文章目录
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
一、项目背景
随着全球人口的持续增长和消费结构的升级,农产品价格波动已成为影响农业生产决策和市场稳定的重要因素。我国作为农业生产大国,农产品种类繁多,市场规模巨大,价格受季节、供求关系、气象条件等多重因素影响。传统的价格统计与分析方式往往依赖人工整理和单一数据库查询,数据来源分散、更新滞后,难以满足实时分析和决策支持的需求。
与此同时,大数据技术特别是 Hadoop 生态系统的发展,为农业数据的采集、存储、分析和可视化提供了全新的技术手段。本项目旨在利用 Hadoop 及其配套工具,构建一个农产品价格数据分析与可视化平台,实现对海量、多源价格数据的高效处理和直观展示,助力农业产业链的数字化升级。
二、项目目标
本项目的核心目标包括:
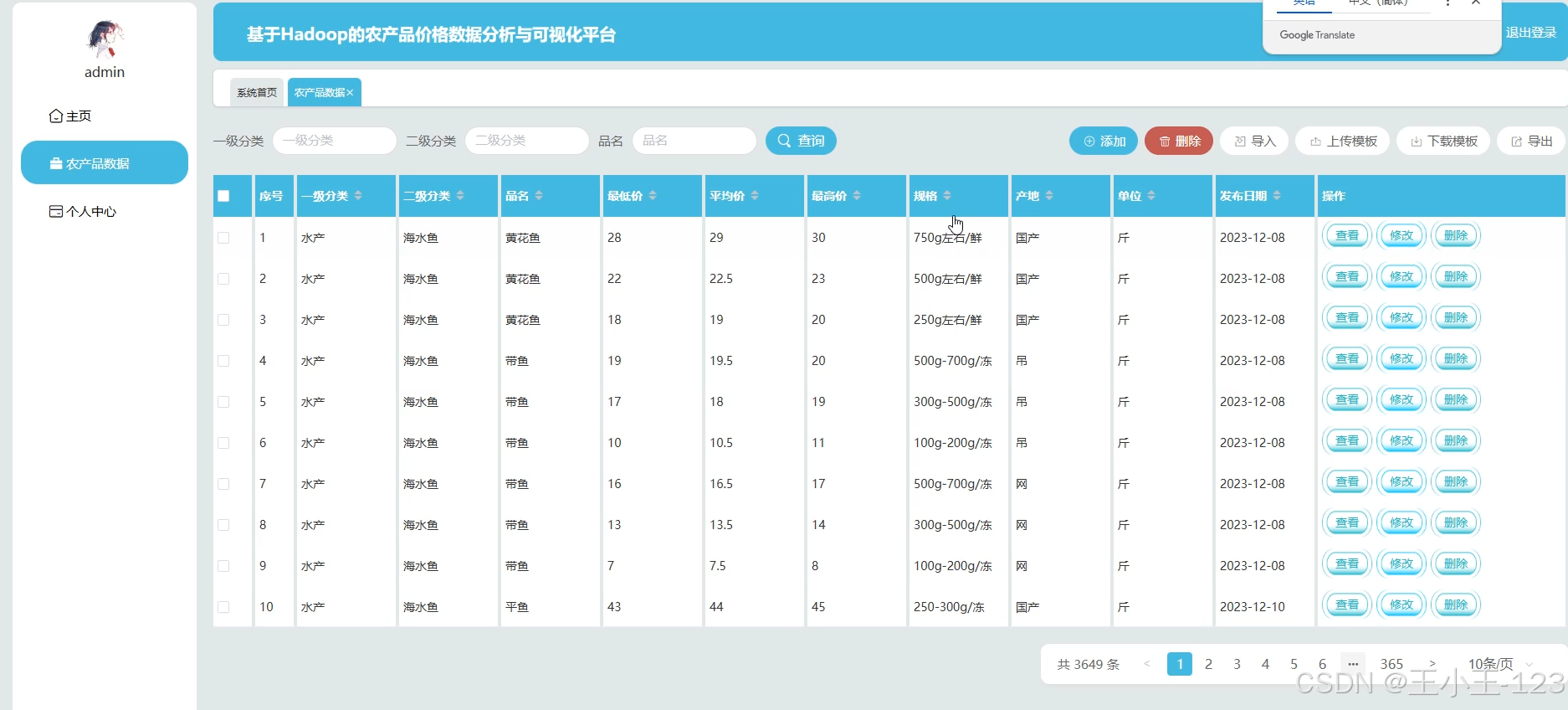
- 实现农产品价格数据的多源采集:通过网络爬虫、API接口或开源数据等方式,从权威农产品价格信息网站、市场监测系统等采集农产品价格、交易量、产地等数据。
- 构建高效的数据存储与管理系统:基于 Hadoop HDFS 分布式文件系统管理数据,实现大规模数据的持久化与高可用。
- 开展深度数据分析:使用 Spark 计算框架,对数据进行清洗、缺失值处理、异常值识别,并进行趋势分析、区域差异分析和价格预测。
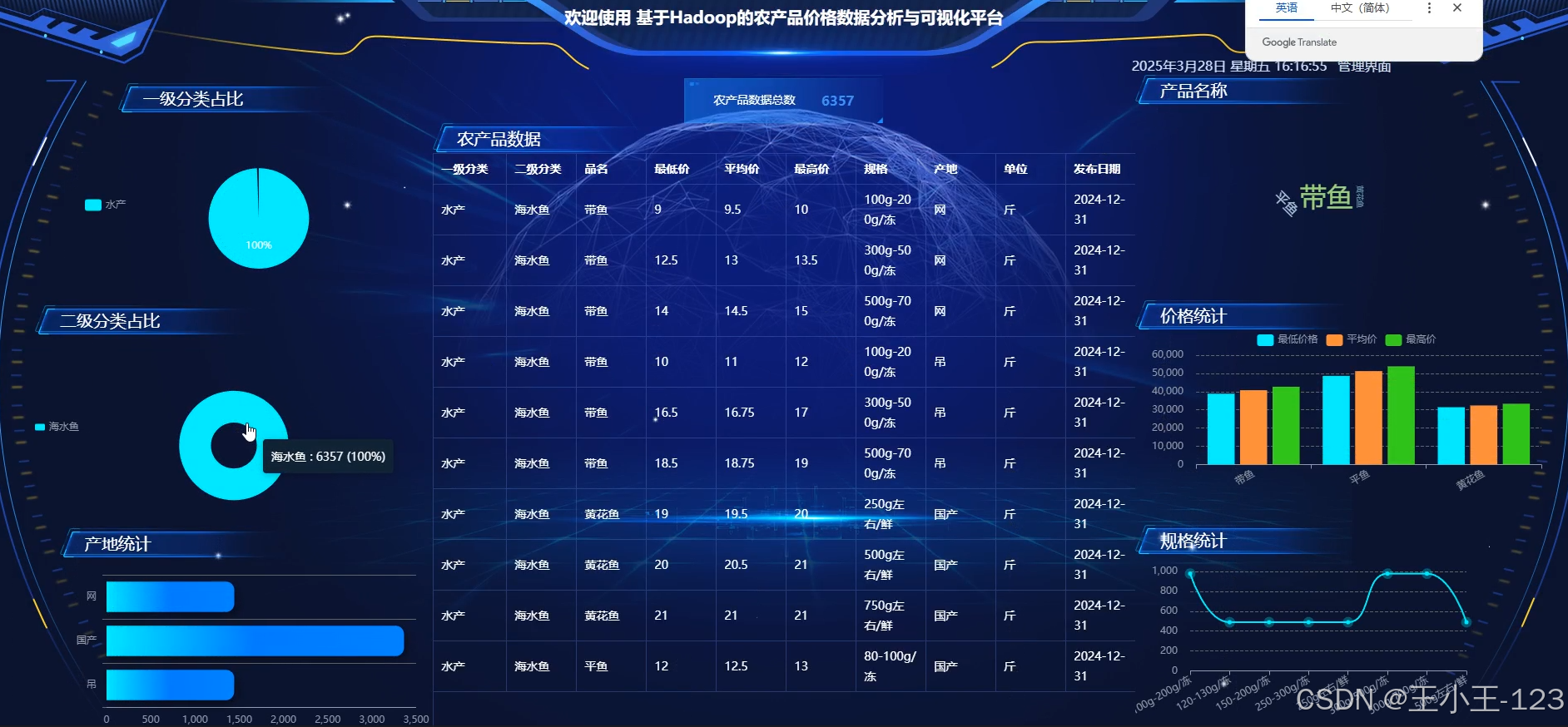
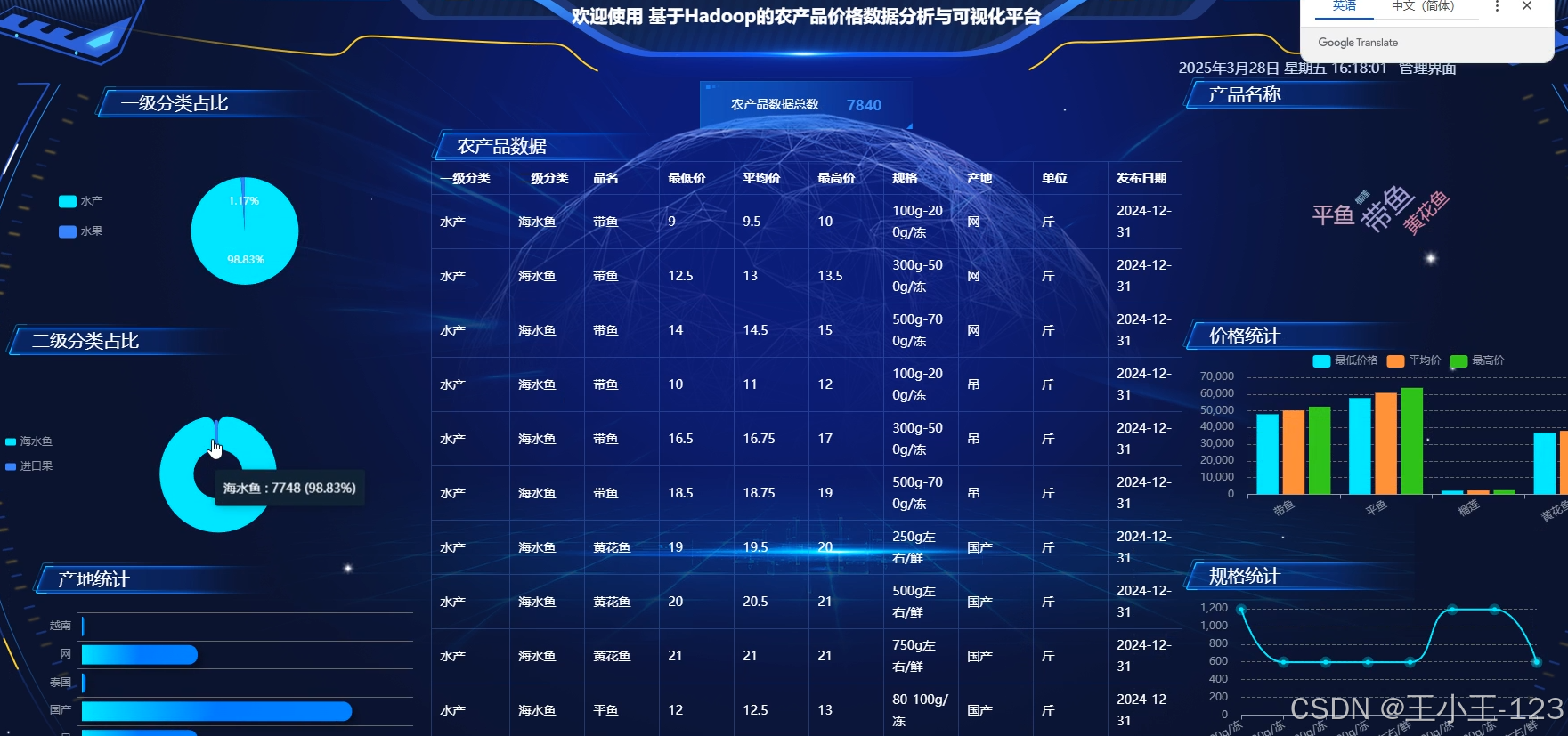
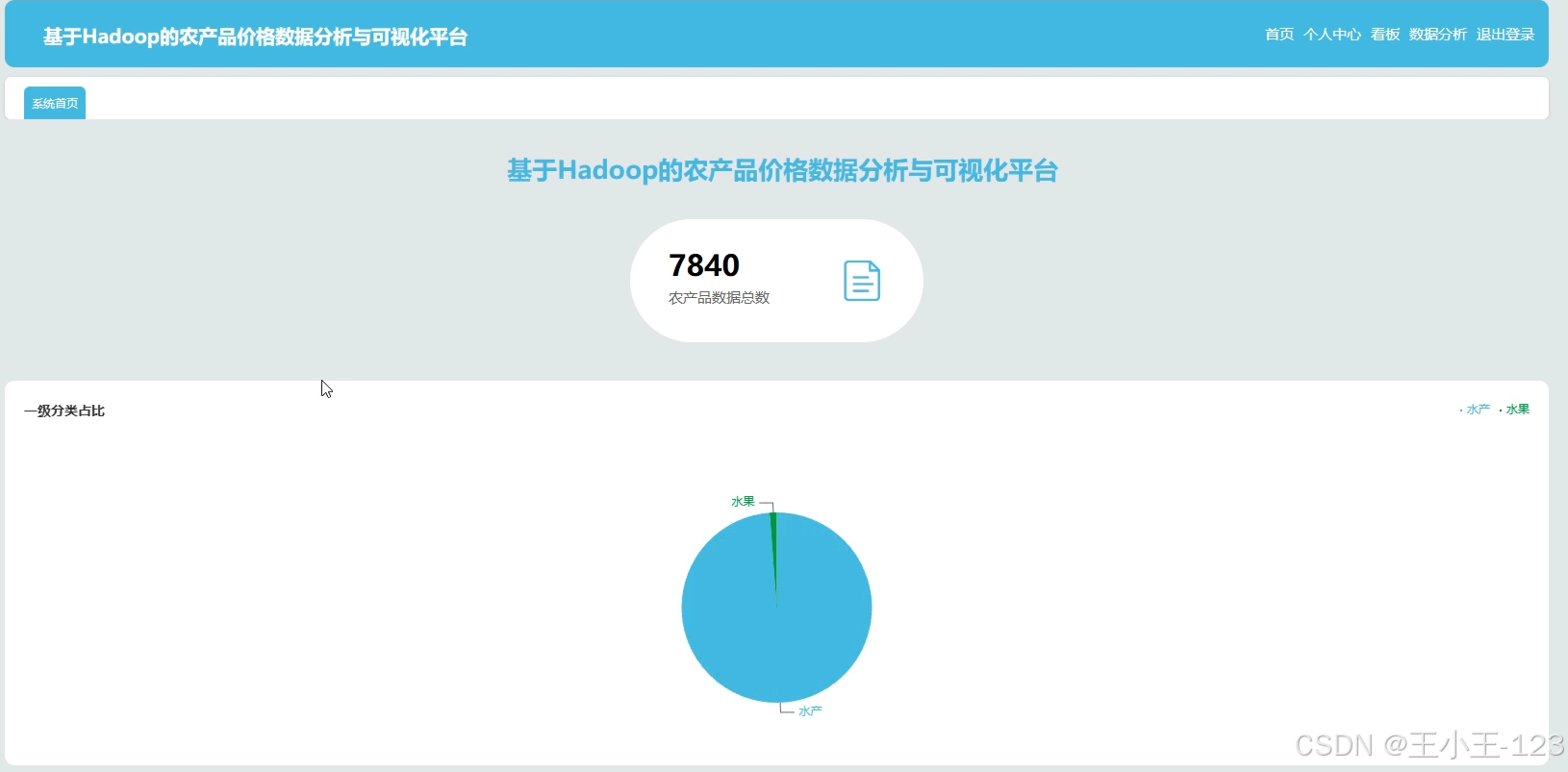
- 提供可视化与决策支持:通过交互式可视化平台,将复杂的分析结果转化为易于理解的图表、地图和仪表盘,支持用户按时间、区域、品类进行灵活查询。
- 提升数据实时性与准确性:实现数据的定时采集与自动更新,确保平台分析结果能够反映最新市场动态。
三、系统架构与功能模块
系统整体架构基于 Hadoop 生态系统,结合 Spark、MySQL、ECharts 等工具,分为六大功能模块:
-
数据采集层
- 利用 Python 爬虫(Scrapy、Requests 等)和 API 接口抓取数据
- 数据来源包括政府农业部网站、农产品批发市场信息平台、气象局数据接口等
-
数据存储层
- 采用 Hadoop HDFS 作为核心存储
- 按日期、品类等维度进行数据分区
- 同时将分析结果存储到 MySQL 以便快速查询
-
数据预处理层
- 使用 Spark 对数据进行去重、缺失值处理、异常检测
- 标准化不同来源的数据字段,保证一致性
- 支持数据合并与多维特征构建
-
数据分析层
- 价格趋势分析:按日、周、月计算平均价格并绘制趋势曲线
- 区域对比分析:比较不同地区同类农产品价格差异
- 市场份额分析:统计各类农产品在市场中的交易占比
-
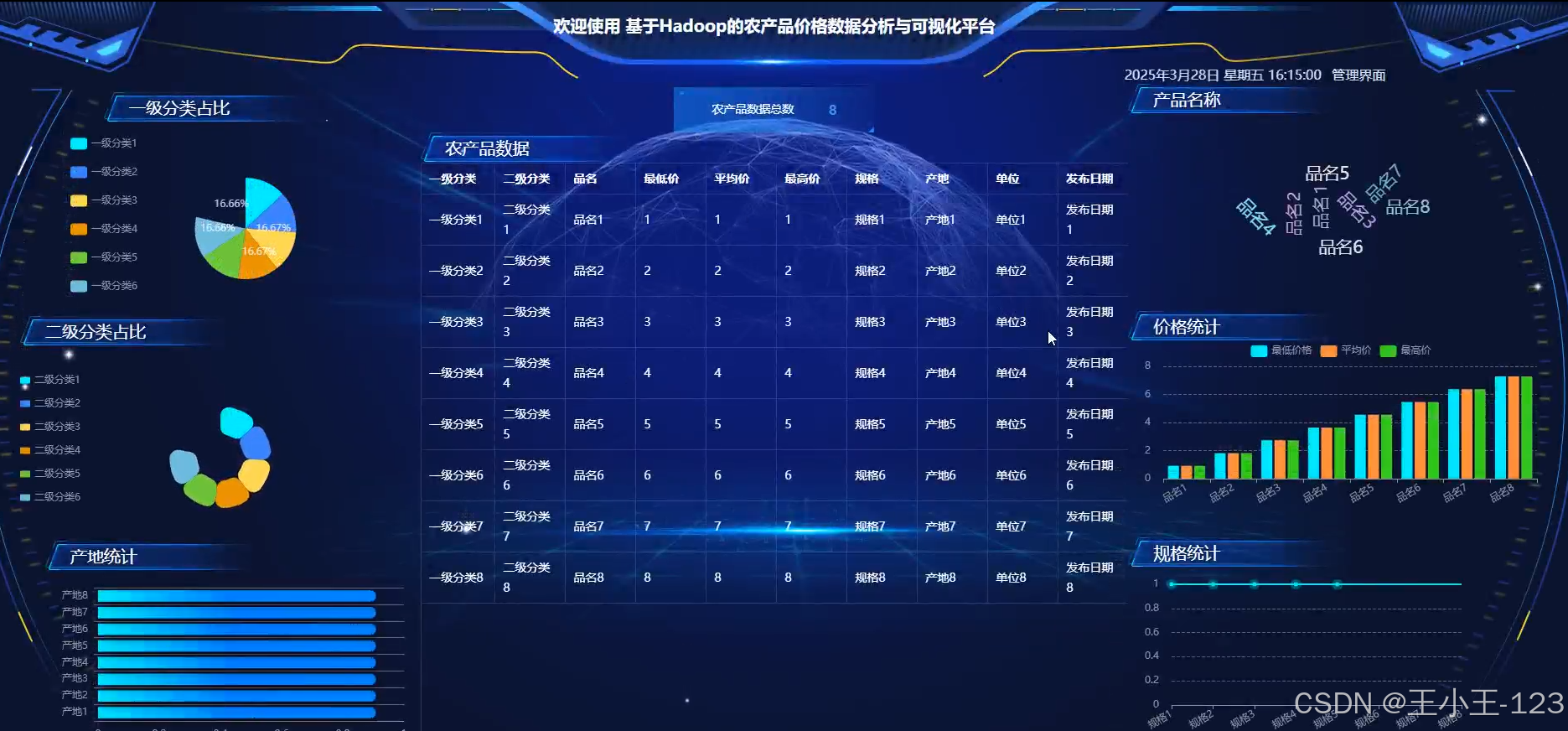
可视化展示层
- 使用 ECharts/D3.js/Mapbox 等前端可视化技术
- 提供折线图、柱状图、饼图、热力地图等多种可视化形式
- 支持数据筛选与交互操作
-
用户交互与决策支持层
- 针对农民:提供价格走势、最佳销售时间建议
- 针对企业:提供市场布局、供需预测
- 针对政府:提供宏观市场监管与政策参考
预期成果与应用价值
- 提升农业生产效率:为农民提供数据驱动的种植与销售决策,降低因价格波动带来的经济损失。
- 提高市场透明度:帮助消费者和企业及时了解价格信息,促进公平交易。
- 支持政府监管与宏观决策:为农业政策制定提供科学依据,优化产业结构。
- 促进农业信息化发展:推动农业与大数据、云计算技术的深度融合,为智慧农业建设提供参考案例。
每文一语
持续...