目录
[1.1 重载与重写的区别](#1.1 重载与重写的区别)
[1.2 == 与 equals 的区别](#1.2 == 与 equals 的区别)
[1.3 String,StringBuilder 和 StringBuffer 的区别](#1.3 String,StringBuilder 和 StringBuffer 的区别)
[2.1 你知道的数据结构有哪些](#2.1 你知道的数据结构有哪些)
[2.2 说说 java 中常见的集合类](#2.2 说说 java 中常见的集合类)
[2.3 HashMap 原理(数据结构)](#2.3 HashMap 原理(数据结构))
[2.4 HashMap 原理(扩容)](#2.4 HashMap 原理(扩容))
[2.5 HashMap 原理(方法执行流程)](#2.5 HashMap 原理(方法执行流程))
[3.1 说说 BIO、NIO、AIO](#3.1 说说 BIO、NIO、AIO)
[5.1 ThreadLocal 的原理](#5.1 ThreadLocal 的原理)
[5.2 解释悲观锁与乐观锁](#5.2 解释悲观锁与乐观锁)
[5.3 synchronized 原理](#5.3 synchronized 原理)
[5.4【追问】 synchronized 锁升级](#5.4【追问】 synchronized 锁升级)
[5.5 对比 synchronized 和 volatile](#5.5 对比 synchronized 和 volatile)
[5.6 对比 synchronized 和 Lock](#5.6 对比 synchronized 和 Lock)
[5.7 线程池的核心参数](#5.7 线程池的核心参数)
[6、JVM 虚拟机](#6、JVM 虚拟机)
[6.1 JVM 堆内存结构](#6.1 JVM 堆内存结构)
[6.2 垃圾回收算法](#6.2 垃圾回收算法)
[8.1 反射](#8.1 反射)
[8.2 泛型](#8.2 泛型)
1、基础语法与面向对象
1.1 重载与重写的区别
-
重载是对象的方法之间,它们方法名相同,但方法的参数列表不同
-
重写是父子类(包括接口与实现类)中两个同名方法,它们方法名相同,且方法的参数列表相同
-
重载在编译阶段,由编译器根据传递给方法的参数来区分方法,例如
MyObject obj = ... obj.test(123); // 应该是调用 test(int x) 这个方法 obj.test("abc"); // 应该是调用 test(String x) 这个方法 -
而重写是在运行阶段,由虚拟机解释器去获取引用对象的实际类型,根据类型才能确定该调用哪个方法,例如
Super obj = ... obj.test(); // 到底是调用父类,还是子类的 test 方法,必须检查引用对象的实际类型才能确定 -
有没有发生重写,可以使用 @Override 来检查
P.S.
括号内的说明是为了严谨,自己知道就行,回答时不必说出,这样比较简洁
个人觉得,在回答方法重载时,不必去细说什么参数的类型、个数、顺序,就说参数列表不同就完了
个人觉得,重点在于点出:重载是编译时由编译器 来区分方法,而重写是运行时由解释器来区分方法
语法细节,问了再说,不问不必说
重写时,子类方法的访问修饰符要 >= 父类方法的访问修饰符
重写时,子类方法抛出的检查异常类型要 <= 父类方法抛出的检查异常类型,或子类不抛异常
重写时,父子类的方法的返回值类型要一样,或子类方法返回值是父类方法返回值的子类
1.2 == 与 equals 的区别
-
对于基本类型,== 是比较两边的值是否相同
-
对于引用类型,== 是比较两边的引用地址是否相同,用来判断是否引用着同一对象
-
equals 要看实现
-
Object.equals(Object other) 的内部实现就是 ==,即判断当前对象和 other 是否引用着同一对象
-
比如 String,它的内部实现就是去比较两个字符串中每个字符是否相同,比较的是内容
-
比如 ArrayList,它的内部实现就是去比较两个集合中每个元素是否 equals,比较的也是内容
-
1.3 String,StringBuilder 和 StringBuffer 的区别
-
它们都可以用来表示字符串对象
-
String 表示的字符串是不可变的,而后两者表示的字符串是内容可变的(可以增、删、改字符串里的内容)
-
StringBuilder 不是线程安全的,StringBuffer 是线程安全的,而 String 也算是线程安全的
适用场景
-
大部分场景下使用 String 就足够了
-
如果有大量字符串拼接的需求,建议用后两者,此时
-
此字符串对象需要被多线程同时访问,用 StringBuffer 保证安全
-
此字符串对象只在线程内被使用,用 StringBuilder 足够了
-
另外针对 String 类是 final 修饰会提一些问题,把握下面几点
-
本质是因为 String 要设计成不可变的,final 只是条件之一
-
不可变的好处有很多:线程安全、可以缓存等
-
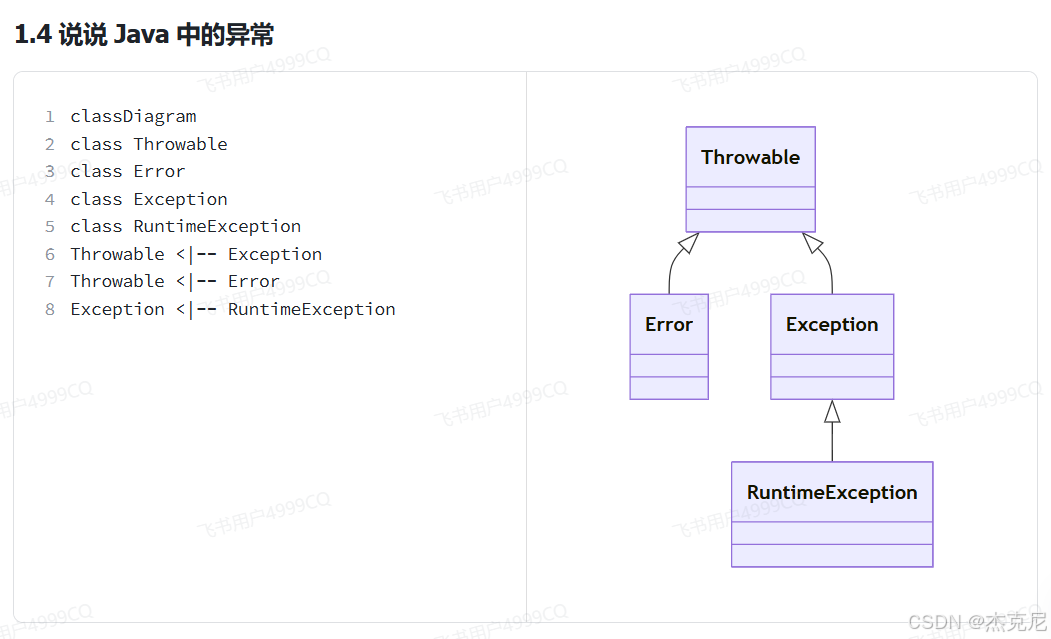
异常的重要继承关系如图所示,其中
-
Throwable 是其它异常类型的顶层父类
-
Error 表示无法恢复的错误,例如 OutOfMemoryError 内存溢出、StackOverflowError 栈溢出等
- 这类异常即使捕捉住,通常也无法让程序恢复正常运行
-
Exception 表示可恢复的错误,处理方式有两种
-
一是自己处理,用 catch 语句捕捉后,可以进行一些补救(如记录日志、恢复初始状态等)
-
二是用 throw 语句将异常继续抛给上一层调用者,由调用者去处理
-
-
Exception 有特殊的子类异常 RuntimeException,它与 Exception 的不同之处在于
-
Exception 被称之为检查异常,意思是必须在语法层面对异常进行处理,要么 try-catch,要么 throws
-
RuntimeException 和它的子类被称为非检查异常(也可以翻译为字面意思:运行时异常),在语法层面对这类异常并不要求强制处理,不加 try-catch 和 throws 编译时也不会提示错误
-
-
常见的非检查异常有
-
空指针异常
-
算术异常(例如整数除零)
-
数组索引越界异常
-
类型转换异常
-
...
-
2、集合类
2.1 你知道的数据结构有哪些
线性结构
-
动态数组:相对于普通数组可以扩容
-
java 中 ArrayList 就属于动态数组
-
数组的特点是其中元素是连续存储的
-
-
链表:由多个节点链在一起
-
java 中的 LinkedList 就属于链表
-
链表的特点是其中元素是不连续存储的,每次需要根据当前节点,才能找到相邻节点
-
-
栈:符合 First In Last Out(先进后出)规则
-
java 中的 LinkedList 可以充当栈
-
它的 push 方法向栈顶添加元素
-
它的 pop 方法从栈顶移除元素
-
它的 peek 方法从栈顶获取元素(不移除)
-
-
队列:符合 First In First Out(先进先出)规则
-
java 中 LinkedList 也可以充当队列
-
它的 offer 方法用来向队列尾部添加元素(入队)
-
它的 poll 方法用来从队列头部移除元素(出队)
-
非线性结构
-
优先级队列:在队列基础上增加了优先级,队列会根据优先级调整元素顺序,保证优先级高的元素先出队
-
java 中 PriorityQueue 可以作为优先级队列
-
它底层用大顶堆或小顶堆来实现
-
它适用于实现排行榜、任务调度等编码
-
它特别适合于流式数据的处理,利用它能够大大节省内存
-
-
Hash 表(哈希表,也叫散列表):由多对 key - value 组成,会根据 key 的 hash 码把它们分散存储在数组当中,其中 key 的 hash 码与数组索引相对应
-
java 中的 HashMap,Hashtable 都属于哈希表
-
它特别适用于实现数据的快速查找
-
-
红黑树:可以自平衡的二叉查找树,相对于线性结构来说,拥有更好的性能
- java 中的 TreeMap 属于红黑树
-
跳表:多级链表结构,也能达到与红黑树同级的性能,且实现更为简单
-
java 中的 ConcurrentSkipListMap 用跳表结构实现
-
redis 中的 SortedSet 也是用跳表实现
-
-
B+ 树:可以自平衡的 N 叉查找树
- 关系型数据库的索引常用 B+ 树实现
P.S.
以上数据结构不必全部掌握,根据自己实际情况,捡熟悉的回答即可
以上仅是这些数据结构的简述,关于它们的详细讲解,请参考黑马《数据结构与算法》课程:
2.2 说说 java 中常见的集合类
重要的集合接口以及实现类参考下图
暂时无法在飞书文档外展示此内容
接口
-
接口四个:Collection、List、Set、Map,它们的关系:
- Collection 是父接口,List 和 Set 是它的子接口
-
Map 接口与其它接口的关系
-
Map 调用 entrySet(),keySet() 方法时,会创建 Set 的实现
-
Map 调用 values() 方法时,会用到 Collection 的实现
-
List 实现(常见三个)
-
ArrayList 基于数组实现
-
随机访问(即根据索引访问)性能高
-
增、删由于要移动数组元素,性能会受影响
-
【进阶】但如果增、删操作的是数组尾部不牵涉移动元素
-
-
LinkedList 基于链表实现
-
随机访问性能低,因为需要顺着链表一个个才能访问到某索引位置
-
增、删性能高
-
【进阶】说它随机访问性能低是相对的,如果是头尾节点,无论增删改查都快
-
【进阶】说它增删性能高也是有前提的,并没有包含定位到该节点的时间,把这个算上,增删性能并不高
-
-
Vector 基于数组实现
-
相对于前两种 List 实现是线程安全的
-
【进阶】一些说法说 Vector 已经被舍弃,这是不正确的
-
Set 实现
-
HashSet 内部组合了 HashMap,利用 Map key 唯一的特点来实现 Set
-
集合中元素唯一,注意需要为元素实现 hashCode 和 equals 方法
-
【进阶】Set 的特性只有元素唯一,有些人说 Set 无序,这得看实现,例如 HashSet 无序,但TreeSet 有序
-
Map 实现(常见五个)
-
HashMap 底层是 Hash 表,即数组 + 链表,链表过长时会优化为红黑树
- 集合中 Key 要唯一,并且它需要实现 hashCode 和 equals 方法
-
LinkedHashMap 基于 HashMap,只是在它基础上增加了一个链表来记录元素的插入顺序
-
【进阶】这个链表,默认会记录元素插入顺序,这样可以以插入顺序遍历元素
-
【进阶】这个链表,还可以按元素最近访问来调整顺序,这样可以用来做 LRU Cache 的数据结构
-
-
TreeMap 底层是红黑树
-
Hashtable 底层是 Hash 表,相对前面三个实现来说,线程安全
- 【进阶】它的线程安全实现方式是在 put,get 等方法上都加了 synchronized,锁住整个对象
-
ConcurrentHashMap 底层也是 Hash 表,也是线程安全的
-
【进阶】它的 put 方法执行时仅锁住一个链表,并发度比 Hashtable 高
-
【进阶】它的 get 方法执行不加锁,是通过 volatile 保证数据的可见性
-
P.S.
未标注的是必须记住的部分
标注【进阶】的条目是该集合比较有特色的地方,回答出来就是加分项,不过也根据自己情况来记忆
2.3 HashMap 原理(数据结构)
底层数据结构:数组+链表+红黑树
接下来的回答中要点出数组的作用 ,为啥会有冲突 ,如何解决冲突
-
数组:存取元素时,利用 key 的 hashCode 来计算它在数组中的索引,这样在没有冲突的情况下,能让存取时间复杂度达到 O(1)
-
冲突:数组大小毕竟有限,就算元素的 hashCode 唯一,数组大小是 n 的情况下要放入 n+1 个元素,根据鸽巢原理,肯定会发生冲突
-
解决冲突:一种办法就是利用链表,将这些冲突的元素链起来,当然在在此链表中存取元素,时间复杂度会提高为 O(n)
接下来要能说出为什么在在链表的基础上还要有红黑树
- 树化目的是避免链表过长引起的整个 HashMap 性能下降,红黑树的时间复杂度是 O(\\log{n})
有一些细节问题可以继续回答,比如树化的时机【进阶】
-
时机:在数组容量达到 >= 64 且链表长度 >= 8 时,链表会转换成红黑树
-
如果树中节点做了删除,节点少到已经没必要维护树,那么红黑树也会退化为链表
2.4 HashMap 原理(扩容)
扩容因子:0.75 也就是 3/4
-
初始容量 16,当放入第 13 个元素时(超过 3/4)时会进行扩容
-
每次扩容,容量翻倍
-
扩容后,会重新计算 key 对应的桶下标(即数组索引)这样,一部分 key 会移动到其它桶中
2.5 HashMap 原理(方法执行流程)
以 put 方法为例进行说明
-
产生 hash 码。
-
先调用 key.hashCode() 方法
-
为了让哈希分布更均匀,还要对它返回结果进行二次哈希,这个结果称为 hash
-
二次哈希就是把 hashCode 的高 16 位与低 16 位做了个异或运算
-
-
搞定数组。
-
如果数组还不存在,会创建默认容量为 16 的数组,容量称为 n
-
否则使用已有数组
-
-
计算桶下标。
-
利用 (n - 1) & hash 得到 key 对应的桶下标(即数组索引)
-
也可以用 hash % n 来计算,但效率比前面的方法低,且有负数问题
-
用 (n - 1) & hash 有前提,就是容量 n 必须是 2 的幂(如 16,32,64 ...)
-
-
计算好桶下标后,分三种情况
-
如果该桶位置还空着,直接根据键值创建新的 Node 对象放入该位置即可
-
如果该桶是一条链表,沿着链表找,看看是否有值相同的 key,有走更新,没有走新增
-
走新增逻辑的话,是把节点链到尾部(尾插法)
-
新增后还要检查链表是否需要树化,如果是,转成红黑树
-
新增的最后要检查元素个数 size,如果超过阈值,要走扩容逻辑
-
-
如果该桶是一棵红黑树,走红黑树新增和更新逻辑,同样新增的最后要看是否需要扩容
-
P.S.
以上讲解基于 jdk 1.8 及以上版本的 HashMap 实现
考虑到 jdk 1.7 已经很少使用了,故不再介绍基于 1.7 的 HashMap,有需求可以看 b 站黑马面试视频
3、网络编程
3.1 说说 BIO、NIO、AIO
问这个问题,通常是考察你对 Web 应用高并发的理解
预备知识
-
开发 Web 应用,肯定分成客户端和服务器。
-
客户端与服务器交互,肯定得做这么几件事:
-
服务器线程等待 有客户端连接上来
-
客户端真的连上来了,建立连接
-
客户端没有向服务器发送请求,此时服务器线程需要等待数据准备好
-
客户端向服务器发送请求,需要将请求数据 从网卡复制到系统内存
-
-
上面 a. c. 这两个阶段,没有客户端连接,没有数据请求,这时是否需要一个线程时刻盯着?
-
如果需要占用一个线程,那么就称线程被阻塞
-
如果不需要线程盯着,线程可以腾出手来去干别的活,那么就称线程非阻塞
-
-
d. 阶段的数据复制,不会用到 CPU,也就是不会用到线程,同样也存在线程阻塞还是线程非阻塞两种情况
BIO(阻塞 I/O)
-
是指 b. c. d.这几个阶段,线程都得阻塞,腾不出手干别的,即使此时它无所事事
-
高并发下,阻塞线程多了,处理连接、处理请求的能力就会大受影响
-
增加线程不可行,毕竟线程是有限资源,这是成本问题
-
不增加线程也不行,没有新线程,没人去处理新连接,处理新请求
-
NIO(非阻塞 I/O)
-
是指 b. c. 这两个阶段,线程可以不阻塞,腾出手干别的(怎么干别的,要靠多路复用)
-
非阻塞 I/O 通常结合多路复用技术一起使用,能够在高并发下用少量线程处理大量请求
-
多路复用是以面向事件的方式处理连接、处理请求,有事件发生才去处理,没有事件则不会占用线程
-
使用了多路复用技术后,新客户端来了要连接,客户端发来了新请求,都会产生事件,把这些事件交给一个线程去统一处理就行了
-
线程不会在高并发下存在无事可做的现象,它被充分压榨,利用率高
-
AIO(异步 I/O)
-
NIO 在 d. 这个阶段,线程仍需阻塞,不能被解放出来干其它活
-
AIO 则更进一步,只需要提前准备好回调函数,在数据复制时线程被解放,该干嘛干嘛,等数据复制完毕,由系统使用另外线程来调用回调函数做后续处理
-
AIO 在 Linux 下本质还是用多路复用技术来实现
小结
-
BIO 并发性低,但代码更容易编写
-
NIO 并发性高,不过代码编写困难
-
AIO 并发性在 Linux 下没有本质提高,用的人少
-
【进阶】Java 21 起,正式支持虚拟线程
-
配合虚拟线程时,仍然是以 BIO 方式来编写代码,代码编写容易
-
虚拟线程非常廉价,线程不是不够吗,可劲加就行(不用担心线程闲置问题)
-
Java 21 重新实现了网络 API,虚拟线程底层也会配合多路复用机制,在代码易编写的情况下,兼具高性能
-
P.S.
B 是 Blocking 阻塞
N 是 Non-Blocking 非阻塞
A 是 Asynchronous 异步
4、IO流
分类
-
字节流,读写时以字节为单位,抽象父类是 InputStream 和 OutputStream
-
字符流,读写时以字符为单位,抽象父类是 Reader 和 Writer
-
转换流,用来把字节流转换为字符流,相关类:InputStreamReader 和 OutputStreamWriter
-
缓冲流,增加缓冲来提高读写效率,相关类:
-
BufferedInputStream
-
BufferedOutputStream
-
BufferedReader
-
BufferedWriter
-
-
对象流,配合序列化技术将 java 对象转换成字节流或逆操作,相关类:ObjectInputStream,ObjectOutputStream
5、线程与并发
5.1 ThreadLocal 的原理
ThreadLocal 的主要目的是用来实现多线程环境下的变量隔离
- 【解释】即每个线程自己用自己的资源,这样就不会出现共享,既然没有共享,就不会有多线程竞争的问题
原理
-
每个线程对象内部有一个 ThreadLocalMap,它用来存储这些需要线程隔离的资源
-
资源的种类有很多,比如说数据库连接对象、比如说用来判断身份的用户对象 ...
-
怎么区分它们呢,就是通过 ThreadLocal,它作为 ThreadLocalMap 的 key,而真正要线程隔离的资源作为 ThreadLocalMap 的 value
-
ThreadLocal.set 就是把 ThreadLocal 自己作为 key,隔离资源作为值,存入当前线程的 ThreadLocalMap
-
ThreadLocal.get 就是把 ThreadLocal 自己作为 key,到当前线程的 ThreadLocalMap 中去查找隔离资源
-
-
ThreadLocal 一定要记得用完之后调用 remove() 清空资源,避免内存泄漏
5.2 解释悲观锁与乐观锁
悲观锁
-
像 synchronized,Lock 这些都属于悲观锁
-
如果发生了竞争,失败的线程会进入阻塞
-
【理解】悲观的名字由来:害怕其他线程来同时修改共享资源,因此用互斥锁让同一时刻只能有一个线程来占用共享资源
乐观锁
-
像 AtomicInteger,AtomicReference 等原子类,这些都属于乐观锁
-
如果发生了竞争,失败的线程不会阻塞,仍然会重试
-
【理解】乐观的名字由来:不怕 其他线程来同时修改共享资源,事实上它根本不加锁,所有线程都可以去修改共享资源,只不过并发时只有一个线程能成功,其它线程发现自己失败 了,就去重试,直至成功
适用场景
-
如果竞争少,能很快占有共享资源,适合使用乐观锁
-
如果竞争多,线程对共享资源的独占时间长,适合使用悲观锁
P.S.
- 这里讨论 Java 中的悲观锁和乐观锁,其它领域如数据库也有这俩概念,当然思想是类似的
5.3 synchronized 原理
以重量级锁为例,比如 T0、T1 两个线程同时执行加锁代码,已经出现了竞争(代码如下)
synchronized(obj) { // 加锁 ... } // 解锁
-
当执行到行1 的代码时,会根据 obj 的对象头找到 或创建此对象对应的 Monitor 对象(C++对象)
-
检查 Monitor 对象的 owner 属性,用 Cas 操作去设置 owner 为当前线程,Cas 是原子操作,只能有一个线程能成功
-
假设 T0 Cas 成功,那么 T0 就加锁成功,可以继续执行 synchronized 代码块内的部分
-
T1 这边 Cas 失败,会自旋若干次,重新尝试加锁,如果
-
重试过程中 T0 释放了锁,则 T1 不必阻塞,加锁成功
-
重试时 T0 仍持有锁,则 T1 会进入 Monitor 的等待队列阻塞,将来 T0 解锁后会唤醒它恢复运行(去重新抢锁)
-
-
5.4【追问】 synchronized 锁升级
synchronized 锁有三个级别:偏向锁、轻量级锁、重量级锁,性能从左到右逐渐降低
-
如果就一个线程对同一对象加锁,此时就用偏向锁
-
又来一个线程,与前一个线程交替为对象加锁,但只是交替,没有竞争,此时要升级为轻量级锁
-
如果多个线程加锁时发生了竞争,必须升级为重量级锁
【说明】
-
自 java 6 开始对 synchronized 提供了锁升级功能,之前只有重量级锁
-
但从 java 15 开始,偏向锁被标记为已废弃,将来会移除(因为实际带来的性能提升不明显,某些情况下反而影响性能)
5.5 对比 synchronized 和 volatile
并发编程需要从三个方面考虑线程安全,分别是:原子性、可见性、有序性
-
volatile 修饰共享变量,可以保证它的可见性和有序性,但不能保证原子性
-
synchronized 代码块,不仅能保证共享变量的可见性、有序性,同时也能保证原子性
P.S.
- 实际上用 volatile 去保证可见性和有序性,并不像上面那一句话描述的那么简单,可以参考黑马课程
5.6 对比 synchronized 和 Lock
-
synchronized 是关键字,Lock 是 Java 接口
-
前者底层是 C++ 代码实现锁,后者是 Java 自己的代码来实现锁
-
Lock 功能更多,比如可以选择是公平锁还是非公平锁、可以设置加锁超时时间、可打断等
-
Lock 的提供多种扩展实现(例如读写锁),可以根据场景选择更合适的实现
-
Lock 释放锁需要调用 unlock 方法,而 synchronzied 在代码块结束无需显式调用就可以释放锁
5.7 线程池的核心参数
记忆七个参数
-
核心线程数
- 核心线程会常驻线程池
-
最大线程数
-
如果同时执行的任务数超过了核心线程数,且队列已满,会创建新的线程来救急
-
总线程数(新线程+原有的核心线程)不超这个最大线程数
-
-
存活时间
- 超过核心线程数的线程一旦闲下来,会存活一段时间,然后被销毁
-
存活时间单位
-
工作队列
- 如果同时执行的任务数超过了核心线程数,会把暂时无法处理的任务放入此队列
-
线程工厂
- 可以控制池中线程的命名规则,是否是守护线程等(不太重要的参数)
-
拒绝策略,队列放满任务,且所有线程都被占用,再来新任务,就会有问题,此时有四种拒绝策略:
-
AbortPolicy 报错策略,直接抛异常
-
CallerRunsPolicy 推脱策略,线程池不执行任务,推脱给任务提交线程
-
DiscardOldestPolicy 抛弃最老任务策略,把队列中最早的任务抛弃,新任务加入队列等待
-
DiscardPolicy 抛弃策略,直接把新任务抛弃不执行
-
6、JVM 虚拟机
6.1 JVM 堆内存结构
堆内存的布局与垃圾回收器有关。
传统的垃圾回收器会把堆内存划分为:老年代和年轻代,年轻代又分为
-
伊甸园 Eden
-
幸存区 S0,S1
如果是 G1 垃圾回收器,会把内存划分为一个个的 Region,每个 Region 都可以充当
-
伊甸园
-
幸存区
-
老年代
-
巨型对象区
6.2 垃圾回收算法
记忆三种:
-
标记-清除算法。优点是回收速度快,但会产生内存碎片
-
标记-整理算法。相对清除算法,不会有内存碎片,当然速度会慢一些
-
标记-复制算法。将内存划分为大小相等的两个区域 S0 和 S1
-
S0 的职责用来存储对象,S1 始终保持空闲
-
垃圾回收时,只需要扫描 S0 的存活对象,把它们复制到 S1 区域,然后把 S0 整个清空,最后二者互换职责即可
-
不会有内存碎片,特别适合存活对象很少时(因为此时复制工作少)
-
6.3【追问】伊甸园、幸存区、老年代细节
-
对象最初都诞生在伊甸园,这些对象通常寿命都很短,在伊甸园空间不足,会触发年轻代回收,还活着的对象进入幸存区 S0,年轻代回收适合采用标记-复制算法
-
接下来再触发年轻代回收时,会将伊甸园和 S0 仍活着的对象复制到 S1,清空 S0,交换 S0 和 S1 职责
-
经过多次回收仍不死的对象,会晋升至老年代,老年代适合放那些长时间存活的对象
-
老年代回收如果满了,会触发老年代垃圾回收,会采用标记-整理或标记-清除算法。老年代回收时的暂停时间通常比年轻代回收更长
还会常问
晋升条件
-
注意不同垃圾回收器,晋升条件不一样
-
在 parallel 里,经历 15 次(默认值)新生代回收不死的对象,会晋升
-
可以通过 -XX:MaxTenuringThreshold 来调整
-
例外:如果幸存区中的某个年龄对象空间占比已经超过 50%,那么大于等于这个年龄的对象会提前晋升
-
大对象的处理
-
首先大对象不适合存储在年轻代,因为年轻代是复制算法,对象移动成本高
-
注意不同垃圾回收器,大对象处理方式也不一样
-
在 serial 和 cms 里,如果对象大小超过阈值,会直接把大对象晋升到老年代
- 这个阈值通过 -XX:PretenureSizeThreshold 来设置
-
在 g1 里,如果对象被认定为巨型对象(对象大小超过了 region 的一半),会存储在巨型对象区
- Region 大小是堆内存总大小 / 2048(必须取整为2的幂),或者通过 -XX:G1HeapRegionSize 来设置
P.S.
著名教材《深入理解Java虚拟机》一书关于这些论述,很多观点陈旧过时,需要带批判眼光来学习。例如在它的《内存分配与回收策略》这一章节,提到了这些:
对象优先在Eden分配(OK)
大对象直接进入老年代(没有提到 g1 情况)
长期存活的对象将进入老年代(即我上面讲的晋升条件,但没强调要区分垃圾回收器)
动态对象年龄判定(即提前晋升)
空间分配担保(已过时)文中提到的 -XX:+HandlePromotionFailure 参数在 jdk8 之后已经没了
7、Lambda表达式
什么是 Lambda 表达式
-
文献中把 Lambda 表达式一般称作匿名函数 ,语法为
(参数部分) -> 表达式部分 -
它本质上是一个函数对象
-
它可以用在那些需要将行为参数化的场景,例如 Stream API,MyBatisPlus 的 QueryWrapper 等地方
Lambda 与匿名内部类有何异同
-
它们都可以用于需要行为参数化的场景
-
Lambda 表达式必须配合函数式接口使用,而匿名内部类不必拘泥于函数式接口,其它接口和抽象类也可以
-
Lambda 表达式比匿名内部类语法上更加简洁
-
匿名内部类是在编译阶段由程序员编写提供,而 Lambda 表达式是在运行阶段动态生成它所需的类
-
【进阶】Lambda 中 this 含义与匿名内部类中的 this 不同
8、反射及泛型
8.1 反射
什么是反射
-
反射是 java 提供的一套 API,通过这套 API 能够在运行期间
-
根据类名加载类
-
获取类的各种信息,如类有哪些属性、哪些方法、实现了哪些接口 ...
-
类型参数化,根据类型创建对象
-
方法、属性参数化,以统一的方式来使用方法和属性
-
-
反射广泛应用于各种框架实现,例如
-
Spring 中的 bean 对象创建、依赖注入
-
JUnit 单元测试方法的执行
-
MyBatis 映射查询结果到 java 对象
-
...
-
-
反射在带来巨大灵活性的同时也不是没有缺点,那就是反射调用效率会受一定影响
8.2 泛型
什么是 Java 泛型
-
泛型的主要目的是实现类型参数化,java 在定义类、定义接口、定义方法时都支持泛型
-
泛型的好处有
-
提供编译时类型检查,避免运行时类型转换错误,提高代码健壮性
-
设计更通用的类型,提高代码通用性
-
【例如】想设计 List 集合,里面只放一种类型的元素,如果不用泛型,怎么办呢?你必须写很多实现类
-
Impl1 实现类中,只放 String
-
Impl2 实现类中,只放 Integer
-
...
-
要支持新的元素类型,实现类型也得不断增加,解决方法需要把元素类型作为参数,允许它可变化:List<T>,其中 T 就是泛型参数,它将来即可以是 String,也可以是 Integer ...
P.S.
【例如】是为了帮助你理解,不是必须答出来。
关键是答出类型参数化,懂的面试官不必多说,不懂的也没必要跟他继续啰嗦
9、Tomcat优化
P.S.
Tomcat 优化要从多方面综合考虑,如
Tomcat JVM 参数调优
Tomcat 线程池配置
网络配置优化
静态资源优化
日志记录优化
...
篇幅原因,本题作答时只侧重其中线程池配置和网络配置这两方面
以 springboot(3.2.3) 中的 tomcat 配置为例
server.tomcat.max-connections=8192 server.tomcat.accept-count=100 server.tomcat.threads.max=200 server.tomcat.threads.min-spare=10
-
Tomcat I/O 模式默认采用 NIO,由于一般采用 Linux 系统,因此改成 NIO2 没有必要
-
这些配置项值都是 springboot 的默认值,这些值其实够用,根据情况调整,其中
-
max-connections 控制最大连接数
-
accept-count 控制连接队列中的连接数
-
threads.max 控制线程池中最大线程数
-
threads.min-spare 控制线程池中最少备用线程数
-
【进阶】虚拟线程优化
-
springboot(3.2.x)配合 jdk 21 可以使用虚拟线程来优化
spring.threads.virtual.enabled=true -
更早 springboot 想使用 jdk 21 虚拟线程,可以用替换 Tomcat 线程池的办法
@Bean public TomcatProtocolHandlerCustomizer<?> tomcatProtocolHandlerCustomizer() { return protocolHandler -> protocolHandler .setExecutor(Executors.newVirtualThreadPerTaskExecutor()); }