目录
- 一.Prometheus架构介绍
- 二.Prometheus的安装
-
- 1.基础环境
- 3.部署prometheus
- 3.访问测试
-
- [① 访问prometheus首页](#① 访问prometheus首页)
- ②查看被监控端的状态
- ③查看详细监控信息
- 三.部署node_exporter
-
- [1.被监控端安装 node_exporter](#1.被监控端安装 node_exporter)
- 2.配置prometheus
- 四.Grafana部署与应用
- 五.Prometheus告警
){kind=link}
一.Prometheus架构介绍
1.起源
Prometheus 起源于 Soundcloud ,因为微服务迅速发展,导致实例数量以几何倍数递增,不得不考虑设计一个符合以下几个功能的监控系统:
- 多维数据模型,可以按照实例,服务,端点和方法之类的维度随意对数据进行切片和切块。
- 操作简单,可以随时随地部署监控服务,甚至在本地工作站上,而无需设置分布式存储后端或重新配置环境。
- 可扩展的数据收集和分散的架构,以便于可以可靠的监控服务的许多实例,独立团队可以部署独立的监控服务。
- 转化为一种查询语言,可以利用数据模型进行有效的警报和图形展示。
但是,当时的情况是,以上的功能都分散在各个系统之中,直到 2012年 Soundcloud 某位大神启动了一个孵化项目, Soundcloud 才把所有功能集合到一起,这时也就有了 Prometheus。 Prometheus是用 Go 语言编写,从一开始就是开源的。 尽管一直很低调,一开始还是获得了很多粉丝与贡献者; 2016年 Prometheus 成为继 Kubernetes 之后,成为 CNCF(cloud Native computing Foundation)第二个成员。
2.什么是prometheus
Prometheus 具有足够的通用性,可以监控各个级别的实例:你自己的应用程序、第三方服务、主机或网络设备等等。此外 Prometheus 特别适用于监控动态云环境和 Kubernetes 云原生环境。
但是也需要注意的是 Prometheus 并不是万能的,目前并没有解决下面的一些问题:
- 日志和追踪(Prometheus 只处理指标,也称为时间序列)
- 基于机器学习或 AI 的异常检测
- 水平扩展、集群化的存储
3.Prometheus的运行原理
通过 Http 协议周期性抓取被监控组件的状态。输出被监控组件信息的 Http接口称为 exporter。常用组件大部分都有 exporter 可以直接使用,比如 haproxy,Nginx,MySQL,Linux 系统信息(磁盘内存、CPU、网络等)
4.Prometheus组件构成
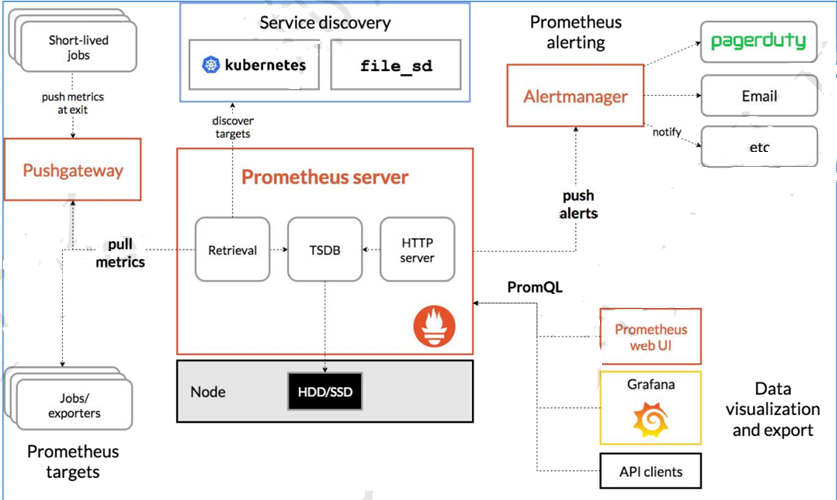
- (1)Prometheus server
服务核心组件,采用 pu11方式收集数据,通过 http 协议传输。并存储时间序列数据 - (2)Exporters/Jobs
负责收集不支持 Instrumentation 的目标对象的性能数据,并通过 HTTP 接口供 PrometheusServer 获取。 - (3)Node-Exporter
用于收集各 node 节点的物理指标状态数据,如平均负载、CPU、内存、磁盘、网络等资源信息的指标数据,需要部署到所有运算节点。 - (4)Kube-state-Metrics
为 prometheus 采集 k8s 资源数据的 exporter,通过监听 APIServer 收集 kubernetes 集群内资源对象的状态指标数据,例如 pod、deployment、service 等等。同时它也提供自己的数据,主要是资源采集个数和采集发生的异常次数统计。需要注意的是 kube-state-metrics 只是简单的提供一个metrics 数据,并不会存储这些指标数据,所以可以使用 Prometheus 来抓取这些数据然后存储,主要关注的是业务相关的一些元数据,比如 Deployment、Pod、副本状态等;调度了多少个replicas?现在可用的有几个?多少个 Pod是 running/stopped/terminated 状态?Pod 重启了多少次?有多少job 在运行中。 - (5)cadvisor
用来监控容器内部使用资源的信息,比如CPU、内存、网络 I/0、磁盘 I/0。 - (6)blackbox-exporter
监控业务容器存活性。 - (7)Service Discovery
服务发现,Prometheus 支持多种服务发现机制:文件,DNS,Consul,Kubernetes,openstack,EC2等等。基于服务发现的过程并不复杂,通过第三方提供的接口,Prometheus 查询到需要监控的Target列表,然后轮训这些 Target 获取监控数据。 - (8)Alertmanager
是一个独立的告警模块,从 Prometheus server 端接收到 alerts 后,会进行去重、分组, 并路由到相应的接收方,发出报警,常见的接收方式有:电子邮件,微信,钉钉等。 - (9)Pushgateway
类似一个中转站,Prometheus 的 server 端只会使用 pu11 方式拉取数据,但是某些节点因为某些原因只能使用 push 方式推送数据,那么它就是用来接收 push 而来的数据并暴露给 Prometheus 的server 拉取的中转站。 可以理解成目标主机可以上报短期任务的数据到 Pushgateway,然后Prometheus server 统一从Pushgateway 拉取数据 - (10)Grafana
是一个跨平台的开源的度量分析和可视化工具,可以将采集的数据可视化的展示,并及时通知给告警接收方。其官方库中具有丰富的仪表盘插件。
5.prometheus特性
- (1)提供多维度数据模型和灵活的査询语言:通过将监控指标关联多个Tag,来将监控数据进行任意维度的组合;提供 HTTP 查询接口:可以很方便的结合Grafana 等组件展示数据。
- (2)支持服务器节点的本地存储,通过 prometheus 自带的时序数据库,可以完成每秒千万级的数据存储。不仅如此,在保存大量历史数据的场景中,prometheus 还可以对接第三方时序数据库如 OpenTSDB等
- (2)支持服务器节点的本地存储,通过 prometheus 自带的时序数据库,可以完成每秒千万级的数据存储。不仅如此,在保存大量历史数据的场景中,prometheus 还可以对接第三方时序数据库如 OpenTSDB等。
- (3)定义了开放指标数据标准,以基于 HTTP 的 Pu11 方式采集时序数据,只有实现了 prometheus 监控数据格式的监控数据才可以被 prometheus 采集;并支持以 Push 方式向中间网关推送时序数据,能更灵活地应对各种监控场景。
- (4)支持通过静态文件配置和动态发现机制发现监控对象,自动完成数据采集。prometheus 目前已经支持 Kubernetes、consul 等多种服务发现机制,可以减少运维人员的手动配置环节。
- (5)支持多种多样的图表和界面展示,比如 Grafana 等。
6.Prometheus工作流程
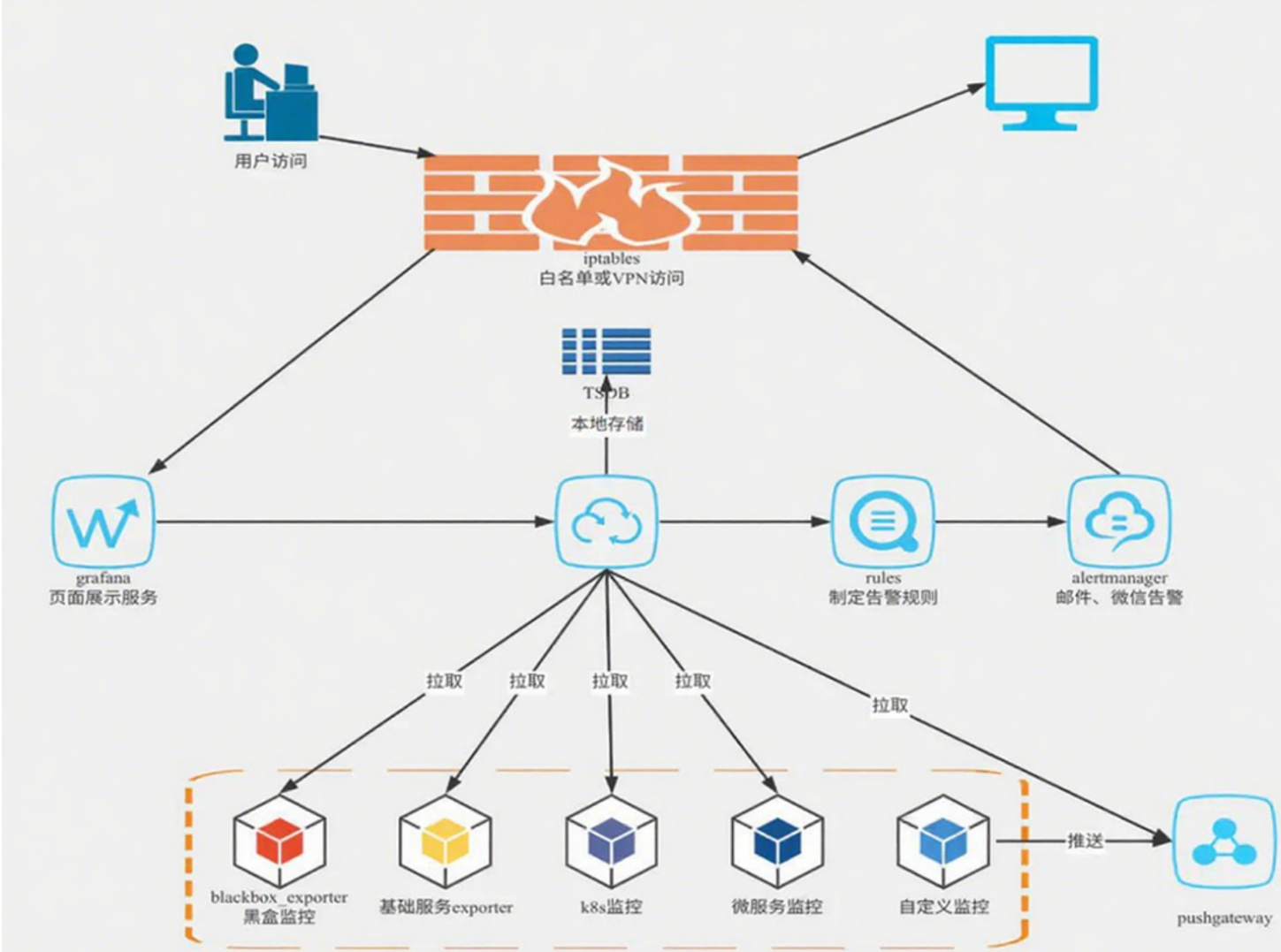
- (1)配置监控目标:在 Prometheus配置文件中定义监控目标及其相应的指标。
- (2)拉取指标数据:Prometheus 会定期从监控目标拉取指标数据,并将数据存储到本地存储中。
- (3)存储指标数据:Prometheus 会使用一种自定义的时间序列数据库(TSDB)存储指标数据,以便进行分析和查询。
- (4)分析指标数据:Prometheus 提供了一个表达式语言,可以基于时间序列数据进行数据处理和分析操作,比如计算归一化指标、统计分位数、处理异常值等。
- (5)查询指标数据:Prometheus 提供了一个基于 HTTP 的查询 API,可以用来执行査询操作和获取查询结果,获取到的查询数据可以通过图表和仪表盘的方式进行展示。
7.Grafana介绍
Grafana 是一款用 Go 语言开发的开源数据可视化工具,可以做数据监控和说几句统计,带有告警功能。其特点如下:
- ①可视化:快速和灵活的客户端图形具有多种选项,面板插件为许多不同的方式可视化指标和日志。
- ②报警:可视化地为最重要的指标定义警报规则,Granfana将持续评估他们,并发送通知。
- ③通知:警报更改状态时,他会发出通知,接受电子邮件通知。动
- ④态仪表盘:使用模板变量创建动态和可重用的仪表盘,这些模板变量作为下拉菜单出现在仪表板顶部。
- ⑤混合数据源:在同一个图中混合不同的数据源,可以根据每个查询指定数据源,这甚至适用于自定义数据源。
- ⑥注释:注释来自不同数据源图标,将鼠标悬停在事件上可以显示完整的事件元数据和标记。
- ⑦过滤器:过滤器允许您动态创建新的键~值,这些过滤器将自动应用于该数据源的所有查询
二.Prometheus的安装
1.基础环境
①关闭防火墙以及安全机制selinux
②时间同步

③修改主机名

3.部署prometheus
①Prometheus安装
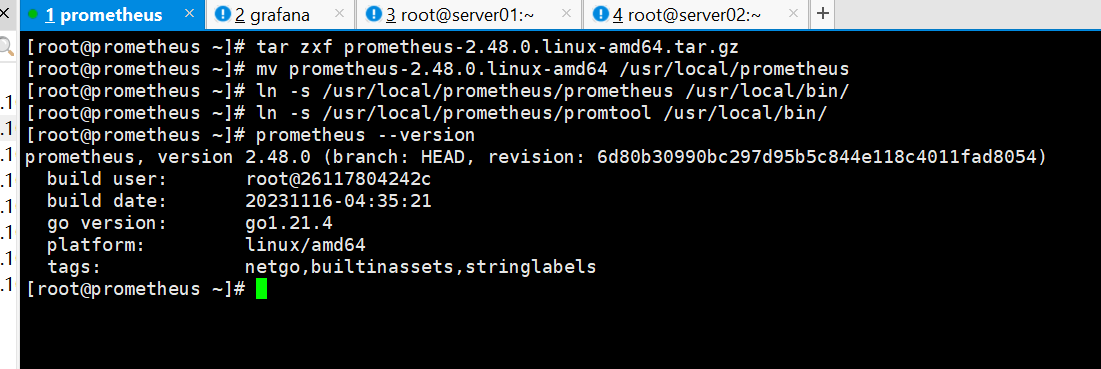
②注册Prometheus系统服务
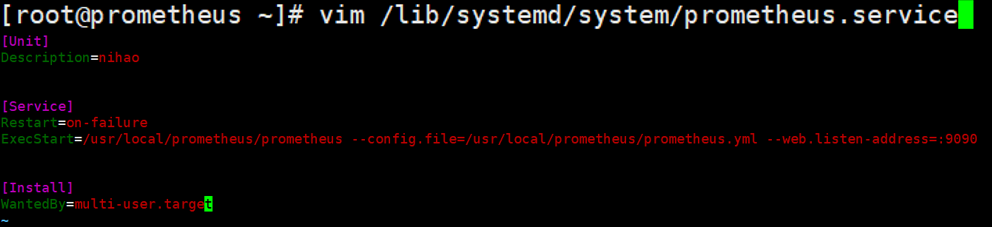
③启动服务

3.访问测试
① 访问prometheus首页
②查看被监控端的状态
点击 status 下 Targets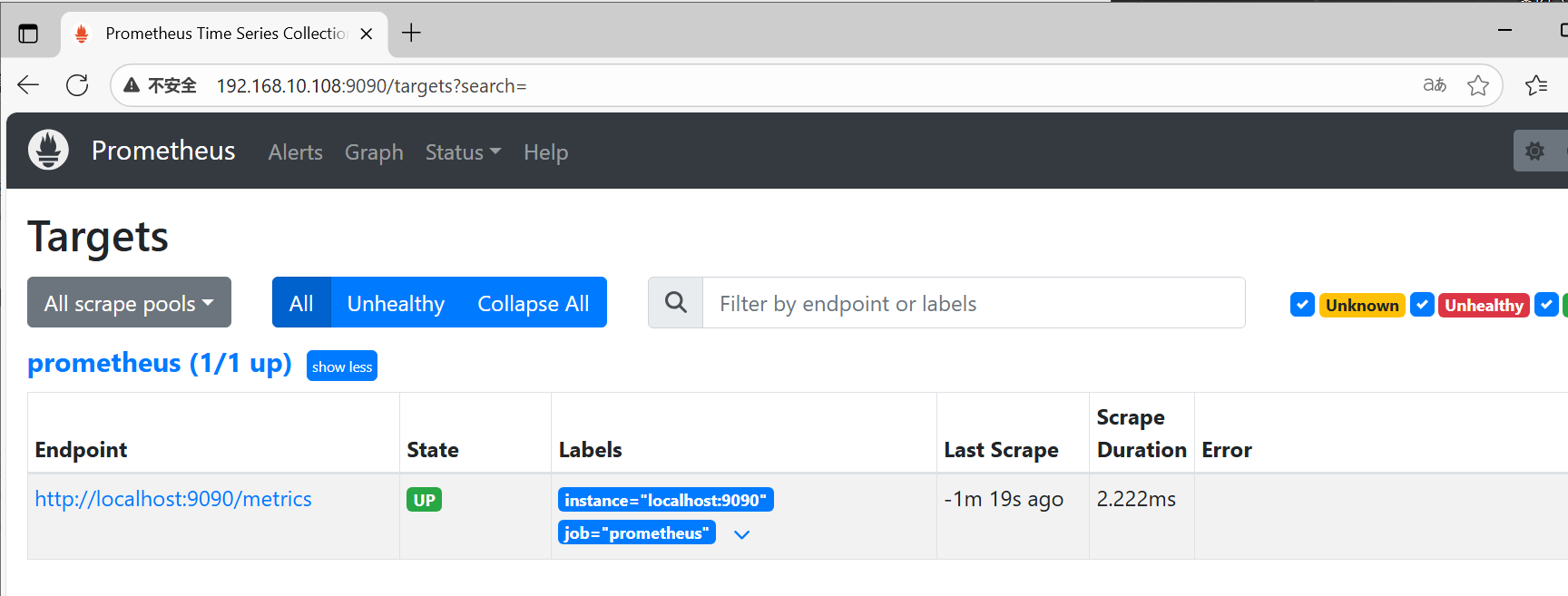
③查看详细监控信息
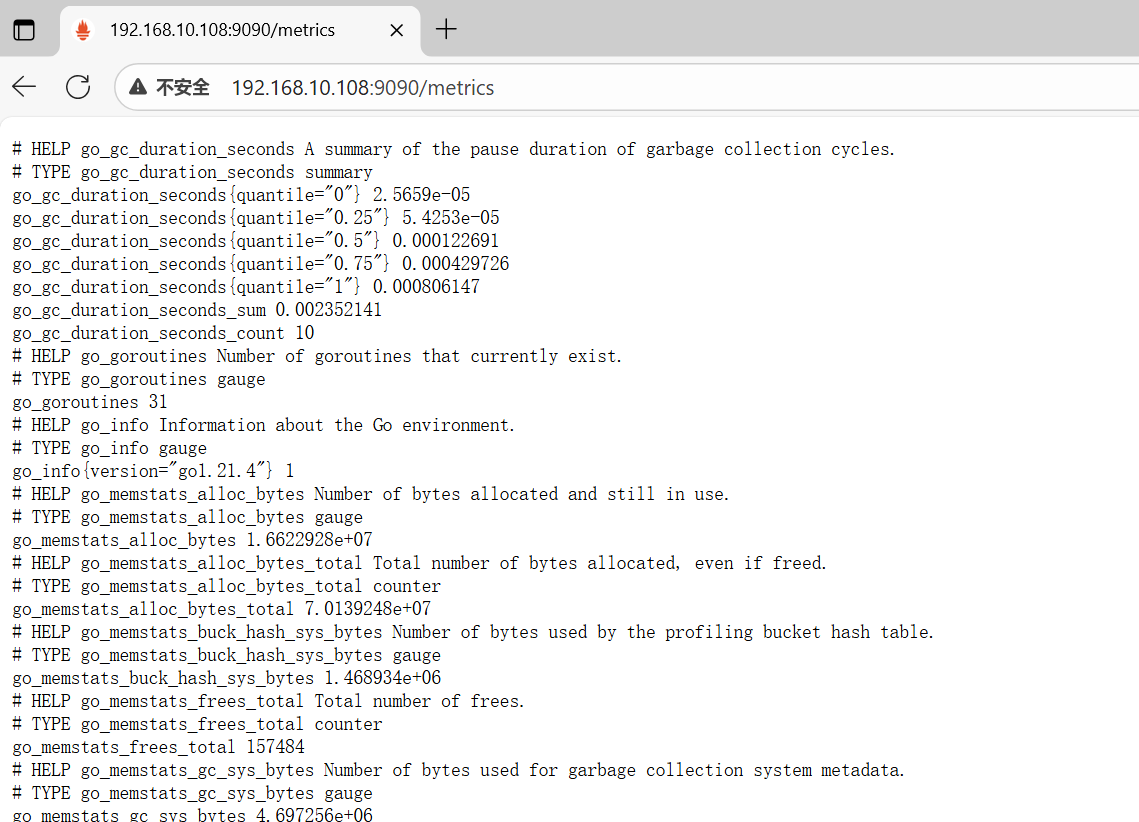
三.部署node_exporter
Exporter 是 Prometheus 的指标数据收集组件。它负责从目标 Jobs 收集数据,并把收集到的数据转和传统的指标数据收集组件不同的是,他只负责收集,并不向换为 Prometheus 支持的时序数据格式。Server 端发送数据,而是等待 Prometheus server 主动抓取,node-exporter 默认的抓取 ur1 地址:http://ip:9100/metrics
1.被监控端安装 node_exporter
①linux安装node_exporter


②windows安装node_exporter
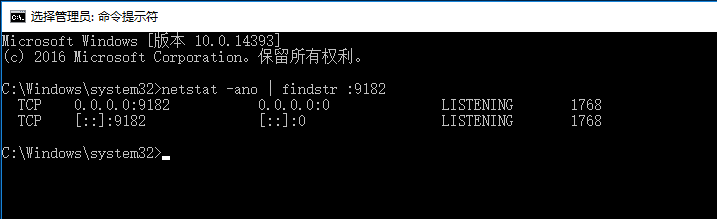
Linux 主机的exporter 进程监听的是TCP9100 端。
windows 主机的exporter 进程监听的TCP 9182 端。
2.配置prometheus
①进入Prometheus配置文件添加target

②重启Prometheus服务

重启完浏览器刷新访问 :9090,打开普罗米修斯的监控页面 status 下 Targets 查
看有没有添加成功。如下图所示。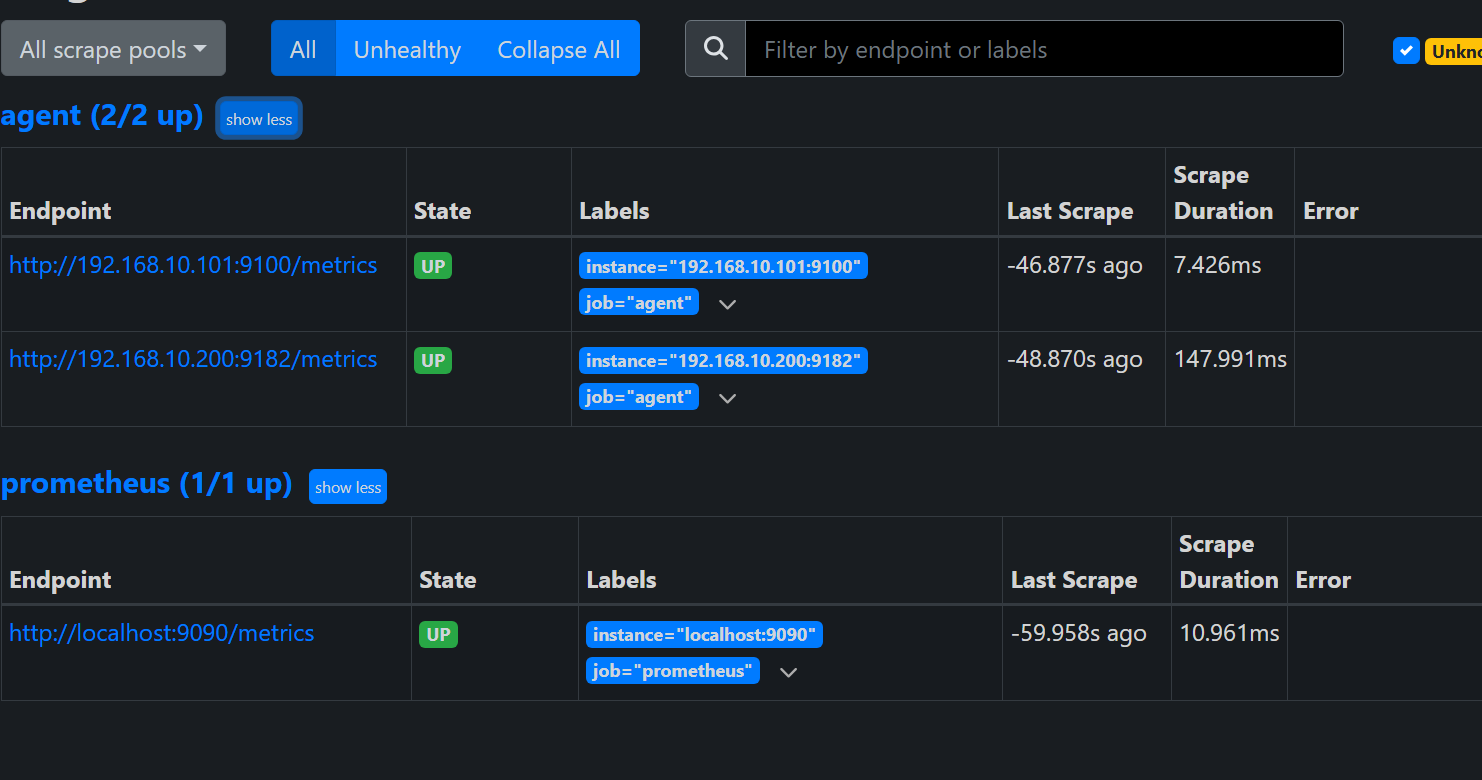
四.Grafana部署与应用
默认账号密码admin
②设置数据源
进入Grafana,点击DATA SOURCES添加数据源
③设置Prometheus为数据源
④填写连接信息
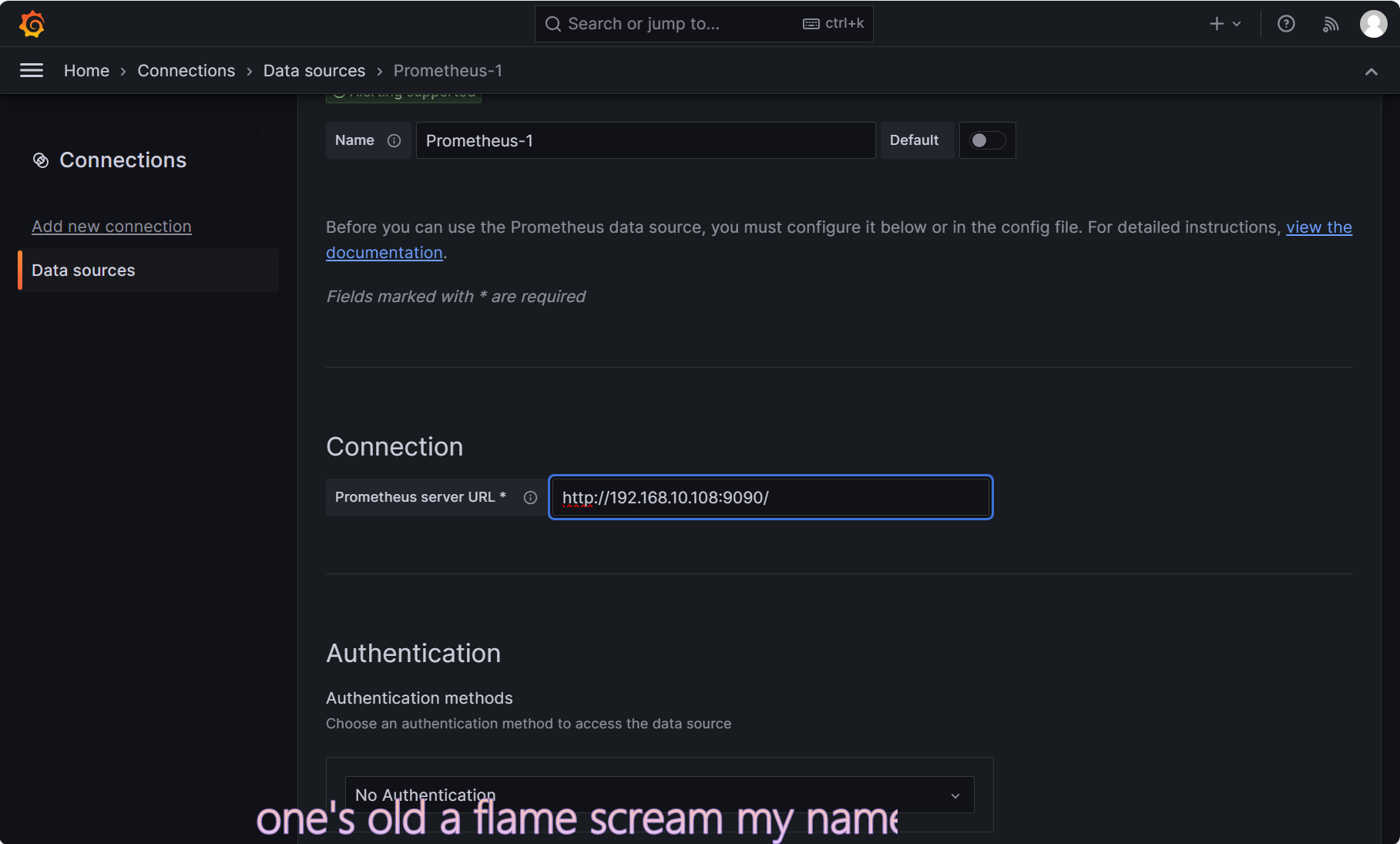
然后点击最下面的 Save & test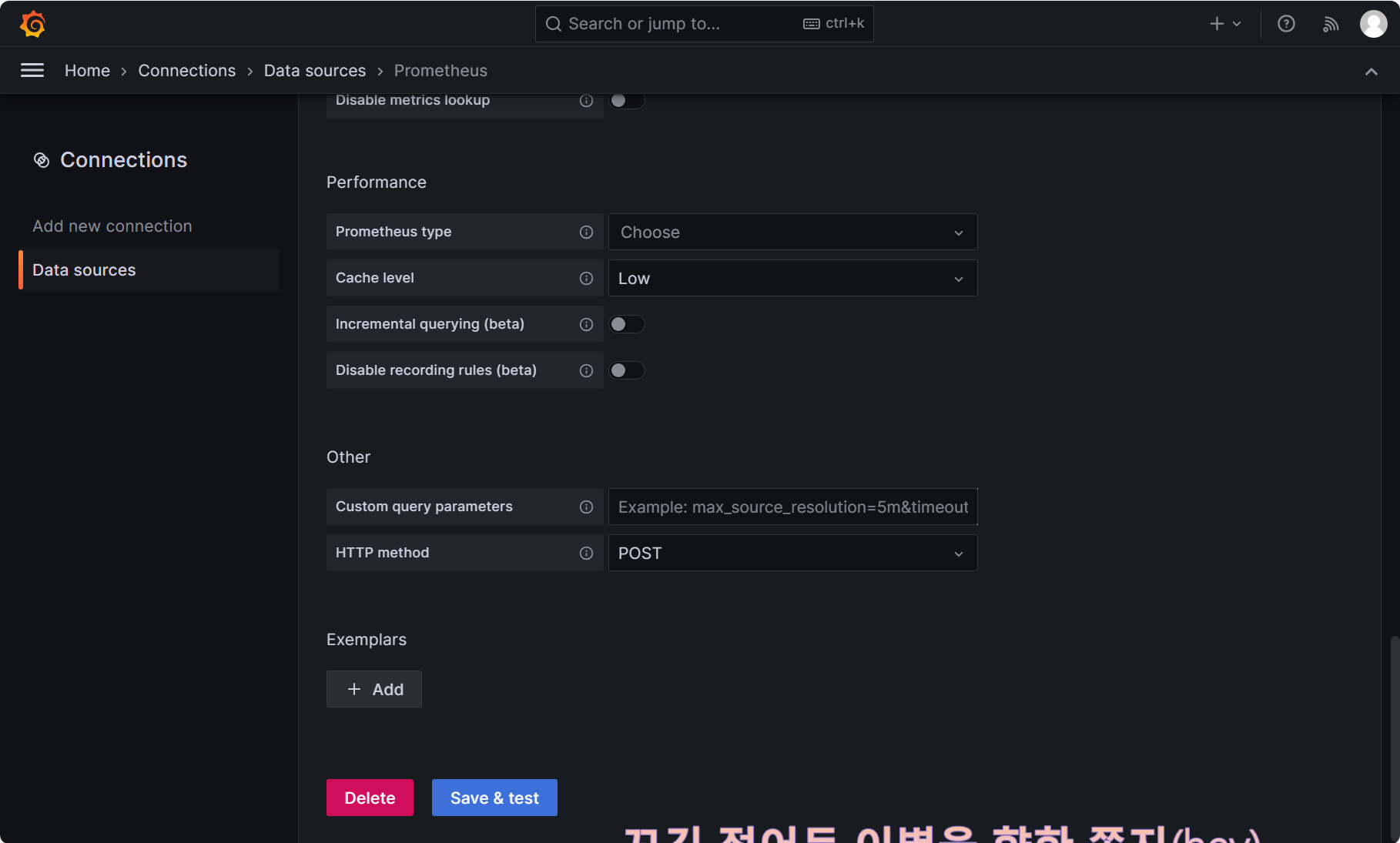
3.用导入模板方法添加Grafana监控面包
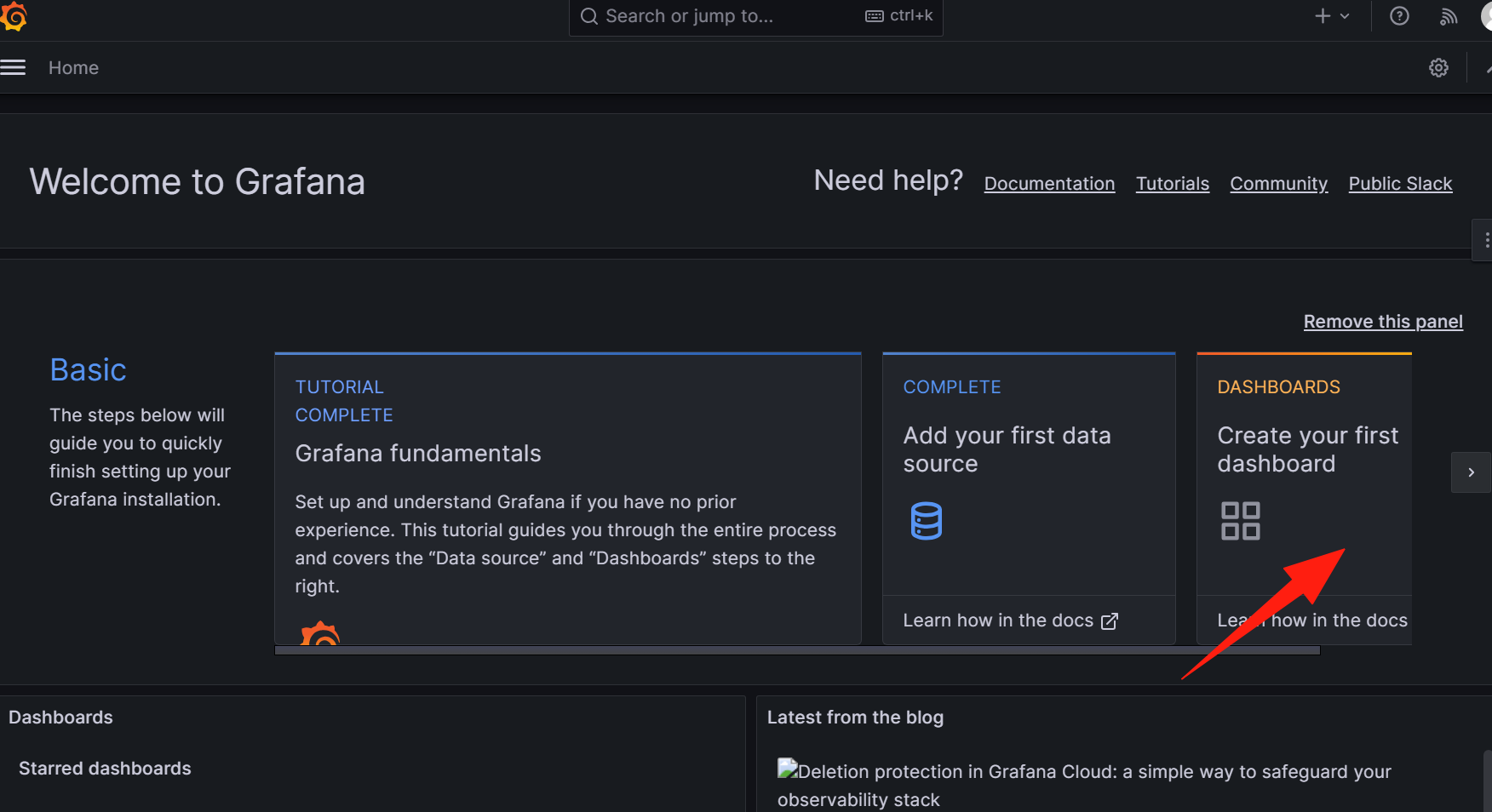
③指定模板ID
模板 ID 可以从 Grafana 官网获得,Grafana为用户提供了大量的模板,简化了用户的管理难度。本案例中使用的模板 ID 为 12633,填写好 ID 后点击"Load"按钮。https://grafana.com/grafana/dashboards/
12633:针对Linux 的节点进行监控的模板14694:针对Windows 的节点进行监控的模板用户也可以选择其他对应的模板进行创建。
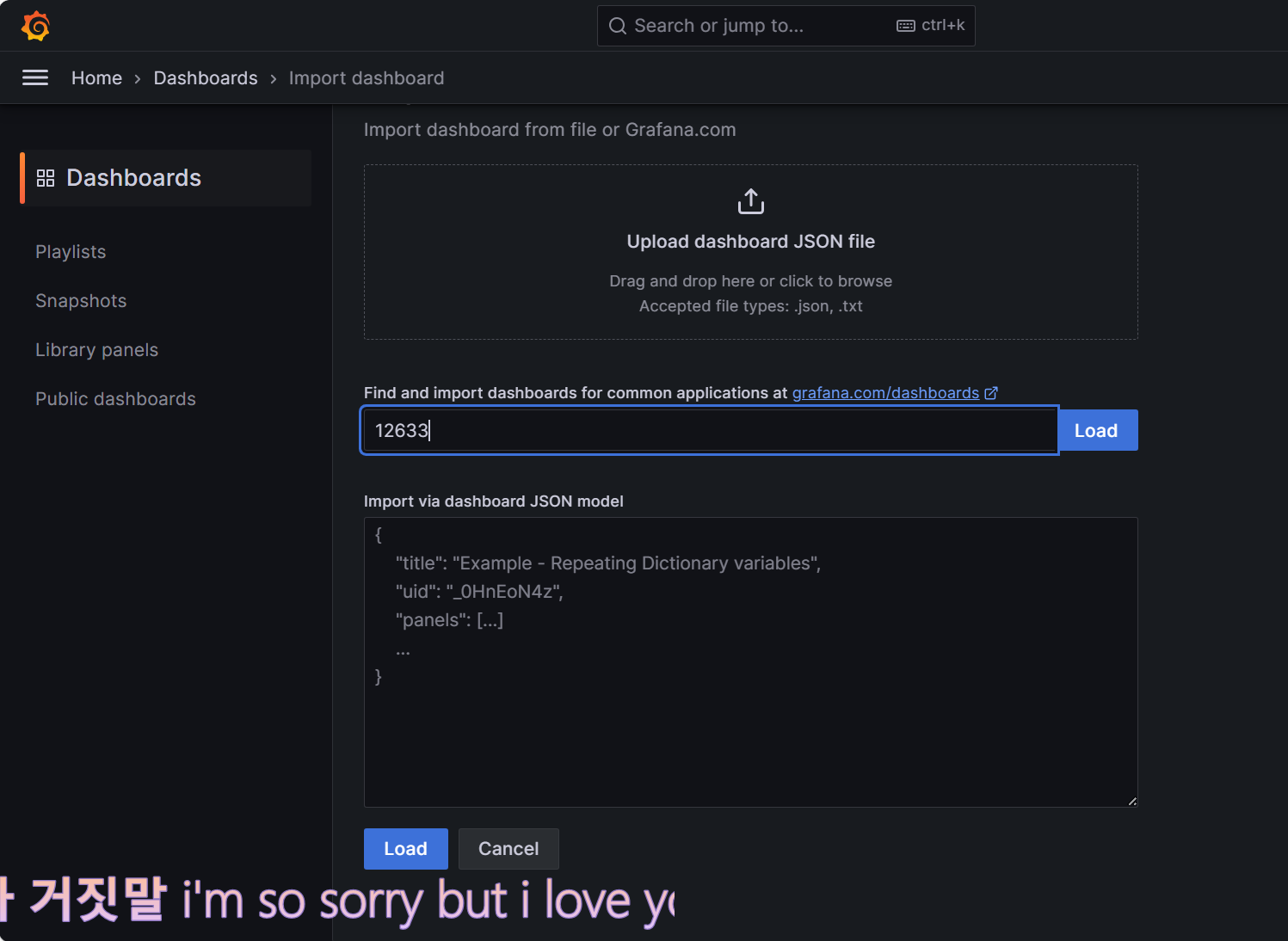
④选择数据源
在下拉菜单中选择对应的数据源,再点击"Import"按钮进行导入。
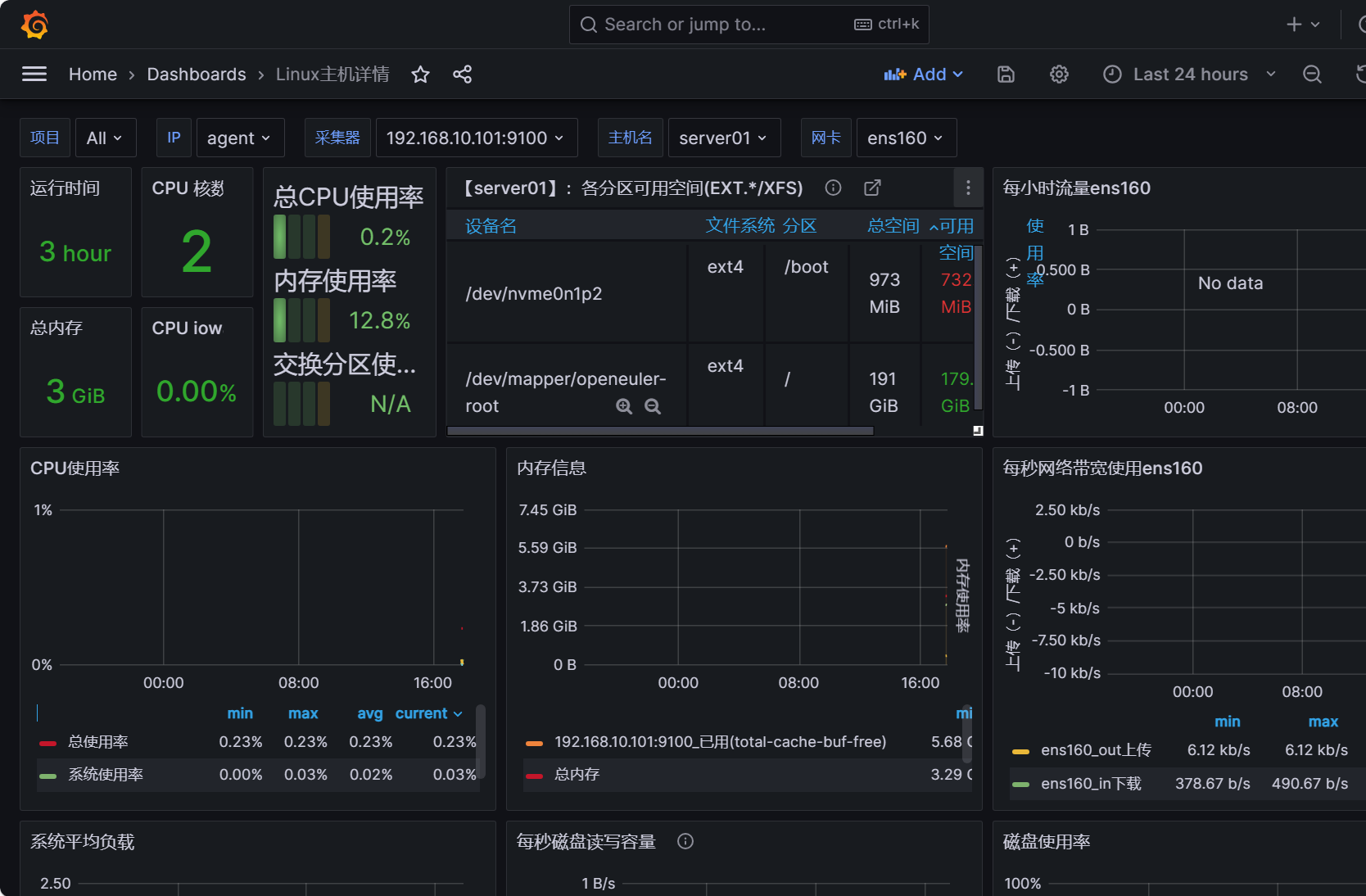
⑤导入后查看监控图像
五.Prometheus告警
1.安装告警组件alertmanager
①安装alertmanager

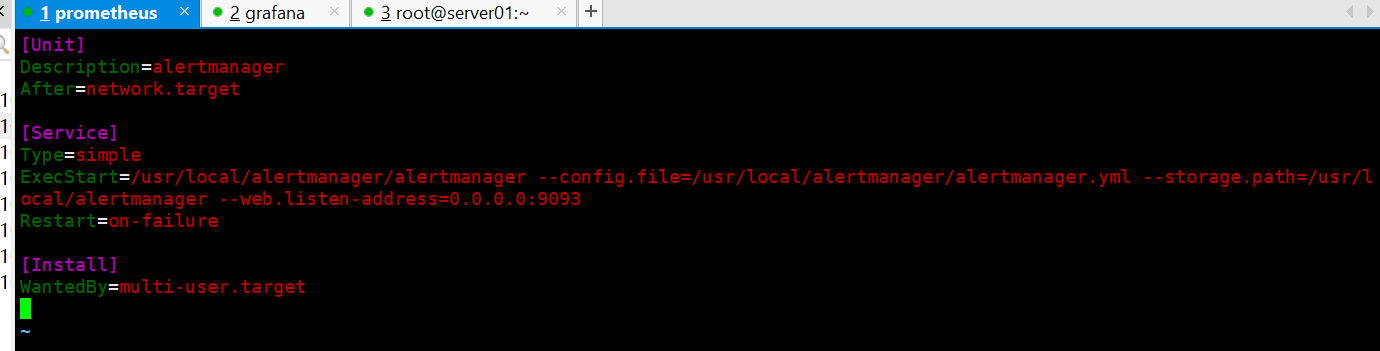
②添加alertmanager服务
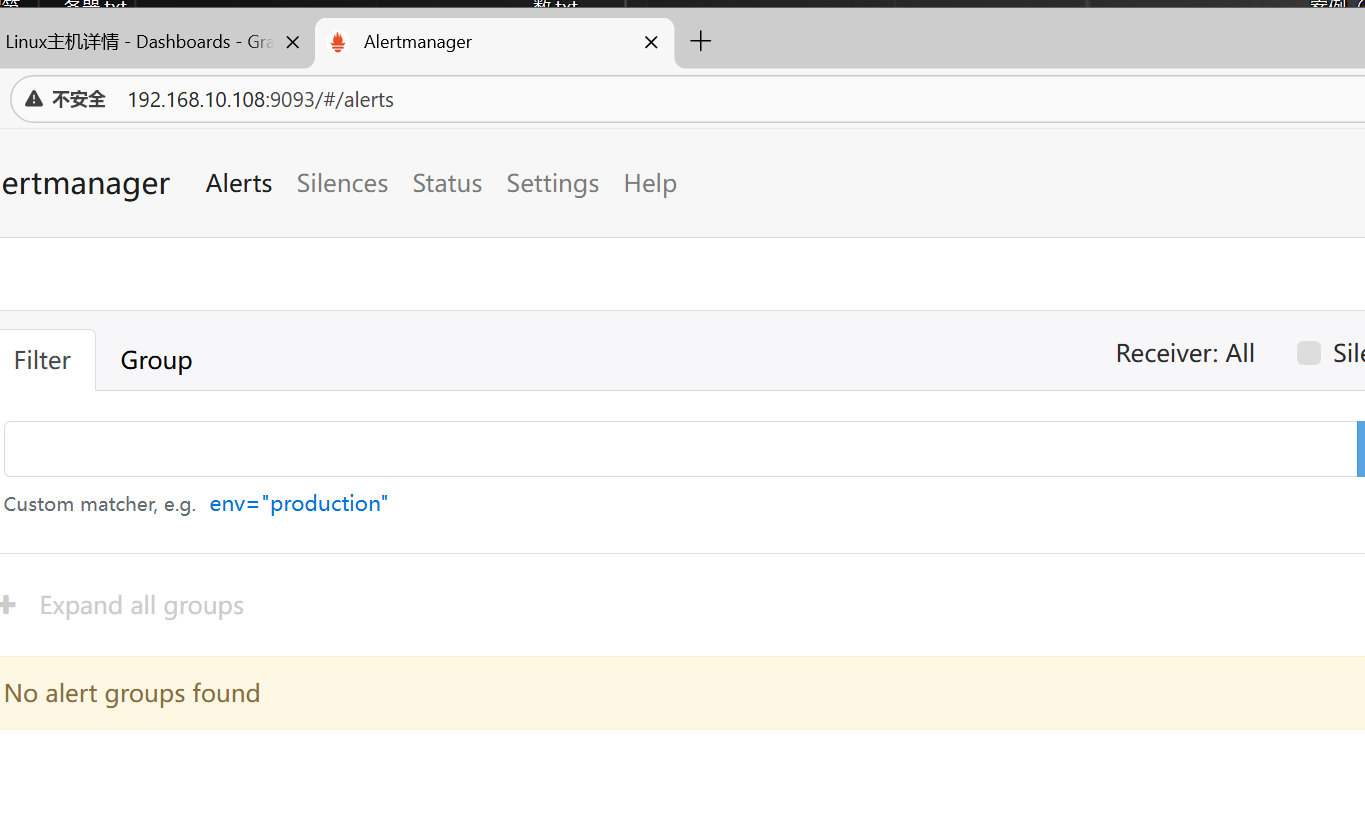
③访问alertmanager页面
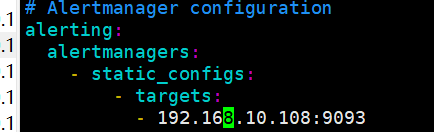
⑤将alertmanager增加到prometheus

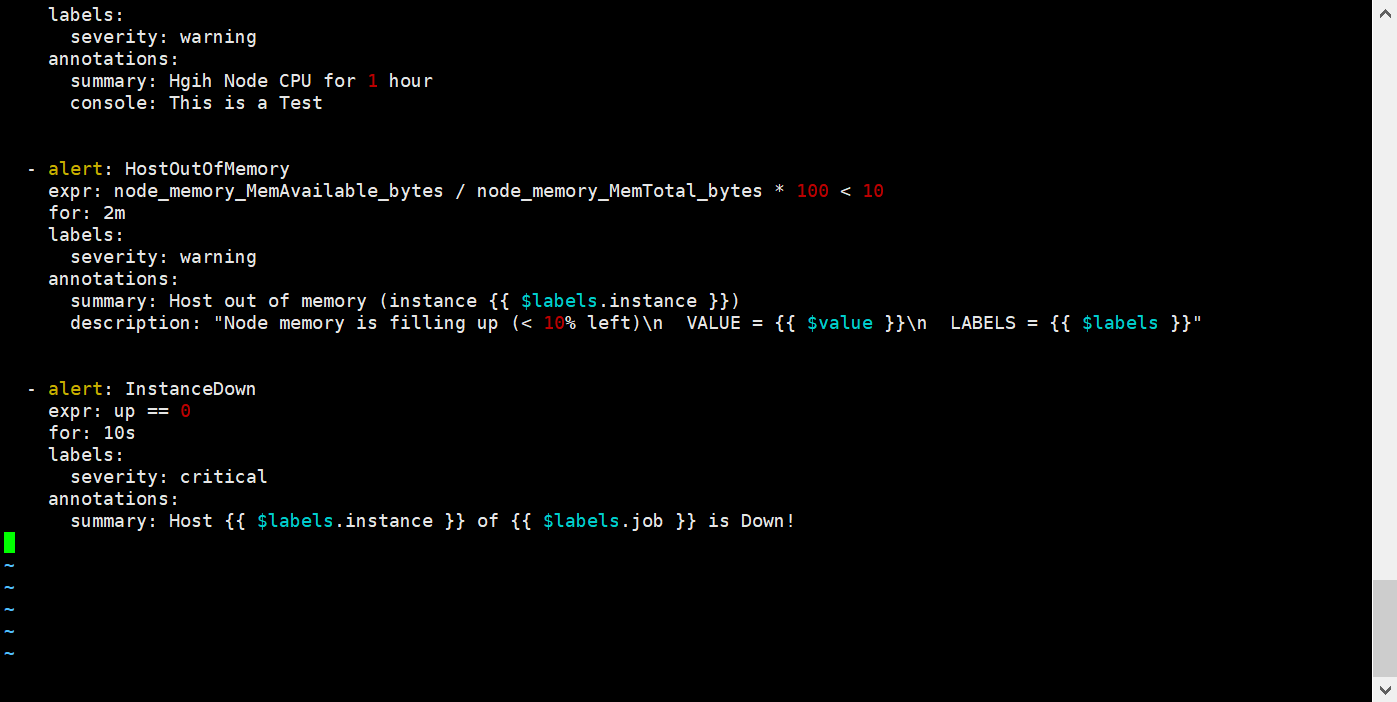
该规则文件总共添加了三条规则,第一个规则是检测 CPU负载,第二个是内存利用率的检测,第三个
是主机 down 的检测。

⑥检查prometheus配置文件语法
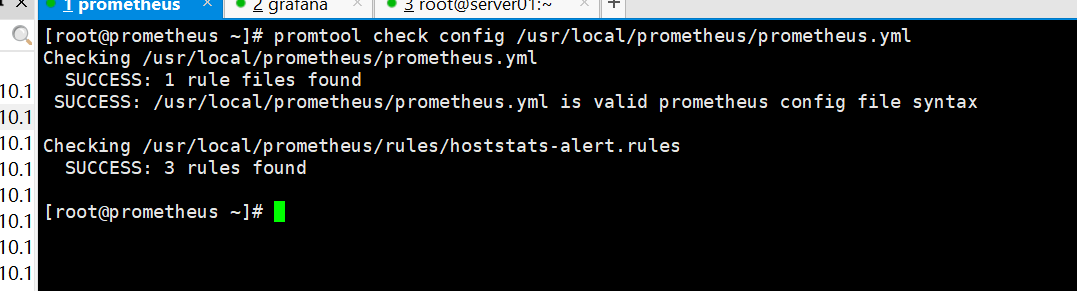
⑦重启prometheus

2.添加邮箱告警媒介

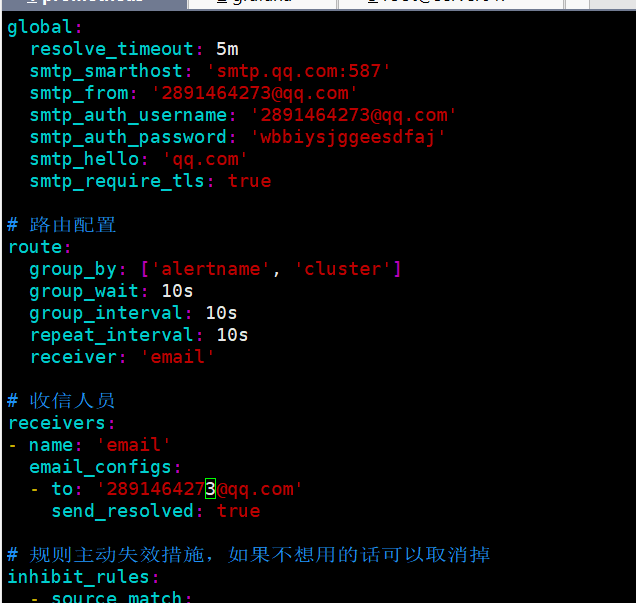
配置说明
global:
resolve timeout:5m#当告警的状态由"firing"变为"resolve"的以后还要呆多长时间,才宜布告警解除
smtp from:'xxxxxxxxxx@qq.comsmtp smarthost:'smtp.gq.com:465#qq 邮箱 smtp 端口端囗#邮箱地址smtp auth username:xxxxxxxxx@qq.com'smtp auth password:''pcmibkzsdrfefcaha#邮箱安全码smtp require tls:false
#发件人邮箱
#不携带证书请求
smtp hello:'qq.com'
#路由配置
route:
group_by:'alertname' #告警应该根据那些标签进行分组
#这里匹配的是 key,当相同标签的告警一起来的时候分为同一组#一组的告警发出前要等待多少秒,这个是为了把更多的告警一个批次发出去group wait:5s#同一组的多批次告警间隔多少秒后,才能发出#重复的告警要等待多久后才能再次发出去
group interval:5s
repeat interval:5m
receiver:"email
#指定路由到 email 的路由
#发送配置
receivers:
emailt-name :
email configs :
to:'xxxxxxxxx@qq.com
send resolved: true
(接收路由的告警)#定义谁接收告警,
#名称对应 route 中的 receiver 参数
#采用邮箱机制
#发送到那里的邮箱
#是否发送状态恢复的邮件

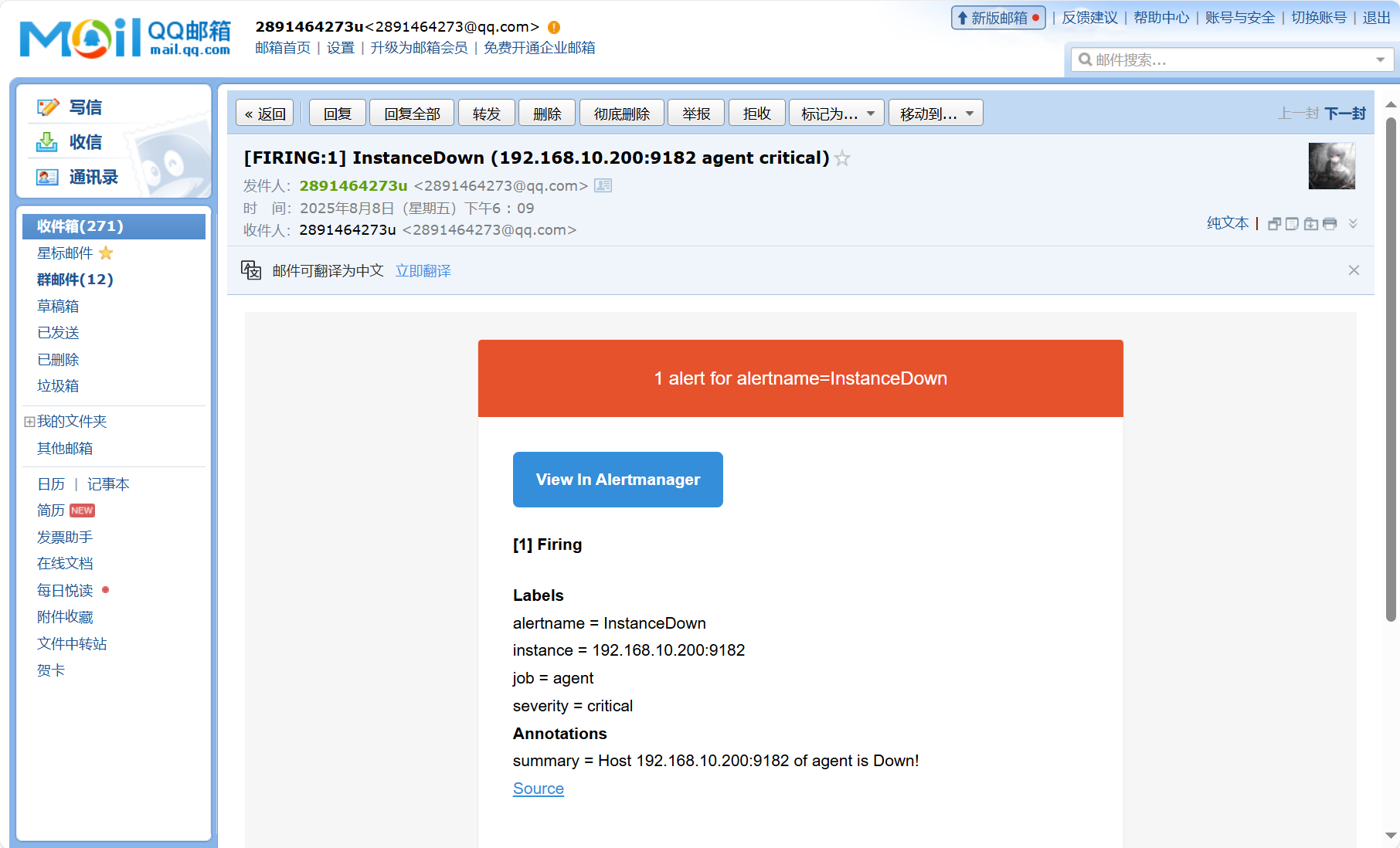
3.测试
①关闭监控节点
等待邮件