四、内存中的栈区和堆区 (Stack and Heap)
概念:
-
栈区 (Stack): 就像一个后进先出的箱子。
-
堆区 (Heap): 就像一个巨大的、可以自由分配和回收的空地。程序员可以使用
new和delete手动地在这片区域申请和释放内存。 堆区的大小相对较大,但需要程序员自己管理。
示例代码:
cpp
#include <iostream>
int* createOnHeap() {
int* num = new int(100); // 在堆区分配内存
return num;
}
void functionOnStack() {
int localVar = 50; // 在栈区分配内存
std::cout << "栈区变量 localVar 的地址: " << &localVar << std::endl;
}
int main() {
// 栈区变量
int a = 10;
std::cout << "栈区变量 a 的地址: " << &a << std::endl;
// 堆区变量
int* b = new int;
*b = 20;
std::cout << "堆区变量 b 的地址: " << b << std::endl;
functionOnStack();
int* heapVar = createOnHeap();
std::cout << "堆区变量 heapVar 的地址: " << heapVar << std::endl;
std::cout << "堆区变量 heapVar 指向的值: " << *heapVar << std::endl;
delete heapVar;
heapVar = nullptr;
return 0;
}讲解要点:
- 栈区和堆区的区别:
| 特征 | 栈区 (Stack) | 堆区 (Heap) |
|---|---|---|
| 分配和释放 | 编译器自动分配和释放 | 程序员手动分配和释放 (new/delete) |
| 存储内容 | 局部变量、函数参数、函数调用信息 | 动态分配的内存 |
| 大小限制 | 有限,由编译器或操作系统预先设定 | 相对较大,受系统可用内存限制 |
| 分配速度 | 快 | 相对较慢 |
| 管理方式 | 自动管理 | 手动管理 |
-
栈区和堆区的内存分配方式:
- 栈区: 内存分配和释放就像叠盘子一样,后进先出。
- 堆区: 内存分配和释放更加灵活,可以在任意时刻申请和释放任意大小的内存块。操作系统维护着一个空闲内存列表,当
new请求内存时,系统会找到合适的空闲块分配出去。
-
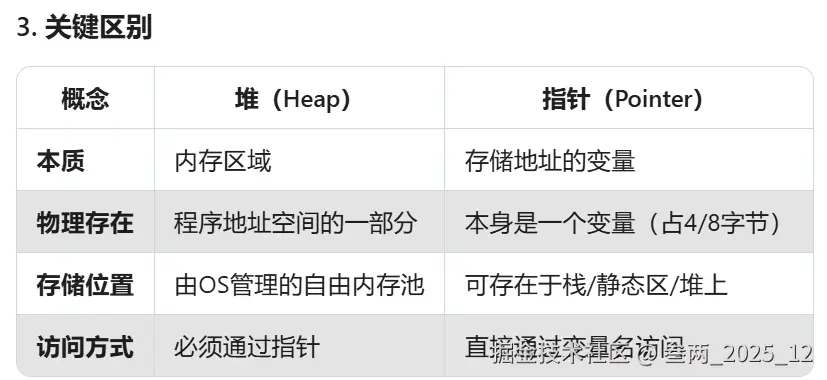
堆是内存区域,指针是访问内存的工具。
延申问题:堆是指针吗 堆(Heap)不是指针,但堆内存的访问必须通过指针来实现。