使用TensorFlow架构
2.6节介绍了用Numpy实现回归分析,2.7节介绍了用PyTorch的Autograd及Tensor实现
这个任务。这节我们将用深度学习的另一个框架,TensorFlow,实现该回归分析任务,大
家可比较一下使用不同架构之间的一些区别。为便于比较,这里使用TensorFlow的静态图
(TensorFlow2.0新增核心功能Eager Execution,并把Eager Execution变为TensorFlow默认
的执行模式。这意味着TensorFlow如同PyTorch那样,由编写静态计算图全面转向了动态
计算图)。
1)导入库及生成训练数据。
python
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
#生成训练数据
np.random.seed(100)
x = np.linspace(-1, 1, 100).reshape(100,1)
y = 3*np.power(x, 2) +2+ 0.2*np.random.rand(x.size).reshape(100,1)2)初始化参数。
python
# 运行计算图时,导入数据.
x1 = tf.placeholder(tf.float32, shape=(None, 1))
y1 = tf.placeholder(tf.float32, shape=(None, 1))
# 创建权重变量w和b,并用随机值初始化.
# TensorFlow 的变量在整个计算图保存其值.
w = tf.Variable(tf.random_uniform([1], 0, 1.0))
b = tf.Variable(tf.zeros([1]))3)实现前向传播及损失函数。
python
# 前向传播,计算预测值.
y_pred = np.power(x,2)*w + b
# 计算损失值
loss=tf.reduce_mean(tf.square(y-y_pred))
# 计算有关参数w、b关于损失函数的梯度.
grad_w, grad_b = tf.gradients(loss, [w, b])
#用梯度下降法更新参数.
# 执行计算图时给 new_w1 和new_w2 赋值
# 对TensorFlow 来说,更新参数是计算图的一部分内容
# 而PyTorch,这部分属于计算图之外.
learning_rate = 0.01
new_w = w.assign(w - learning_rate * grad_w)
new_b = b.assign(b - learning_rate * grad_b)4)训练模型。
# 已构建计算图,接下来创建TensorFlow session,准备执行计算图.
with tf.Session() as sess:
# 执行之前需要初始化变量w、b
sess.run(tf.global_variables_initializer())
for step in range(2000):
# 循环执行计算图. 每次需要把x1、y1赋给x和y.
# 每次执行计算图时,需要计算关于new_w和new_b的损失值,
# 返回numpy多维数组
loss_value, v_w, v_b = sess.run([loss, new_w, new_b],
feed_dict={x1: x, y1: y})
if step%200==0: #每200次打印一次训练结果
print("损失值、权重、偏移量分别为{:.4f},{},{}".format(loss_value,v_w,v_b))5)可视化结果。
python
# 可视化结果
plt.figure()
plt.scatter(x,y)
plt.plot (x, v_b + v_w*x**2)完整代码已经调试
python
import tensorflow as tf
import numpy as np
from matplotlib import pyplot as plt
# Disable eager execution for TF 2.x compatibility with TF 1.x code
tf.compat.v1.disable_eager_execution()
# Generate training data
np.random.seed(100)
x = np.linspace(-1, 1, 100).reshape(100, 1)
y = 3 * np.power(x, 2) + 2 + 0.2 * np.random.rand(x.size).reshape(100, 1)
# Create placeholders
x1 = tf.compat.v1.placeholder(tf.float32, shape=(None, 1))
y1 = tf.compat.v1.placeholder(tf.float32, shape=(None, 1))
# Create variables
w = tf.Variable(tf.random.uniform([1], 0, 1))
b = tf.Variable(tf.zeros([1]))
# Forward propagation
y_pred = tf.pow(x1, 2) * w + b # Use x1 here, not x
# Loss function
loss = tf.reduce_mean(tf.square(y1 - y_pred))
# Gradients
grad_w, grad_b = tf.gradients(loss, [w, b]) # Calculate gradients of loss, not y-y_pred
# Update parameters
learning_rate = 0.01
new_w = w.assign(w - learning_rate * grad_w)
new_b = b.assign(b - learning_rate * grad_b)
# Training
with tf.compat.v1.Session() as sess:
# Initialize variables
sess.run(tf.compat.v1.global_variables_initializer()) # Fixed typo in 'global_variables_initializer'
for step in range(2000):
# Run the graph
loss_value, v_w, v_b, _ = sess.run([loss, w, b, [new_w, new_b]],
feed_dict={x1: x, y1: y})
if step % 200 == 0:
print("损失值, 权重, 偏移量分别为 {:.4f}, {}, {}".format(loss_value, v_w, v_b))
# Get final values for plotting
final_w, final_b = sess.run([w, b])
# Visualization
plt.figure()
plt.scatter(x, y)
plt.plot(x, final_b + final_w * x**2)
plt.show() 运行结果
损失值, 权重, 偏移量分别为 10.0000, [0.20236146], [0.]
损失值, 权重, 偏移量分别为 0.1559, [1.7073209], [2.5402448]
损失值, 权重, 偏移量分别为 0.0818, [2.074751], [2.4366689]
损失值, 权重, 偏移量分别为 0.0440, [2.3316913], [2.341815]
损失值, 权重, 偏移量分别为 0.0244, [2.516549], [2.2733293]
损失值, 权重, 偏移量分别为 0.0142, [2.649602], [2.224032]
损失值, 权重, 偏移量分别为 0.0090, [2.7453692], [2.188551]
损失值, 权重, 偏移量分别为 0.0063, [2.8142998], [2.163012]
损失值, 权重, 偏移量分别为 0.0049, [2.863912], [2.1446302]
损失值, 权重, 偏移量分别为 0.0041, [2.8996227], [2.1313996]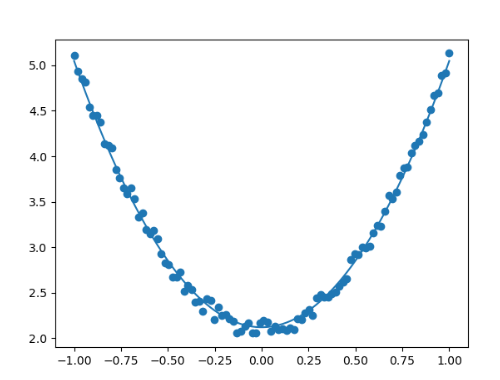
迭代2000次后,损失值达到0.0038,权重和偏移量分别为2.92、2.12,与目标值3、2是比较接近了,当然如果增加迭代次数,精度将进一步提升。大家可以尝试一下。
TensorFlow使用静态图,其特点是先构造图形(如果不显式说明,TensorFlow会自动
构建一个缺省图形),然后启动Session,执行相关程序。这个时候程序才开始运行,前
面都是铺垫,所以也没有运行结果。而PyTorch的动态图,动态的最关键的一点就是它是
交互式的,而且执行每个命令马上就可看到结果,这对训练、发现问题、纠正问题非常方
便,且其构图是一个叠加(动态)过程,期间我们可以随时添加内容。这些特征对于训练
和调试过程无疑是非常有帮助的,这或许也是PyTorch为何在高校、科研院所深得使用者
喜爱的重要原因。