一、题目
预测提供的新闻数据属于哪个类别。
二、数据
数据为新闻文本,并按照字符级别进行匿名处理。整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐的文本数据。
数据由以下几个部分构成:训练集20w条样本,测试集A包括5w条样本,测试集B包括5w条样本。 处理后的训练数据如下:
| label | text |
|---|---|
| 6 | 57 44 66 56 2 3 3 37 5 41 9 57 44 47 45 33 13 63 58 31 17 47 0 1 1 69 26 60 62 15 21 12 49 18 38 20 50 23 57 44 45 33 25 28 47 22 52 35 30 14 24 69 54 7 48 19 11 51 16 43 26 34 53 27 64 8 4 42 36 46 65 69 29 39 15 37 57 44 45 33 69 54 7 25 40 35 30 66 56 47 55 69 61 10 60 42 36 46 65 37 5 41 32 67 6 59 47 0 1 1 68 |
在数据集中标签的对应的关系如下:
arduino
{'科技': 0, '股票': 1, '体育': 2, '娱乐': 3, '时政': 4, '社会': 5, '教育': 6, '财经': 7, '家居': 8, '游戏': 9, '房产': 10, '时尚': 11, '彩票': 12, '星座': 13}赛题数据来源为互联网上的新闻,通过收集并匿名处理得到。
三、 评测标准
评价标准为类别f1_score的均值,结果与实际测试集的类别进行对比,结果越大越好。
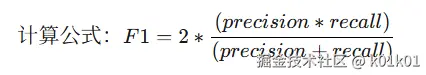
可以通过sklearn完成f1_score计算:
ini
from sklearn.metrics import f1_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
f1_score(y_true, y_pred, average='macro')四、代码
ini
# 读取数据
print("读取数据...")
train_df = pd.read_csv('data/train_set.csv', sep='\t')
test_df = pd.read_csv('data/test_a.csv', sep='\t')
# 查看数据基本信息
print(f"训练集大小: {train_df.shape}")
print(f"测试集大小: {test_df.shape}")
print(f"训练集列名: {train_df.columns.tolist()}")
print(f"训练集标签分布:\n{train_df['label'].value_counts()}")
# 特征工程:使用TF-IDF向量化文本
print("文本向量化...")
vectorizer = TfidfVectorizer(max_features=10000, ngram_range=(1, 2))
X_train = vectorizer.fit_transform(train_df['text'])
X_test = vectorizer.transform(test_df['text'])
y_train = train_df['label']
# 划分训练集和验证集
X_train_split, X_val_split, y_train_split, y_val_split = train_test_split(
X_train, y_train, test_size=0.2, random_state=42, stratify=y_train
)
# 模型调参和训练
print("训练模型...")
# 模型1: 逻辑回归
model1 = LogisticRegression(random_state=42, max_iter=1000)
model1.fit(X_train_split, y_train_split)
# 模型2: 随机森林
model2 = RandomForestClassifier(n_estimators=100, random_state=42)
model2.fit(X_train_split, y_train_split)
# 模型3: 朴素贝叶斯
model3 = MultinomialNB()
model3.fit(X_train_split, y_train_split)
# 验证模型
print("验证模型...")
y_val_pred1 = model1.predict(X_val_split)
y_val_pred2 = model2.predict(X_val_split)
y_val_pred3 = model3.predict(X_val_split)
f1_1 = f1_score(y_val_split, y_val_pred1, average='macro')
f1_2 = f1_score(y_val_split, y_val_pred2, average='macro')
f1_3 = f1_score(y_val_split, y_val_pred3, average='macro')
print(f"逻辑回归模型F1得分: {f1_1}")
print(f"随机森林模型F1得分: {f1_2}")
print(f"朴素贝叶斯模型F1得分: {f1_3}")
# 模型融合
print("模型融合...")
# 使用加权平均进行模型融合
y_val_pred_ensemble = []
for i in range(len(y_val_pred1)):
# 根据验证集表现分配权重
weights = [f1_1, f1_2, f1_3]
weights = [w / sum(weights) for w in weights] # 归一化权重
# 统计每个类别的加权票数
votes = {}
for model_idx, pred in enumerate([y_val_pred1[i], y_val_pred2[i], y_val_pred3[i]]):
if pred not in votes:
votes[pred] = 0
votes[pred] += weights[model_idx]
# 选择得票最多的类别
ensemble_pred = max(votes, key=votes.get)
y_val_pred_ensemble.append(ensemble_pred)
f1_ensemble = f1_score(y_val_split, y_val_pred_ensemble, average='macro')
print(f"融合模型F1得分: {f1_ensemble}")
# 预测测试集
print("预测测试集...")
y_test_pred1 = model1.predict(X_test)
y_test_pred2 = model2.predict(X_test)
y_test_pred3 = model3.predict(X_test)
# 模型融合预测
y_test_pred_ensemble = []
for i in range(len(y_test_pred1)):
# 根据验证集表现分配权重
weights = [f1_1, f1_2, f1_3]
weights = [w / sum(weights) for w in weights] # 归一化权重
# 统计每个类别的加权票数
votes = {}
for model_idx, pred in enumerate([y_test_pred1[i], y_test_pred2[i], y_test_pred3[i]]):
if pred not in votes:
votes[pred] = 0
votes[pred] += weights[model_idx]
# 选择得票最多的类别
ensemble_pred = max(votes, key=votes.get)
y_test_pred_ensemble.append(ensemble_pred)
# 生成提交文件
print("生成提交文件...")
submission = pd.DataFrame({'label': y_test_pred_ensemble})
submission.to_csv('data/submission.csv', index=False)
print("完成!提交文件已保存为 data/submission.csv")代码分析
1. 数据准备与预处理
数据加载
- 使用pandas读取训练集(
train_set.csv)和测试集(test_a.csv),以制表符分隔 - 打印了数据集的基本信息,包括大小、列名和标签分布,便于初步了解数据
数据探索
- 检查了训练集的维度、列名和标签分布,这是数据探索的重要步骤
- 标签分布信息有助于识别潜在的类别不平衡问题
2. 特征工程
文本向量化
-
使用
TfidfVectorizer将原始文本转换为TF-IDF特征向量 -
关键参数设置:
max_features=10000:限制特征数量,控制维度ngram_range=(1, 2):考虑单个词和双词组合,捕捉更多上下文信息
-
分别对训练集(
fit_transform)和测试集(transform)进行转换,避免数据泄露
3. 模型训练与验证
数据集划分
-
使用
train_test_split划分训练集和验证集 -
参数设置合理:
test_size=0.2:20%数据用于验证stratify=y_train:保持标签分布一致性random_state=42:确保可重复性
模型选择与训练
实现了三种不同的分类模型:
-
逻辑回归(LogisticRegression)
- 线性模型,适合高维稀疏特征
- 设置
max_iter=1000确保收敛
-
随机森林(RandomForestClassifier)
- 集成方法,能捕捉非线性关系
- 使用100棵树(
n_estimators=100)
-
朴素贝叶斯(MultinomialNB)
- 适合文本数据的概率模型
- 计算高效,适合大规模数据
模型评估
- 使用F1分数(macro平均)作为评估指标,适合多分类问题
- 在验证集上评估各模型性能,为后续模型融合提供权重依据
4. 模型融合
加权投票融合
- 根据各模型在验证集上的F1分数分配权重
- 权重归一化处理,确保总和为1
- 对每个样本,计算各模型的加权投票结果
- 选择得票最多的类别作为最终预测
融合效果验证
- 在验证集上评估融合模型的F1分数
- 比较单模型和融合模型的性能差异
预测结果
