前端如何解析 excel 文件?当然是用库啊 ~
Excel 解析
需求背景
目前项目中添加资源通常是一条一条手动创建的,当需要创建的资源数量很大时,非常影响用户体验:
- 每次添加都需要 打开创建弹窗 => 填写数据 => 点击保存 => 等待创建,消耗大量时间。
- 不能一次性查看全部数据,调整优先级或排序。
- 在友商配置的资源通常是批量导出到 csv 文件中,无法轻量迁移。
因此需要增加一个批量导入的功能来节省用户时间,流程如下:

使用 Sheet JS 实现
Sheet JS 官网给出的解析流程如下图所示:

- 使用
FileReader.readAsArrayBuffer读取本地文件。 - 使用
XLSX.read方法,将 ArrayBuffer 读取为 workbook。 - 使用
sheet_to_json方法转换为 JSON 数据。
ini
// 解析文件
var reader = new FileReader();
reader.onload = function(e) {
var data = e.target.result
var workbook = XLSX.read(data, { type: 'binary' });// 获取第一张表
var first_sheet_name = workbook.SheetNames[0];
var worksheet = workbook.Sheets[first_sheet_name];// 将表单数据转换为 JSON 对象
var jsonData = XLSX.utils.sheet_to_json(worksheet, { defval: "" });// 输出 JSON
};
//
reader.readAsBinaryString(f);导入 .xlsx 文件时岁月静好,当尝试导入 .csv 文件时就全部乱码了!
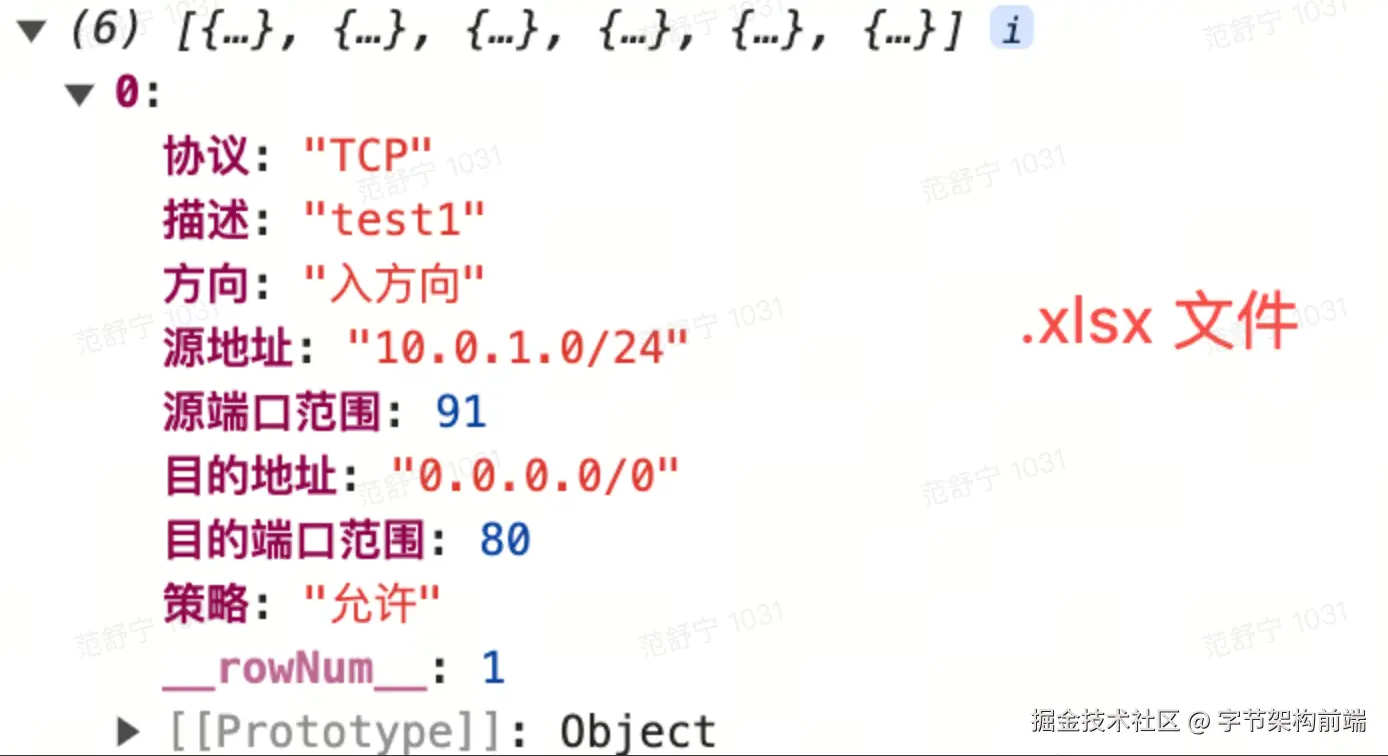
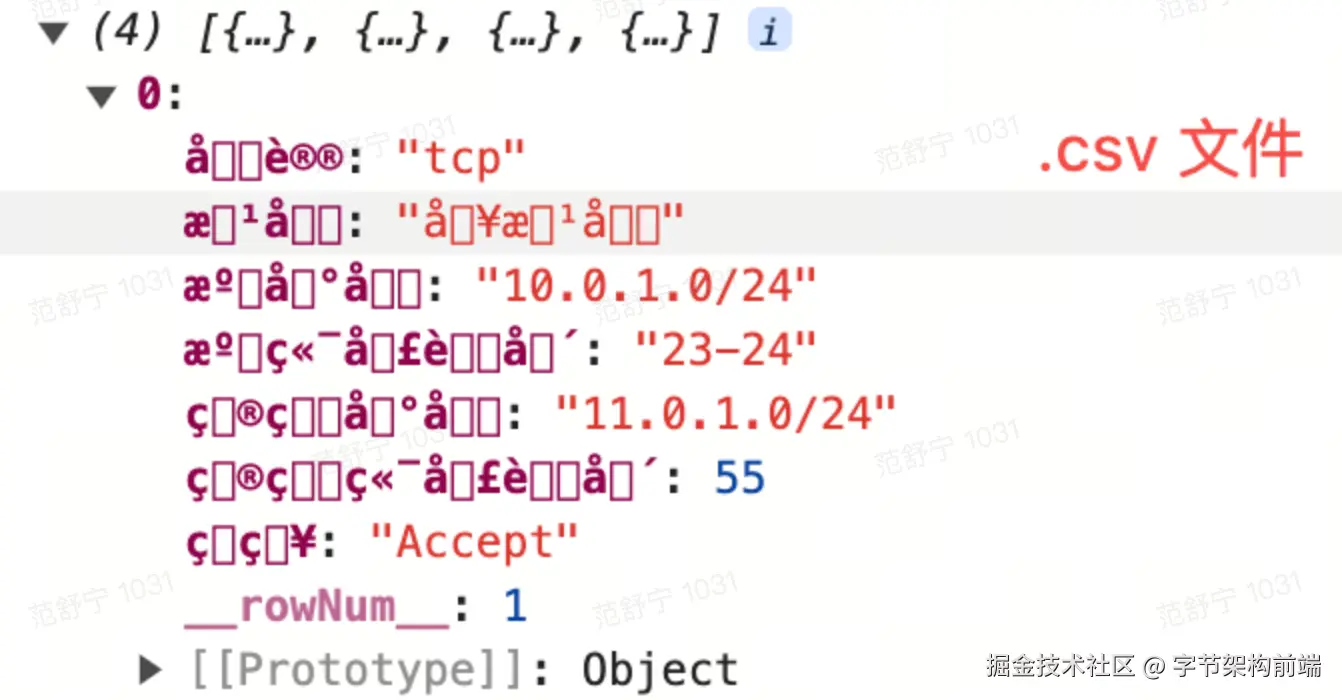
为什么 .csv 会乱码?
.csv 文件是一种纯文本文件,它的编码方式可能是 ASCII、UTF-8、GBK 或者其他。当使用不正确的编码方式去解析 .csv 文件时,中文字符可能出现乱码。而 .xlsx 文件是一种 XML-based 类型的文件,它包含了关于字符编码的信息,所以 .xlsx 文件在处理中文字符时,通常不会出现乱码。
乱码怎么办
这里我们分为三种类型:.xlsx 文件、UTF-8 编码的 .csv 文件,和非 UTF-8 编码的 .csv 文件。
首先来看一下 FileReader 中 readAsText, readAsBinaryString, readAsArrayBuffer 这三个方法的区别
-
readAsText: 这个方法是以文本形式读取指定的Blob或File对象。结果数据是以字符串(UTF-8格式)的形式返回的。这种方式适合读取纯文本文件,如.txt、.csv、.xml、.html等。 -
readAsBinaryString: 这个方法是以二进制字符串的形式读取指定的Blob或File对象,这种方法适合读取的文件类型主要有:- 图片文件:JPEG、PNG、GIF、SVG、BMP等。
- 文档文件:PDF、DOCX、PPTX、XLSX等。
- 音频和视频文件:MP3、MP4、WAV、OGG、FLAC等。
- 压缩文件:ZIP、RAR、7Z、TAR等。
- 数据库文件:例如 SQLite 数据库。
- 二进制可执行文件:EXE、DMG等。
-
readAsArrayBuffer: 是以 ArrayBuffer 的形式读取 Blob 或 File 对象,储存的是二进制数据的数值,而不是字符串或者文本,所以适合在需要进行数值处理和大量数据处理的场景中使用。比如你需要读取文件并对这个文件的数据进行修改,就可以使用该方法。
我们对这三种类型的文件使用不同的方法解析:
解析.xlsx
因为 .xlsx 是一个复杂的文件格式,它实际上是一个包含了多个 XML 文件的 ZIP 。而这些 XML 文件都是以 UTF-8 编码格式存储的。所以,在处理.xlsx文件时通常不需要担心字符编码的问题。直接用 binary string 的格式将文件读入,然后再调用 xlsx.js 来按格式解析就好。
ini
const reader = new FileReader();
reader.onload = function(event) {
const data = event.target.result;
// 以二进制形式解析
workbook = read(data, { type: 'binary' })
const firstSheet = workbook.Sheets[workbook.SheetNames[0]];
const json = utils.sheet_to_json(firstSheet);
};
// 以二进制字符串的形式读取文件
reader.readAsBinaryString(file);解析 UTF-8 编码的 .csv 文件
由于文件的内容是纯文本的,所以我们直接使用 'string' 类型来读取和解析文件即可。
ini
const reader = new FileReader();
reader.onload = function(event) {
const data = event.target.result;
// 以二进制形式解析
workbook = read(data, { type: 'string' })
const firstSheet = workbook.Sheets[workbook.SheetNames[0]];
const json = utils.sheet_to_json(firstSheet);
};
// 以二进制字符串的形式读取文件
reader.readAsText(file, 'UTF-8');解析非 UTF-8 编码的 .csv 文件(以GB-2312为例)
ini
const reader = new FileReader();
reader.onload = function(event) {
const buffer = event.target.result;
const unit8 = new Unit8Array(buffer);
// 转换为unicode
const unicodeStr = cptable.utils.decode(936, uint8Array)
workbook = read(unicodeStr, { type: 'string' })
};
// 以二进制字符串的形式读取文件
reader.readAsArrayBuffer(file, 'UTF-8');Excel 文件的编码介绍
Open XML 标准
大家是否思考过一个问题,为什么你创建了一个 excel / word 之后,既可以使用 Office 软件打开,也可以使用 WPS 打开。是因为这些文件都遵循同一套标准,叫做Microsoft Office Open XML 标准。
.xlsx 文件结构
上面提到,解析 .xlsx 文件不会乱码的原因是, .xlsx 文件包含了关于字符编码的信息。那么它是在哪里包含的呢?
比如我们有一个源文件:
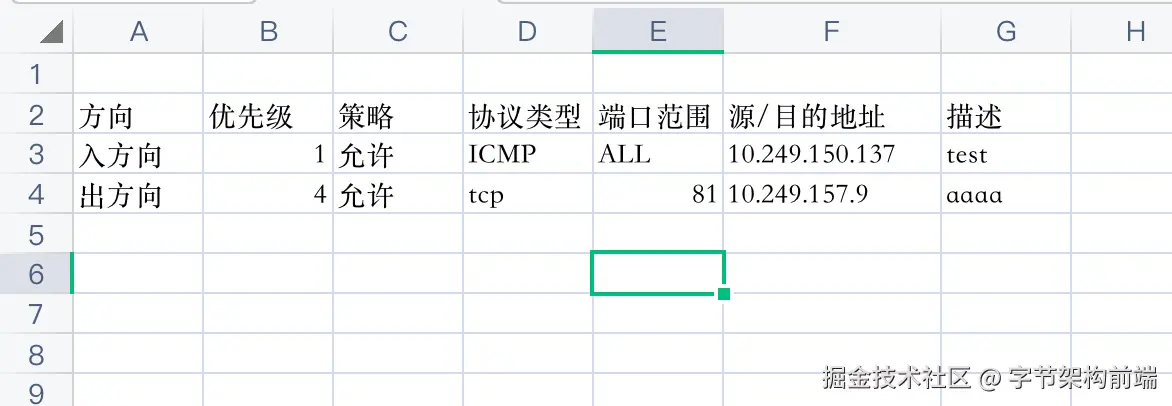
.xlsx 文件是一种基于 XML 的文件格式,通常包含多个 XML 文件和一些附加的文件,这些文件压缩成一个 .zip 文件。我们把源文件后缀改成 .zip 后解压缩,就可以得到这样一个文件夹。
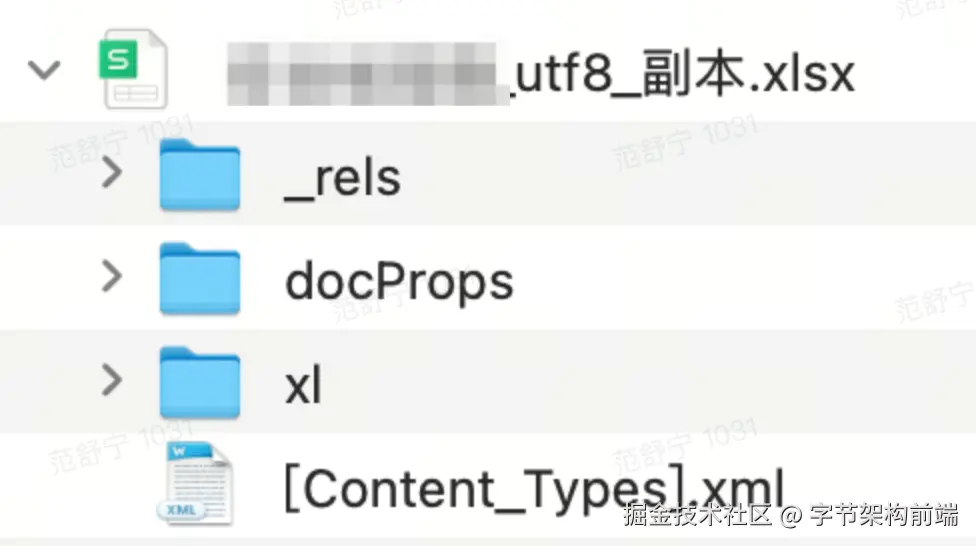
结构如下:
csharp
UTF8_副本.xlsx/
_rels/
docProps/
xl/
_rels/
theme/
worksheets/
sheet1.xml
workbook.xml
styles.xml
sharedStrings.xml
[Content_Types].xml在这些 XML 文件中,通常使用的编码是 UTF-8 或 UTF-16。在这些 XML 文件的头部可以看到表示编码格式的声明,比如:
xml
<?xml version="1.0" encoding="UTF-8"?>接下来我们来看看这些文件里写了什么东西。
Content_types.xml
Content_Types.xml 文件是一个总体资源文件列表,该文件中描述了这个 excel 文件中的 xml 资源的路径,以及遵守的规范。截取一部分内容如下:
xml
// 声明使用 UTF-8 编码
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
// ...
<Override PartName="/xl/sharedStrings.xml"
ContentType="application/vnd.openxmlformats-officedocument.spreadsheetml.sharedStrings+xml" />
<Override PartName="/xl/worksheets/sheet1.xml" ContentType="application/vnd.openxmlformats-officedocument.spreadsheetml.worksheet+xml" />
// ...PartName 属性表示某个文件的路径,ContentType 表示该文件的类型,也就是该文件遵守的规范,由 xlsx.js 解析后得到如下对象。
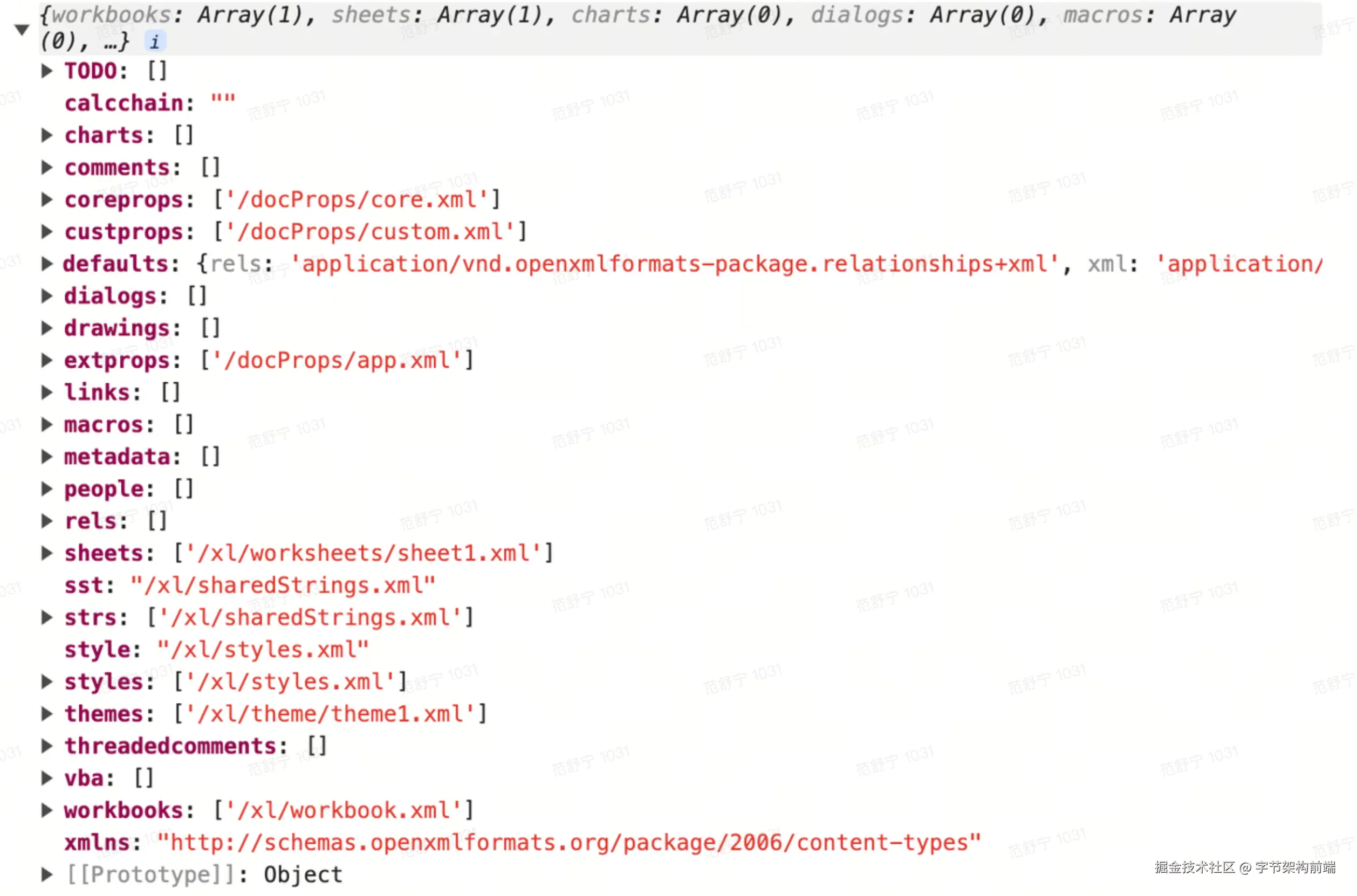
workbook.xml
这个文件用于描述 Excel 工作簿的相关属性,比如包含几个工作表(sheets),每个工作表(sheets)的外键ID。
xml
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<workbook xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main"
<sheets>
// 这里表示这个 wookbook 下有一个 sheet, id是 rId1
<sheet name="安全组规则_UTF8" sheetId="1" r:id="rId1" />
</sheets>
</workbook>workbook.xml.rels
上面的文件提到了外键 ID,这里就解析 workbook.xml.rels 文件,用于获得这个外键 ID 对应的 Sheet 的具体路径。
xml
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/worksheet"
Target="worksheets/sheet1.xml" />
</Relationships>sheet1.xml
这个文件是 sheet 的主要内容。
xml
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<worksheet xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main">
// ...
<cols>
<col min="6" max="6" width="16.2232142857143" customWidth="1" />
</cols>
// sheet 的主要内容
<sheetData>
<row r="2" spans="1:7"> // <row> 表示一行
// 这里 t = "s" 代表共享字符串,会从 sharedStrings.xml 中读取
<c r="A2" t="s"> // <c> 表示单元格。属性 r 表示单元格位置,t 代表单元格类型
<v>0</v> // <v> 表示单元格的值
</c>
<c r="B2" t="s">
<v>1</v>
</c>
<c r="C2" t="s">
<v>2</v>
</c>
<c r="D2" t="s">
<v>3</v>
</c>
<c r="E2" t="s">
<v>4</v>
</c>
<c r="F2" t="s">
<v>5</v>
</c>
<c r="G2" t="s">
<v>6</v>
</c>
</row>
<row r="3" spans="1:7">
<c r="A3" t="s">
<v>7</v>
</c>
<c r="B3">
<v>1</v>
</c>
<c r="C3" t="s">
<v>8</v>
</c>
<c r="D3" t="s">
<v>9</v>
</c>
<c r="E3" t="s">
<v>10</v>
</c>
<c r="F3" t="s">
<v>11</v>
</c>
<c r="G3" t="s">
<v>12</v>
</c>
</row>
<row r="4" spans="1:7">
<c r="A4" t="s">
<v>13</v>
</c>
<c r="B4">
<v>4</v>
</c>
<c r="C4" t="s">
<v>8</v>
</c>
<c r="D4" t="s">
<v>14</v>
</c>
<c r="E4">
<v>81</v>
</c>
<c r="F4" t="s">
<v>15</v>
</c>
<c r="G4" t="s">
<v>16</v>
</c>
</row>
</sheetData>
<pageMargins left="0.75" right="0.75" top="1" bottom="1" header="0.511805555555556" footer="0.511805555555556" />
<headerFooter />
</worksheet>t:表示内容类型,下面列出一些 t 的取值。
markdown
Type | Description
_______________________________________________
b | Boolean
e | Error,遵循特等的错误码
n | Number
d | Date
s | 共享的字符串
z | 空白在 .xlsx 文件格式中,所有的数据(数值、文本、日期等等)都被单独存储在/sharedStrings.xml文档中,而不是直接存储在各个sheet#.xml文件中。这是一种优化策略,它允许这些数据在整个工作簿中的多个位置进行重用,而无需存储多个副本,可以节省存储空间。
每个单元格在 sheet#.xml 文件中都有一个索引,该索引参考sharedStrings.xml中的一个字符串。比如有个单元格的内容是 5 ,那么指的就是sharedStrings.xml中索引为5的字符串。
所以,当你尝试直接打开并读取sheet1.xml文件时,你可能看不到直接的文本字段,而只看到这些单元格引用的字符串索引。这就是为什么即使你的表格中包含中文,你在sheet#.xml中也看不到它们的原因。你需要同时查看sharedStrings.xml文件才能看到实际的文本值。
sharedStrings.xml
结合 sharedStrings.xml 我们就能获取表格中的原始数据。
xml
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<sst xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" count="17">
<si>
<t>方向</t>
</si>
<si>
<t>优先级</t>
</si>
<si>
<t>策略</t>
</si>
<si>
<t>协议类型</t>
</si>
<si>
<t>端口范围</t>
</si>
<si>
<t>源/目的地址</t>
</si>
<si>
<t>描述</t>
</si>
<si>
<t>入方向</t>
</si>
<si>
<t>允许</t>
</si>
<si>
<t>ICMP</t>
</si>
<si>
<t>ALL</t>
</si>
<si>
<t>10.249.150.137</t>
</si>
<si>
<t>test</t>
</si>
<si>
<t>出方向</t>
</si>
<si>
<t>tcp</t>
</si>
<si>
<t>10.249.157.9</t>
</si>
<si>
<t>aaaa</t>
</si>
</sst>SheetJS 解析 .xlsx 文件过程
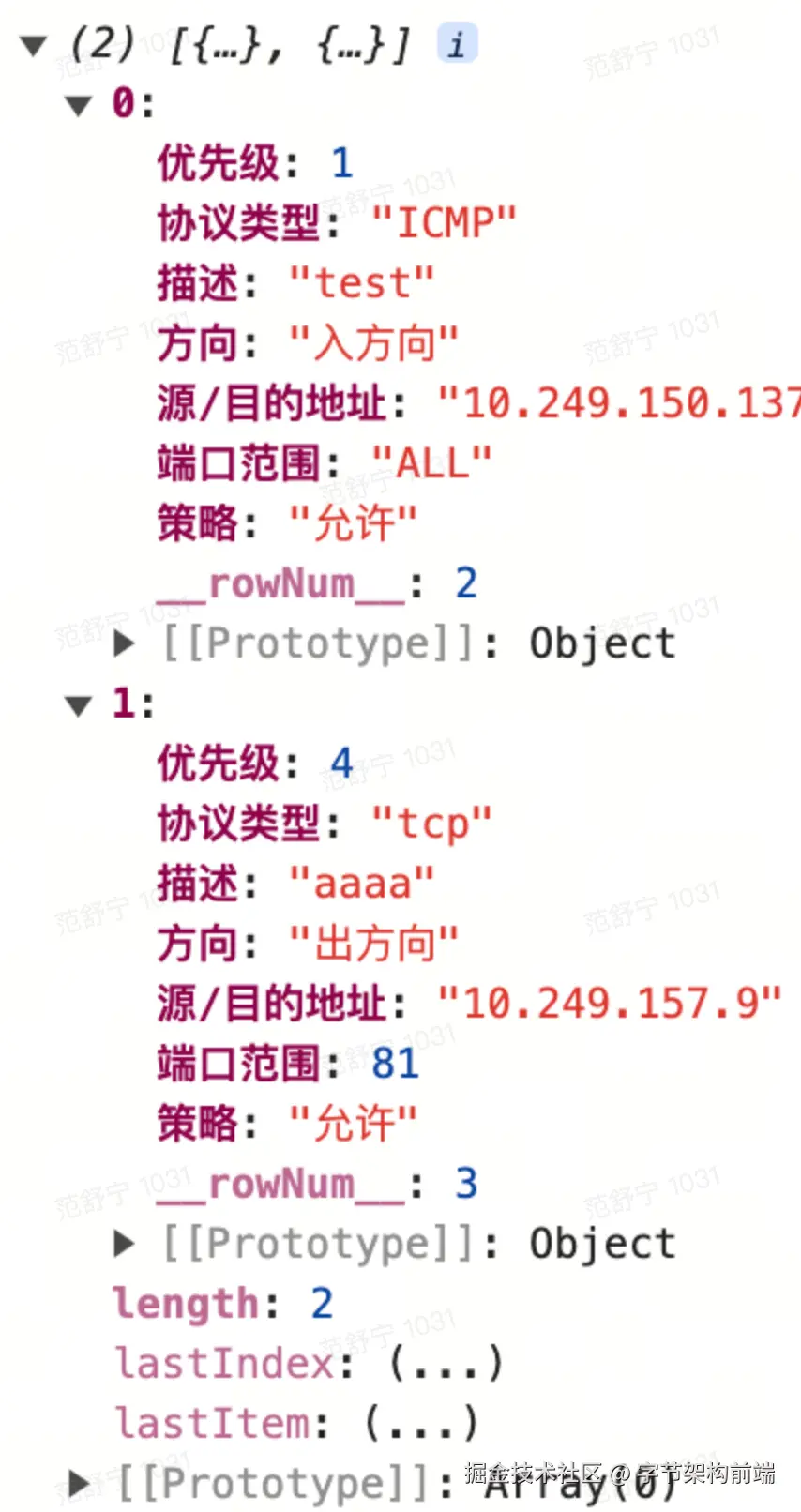
首先使用 read 方法解析成由一系列的 Worksheets 构成的 Workbook 对象,每个 Worksheet 是一个键值对的数组。键是单元格的地址(如 'A1'),值就是单元格的内容。
一个 sheet 对象的结构如下:

!ref 指定了工作表中数据的范围。比如 "A2:G4",表示这个工作表有效数据的范围是从A2单元格到C4单元格。
单元格的内容是一个对象,该对象可能包含以下属性:
markdown
Key | Description ___________________________________________________
v | 原始值
t | 数据类型(如 'n' 表示数字,'s' 表示共享字符串等)
w | 格式化文本
r | 富文本内容
h | HTML内容
c | 与单元格关联的注释
z | 与单元格关联的数字格式字符串
l | 单元格的超链接对象 (.Target 是地址, .Tooltip 是提示消息)
s | 单元格的样式/主题下面是 sheet_to_json 的部分源码。
ini
function sheet_to_json(sheet, opts) {
if(sheet == null || sheet["!ref"] == null) return [];
var val = {t:'n',v:0}, header = 0, offset = 1, hdr = [], v=0, vv="";
var r = {s:{r:0,c:0},e:{r:0,c:0}};
var o = opts || {};
var range = o.range != null ? o.range : sheet["!ref"];
if(o.header === 1) header = 1;
else if(o.header === "A") header = 2;
else if(Array.isArray(o.header)) header = 3;
else if(o.header == null) header = 0;
switch(typeof range) {
case 'string': r = safe_decode_range(range); break;
case 'number': r = safe_decode_range(sheet["!ref"]); r.s.r = range; break;
default: r = range;
}
if(header > 0) offset = 0;
var rr = encode_row(r.s.r);
var cols = [];
var out = [];
var outi = 0, counter = 0;
var dense = Array.isArray(sheet);
var R = r.s.r, C = 0;
var header_cnt = {};
if(dense && !sheet[R]) sheet[R] = [];
var colinfo = o.skipHidden && sheet["!cols"] || [];
var rowinfo = o.skipHidden && sheet["!rows"] || [];
// r.s.r和r.e.c主要使用在循环遍历工作表中的单元格数据的过程中。通过这两个值,我们能确定需要读取数据的范围。
// 下面这个 for 循环中,遍历了从起始列到结束列的所有列,创建了列标题(hdr)。
for(C = r.s.c; C <= r.e.c; ++C) {
if(((colinfo[C]||{}).hidden)) continue;
cols[C] = encode_col(C);
val = dense ? sheet[R][C] : sheet[cols[C] + rr];
switch(header) {
case 1: hdr[C] = C - r.s.c; break;
case 2: hdr[C] = cols[C]; break;
case 3: hdr[C] = o.header[C - r.s.c]; break;
default:
if(val == null) val = {w: "__EMPTY", t: "s"};
vv = v = format_cell(val, null, o);
counter = header_cnt[v] || 0;
if(!counter) header_cnt[v] = 1;
else {
do { vv = v + "_" + (counter++); } while(header_cnt[vv]); header_cnt[v] = counter;
header_cnt[vv] = 1;
}
hdr[C] = vv;
}
}
// 在遍历行数据并转换为JSON过程中,使用了r.s.r + offset 和 r.e.r:
// 这段代码遍历了从起始行(加上了一个可能的偏移量)到结束行的所有行,根据列标题(hdr)和单元格数据创建了对应的JSON对象。在这两个过程中,r.s.r表示起始行号,r.e.c表示结束列号,它们被用来确定数据读取的边界。
for (R = r.s.r + offset; R <= r.e.r; ++R) {
if ((rowinfo[R]||{}).hidden) continue;
var row = make_json_row(sheet, r, R, cols, header, hdr, dense, o);
if((row.isempty === false) || (header === 1 ? o.blankrows !== false : !!o.blankrows)) out[outi++] = row.row;
}
out.length = outi;
return out;
}变量r在这段代码中作为一个范围对象,用来储存解码后的!ref或用户提供的range信息。它包含两个属性s和e,分别表示范围的起始和结束位置。s和e又是两个对象,它们包含r和c属性分别代表行号和列号。比如r.s.r表示范围起始位置的行号,r.e.c表示范围结束位置的列号。
完成后得到解析json数据:
总结
-
解析 .csv 文件时需要对不同编码方式分开处理,.xlsx 不需要。
-
每个 .xlsx 文件都可以被解压成一堆遵循 Open XML 规范的 xml 文件,通常是以 UTF-8 编码(xml 文件顶部有声明)。
-
第三方库利用这些规范中定义的数据结构和格式,解析和提取出文件中的数据。
字符集演进历史
乱码问题的罪魁祸首就是这么多的编码格式。那么为什么全世界不能使用同一套编码规范?这就不得不扒一扒字符集的历史了。
ASCII 编码的诞生
计算机最开始诞生于美国,而且计算机只能识别二进制。美国人把英文里面常用的字符以及一些控制字符转换成了二进制数据。而一个字节有 8 位,即最大能表示 255 个字符,但是英语的常用字符比较少,常用的字母以及一些常用符号列出来就是 128 个,所以美国人就占用了这 0-127 的位置,形成了一个编码对应关系表,这就是 ASCII(American Standard Code for Information Interchange,美国标准信息交换码) 编码。
IOS-8859 编码家族诞生
随着计算机传到了欧洲,国际标准化组织(ISO)制定了 ISO-8859-1 字符集。由于 ASCII 只用到了 0-127 个位置,最高位并没有占用,于是欧洲人就把第 8 位利用了起来。
GB2312 和 GBK 等双字节编码诞生
当计算机发展到亚洲之后,现有的单字节编码方式显然是不够用的,于是只能再扩展一个字节。但是两个字节来存储又有一个问题,那就是比如我读取了两个字节出来,他们到底是表示两个单字节字符还是表示的是双字节的中文呢?
于是我们伟大的中国人民就决定制定一套中文编码,用来兼容 ASCII,因为 ASCII 编码中的单字节字符一定是小于 128 的,所以最后我们就决定,中文的双字节字符都从 128 之后开始,也就是当发现字符连续两位都大于 128 时,就说明这是一个中文,指定了之后我们就把这种编码方式称之为 GB2312 编码。
GB2312 编码收录了常用的汉字 6763 个和非汉字图形字符 682 个,但这也是不够的。 GB2312 中收录的中文汉字都是简体字和常用字,对于一些生僻字以及繁体字没有收录,于是乎 GBK 出现了。
GBK 的做法就是只要求第一位是大于 128,第二位可以小于 128,这就是说只要发现一个字节大于 128,那么紧随其后的一个字节就是和其作为一个整体作为中文字符,这样最多就能存储 32640 个汉字了。
Unicode 字符集的诞生
为了统一编码问题,有关部门决定重新制定另一套字符标准,目标是收录世界上全部的字符,这就是 Unicode。
需要注意的是: Unicode 只是一个字符集,它只规定了字符的二进制代码,却没有规定这个二进制代码应该如何存储。 比如,"中" 字的 Unicode 码是 4E2D,转换成二进制数足足有15位(100111000101101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,而对于英文来说,只需要一个字节就够了。于是演变出多种 Unicode 的存储方式。
UTF 编码家族诞生
互联网的普及,强烈要求出现一种统一的编码方式。于是出现了 UTF 系列编码家族,只不过实现的方式有所区别,其中主要有:UTF-8,UTF-16,UTF-32 等类型,目前使用最广泛使用的是 UTF-8 。
UTF-32 编码
UTF-32 编码基本按照 Unicode字符集标准来实现,任何一个符号都占用 4 个字节。可以想象,这会浪费多大空间,对英文而言,空间扩大了四倍,中文也扩大了两倍,所以这种编码方式也导致了 Unicode 在最初并没有被大家广泛的接受。
UTF-16 编码
UTF-16 编码相比较 UTF-32 做了一点改进,其采用 2 个字节或者 4 个字节来存储。编码规则如下:
-
小于 0x10000 的,Unicode 直接对应 UTF-16。
-
大于 0x10000 的需要做编码转换。
下表就是 UTF-16 编码的存储格式:
| Unicode 编码范围(16 进制) | UTF-16 编码的二进制存储格式 |
|---|---|
| 0x0000 0000 - 0x0000 FFFF | xxxxxxxx xxxxxxxx |
| 0x0001 0000 - 0x0010 FFFF | 110110xx xxxxxxxx 110111xx xxxxxxxx |
前面提到过,"中" 字的 Unicode 码是 4E2D, 它小于 0x10000,根据表格可知,它的 UTF-16 编码占两个字节,并且和 Unicode 码相同,所以 "中" 字的 UTF-16 编码为 4E2D。
需要注意的是:在 UTF-16 编码中,2 个字节也可能出现 4 字节中 110110xx 或者 110111xx 开头的格式,这两部分对应的区间分别是:D800DBFF 和 DC00DFFF,所以为了避免这种歧义的发生,这两部分区间是是专门空出来的,没有进行编码。
🌰:比如"😁" 这个emoji,对应的 Unicode 编码是 0x1F604
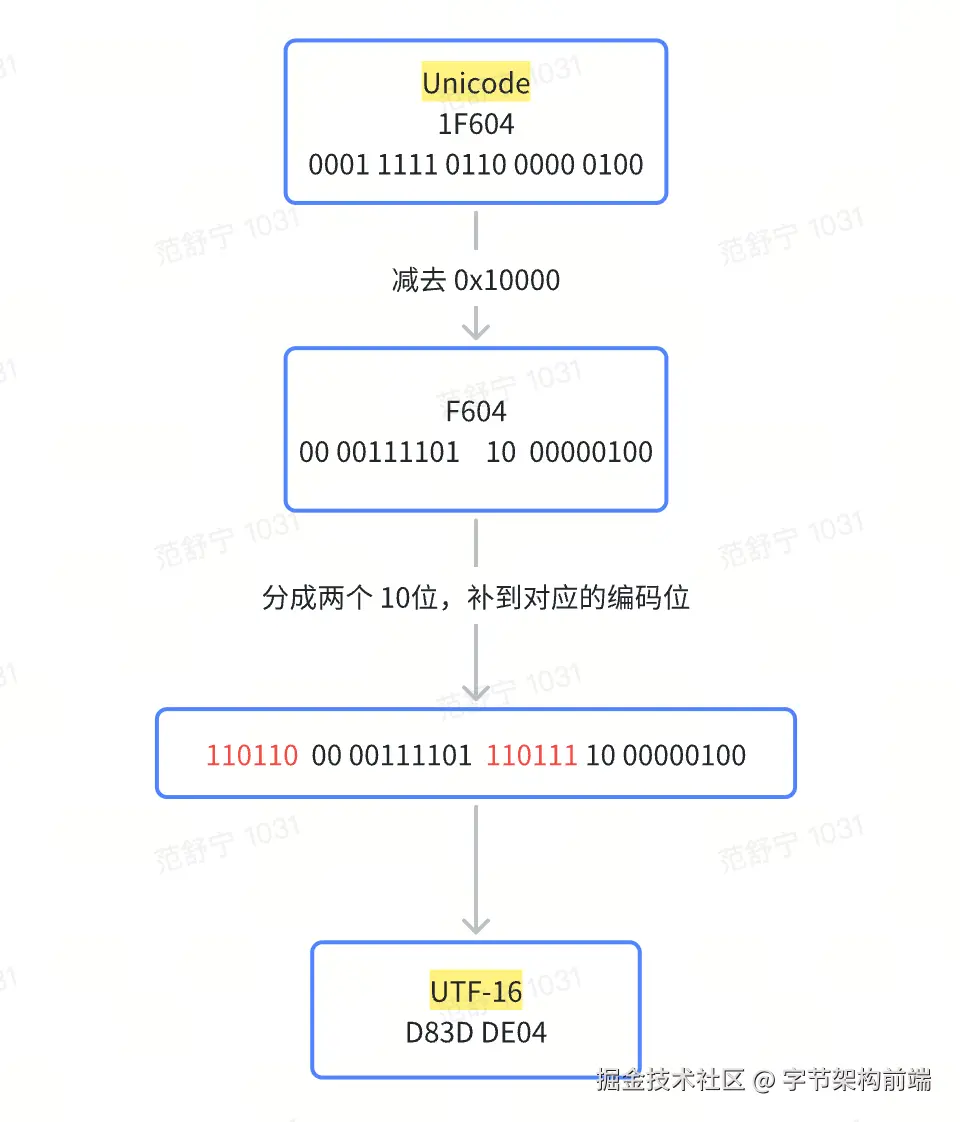
这个编码大于 0xFFFF,因此是采用四字节的编码方式,步骤如下:
-
首先把 Unicode 码 0x1F604 转成二进制。
-
然后把 Unicode 码 0x1F604 减去 0x10000 = 0xF604 并把这个值转成二进制 00 00111101 10 00000100。
-
把这 20位 2进制分别填入上表中"x"的位置。
-
转换成16进制,得到对应的 UTF-16 编码:0xD83DDe04。
UTF-8 编码
UTF-8 是一种变长的编码,兼容了 ASCII 编码,为了实现变长这个特性,那么就必须要有一个规范来规定存储格式,这样当程序读了 2 个或者多个字节时能解析出这到底是表示多个单字节字符还是一个多字节字符。
UTF-8 的编码规则:
-
对于单字节的符号:字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
-
对于n字节的符号(n > 1):第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
可参考下表:
| Unicode 编码范围(16 进制) | UTF-8 编码的二进制存储格式 | 可存储位数 |
|---|---|---|
| 0x0000 0000 - 0x0000 007F | 0xxxxxxx | 7 |
| 0x0000 0080 - 0x0000 07FF | 110xxxxx 10xxxxxx | 11 |
| 0x0000 0800 - 0x0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx | 16 |
| 0x0001 0000 - 0x0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 21 |
🌰 比如 "中"这个字,对应的 Unicode 编码为:0x4E2D,转换位 UTF-8 编码的步骤如下:
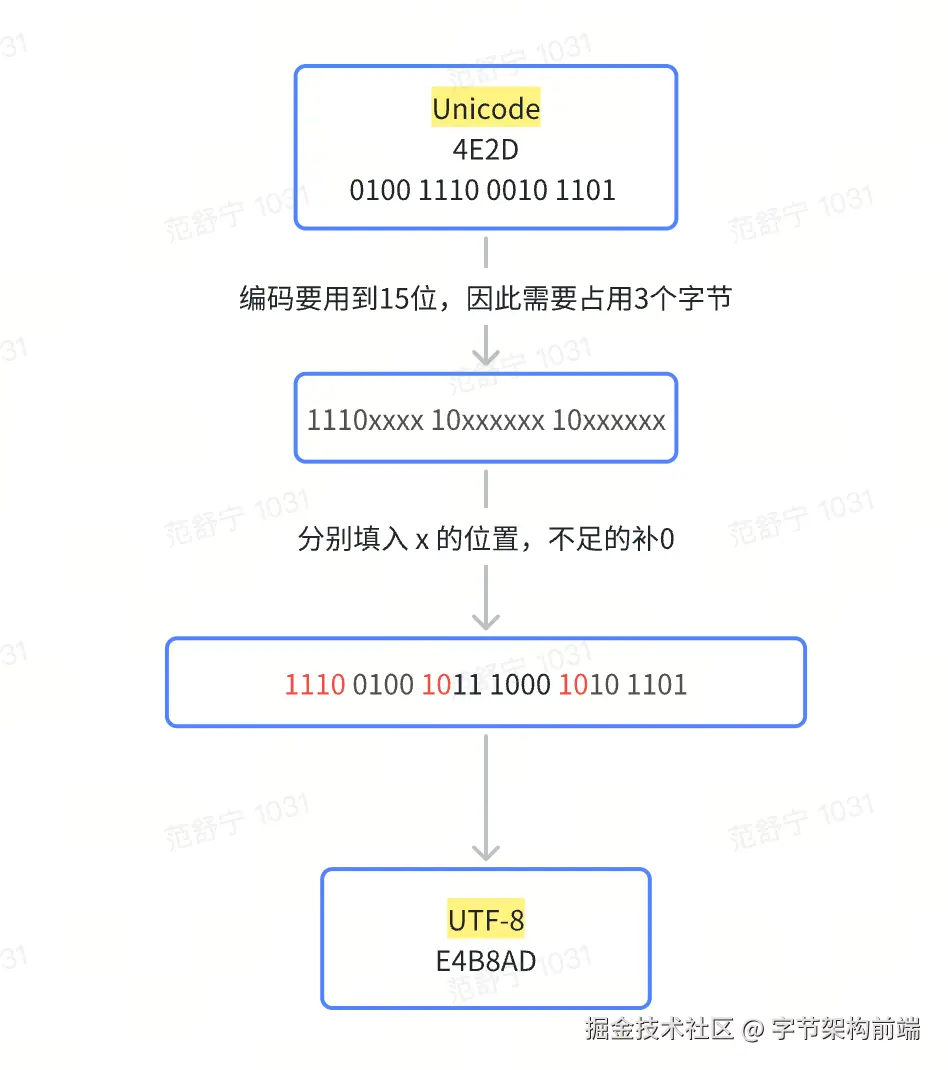
- Unicode 码 0x4E2D, 转成二进制 0100 1110 0010 1101 , 总共有 16 个二进制位。
- 查询上表,需要使用 3 个字节编码。
- 将二进制分别填入"x" 的位置。
- 得到 UTF-8 编码:E4B8AD。
各个编码方式对比
| UTF-32 | UTF-16 | UTF-8 | |
|---|---|---|---|
| 特点 | 固定长度编码。一个字符固定占据 4 个字节长度。 | 变长编码,一个字符占据 2 或 4 个字节。 | 变长编码,一个字符可能占据 1 到 4 个字节。 |
| 优点 | 每个字符长度固定,查找字符串中的特定位置的字符非常容易。 | 非英文字符存储效率高 | 兼容性好,对于大量使用英文的应用很节省空间。 |
| 缺点 | 存储效率相对较低。 | 编码方式与通用网络字节顺序(BOM)有关 | 非英文字符占用空间大 |
UTF 字节序
由于 UTF-8 的设计特性,所以它没有字节顺序的问题,但在 UTF-16 和 UTF-32 中就会存在。
比如:前面提到过,"中" 字的 Unicode 码是 4E2D, "?" 字符的 Unicode 码是 2D4E, 当我们收到一个 4E2D 的 UTF-16 编码 时,计算机如何识别它表示的是字符 "中" 还是 字符 "?" 呢 ?
所以,对于多字节的编码单元,需要有一个标记显式的告诉计算机,按照什么样的顺序解析字符,也就是字节序。
小端字节序简写为 LE( Little-Endian )
表示 低位字节在前,高位字节在后, 高位字节保存在内存的高地址端,而低位字节保存在内存的低地址端。对应编码 UTF-16 LE:2D4E。
大端字节序简写为 BE( Big-Endian )
表示 高位字节在前,低位字节在后,高位字节保存在内存的低地址端,低位字节保存在在内存的高地址端。对应编码 UTF-16 BE: 4E2D。
BOM
BOM ( byte-order mark )是 "字节序标记" 的意思。
对于 UTF-16 ,如果接收到以 FEFF 开头的字节流, 就表明是大端字节序,如果接收到 FFFE, 就表明字节流 是小端字节序。
UTF-8 没有字节序问题,上述字符只是用来标识它是 UTF-8 文件,而不是用来说明字节顺序的。 UTF-8 编码的字节序是 EF BB BF,看到这个就知道这是UTF-8 文件。
下面的表格列出了不同 UTF 格式的固定文件头
| UTF 编码 | 固定文件头 |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16 LE | FF FE |
| UTF-16 BE | FE FF |
| UTF-32 LE | FF FE 00 00 |
| UTF-32 BE | 00 00 FE FF |
总结
-
Excel 文件都遵循 Open XML 规范,因此第三方库只要按照这套标准就能正确的解析文件。
-
CSV 是纯文本格式,编码方式可能会有所不同(如 UTF-8, GBK 或其他)。因此在解析 csv 文件时要注意编码格式的处理。
-
介绍了 Unicode 出现的原因,以及 Unicode 字符集中 三种不同的编码方式:UTF-8、UTF-16、UTF-32 。分别介绍了它们的的编码方法和优缺点。