什么事微服务
微服务可以通过标签来找到能发布的服务
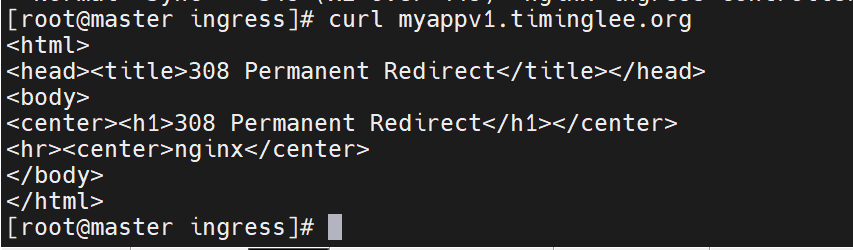
现在还不知道能让谁来做负载均衡,需要做端口暴漏


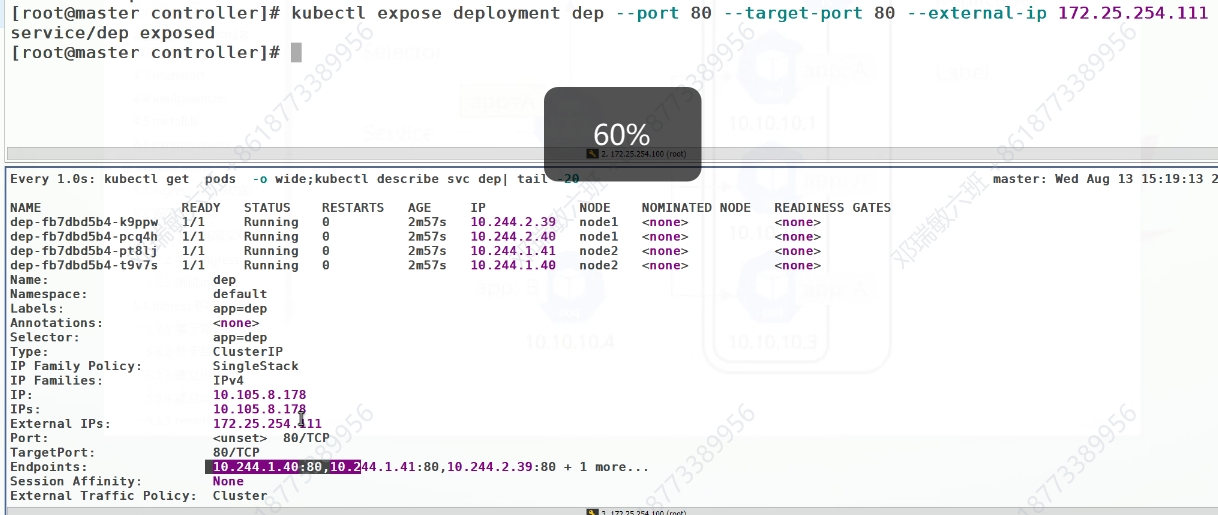
当我们访问111时,它会带我们访问后端的四个IP
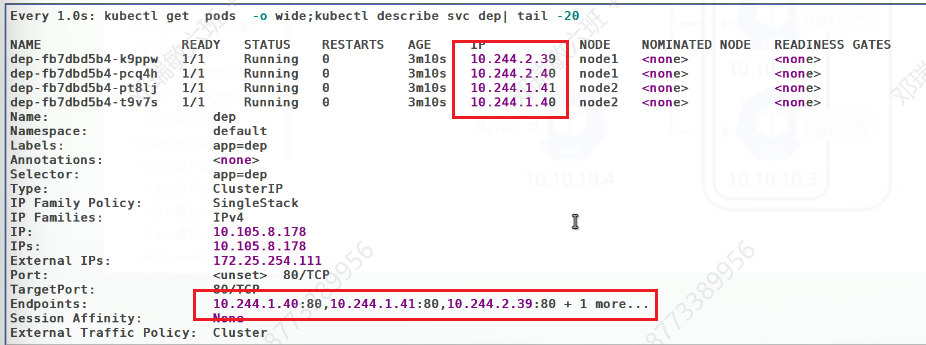

当我们改变了标签,并覆盖后,原先这个这个标签的主机就被开出去了
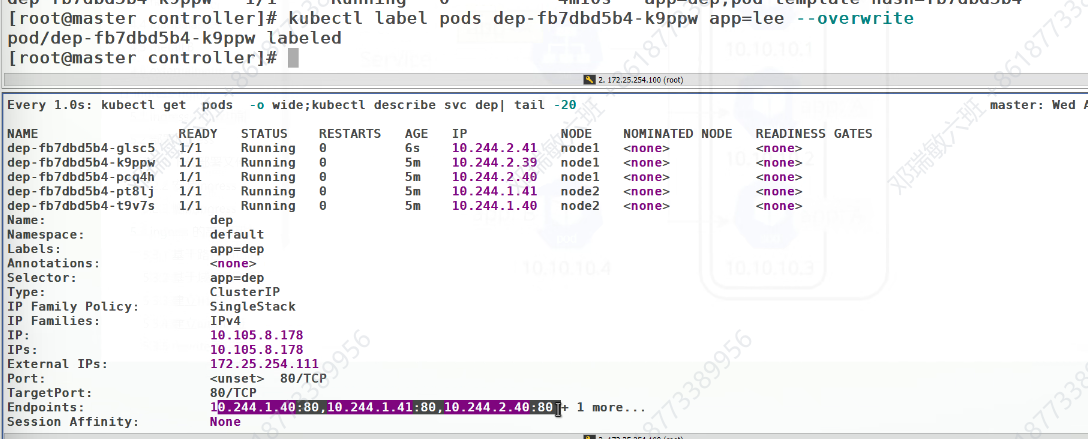
重新返回,把标签还原
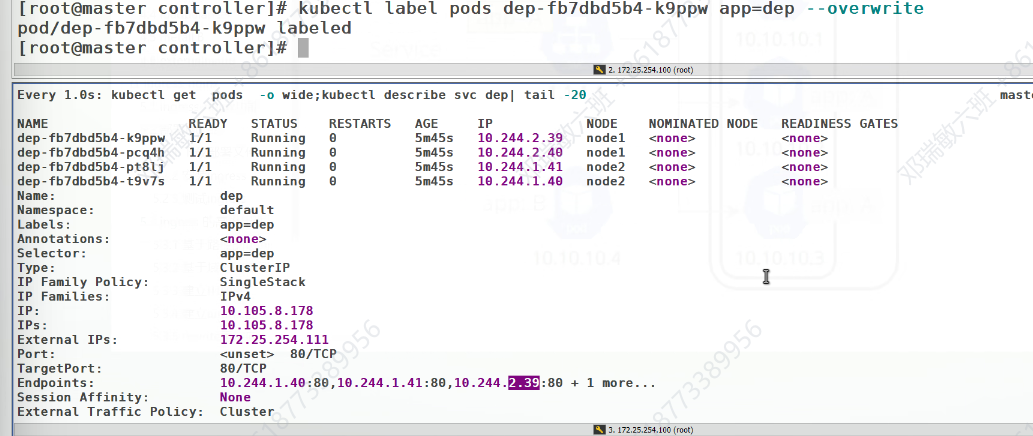
查看策略,当我们访问这个IP时,他的策略把他带去访问后端的IP地址



这个策略本身是不太好的,IP地址总是会变,而且是防火墙里的策略,数据一多,每次扫描都会造成浪费
即便测试器删了,微服务也不会被删除

要再次删除微服务

微服务的类型
| 微服务类型 | 作用描述 |
|---|---|
| ClusterIP | 默认值,k8s系统给service自动分配的虚拟IP,只能在集群内部访问 |
| NodePort | 将Service通过指定的Node上的端口暴露给外部,访问任意一个NodeIP:nodePort都将路由到ClusterIP |
| LoadBalancer | 在NodePort的基础上,借助cloud provider创建一个外部的负载均衡器,并将请求转发到 NodeIP:NodePort,此模式只能在云服务器上使用 |
| ExternalName | 将服务通过 DNS CNAME 记录方式转发到指定的域名(通过 spec.externlName 设定 |
LoadBalancer:集群内访问集群外
ExternalName:集群外访问集群内
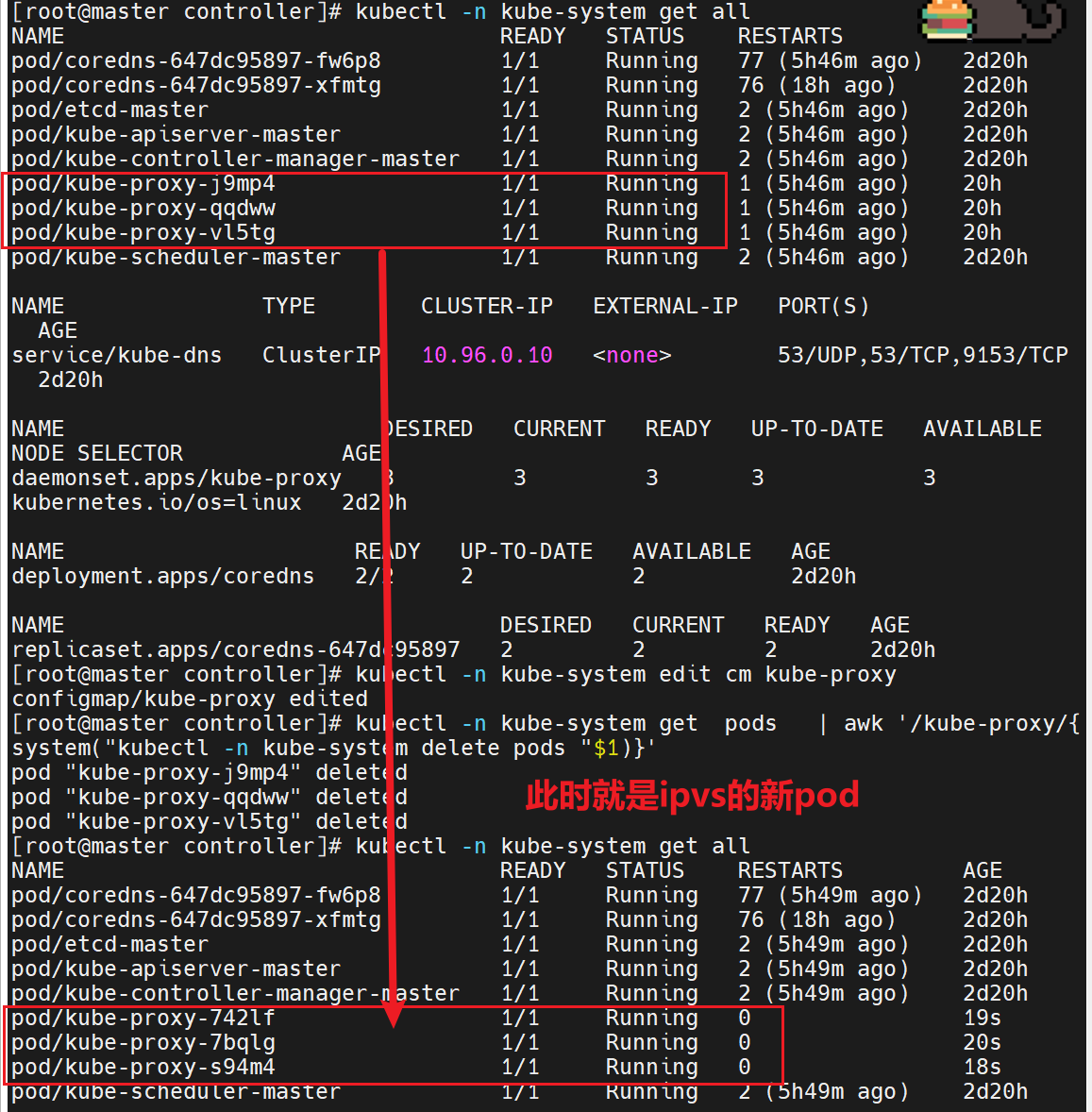
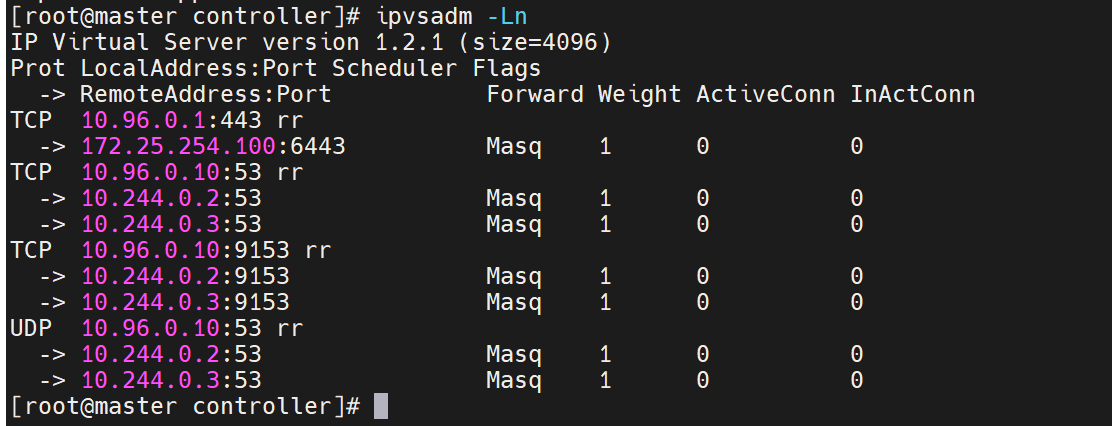
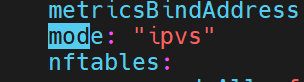
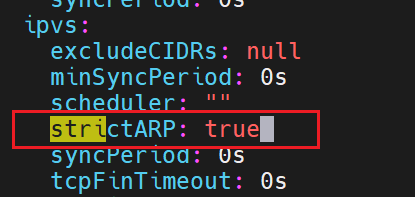
ipvs模式
之前说过,iptables防火墙里的策略不好,所以这里我们可以换成ipvs模式
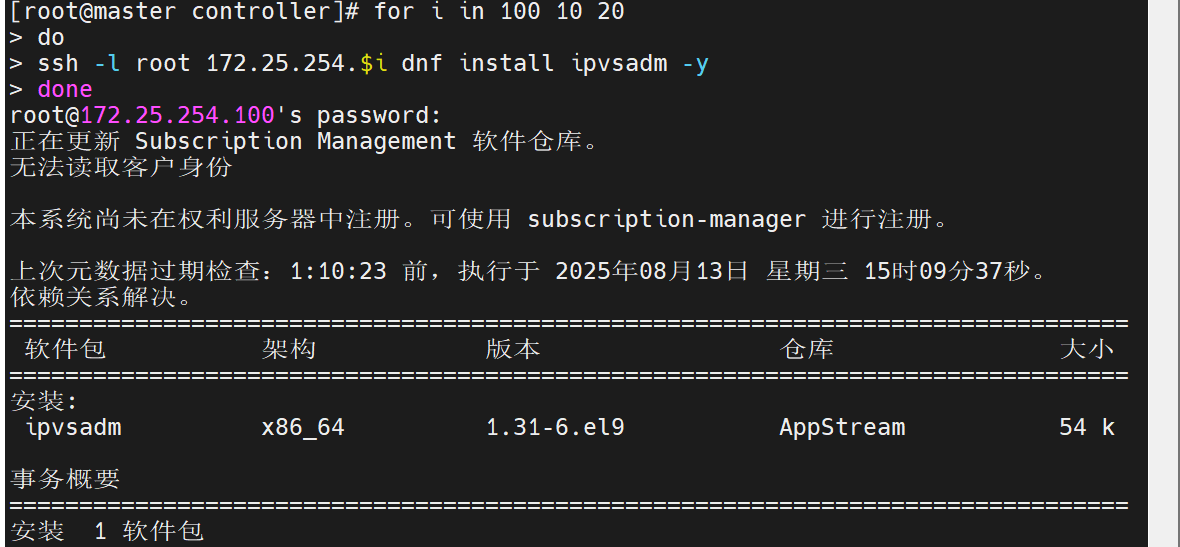
查看集群的配置
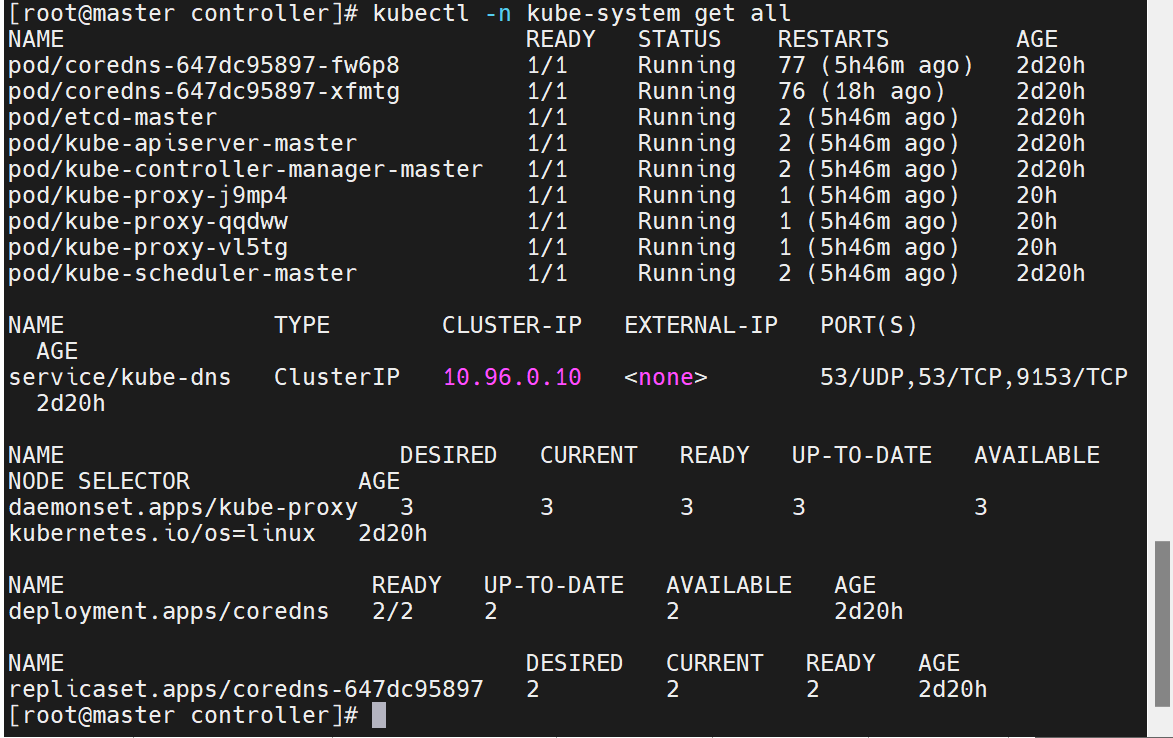
更改集群的配置
更改集群资源的命令

如果什么都没有,说明是默认的使用iptables,这里我们加上ipvs
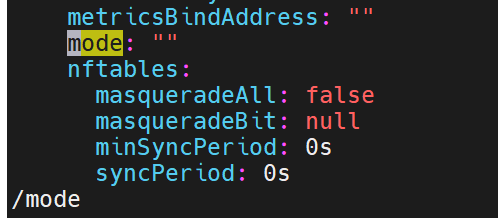
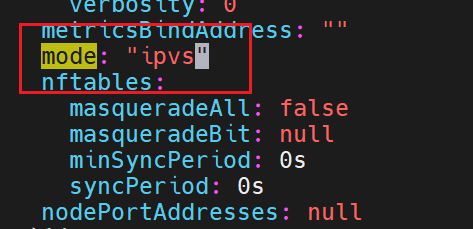
修改配置后,要重启,这里可以删掉之前的网络配置pod,重新刷新新的pod出来,此时就是新策略的pod

微服务类型详解
clusterip
clusterip模式只能在集群内访问,并对集群内的pod提供健康检测和自动发现功能

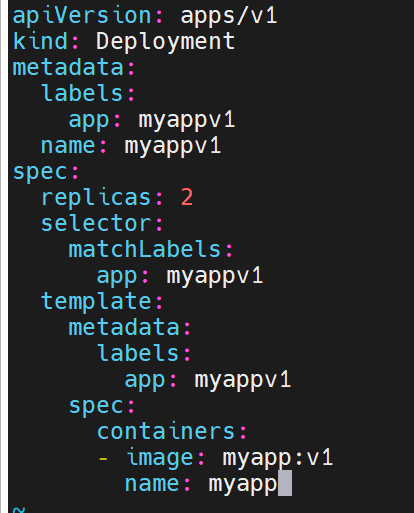
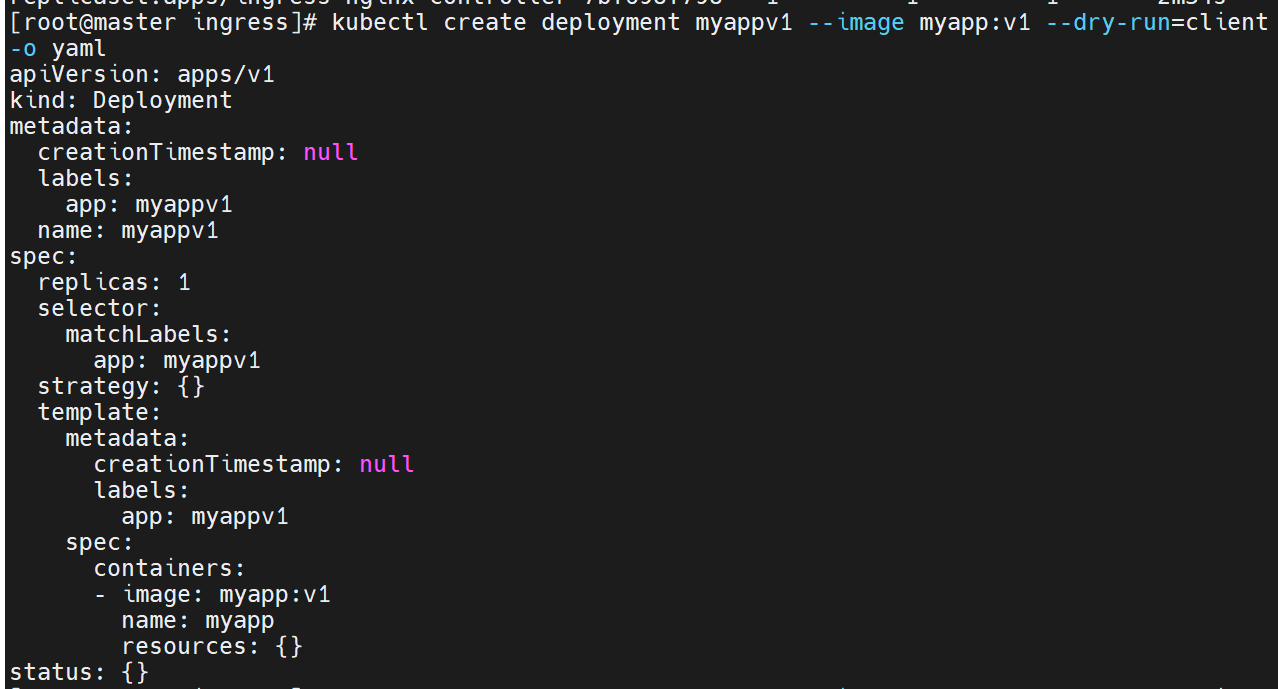
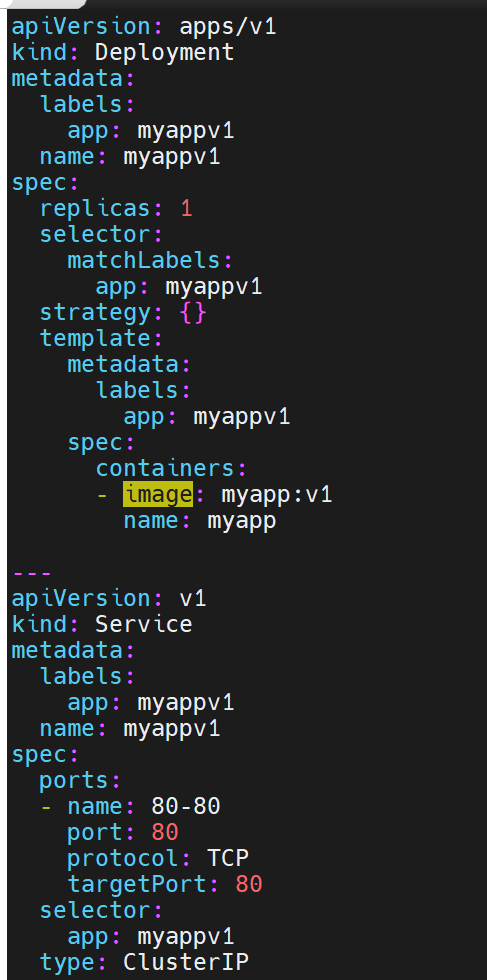
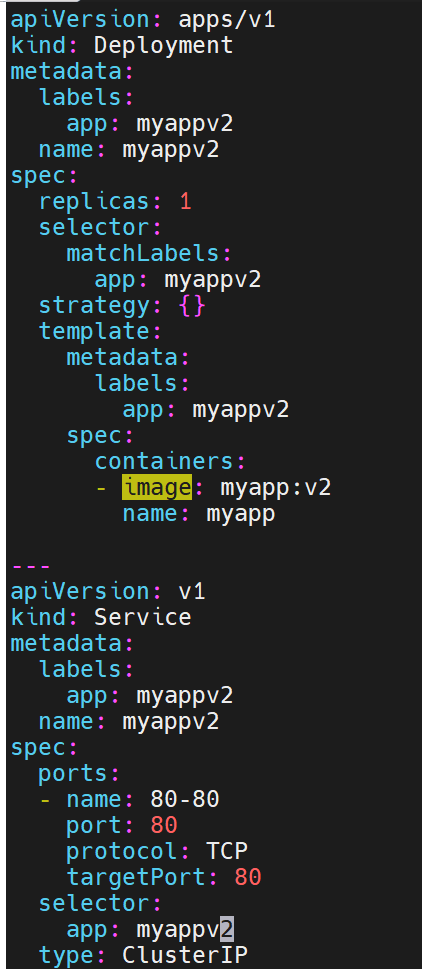
追加内容,此时微服务和控制器就在一个配置文件里了

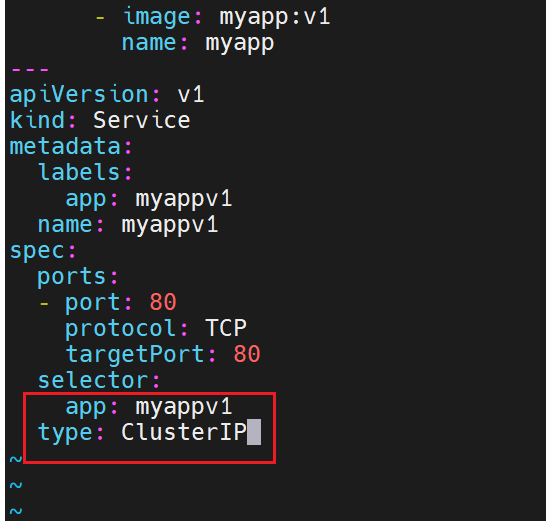
只有集群内部的IP,集群外部的不暴露
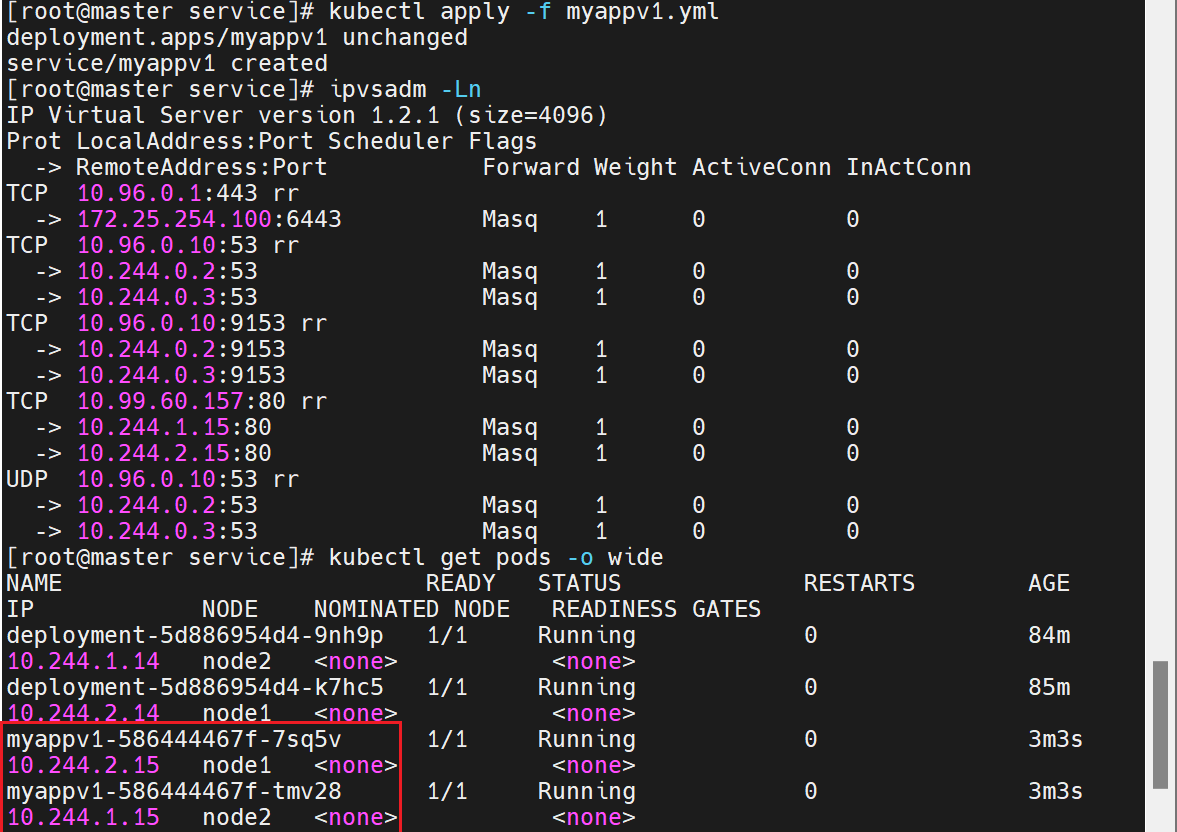
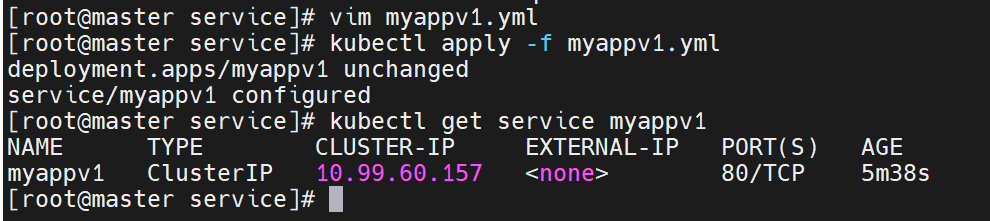
查看clusterIP是否成功
- 这个虚拟 IP(10.99.60.157)在集群内部是可访问的(从 master 节点能成功 curl 通,说明 ClusterIP 有效)
- Service 已正确关联后端 Pod(返回
Hello MyApp | Version: v1证明请求被转发到了myapp:v1镜像的 Pod 并处理)
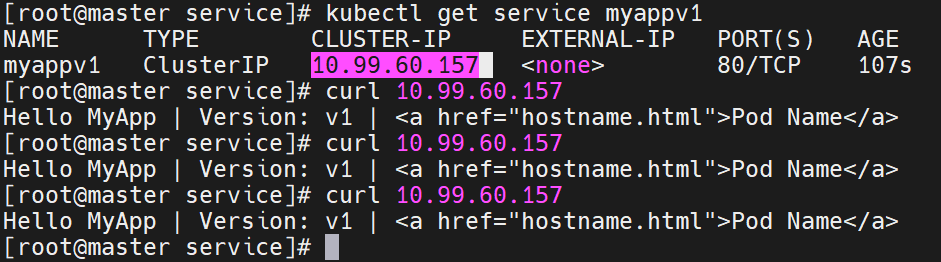
ClusterIP 服务的内部通信机制
- 集群内部的客户端(如其他 Pod、节点上的进程)想要访问
myappv1服务时,会使用 Service 的 ClusterIP:10.99.60.157:80。- 请求到达任意节点的内核时,IPVS 规则会匹配
10.99.60.157:80,并按轮询策略将流量转发到后端的两个 Pod(10.244.1.15:80 或 10.244.2.15:80)。- Pod 处理请求后,通过反向 NAT 将响应返回给客户端,客户端全程只感知 ClusterIP,无需知道具体 Pod 的 IP(即使 Pod 重建、IP 变化,Service 也会自动更新转发规则)。
想要访问发布,可以手动加入
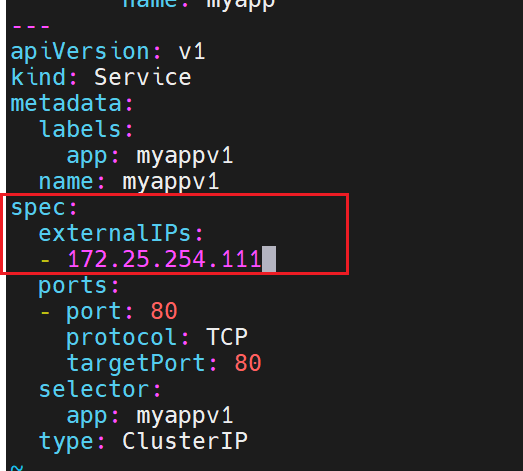
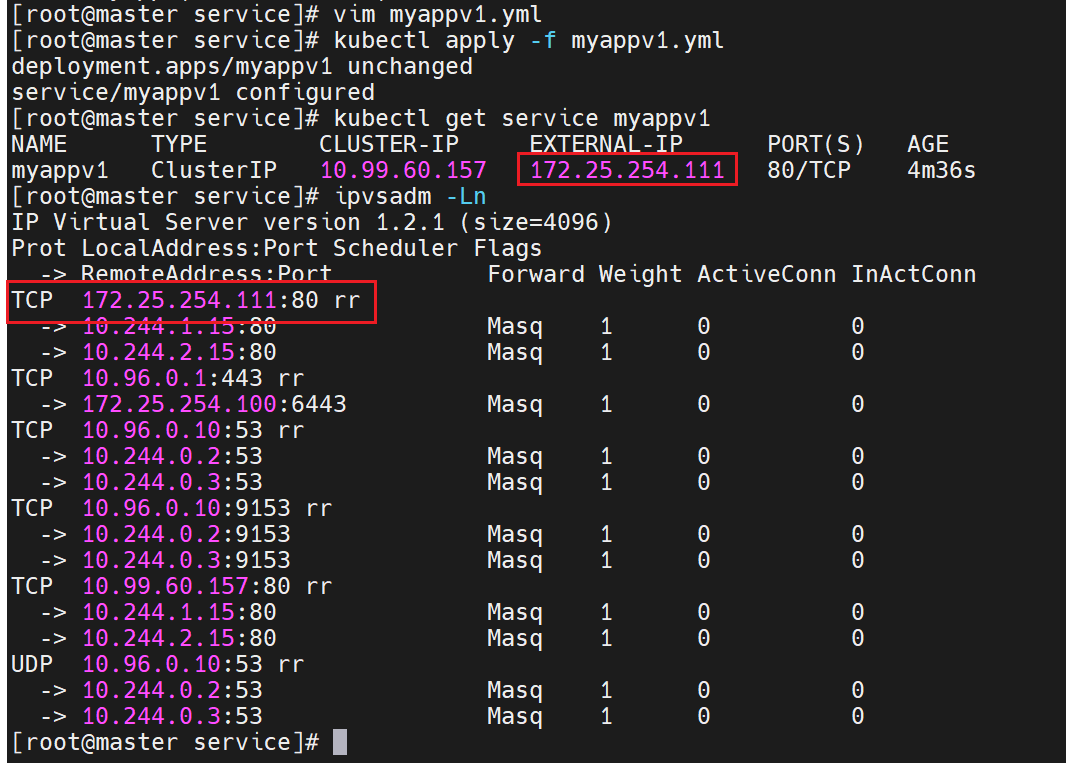
172.25.254.111:Service 的 **ExternalIP(**手动配置的外部可访问 IP)
10.244.1.15、10.244.2.15:Deploymentmyappv1管理的两个 Pod 的实际 IP(容器运行的真实 IP)ClusterIP 类型的 Service 核心作用是:提供一个固定的虚拟 IP(ClusterIP),通过标签关联动态变化的 Pod,并通过 IPVS 实现负载均衡 。数据传输的核心路径是:
客户端 Pod → ClusterIP(10.99.60.157)→ IPVS 负载均衡 → 后端 Pod(10.244.1.15/2.15)
如果不写,对外的IP就没了
默认情况下,只对集群内部的访问生效
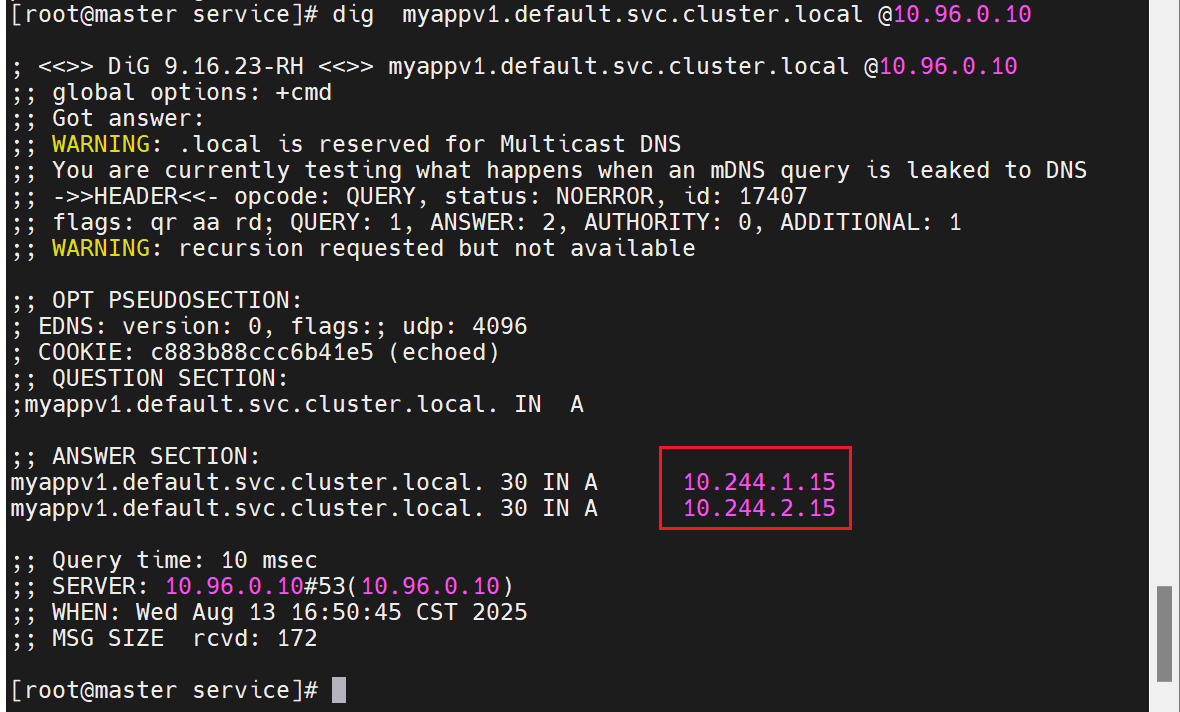
前面是微服务的名称加上命名空间,对微服务进行域名解析,能解析到她的IP
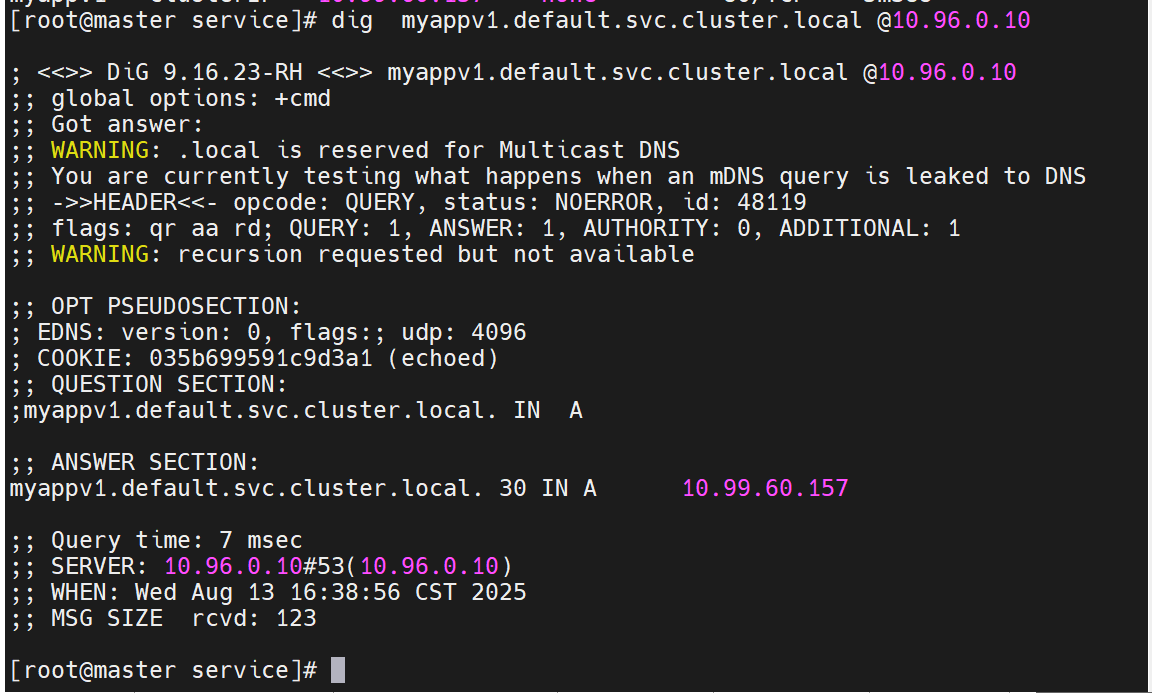
ClusterIP中的特殊模式headless
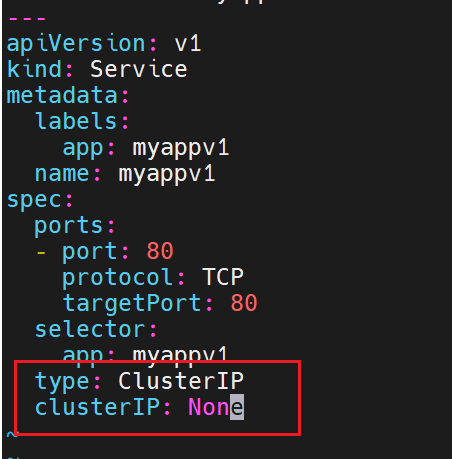
之前有了无头服务,要删掉,不然影响实验
没有了IP以后,后端就没有调度了
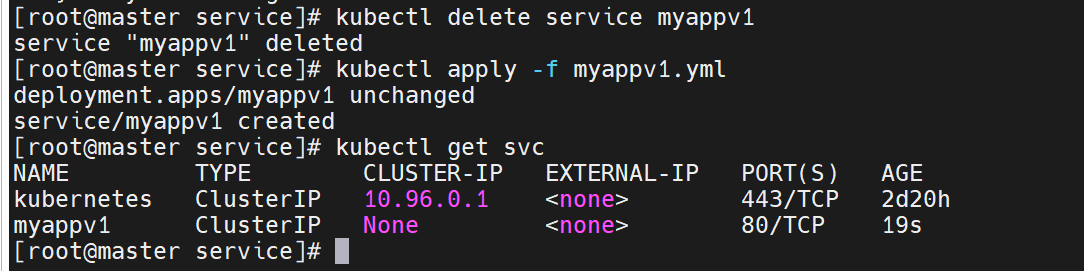
此时我们可以用dns来写,把要访问的server直接指定到后端的服务器中去
#开启一个busyboxplus的pod测试

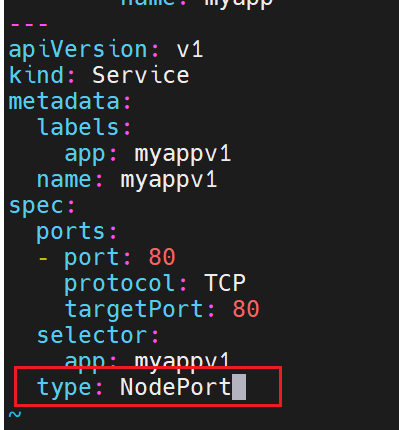
nodeport
之前的服务设置了无头服务,这里要删除之前环境,重新运行
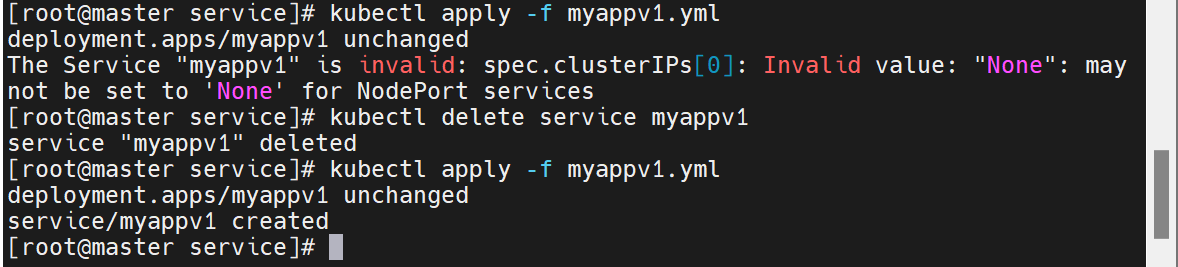
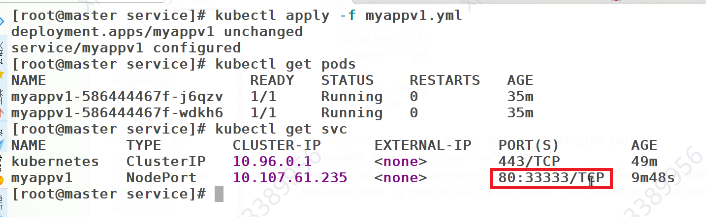
多了一个端口

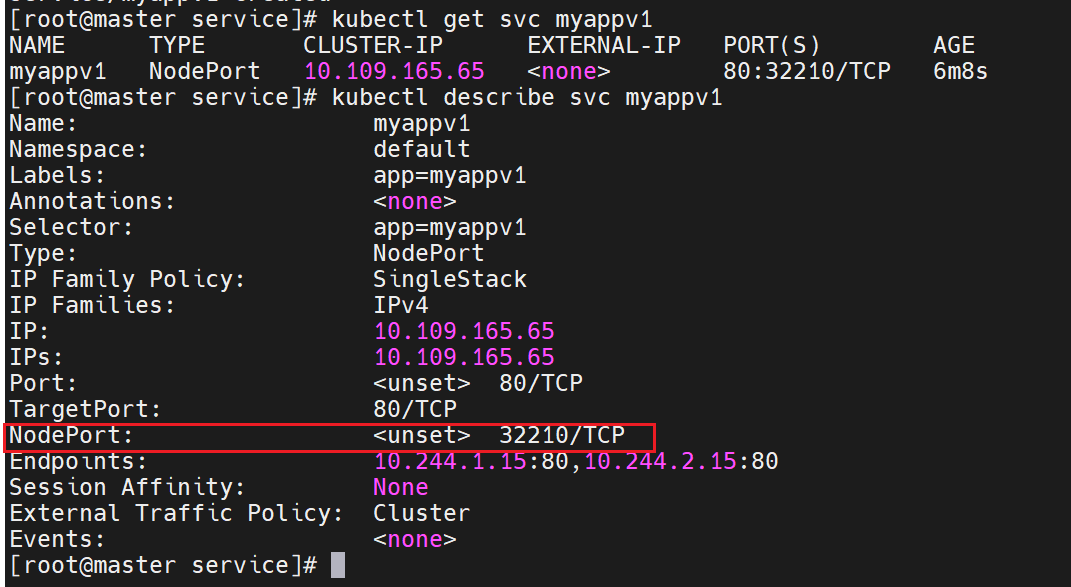
这个端口用来直接对外暴露

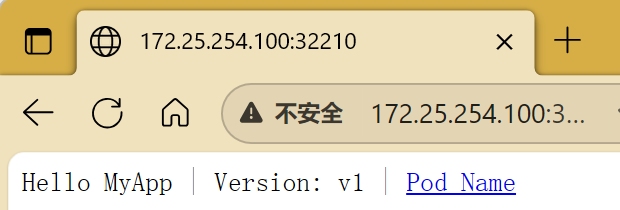
nodeport在集群节点上绑定端口,一个端口对应一个服务
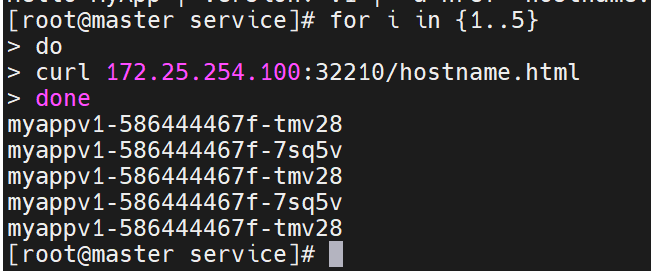
直接负载到下面两个
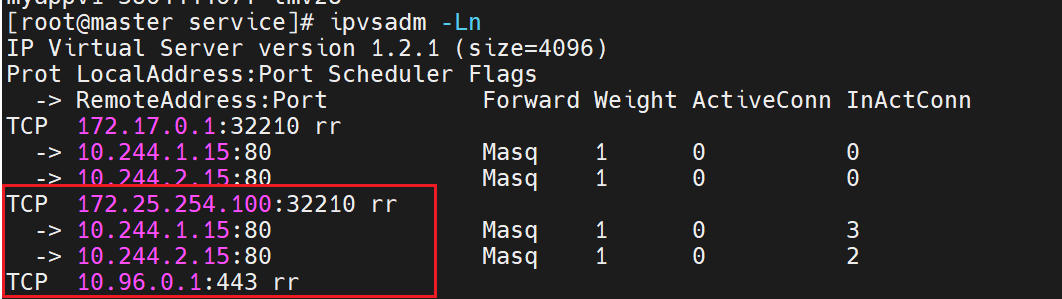
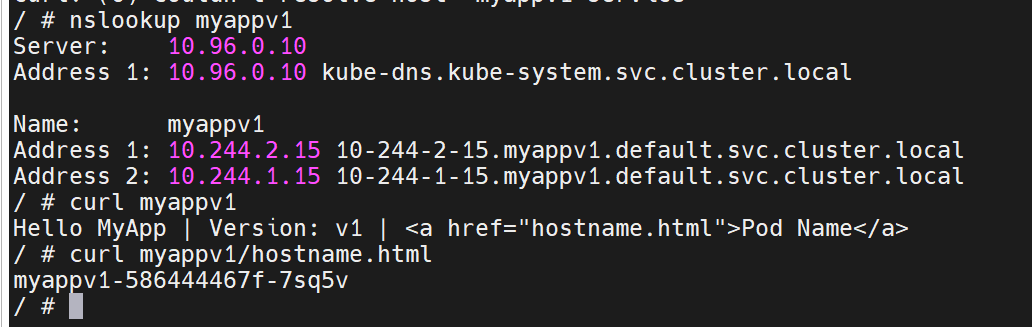
用clusterip来访问后端的
访问模式

对应的端口是不固定的,但是我们可以直接指定,但是有范围限制最大30000
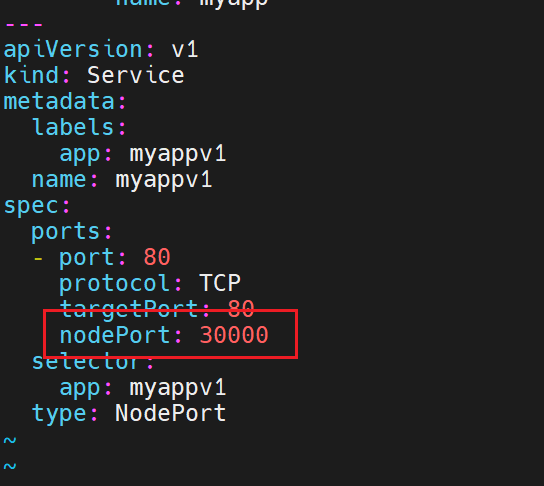

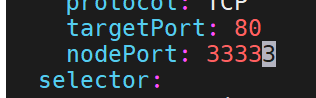

但是想要超过限制也可以,修改配置文件就行。但是集群会挂掉,要等待自愈


加上这句话- --service-node-port-range=30000-40000
刚刚还不能超过的限制,现在就可以了
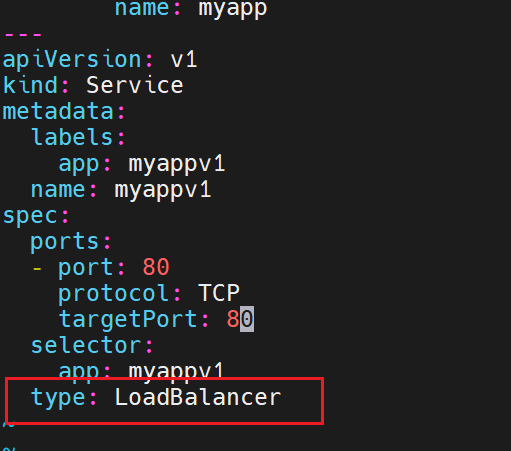
loadbalancer
没有云平台的情况
有云平台的情况,把服务搭建到云平台上,云平台会给一个自动分配对外ip的业务
状态正在获取,默认无法分配外部访问IP

可以访问,但是对外访问时,并不好做

如果主机没有IP,可以用dhcp来分配,但是此时集群中没有,所以我们要做一个类似的
metaILB
部署安装
必须要把集群做成ipvs的模式

并且重启网络方面的pod


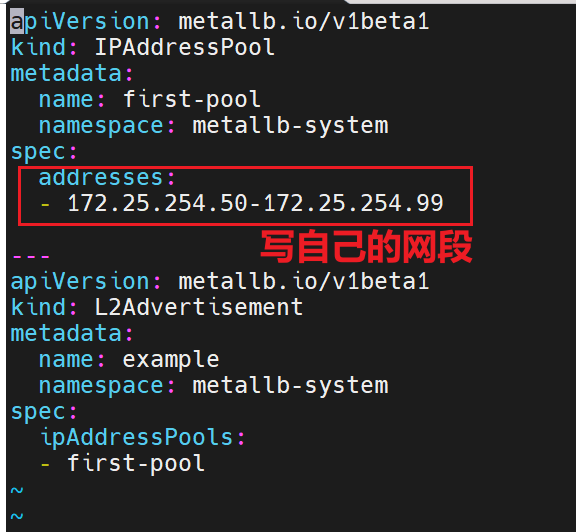
这个文档里的路径已经修改好了,如果是未修改的,记得把路径换成自己的软件仓库

这个生效了之后,才能改配置

之前这里还是正在生效,现在已经有了IP

#通过分配地址从集群外访问服务

已经自动分配对外IP
externalname
-
开启services后,不会被分配IP,而是用dns解析CNAME固定域名来解决ip变化问题
-
一般应用于外部业务和pod沟通或外部业务迁移到pod内时
-
在应用向集群迁移过程中,externalname在过度阶段就可以起作用了。
-
集群外的资源迁移到集群时,在迁移的过程中ip可能会变化,但是域名+dns解析能完美解决此问题
集群内部的IP在访问时,做的是域名解析
把真实的微服务转化成其他主机上
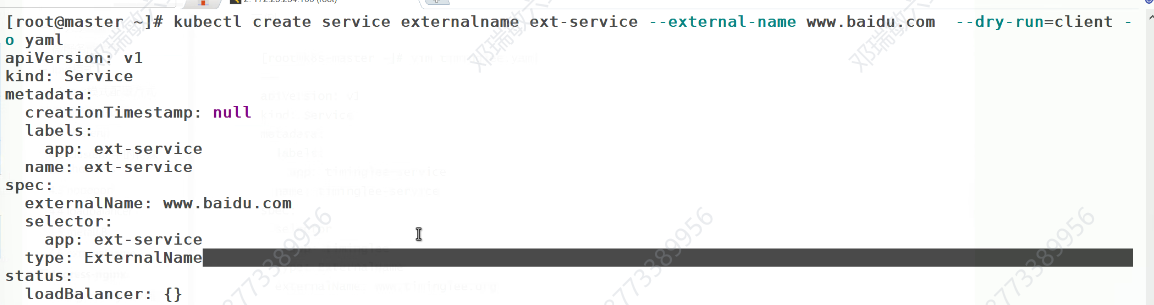

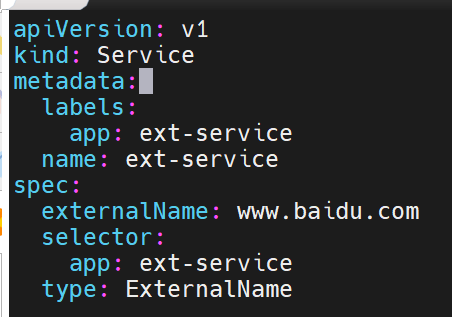
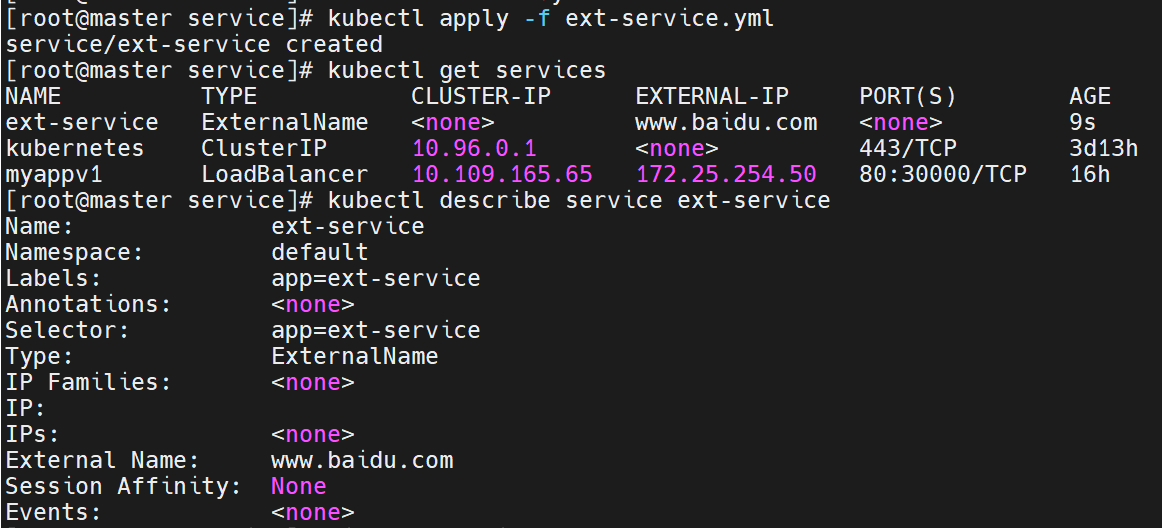
没有IP时如何被访问的,通过dns的域名解析
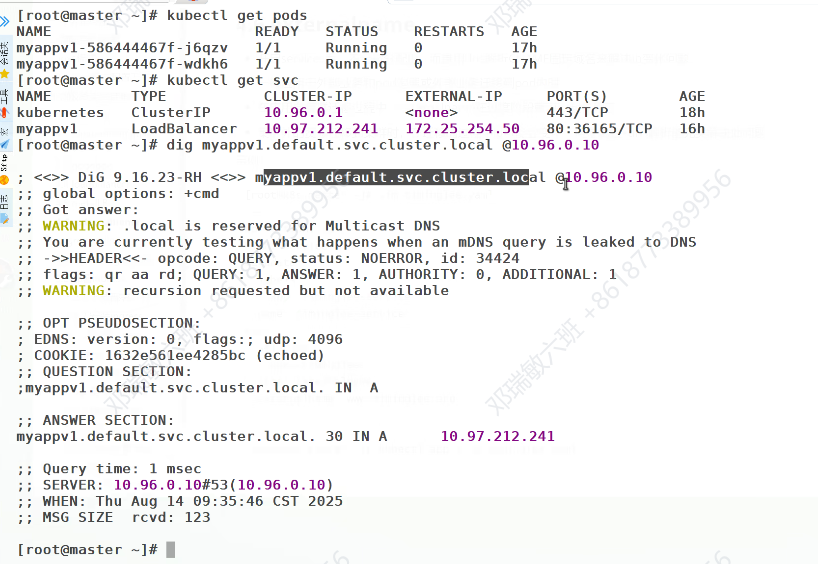
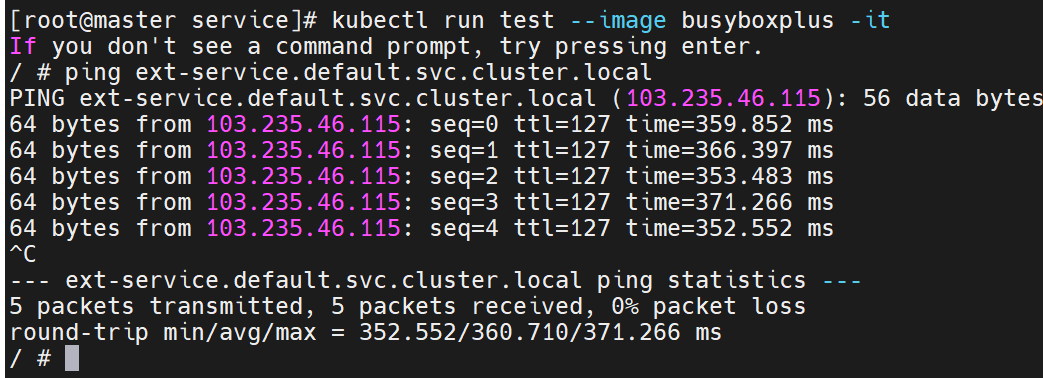
验证 DNS 解析
这行命令测试 Kubernetes 集群内部 DNS(
10.96.0.10是集群 DNS 服务的 IP)是否能正确解析ext-service对应的域名:
- 结果显示
ext-service.default.svc.cluster.local(集群内部服务域名)被解析为www.baidu.com- 最终解析到百度的实际 IP 地址(
103.235.46.115和103.235.46.102)
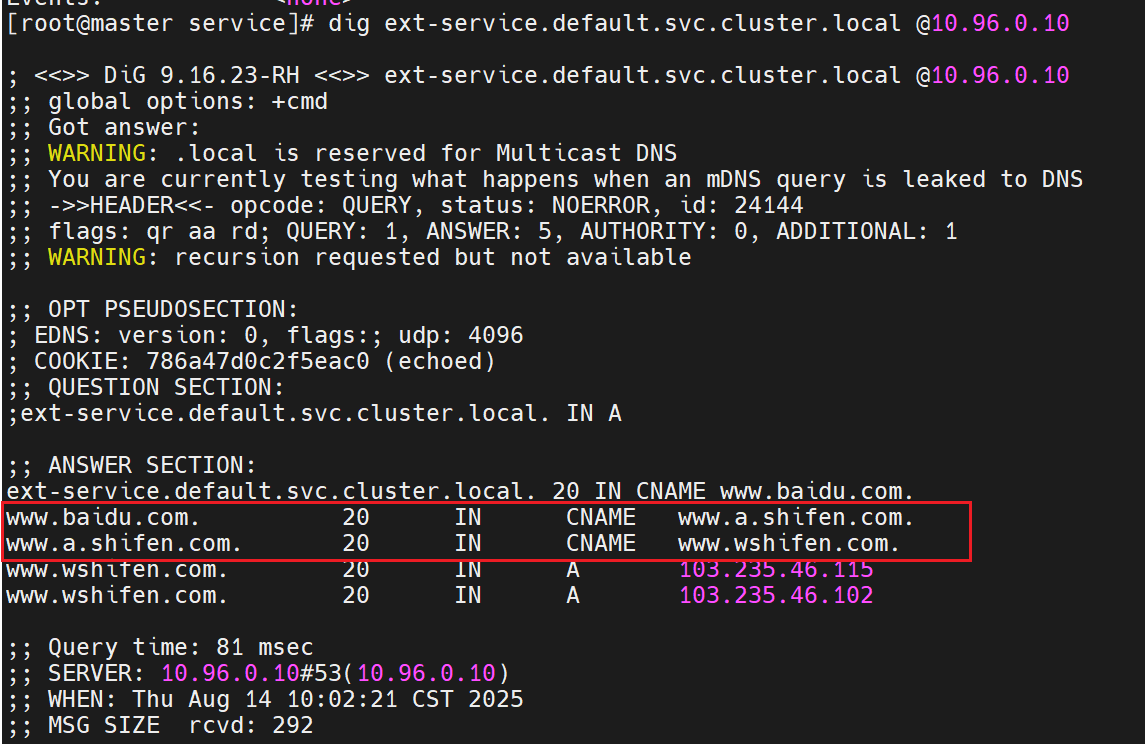
得到了集群内部的主机
微服务把集群外部的资源映射到集群内部,让集群内部可以使用
Ingress-nginx
在service前面在加一个nginx
在集群暴露时,再加一个反向代理
-
一种全局的、为了代理不同后端 Service 而设置的负载均衡服务,支持7层
-
Ingress由两部分组成:Ingress controller和Ingress服务
-
Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。
-
业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为Kubernetes 专门维护了对应的 Ingress Controller。
首先先下载镜像源
在部署文件里




上传ingress所需镜像到harbor

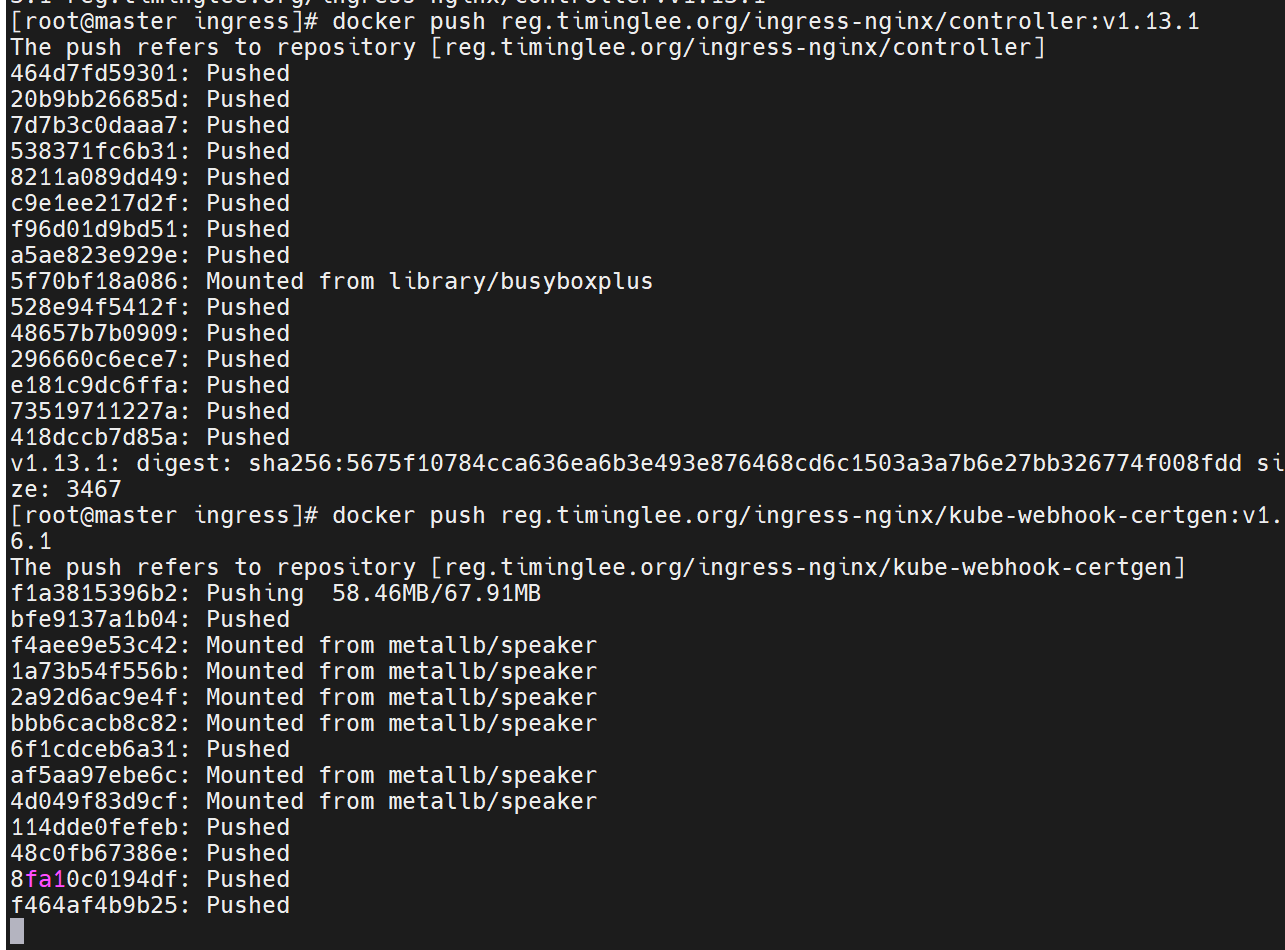
运行配置文件,并且查看是否建立了新的命名空间
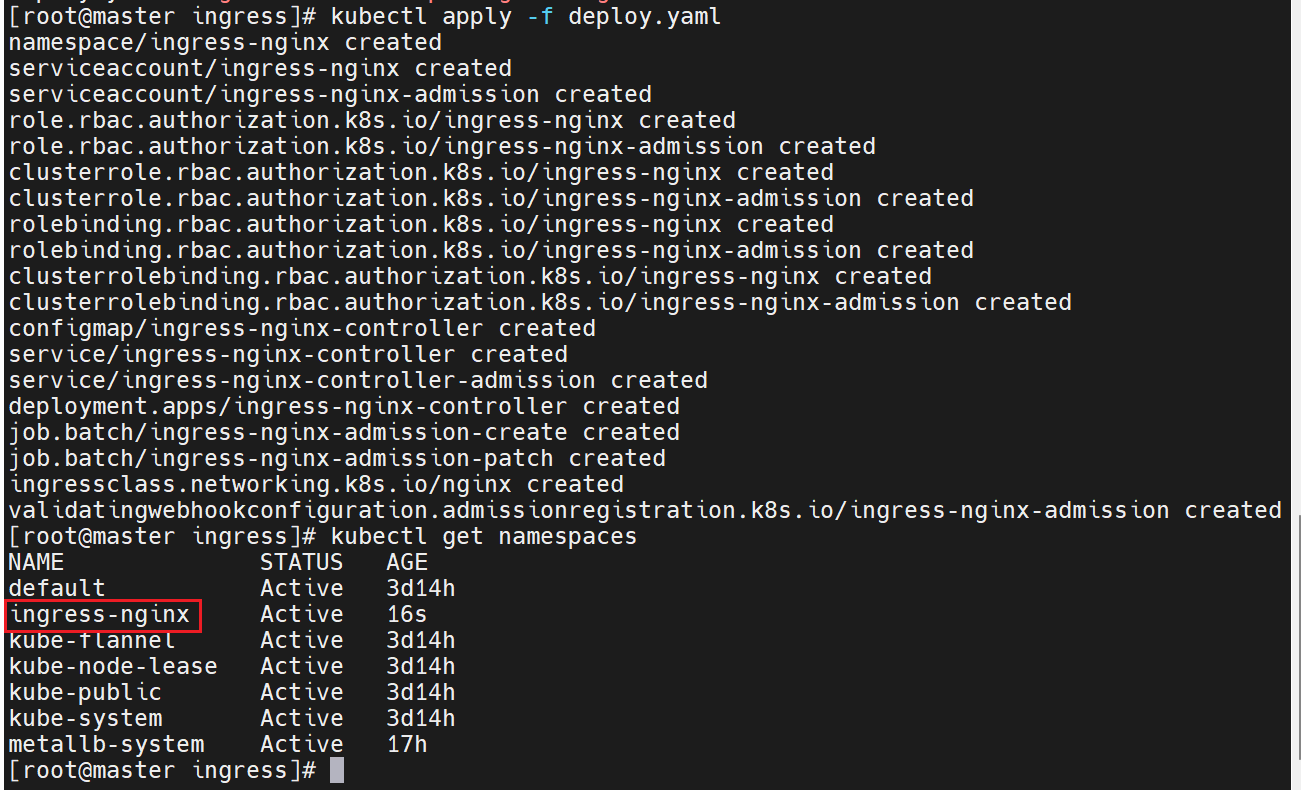
此时查看还是没有对外开放的ip的,因为微服还没有修改,现在还是只能集群内部访问


#修改微服务为loadbalancer
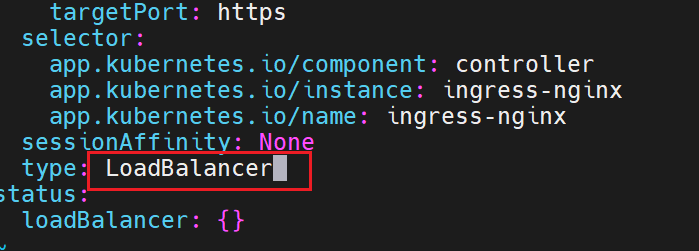
此时就有对外开放的IP了
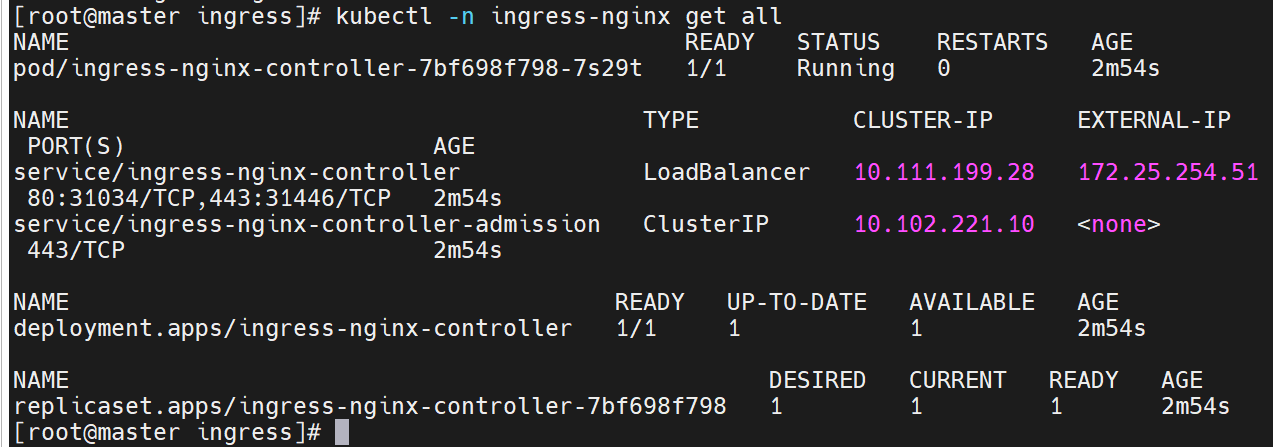
在ingress-nginx-controller中看到的对外IP就是ingress最终对外开放的ip
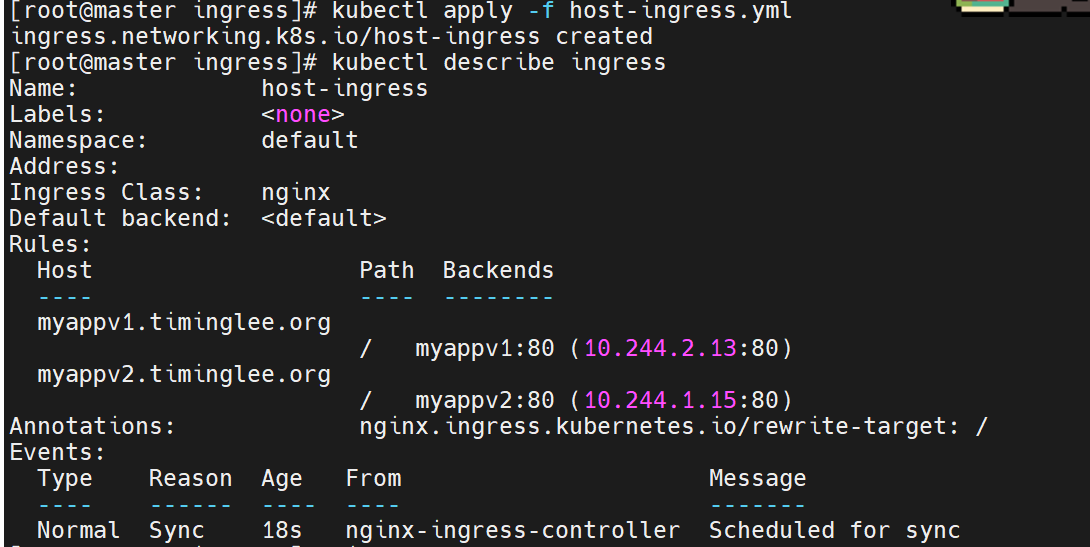
测试ingress
生成一下模板

上面是控制器,下面是微服务

装了两台主机,两台主机呈现不同web页面
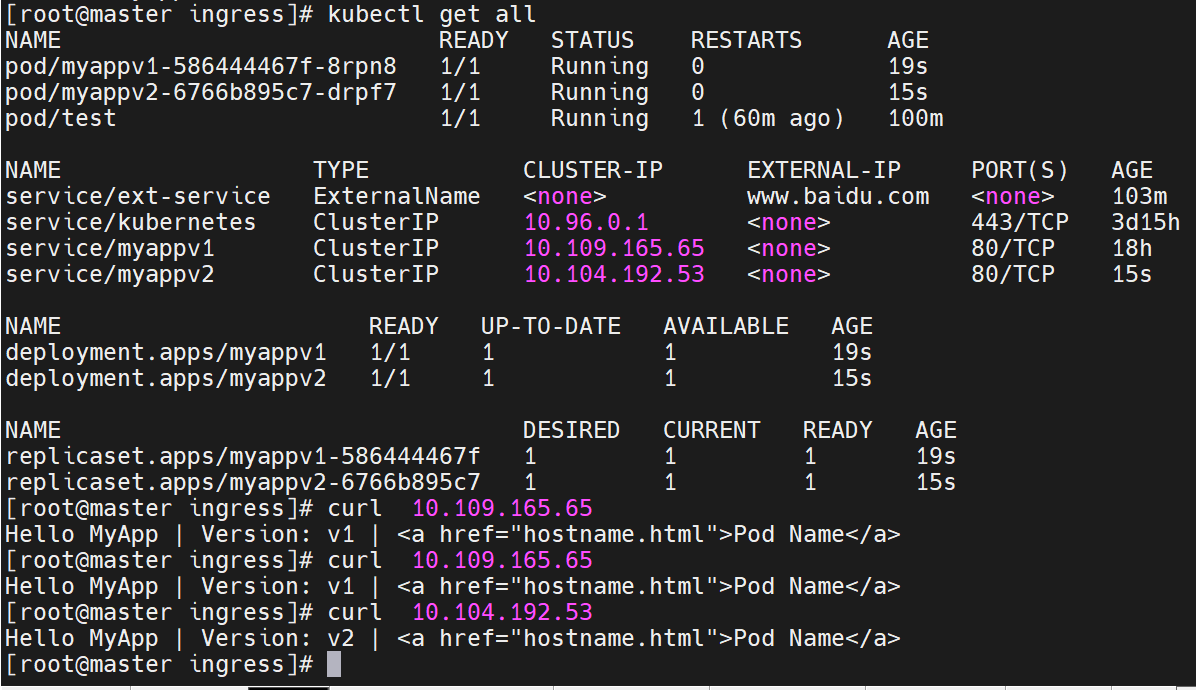
核心动作都是nginx完成的

调用nginx类,访问微服务的80端口

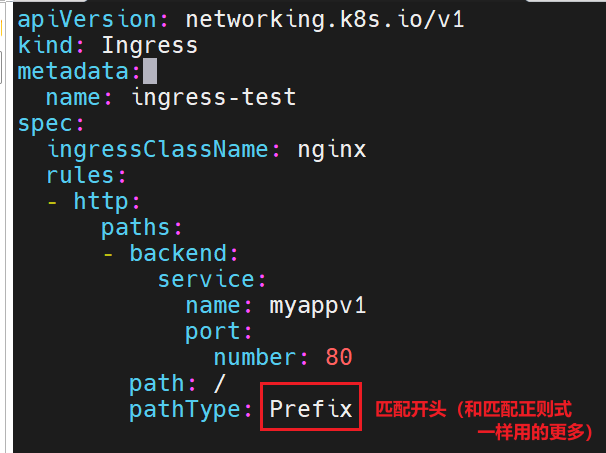
当我们去访问我们刚刚设立的对外IP时,它带我们去看的时myappv1的80端口里的内容
确认 IngressClass
- 执行
kubectl -n ingress-nginx get ingressclasses,确认集群中存在nginx类型的 IngressClass(控制器为k8s.io/ingress-nginx),为后续 Ingress 配置提供基础。创建 Ingress 规则
- 通过
kubectl create ingress生成ingress-test.yml,定义规则:将外部访问的根路径/映射到内部服务myappv1:80,并指定 IngressClass 为nginx。- 应用配置后,Ingress 资源
ingress-test创建成功,规则生效(外部访问/指向myappv1的 Pod)。
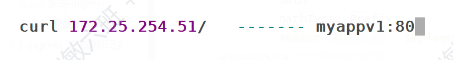
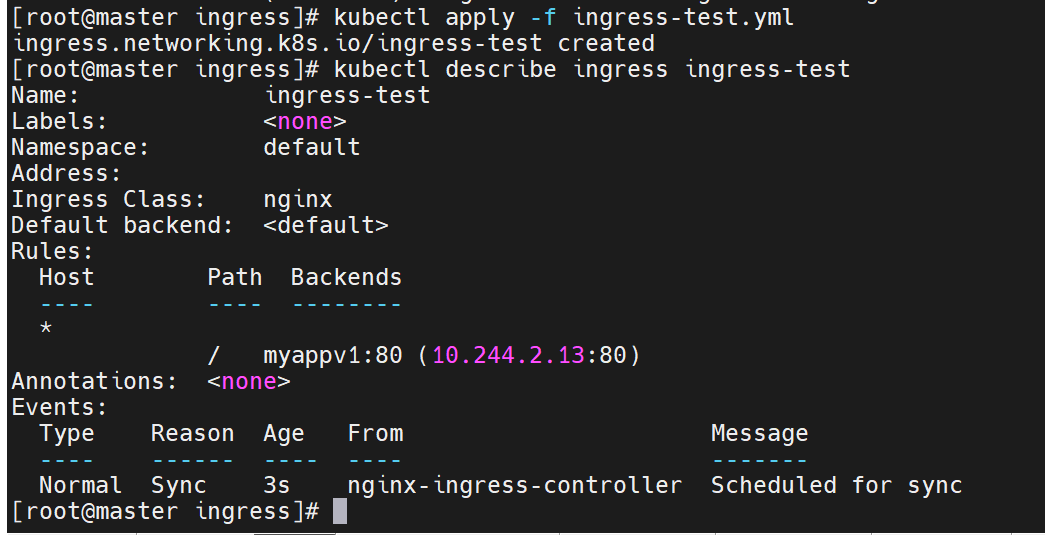

- 执行
curl 172.25.254.51(外部访问 IP),返回v1版本响应,确认通过 Ingress 成功从集群外部访问到myappv1。
ingress 的高级用法
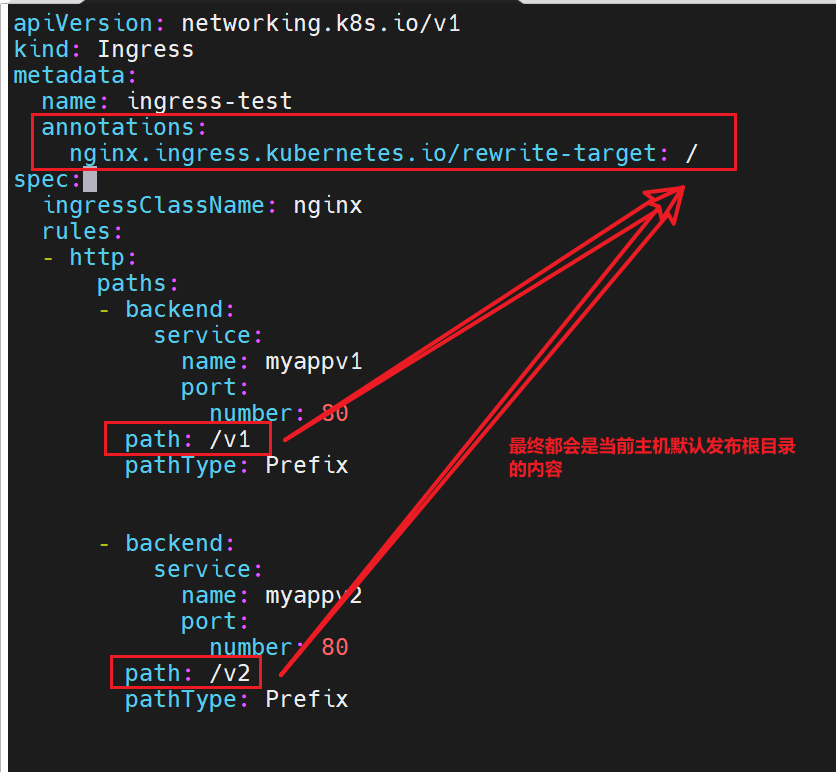
backend可以写无数个
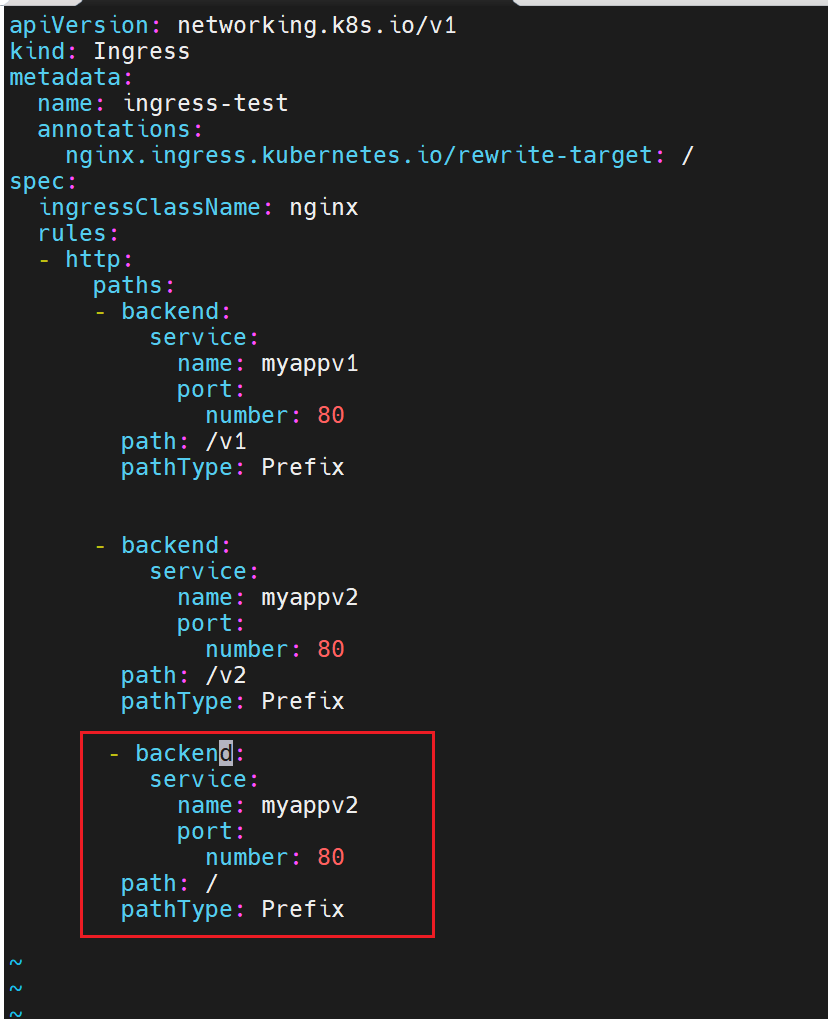
虽然我们这里写了不同的目录,但是实际上在这里,目标主机里的默认发布并没有我们设定的目录,访问一定不成功,所以我们可以设定无论访问什么目录,最终都指向我们根目录下的内容,这样无论写什么目录,都能访问到要去的主机里根目录的内容
基于路径的访问

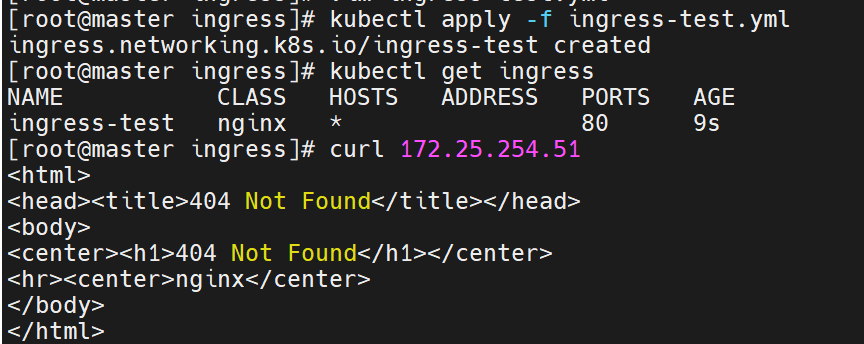
此时直接访问是不行的,因为没有设定默认发布目录
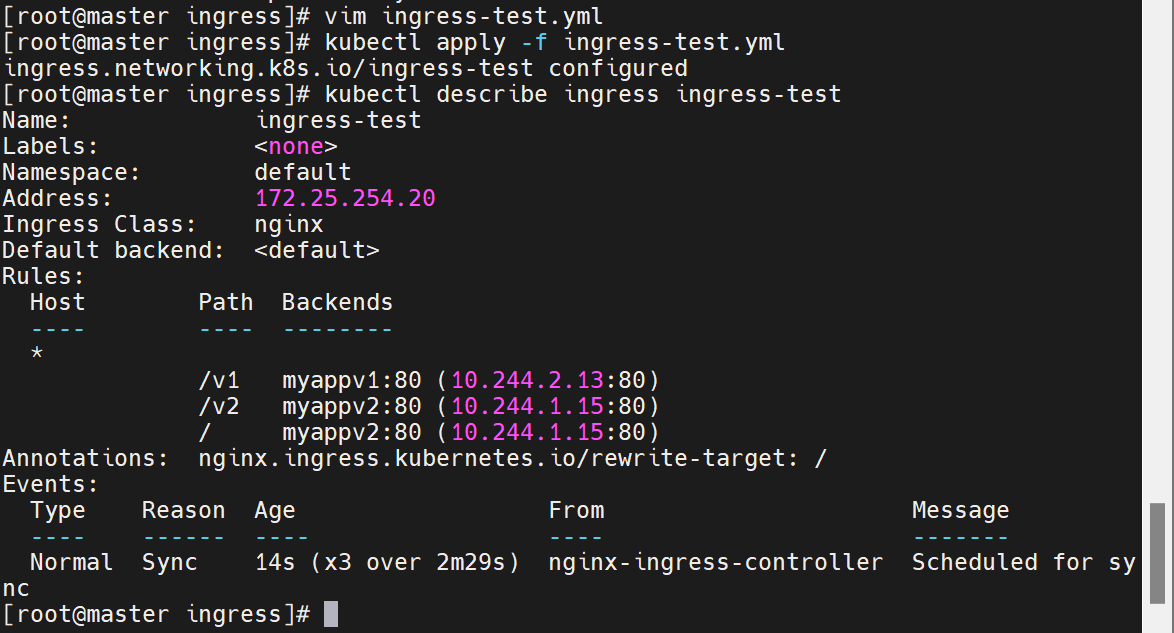
可以设定一下

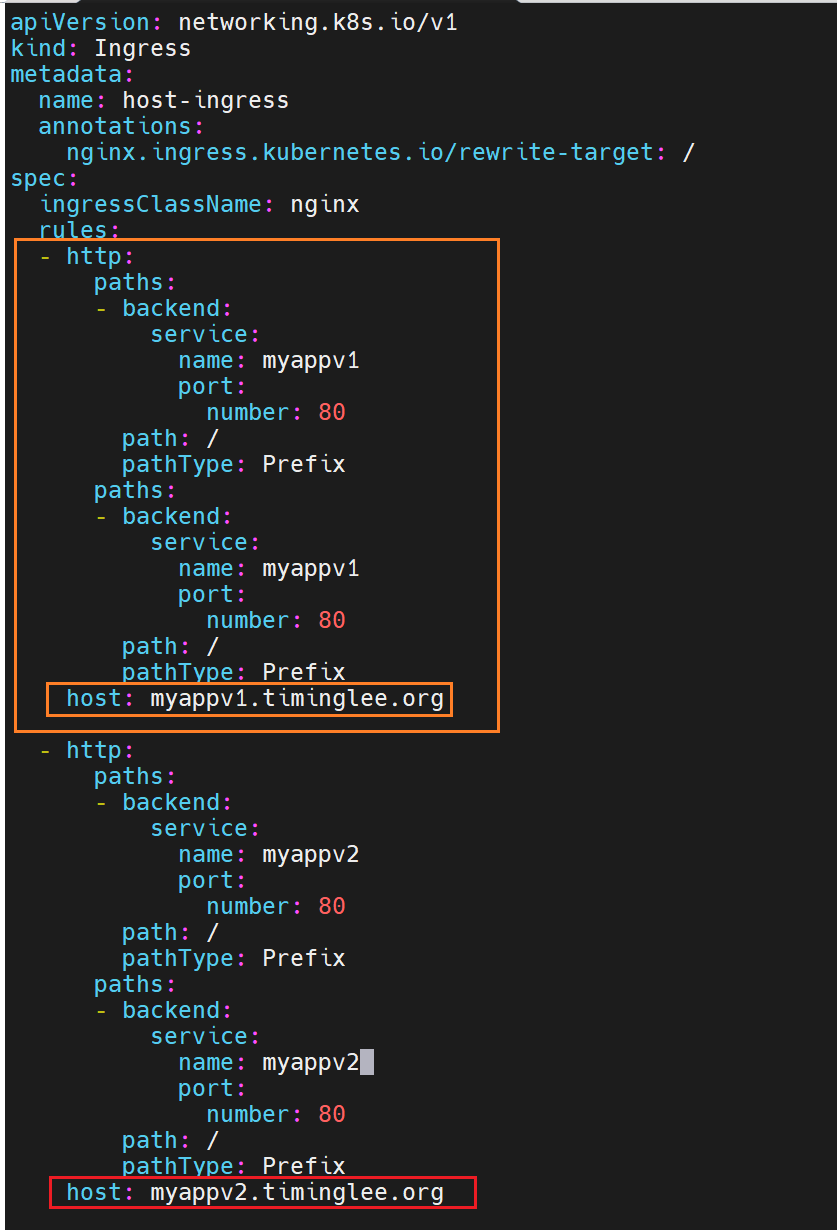
基于域名的访问

子集写在最前面也行,写最后面也行
此时我们

建立tls加密
生成证书去加密
设置非交互式输入
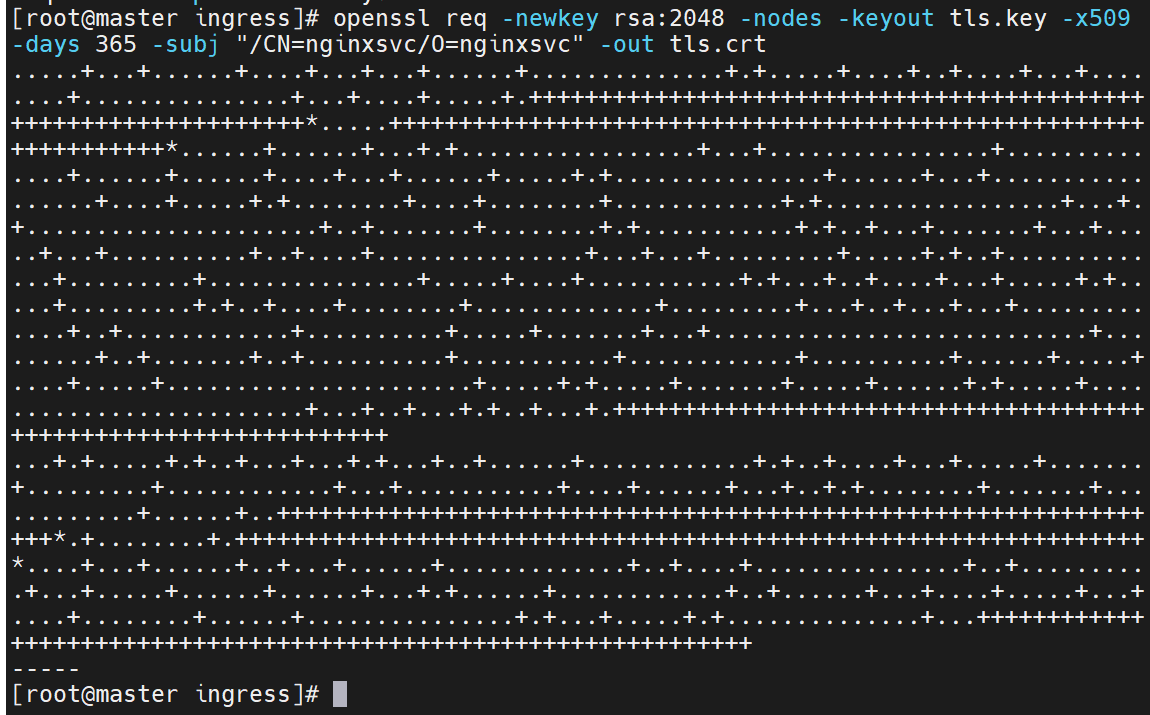
此时生成的证书与集群无关

把证书变成资源,能被集群调用

里面有两个文件
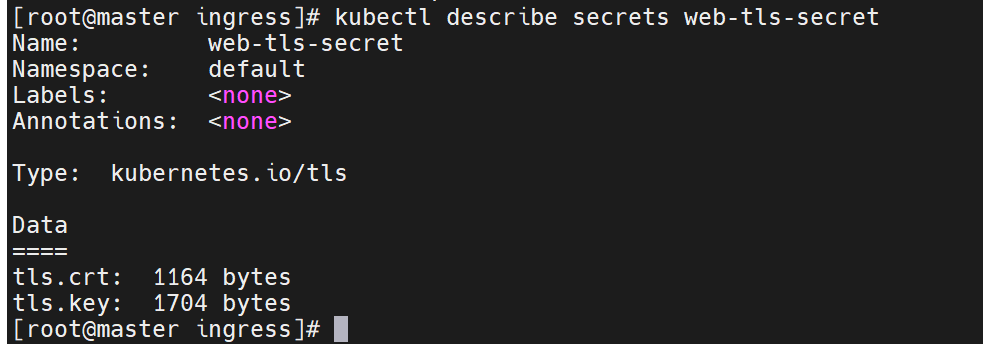
查看资源信息,它们以键值的方式保存了
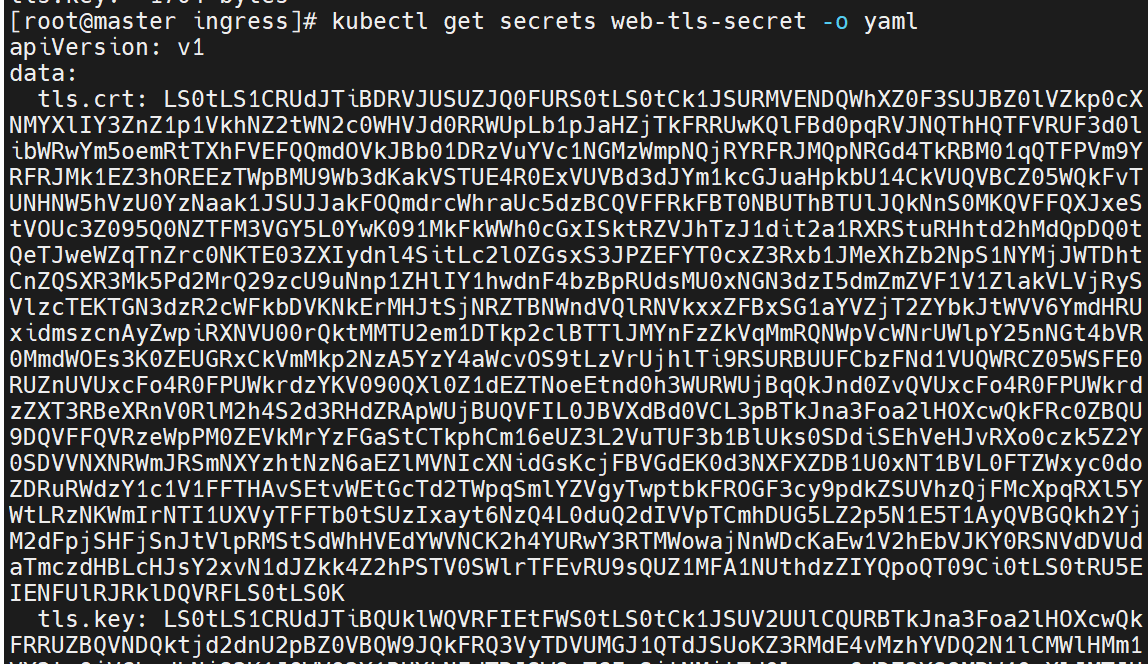

要把加密的模式保存到配置文件中去
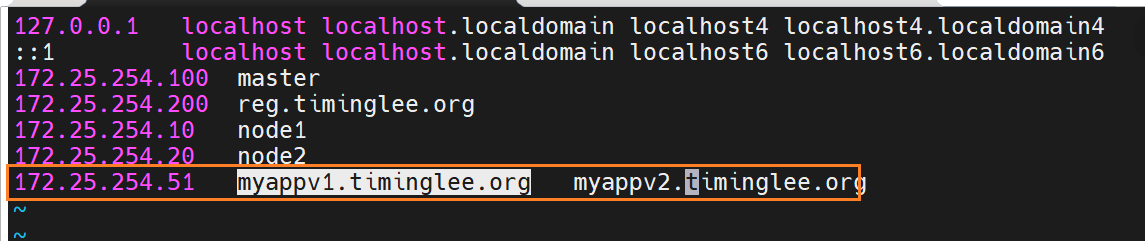
一次性可以给多个设备加密 host
最终要调用的资源里的证书
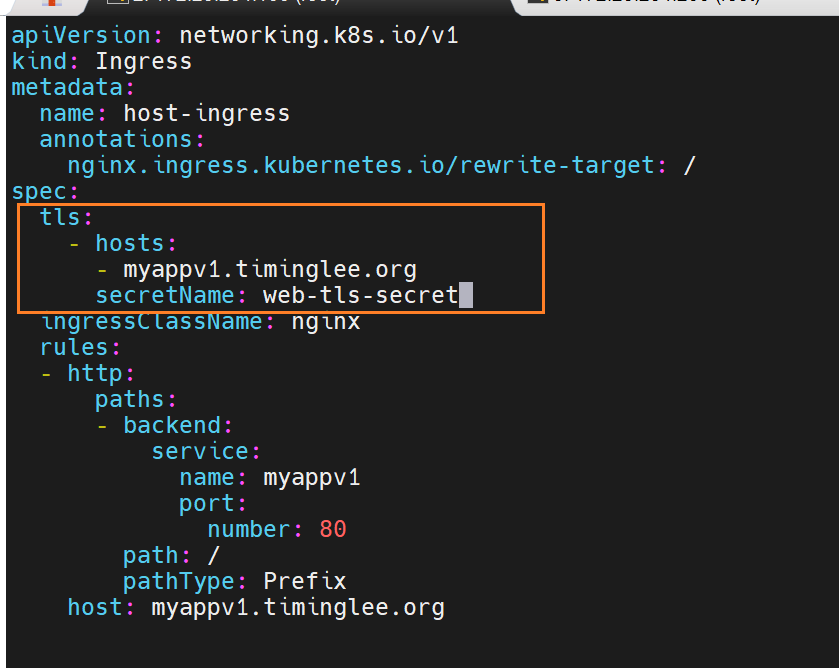
查看新建的ingress的详细情况,是否加密成功
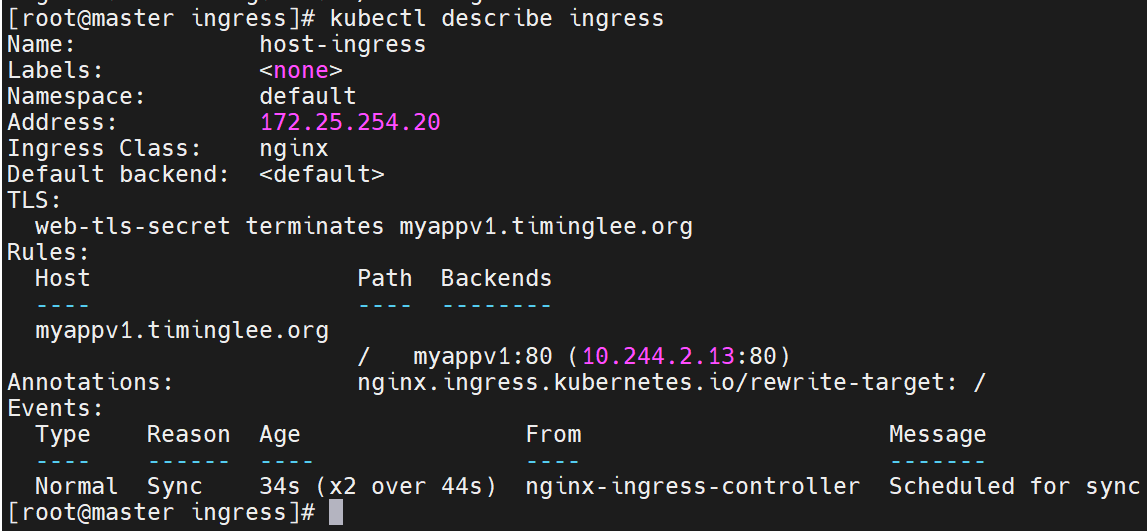
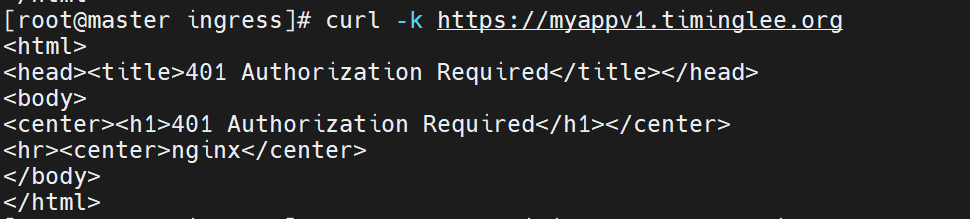
此时直接访问已经不行了

https://表示使用 HTTPS 协议 访问,符合 Ingress 配置中强制 HTTPS 的要求,因此不会被重定向。-k参数的作用是 跳过 SSL 证书验证 。如果你的 Ingress 使用的是自签名证书(而非可信 CA 颁发的证书),curl会默认验证证书并报错(如SSL certificate problem)。加上-k后会忽略证书验证,从而成功建立连接并获取响应。
建立auth认证
用户级别的访问限制
此时的文件还是没有关系和集群

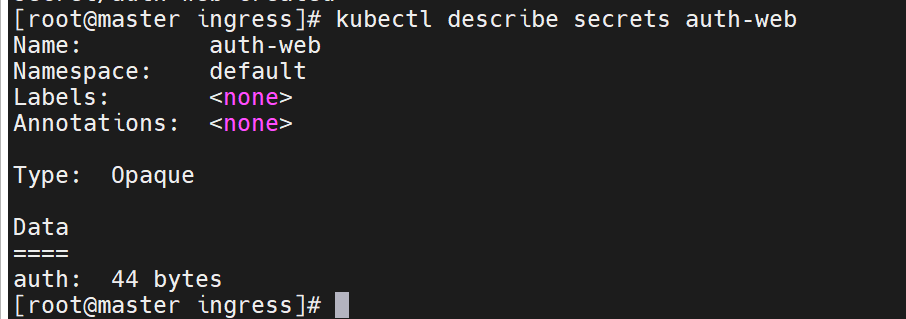
要通过这个命令,把这个叫做htpasswd的文件抽象成集群中的资源


编辑配置文件,要用到参数

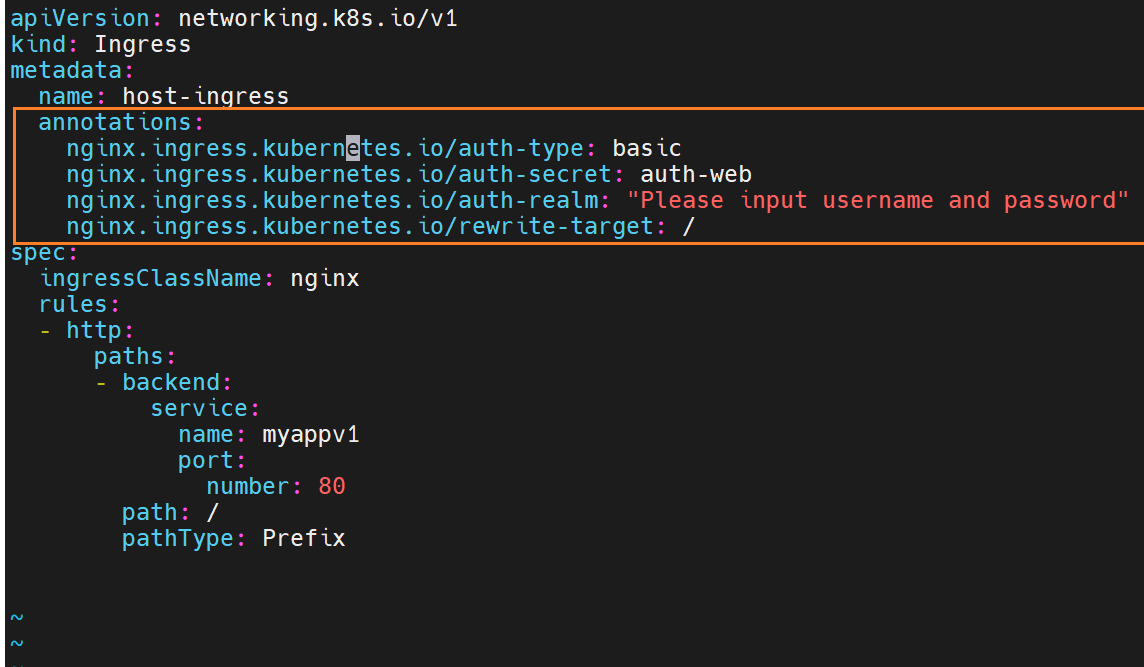 在调用时,也会验证这些参数
在调用时,也会验证这些参数
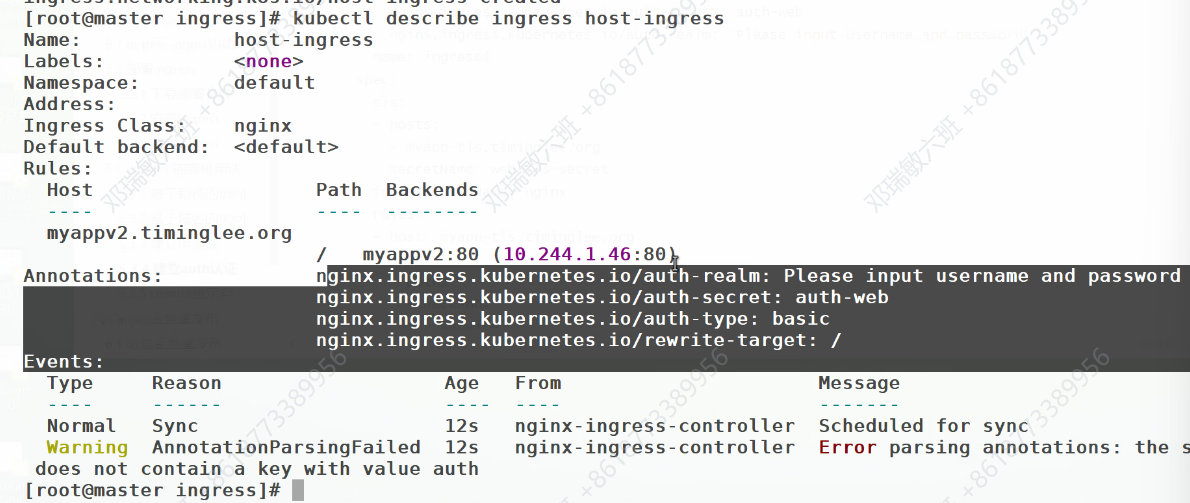
错误情况:
这里会错误,是因为他默认调用auth这个名字,而之前创建用户密码时,储存的文件名不是它,系统此时访问不了
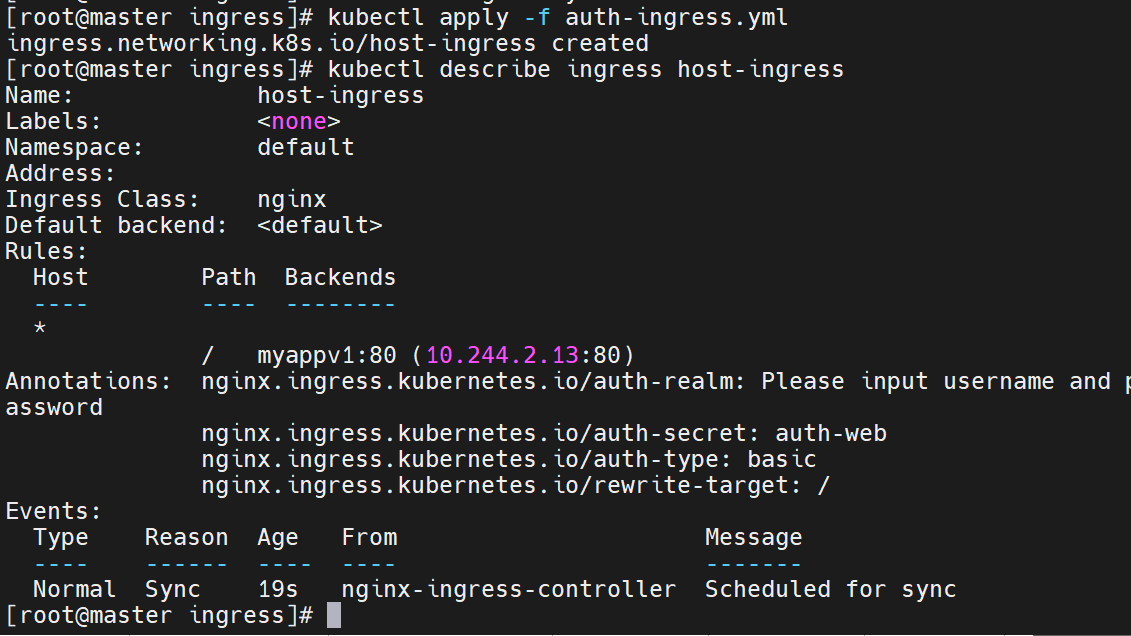
修改名字:
删除之前储存的资源
重新建立资源
删除之前运行的配置文件
重新运行一次就行了





rewrite重定向

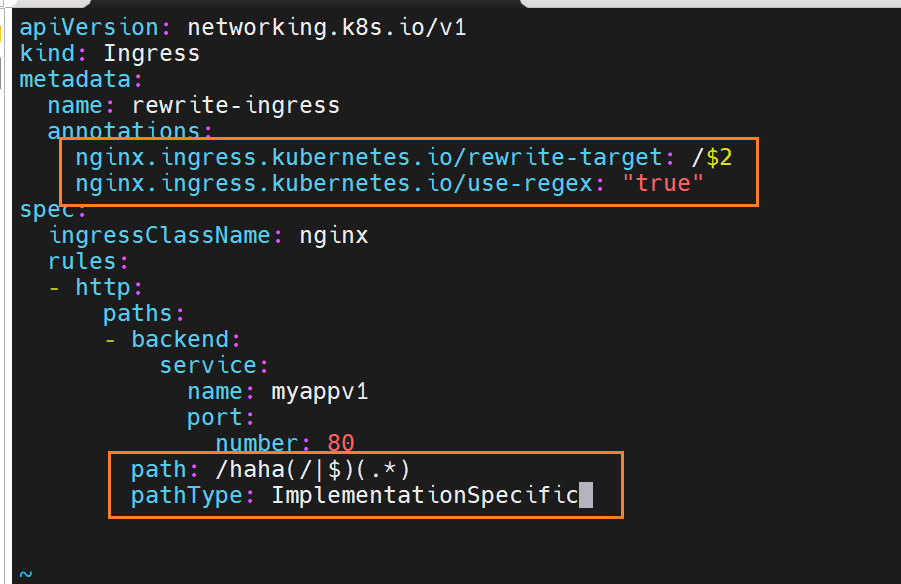
正则表达式主要通过
path字段和rewrite-target注解配合,实现URL 路径的匹配与重写,核心作用是将外部访问的特定路径映射到后端服务的指定路径。具体正则分析:
path: /haha(/|$)(.*)这是用于匹配外部访问 URL 的正则表达式,拆解如下:
/haha:固定前缀,匹配包含/haha的路径(如/haha、/haha/、/haha/abc等)。(/|$):匹配/或字符串结尾($),避免误匹配类似/hahaX的路径:
(/:匹配/haha后的斜杠(如/haha/abc中的/)。$):匹配/haha本身(无后续字符,如/haha)。(.*):捕获/haha/之后的所有字符(任意长度、任意字符),作为第二个分组($2)。
rewrite-target: /$2定义路径重写规则:将匹配到的 URL 重写为
/$2,其中$2对应正则表达式中第二个分组(.*)捕获的内容。实际效果举例:
外部访问的 URL 正则匹配情况 重写后转发到后端服务的路径 后端服务接收的请求 http://域名/haha匹配 /haha($2为空)重写为 /后端服务收到 /请求http://域名/haha/匹配 /haha/($2为空)重写为 /后端服务收到 /请求http://域名/haha/abc匹配 /haha/abc($2为abc)重写为 /abc后端服务收到 /abc请求http://域名/haha/xyz/123匹配 /haha/xyz/123($2为xyz/123)重写为 /xyz/123后端服务收到 /xyz/123请求核心作用:
通过正则表达式的分组捕获和重写规则,实现了 "外部访问路径
/haha/*映射到后端服务的/*路径 " 的效果。这种配置常用于:
- 为不同服务分配统一的路径前缀(如
/serviceA/*、/serviceB/*),避免路径冲突。- 隐藏后端服务的实际路径结构,增强安全性或简化外部访问方式。
配合
nginx.ingress.kubernetes.io/use-regex: "true"注解,开启了 Ingress 对正则表达式的支持,确保上述规则生效。
匹配正则表达式

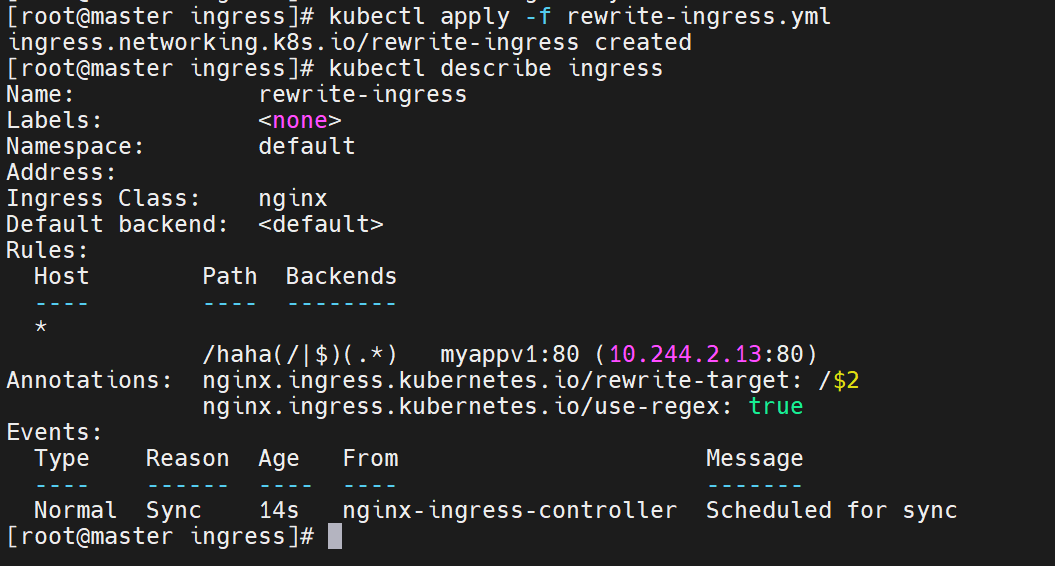
测试:

Canary金丝雀发布
金丝雀发布(Canary Release)也称为灰度发布,是一种软件发布策略。
主要目的是在将新版本的软件全面推广到生产环境之前,先在一小部分用户或服务器上进行测试和验证,以降低因新版本引入重大问题而对整个系统造成的影响。
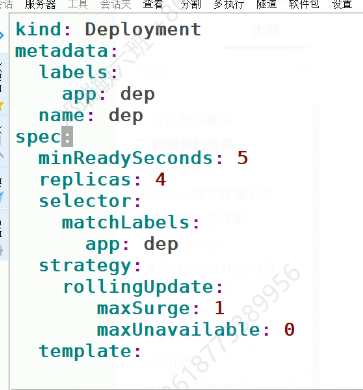
是一种Pod的发布方式。金丝雀发布采取先添加、再删除的方式,保证Pod的总量不低于期望值。并且在更新部分Pod后,暂停更新,当确认新Pod版本运行正常后再进行其他版本的Pod的更新。
Canary发布方式
不同的信息到不同的主机里去
优先级:

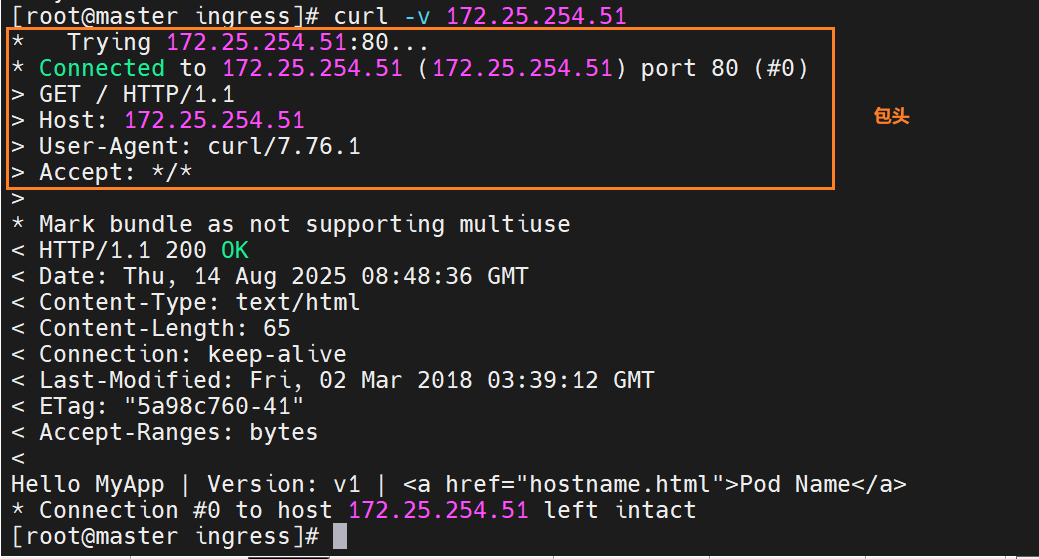
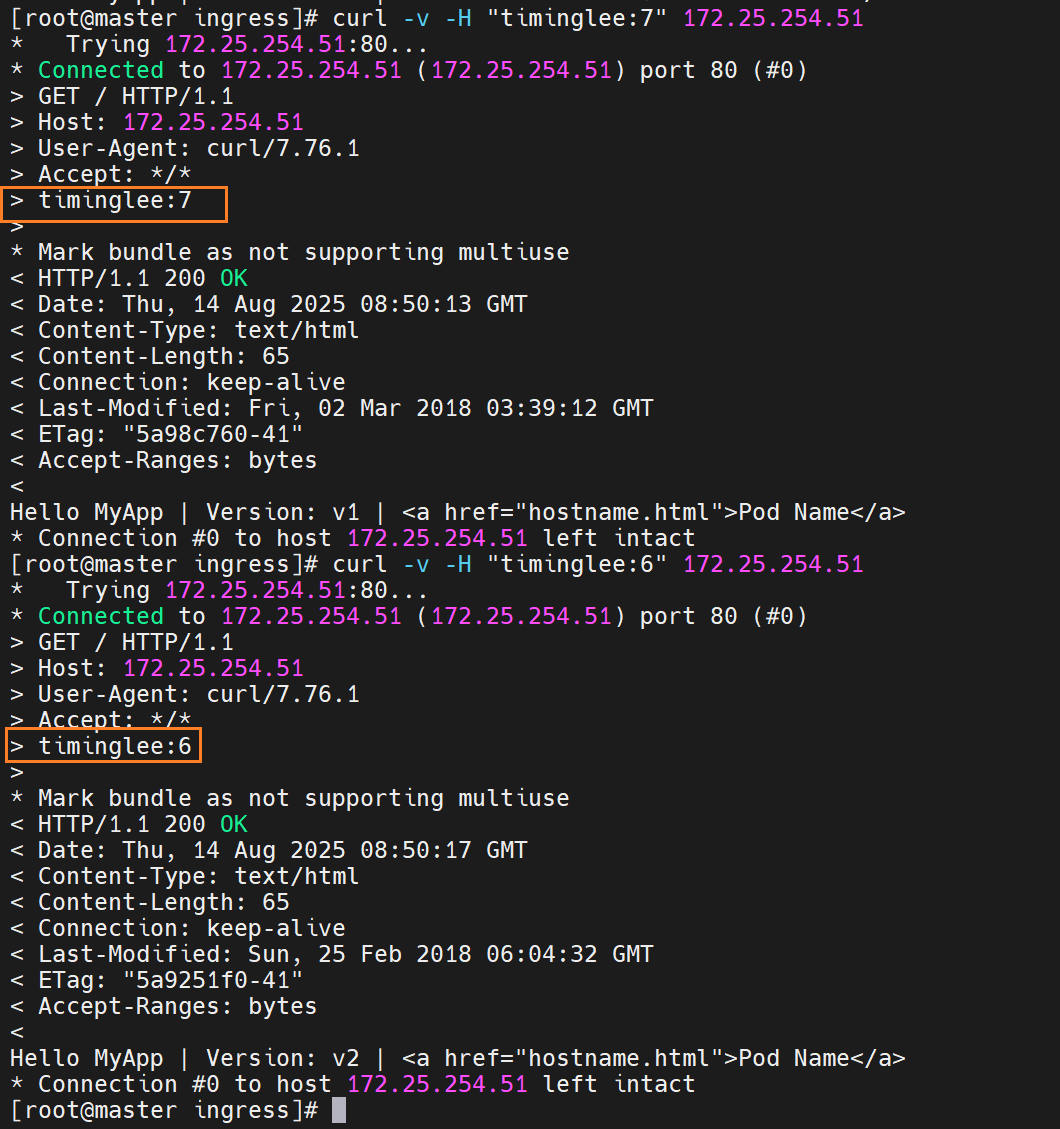
基于header(http包头)灰度
部署老版本的
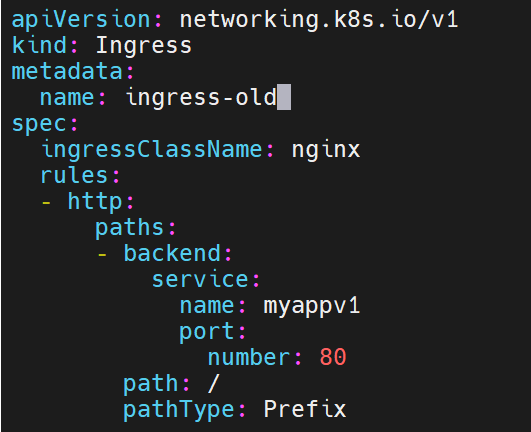


升级后的访问是要基于什么情况下访问
要写参数来设置了
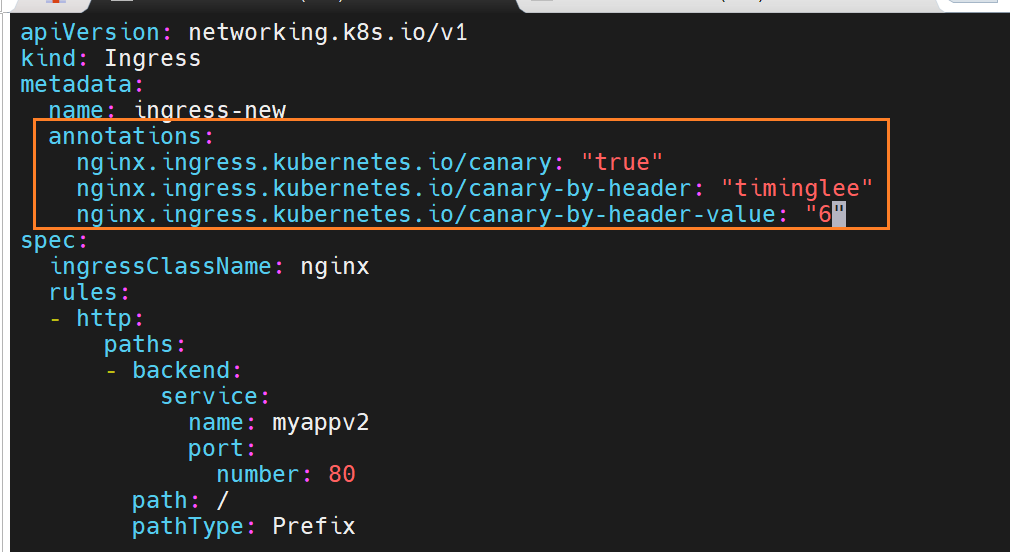

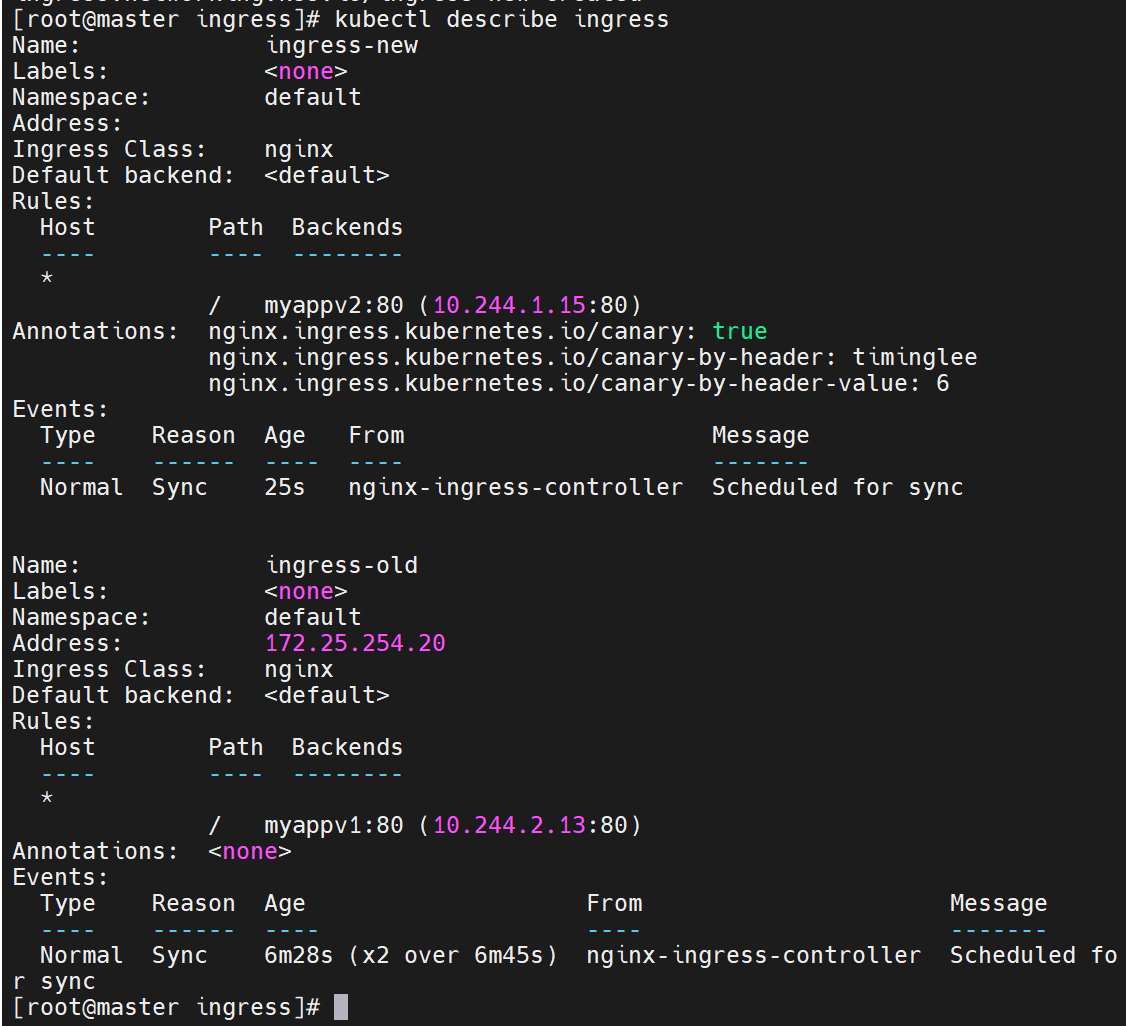
当携带timinglee的值是6时,就访问new的
基于包头灰度发布

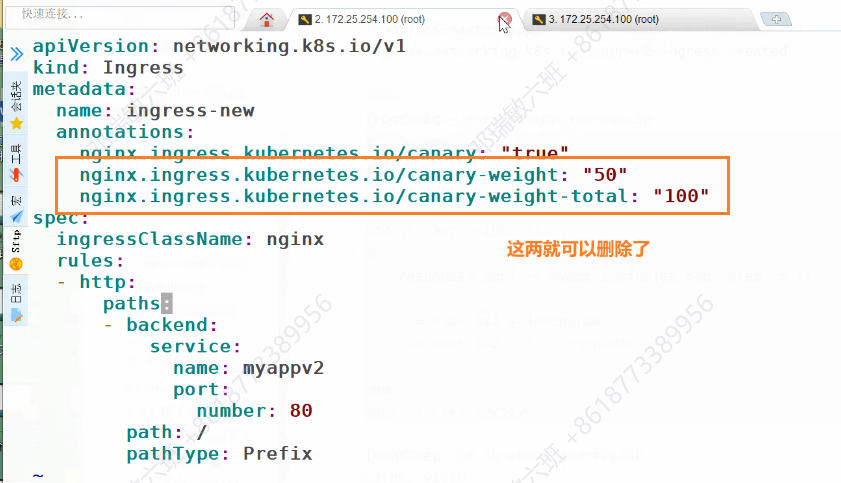
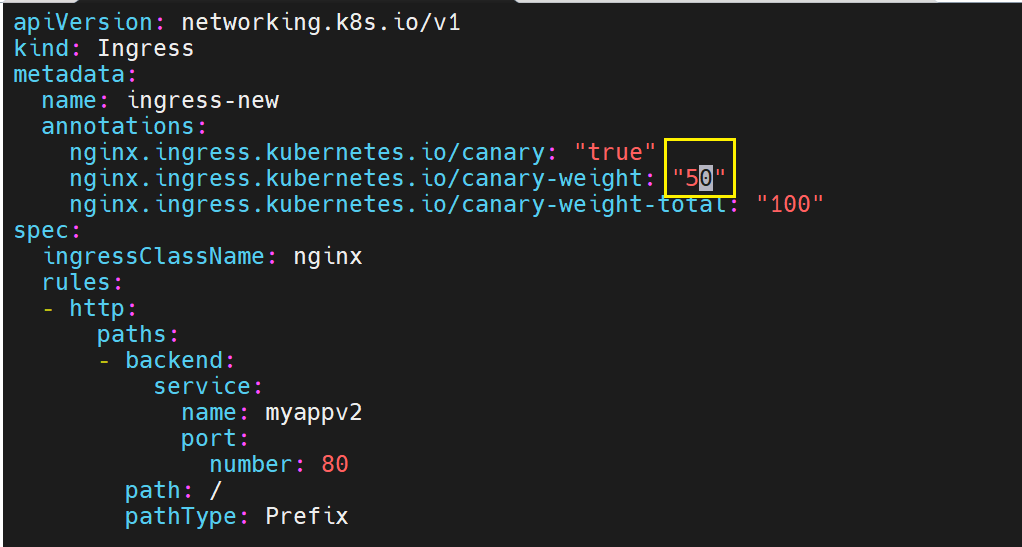
基于权重的灰度发布

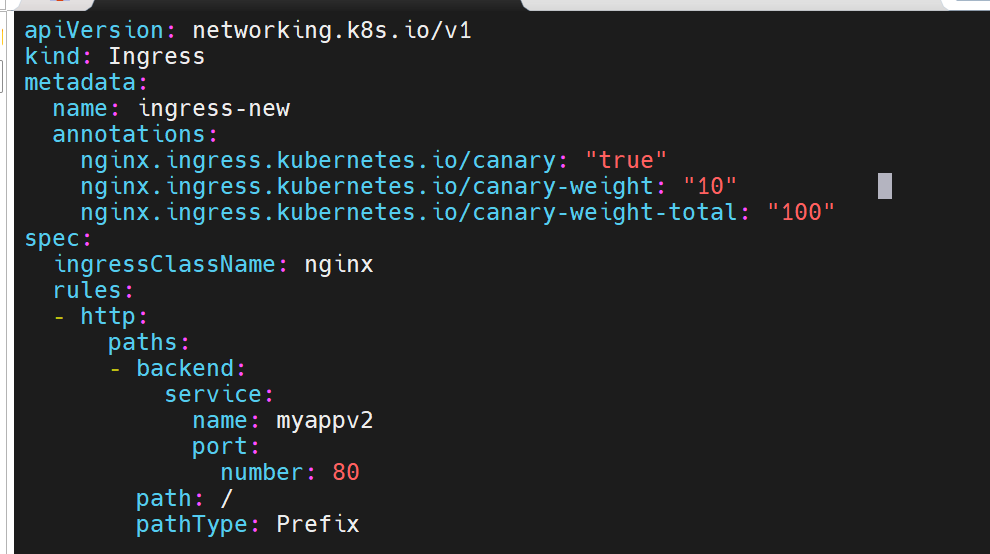

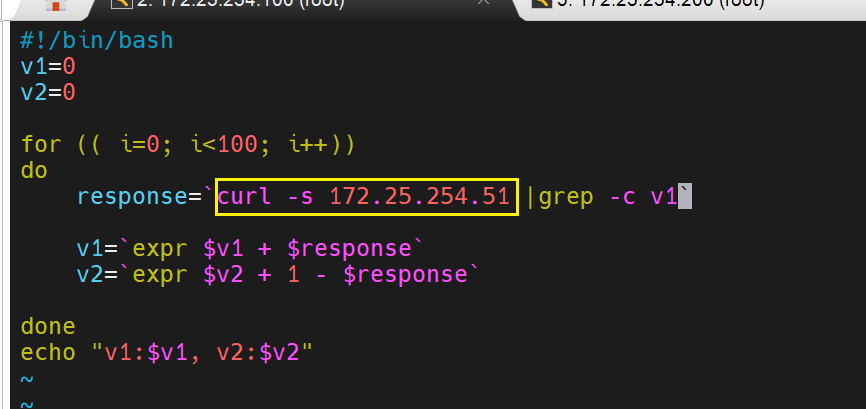
脚本测试:
做100次访问51
-s静默输出
筛选v1的值,访问v1就是1,访问v2就是0
是v1的话就是v1的值加1
是v2的话局势v2的值加1减当时的值
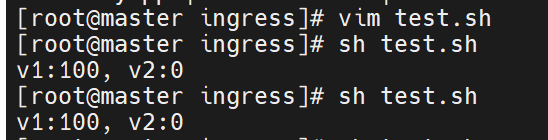
测试没有问题了
就修改权重
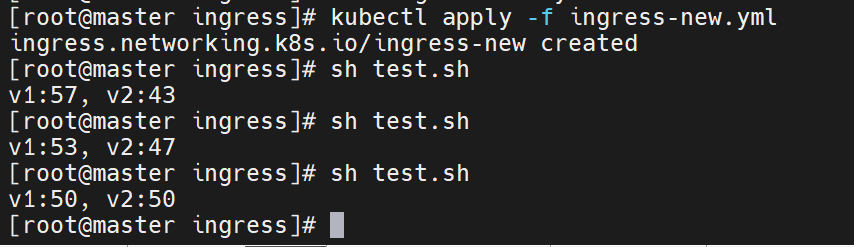
直到最后没有问题,old的版本就可以删除了