lmkd(low momery killer demon),跟大多数守护进程一样,都由init进程启动,在系统中作为一个单独的进程存在,启动时直接运行lmkd.cpp中的main函数。
js
system\memory\lmkd\lkmd.rc
service lmkd /system/bin/lmkd
class core
user lmkd
group lmkd system readproc
capabilities DAC_OVERRIDE KILL IPC_LOCK SYS_NICE SYS_RESOURCE
critical
socket lmkd seqpacket+passcred 0660 system system
task_profiles ServiceCapacityLow这里创建的 socket lmkd 的 user/group 都是 system,而它的权限是 0660,所以只有system 应用才能读写(一般是 activity manager)。
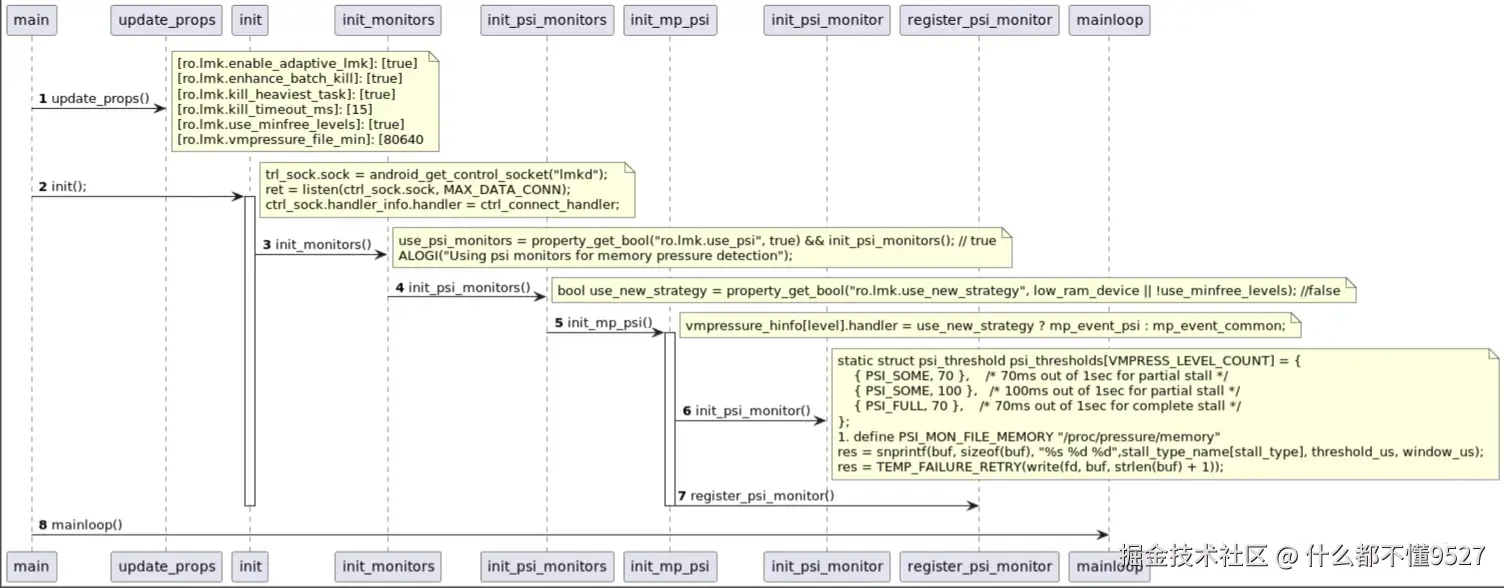
启动后,开始执行main方法:main函数中,逻辑较清楚,更新参数,创建logger,之后在if中进行init,之后在mainloop()中循环等待。
1:update_props()
使用GET_LMK_PROPERTY从属性中获取各个参数配置,例如从参数中获取low、medium、critical三种压力等级下,可以kill的adj等级。GET_LMK_PROPERTY用来读取ro.lmk参数。
js
static bool update_props() {
/* By default disable low level vmpressure events */
level_oomadj[VMPRESS_LEVEL_LOW] =
GET_LMK_PROPERTY(int32, "low", OOM_SCORE_ADJ_MAX + 1);
level_oomadj[VMPRESS_LEVEL_MEDIUM] =
GET_LMK_PROPERTY(int32, "medium", 800);
level_oomadj[VMPRESS_LEVEL_CRITICAL] =
GET_LMK_PROPERTY(int32, "critical", 0);
debug_process_killing = GET_LMK_PROPERTY(bool, "debug", false);
...
return true;
}2:static int init(void)
init中关键是epoll的创建,宏定义MAX_EPOLL_EVENTS是9,也就是epoll监听了9个event。
java
static int init(void) {
static struct event_handler_info kernel_poll_hinfo = { 0, kernel_event_handler };
struct reread_data file_data = {
.filename = ZONEINFO_PATH,
.fd = -1,
};
struct epoll_event epev;
int pidfd;
int i;
int ret;
// Initialize page size
pagesize = getpagesize();
page_k = pagesize / 1024;
epollfd = epoll_create(MAX_EPOLL_EVENTS);
if (epollfd == -1) {
ALOGE("epoll_create failed (errno=%d)", errno);
return -1;
}
// mark data connections as not connected
for (int i = 0; i < MAX_DATA_CONN; i++) {
data_sock[i].sock = -1;
}
ctrl_sock.sock = android_get_control_socket("lmkd");
if (ctrl_sock.sock < 0) {
ALOGE("get lmkd control socket failed");
return -1;
}
ret = listen(ctrl_sock.sock, MAX_DATA_CONN);
if (ret < 0) {
ALOGE("lmkd control socket listen failed (errno=%d)", errno);
return -1;
}
epev.events = EPOLLIN;
ctrl_sock.handler_info.handler = ctrl_connect_handler;
epev.data.ptr = (void *)&(ctrl_sock.handler_info);
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, ctrl_sock.sock, &epev) == -1) {
ALOGE("epoll_ctl for lmkd control socket failed (errno=%d)", errno);
return -1;
}
maxevents++;
has_inkernel_module = !access(INKERNEL_MINFREE_PATH, W_OK);
use_inkernel_interface = has_inkernel_module;
//在高版本use_inkernel_interface这值为false,也就是不会使用lowmemorykiller这个功能
if (use_inkernel_interface) {
ALOGI("Using in-kernel low memory killer interface");
if (init_poll_kernel()) {
epev.events = EPOLLIN;
epev.data.ptr = (void*)&kernel_poll_hinfo;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, kpoll_fd, &epev) != 0) {
ALOGE("epoll_ctl for lmk events failed (errno=%d)", errno);
close(kpoll_fd);
kpoll_fd = -1;
} else {
maxevents++;
/* let the others know it does support reporting kills */
property_set("sys.lmk.reportkills", "1");
}
}
} else {
// Do not register monitors until boot completed for devices configured
// for delaying monitors. This is done to save CPU cycles for low
// resource devices during boot up.
if (!delay_monitors_until_boot || property_get_bool("sys.boot_completed", false)) {
// init函数需要决定lmkd的触发方式
// 在init_monitors()( 判断通过psi 还是vmpressure检测内存
if (!init_monitors()) {
return -1;
}
}
/* let the others know it does support reporting kills */
property_set("sys.lmk.reportkills", "1");
}
for (i = 0; i <= ADJTOSLOT(OOM_SCORE_ADJ_MAX); i++) {
procadjslot_list[i].next = &procadjslot_list[i];
procadjslot_list[i].prev = &procadjslot_list[i];
}
memset(killcnt_idx, KILLCNT_INVALID_IDX, sizeof(killcnt_idx));
/*
* Read zoneinfo as the biggest file we read to create and size the initial
* read buffer and avoid memory re-allocations during memory pressure
*/
if (reread_file(&file_data) == NULL) {
ALOGE("Failed to read %s: %s", file_data.filename, strerror(errno));
}
/* check if kernel supports pidfd_open syscall */
pidfd = TEMP_FAILURE_RETRY(pidfd_open(getpid(), 0));
if (pidfd < 0) {
pidfd_supported = (errno != ENOSYS);
} else {
pidfd_supported = true;
close(pidfd);
}
ALOGI("Process polling is %s", pidfd_supported ? "supported" : "not supported" );
if (!lmkd_init_hook()) {
ALOGE("Failed to initialize LMKD hooks.");
return -1;
}
return 0;
}2.1 init_monitors
js
static bool init_monitors() {
/* Try to use psi monitor first if kernel has it */
/* 在内核支持的情况下,尽量使用PSI监控器 */
use_psi_monitors = GET_LMK_PROPERTY(bool, "use_psi", true) &&
init_psi_monitors();
/* Fall back to vmpressure */
/* PSI监控器初始化失败,回退到vmpressure触发 */
if (!use_psi_monitors &&
(!init_mp_common(VMPRESS_LEVEL_LOW) ||
!init_mp_common(VMPRESS_LEVEL_MEDIUM) ||
!init_mp_common(VMPRESS_LEVEL_CRITICAL))) {
ALOGE("Kernel does not support memory pressure events or in-kernel low memory killer");
return false;
}
if (use_psi_monitors) {
ALOGI("Using psi monitors for memory pressure detection");
} else {
ALOGI("Using vmpressure for memory pressure detection");
}
monitors_initialized = true;
return true;
}2.1.1 init_psi_monitors
在init_psi_monitors()中,通过下面两个配置,进行不同的kill策略 ro.config.low_ram 配置设备为低内存ro.lmk.use_minfree_levels 与内核中的 LMK 驱动程序相同的kill策略(即可用内存和文件缓存阈值(file cache thresholds))做出终止决策。
这段代码的主要逻辑是:
1:检查是否有需要kill的进程,如果有正在kill的进程则跳过本次循环
2:解析/proc/vmstat和/proc/meminfo获取内存状态信息
3:根据内存水位线、thrashing值、swap使用情况等判断是否需要kill进程
- 如果刚kill完进程但内存使用依然过高,则再次kill
- 如果设备长时间无响应,则kill进程试图让设备响应
- 如果swap使用过高且thrashing过高,则kill进程
- 如果内存使用过高且swap空间不足,则kill进程
- 如果内存使用过高且thrashing过高,则kill进程
4:如果确定需要kill进程,则调用find_and_kill_process函数找到进程kill
5:根据内存状况决定PSI事件的轮询间隔,如果内存压力大则增大轮询频率
6:如果正在等待已kill进程退出,则暂停轮询
js
static bool init_psi_monitors() {
//当为低内存设备 或用旧模式的时候,使用use_new_strategy
bool use_new_strategy =
GET_LMK_PROPERTY(bool, "use_new_strategy", low_ram_device || !use_minfree_levels);
if (!use_new_strategy && memcg_version() != MemcgVersion::kV1) {
ALOGE("Old kill strategy can only be used with v1 cgroup hierarchy");
return false;
}
/* In default PSI mode override stall amounts using system properties */
if (use_new_strategy) {
/* Do not use low pressure level */
psi_thresholds[VMPRESS_LEVEL_LOW].threshold_ms = 0;
psi_thresholds[VMPRESS_LEVEL_MEDIUM].threshold_ms = psi_partial_stall_ms;
psi_thresholds[VMPRESS_LEVEL_CRITICAL].threshold_ms = psi_complete_stall_ms;
}
if (!init_mp_psi(VMPRESS_LEVEL_LOW, use_new_strategy)) {
return false;
}
if (!init_mp_psi(VMPRESS_LEVEL_MEDIUM, use_new_strategy)) {
destroy_mp_psi(VMPRESS_LEVEL_LOW);
return false;
}
if (!init_mp_psi(VMPRESS_LEVEL_CRITICAL, use_new_strategy)) {
destroy_mp_psi(VMPRESS_LEVEL_MEDIUM);
destroy_mp_psi(VMPRESS_LEVEL_LOW);
return false;
}
return true;
}决定好策略后,接下来调用init_mp_psi来初始化各个等级的PSI事件。在明确设置属性use_new_strategy为true的情况下,或低内存设备,或明确use_minfree_levels为false的情况下,都是倾向于使用"新的策略"。这里新的策略其实指的是在PSI触发之后,是根据free page的情况(水线)去查杀进程,还是根据不同PSI压力去查杀进程,前者就是旧策略,后者为新策略。新旧策略区别是依据PSI压力杀进程还是依据水线杀进。
重点在init_mp_psi方法上,init_mp_psi有两个参数,第一个是压力等级,第二个新旧策略的标志位。注意第一个参数的命名是"vmpressure_level",尽管是"vmpressure",但实际这里用PSI触发,是根据PSI来判断内存压力等级的。
init_mp_psi: 只有当设备不是低内存设备,同时使用minfree级别时,不使用新策略。
js
static bool init_mp_psi(enum vmpressure_level level, bool use_new_strategy) {
int fd;
/* Do not register a handler if threshold_ms is not set */
if (!psi_thresholds[level].threshold_ms) {
return true;
}
//往该节点(/proc/pressure/memory)写入stall_type、threshold_ms 、PSI_WINDOW_SIZE_MS
//调用psi.cpp 窗口大小时间(1000ms),PSI监视器监控窗口大小,
//在每个窗口最多生成一次事件,因此在PSI窗口大小的持续时间内轮询内存状态
fd = init_psi_monitor(psi_thresholds[level].stall_type,
psi_thresholds[level].threshold_ms * US_PER_MS,
PSI_WINDOW_SIZE_MS * US_PER_MS);
if (fd < 0) {
return false;
}
vmpressure_hinfo[level].handler = use_new_strategy ? mp_event_psi : mp_event_common;
vmpressure_hinfo[level].data = level;
if (register_psi_monitor(epollfd, fd, &vmpressure_hinfo[level]) < 0) {
destroy_psi_monitor(fd);
return false;
}
maxevents++;
mpevfd[level] = fd;
return true;
}init_psi_monitor是定义在system/memory/lmkd/libpsi/psi.cpp中的,他的作用是根据stall类型、阈值、窗口大小,获取epoll监听的句柄。
然后最重要的就是vmpressure_hinfolevel.handler,其根据是否使用新策略,决定了在这个压力等级事件发生时,要调用的是mp_event_psi还是mp_event_common。也就是使用新策略的情况下,当这个压力事件到来时,会调用mp_event_psi。
后面register_psi_monitor则是epoll监听压力事件。
至此可以认为init_psi_monitors()也就是PSI监控器初始化完成,各个压力事件发生时,会调用mp_event_psi。
2.1.1.1 mp_event_psi
mp_event_psi函数可以大致分为三个部分,第一部分做一些参数和状态的计算,第二部分根据得出的状态确定查杀原因(kill_reason),第三部分选择进程进行一轮查杀。
2.1.1.2 mp_event_common
js
static void mp_event_common(...) {
...
if (meminfo_parse(&mi) < 0 || zoneinfo_parse(&zi) < 0) {
ALOGE("Failed to get free memory!");
return;
}
...
if (use_minfree_levels) { //系统属性值,使用系统剩余的内存页和文件缓存阈值作为判断依据。
int i;
//other_free 表示系统可用的内存页的数目,从meminfo和zoneinfo中参数计算
// nr_free_pages为proc/meminfo中MemFree,当前系统的空闲内存大小,是完全没有被使用的内存
// totalreserve_pages为proc/zoneinfo中max_protection+high,其中max_protection在android中为0
other_free = mi.field.nr_free_pages - zi.field.totalreserve_pages;
//nr_file_pages = cached + swap_cached + buffers;有时还会有多余的页(other_file就是多余的),需要减去
if (mi.field.nr_file_pages > (mi.field.shmem + mi.field.unevictable + mi.field.swap_cached)) {
//other_file 基本就等于除 tmpfs 和 unevictable 外的缓存在内存的文件所占用的 page 数
other_file = (mi.field.nr_file_pages - mi.field.shmem - mi.field.unevictable - mi.field.swap_cached);
} else {
other_file = 0;
} //由此计算出 other_free 和 other_file
//遍历oomadj和minfree数组,找出other_free对应的minfree和adj,作为min_score_adj
min_score_adj = OOM_SCORE_ADJ_MAX + 1; //综合other_free,other_file 和 lowmem_minfree计算
for (i = 0; i < lowmem_targets_size; i++) {
//根据 lowmem_minfree 的值来确定 min_score_adj,oomadj小于 min_score_adj 的进程在这次回收过程中不会被杀死
minfree = lowmem_minfree[i];
if (other_free < minfree && other_file < minfree) {
min_score_adj = lowmem_adj[i];
// Adaptive LMK
if (enable_adaptive_lmk && level == VMPRESS_LEVEL_CRITICAL && i > lowmem_targets_size-4) {
min_score_adj = lowmem_adj[i-1];
}
break;
}
}
if (min_score_adj == OOM_SCORE_ADJ_MAX + 1) {//adj没变化不做任何处理
if (debug_process_killing) {
ALOGI("Ignore %s memory pressure event "
"(free memory=%ldkB, cache=%ldkB, limit=%ldkB)",
level_name[level], other_free * page_k, other_file * page_k,
(long)lowmem_minfree[lowmem_targets_size - 1] * page_k);
}
return;
}
goto do_kill;
}
//对于没有配置use_minfree_levels的情况,内存压力low时会调用record_low_pressure_levels,记录low等级时,
if (level == VMPRESS_LEVEL_LOW) {
record_low_pressure_levels(&mi); //这里主要是赋值low_pressure_mem.min_nr_free_pages low_pressure_mem.max_nr_free_pages
}
if (level_oomadj[level] > OOM_SCORE_ADJ_MAX) {//大于1000不考虑
/* Do not monitor this pressure level */
return;
}
// 当前memory使用情况,不含swap
if ((mem_usage = get_memory_usage(&mem_usage_file_data)) < 0) {//"/dev/memcg/memory.usage_in_bytes"
goto do_kill;
}
// 当前memory使用情况,含swap
if ((memsw_usage = get_memory_usage(&memsw_usage_file_data)) < 0) {//"/dev/memcg/memory.memsw.usage_in_bytes"
goto do_kill;
}
// Calculate percent for swappinness.
// 这个指标类似于swapness,值越大,swap使用越少,剩余swap空间越大
mem_pressure = (mem_usage * 100) / memsw_usage;
if (enable_pressure_upgrade && level != VMPRESS_LEVEL_CRITICAL) {//ro.lmk.critical_upgrade
// We are swapping too much.
// 指标偏小说明swap使用很厉害,但仍然内存压力很大
// 提高level,杀得更激进
if (mem_pressure < upgrade_pressure) { //ro.lmk.upgrade_pressure 代码default100 我的设备35
level = upgrade_level(level); //升级vmpressure level
if (debug_process_killing) {
ALOGI("Event upgraded to %s", level_name[level]);
}
}
}
// If we still have enough swap space available, check if we want to
// ignore/downgrade pressure events.
// swap_free_low_percentage为swap低阈值 此时swap空间还没到低阈值,有可操作空间
if (mi.field.free_swap >=
mi.field.total_swap * swap_free_low_percentage / 100) {
//ro.lmk.swap_free_low_percentage 10或者15
// If the pressure is larger than downgrade_pressure lmk will not
// kill any process, since enough memory is available.
if (mem_pressure > downgrade_pressure) {// 虽然有内存压力警报,但是swap还是足够的,不杀进程
if (debug_process_killing) {
ALOGI("Ignore %s memory pressure", level_name[level]);
}
return;
} else if (level == VMPRESS_LEVEL_CRITICAL && mem_pressure > upgrade_pressure) {
if (debug_process_killing) {
ALOGI("Downgrade critical memory pressure");
}//swap空间足够的话,只有mem_pressure压力足够大,才会杀得更激进
// Downgrade event, since enough memory available.
level = downgrade_level(level);
}
}
do_kill:
if (low_ram_device) {//如果是低内存设备
/* For Go devices kill only one task */
if (find_and_kill_process(level_oomadj[level], NULL, &mi, &wi, &curr_tm) == 0) {
if (debug_process_killing) {
ALOGI("Nothing to kill");
}
}
} else {
int pages_freed;
static struct timespec last_report_tm;
static unsigned long report_skip_count = 0;
if (!use_minfree_levels) {
//高版本设备一般不会走到这,只有用vmpressure策略并且不用use_minfree_levels
/* Free up enough memory to downgrate the memory pressure to low level */
if (mi.field.nr_free_pages >= low_pressure_mem.max_nr_free_pages) {
if (debug_process_killing) {
ALOGI("Ignoring pressure since more memory is "
"available (%" PRId64 ") than watermark (%" PRId64 ")",
mi.field.nr_free_pages, low_pressure_mem.max_nr_free_pages);
}
return;
}
min_score_adj = level_oomadj[level];
}
//最终进程被杀
pages_freed = find_and_kill_process(min_score_adj, NULL, &mi, &wi, &curr_tm);
···
/* Log whenever we kill or when report rate limit allows */
if (use_minfree_levels) {
ALOGI("Reclaimed %ldkB, cache(%ldkB) and free(%" PRId64 "kB)-reserved(%" PRId64 "kB) "
"below min(%ldkB) for oom_score_adj %d",
pages_freed * page_k,
other_file * page_k, mi.field.nr_free_pages * page_k,
zi.totalreserve_pages * page_k,
minfree * page_k, min_score_adj);
} else {
ALOGI("Reclaimed %ldkB at oom_score_adj %d", pages_freed * page_k, min_score_adj);
}
}2.1.1.3 mp_event_psi和mp_event_common区别
1:mp_event_psi主要基于zoneinfo的水位线方式判断内存状态,mp_event_common主要检测2:meminfo中的free memory大小。
3:mp_event_psi会计算thrashing和swap使用情况,mp_event_common主要检测vmpressure级别。
4:mp_event_psi有定期轮询逻辑, mp_event_common仅在收到事件时触发。
5:mp_event_psi会更细致地判断不同内存压力场景,mp_event_common较简单直接。
6:mp_event_psi自身就可以完成整个判断和杀进程流程,mp_event_common仅完成内存判断后交给上层管理杀进程。
7:mp_event_psi可以动态调整轮询间隔,mp_event_common没有这方面逻辑。
8:mp_event_psi记录更多调试统计信息。
2.2 find_and_kill_process
find_and_kill_process函数的作用是在大于等于min_score_adj的范围内,选择合适的进程进行查杀。
js
static int find_and_kill_process(int min_score_adj, struct kill_info *ki, union meminfo *mi, struct wakeup_info *wi, struct timespec *tm, struct psi_data *pd) {
int i;
int killed_size = 0;
int multi_killed_size = 0;
bool lmk_state_change_start = false;
bool choose_heaviest_task = kill_heaviest_task;
// 从 1000 开始循环
for (i = OOM_SCORE_ADJ_MAX; i >= min_score_adj; i--) {
struct proc *procp;
if (!choose_heaviest_task && i <= PERCEPTIBLE_APP_ADJ && is_kill_heaviest_task_enabled()) {
/*
* If we have to choose a perceptible process, choose the heaviest one to
* hopefully minimize the number of victims.
如果我们必须选择一个可感知的进程(adj<=200),就选择最严重的一个,来尽量避免查杀过多的进程。
*/
choose_heaviest_task = true;
}
while (true) {
procp = choose_heaviest_task ? proc_get_heaviest(i) : (is_lmkd_whitelist_enabled() ? proc_adj_lru_skip(i) : proc_adj_tail(i));/ 在adj==i的进程中找"最严重的"或末尾的
if (!procp)
break;
killed_size = kill_one_process(procp, min_score_adj, ki, mi, wi, tm, pd);
if (killed_size >= 0) {
if(!is_multi_kill_enable()) {
break;
} else {
multi_killed_size += killed_size;
if (strstr(ki->kill_desc, "<do fast kill>")){
if (is_fastkill_finish(multi_killed_size, fast_kill_mem)) {
goto fast_kill_finished;
}
}
}
}
}
// 有进程查杀发生时,不再继续查杀更低adj的进程
if (!is_multi_kill_enable() && killed_size) {
break;
}
fast_kill_finished:
if (is_multi_kill_enable()) {
disable_multi_kill();
}
if (killed_size > 0) {
trigger_enhance_meminfo(i);
}
return killed_size;
}