27M 小模型超越 o3-mini-high 和 DeepSeek-R1! 推理还不靠思维链。
2700万参数,就实现了对现有大模型的精准超车。
不用预训练补课,还不靠思维链打草稿,仅凭 1000个训练样本,就把极端数独、30x30 迷宫玩得明明白白。
最新提出的开源可复现的分层推理模型 Hierarchical Reasoning Model(下面简称 HRM),模仿大脑的分层处理与多时间尺度运作机制,克服了标准Transfomer的计算局限。
1. 核心是仿脑的双层循环模块设计
1.1 首先是分层循环模块与时间尺度分离
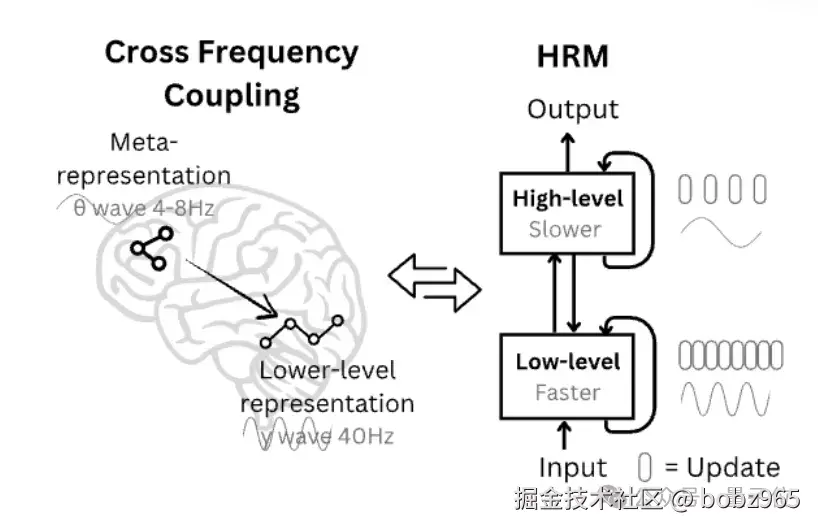
HRM 受大脑皮层区域分层处理和时间分离机制启发,设计了两个相互配合的循环模块:
- 一个高层模块负责慢节奏的抽象规划
- 一个低层模块处理快节奏的细节计算
不用明确监督中间过程,一次就能完成推理。
两者在不同时间尺度上协同工作。低阶模块在每个高阶周期内完成多次计算并达到临时稳定状态后,高阶模块才会更新决策,随后低阶模块重置并开启新一轮计算。
这种设计既保证了全局方向的正确性,又提升了局部执行的效率。
1.2 分层收敛机制
普通的循环神经网络常出现过早收敛的问题------计算几步就陷入稳定状态,后续再复杂的任务也无法推进。
而 HRM 中,低阶模块在每轮计算中会收敛到基于当前高阶状态的局部结果,但高阶模块更新后,会给低阶模块设定新的目标,使其进入新的收敛周期。
1.3 近似梯度技术
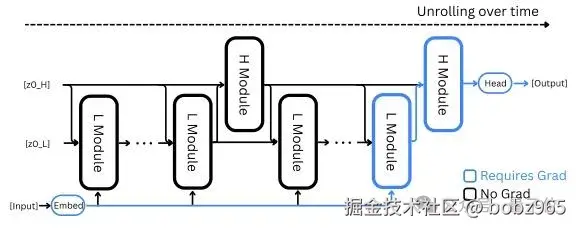
传统循环模型训练时,需要存储所有中间状态并反向追溯,类似复盘时要回看每一步操作,既耗内存又低效。
HRM 则采用一步梯度近似,只需根据最终状态反推优化方向,如同根据考试结果直接定位薄弱知识点,内存需求恒定且计算高效,更符合生物大脑的学习规律。
1.4 深度监督机制
它受大脑中神经振荡调节学习节奏的启发,引入了阶段性测试。
模型在学习过程中被分成多个阶段,每个阶段结束后立即评估并调整参数,且前后阶段的计算互不干扰。
这种方式能及时纠正偏差,就像学生每学一单元就测试巩固,比期末一次性考试的学习效果更扎实。
2. 自适应计算时间让 HRM 能像人一样灵活分配思考时间
它通过类似评估收益的算法(Q学习),动态决定是否继续计算,在保证准确率的同时避免算力浪费,推理时还能通过增加计算资源进一步提升表现。
3. 总结
在衡量 AI 通用推理能力的 ARC-AGI 挑战中,HRM 仅用 2700万参数和1000个训练样本,就达到 40.3% 的准确率,超过了参数规模更大的o3-mini-high(34.5%)和Claude 3.7 8K(21.2%)。