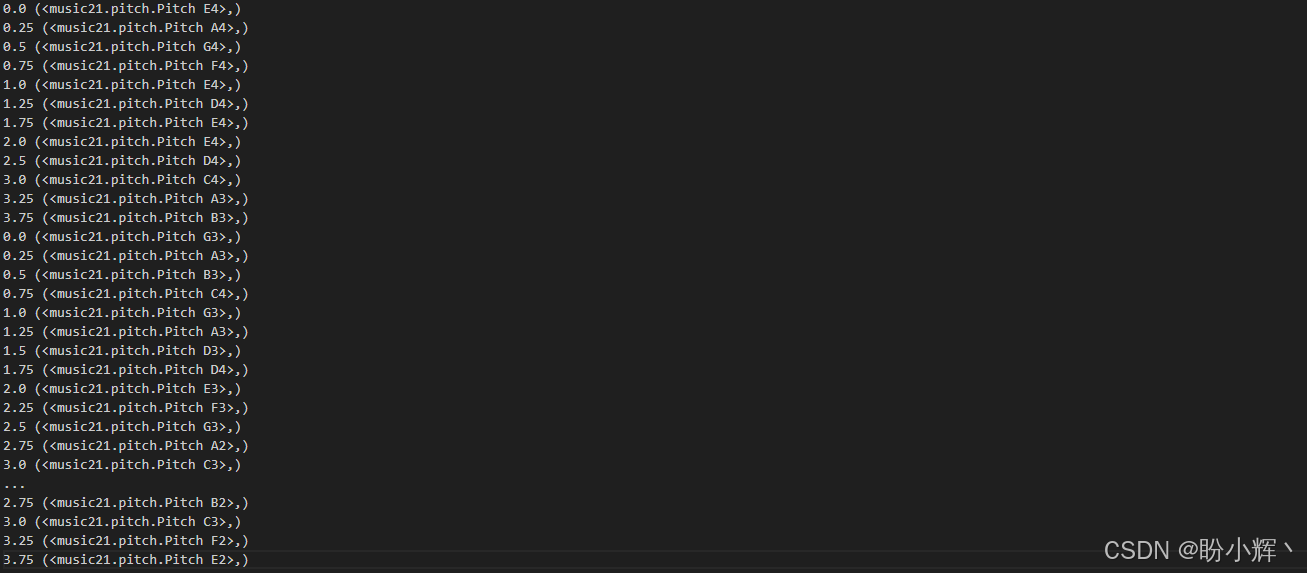
在以上输出中,每行中的第一个值代表时间。在大多数情况下,每行的时间增加 0.25 秒。如果下一行的时间增加超过 0.25 秒,则表示一个音符的持续时间超过了 0.25 秒。可以看到,起始音符是 E4。0.25 秒后,音符变为 A4,然后是 G4,依此类推。
(3) 接下来,将一系列音乐音符转换为形状为 (4, 2, 16, 84) 的对象。首先,我们查看每个时间步中的音符的音高编号:
python
for n in stream.recurse().notes:
print(n.offset,n.pitches[0].midi)输出结果如下所示:
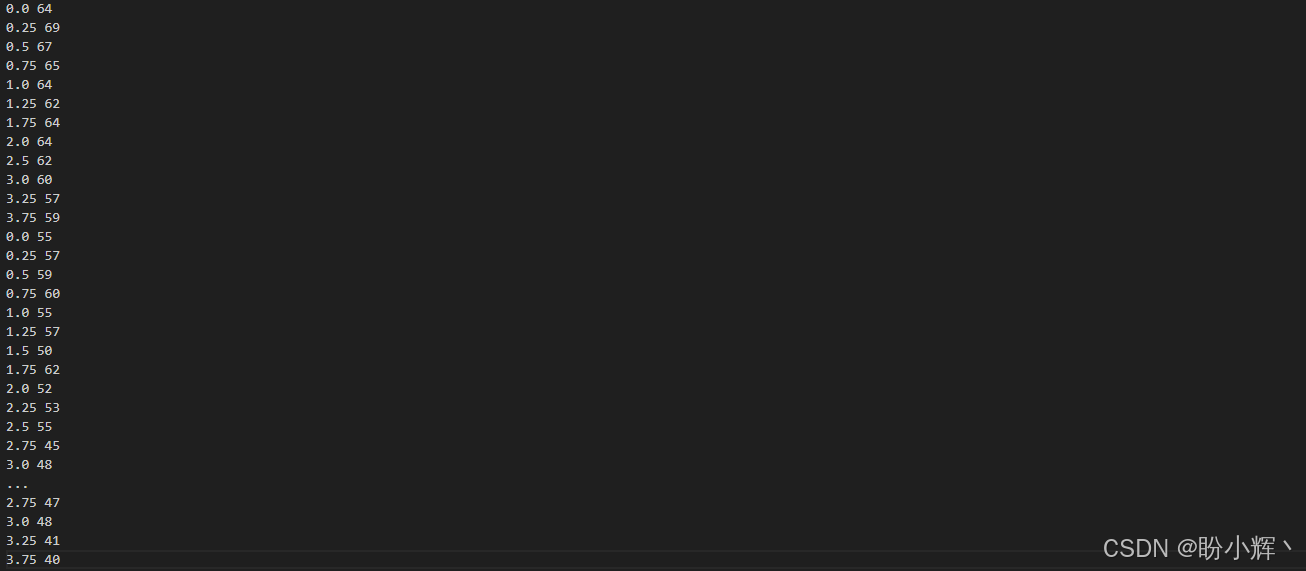
以上代码将每个时间步中的音符转换为一个音高编号,音高编号的范围是 0 到 83。每个音高编号随后被转换为一个包含 84 个值的独热编码变量,其中除了一个位置为 1,其他位置均为 -1,将值设置在 -1 和 1 之间可以将数据中心化到 0 周围,这有助于训练过程更加稳定且更快。许多激活函数和权重初始化方法假设输入数据已将数据中心化到 0 周围。
将一段 MIDI 音乐编码成形状为 (4, 2, 16, 84) 的对象,每个音乐作品包含 4 条音轨,每条音轨包含 2 小节,每小节被细分为 16 个音符(每小节 4 拍,每拍有 4 个音符,因此每小节有 16 个音符)。由于我们训练集中的音高编号范围是 0 到 83,因此每个音符由一个包含 84 个值的独热向量表示。
2. MuseGAN 模型分析
在创作音乐时,我们需要引入更详细的输入,以增强可控性和多样性,我们将在音乐生成过程中使用 4 个不同的噪声向量。由于每个音乐作品包含 4 条音轨和 2 小节,我们将使用 4 个向量来管理这种结构。我们将使用一个向量来统一控制所有音轨和小节,第二个向量来控制每个小节的所有音轨中的表现,第三个向量来管理所有轨道在不同小节中的表现,第四个向量用于控制每个音轨中的每个单独小节的内容。本节将介绍和弦、风格、旋律和节奏的概念,并解释它们如何影响音乐生成的各个方面。之后,我们将讨论构建和训练 MuseGAN 模型的步骤。
2.1 用和弦、风格、旋律和节奏构建音乐
在音乐生成阶段,我们从潜空间中获取 4 个噪声向量(分别代表和弦、风格、旋律和节奏),并将它们输入到生成器中以创作一段音乐。在音乐中,和弦、风格、旋律和节奏是影响音乐整体声音和感觉的关键要素。
- 风格 (
style):音乐的创作、表演和体验的特征方式。它包括音乐的流派(例如爵士乐、古典音乐、摇滚等)、音乐创作的时代背景,以及作曲家或演奏者的独特风格。风格受文化、历史和个人因素的影响,它有助于定义音乐的身份 - 节奏 (
groove):音乐中的节奏感受或律动,尤其是在像爵士和灵魂乐等风格中。它是让听众想要拍打节拍或跳舞的原因。节奏通过重音模式、节奏部分(鼓、贝斯等)之间的互动以及节奏速度 (tempo) 共同创造。它是赋予音乐动感和流动性的元素 - 和弦 (
chords):同时演奏的两个或更多音符的组合,它们为音乐提供和声基础。和弦建立在音阶之上,并用于赋予音乐结构和情感深度。不同类型的和弦(大调、小调、减和弦、增和弦等)及其排列可以在听者中唤起不同的情绪和感觉 - 旋律 (
melody):音乐中最容易被识别的音符序列。它是听众可能会哼唱或跟着唱的部分,旋律通常是从音阶中构建的,并由音高、节奏和轮廓(音高的上升和下降模式)来表征。一个好的旋律是令人难忘且富有表现力的,能够传达音乐作品的主要主题和情感
这些元素共同作用,创造出音乐作品的整体声音和体验。每个元素都有其作用,它们相互作用并相互影响,最终形成完整的音乐作品。具体来说,一首音乐作品由 4 条音轨组成,每条音轨包含 2 小节,总共形成 8 个小节的组合。我们将使用一个噪声向量来表示风格,应用于所有小节;使用 8 个不同的噪声向量来表示旋律,每个噪声向量应用于一个独特的小节;节奏有 4 个噪声向量,每个应用于不同的音轨,并在 2 个小节中保持不变;和弦使用 2 个噪声向量,每个小节一个。下图展示了这 4 个元素如何共同作用以创建一首完整的音乐作品。
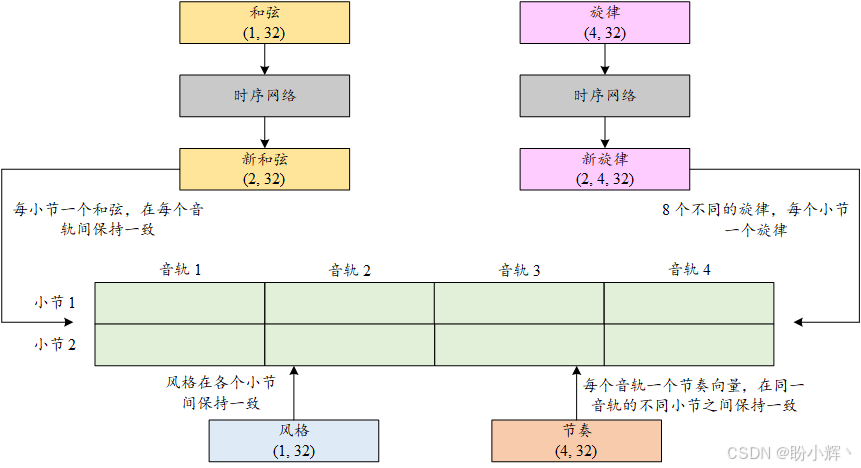
生成器通过一次生成一个音轨中的一个小节来创建一首音乐。为此,它需要四个噪声向量作为输入,每个向量的形状为 (1, 32)。这些向量分别代表和弦、风格、旋律和节奏,每个向量控制音乐的一个不同方面。由于音乐作品由四个音轨组成,每个音轨有两个小节,因此总共有八个小节组合。因此,我们需要八组和弦、风格、旋律和节奏来生成音乐作品的所有部分。
我们将从潜空间中获取四个噪声向量,分别对应和弦、风格、旋律和节奏。我们还将引入一个时序网络,作用是沿小节维度扩展输入。音乐本质上具有时序性,具有随时间展开的模式和结构。MuseGAN 中的时序网络旨在捕捉这些时序依赖性,确保生成的音乐连贯且合乎逻辑。
- 和弦的噪声向量形状为
(1, 32),经过时序网络处理后,得到两个(1, 32)大小的向量。第一个向量用于所有音轨的第一个小节,第二个向量用于所有音轨的第二个小节 - 风格的噪声向量形状为
(1, 32),统一应用于所有八个小节。需要注意的是,风格向量不需要通过时序网络,因为风格向量设计为在各个小节间保持一致 - 旋律的噪声向量形状为
(4, 32),通过时序网络后,它会输出两个(4, 32)大小的向量,然后再细分为八个(1, 32)大小的向量,每个向量用于一个独特的小节 - 节奏的噪声向量形状为
(4, 32),每个(1, 32)大小的向量应用于不同的音轨,并在两个小节中保持不变。我们不会将节奏向量通过时间网络,因为节奏向量设计为在小节之间保持一致
所有 8 个小节的音乐生成后,将它们合并成一段完整的音乐,包含 4 个不同的音轨,每个音轨由两个独特的小节组成。
2.2 训练 MuseGAN 的步骤
MuseGAN 生成的音乐风格受训练数据风格的影响。因此,为了生成巴赫风格的音乐,首先需要收集巴赫作品的数据集,并将其格式化为适合训练的形式。接下来,创建一个 MuseGAN 模型,其中包含一个生成器和一个判别器(评论家)。生成器网络接受四个随机噪声向量作为输入(分别对应和弦、风格、旋律和节奏),并输出一段音乐。判别器网络评估生成的音乐,并给出评分,对于真实音乐(来自训练集)给出较高的评分,而对于生成器生成的虚假音乐则给出较低的评分。生成器和判别器网络都使用深度卷积层来捕捉输入的空间特征。
下图展示了 MuseGAN 的训练过程。生成器接收四个随机噪声向量(和弦、风格、旋律和节奏)作为输入,并生成虚假音乐作品。判别器评估生成器生成的虚假音乐作品与训练集中的真实作品。判别器为所有音乐作品给出真实性分数,旨在给真实音乐给出较高的评分,给虚假音乐给出较低的评分。
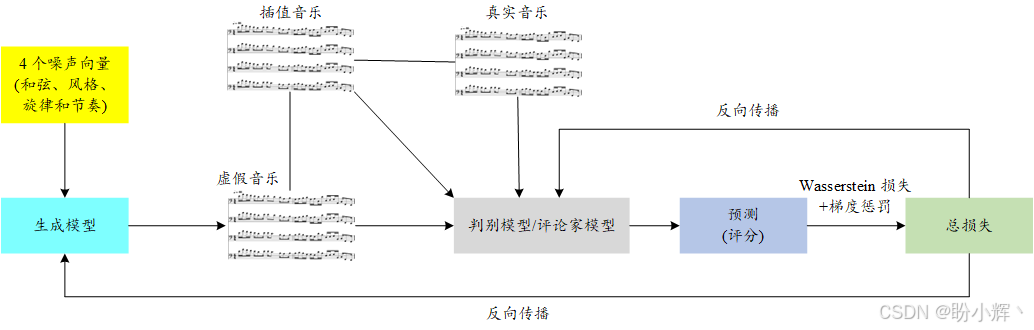
为了指导模型参数的调整,必须为生成器和判别器选择合适的损失函数。生成器的损失函数旨在鼓励生成的数据尽可能接近训练数据集中的数据。具体来说,生成器的损失函数是判别器评分的负值。通过最小化这个损失函数,生成器力求创建能够获得判别器高评分的音乐作品。另一方面,判别器的损失函数旨在鼓励判别器准确评估真实和生成的数据样本。因此,判别器的损失函数是评分本身(如果音乐作品来自训练集)或评分的负值(如果音乐作品由生成器生成)。本质上,判别器旨在给真实音乐作品给出较高的评分,给虚假音乐给出较低的评分。
此外,我们在损失函数中引入了 Wasserstein 距离与梯度惩罚,以增强模型的训练稳定性和性能。为了实现这一点,判别器评估一个插值音乐作品,该作品混合了真实和虚假音乐。基于判别器对这个插值作品的评分,添加梯度惩罚到训练过程中的总损失中。
在整个训练过程中,交替训练判别器和生成器。在每次训练迭代中,我们从训练集中采样一批真实的音乐作品,并生成一批虚假音乐作品。通过将判别器的评分与真实标签(音乐作品是真实还是虚假)进行比较来计算总损失。然后,我们稍微调整生成器和判别器网络中的权重,以便在后续的迭代中,生成器能够生成更加逼真的音乐作品,判别器则能给真实音乐作品分配较高的评分,给虚假音乐作品分配较低的评分。
3. 训练数据集处理
我们将使用巴赫的合唱作品作为训练数据集,生成类似于巴赫风格的音乐。如果对其他音乐家的风格感兴趣,可以使用他们的作品作为训练数据。
3.1 下载训练数据
(1) 使用 JSB Chorales 钢琴卷帘数据集作为训练集,下载音乐文件 Jsb16thSeparated.npz 并将其保存到 ./files/ 目录中。
(2) 编写两个实用模块 midi_util.py 和 MuseGAN_util.py,使用这些模块,我们就可以加载音乐文件,并将其组织成批数据以供后续处理,限于篇幅,完整代码不再单独展示,可以直接进行下载。
(3) 加载数据集,然后提取第一首音乐并命名为 first_song。由于音乐是以多维对象表示的,打印出第一首音乐的形状。最后,我们将训练数据按批大小为 64 进行分组,供模型训练使用:
python
from torch.utils.data import DataLoader
from midi_util import MidiDataset
dataset = MidiDataset('files/Jsb16thSeparated.npz')
first_song=dataset[0]
print(first_song.shape)
loader = DataLoader(dataset, batch_size=64,
shuffle=True, drop_last=True)输出结果如下所示:
shell
torch.Size([4, 2, 16, 84])可以看到,数据集中的每首歌曲的形状为 (4, 2, 16, 84)。这意味着每首歌曲由 4 个音轨组成,每个音轨有 2 个小节。每个小节包含 16 个音级,每个音级的音符通过一个包含 84 个值的独热编码向量表示。在每个独热编码向量中,所有值都被设置为 -1,只有一个位置的值为 1,表示该位置存在一个音符。验证数据集中值的范围:
python
flat=first_song.reshape(-1,)
print(set(flat.tolist()))输出结果如下所示:
shell
{1.0, -1.0}3.2 将多维对象转换为音乐作品
歌曲以 PyTorch 张量的形式存储,并已准备好输入到 MuseGAN 模型中。然而,在继续之前,需要了解如何将这些多维对象转换为计算机上可以播放的音乐作品,用于将生成的音乐作品转换为可播放的文件。
(1) 首先,将所有包含 84 维的独热编码转换为范围从 0 到 83 的音高数字:
python
import numpy as np
from music21 import note, stream, duration, tempo
parts = stream.Score()
parts.append(tempo.MetronomeMark(number=66))
# 将 84 维的独热编码向量转换为 0 到 83 之间的数字
max_pitches = np.argmax(first_song, axis=-1)
# 将结果整形为(32, 4)
midi_note_score = max_pitches.reshape([2 * 16, 4])
print(midi_note_score)输出结果如下所示:
(2) 接下来,继续将 tensor midi_note_score 转换为 MIDI 文件:
python
# 遍历 4 个音轨
for i in range(4):
last_x = int(midi_note_score[:, i][0])
s = stream.Part()
dur = 0
# 遍历每个音轨中的所有音符
for idx, x in enumerate(midi_note_score[:, i]):
x = int(x)
if (x != last_x or idx % 4 == 0) and idx > 0:
n = note.Note(last_x)
n.duration = duration.Duration(dur)
s.append(n)
dur = 0
last_x = x
# 每个时间步增加 0.25 秒
dur = dur + 0.25
n = note.Note(last_x)
n.duration = duration.Duration(dur)
# 将音符添加到音乐流中
s.append(n)
parts.append(s)
parts.write("midi","files/first_song.midi")4. 构建 MuseGAN
从本质上讲,我们将把音乐作品视为一个具有多个维度的对象。因为卷积神经网络能够有效地从多维对象中提取空间特征,我们将使用深度卷积神经网络来处理音乐生成任务。在 MuseGAN 中,我们将构建一个生成器和一个判别器,类似于图像生成中生成器如何根据判别器的反馈来完善图像,生成器将生成 4D 对象的音乐作品。
在训练过程中,生成的虚假音乐和训练集中的真实音乐都会输入到判别器中。判别器将为每个音乐作品评分,分数范围从负无穷到正无穷,分数越高表示音乐越有可能是真实音乐。判别器的目标是为真实音乐输出较高分数,为虚假音乐输出较低分数。相反,生成器的目标是生成与真实音乐难以区分的音乐作品,从而使判别器输出较高分数。
4.1 MuseGAN 中的判别器
将Wasserstein 距离引入损失函数有助于稳定训练。因此,在 MuseGAN 中,我们采用了类似的方法,使用评论家 (critic) 而不是二分类器。评论家不是一个二分类器,而是评估生成器输出(本节为音乐作品),并为其分配一个分数,范围从负无穷到正无穷。较高的分数表示音乐更有可能是真实的(即来自训练集)。
(1) 在 MuseGAN_util.py 中构建音乐评论家神经网络,评论家网络的输入是一段音乐作品,维度为 (4, 2, 16, 84)。网络主要由若干个 Conv3d 层组成,将音乐作品的每一轨道视为一个 3D 对象,并应用卷积核提取空间特征,Conv3d 层的操作类似于图像生成中使用的 Conv2d 层:
python
class MuseCritic(nn.Module):
def __init__(self,hid_channels=128,hid_features=1024,
out_features=1,n_tracks=4,n_bars=2,n_steps_per_bar=16,
n_pitches=84):
super().__init__()
self.n_tracks = n_tracks
self.n_bars = n_bars
self.n_steps_per_bar = n_steps_per_bar
self.n_pitches = n_pitches
in_features = 4 * hid_channels if n_bars == 2 else 12 * hid_channels
self.seq = nn.Sequential(
# 将输入通过多个Conv3d层
nn.Conv3d(self.n_tracks, hid_channels,
(2, 1, 1), (1, 1, 1), padding=0),
nn.LeakyReLU(0.3, inplace=True),
nn.Conv3d(hid_channels, hid_channels,
(self.n_bars - 1, 1, 1), (1, 1, 1), padding=0),
nn.LeakyReLU(0.3, inplace=True),
nn.Conv3d(hid_channels, hid_channels,
(1, 1, 12), (1, 1, 12), padding=0),
nn.LeakyReLU(0.3, inplace=True),
nn.Conv3d(hid_channels, hid_channels,
(1, 1, 7), (1, 1, 7), padding=0),
nn.LeakyReLU(0.3, inplace=True),
nn.Conv3d(hid_channels, hid_channels,
(1, 2, 1), (1, 2, 1), padding=0),
nn.LeakyReLU(0.3, inplace=True),
nn.Conv3d(hid_channels, hid_channels,
(1, 2, 1), (1, 2, 1), padding=0),
nn.LeakyReLU(0.3, inplace=True),
nn.Conv3d(hid_channels, 2 * hid_channels,
(1, 4, 1), (1, 2, 1), padding=(0, 1, 0)),
nn.LeakyReLU(0.3, inplace=True),
nn.Conv3d(2 * hid_channels, 4 * hid_channels,
(1, 3, 1), (1, 2, 1), padding=(0, 1, 0)),
nn.LeakyReLU(0.3, inplace=True),
# 展平
nn.Flatten(),
# 通过两个线性层
nn.Linear(in_features, hid_features),
nn.LeakyReLU(0.3, inplace=True),
nn.Linear(hid_features, out_features))
def forward(self, x):
return self.seq(x)评论家模型的最后一层是线性层,且我们不对其输出应用任何激活函数。因此,评论家模型的输出是一个范围从负无穷到正无穷的值,可以将其解释为评论家对音乐作品的评分。
4.2 MuseGAN 中的生成器
本节中,生成器一次生成一小节音乐,然后将这些小节组合成完整的音乐作品。与仅使用一个噪声向量不同,MuseGAN 中的生成器输入四个独立的噪声向量,以控制生成音乐的不同方面。这四个向量中,有两个会通过时序网络处理,用于在小节维度上进行扩展。风格 (style) 和节奏 (groove) 向量的设计是为了在各个小节之间保持不变,而和弦 (chords) 和旋律 (melody) 向量则是为了在小节之间有所变化。因此,我们首先建立一个时序网络,将和弦和旋律向量跨越两个小节进行扩展,确保生成的音乐在时间上具有连贯性和逻辑性。
(2) 在 MuseGAN_util.py 模块中,定义 TemporalNetwork() 类:
python
class TemporalNetwork(nn.Module):
def __init__(
self,
z_dimension=32,
hid_channels=1024,
n_bars=2):
super().__init__()
self.n_bars = n_bars
self.net = nn.Sequential(
# 输入维度是 (1, 32)
Reshape(shape=[z_dimension, 1, 1]),
nn.ConvTranspose2d(
z_dimension,
hid_channels,
kernel_size=(2, 1),
stride=(1, 1),
padding=0,
),
nn.BatchNorm2d(hid_channels),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(
hid_channels,
z_dimension,
kernel_size=(self.n_bars - 1, 1),
stride=(1, 1),
padding=0,
),
nn.BatchNorm2d(z_dimension),
nn.ReLU(inplace=True),
# 输出维度为 (2, 32)
Reshape(shape=[z_dimension, self.n_bars]),
)
def forward(self, x):
return self.net(x)TemporalNetwork() 类使用了两个 ConvTranspose2d 层,将一个噪声向量扩展成两个独立的噪声向量,每个噪声向量对应于一个小节。转置卷积层用于上采样和生成特征图,在本节中它们用来将噪声向量扩展到不同的小节。
(2) 为了避免一次生成所有音轨的所有小节,我们会逐个小节生成音乐。这样做可以让 MuseGAN 在计算效率、灵活性和音乐连贯性之间取得平衡,从而生成更有结构和吸引力的音乐作品。因此,接下来在 MuseGAN_util.py 中构建小节生成器类 BarGenerator(),负责生成音乐作品中的一个小节:
python
class BarGenerator(nn.Module):
def __init__(self,z_dimension=32,hid_features=1024,hid_channels=512,
out_channels=1,n_steps_per_bar=16,n_pitches=84):
super().__init__()
self.n_steps_per_bar = n_steps_per_bar
self.n_pitches = n_pitches
self.net = nn.Sequential(
# 将和弦、风格、旋律和节奏连接成一个向量,大小为 4 * 32
nn.Linear(4 * z_dimension, hid_features),
nn.BatchNorm1d(hid_features),
nn.ReLU(inplace=True),
Reshape(shape=[hid_channels,hid_features//hid_channels,1]),
# 然后将输入重塑为 2D,并使用多个 ConvTranspose2d 层进行上采样和音乐特征生成
nn.ConvTranspose2d(hid_channels,hid_channels,
kernel_size=(2, 1),stride=(2, 1),padding=0),
nn.BatchNorm2d(hid_channels),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(hid_channels,hid_channels // 2,
kernel_size=(2, 1),stride=(2, 1),padding=0),
nn.BatchNorm2d(hid_channels // 2),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(hid_channels // 2,hid_channels // 2,
kernel_size=(2, 1),stride=(2, 1),padding=0),
nn.BatchNorm2d(hid_channels // 2),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(hid_channels // 2,hid_channels // 2,
kernel_size=(1, 7),stride=(1, 7),padding=0),
nn.BatchNorm2d(hid_channels // 2),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(hid_channels // 2,out_channels,
kernel_size=(1, 12),stride=(1, 12),padding=0),
# 输出的形状为 (1, 1, 16, 84):1 个轨道,1 小节和 16 个音符,每个音符由一个 84 维的向量表示
Reshape([1, 1, self.n_steps_per_bar, self.n_pitches]))
def forward(self, x):
return self.net(x)BarGenerator() 类接受四个噪声向量作为输入,每个向量代表不同音轨中特定小节的和弦、风格、旋律和节奏,且每个噪声向量的形状为 (1, 32)。这些向量会被拼接成一个包含 128 个值的向量,然后输入到 BarGenerator() 类中。BarGenerator() 类的输出是一小节音乐,维度为 (1, 1, 16, 84),表示 1 条音轨,1 小节,16 个音符,每个音符由一个 84 维的向量表示。
(3) 最后,使用 MuseGenerator() 类来生成完整的音乐作品,包含四条音轨,每条轨道有两个小节,每一小节都通过 BarGenerator() 类构建。在 MuseGAN_util.py 模块中定义 MuseGenerator() 类:
python
class MuseGenerator(nn.Module):
def __init__(self,z_dimension=32,hid_channels=1024,
hid_features=1024,out_channels=1,n_tracks=4,
n_bars=2,n_steps_per_bar=16,n_pitches=84):
super().__init__()
self.n_tracks = n_tracks
self.n_bars = n_bars
self.n_steps_per_bar = n_steps_per_bar
self.n_pitches = n_pitches
self.chords_network=TemporalNetwork(z_dimension,
hid_channels, n_bars=n_bars)
self.melody_networks = nn.ModuleDict({})
for n in range(self.n_tracks):
self.melody_networks.add_module(
"melodygen_" + str(n),
TemporalNetwork(z_dimension,
hid_channels, n_bars=n_bars))
self.bar_generators = nn.ModuleDict({})
for n in range(self.n_tracks):
self.bar_generators.add_module(
"bargen_" + str(n),BarGenerator(z_dimension,
hid_features,hid_channels // 2,out_channels,
n_steps_per_bar=n_steps_per_bar,n_pitches=n_pitches))
def forward(self,chords,style,melody,groove):
chord_outs = self.chords_network(chords)
bar_outs = []
# 遍历 2 个小节
for bar in range(self.n_bars):
track_outs = []
chord_out = chord_outs[:, :, bar]
style_out = style
# 遍历 4 个音轨
for track in range(self.n_tracks):
melody_in = melody[:, track, :]
melody_out = self.melody_networks["melodygen_"\
+ str(track)](melody_in)[:, :, bar]
groove_out = groove[:, track, :]
# 将和弦、风格、旋律和节奏连接成一个向量
z = torch.cat([chord_out, style_out, melody_out,\
groove_out], dim=1)
# 使用小节生成器生成一个小节
track_outs.append(self.bar_generators["bargen_"\
+ str(track)](z))
track_out = torch.cat(track_outs, dim=1)
bar_outs.append(track_out)
# 将八个小节连接成一首完整的音乐作品
out = torch.cat(bar_outs, dim=2)
return out生成器接收四个噪声向量作为输入,遍历 4 条音轨和 2 个小节。在每次迭代中,生成器利用小节生成器来创建一小节音乐。完成所有迭代后,MuseGenerator() 类将 8 个小节合并成一个完整的音乐作品,输出的维度为 (4, 2, 16, 84)。
4.3 优化器和损失函数
(1) 基于 MuseGenerator() 和 MuseCritic() 类创建生成器和评论家:
python
import torch
from MuseGAN_util import (init_weights, MuseGenerator, MuseCritic)
device = "cuda" if torch.cuda.is_available() else "cpu"
generator = MuseGenerator(z_dimension=32, hid_channels=1024,
hid_features=1024, out_channels=1).to(device)
critic = MuseCritic(hid_channels=128,
hid_features=1024,
out_features=1).to(device)
generator = generator.apply(init_weights)
critic = critic.apply(init_weights)(2) 评论家的损失函数定义为预测值与目标值的乘积的负平均值。因此,在 MuseGAN_util.py 中定义 loss_fn() 函数:
python
def loss_fn(pred,target):
return -torch.mean(pred*target)在训练过程中,对于生成器,将损失函数中的 target 参数设置为 1,旨在引导生成器生成能够获得高评分(即 loss_fn() 函数中的预测变量 pred) 的音乐;对于评论家,我们将真实音乐的 target 设置为 1,虚假音乐的 target 设置为 -1,旨在引导评论家给真实音乐分配较高分数,给虚假音乐分配较低分数。
(3) 将 Wasserstein 距离与梯度惩罚结合到评论家的损失函数中,以确保训练的稳定性。梯度惩罚在 MuseGAN_util.py 文件中定义:
python
class GradientPenalty(nn.Module):
def __init__(self):
super().__init__()
def forward(self, inputs, outputs):
grad = torch.autograd.grad(
inputs=inputs,
outputs=outputs,
grad_outputs=torch.ones_like(outputs),
create_graph=True,
retain_graph=True,
)[0]
grad_=torch.norm(grad.view(grad.size(0),-1),p=2,dim=1)
penalty = torch.mean((1. - grad_) ** 2)
return penaltyGradientPenalty() 类需要两个输入:插值音乐(由真实音乐和虚假音乐混合而成)和评论家网络对此插值音乐分配的评分。GradientPenalty() 类计算评论家评分相对于插值音乐的梯度。然后,梯度惩罚计算为这些梯度的范数与目标值 1 的平方差。
(3) 使用 Adam 优化器来优化判别器和生成器:
python
lr = 0.001
g_optimizer = torch.optim.Adam(generator.parameters(),
lr=lr, betas=(0.5, 0.9))
c_optimizer = torch.optim.Adam(critic.parameters(),
lr=lr, betas=(0.5, 0.9))5. 训练 MuseGAN 生成音乐
交替训练评论家和生成器。在每次训练迭代中,我们会从训练数据集中采样一批真实的音乐样本,并从生成器中采样一批生成的音乐样本,然后将它们提供给评论家评估。在评论家训练过程中,将评论家的评分与真实标签进行比较,并调整评论家网络的权重,以便在下一次迭代中,真实音乐的评分尽可能高,生成音乐的评分尽可能低。在生成器训练过程中,我们将生成的音乐输入评论家模型以获得评分,然后调整生成器网络的权重,以便在下一次迭代中,生成的音乐评分更高(因为生成器的目标是创作出能够欺骗评论家的音乐,使其认为是真实的音乐作品)。多次重复以上过程,逐渐使生成器网络能够创作出更真实的音乐作品。
5.1 训练 MuseGAN
(1) 在开始进行 MuseGAN 模型的训练循环之前,首先定义一些超参数和辅助函数。repeat 控制每次迭代中训练评论家的次数,display_step 指定我们显示输出的频率,epochs 是训练模型的 epoch 数:
python
from MuseGAN_util import loss_fn, GradientPenalty
# 定义超参数
batch_size=64
repeat=5
display_step=10
epochs=500
# 定义 alpha 用于创建插值音乐
alpha=torch.rand((batch_size,1,1,1,1)).requires_grad_().to(device)
# 实例化 gp 计算梯度惩罚
gp=GradientPenalty()
# 定义 noise() 函数获取四个随机噪声向量
def noise():
chords = torch.randn(batch_size, 32).to(device)
style = torch.randn(batch_size, 32).to(device)
melody = torch.randn(batch_size, 4, 32).to(device)
groove = torch.randn(batch_size, 4, 32).to(device)
return chords,style,melody,groove(2) 定义函数 train_epoch(),用于训练模型一个 epoch:
python
def train_epoch():
e_gloss = 0
e_closs = 0
# 遍历所有批数据
for real in loader:
real = real.to(device)
# 在每次迭代中训练评论家五次
for _ in range(repeat):
chords,style,melody,groove=noise()
c_optimizer.zero_grad()
with torch.no_grad():
fake = generator(chords, style, melody,groove).detach()
realfake = alpha * real + (1 - alpha) * fake
fake_pred = critic(fake)
real_pred = critic(real)
realfake_pred = critic(realfake)
fake_loss = loss_fn(fake_pred,-torch.ones_like(fake_pred))
real_loss = loss_fn(real_pred,torch.ones_like(real_pred))
penalty = gp(realfake, realfake_pred)
# 总损失有三个组成部分:
# 评估真实音乐的损失、评估虚假音乐的损失以及梯度惩罚损失
closs = fake_loss + real_loss + 10 * penalty
closs.backward(retain_graph=True)
c_optimizer.step()
e_closs += closs.item() / (repeat*len(loader))
# 训练生成器
g_optimizer.zero_grad()
chords,style,melody,groove=noise()
fake = generator(chords, style, melody, groove)
fake_pred = critic(fake)
gloss = loss_fn(fake_pred, torch.ones_like(fake_pred))
gloss.backward()
g_optimizer.step()
e_gloss += gloss.item() / len(loader)
return e_gloss, e_closs(3) 训练模型 500 个 epoch:
python
for epoch in range(1,epochs+1):
e_gloss, e_closs = train_epoch()
if epoch % display_step == 0:
print(f"Epoch {epoch}, G loss {e_gloss} C loss {e_closs}")
torch.save(generator.state_dict(),'files/MuseGAN_G.pth')5.2 使用训练好的MuseGAN生成音乐
为了使用训练好的生成器生成音乐,从潜空间采样四个噪声向量输入生成器。需要注意的是,我们可以同时生成多个音乐对象,并将它们一起解码为一首连续的音乐作品。
(1) 首先,加载训练好的生成器权重:
python
generator.load_state_dict(torch.load('files/MuseGAN_G.pth', weights_only=False))(2) 与生成单一的 4D 音乐对象不同,我们可以同时生成多个 4D 音乐对象,并将它们合并成一首连续的音乐。例如,如果我们希望生成五个音乐对象,我们首先从潜空间中采样五组噪声向量,每组由四个向量组成:和弦、风格、旋律和节奏:
python
num_pieces = 5
chords = torch.rand(num_pieces, 32).to(device)
style = torch.rand(num_pieces, 32).to(device)
melody = torch.rand(num_pieces, 4, 32).to(device)
groove = torch.rand(num_pieces, 4, 32).to(device)每个生成的音乐对象可以转化为大约持续 8 秒的音乐片段。我们选择生成五个音乐对象,然后将它们解码为一个单一的音乐作品,这样最终的时长大约为 40 秒。可以调整 num_pieces 变量的值,以控制生成的音乐时长。
(3) 接下来,将五组潜变量输入生成器,生成一组音乐对象:
python
preds = generator(chords, style, melody, groove).detach()(4) 输出 preds 由五个音乐对象组成。然后,我们将这些对象解码为一首完整的音乐作品,并以 MIDI 文件的形式保存:
python
from midi_util import convert_to_midi
music_data = convert_to_midi(preds.cpu().numpy())
music_data.write('midi', 'files/MuseGAN_song.midi')convert_to_midi() 函数将音乐对象转换为 MIDI 文件,由于 MIDI 文件表示的是时间序列中的音符,我们只需将对应于五个音乐对象的五个音乐片段合并成一个扩展的音符序列。然后,将合并后的音符序列保存为 MuseGAN_song.midi 文件。