温馨提示:
本篇文章已同步至"AI专题精讲 " 大语言模型的知识蒸馏综述
摘要
在大语言模型(LLMs)时代,知识蒸馏(Knowledge Distillation,KD)成为一种关键方法,用于将如 GPT-4 等领先的专有 LLM 的先进能力迁移到开源模型如 LLaMA 和 Mistral 上。与此同时,随着开源 LLM 的快速发展,KD 也在压缩这些模型、以及通过自蒸馏方式实现自我提升方面扮演了重要角色。本文对 KD 在 LLM 领域中的作用进行了全面调研,强调其在向小型模型传授高级知识、模型压缩和自我改进方面的重要性。
本综述围绕三个基础支柱展开:算法、技能和垂直化,系统探讨了 KD 的核心机制、对特定认知能力的增强方式,以及其在各个实际应用场景中的价值。尤为重要的是,本文深入分析了数据增强(Data Augmentation,DA)与 KD 之间的协同作用,展示了 DA 如何在 KD 框架中成为一个强有力的范式,用于提升 LLM 的性能。通过生成富含上下文且与技能相关的训练数据,DA 使 KD 超越了传统局限,使开源模型能够逼近专有模型在上下文理解、伦理对齐和深层语义洞察等方面的能力。
本研究旨在为研究人员和工程实践者提供一份全面而深入的指南,详细梳理当前的知识蒸馏方法,并提出未来的研究方向。通过桥接专有模型与开源模型之间的差距,本综述强调了开发更加可及、高效和强大的 AI 解决方案的潜力。最重要的是,我们强烈主张严格遵守关于 LLM 使用的法律条款,确保知识蒸馏应用的伦理性与合法性。
相关的 Github 仓库地址为:https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs
关键词------大语言模型、知识蒸馏、数据增强、技能蒸馏、有监督微调
1 引言
在人工智能(AI)不断演进的格局中,GPT-3.5(Ouyang et al., 2022)、GPT-4(OpenAI et al., 2023)、Gemini(Team et al., 2023)以及 Claude 等专有大语言模型(LLMs)已经成为颠覆性的技术,重塑了我们对自然语言处理(NLP)的理解。这些模型以其庞大的规模和复杂性为特征,开启了新的可能性领域,从生成类人文本到提供复杂的问题解决能力。这些 LLM 的核心价值在于它们的涌现能力(Wei et al., 2022a,b;Xu et al., 2024a),即模型展现出超出其显式训练目标的能力,使其能够以惊人的熟练度应对多样化的任务。这些模型在理解与生成方面表现出色,驱动了从创意生成到复杂问题求解的多种应用(OpenAI et al., 2023;Liang et al., 2022)。这些模型的潜力远超当前的应用前景,有望彻底变革行业、增强人类创造力,并重新定义我们与技术的交互方式。
尽管 GPT-4 和 Gemini 等专有 LLM 拥有令人瞩目的能力,但它们也存在一些不足,特别是在与开源模型相比时。一项显著的劣势是可访问性差和成本高(OpenAI et al., 2023)。这些专有模型通常附带高额的使用费用和访问限制,使得个人用户和中小型组织难以获取。从数据隐私和安全性角度来看(Wu et al., 2023a),使用这些专有 LLM 通常意味着需要将敏感数据传输到外部服务器,这引发了对隐私和安全的担忧。对于处理机密信息的用户而言,这一点尤为关键。此外,专有 LLM 的通用设计虽然强大,但并不总是能满足某些细分应用场景的特定需求。因此,在可访问性、成本和适配性方面的限制,成为充分发挥专有 LLM 潜力的重要障碍。
相比之下,像 LLaMA(Touvron et al., 2023)和 Mistral(Jiang et al., 2023a)这样的开源模型具有多个显著优势。其一是较高的可访问性和适应性。由于没有授权费用或使用政策方面的限制,这些模型对更广泛的用户群体更加友好,从个人研究者到中小型机构都可自由使用。这种开放性促进了更具协作性和包容性的 AI 研究环境,鼓励了创新和多样化应用。此外,开源 LLM 的可定制特性使其能够实现更加精准的解决方案,以应对通用模型可能无法满足的特定需求。
然而,开源 LLM 也面临自身的挑战,主要来自于其规模和资源的相对有限。一个最显著的限制在于模型规模较小,常常导致其在面对复杂指令集合的实际任务中表现较差(Zheng et al., 2023a)。这些参数更少的模型可能难以捕捉类似 GPT-4 等更大模型所具备的深层次知识。此外,开源模型的预训练投入通常也不如专有模型充分。这种投入不足可能会导致预训练数据范围受限,进而影响模型对多样或专业主题的理解与处理能力(Liang et al., 2022;Sun et al., 2024a)。更进一步,由于资源限制,开源模型通常缺乏足够的微调过程。而微调对于提升模型在特定任务或行业中的表现至关重要,微调不足会限制其在专业场景中的应用效果。这种局限性在与高度微调、被优化以在复杂场景中表现卓越的专有 LLM 相比时尤为明显(OpenAI et al., 2023)。
正因如此,为了弥合专有与开源 LLM 之间的性能差距,知识蒸馏(KD)技术迅速发展起来(Gou et al., 2021;Gupta and Agrawal, 2022)。在这一背景下,知识蒸馏的核心在于利用 GPT-4 或 Gemini 等领先专有模型的先进能力作为指导框架,提升开源 LLM 的综合能力。这一过程类似于由"教师"将知识传授给"学生",其中学生(例如开源 LLM)学习并模仿教师(如专有 LLM)的性能特征。与传统知识蒸馏算法(Gou et al., 2021)相比,数据增强(DA)(Feng et al., 2021)已成为实现 LLM 蒸馏的主流范式,即利用一小段种子知识引导 LLM 针对特定技能或领域生成更多训练数据(Taori et al., 2023)。此外,KD 仍保留其在压缩 LLM 方面的重要作用,在性能几乎无损的前提下实现更高的效率(Gu et al., 2024;Agarwal et al., 2024)。近年来,使用开源 LLM 作为自身的教师以实现自我提升的策略也逐渐成为一种有前景的路径,极大地增强了模型能力(Yuan et al., 2024a;Chen et al., 2024a)。图 1 展示了知识蒸馏在 LLM 语境下的这三种关键作用。
知识蒸馏的一个核心方面,是对以下能力的增强:如高级上下文理解能力(例如 in-context learning(Huang et al., 2022a)和 instruction following(Taori et al., 2023))、更好的用户意图对齐(如人类价值观/原则(Cui et al., 2023a))、以及推理模式如 chain-of-thought(CoT)(Mukherjee et al., 2023)等思维路径。此外还包括 NLP 任务特化能力(如语义理解(Ding et al., 2023a)和代码生成(Chaudhary, 2023))。这些能力对于 LLM 要执行的广泛应用场景至关重要,从日常对话到特定领域的复杂问题求解皆是如此。举例而言,在医疗(Wang et al., 2023a)、法律(LAW, 2023)或科学(Zhang et al., 2024)等垂直领域中,准确性和特定知识尤为关键,知识蒸馏使得开源模型能够借助在这些领域深度训练与微调过的专有模型,显著提升其任务表现。
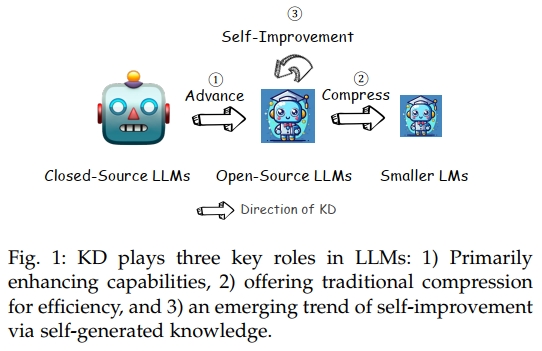
在大语言模型(LLMs)时代,知识蒸馏(Knowledge Distillation, KD)所带来的益处是多方面且具有变革性的(Gu et al., 2024)。通过一系列蒸馏技术,专有模型与开源模型之间的差距被显著缩小(Chiang et al., 2023;Xu et al., 2023a),甚至被弥合(Zhao et al., 2023a)。这一过程不仅简化了计算资源的需求,还提升了 AI 运行的环境可持续性,因为开源模型在更少计算开销下变得更为高效。此外,知识蒸馏促进了更加可访问和公平的 AI 生态,使得小型实体和独立研究人员也能够获取最先进的能力,从而鼓励更广泛的参与和 AI 进步的多样性。这种技术的民主化带来了更健壮、多样且可访问的 AI 解决方案,进一步推动了各行各业与研究领域的创新与发展。
对于 LLMs 的知识蒸馏进行一项全面综述的需求日益增长,其根源在于 AI 技术快速演进的格局(OpenAI et al., 2023;Team et al., 2023)以及这些模型日益增长的复杂性。随着 AI 不断渗透到各个行业,从专有 LLM 高效、有效地蒸馏知识到开源模型的能力,不再只是一个技术目标,而是成为一种现实的必要。这一需求源于对更具可访问性、成本效益和适应性的 AI 解决方案日益增长的渴望,这些解决方案能够满足多样的应用场景和用户需求。在该领域进行一项系统的综述研究至关重要,它有助于整合当前的知识蒸馏方法、面临的挑战与最新突破。这样的综述能够为研究人员和工程实践者提供明确方向,帮助他们将复杂的 AI 能力提炼为更易管理和获取的形式。此外,这样的综述也能够指明未来发展路径,识别当前技术的空白,提出未来研究的方向。
综述结构。本综述的其余部分划分为若干综合章节,旨在深入探讨大语言模型(LLMs)领域内知识蒸馏的多方面内容。继本引言之后,第2节提供知识蒸馏的基础概述,对比传统技术与LLMs时代涌现的新方法,并重点介绍数据增强(DA)在该背景下的作用。第3节深入探讨如何从教师LLM中提取知识及核心蒸馏算法,涵盖从监督微调到涉及散度与相似性、强化学习及排序优化的更复杂策略。随后,第4节聚焦于技能蒸馏,探讨如何提升学生模型以改善上下文理解、用户意图对齐及在多种自然语言处理任务中的表现,内容涵盖自然语言理解(NLU)、生成(NLG)、信息检索、推荐系统及文本生成的评估。第5节则进入领域特定的垂直蒸馏,展示知识蒸馏技术在法律、医疗、金融及科学等专业领域中的应用,说明这些方法的实际影响与变革性作用。第6节提出开放问题,识别当前知识蒸馏研究中的挑战与空白,为未来研究提供机会。最后,第7节总结与讨论,综合归纳所获得的洞见,反思对更广泛AI和自然语言处理研究社区的意义,并提出未来研究方向。图2展示了本综述的整体框架。
2 概述
2.1 传统方案对比
知识蒸馏在人工智能(AI)和深度学习(DL)领域指的是将知识从大型复杂模型(教师模型)转移到较小且更高效的模型(学生模型)的过程(Gou et al., 2021)。该技术在缓解部署大规模模型时面临的计算需求和资源限制方面起到了关键作用。
在LLMs时代之前,知识蒸馏技术主要集中于将知识从复杂且通常较为笨重的神经网络转移到更紧凑高效的架构上(Sanh et al., 2019;Kim and Rush, 2016)。这一过程主要源于在资源受限环境中部署机器学习模型的需求,如移动设备或边缘计算平台,这些环境中计算能力和内存有限。其重点通常放在针对单一任务的特定神经架构选择和训练目标上。早期方法通常训练一个较小的学生网络去模仿较大教师网络的输出,常用的方法包括软目标训练,即学生从教师模型的软化softmax输出中学习。更多关于AI和DL中通用知识蒸馏技术的细节,请参考综述(Gou et al., 2021)。
相比之下,LLMs 的出现彻底改变了知识蒸馏的格局。当前LLMs时代的知识蒸馏将焦点从单纯的架构压缩转向知识的提取与传递(Taori et al., 2023;Chaudhary, 2023;Tunstall et al., 2023)。这一范式的转变主要源于GPT-4和Gemini等大型语言模型所拥有的广泛且深层的知识。而且,LLMs的参数不可访问,使得通过剪枝(Han et al., 2016)或量化(Liu et al., 2023a)等技术对它们进行压缩变得困难。与早期仅复制教师模型输出行为或减少模型规模的目标不同,当前基于LLM的知识蒸馏关注的是如何提取这些模型所蕴含的特定知识。
这一现代方法的关键在于启发式且精心设计的提示(prompt),用于从LLMs中提取特定知识(Ding et al., 2023b)或能力(Chaudhary, 2023)。这些提示被巧妙设计,以挖掘LLM在多个领域的理解和能力,涵盖从自然语言理解(He et al., 2023a)到更复杂的认知任务,如推理(Hsieh et al., 2023)和问题解决(Qiao et al., 2024)。使用提示作为知识提取手段提供了一种更加灵活和动态的蒸馏方法,使得能够有针对性地抽取特定技能或关注领域的知识。这种方法尤其有效地利用了LLMs的"涌现能力",即模型展现出超出其明确训练目标的能力。
此外,当前的知识蒸馏时代还强调了更抽象特质的传递,如推理模式(Mitra et al., 2023)、偏好对齐(Cui et al., 2023a)以及价值观对齐(Sun et al., 2024b)。这与早期仅关注输出复制(Taori et al., 2023)形成鲜明对比,体现了向更加整体和全面的认知能力传递的转变。当前的技术不仅复制输出,还模拟教师模型的思考过程(Mitra et al., 2023)和决策模式(Asai et al., 2023)。这包括复杂策略,例如链式思维提示(chain-of-thought prompting),学生模型被训练学习教师模型的推理过程,从而提升其问题解决和决策能力。
2.2 与数据增强(DA)的关系
在LLMs时代,数据增强(Data Augmentation, DA)(Wang et al., 2022a;Ye et al., 2022)成为知识蒸馏过程中不可或缺的关键范式。不同于传统的DA技术,如同义句转换(paraphrasing)(Gangal et al., 2022)或反向翻译(back-translation)(Longpre et al., 2019),这些传统技术主要通过较为机械的方式扩展训练数据集,LLMs环境下的DA更侧重于生成新颖且富有上下文信息的训练数据,这些数据针对特定领域和技能量身定制。
在LLMs中,DA与知识蒸馏(KD)之间的关系既是共生的也是基础性的。KD通过利用一组种子知识,借助DA促使LLMs生成明确体现特定技能或领域专长的数据(Chaudhary, 2023;West et al., 2022)。这种方法作为缩小专有模型与开源模型之间知识与能力差距的强大机制脱颖而出。通过DA,LLMs被引导生成有针对性、高质量的数据集,这些数据不仅规模更大,而且在多样性和针对性上也更丰富。此方法使得蒸馏过程更加有效,确保蒸馏后的模型不仅复制教师模型的输出行为,还能体现其深层次的理解和认知策略。
DA发挥了乘数效应,使得蒸馏模型能够习得并完善那些否则需要指数级更大数据集和计算资源的能力。它促进了知识更有效的转移,更关注学习的质的方面,而非单纯的量的扩展。在KD过程中战略性地使用DA,标志着向更高效、可持续且更易获得的LLMs能力利用方式的关键转变。它赋予开源模型接近专有模型的上下文敏捷性、伦理对齐和深度语义洞察力,从而实现了先进AI能力的民主化,促进了更广泛的应用和用户群体中的创新。
2.3 调查范围
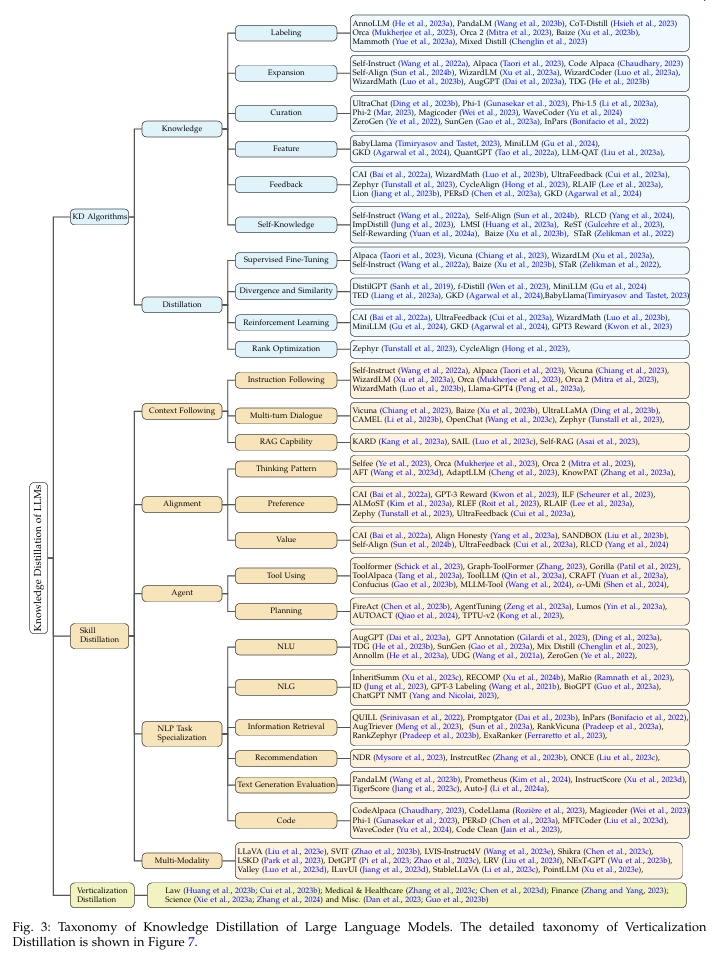
基于前述讨论,本综述旨在全面探讨LLMs环境下的知识蒸馏领域,遵循如图3所示的精心构建的分类体系。调查范围由三个主要方面界定:知识蒸馏算法(KD Algorithms)、技能蒸馏(Skill Distillation)和垂直领域蒸馏(Verticalization Distillation)。每个方面涵盖了一系列子主题和方法论。需要注意的是,KD算法为技能蒸馏和垂直领域蒸馏提供技术基础。
知识蒸馏算法
本部分聚焦于知识蒸馏的技术基础和方法学,深入探讨从教师模型(如专有LLMs)构建知识并将其整合进学生模型(如开源LLMs)的过程。在"知识"范畴下,我们探讨诸如标签生成(Hsieh et al., 2023)、知识扩展(Taori et al., 2023)、数据筛选(Gunasekar et al., 2023)、特征理解(Agarwal et al., 2024)、反馈机制(Tunstall et al., 2023)以及自我知识生成(Wang et al., 2022a)等策略。这些探索旨在揭示知识被识别、扩展和筛选以实现有效蒸馏的多种方式。"蒸馏"子部分考察了学习方法,如监督微调(Supervised Fine-Tuning, SFT)(Wang et al., 2022a)、散度最小化(Divergence Minimization)(Agarwal et al., 2024)、强化学习技术(Cui et al., 2023a)以及排序优化策略(Tunstall et al., 2023)。这些技术共同展示了知识蒸馏如何使开源模型获得专有模型的知识。
技能蒸馏 (Skill Distillation)
本部分考察通过知识蒸馏提升的具体能力与技能。内容包括对上下文理解能力的详细讨论(Taori et al., 2023;Luo et al., 2023c),涵盖子主题如指令遵循(instruction following)和基于检索增强生成(Retrieval-Augmented Generation, RAG)能力。在对齐(alignment)领域(Mitra et al., 2023;Tunstall et al., 2023),调研探讨了思维模式、人格/偏好建模以及价值观对齐。"代理(agent)"类别涵盖了工具使用(Tool Using)和规划(Planning)等技能。自然语言处理(NLP)任务的专门化(Dai et al., 2023a;Jung et al., 2023;Chaudhary, 2023)则从自然语言理解(NLU)、自然语言生成(NLG)、信息检索、推荐系统、文本生成评估及代码生成等角度进行审视。最后,调查还涉及多模态(multi-modality)(Liu et al., 2023e;Zhao et al., 2023b),探讨知识蒸馏如何提升LLMs整合多种输入形式的能力。
垂直领域蒸馏 (Verticalization Distillation)
本章节评估知识蒸馏技术在各类垂直领域的应用,深入解析蒸馏后的LLMs如何针对法律(LAW, 2023)、医疗与健康(Wang et al., 2023a)、金融(Zhang and Yang, 2023)、科学(Zhang et al., 2024)等专业领域进行定制。这一部分不仅展示了知识蒸馏技术的实际应用价值,也凸显了其对特定领域AI解决方案的变革性影响。
通过上述各个方面的探讨,本综述为研究人员和实践者提供了关于LLMs中知识蒸馏的全面分析,指引其了解该快速发展领域中的方法论、挑战及机遇。
声明
本综述体现了我们对知识蒸馏技术在LLMs中应用的全面而深刻的总结,重点关注算法、技能提升及领域特定应用。鉴于该领域的广泛性和快速演变,尤其是在学术界普遍采用训练数据中知识引导的做法,我们承认本文可能未涵盖所有相关研究或最新进展。然而,我们力求介绍知识蒸馏的基础范式,突出关键方法及其在多种应用中的影响。
2.4 LLM时代的蒸馏流程
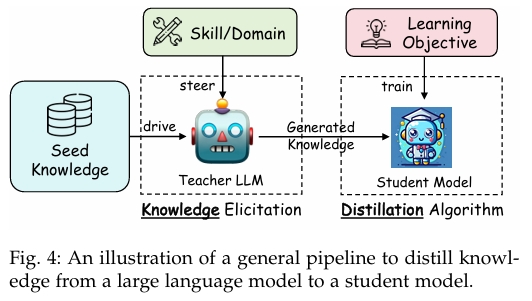
大型语言模型(LLMs)的一般蒸馏流程是一个结构化且有条理的过程,旨在将复杂的教师模型中的知识转移到较为简单的学生模型中。该流程对于将 GPT-4 或 Gemini 等先进模型的能力应用于更易获取且高效的开源模型中具有重要意义。整体流程大致可以分为四个关键阶段,每个阶段在知识蒸馏的成功实施中都扮演着重要角色。流程示意图见图4,详细流程可见图2。
一、针对特定技能或领域引导教师模型
第一阶段通过精心设计的指令或模板,指导教师模型聚焦于特定技能或领域。这些指令旨在引导模型展现其在特定领域(如医疗、法律)或特定能力(如推理、语言理解)上的专业水平。
二、以种子知识作为输入
确定目标领域后,接下来将种子知识输入教师模型。种子知识通常是一个小型数据集或与目标技能或领域相关的关键信息。这些信息作为催化剂,促使教师模型基于初始知识生成更加详细和丰富的输出。种子知识为教师模型构建和扩展提供基础,从而产生更全面深入的知识示例。
三、生成蒸馏知识
教师模型根据引导指令和种子知识生成知识示例。这些示例多以问答对话或叙述性解释的形式出现,契合模型的自然语言处理和理解能力。在某些专业场景下,输出也可能包括 logits 或隐藏特征,但由于其复杂性和特定需求,这类形式较少见。生成的知识示例构成了蒸馏知识的核心,体现了教师模型的深层理解和技能。
四、以特定学习目标训练学生模型
最后阶段利用生成的知识示例训练学生模型。训练过程通过损失函数来指导,损失函数衡量学生模型复制或适应教师模型知识的效果。通过最小化损失,学生模型学习模仿教师模型的目标技能或领域知识,获得类似的能力。该过程包括反复调整学生模型参数,减少其输出与教师模型输出之间的差距,确保知识的有效转移。
本质上,上述四个阶段可以抽象为两种形式,第一种形式代表知识的引导过程:
D I ( k d ) = { P a r s e ( o , s ) ∣ o ∼ p T ( ∘ ∣ I ⊕ s ) , ∀ s ∼ S } ( 1 ) \mathcal { D } _ { I } ^ { ( \mathrm { k d } ) } = \{ \mathrm { P a r s e } ( o , s ) | o \sim p _ { T } ( \circ | I \oplus s ) , \forall s \sim \mathcal { S } \} \quad(1) DI(kd)={Parse(o,s)∣o∼pT(∘∣I⊕s),∀s∼S}(1)
其中,⊕ 表示将两段文本融合,I 代表用于引导大型语言模型(LLM)并引出知识的任务、技能或领域的指令或模板,s ∼ S 表示种子知识的一个示例,LLM 可基于此示例进行探索以生成新的知识。Parse(o, s) 表示从教师模型的输出 o(有时加上输入 s)中解析蒸馏示例(例如 (x, y))。 p T p_T pT 代表带参数 θ T θ_T θT 的教师大型语言模型。
给定为蒸馏构建的数据集 D I ( k d ) D^{(kd)}_I DI(kd) 后,我们定义一个学习目标为:
L = ∑ I L I ( D I ( k d ) ; θ S ) ( 2 ) \mathcal { L } = \sum _ { I } \mathcal { L } _ { I } ( \mathcal { D } _ { I } ^ { ( \mathrm { k d } ) } ; \theta _ { S } )\quad(2) L=I∑LI(DI(kd);θS)(2)
其中, ∑ I \textstyle \sum _ { I } ∑I 表示可能存在多个任务或技能被蒸馏到一个学生模型中, L I ( ⋅ ; ⋅ ) L_I(\cdot; \cdot) LI(⋅;⋅) 代表具体的学习目标函数, θ S \theta_S θS 是学生模型的参数。
在对蒸馏流程及大型语言模型时代知识蒸馏的基础概念进行了探讨之后,我们接下来将重点关注在这一时代获得广泛关注的具体算法。
3 知识蒸馏算法
本节将介绍知识蒸馏的整个流程。根据第 2.4 节的描述,该流程可以划分为两个主要步骤:"Knowledge(知识)",即从教师 LLM 中引出知识(见公式 1);以及 "Distillation(蒸馏)",即将这些知识注入学生模型(见公式 2)。我们将在后续小节中详细阐述这两个过程。
3.1 知识
本节关注从教师 LLM 中提取知识的方法。根据获取知识的方式不同,我们将其划分为以下几类:Labeling(标注) 、Expansion(扩展) 、Data Curation(数据策划) 、Feature(特征) 、Feedback(反馈) 以及 Self-Knowledge(自我知识)。图 5 展示了这些知识提取方式的示意图。
3.1.1 标注
标注类知识指的是:使用教师 LLM 对给定输入 x x x 进行输出 y y y 的标注,将其作为种子知识,标注过程依据指令 I I I 或示范样本 c c c 进行,其中 c = ( x 1 , y 1 ) , ... , ( x n , y n ) c = (x_1, y_1), \dots, (x_n, y_n) c=(x1,y1),...,(xn,yn)。这种从教师 LLM 中提取知识的方法简单却高效,已被广泛应用于各种任务与场景中。该方法只需收集一组输入数据集,然后输入到 LLM 中获取所需的生成结果。此外,输出 y y y 的生成过程可以通过预定义的 I I I 和 c c c 进行控制。该过程可形式化表示如下:
D ( l a b ) = { x , y ∣ x ∼ X , y ∼ p T ( y ∣ I ⊕ c ⊕ x ) } ( 3 ) \mathcal { D } ^ { ( \mathrm { l a b } ) } = \{ x , y | x \sim \mathcal { X } , y \sim p _ { T } ( y | I \oplus c \oplus x ) \}\quad(3) D(lab)={x,y∣x∼X,y∼pT(y∣I⊕c⊕x)}(3)
输入 x x x 可以来自现有的 NLP 任务数据集,这些数据集是蒸馏工作中常用的典型数据源。许多研究致力于利用强大的教师 LLM 能力对不同任务的数据样本进行标注。例如,在自然语言理解任务中,可以使用 LLM 对文本进行分类(Gilardi et al., 2023; Ding et al., 2023a; He et al., 2023a);在自然语言生成任务中,LLM 可用于生成输出序列(Hsieh et al., 2023; Jung et al., 2023; Wang et al., 2021b)。文本生成评估任务中,LLM 被用来为评估结果打标签(Li et al., 2024b; Wang et al., 2023b);在推理任务中,LLM 被用于标注 Chain-of-Thought(CoT)解释(Hsieh et al., 2023; Li et al., 2022; Ho et al., 2023; Magister et al., 2023; Fu et al., 2023; Ramnath et al., 2023; Li et al., 2023d; Liu et al., 2023g)等。
与其专注于特定任务,当前许多工作更关注基于指令的输出标注,从而教授学生模型以更灵活的方式通过"跟随指令"完成任务。多种 NLP 任务集合配合指令模板,成为 x x x 的有价值输入来源。例如,FLAN-v2 集合(Longpre et al., 2023)提供了大量带有指令的公开任务集合,其响应由教师 LLM(如 Orca(Mukherjee et al., 2023; Mitra et al., 2023))生成。这些 NLP 任务的指令是通过预定义模板构建的,可能缺乏多样性,并与人类自然查询存在差距。相比之下,人类与聊天模型之间的真实对话提供了大规模的真实查询数据,这些数据由强大的 LLM 生成标注,如 ShareGPT。此外,Xu et al. (2023b) 和 Anand et al. (2023) 对来自 Quora 和 Stack Overflow 等论坛中抽样的真实问题进行了标注。
此外,标注过程可以由指令 I I I 或示范 c c c 引导。用于引导标注的常见指令类型是 Chain-of-Thought(CoT)prompt(Hsieh et al., 2023; Fu et al., 2023; Magister et al., 2023)。Mukherjee et al. (2023) 添加了多个系统消息(例如:"你必须生成一个详细且冗长的回答。" 或 "像在向五岁小孩解释一样逐步思考")以引出丰富的信号。Yue et al. (2023a) 和 Chenglin et al. (2023) 对 CoT 和 Program-of-Thought(PoT)混合知识进行标注。Xu et al. (2023b) 提出了一种 self-chat 技术,即由两个教师 LLM 模拟真实对话,为来自 Quora 和 Stack Overflow 的一个问题生成多轮对话。
3.1.2 扩展
尽管标注方法简单且有效,但它面临一些限制。主要体现在输入数据的规模和多样性方面的约束。在现实应用中,尤其涉及用户对话的场景,还存在数据隐私方面的顾虑。为了解决这些限制,研究者提出了多种扩展方法(Wang et al., 2022a; Taori et al., 2023; Chaudhary, 2023; Si et al., 2023; Ji et al., 2023a; Luo et al., 2023b,a; Wu et al., 2023c; Sun et al., 2024b; Xu et al., 2023a; Guo et al., 2023c; Roziere et al.`, 2023; West et al., 2022)。这些方法将示范样本作为 seed knowledge,并旨在通过 in-context learning 扩展大规模且多样化的数据。
这些扩展方法的一个关键特征,是利用 LLM 的 in-context learning 能力生成与提供的示范 c c c 相似的数据。与标注方法不同,标注方法中的输入 x x x 来自现有数据集,而扩展方法中, x x x 和 y y y 都由教师 LLM 生成。这个过程可以形式化为:
D ( e x p ) = { ( x , y ) ∣ x ∼ p T ( x ∣ I ⊕ c ) , y ∼ p T ( y ∣ I ⊕ x ) } ( 4 ) \mathcal { D } ^ { \mathrm { ( e x p ) } } = \{ ( x , y ) | x \sim p _ { T } ( x | I \oplus c ) , y \sim p _ { T } ( y | I \oplus x ) \}\quad(4) D(exp)={(x,y)∣x∼pT(x∣I⊕c),y∼pT(y∣I⊕x)}(4)
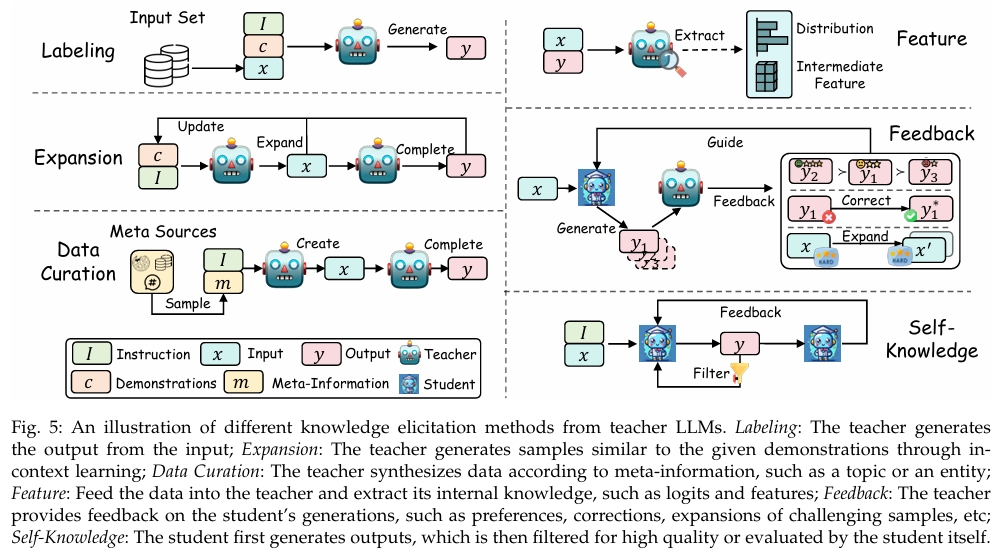
在上述公式中, x x x 和 y y y 表示由教师 LLM 生成的新输入-输出对。输入 x x x 是基于一组输入-输出示范 c c c 生成的,输出 y y y 则是在指令 I I I 的引导下针对新输入 x x x 生成的。需要注意的是,示范样本可以是预定义的,也可以通过添加新生成的样本动态更新。
扩展技术已被广泛用于从教师 LLM 中提取大量遵循指令的知识。Wang et al. (2022a) 首次提出一种迭代自举方法 Self-Instruct,利用 LLM 基于从 175 条人工编写指令中抽样的几个示例生成大量新指令。新生成的指令会被添加回初始池中,从而使后续的扩展迭代受益。随后,Taori et al. (2023) 将该扩展方法应用于更强大的教师 LLM------textdavinci-003,以蒸馏出 52K 条高质量数据。为提高扩展过程中的多样性和覆盖率,Wu et al. (2023c) 和 Sun et al. (2024b) 提示教师 LLM 生成与特定主题相关的指令。Xu et al. (2023a) 提出 Evol-Instruct 方法,从两个维度扩展指令:难度(例如将问题改写得更复杂)和多样性(例如生成更多长尾指令)。该 Evol-Instruct 方法具有领域无关性,并被用于扩展编程任务的蒸馏(Luo et al., 2023a)和数学任务的蒸馏(Luo et al., 2023b)。此外,扩展方法可以通过生成相似样本大幅增强 NLP 任务数据集,从而提升任务性能。例如,AugGPT(Dai et al., 2023a)利用教师 LLM 将训练样本中的每句话改写为多个概念相似但语义不同的样本,以提升分类性能。类似地,TDG(He et al., 2023b)提出目标数据生成(Targeted Data Generation, TDG)框架,自动识别数据中的困难子群体,并通过 in-context learning 使用 LLM 为这些子群体生成新样本。
总之,扩展方法利用 LLM 的 in-context learning 优势生成更多样且大规模的输入与输出数据集。然而,所生成数据的质量和多样性在很大程度上依赖于教师 LLM 及初始的 seed 示范。这种依赖可能导致数据集中存在 LLM 本身的偏差(Yu et al., 2023a;Wei et al., 2023),以及在生成中出现同质化问题,从而限制了该方法试图实现的数据多样性(Ding et al., 2023b)。此外,扩展过程可能无意中放大 seed 数据中存在的偏见。
3.1.3 数据整理
在从 LLM 中进行知识蒸馏时,为生成高质量且可扩展的数据,数据整理(Data Curation)方法应运而生。该方法是为了解决在标注(Labeling)和扩展(Expansion)方法中观察到的局限性。这些方法往往会产生质量不一的数据,并在数量上受到限制。在标注中,seed knowledge 来自任务数据集,可能包含噪声和脏数据;而在扩展中,输入 x x x 来源于 seed 示范,若大量生成则可能导致数据同质化。为克服这些问题,数据整理方法通过大量元信息(meta-information)作为 seed knowledge 来整理高质量或大规模数据(Ding et al., 2023b;Gunasekar et al., 2023;Li et al., 2023a;Mar, 2023;Liu et al., 2023d;Wei et al., 2023;Yu et al., 2024;Ye et al., 2022;Gao et al., 2023a;Yang and Nicolai, 2023)。
数据整理(Data Curation)的一个显著特征在于其从零开始合成数据的方式。该过程中可以融入多种多样的元信息(如主题或知识点),以生成可控的 xx 和 yy。因此,该过程能够被精细地控制,从而产出不仅规模庞大而且质量较高的数据集。数据整理的公式表达如下所示:
D ( c u r ) = { ( x , y ) ∣ x ∼ p T ( x ∣ I ⊕ m ) , y ∼ p T ( y ∣ I ⊕ x ) } ( 5 ) \mathcal { D } ^ { ( \mathrm { c u r } ) } = \{ ( x , y ) | x \sim p _ { T } ( x | I \oplus m ) , y \sim p _ { T } ( y | I \oplus x ) \}\quad(5) D(cur)={(x,y)∣x∼pT(x∣I⊕m),y∼pT(y∣I⊕x)}(5)
在该公式中, m m m 表示用于引导合成 x x x 的多样化元信息,而 I I I 则是用于引导 teacher LLM 生成 x x x 或 y y y 的指令。
不同研究的主要区别在于其元信息的来源及其使用方式。UltraChat(Ding et al., 2023b)通过蒸馏知识展示了高质量且多样化数据整理的有效流程。他们在三个领域收集了大量元信息:世界问题(Questions about the World)、创作与生成(Creation and Generation)、已有材料辅助(Assistance on Existing Materials)。例如,在"世界问题"这一领域下,他们探索了如"Technology"和"Food and Drink"等30个元主题,teacher LLM 随后利用这些元信息来蒸馏大量指令和对话数据,最终整理出高达150万个实例的数据集。UltraChat 在词汇和主题多样性上表现突出,其微调后的 UltraLLaMA 模型在多个基准上持续优于其他开源模型。
另一个值得关注的系列是 phi(Gunasekar et al., 2023;Li et al., 2023a;Mar, 2023),该系列专注于蒸馏类似"教科书"的高质量小规模数据。Phi-1(Gunasekar et al., 2023)尝试在编码领域合成"教科书质量"的数据,其方法是从 LLM 中蒸馏出清晰、自包含、具教学性和平衡性的数据,使用随机主题或函数名作为元信息以增强多样性。最终获得的数据包括10亿个 Python 教程风格 token(含自然语言解释与代码片段),以及1.8亿个 Python 练习及其解答。令人瞩目的是,phi-1 模型虽体积较小,但在 HumanEval 与 MBPP 等编码基准测试中几乎全面超越其他开源模型,其模型规模仅为后者的1/10,数据规模更小至1/100。
MFTCoder(Liu et al., 2023d)则使用数百个 Python 知识点作为元信息,构建了 CodeExercise 数据集。相比之下,Magicoder(Wei et al., 2023)与 WaveCoder(Yu et al., 2024)则从开源代码数据集中获取原始代码集合,作为元信息来生成教学类数据。
在自然语言理解(NLU)任务中,一些研究(Ye et al., 2022;Gao et al., 2023a;Wang et al., 2021a)尝试使用标签作为元信息,合成对应样本用于数据增强。类似地,在信息检索任务中,也有研究尝试使用文档作为元信息来生成可能的查询,从而构建大规模的检索对(Bonifacio et al., 2022;Meng et al., 2023)。
总之,通过 teacher LLM 进行的数据整理已成为一种有前景的合成数据技术,能够产出高质量、多样化且大规模的数据集。诸如 phi-1 等模型在特定领域的成功证明了该方法的有效性。创建合成数据集的能力将成为 AI 领域的一项关键技术技能与研究焦点(Li et al., 2023a)。
3.1.4 Feature
前述的知识抽取方法通常适用于功能强大的黑盒模型,这类模型因需调用 API 而成本较高,且复现性较差。相比之下,白盒蒸馏(white-box distillation)为研究人员提供了一种更加透明且易于访问的方式。它利用的是来自 teacher LLM 的输出分布、中间特征或激活值,这些统称为 Feature 知识。白盒知识蒸馏(KD)方法主要研究对象是规模较小的编码器模型(通常参数量低于 10 亿,参见 Gou et al. (2021) 获取详细信息)。然而,近期的研究开始探索生成式 LLM 中的白盒蒸馏方法(Timiryasov and Tastet, 2023;Liang et al., 2023a;Gu et al., 2024;Agarwal et al., 2024;Liu et al., 2023a;Wen et al., 2023;Wan et al., 2024a;Zhao and Zhu, 2023;Qin et al., 2023b;Boizard et al., 2024;Zhong et al., 2024)。
获取 Feature 知识的典型方法是让 teacher LLM 对输出序列 y y y 进行标注,附上其内部表示。这些带标注的表示随后可通过如 Kullback-Leibler 散度(KLD)等方法蒸馏至 student 模型中。抽取 feature 知识的过程可以形式化如下:
D ( f e a t ) = { ( x , y , ϕ f e a t ( x , y ; θ T ) ) ∣ x ∼ X , y ∼ y } ( 6 ) \mathcal { D } ^ { ( \mathrm { f e a t } ) } = \{ ( x , y , \phi _ { \mathrm { f e a t } } ( x , y ; \theta _ { T } ) ) \mid x \sim \mathcal { X } , y \sim \mathcal { y } \}\quad(6) D(feat)={(x,y,ϕfeat(x,y;θT))∣x∼X,y∼y}(6)
在该公式中, y \mathcal { y} y 表示输出集合,可以由 teacher LLM、student 模型生成,或直接来源于数据集。 ϕ feat ( ⋅ ; θ T ) \phi_{\text{feat}}(\cdot;\theta_T) ϕfeat(⋅;θT) 表示从 teacher LLM 中提取 feature 知识(例如输出分布)的操作。
最直接的获取 teacher feature 知识的方法是,对固定的数据集序列进行标注,获取其 token 级别的概率分布(Sanh et al., 2019;Wen et al., 2023)。为了利用 teacher 模型中间层所蕴含的丰富语义和句法知识,TED(Liang et al., 2023a)设计了一种任务感知的逐层蒸馏方法,通过在每一层将 student 的隐藏表示与 teacher 对齐,选择性地提取与目标任务相关的知识。Gu et al. (2024) 和 Agarwal et al. (2024) 提出了一种新方法:student 模型首先生成序列(称为"自生成序列"),然后使用 teacher 在这些序列上的反馈(即输出分布)进行学习。这种方法在 student 模型无法直接模拟 teacher 分布时尤为有效。
此外,还提出了多种结合 feature 知识的 LLM 量化方法(Tao et al., 2022a;Liu et al., 2023a;Kim et al., 2023b),这些方法旨在量化 LLM 时保留原始输出分布,从而确保性能损失最小。
此外,feature 知识也可以作为多教师知识蒸馏的强大信息源。Timiryasov 和 Tastet (2023) 利用 GPT-2 和 LLaMA 的集合作为教师模型,提取输出分布。类似地,FuseLLM(Wan et al., 2024a)创新性地通过对多个 LLM 的输出分布进行加权融合,将其能力整合至单个 LLM 中。这种方法有望显著增强 student 模型的能力,甚至超过任一单独的 teacher LLM。
总而言之,feature 知识为黑盒方法提供了一种更为透明的替代方式,使得蒸馏过程更易于理解和控制。通过使用来自 teacher LLM 的 feature 知识(如输出分布与中间层特征),白盒方法实现了更丰富的知识迁移。尽管在小模型上展现出前景,但该方法不适用于内部参数不可访问的黑盒 LLM。此外,从白盒 LLM 蒸馏得到的 student 模型性能可能仍不如来自更强大的黑盒 teacher LLM(如 GPT-4)的蒸馏模型。
3.1.5 Feedback
大多数以往的工作主要聚焦于教师向学生的单向知识迁移,用于模仿学习,而没有考虑教师对学生生成结果的反馈。教师的反馈通常通过提供偏好、评估或纠正信息来对学生生成的输出给予指导。例如,一种常见的反馈形式是教师对学生生成的结果进行排序,并通过人工智能反馈强化学习(Reinforcement Learning from AI Feedback,RLAIF)(Bai et al., 2022a)将这种偏好蒸馏到学生模型中。以下是获取反馈知识的通用公式:
D ( f b ) = { ( x , y , ϕ f b ( x , y ; θ T ) ) ∣ x ∼ X , y ∼ p S ( y ∣ x ) } ( 7 ) D ^ { ( \mathrm { f b } ) } = \{ ( x , y , \phi _ { \mathrm { f b } } ( x , y ; \theta _ { T } ) ) | x \sim \mathcal { X } , y \sim p _ { S } ( y | x ) \}\quad(7) D(fb)={(x,y,ϕfb(x,y;θT))∣x∼X,y∼pS(y∣x)}(7)
学生模型根据输入 x 生成的输出为 y, ϕ f b ( ⋅ ; θ T ) ) \phi _ { \mathrm { f b } } ( \cdot ; \theta _ { T } ) ) ϕfb(⋅;θT)) 表示教师 LLM 提供反馈的操作。该操作对学生模型给定输入 x 的输出 y 进行评估,提供评估、纠正信息或其他形式的指导。这种反馈知识不仅可以被蒸馏进学生模型以使其也能生成反馈(例如创建学生偏好模型),更重要的是能够使学生基于反馈来改进其回答。已有多种方法用于引导这种高级知识的获取(Bai et al., 2022a; Luo et al., 2023b; Cui et al., 2023a; Kwon et al., 2023; Jiang et al., 2023b; Chen et al., 2023a; Gu et al., 2024; Agarwal et al., 2024; Chen et al., 2024b; Guo et al., 2024; Ye et al., 2023; Hong et al., 2023; Lee et al., 2023a)。
温馨提示:
阅读全文请访问"AI深语解构 " 大语言模型的知识蒸馏综述